线性回归是一种非常简单但已被证明对许多情况都非常有用。
在本帖中,您将逐步了解线性回归的工作原理。阅读本帖后,您将了解
- 如何一步一步计算简单线性回归。
- 如何使用电子表格执行所有计算。
- 如何使用模型对新数据进行预测。
- 大大简化计算的快捷方式。
本教程是为开发人员编写的,不假定您有任何数学或统计学背景。
本教程的目的是让您在自己的电子表格中进行学习,这将有助于巩固概念。
通过我的新书《机器学习算法精通》启动您的项目,其中包含分步教程和所有示例的Excel电子表格文件。
让我们开始吧。
更新#1:修复了 RMSE 计算中的一个错误。

机器学习简单线性回归教程
照片由Catface27拍摄,保留部分权利。
教程数据集
我们使用的数据集是完全虚构的。
以下是原始数据。
|
1 2 3 4 5 6 |
x y 1 1 2 3 4 3 3 2 5 5 |
属性 x 是输入变量,y 是我们试图预测的输出变量。如果我们获得更多数据,我们将只有 x 值,而会关注预测 y 值。
以下是 x 与 y 的简单散点图。
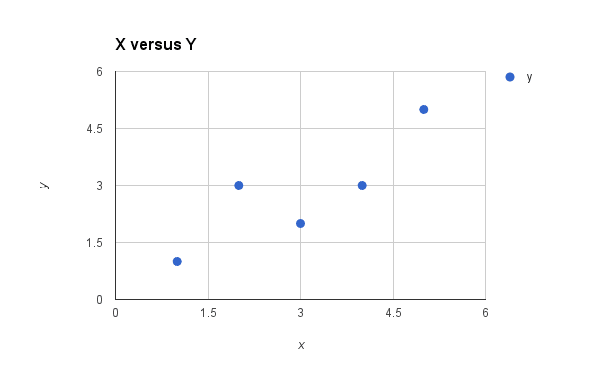
用于简单线性回归的数据集图
我们可以看到 x 和 y 之间的关系看起来有点线性。也就是说,我们可能可以在图的左下角到右上角画一条对角线来大致描述数据之间的关系。
这表明对这个小型数据集使用线性回归可能是合适的。
获取您的免费算法思维导图
方便的机器学习算法思维导图样本。
我创建了一份方便的思维导图,其中包含60多种按类型组织的算法。
下载、打印并使用它。
还可以独家访问机器学习算法电子邮件迷你课程。
简单线性回归
当我们只有一个输入属性 (x) 并想使用线性回归时,这被称为简单线性回归。
如果我们有多个输入属性(例如 x1、x2、x3 等),这被称为多元线性回归。线性回归的步骤与多元线性回归不同,且更简单,因此这是一个很好的起点。
在本节中,我们将根据训练数据创建一个简单线性回归模型,然后对训练数据进行预测,以了解模型对数据的关系学习得如何。
使用简单线性回归,我们希望模型如下所示
y = B0 + B1 * x
这是一个直线,其中 y 是我们想要预测的输出变量,x 是我们已知的输入变量,B0 和 B1 是我们需要估计的系数,它们可以移动直线。
技术上讲,B0 被称为截距,因为它决定了直线在 y 轴上的截距。在机器学习中,我们可以称之为偏差,因为它被加到所有预测中以进行偏移。B1 项被称为斜率,因为它定义了直线的斜率,或者 x 在我们添加偏差之前如何转换为 y 值。
目标是找到最佳的系数估计值,以最小化从 x 预测 y 的误差。
简单回归很棒,因为我们不必通过试错来寻找值,也不必使用更高级的线性代数来解析计算它们,而是可以直接从数据中估计它们。
我们可以开始估计 B1 的值
B1 = sum((xi-mean(x)) * (yi-mean(y))) / sum((xi – mean(x))^2)
其中 mean() 是我们数据集中变量的平均值。xi 和 yi 指的是我们需要对数据集中的所有值重复这些计算,而 i 指的是 x 或 y 的第 i 个值。
我们可以使用 B1 和我们数据集的一些统计数据来计算 B0,如下所示
B0 = mean(y) – B1 * mean(x)
不算太难吧?我们可以在电子表格中直接计算这些。
估计斜率 (B1)
让我们从方程的顶部开始,即分子。
首先,我们需要计算 x 和 y 的平均值。平均值计算为
1/n * sum(x)
其中 n 是值的数量(本例中为 5)。您可以在电子表格中使用 AVERAGE() 函数。让我们计算 x 和 y 变量的平均值
mean(x) = 3
mean(y) = 2.8
现在我们需要计算每个变量与平均值的差值。我们先用 x 来做
|
1 2 3 4 5 6 |
x mean(x) x - mean(x) 1 3 -2 2 3 -1 4 3 1 3 3 0 5 3 2 |
现在我们为 y 变量也这样做
|
1 2 3 4 5 6 |
y mean(y) y - mean(y) 1 2.8 -1.8 3 2.8 0.2 3 2.8 0.2 2 2.8 -0.8 5 2.8 2.2 |
现在我们有了计算分子的部分。我们所要做的就是将每个 x 的差值与每个 y 的差值相乘,然后计算这些乘积的总和。
|
1 2 3 4 5 6 |
x - mean(x) y - mean(y) 乘积 -2 -1.8 3.6 -1 0.2 -0.2 1 0.2 0.2 0 -0.8 0 2 2.2 4.4 |
对最后一列求和,我们计算出的分子是 8。
现在我们需要计算 B1 方程的底部,即分母。这是通过计算每个 x 值与平均值的平方差的总和来计算的。
我们已经计算了每个 x 值与平均值的差值,我们只需要对每个值进行平方,然后计算总和。
|
1 2 3 4 5 6 |
x - mean(x) 平方 -2 4 -1 1 1 1 0 0 2 4 |
计算这些平方值的总和得到分母 10
现在我们可以计算斜率的值了。
B1 = 8 / 10
B1 = 0.8
估计截距 (B0)
这要容易得多,因为我们已经知道所有涉及项的值。
B0 = mean(y) – B1 * mean(x)
或者
B0 = 2.8 – 0.8 * 3
或者
B0 = 0.4
很简单。
进行预测
现在我们有了简单线性回归方程的系数。
y = B0 + B1 * x
或者
y = 0.4 + 0.8 * x
让我们通过对训练数据进行预测来尝试模型。
|
1 2 3 4 5 6 |
x y 预测的 y 1 1 1.2 2 3 2 4 3 3.6 3 2 2.8 5 5 4.4 |
我们可以将这些预测值与我们的数据一起绘制成一条线。这给了我们一个直观的印象,这条线在多大程度上拟合了我们的数据。
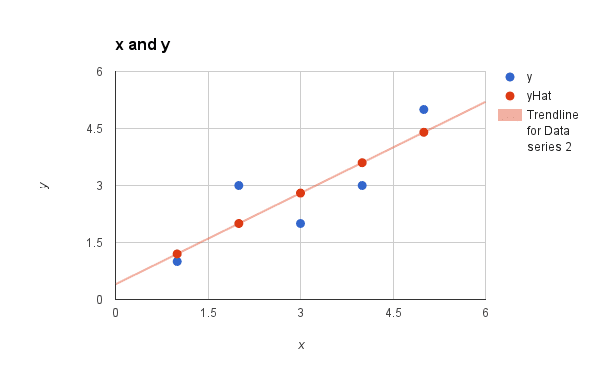
简单线性回归模型
误差估计
我们可以计算一个预测误差,称为均方根误差 (Root Mean Squared Error) 或 RMSE。
RMSE = sqrt( sum( (pi – yi)^2 )/n )
其中 sqrt() 是平方根函数,p 是预测值,y 是实际值,i 是特定实例的索引,n 是预测的数量,因为我们必须计算所有预测值的误差。
首先,我们必须计算模型预测值与实际 y 值之间的差值。
|
1 2 3 4 5 6 |
预测的 y - 实际 y 误差 1.2 1 0.2 2 3 -1 3.6 3 0.6 2.8 2 0.8 4.4 5 -0.6 |
我们可以轻松计算这些误差值的平方(误差*误差或误差^2)。
|
1 2 3 4 5 6 |
误差的平方 误差 0.2 0.04 -1 1 0.6 0.36 0.8 0.64 -0.6 0.36 |
这些误差的总和是 2.4 单位,除以 n 并取平方根得到
RMSE = 0.692
或者说,每次预测平均误差约为 0.692 单位。
快捷方式
在我们结束之前,我想给您展示一种快速计算系数的方法。
简单线性回归是最简单的回归形式,也是研究得最多的。有一个快捷方式,您可以使用它来快速估计 B0 和 B1 的值。
实际上,这是计算 B1 的快捷方式。B1 的计算可以重写为
B1 = corr(x, y) * stdev(y) / stdev(x)
其中 corr(x) 是 x 和 y 之间的相关性,stdev() 是变量的标准差计算。
相关性(也称为皮尔逊相关系数)是衡量两个变量在 -1 到 1 范围内的相关程度。值为 1 表示两个变量完全正相关,它们一起移动,值为 -1 表示它们完全负相关,一个移动时另一个会向相反方向移动。
标准差是衡量数据与平均值平均分散程度的指标。
您可以使用电子表格中的 PEARSON() 函数将 x 和 y 的相关性计算为 0.852(高度相关),并使用 STDEV() 函数计算 x 的标准差为 1.5811,y 的标准差为 1.4832。
将这些值代入,我们得到
B1 = 0.852 * 1.4832 / 1.5811
B1 = 0.799
与上面的 0.8 值非常接近。请注意,如果我们对电子表格中的相关性和标准差方程使用更完整的精度,我们会得到 0.8。
总结
在本帖中,您了解了如何在电子表格中逐步实现线性回归。您学到了
- 如何根据训练数据估计简单线性回归模型的系数。
- 如何使用学习到的模型进行预测。
您对这篇帖子或线性回归有任何疑问吗?请留言提问,我会尽力回答。







我花了一天时间学习,这真的很好,感谢 Jasom。
很高兴你觉得它有用,Chen。
你能帮我解决一个困扰我的问题吗?
谢谢。非常有用的文章。
我显然没有数学技能。但这些东西太奇怪了。我在 Udemy.com 上有一门机器学习课程,但我不知道是怎么回事或者为什么。
我不知道我的课程是否糟糕,意思是讲师不好,或者只是超出我的理解能力。但我完全不知道这些东西意味着什么或做什么。Python 中的代码也很奇怪。
有没有人推荐一门适合“愚蠢的人”学习的 Udemy 机器学习课程?这些东西真的很难。嗯,我课程的一个小时让我觉得自己很蠢。
刚开始的时候确实有点奇怪。
也许这会有帮助。
https://machinelearning.org.cn/start-here/#getstarted
特别是这个
https://machinelearning.org.cn/think-machine-learning/
有一个 YouTube 教程对我理解线性回归很有帮助,你一定要看看。
https://www.youtube.com/watch?v=ujTCoH21GlA&list=PLzMcBGfZo4-mP7qA9cagf68V06sko5otr
感谢分享。
你是一位很棒的导师。天赐的
继续做好工作..
感谢你的美言,AmiMo。
嗨,Jason,
非常感谢这篇精彩的博文!我正在阅读所有内容,在这里学到了很多新东西。
如果我错了,请纠正我,但我觉得这篇帖子中 RMSE 的计算有小错误。我认为平方误差的总和应该先取平均值,然后再取平方。结果也很奇怪:RMSE = 1.549 超过了每个数据点的误差。
是的,谢谢 Dominika。我正在处理这个列表以修复它。
更新:我已经修复了 RMSE 的计算。
首先,这是一篇很好的带有解释的文章。
我有一个疑问。
最后我们得到了 RMSE 值,但是方程的哪个部分进行了训练,以便我们的误差能减少到最佳水平或接近于零?
如果可行,请解释一下。
你好 Chandan,由于问题中的噪声,我们可能无法获得零误差。
你好 Jason,这真的很有帮助。
我有一个疑问。
如何在线性回归中设置 theta 值来最小化成本函数?
Pranaya,在上下文中,theta 指的是什么?学习率?系数?
你好 Jason,
您关于简单线性回归的文章太棒了。有关于岭回归的教程吗?
谢谢 Deependra。抱歉,目前没有关于岭回归的内容。
您能解释一下以下方程吗?
B1 = sum((xi-mean(x)) * (yi-mean(y))) / sum((xi – mean(x))^2)
您是如何得到这个方程的?我的意思是 B1 是斜率,所以它应该看起来像 ((y2-y1)/(x2-x1))。
我是新手。
你好 Amar,你可以在这里看到方程的解释
https://en.wikipedia.org/wiki/Simple_linear_regression#Fitting_the_regression_line
这不合适!!!!
也许我的教程不适合您。
哦,Jeersserg!到底是什么不合适??
非常感谢🙂
不客气,Asbar。
您太棒了 Jason。感谢这篇文章。
不客气。
Jason 完成了这项伟大工作。
谢谢 Jason,
谢谢 Munir。
嗨,Json,
感谢您的优质教程。上帝保佑您
很高兴您觉得有用,Nuwan。
非常简单方便应用。
Jason,你把它变得简单了。请继续教育工作。
谢谢。
哦,是的 Raja!
嗯,呃
这是什么 Raja…??
你好 Jason,我有点困惑,可能是因为这里提到的公式解释。
B1 = corr(x, y) * stdev(y) / stdev(x)
另外,
corr(x,y) = (x 和 y 的协方差) / stdev(x)*stdev(y)
那么这是否意味着:B1= (x 和 y 的协方差) / (stdev(x))^2)
如果我错了,请纠正我,这困扰着我。这样我们就不必计算 stdev(y) 了。请解释一下!
您可以在此处查看推导。
https://en.wikipedia.org/wiki/Simple_linear_regression
精彩的教程。我对如何找到 Theta 感到非常困惑。我看了很多 YouTube 和其他网站的教程……现在我明白了。
很高兴听到这个消息。
解释得非常好,非常出色。我很高兴找到了这个教程……谢谢 Jason
谢谢 Hima。
感谢 Jason 的精彩文章,
一个澄清,对于给定的数据集列表,这是最佳拟合,我们不需要调整 B0 和 B1,我的假设正确吗?
这是一个拟合,也许不是最佳拟合,因为我们使用的是随机过程。
我完全不明白。请解释清楚。
非常好的文章。我不明白为什么我们在这里计算 RMSE。您能解释一下吗?
它是用来总结模型技能的预测误差。
如果您愿意,您也可以使用其他误差指标。
正如您在概率统计中所知,您对底层数据做了许多假设。机器学习如何忽略这些?
通过关注预测模型在所有其他问题上的技能。
它将问题从“数据中发生了什么”转变为“什么将使预测更具技能”。
在“进行预测”部分:您是如何得到“预测的 Y”字段的值的?
通过使用我们开发的回归方程并输入输入数据 (x)。
这非常有帮助。谢谢你,Jason!
谢谢 Esther,很高兴听到这个。
你好 Jason,算法思维导图链接无法正常工作!
您可以在此处获取。
https://machinelearningmastery.leadpages.co/machine-learning-algorithms-mini-course/
非常感谢 Jason 的精彩解释,正如每个人都知道机器学习是多么难,您把它变得如此简单,请继续,上帝保佑您,再次感谢。
谢谢 AJ,坚持下去!
感谢 Jason 的精彩解释。
您是否还写了关于多元线性回归的博客?
如果有,请附上链接……
是的,请使用页面顶部的搜索功能。
抱歉,我无法通过顶部的搜索框找到该博客,所以请发送给我博客的链接……
Jason,你能推导一下逻辑回归和多元回归吗?
感谢您的建议。
您的博客对学习非常有帮助。
谢谢,听到这个我很高兴。
嗨,Jason,
希望您一切都好!
我真的很欣赏您使用 Excel 来更好地理解算法的想法。我们有时会忽视简单事物的力量。
谢谢。
谢谢,希望它有帮助。
如何创建数据?或者,如果我将数据复制到一个 csv 文件中,如何将其导入 Python?
这篇博文展示了如何在 Python 中加载 CSV 文件。
https://machinelearning.org.cn/load-machine-learning-data-python/
首先,非常感谢您用非常简单的方式进行解释。
现在是问题时间:)
在教程的结尾,您解释了计算系数 B1 的快捷方法。
对于另一个系数 B0,也有快捷方法吗?
谢谢你
B0 可以以同样的方式从 B1 计算出来。
您能否详细解释一下线性回归是如何工作的,例如,为了获得最佳拟合线,我们如何使用 OLS 估计量等等?
感谢您的建议。
这是解释线性回归整体概念的非常简单的方法。非常令人印象深刻和出色。非常容易理解。优秀!
谢谢。
Jason,感谢您简化了分析。
我对计算您提到的“平均每个预测值会错约 0.692 个单位”的误差有一个疑问。
这是什么意思?无论如何,从散点图来看,预测效果很好。
RMSE 是否有任何范围?这意味着如果它接近 1,则错误越多。
我是新手,不太懂。
误差得分通常相对于输出变量的比例和单位(例如,厘米、英尺、美元等)。最好结合一些领域专业知识来解释这些得分。
解释得很棒。我对这个概念更清楚了。
很高兴它有帮助。
嗨,Jason,
非常感谢您的所有博文。我非常享受学习 ML 的过程!
我对上面的博文有一个疑问。使用上面的方法,我们只会得到一个 B0 和 B1 的值,对吗?我们如何使用这种方法来最小化误差并找到新的 B0 和 B1?如果我在这里有什么误解,请纠正我。
此致
Sara。
是的,这个过程会得到一组系数,这就是模型。
学习过程将最小化误差。
嗨,Jason,
这是对简单线性回归的一个很好的解释。
但是多元线性回归的方程是什么?我将如何计算其中的常数?
提前感谢。
您只需添加更多变量(X)和系数(beta)。
嗨,Jason
我阅读了 Wiki 上的“Fitting the regression line”部分(https://en.wikipedia.org/wiki/Simple_linear_regression#Fitting_the_regression_line)。但我自己找不到用于最小化问题的 alpha_hat 和 beta_hat。您能解释一下或给我一些数学参考资料,以便我能自己解决问题吗?
谢谢。
也许这本书
https://amzn.to/2LET8rD
嗨,Jason,
我是一名技术学士。您能否推荐一本适合初学数据科学和机器学习的书?
从这里免费开始。
https://machinelearning.org.cn/start-here/
嗨 Jason,这篇文章写得非常好,解释得很详细,我在其他网站上找不到这样的内容。非常感谢。
“如何使用”非常清晰,如果能提到“何时使用”,那就更好了。
许多论坛提到,1个因变量和1个自变量是标准,但我认为具有相同标准的数据也可能是非线性的。请帮助我弄清楚“何时使用何种方法”。
再次感谢您的详细解释。
谢谢 Krishna。
解释得很棒。
我很高兴也很兴奋能将您的这篇博文作为我学习的第一个机器学习算法。
非常感谢!
谢谢。
解释得很棒,先生。
谢谢。
您能否为 ML 教程录制视频?这会吸引很多关注。
感谢您的建议。
我认为视频太被动了,我们是一个“实践者”社区,而不是“观看者”。
谢谢 Jason,
非常有用的观点。
您能否继续讲解多元线性回归?
感谢您的建议。
非常感谢!
不客气。
谢谢 Jason。
我搜索了很多关于线性回归的资料,但没有找到好的来源。这个来源非常好。谢谢,兄弟。
谢谢,很高兴对您有帮助。
您的文章非常好,我能轻松理解简单线性回归的概念。感谢您的精彩文章。
谢谢,很高兴听到这个。
非常感谢您,先生,您的解释非常精彩。
不客气。很高兴它有帮助。
谢谢您,先生,您的解释非常好。请继续。您能解释一下 Kernel PCA 吗?
谢谢。
好建议!
解释得非常简单有趣。请继续讲解其他预测算法????
谢谢。
非常感谢您分享有价值的信息。易于理解,无需任何工具即可获取详细信息。
完成这些计算后,我希望我们能认为模型是准确的。请建议。
可以通过在未用于训练的数据上进行预测,并计算预测值与预期值之间的误差来评估模型。
明白了。感谢您的澄清。
不客气。
为什么不使用 pinv() 伪逆来获取 B0 和 B1 参数?是否有关于“快捷”方法的参考资料供我参考?此方法在不执行逆矩阵运算方面做得很好。谢谢。
是的,请看这个
https://en.wikipedia.org/wiki/Simple_linear_regression
还有这个。
https://machinelearning.org.cn/solve-linear-regression-using-linear-algebra/
感谢您的解释。通过阅读您的指南 15 分钟,学习概念比上 2 小时的课更容易!希望您一切安好、平安。
谢谢!
嗨 Jason,文章很棒。我想知道您是否有关于多元线性回归的类似文章?
也许这会有帮助。
https://machinelearning.org.cn/multi-output-regression-models-with-python/
嗨,Jason,
我的数据记录了我每天的心情。我收集了一年左右的数据,它有两列:日期和心情。在我记录心情的同时,有 5 种心情。现在,我想使用这些数据预测未来某个日期的我的心情。我想知道您是否能帮助我,我是一个 DS & ML 的绝对新手。我正在考虑使用 LinearRegression 来预测结果。
您能否建议我如何着手解决这个问题?我该如何将日期作为参数传递给 ML Algo 来预测心情?请帮助我。
注意:如果您愿意,我可以分享数据,其中不包含任何个人信息。任何对此感兴趣的人都可以通过 maxlinkdir[at]Gmail[dot]com 联系我。
谢谢。
听起来像一个时间序列问题。
https://machinelearning.org.cn/start-here/#timeseries
也许是时间序列分类。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
或者尝试构建一个用于普通分类的监督学习问题。
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
你好,
谢谢您的回复。我会尽力通过时间序列来解决它。首先,我需要大量阅读,因为我是在自学 DS & ML。我认为解决这个问题需要一些时间。一旦我解决了这个问题,我会在这里给您留言。
再次感谢。
不客气。
嗨,Jason,
这是一个很棒的资源,只有一个疑问:由于 RMSE 是 0.69,这是否意味着我们的模型有 69% 的预测不正确?换句话说,我们的模型有 31% 的预测是正确的。
另外,在估计误差后,我们是需要将平方数相加还是取平均值,正如
Dominika Tkaczyk 在 2016 年 9 月 30 日指出的那样。
如果您能澄清这一点,我将不胜感激。
谢谢。
不,这是模型的预测误差。可以理解为,平均而言,预测值会偏离真实值约 0.69 个单位,具体单位取决于目标变量的单位。
嗨,Jason,
花了几个小时才完成。无需编码就完成了,非常值得。
此致,
S Dash。
干得好!
感谢教程。这是互联网上关于回归基本理解的最好的教程之一。
谢谢!
嗨 Jason,这帮助我消除了疑虑,使我能相当简单地理解简单线性回归的概念和应用。非常感谢您的努力。谢谢。
不客气。
嗨,Jason,
这是一篇很棒的文章,也是机器学习教程中最好的资源之一。您能否解释一下如何使用 kerasregressor 在多元回归中查找系数?
请看这个例子
https://machinelearning.org.cn/regression-tutorial-keras-deep-learning-library-python/