减少预测模型的输入变量数量被称为降维。
更少的输入变量可以生成更简单的预测模型,该模型在对新数据进行预测时可能具有更好的性能。
在机器学习中,也许更流行的降维技术是奇异值分解,简称SVD。这是一项源自线性代数领域的技朮,可用作数据预处理技术,在拟合模型之前创建稀疏数据集的投影。
在本教程中,您将了解在开发预测模型时如何使用SVD进行降维。
完成本教程后,您将了解:
- 降维涉及减少建模数据中的输入变量或列的数量。
- SVD是一项源自线性代数领域的技朮,可用于自动执行降维。
- 如何评估使用SVD投影作为输入并使用新原始数据进行预测的预测模型。
启动您的项目,阅读我的新书《机器学习数据准备》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 更新于2020年5月:改进了代码注释。

Python 中用于降维的奇异值分解
照片作者:Kimberly Vardeman,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- 降维与SVD
- SVD Scikit-Learn API
- SVD降维实例
降维与SVD
降维指的是减少数据集的输入变量数量。
如果您的数据以行和列的形式表示,例如在电子表格中,那么输入变量就是作为模型输入以预测目标变量的列。输入变量也称为特征。
我们可以将数据的列视为n维特征空间中的维度,将数据的行视为该空间中的点。这是数据集的一个有用的几何解释。
在具有 k 个数值属性的数据集中,您可以将数据可视化为 k 维空间中的点云……
— 第 305 页,《数据挖掘:实用机器学习工具和技术》,第 4 版,2016 年。
特征空间中维度数量过多可能意味着该空间的体积非常大,反过来,该空间中的点(数据行)通常代表一个很小且不具代表性的样本。
这会极大地影响在具有许多输入特征的数据上拟合的机器学习算法的性能,通常称为“维度灾难”。
因此,减少输入特征的数量通常是可取的。这会减少特征空间的维数,因此称为“降维”。
降维的一种流行方法是使用线性代数领域的技朮。这通常被称为“特征投影”,所使用的算法称为“投影方法”。
投影方法旨在减少特征空间中的维度数量,同时保留数据中观察到的变量之间最重要的结构或关系。
在处理高维数据时,通过将数据投影到捕获数据“本质”的低维子空间来降低维度通常很有用。这被称为降维。
— 第 11 页,《机器学习:概率视角》,2012 年。
生成的投影数据集可以作为输入来训练机器学习模型。
本质上,原始特征不再存在,而是从可用数据中构建新的特征,这些新特征与原始数据不直接可比,例如,没有列名。
将来在进行预测(例如测试数据集和新数据集)时提供给模型的所有新数据,也必须使用相同的技朮进行投影。
当数据稀疏时,奇异值分解(SVD)可能是最流行的降维技朮。
稀疏数据是指其中许多值为零的数据行。在某些问题域中,例如推荐系统,其中用户对数据库中的很少一部分电影或歌曲有评分,而对所有其他情况的评分都为零,这通常是这种情况。另一个常见示例是文本文档的词袋模型,其中文档对某些单词具有计数或频率,而大多数单词的值为0。
适用于SVD降维的稀疏数据示例
- 推荐系统
- 客户-产品购买
- 用户-歌曲收听次数
- 用户-电影评分
- 文本分类
- 独热编码
- 词袋计数
- TF/IDF
有关稀疏数据和稀疏矩阵的更多信息,请参阅教程
SVD可被视为一种投影方法,其中具有m列(特征)的数据被投影到具有m或更少列的子空间中,同时保留原始数据的本质。
SVD广泛用于计算其他矩阵运算(例如矩阵逆)以及作为机器学习中的数据降维方法。
有关SVD详细计算方式的更多信息,请参阅教程
现在我们已经熟悉了SVD降维,让我们看看如何将其应用于scikit-learn库。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
SVD Scikit-Learn API
我们可以使用SVD来计算数据集的投影,并选择投影的维数或主成分的数量作为模型的输入。
scikit-learn库提供了TruncatedSVD类,可以将其拟合到数据集上,并用于转换训练数据集和将来任何其他数据集。
例如
|
1 2 3 4 5 6 7 8 |
... 数据 = ... # 定义转换 svd = TruncatedSVD() # 准备对数据集进行转换 svd.fit(data) # 对数据集应用转换 transformed = svd.transform(data) |
SVD的输出可用作训练模型的输入。
也许最好的方法是使用Pipeline,第一步是SVD转换,下一步是获取转换后的数据作为输入的学习算法。
|
1 2 3 4 |
... # 定义管道 steps = [('svd', TruncatedSVD()), ('m', LogisticRegression())] model = Pipeline(steps=steps) |
现在我们已经熟悉了SVD API,让我们来看一个实例。
SVD降维实例
SVD通常用于稀疏数据。
这包括推荐系统的数据或文本的词袋模型。如果数据是稠密的,那么最好使用PCA方法。
不过,为了简单起见,本节将演示SVD在稠密数据上的应用。您可以轻松地将其改编为您自己的稀疏数据集。
首先,我们可以使用make_classification()函数创建一个合成的二分类问题,其中包含1,000个示例和20个输入特征,其中15个输入是相关的。
完整的示例如下所示。
|
1 2 3 4 5 6 |
# 测试分类数据集 from sklearn.datasets import make_classification # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 汇总数据集 print(X.shape, y.shape) |
运行示例会创建数据集并总结输入和输出组件的形状。
|
1 |
(1000, 20) (1000,) |
接下来,我们可以在此数据集上使用降维,同时拟合逻辑回归模型。
我们将使用一个Pipeline,其中第一个步骤执行SVD转换并选择最重要的10个维度或分量,然后在此特征上拟合逻辑回归模型。在此数据集上我们无需规范化变量,因为所有变量的设计比例都相同。
该管道将使用重复分层交叉验证进行评估,其中包含三次重复和每次重复 10 折。性能以平均分类准确度表示。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 使用SVD和逻辑回归算法进行分类评估 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.pipeline import Pipeline from sklearn.decomposition import TruncatedSVD 从 sklearn.线性模型 导入 LogisticRegression # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 定义管道 steps = [('svd', TruncatedSVD(n_components=10)), ('m', LogisticRegression())] model = Pipeline(steps=steps) # 评估模型 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise') # 报告表现 print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例会评估模型并报告分类准确率。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到SVD转换与逻辑回归的性能约为81.4%。
|
1 |
准确率:0.814 (0.034) |
我们如何知道将20个输入维度减少到10个是好的,或者我们能做到的最好的呢?
我们不知道;10是一个任意的选择。
一个更好的方法是使用不同数量的输入特征来评估相同的转换和模型,并选择能带来最佳平均性能的特征数量(降维程度)。
下面的示例执行了这个实验,并总结了每个配置的平均分类准确率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# 比较SVD分量数与逻辑回归算法分类 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.pipeline import Pipeline from sklearn.decomposition import TruncatedSVD from sklearn.linear_model import LogisticRegression from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() for i in range(1,20): steps = [('svd', TruncatedSVD(n_components=i)), ('m', LogisticRegression())] models[str(i)] = Pipeline(steps=steps) 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise') 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model, X, y) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.xticks(rotation=45) pyplot.show() |
运行该示例首先报告每个选定组件或特征数量的分类准确性。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能有所不同。请考虑运行示例几次并比较平均结果。
我们可以看到,随着维度数量的增加,性能总体呈上升趋势。在此数据集中,结果表明维度数量与模型分类准确率之间存在权衡。
有趣的是,我们没有看到超过15个分量后的任何改进。这与我们对问题的定义相符,即只有前15个分量包含有关类的信息,而其余五个是冗余的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
>1 0.542 (0.046) >2 0.626 (0.050) >3 0.719 (0.053) >4 0.722 (0.052) >5 0.721 (0.054) >6 0.729 (0.045) >7 0.802 (0.034) >8 0.800 (0.040) >9 0.814 (0.037) >10 0.814 (0.034) >11 0.817 (0.037) >12 0.820 (0.038) >13 0.820 (0.036) >14 0.825 (0.036) >15 0.865 (0.027) >16 0.865 (0.027) >17 0.865 (0.027) >18 0.865 (0.027) >19 0.865 (0.027) |
为每个配置的维度数量的准确度分数分布创建了一个箱线图。
我们可以看到分类准确率随分量数量的增加而增加的趋势,在15个分量处达到极限。
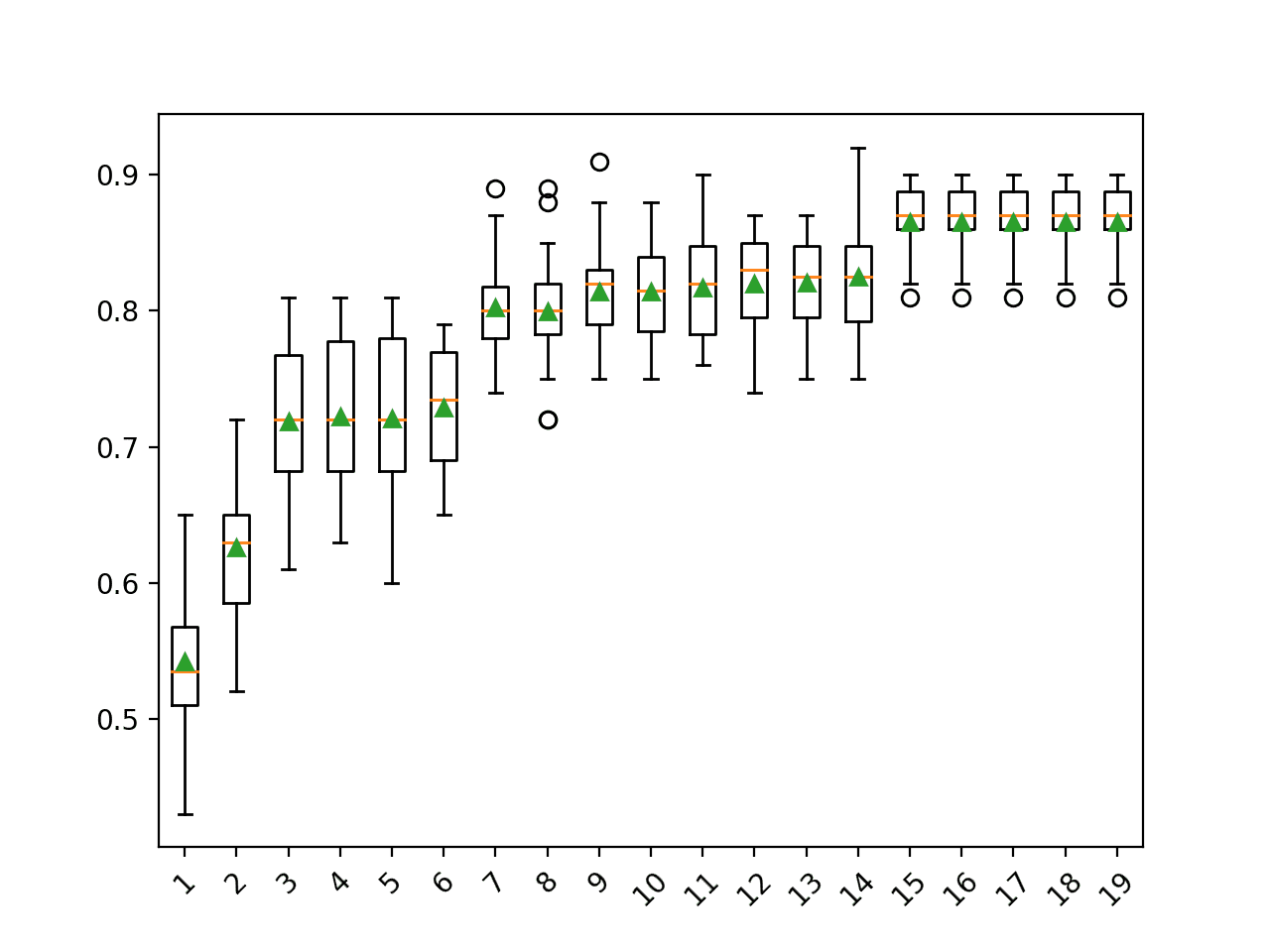
SVD分量数与分类准确率的箱线图
我们可以选择将SVD转换和逻辑回归模型组合作为我们的最终模型。
这包括在所有可用数据上拟合Pipeline,并使用该Pipeline对新数据进行预测。重要的是,必须对这些新数据执行相同的转换,这通过Pipeline自动处理。
以下代码提供了一个使用SVD转换对新数据进行拟合和使用的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 使用SVD和逻辑回归进行预测 from sklearn.datasets import make_classification from sklearn.pipeline import Pipeline from sklearn.decomposition import TruncatedSVD 从 sklearn.线性模型 导入 LogisticRegression # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 定义模型 steps = [('svd', TruncatedSVD(n_components=15)), ('m', LogisticRegression())] model = Pipeline(steps=steps) # 在整个数据集上拟合模型 model.fit(X, y) # 进行单次预测 row = [[0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]] yhat = model.predict(row) print('Predicted Class: %d' % yhat[0]) |
运行示例会在所有可用数据上拟合管道,并对新数据进行预测。
在这里,转换使用了SVD转换最重要的15个分量,正如我们从上面的测试中发现的那样。
提供了一个具有20列的新数据行,它自动转换为15个分量,并馈送到逻辑回归模型以预测类别标签。
|
1 |
预测类别:1 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
论文
- 随机寻找结构:构建近似矩阵分解的概率算法, 2009.
书籍
- 机器学习:概率视角, 2012.
- 《数据挖掘:实用机器学习工具和技术》,第 4 版,2016 年。
- 模式识别与机器学习, 2006.
API
- 将信号分解为组件(矩阵分解问题),scikit-learn.
- sklearn.decomposition.TruncatedSVD API.
- sklearn.pipeline.Pipeline API.
文章
总结
在本教程中,您了解了在开发预测模型时如何使用SVD进行降维。
具体来说,你学到了:
- 降维涉及减少建模数据中的输入变量或列的数量。
- SVD是一项源自线性代数领域的技朮,可用于自动执行降维。
- 如何评估使用SVD投影作为输入并使用新原始数据进行预测的预测模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







你好,你提到SVD通常用于稀疏数据,而PCA更适合稠密数据。你能解释一下为什么吗?
从高层次上讲——是因为每种技术的性质。
你好,抱歉,你介意进一步阐述吗?
当然,你可以在这里了解更多关于SVD如何计算的信息
https://machinelearning.org.cn/singular-value-decomposition-for-machine-learning/
你可以在这里了解更多关于PCA如何计算的信息
https://machinelearning.org.cn/calculate-principal-component-analysis-scratch-python/
你可以使用朴素贝叶斯模型来比较与LDA示例的准确率。
抱歉,我不明白。您是什么意思?
在LDA的教程中,你使用了朴素贝叶斯模型,准确率为0.3。我很好奇这里的SVD与贝叶斯模型是否能获得你得到的0.8的准确率。
啊,我明白了。
我想我们不是要获得最佳性能,而是要演示如何使用该方法,以便您可以复制粘贴并用于自己的项目。
你提到:“本质上,原始特征不再存在,而是从可用数据中构建新特征,这些新特征与原始数据不直接可比,例如没有列名。”
但是,如果我想以近似的方式返回原始特征空间,该怎么办?
假设我在降低的空间中使用数据点进行分类后,根据某种重要性指标发现第2、3和第6个分量排名最高。现在我想回到原始特征空间,找出原始特征的组合是第2个分量。
我该怎么做?
好问题,你可以在这里看到计算方法
https://machinelearning.org.cn/singular-value-decomposition-for-machine-learning/
尝试调整示例和不同的重构。
我们可以将此用于混合数据类型吗?
该示例用于数值数据。
可能有一个适用于序数/分类变量的扩展。我不知道,抱歉。
你好,
当样本数量少于特征数量时,我们可以将SVD用于降维吗?
我正在寻找一种方法来减少这类数据的维度。
是的,我相信是这样。
应用截断SVD后的值范围是多少,这些值又反映了什么?
如果您的输入是NxD矩阵,表示N个数据点,每个数据点有D个维度,那么在应用具有默认值(n_components=2)的TruncatedSVD之后,您将得到一个Nx2矩阵,其中包含相同的N个数据点,但只有2个维度。这是一个降维,允许您使用更简单的模型。
你好,你能提供任何内容来更详细地描述根据SVD拟合对新数据执行SVD的过程吗?
我在理解SVD如何在Pipeline中保存,以及如果可以,需要什么值才能对新数据执行拟合的SVD。
如果问题不完全清楚,我感到抱歉。
你好Al……下面的内容可能会有所帮助
https://www.analyticsvidhya.com/blog/2019/08/5-applications-singular-value-decomposition-svd-data-science/
嗨 James,
感谢您的回复。我查看了您分享的文章。它很好地解释了SVD及其应用的基础知识,但我找不到我正在努力理解的内容。
我将在下面说明我的困惑。我遵循了这里列出的步骤:https://machinelearning.org.cn/singular-value-decomposition-for-machine-learning/
首先,我将创建一个矩阵 A 并执行截断 SVD,其中 n_components = 2…
A = array([
[1,2,3,4,5,6,7,8,9,10],
[11,12,13,14,15,16,17,18,19,20],
[21,22,23,24,25,26,27,28,29,30]])
truncatedA = array([
[-18.52157747 6.47697214]
[-49.81310011 1.91182038]
[-81.10462276 -2.65333138]])
接下来,我将假设未来我们会收到一个与矩阵 A 的第一行完全匹配的新数据点
new_data = array([
[1,2,3,4,5,6,7,8,9,10]])
当我在此新矩阵上使用 truncatedSVD 方法时,结果如下:
new_truncated = array([
[[-1.96214169e+01 -1.11022302e-16]])
所以,我认为这就是我理解该主题不足的地方。我原本期望第一个截断结果的第一行与第二个截断结果匹配。
嗨 James,
显然,我还有很多东西需要学习,但我通过研究我的 Python 代码解决了我的问题。
以下方法有效:
对训练集执行 SVD,保存 VT.T
然后,当我收到新数据时,我只需将保存的 VT.T 与新数据数组进行点积运算。