不平衡分类是指在具有严重类别不平衡的分类数据集上开发预测模型。
处理不平衡数据集的挑战在于,大多数机器学习技术会忽略少数类别,进而导致在少数类别上的性能不佳,尽管通常最重要的是少数类别上的性能。
解决不平衡数据集的一种方法是对少数类别进行过采样。最简单的方法是复制少数类别中的样本,尽管这些样本不会给模型添加任何新信息。相反,可以从现有样本中合成新样本。这是一种针对少数类别的数据增强,称为合成少数过采样技术,或简称SMOTE。
在本教程中,您将了解用于不平衡分类数据集过采样的 SMOTE。
完成本教程后,您将了解:
- SMOTE 如何为少数类别合成新样本。
- 如何正确拟合和评估在 SMOTE 转换的训练数据集上的机器学习模型。
- 如何使用 SMOTE 的扩展,在类别决策边界生成合成样本。
通过我的新书《使用 Python 进行不平衡分类》启动您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2021 年 1 月更新:更新了 API 文档链接。

使用 Python 进行不平衡分类的 SMOTE 过采样
照片由Victor U 提供,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 合成少数过采样技术
- Imbalanced-Learn 库
- 用于平衡数据的 SMOTE
- 用于分类的 SMOTE
- 具有选择性合成样本生成的 SMOTE
- 边界 SMOTE
- 边界 SMOTE 支持向量机
- 自适应合成采样 (ADASYN)
合成少数过采样技术
不平衡分类的一个问题是,少数类别的样本太少,模型无法有效地学习决策边界。
解决此问题的一种方法是对少数类别中的样本进行过采样。这可以通过在拟合模型之前简单地复制训练数据集中的少数类别样本来实现。这可以平衡类别分布,但不会向模型提供任何额外信息。
对复制少数类别样本的改进是从少数类别中合成新样本。这是一种表格数据的数据增强,可以非常有效。
也许最广泛使用的合成新样本的方法是合成少数过采样技术,简称 SMOTE。该技术由 Nitesh Chawla 等人在其 2002 年发表的题为“SMOTE:合成少数过采样技术”的论文中描述。
SMOTE 的工作原理是选择特征空间中彼此接近的样本,在特征空间中的样本之间画一条线,然后在该线上的某个点绘制一个新样本。
具体来说,首先从少数类别中随机选择一个样本。然后找到该样本的 k 个最近邻(通常 k=5)。选择一个随机选择的邻居,并在特征空间中两个样本之间的随机选择点创建一个合成样本。
... SMOTE 首先随机选择一个少数类实例 a,并找到其 k 个最近的少数类邻居。然后通过随机选择 k 个最近邻居 b 中的一个,并将 a 和 b 连接起来在特征空间中形成一个线段来创建合成实例。合成实例是两个选定实例 a 和 b 的凸组合生成的。
— 第 47 页,《不平衡学习:基础、算法和应用》,2013 年。
此过程可用于为少数类别创建所需数量的合成样本。如论文中所述,它建议首先使用随机欠采样来减少多数类别中的样本数量,然后使用 SMOTE 对少数类别进行过采样以平衡类别分布。
SMOTE 和欠采样的组合比单纯的欠采样表现更好。
— 《SMOTE:合成少数过采样技术》,2011 年。
这种方法是有效的,因为从少数类别创建的新合成样本是合理的,也就是说,它们在特征空间中与少数类别中的现有样本相对接近。
我们的合成过采样方法旨在使分类器构建更大的决策区域,其中包含附近的少数类点。
— 《SMOTE:合成少数过采样技术》,2011 年。
该方法的一个普遍缺点是,合成样本的创建没有考虑多数类别,如果类别之间存在强烈重叠,可能会导致模糊样本。
现在我们熟悉了这项技术,让我们来看一个不平衡分类问题的实际示例。
Imbalanced-Learn 库
在这些示例中,我们将使用 imbalanced-learn Python 库提供的实现,该库可以通过 pip 安装,如下所示:
|
1 |
sudo pip install imbalanced-learn |
您可以通过打印已安装库的版本来确认安装成功。
|
1 2 3 |
# 检查版本号 import imblearn print(imblearn.__version__) |
运行示例将打印已安装库的版本号;例如
|
1 |
0.5.0 |
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
用于平衡数据的 SMOTE
在本节中,我们将通过将其应用于不平衡的二元分类问题来培养对 SMOTE 的直觉。
首先,我们可以使用 make_classification() scikit-learn 函数创建一个包含 10,000 个样本和 1:100 类分布的合成二元分类数据集。
|
1 2 3 4 |
... # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) |
我们可以使用 Counter 对象来总结每个类别中的样本数量,以确认数据集已正确创建。
|
1 2 3 4 |
... # 总结类别分布 counter = Counter(y) print(counter) |
最后,我们可以创建一个数据集的散点图,并为每个类别的样本着色不同的颜色,以清楚地看到类不平衡的空间性质。
|
1 2 3 4 5 6 7 |
... # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
综上所述,生成和绘制合成二元分类问题的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 生成并绘制一个合成的不平衡分类数据集 from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先总结了类别分布,确认了 1:100 的比例,在本例中,多数类别大约有 9,900 个样本,少数类别有 100 个样本。
|
1 |
Counter({0: 9900, 1: 100}) |
创建了一个数据集的散点图,显示了属于多数类别(蓝色)的大量点和少数类别(橙色)的少量分散点。我们可以看到这两个类别之间存在一定程度的重叠。
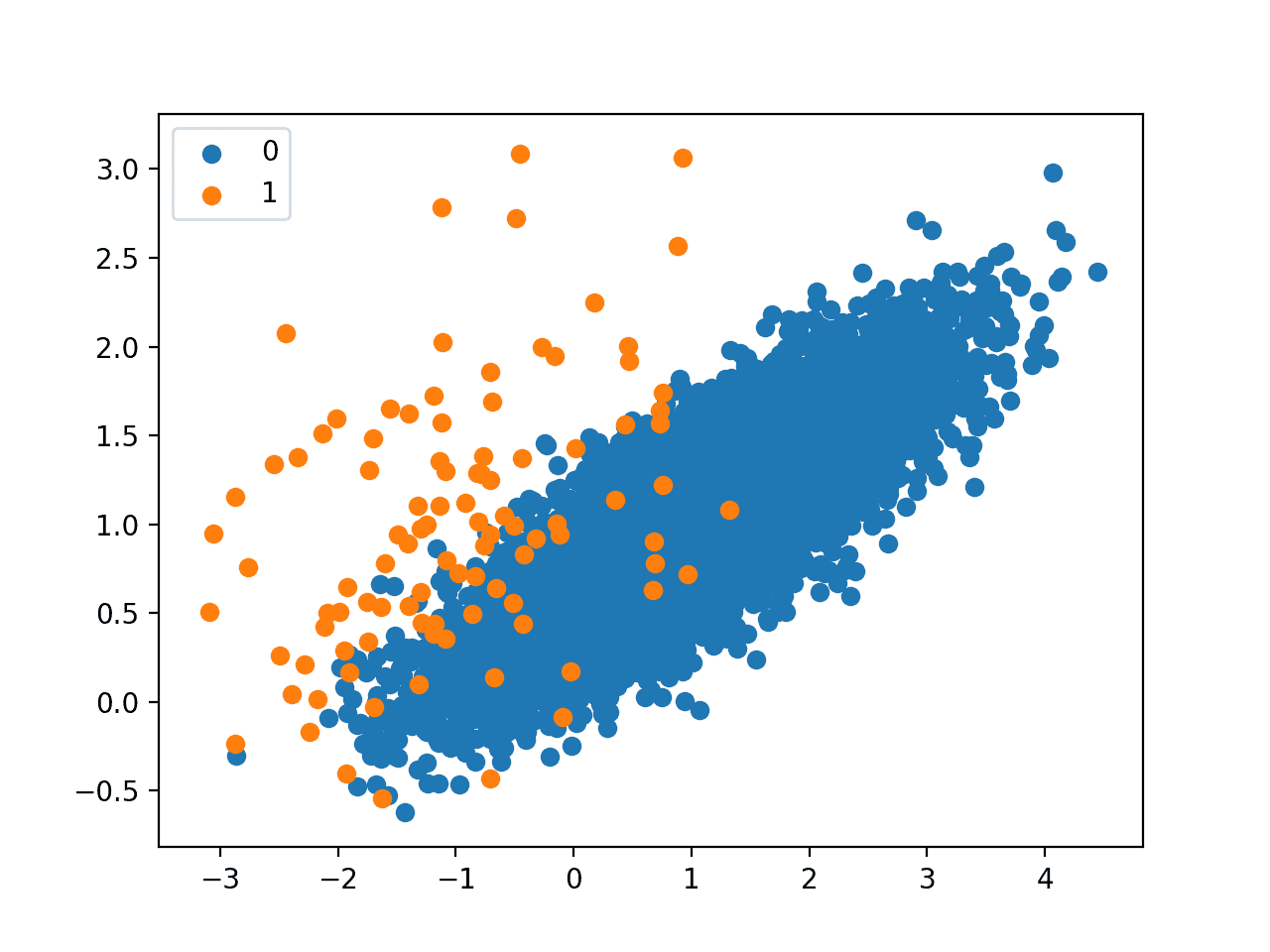
不平衡二元分类问题的散点图
接下来,我们可以使用 SMOTE 对少数类别进行过采样,并绘制转换后的数据集。
我们可以使用 imbalanced-learn Python 库中 SMOTE 类提供的 SMOTE 实现。
SMOTE 类类似于 scikit-learn 中的数据转换对象,因为它必须被定义和配置,在数据集上进行拟合,然后应用于创建数据集的新转换版本。
例如,我们可以定义一个具有默认参数的 SMOTE 实例,该实例将平衡少数类别,然后一步拟合并应用它来创建数据集的转换版本。
|
1 2 3 4 |
... # 转换数据集 oversample = SMOTE() X, y = oversample.fit_resample(X, y) |
一旦转换,我们可以总结新转换数据集的类别分布,通过在少数类别中创建许多新的合成样本,预期现在会变得平衡。
|
1 2 3 4 |
... # 总结新的类别分布 counter = Counter(y) print(counter) |
还可以创建转换后数据集的散点图,我们期望在少数类别中原始样本之间的线上看到更多的少数类别样本。
综上所述,将 SMOTE 应用于合成数据集,然后总结并绘制转换结果的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 使用 SMOTE 对不平衡数据集进行过采样和绘图 from collections import Counter from sklearn.datasets import make_classification from imblearn.over_sampling import SMOTE from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 转换数据集 oversample = SMOTE() X, y = oversample.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先创建数据集并总结类别分布,显示 1:100 的比例。
然后使用 SMOTE 对数据集进行转换,并总结新的类别分布,显示现在是平衡分布,少数类别中有 9,900 个样本。
|
1 2 |
Counter({0: 9900, 1: 100}) Counter({0: 9900, 1: 9900}) |
最后,创建了转换后数据集的散点图。
它显示在少数类别中的原始样本之间的线上创建了更多的少数类别样本。
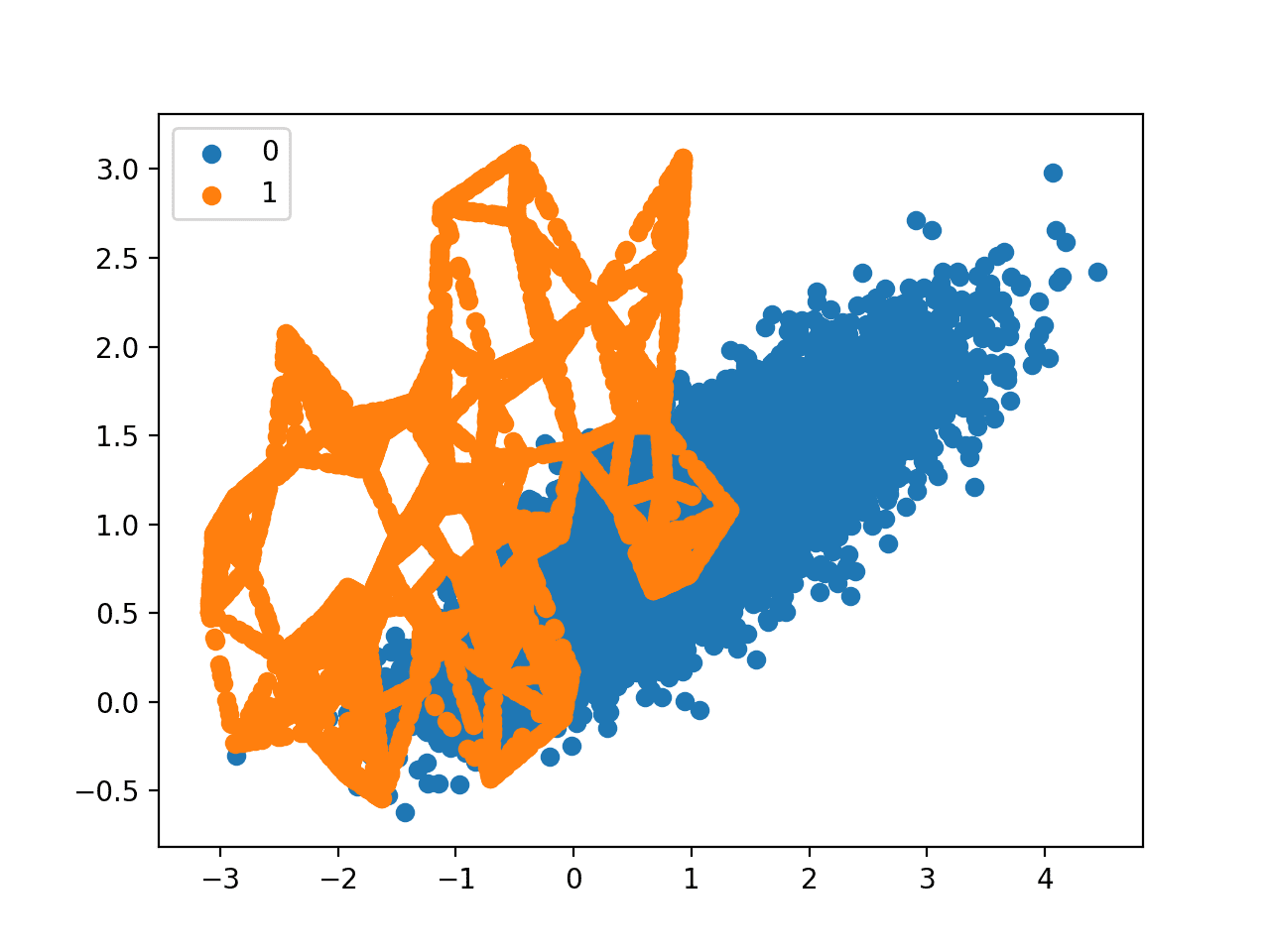
经 SMOTE 转换的不平衡二元分类问题的散点图
SMOTE 的原始论文建议将 SMOTE 与多数类别的随机欠采样相结合。
imbalanced-learn 库通过 RandomUnderSampler 类支持随机欠采样。
我们可以更新示例,首先对少数类别进行过采样,使其样本数量达到多数类别的 10%(例如约 1,000 个),然后使用随机欠采样将多数类别中的样本数量减少到少数类别的 50% 以上(例如约 2,000 个)。
为了实现这一点,我们可以将所需的比率指定为 SMOTE 和 RandomUnderSampler 类的参数;例如
|
1 2 3 |
... over = SMOTE(sampling_strategy=0.1) under = RandomUnderSampler(sampling_strategy=0.5) |
然后我们可以将这两个转换串联成一个 Pipeline。
然后可以将 Pipeline 应用于数据集,依次执行每个转换,并返回一个最终数据集,其中包含了应用于它的转换的累积,在本例中是过采样后跟欠采样。
|
1 2 3 |
... steps = [('o', over), ('u', under)] pipeline = Pipeline(steps=steps) |
然后,管道可以像单个转换一样拟合和应用于我们的数据集
|
1 2 3 |
... # 转换数据集 X, y = pipeline.fit_resample(X, y) |
然后我们可以总结并绘制生成的数据集。
我们预计少数类别会进行一些 SMOTE 过采样,尽管不如之前数据集平衡时那么多。我们还预计通过随机欠采样,多数类别中的样本会更少。
将所有这些结合起来,完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 使用 SMOTE 进行过采样和对不平衡数据集进行随机欠采样 from collections import Counter from sklearn.datasets import make_classification from imblearn.over_sampling import SMOTE from imblearn.under_sampling import RandomUnderSampler from imblearn.pipeline import Pipeline from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 定义流水线 over = SMOTE(sampling_strategy=0.1) under = RandomUnderSampler(sampling_strategy=0.5) steps = [('o', over), ('u', under)] pipeline = Pipeline(steps=steps) # 转换数据集 X, y = pipeline.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先创建数据集并总结类别分布。
接下来,数据集被转换,首先是对少数类别进行过采样,然后是对多数类别进行欠采样。这一系列转换之后的最终类别分布符合我们的预期,比例为 1:2,即多数类别约有 2,000 个样本,少数类别约有 1,000 个样本。
|
1 2 |
Counter({0: 9900, 1: 100}) Counter({0: 1980, 1: 990}) |
最后,创建了转换后数据集的散点图,显示了过采样的少数类别和欠采样的多数类别。
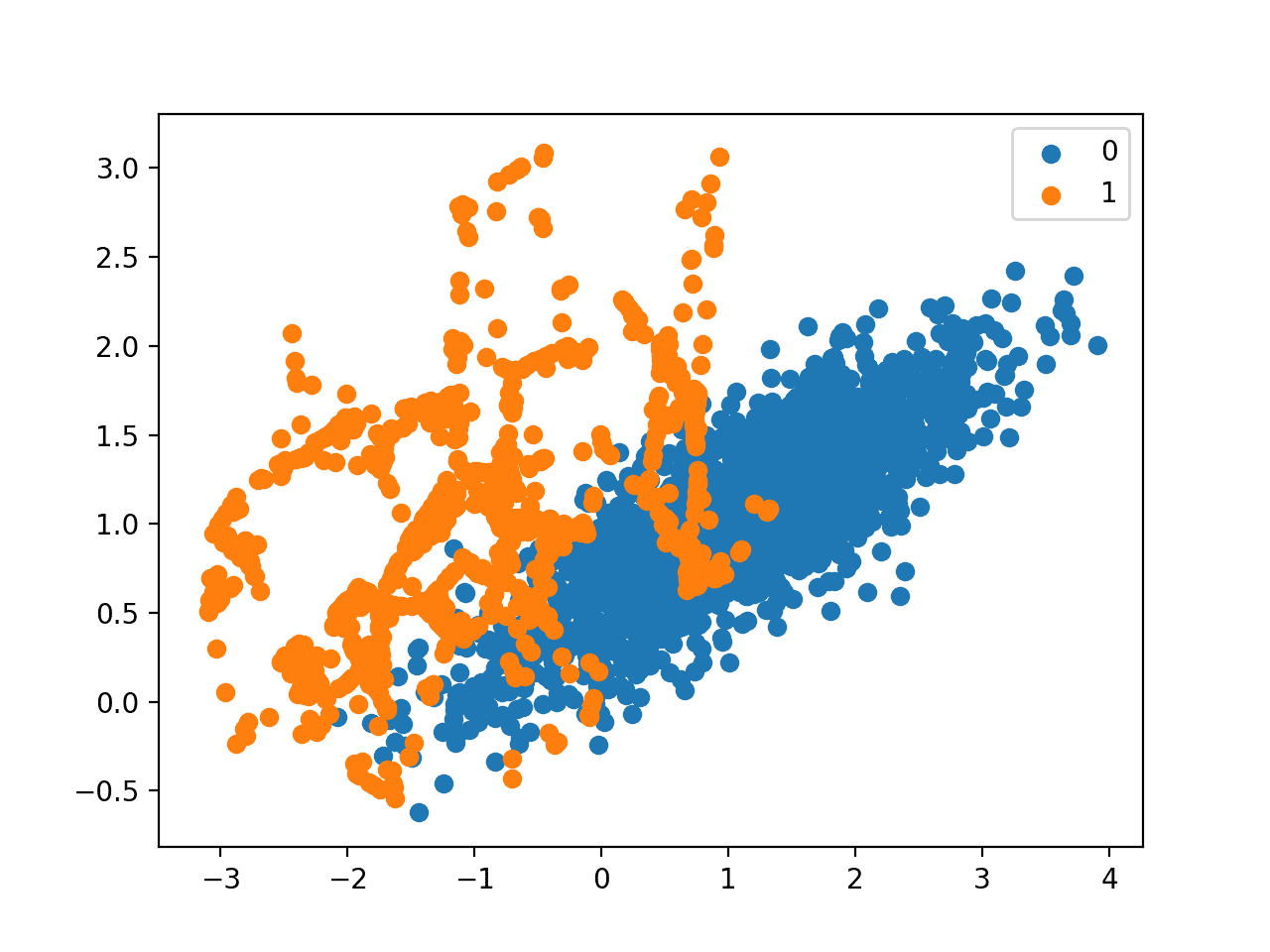
通过 SMOTE 和随机欠采样转换的不平衡数据集的散点图
现在我们熟悉了如何转换不平衡数据集,让我们看看在使用 SMOTE 拟合和评估分类模型时。
用于分类的 SMOTE
在本节中,我们将探讨如何在 scikit-learn 中拟合和评估机器学习算法时,将 SMOTE 作为数据准备方法。
首先,我们使用上一节中的二元分类数据集,然后拟合和评估决策树算法。
算法定义了所有必需的超参数(我们将使用默认值),然后我们将使用重复分层 k 折交叉验证来评估模型。我们将使用 3 次重复的 10 折交叉验证,这意味着 10 折交叉验证应用 3 次,在数据集上拟合和评估 30 个模型。
数据集是分层的,这意味着交叉验证分割的每个折叠将具有与原始数据集相同的类别分布,在本例中为 1:100 的比例。我们将使用 ROC 曲线下面积 (AUC) 指标来评估模型。这对于严重不平衡的数据集可能过于乐观,但仍会显示性能更好的模型的相对变化。
|
1 2 3 4 5 6 |
... # 定义模型 model = DecisionTreeClassifier() # 评估流水线 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) |
一旦拟合,我们可以计算并报告跨折叠和重复的得分平均值。
|
1 2 |
... print('Mean ROC AUC: %.3f' % mean(scores)) |
我们不期望在原始不平衡数据集上拟合的决策树表现非常好。
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 在不平衡数据集上评估的决策树 from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.tree import DecisionTreeClassifier # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 定义模型 model = DecisionTreeClassifier() # 评估流水线 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) print('Mean ROC AUC: %.3f' % mean(scores)) |
运行示例会评估模型并报告平均 ROC AUC。
注意:考虑到算法或评估过程的随机性,或者数值精度差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到报告的 ROC AUC 约为 0.76。
|
1 |
平均 ROC AUC:0.761 |
现在,我们可以尝试相同的模型和相同的评估方法,但使用 SMOTE 转换过的数据集。
在 k 折交叉验证期间,过采样的正确应用是将该方法仅应用于训练数据集,然后评估在分层但未转换的测试集上的模型。
这可以通过定义一个 Pipeline 来实现,该 Pipeline 首先使用 SMOTE 转换训练数据集,然后拟合模型。
|
1 2 3 4 |
... # 定义流水线 steps = [('over', SMOTE()), ('model', DecisionTreeClassifier())] pipeline = Pipeline(steps=steps) |
然后可以使用重复的 k 折交叉验证来评估此管道。
综上所述,在训练数据集上使用 SMOTE 过采样评估决策树的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 在具有 SMOTE 过采样的不平衡数据集上评估的决策树 from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.tree import DecisionTreeClassifier from imblearn.pipeline import Pipeline from imblearn.over_sampling import SMOTE # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 定义流水线 steps = [('over', SMOTE()), ('model', DecisionTreeClassifier())] pipeline = Pipeline(steps=steps) # 评估流水线 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(pipeline, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) print('Mean ROC AUC: %.3f' % mean(scores)) |
运行示例会评估模型并报告跨多个折叠和重复的平均 ROC AUC 分数。
注意:考虑到算法或评估过程的随机性,或者数值精度差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到性能适度提高,ROC AUC 从约 0.76 提高到约 0.80。
|
1 |
平均 ROC AUC:0.809 |
如论文所述,据信 SMOTE 与多数类别的欠采样(例如随机欠采样)结合使用时表现更好。
我们可以通过简单地向 Pipeline 添加一个 RandomUnderSampler 步骤来实现此目的。
与上一节中一样,我们将首先使用 SMOTE 对少数类别进行过采样,使其达到约 1:10 的比例,然后对多数类别进行欠采样,使其达到约 1:2 的比例。
|
1 2 3 4 5 6 7 |
... # 定义流水线 model = DecisionTreeClassifier() over = SMOTE(sampling_strategy=0.1) under = RandomUnderSampler(sampling_strategy=0.5) steps = [('over', over), ('under', under), ('model', model)] pipeline = Pipeline(steps=steps) |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 决策树在不平衡数据集上使用 SMOTE 过采样和随机欠采样 from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.tree import DecisionTreeClassifier from imblearn.pipeline import Pipeline from imblearn.over_sampling import SMOTE from imblearn.under_sampling import RandomUnderSampler # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 定义流水线 model = DecisionTreeClassifier() over = SMOTE(sampling_strategy=0.1) under = RandomUnderSampler(sampling_strategy=0.5) steps = [('over', over), ('under', under), ('model', model)] pipeline = Pipeline(steps=steps) # 评估流水线 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(pipeline, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) print('Mean ROC AUC: %.3f' % mean(scores)) |
运行示例会使用 SMOTE 过采样和训练数据集上的随机欠采样的管道来评估模型。
注意:考虑到算法或评估过程的随机性,或者数值精度差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到报告的 ROC AUC 再次提升到约 0.83。
|
1 |
平均 ROC AUC:0.834 |
您可以探索测试少数类别和多数类别的不同比例(例如更改 sampling_strategy 参数),看看是否有可能进一步提升性能。
另一个可以探索的领域是测试 SMOTE 过程中选择的 k 最近邻的不同值,当创建每个新的合成样本时。默认值为 k=5,但更大或更小的值会影响创建的样本类型,进而可能会影响模型的性能。
例如,我们可以网格搜索一系列 k 值,例如 1 到 7,并评估每个值的管道。
|
1 2 3 4 5 6 |
... # 要评估的值 k_values = [1, 2, 3, 4, 5, 6, 7] for k in k_values: # 定义管道 ... |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 对不平衡分类的 SMOTE 过采样进行 k 值网格搜索 from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.tree import DecisionTreeClassifier from imblearn.pipeline import Pipeline from imblearn.over_sampling import SMOTE from imblearn.under_sampling import RandomUnderSampler # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 要评估的值 k_values = [1, 2, 3, 4, 5, 6, 7] for k in k_values: # 定义管道 model = DecisionTreeClassifier() over = SMOTE(sampling_strategy=0.1, k_neighbors=k) under = RandomUnderSampler(sampling_strategy=0.5) steps = [('over', over), ('under', under), ('model', model)] pipeline = Pipeline(steps=steps) # 评估管道 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(pipeline, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) score = mean(scores) print('> k=%d, Mean ROC AUC: %.3f' % (k, score)) |
运行示例将使用 KNN 中不同的 k 值进行 SMOTE 过采样,然后进行随机欠采样,并在生成的训练数据集上拟合决策树。
报告了每种配置的平均 ROC AUC。
注意:考虑到算法或评估过程的随机性,或者数值精度差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,结果表明 k=3 可能不错,ROC AUC 约为 0.84,而 k=7 也可能不错,ROC AUC 约为 0.85。
这突出表明,执行过采样和欠采样的数量(sampling_strategy 参数)以及从其中选择伙伴以创建合成样本的样本数量(k_neighbors)可能是您数据集中要选择和调整的重要参数。
|
1 2 3 4 5 6 7 |
> k=1,平均 ROC AUC:0.827 > k=2,平均 ROC AUC:0.823 > k=3,平均 ROC AUC:0.834 > k=4,平均 ROC AUC:0.840 > k=5,平均 ROC AUC:0.839 > k=6,平均 ROC AUC:0.839 > k=7,平均 ROC AUC:0.853 |
现在我们熟悉了如何在拟合和评估分类模型时使用 SMOTE,接下来让我们看看 SMOTE 过程的一些扩展。
具有选择性合成样本生成的 SMOTE
我们可以选择性地对少数类别中使用 SMOTE 进行过采样的样本进行操作。
在本节中,我们将回顾 SMOTE 的一些扩展,这些扩展在选择少数类别中作为生成新合成样本基础的样本方面更具选择性。
边界 SMOTE
SMOTE 的一个流行扩展是选择那些被错误分类的少数类实例,例如使用 k 近邻分类模型。
然后我们可以只对那些难以分类的实例进行过采样,只在需要的地方提供更多的分辨率。
边界上的样本以及附近的样本 [...] 比远离边界的样本更容易被错误分类,因此对分类更重要。
— 《Borderline-SMOTE:不平衡数据集学习中的一种新过采样方法》,2005 年。
这些被错误分类的样本很可能含糊不清,并且位于决策边界边缘或边界区域,其中类别成员资格可能重叠。因此,这种修改后的 SMOTE 被称为 Borderline-SMOTE,由 Hui Han 等人在其 2005 年发表的论文“Borderline-SMOTE:不平衡数据集学习中的一种新过采样方法”中提出。
作者还描述了一种方法版本,该方法也对多数类别进行过采样,以针对那些导致少数类别中边界实例错误分类的样本。这被称为 Borderline-SMOTE1,而仅对少数类别中边界情况进行过采样被称为 Borderline-SMOTE2。
Borderline-SMOTE2 不仅从 DANGER 中的每个示例及其在 P 中的正最近邻居生成合成示例,而且还从其在 N 中的最近负邻居生成合成示例。
— 《Borderline-SMOTE:不平衡数据集学习中的一种新过采样方法》,2005 年。
我们可以使用 imbalanced-learn 中的 BorderlineSMOTE 类实现 Borderline-SMOTE1。
我们可以在前几节中使用的合成二元分类问题上演示该技术。
我们期望 Borderline-SMOTE 方法只沿着两个类别之间的决策边界创建合成样本,而不是盲目地为少数类别生成新的合成样本。
使用 Borderline-SMOTE 对二元分类数据集进行过采样的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 不平衡数据集的边界-SMOTE from collections import Counter from sklearn.datasets import make_classification from imblearn.over_sampling import BorderlineSMOTE from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 转换数据集 oversample = BorderlineSMOTE() X, y = oversample.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先创建数据集并总结初始类别分布,显示 1:100 的关系。
应用 Borderline-SMOTE 以平衡类别分布,并通过打印的类别摘要进行确认。
|
1 2 |
Counter({0: 9900, 1: 100}) Counter({0: 9900, 1: 9900}) |
最后,创建了转换后数据集的散点图。该图清晰地显示了选择性过采样方法的效果。少数类别的决策边界上的样本被有意地过采样(橙色)。
该图显示,那些远离决策边界的样本未被过采样。这包括易于分类的样本(图中左上方那些橙色点)和由于强类别重叠而极难分类的样本(图中右下方那些橙色点)。
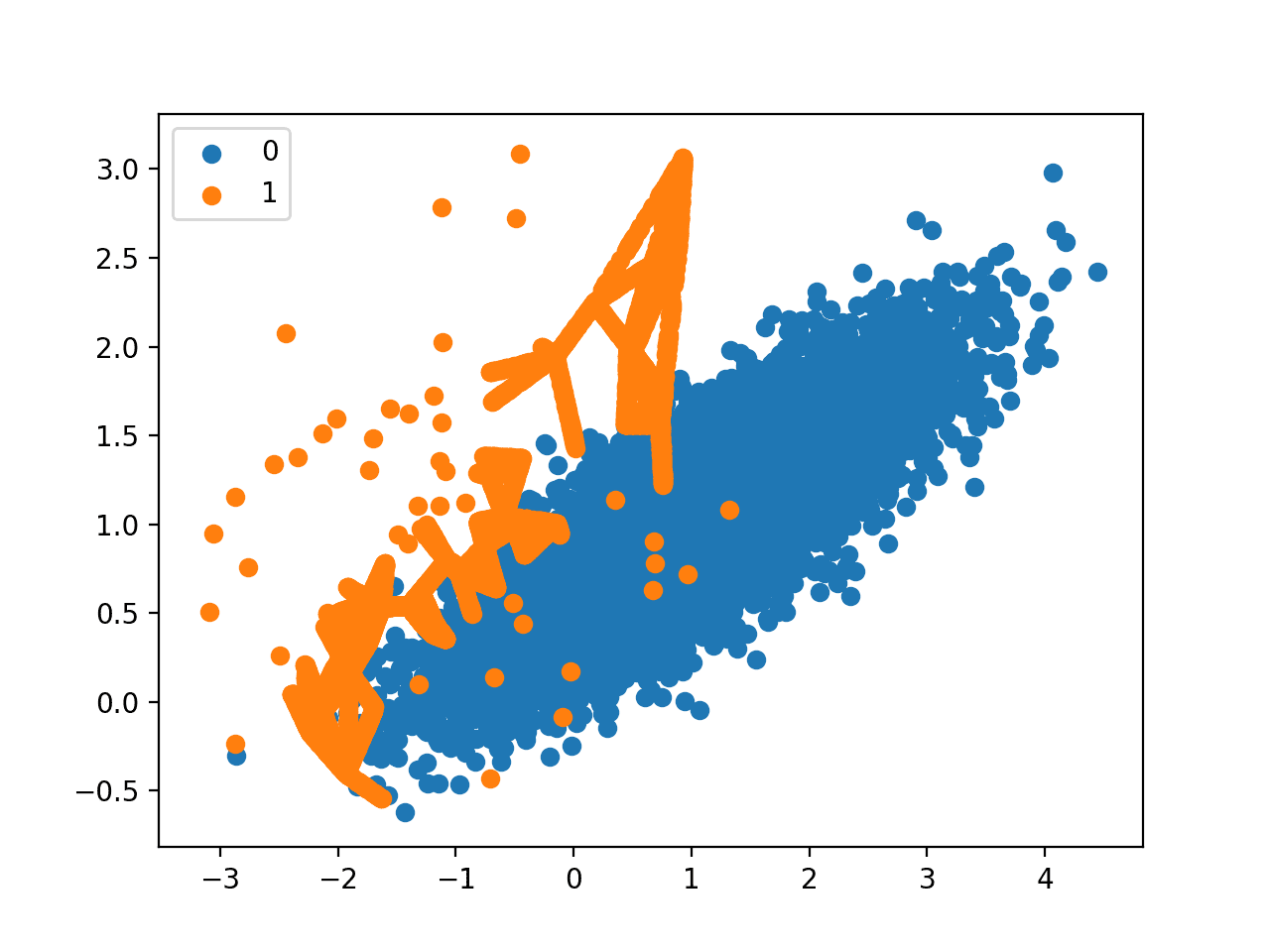
带有边界 SMOTE 过采样的不平衡数据集散点图
边界 SMOTE 支持向量机
Hien Nguyen 等人建议使用 Borderline-SMOTE 的替代方案,其中使用 SVM 算法而不是 KNN 来识别决策边界上的错误分类样本。
他们的研究总结在 2009 年的论文“不平衡数据分类的边界过采样”中。SVM 用于定位由支持向量定义的决策边界,少数类别中靠近支持向量的样本成为生成合成样本的焦点。
……通过在原始训练集上训练标准支持向量机分类器后获得的支持向量来近似边界区域。新的实例将通过插值沿连接每个少数类支持向量与其最近邻居的线随机创建。
— 《不平衡数据分类的边界过采样》,2009 年。
除了使用 SVM,该技术还尝试选择少数类样本较少的区域,并试图向类边界外推。
如果多数类实例占其最近邻居的一半以下,则将通过外推法创建新实例,以将少数类区域扩展到多数类。
— 《不平衡数据分类的边界过采样》,2009 年。
这种变体可以通过 imbalanced-learn 库中的 SVMSMOTE 类实现。
以下示例演示了在相同的不平衡数据集上使用 Borderline SMOTE 的这种替代方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 使用 SVM 的不平衡数据集的边界-SMOTE from collections import Counter from sklearn.datasets import make_classification from imblearn.over_sampling import SVMSMOTE from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 转换数据集 oversample = SVMSMOTE() X, y = oversample.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先总结原始类别分布,然后是应用带 SVM 模型的 Borderline-SMOTE 后的平衡类别分布。
|
1 2 |
Counter({0: 9900, 1: 100}) Counter({0: 9900, 1: 9900}) |
创建了一个数据集的散点图,显示了沿决策边界与多数类别的定向过采样。
我们还可以看到,与 Borderline-SMOTE 不同,更多的样本是远离类别重叠区域合成的,例如朝向图的左上方。
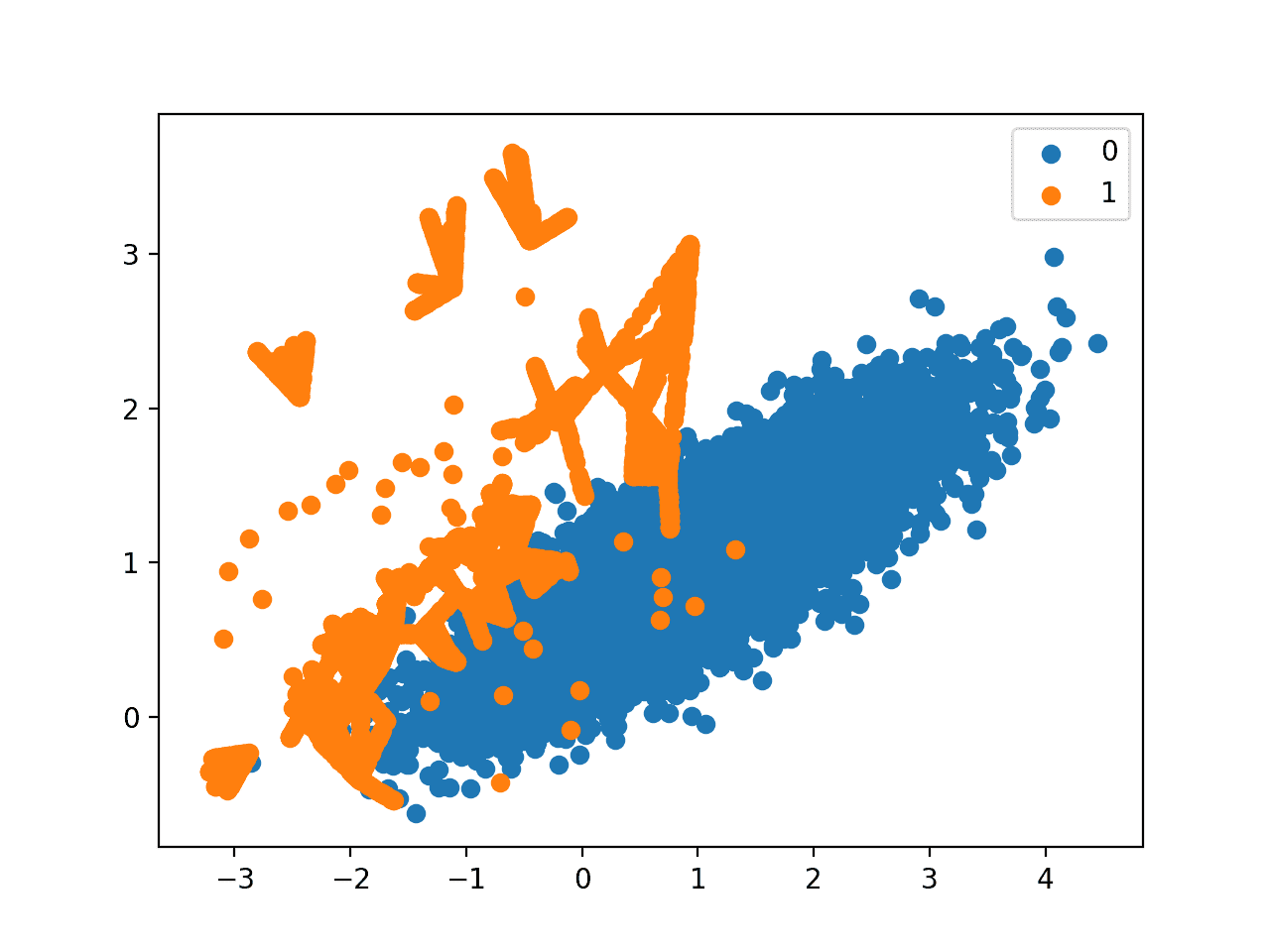
带有 SVM 的边界 SMOTE 过采样的不平衡数据集散点图
自适应合成采样 (ADASYN)
另一种方法是生成与少数类别中样本密度成反比的合成样本。
也就是说,在少数样本密度低的特征空间区域生成更多的合成样本,而在密度高的区域生成较少或不生成合成样本。
这种对 SMOTE 的修改被称为自适应合成采样方法,或 ADASYN,由 Haibo He 等人在其 2008 年发表的题为“ADASYN:不平衡学习的自适应合成采样方法”的论文中提出。
ADASYN 的基础思想是根据少数类数据的分布自适应地生成样本:相对于那些易于学习的少数类样本,为那些更难学习的少数类样本生成更多的合成数据。
— 《ADASYN:不平衡学习的自适应合成采样方法》,2008 年。
使用在线 Borderline-SMOTE,不会创建判别模型。相反,少数类别中的样本根据其密度加权,然后密度最低的样本成为 SMOTE 合成样本生成过程的焦点。
ADASYN 算法的核心思想是使用密度分布作为标准,自动决定为每个少数数据样本生成多少合成样本。
— 《ADASYN:不平衡学习的自适应合成采样方法》,2008 年。
我们可以使用 imbalanced-learn 库中的 ADASYN 类实现此过程。
以下示例演示了在不平衡二元分类数据集上进行过采样的这种替代方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 使用 ADASYN 对不平衡数据集进行过采样和绘图 from collections import Counter from sklearn.datasets import make_classification from imblearn.over_sampling import ADASYN from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 转换数据集 oversample = ADASYN() X, y = oversample.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先创建数据集并总结初始类别分布,然后总结执行过采样后的更新类别分布。
|
1 2 |
Counter({0: 9900, 1: 100}) Counter({0: 9900, 1: 9899}) |
创建了转换后数据集的散点图。与 Borderline-SMOTE 类似,我们可以看到合成样本生成集中在决策边界周围,因为该区域具有最低密度。
与 Borderline-SMOTE 不同,我们可以看到类别重叠最多的样本得到了最多的关注。在这些低密度样本可能是异常值的问题上,ADASYN 方法可能会过分关注这些特征空间区域,这可能导致模型性能更差。
在应用过采样过程之前删除异常值可能会有所帮助,这可能是一个更普遍有用的启发式方法。
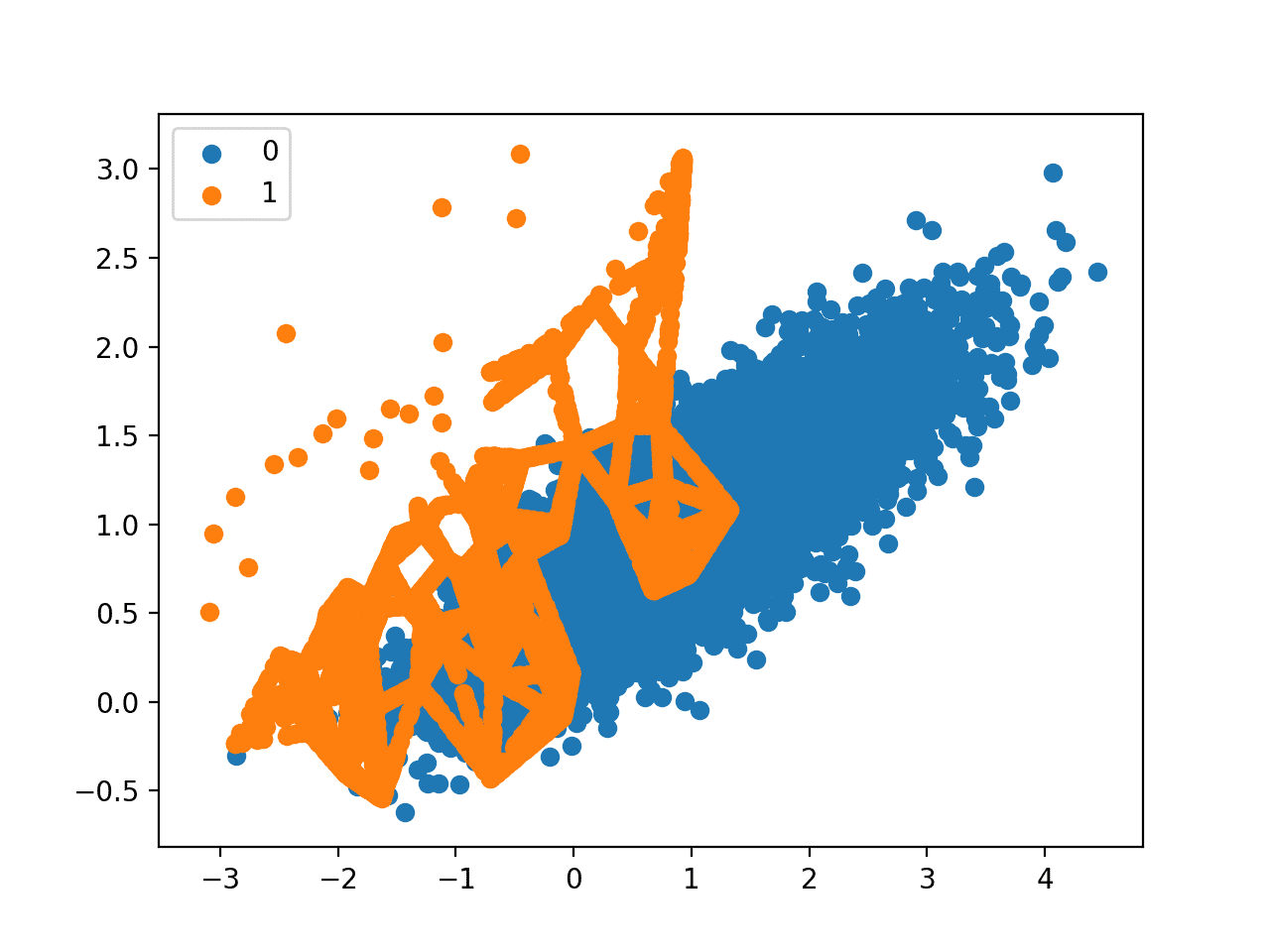
带有自适应合成采样 (ADASYN) 的不平衡数据集散点图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 从不平衡数据集中学习 (Learning from Imbalanced Data Sets), 2018.
- 不平衡学习:基础、算法与应用 (Imbalanced Learning: Foundations, Algorithms, and Applications), 2013.
论文
- SMOTE:合成少数过采样技术, 2002.
- Borderline-SMOTE:不平衡数据集学习中的一种新过采样方法, 2005.
- 不平衡数据分类的边界过采样, 2009.
- ADASYN:不平衡学习的自适应合成采样方法, 2008.
API
- imblearn.over_sampling.SMOTE API.
- imblearn.over_sampling.SMOTENC API.
- imblearn.over_sampling.BorderlineSMOTE API.
- imblearn.over_sampling.SVMSMOTE API.
- imblearn.over_sampling.ADASYN API.
文章
总结
在本教程中,您学习了用于不平衡分类数据集过采样的 SMOTE。
具体来说,你学到了:
- SMOTE 如何为少数类别合成新样本。
- 如何正确拟合和评估在 SMOTE 转换的训练数据集上的机器学习模型。
- 如何使用 SMOTE 的扩展,在类别决策边界生成合成样本。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...
")





嗨
print(‘平均 ROC AUC:%.3f’ % scores 的平均值)
在计算 ROC AUC 时,示例使用的是 mean 函数而不是 roc_auc_score,为什么?
谢谢
ROC AUC 分数是通过 scikit-learn 中的交叉验证过程自动计算的。
嗨,Jason,
有没有办法将 smote 用于多标签问题。
是的,您必须向 smote 配置指定哪些是正/负类以及要对它们进行多少过采样。
您好!我的数据集中有 4 个类别(无 (2552)、感染 (2555)、缺血 (227)、两者皆有 (621))。我如何将此技术应用于我的数据集?
你好艾米丽……希望以下内容能提供更多清晰信息
https://machinelearning.org.cn/multi-class-imbalanced-classification/
嗨,Jason,
感谢分享机器学习知识。
在通过 SMOTE 过采样获得分类器的最佳结果后,如何获得保留数据测试的预测?
此致!
Mamadou。
像往常一样调用 model.predict()。
请记住,SMOTE 仅在模型拟合时应用于训练集。
嗨,Jason,
如您所说,SMOTE 仅应用于训练,这不会影响测试集的准确性吗?
是的,模型将更好地了解边界并在测试集上表现更好——至少在某些数据集上是这样。
只是一个澄清问题:根据 Akil 上面提到的,以及下面的代码,我试图理解如果模型在管道中定义,SMOTE 是否没有应用于验证数据(在 CV 期间),以及如果我使用 oversampke.fit_resample(X, y),它是否甚至应用于验证数据。我想确保它按预期工作。
我发现当我在使用和不使用管道的情况下运行 SMOTE 时,准确性差异很大。
# 定义流水线
步骤 = [(‘over’, SMOTE()), (‘model’, DecisionTreeClassifier())]
管道 = Pipeline(steps=steps)
# 评估流水线
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)
print(‘平均 ROC AUC:%.3f’ % scores 的平均值)
SMOTE 仅应用于训练集,即使在管道中使用,即使通过交叉验证进行评估也是如此。
有道理!正如我们的评论者所说,即使在我的案例中,训练和验证的准确度指标也很接近,但测试集却下降了 7-8%。如何提高测试集的性能(抱歉再问一遍)?
附言
为了再次明确,在我的案例中——3 类问题
我将 X_train 定义为用于拟合和评估模型技能的数据。在幕后发生的是 5 折交叉验证,这意味着 X_train 再次以 80:20 的比例拆分五次,其中 20% 的数据集未应用 SMOTE。这是我的理解。
尝试此处列出的技术以提高模型性能
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
还有这里
https://machinelearning.org.cn/machine-learning-performance-improvement-cheat-sheet/
您在不同的地方多次说过类似“SMOTE 仅应用于训练集,即使在管道中使用,即使通过交叉验证进行评估也是如此。”
但是你的代码
步骤 = [(‘over’, SMOTE()), (‘model’, DecisionTreeClassifier())]
管道 = Pipeline(steps=steps)
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)
据我所见,以及我看到其他人评论的,X 和 y 被输入到管道中并按原样进行交叉验证。在此示例中,在应用管道之前没有分解训练和测试。并且您的 X 和 y 通过过采样数据进行交叉验证——所以每个折叠都将过采样数据用于训练和测试。因此,即使您说您应该只将其应用于训练数据,您的模型正在使用应用于所有数据的 SMOTE 进行优化,这将夸大您的度量结果。这当然是人们所指出的在他们的结果中发生的情况,并且他们的测试结果显着降低。我的理解是,您将需要切割到每个折叠中,并且只将 SMOTE 应用于折叠内的训练数据,我在这里没有看到这样做。
此外,您使用 ROC AUC 作为不平衡分类的优化指标。这不是理想的,最好使用专注于正类别的指标,例如精确召回曲线 AUC,或 average_precision。
感谢您的反馈 Keith!您的建议在实践中表现如何?
你好!
SMOTE 也适用于不平衡图像数据集吗?
此致;
不,它是为表格数据设计的。
您可能能够以相同的方式使用图像增强。
您的书籍和博客对我帮助很大!非常感谢!
谢谢,很高兴听到这个!
你好,我为我的不平衡图像数据集使用了图像增强,但某些类的结果仍然很低,这会影响我的模型性能。另外,您必须知道我将它用于所有数据,我的意思是,我没有指定图像较少的类,我将它应用于所有数据。你能帮我解决这个问题吗?非常感谢
也许模型需要调整,这些建议中的一些会有所帮助
https://machinelearning.org.cn/start-here/#better
你好 Jason,感谢你又一个精彩的教程系列。我在运行
X, y = pipeline.fit_resample(X, y)
在我自己的 X 和 y 不平衡数据上时遇到了一个错误。错误是
“ValueError: The specified ratio required to remove samples from the minority class while trying to generate new samples. Please increase the ratio.”
来自 imblearn/utils 中 _validation.py” 的第 362 行,在 _sampling_strategy_float 中。
您或其他人能解释一下这个错误吗?
谢谢。
后续,我似乎没有理解 SMOTE 和欠采样是如何运作的。
我的输入数据大小是
{0: 23558, 1: 8466}
所以少数类:多数类示例的比例略低于 1:3
现在我明白我之前 SMOTE() 和 RandomUnderSampler() 的“sampling_strategy”比例设置不正确。
继续前进!
很高兴听到,干得好!
嗨
与 gridsearchcv 结合使用时,Smote 是对整个训练集进行过采样还是忽略验证集?
您可以将其作为管道的一部分使用,以确保 SMOTE 仅应用于训练数据集,而不是 val 或测试。
嗨,Jason,
好博客!SMOTE 的变体深入探讨得很好。我想知道
为什么您首先使用 SMOTE 进行过采样,然后才在您的管道中对多数类别进行欠采样?反过来会不会更有效?
谢谢!
这是一种对我来说效果很好的方法。也许您可以在自己的数据集上尝试反向操作并比较结果。
嗨,Jason,
我几天来一直在仔细阅读您关于不平衡分类的非常有帮助的文章。感谢您为机器学习社区提供了如此宝贵的知识!
我有一个关于仅将 SMOTE 应用于训练集所产生的后果的问题。如果我们将 SMOTE 仅应用于训练集而不应用于验证集或测试集,那么这三个集合将不会分层。例如,如果训练集转换为类别 1 和类别 2 的 50:50 分布,验证集和测试集仍然保持其原始分布 10:90,假设如此。这根本不是一个问题,因为我们只关心构建最高性能的模型,该模型将仅基于训练集?如果我们仅将 SMOTE 应用于训练集,模型是否也会假设实际数据也假设类别 1 和类别 2 之间存在 50:50 的分布?
提前感谢您的帮助!
感谢您的支持!
不,您应该在重采样之前对数据进行分层分割。然后使用一种(非准确率)指标,有效评估自然数据(验证集和测试集)的能力。
这至关重要。改变测试集和验证集的性质将使测试工具无效。
确认您在 y 中同时拥有两个类别的样本。
感谢您的教程。
我想问几个问题。
1. 我可以将这种采样技术应用于图像数据吗?
2. 在使用这些技术制作平衡数据后,我可以使用深度学习算法(例如 CNN)而不是机器学习算法吗?
是的,但这被称为数据增强,并且工作方式略有不同
https://machinelearning.org.cn/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/
是的,本教程将向您展示如何操作
https://machinelearning.org.cn/cost-sensitive-neural-network-for-imbalanced-classification/
谢谢您的回答。
我曾经使用过数据增强技术。所以,我能稍微理解数据增强和像SMOTE这样的过采样之间的区别。
事实上,我希望能找到除数据增强之外的其他方法来提高模型的性能。所以,我想尝试过采样。
但是,根据您的回答,我理解为不能在图像数据上使用SMOTE等过采样方法。我的理解对吗?
再次感谢您的耐心回答。
没错,SMOTE对图像数据没有意义,至少目前来看是这样。
以下是提高模型性能的想法:
https://machinelearning.org.cn/start-here/#better
你好 Jason,
在你的机器学习备忘录中,你建议如果数据不够就创造更多数据。你能推荐一些适合这样做的方法或库吗?
Imblearn似乎是平衡数据的好方法。如果想增加整个数据集的大小以获得更多样本并可能改善模型,该怎么办?
可以使用SMOTE。
特征工程是更通用的方法
https://machinelearning.org.cn/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/
感谢这篇精彩的教程,一如既往地超级详细且有帮助。
我正在处理葡萄酒质量数据集(白葡萄酒),并决定在输出特征平衡如下的情况下使用SMOTE。
{6: 2198, 5: 1457, 7: 880, 8: 175, 4: 163, 3: 20, 9: 5}
您认为在这种多类别问题中是否可以使用SMOTE?
我设法使用了一个回归模型(KNN),我认为它很好地完成了任务,但很想听听您对如何处理上述多类别问题中类似类别不平衡的看法?
是的,SMOTE 可以用于多类别问题,但您必须指定正类别和负类别。
多类别中正负是什么意思?根据问题/领域,它可能有所不同,但假设我确定了哪些类别是正的,哪些是负的,接下来该怎么办?
您可以直接对多类别应用SMOTE,也可以向SMOTE指定类别的首选平衡。
另请参见此处的示例:
https://machinelearning.org.cn/multi-class-imbalanced-classification/
谢谢分享,Jason。
在imblearn.pipeline中,predict方法说它应用了转换和采样,然后是估计器的最终预测。
因此,在交叉验证分数中,采样会应用于每个验证集,这不是一个问题吗?
谢谢
抱歉,我不明白你的问题。你能重述或详细说明一下吗?
我认为您对边界SMOTE1和SMOTE2的描述不正确?据我所知,SMOTE1在主要正样本和一些正NN之间生成合成样本,SMOTE2也在主要正样本和一些负NN之间生成合成样本(其中合成样本更接近主要正样本)。因此,不会生成负样本。
如果我错了,请原谅,我喜欢您的内容。
该描述引自ICIC2005论文。
您提到:“与上一节一样,我们首先使用SMOTE将少数类过采样到约1:10的比例,然后对多数类进行欠采样以达到约1:2的比例。”
为什么?这种操作背后的想法是什么,以及为什么这种操作可以提高性能。
这种方法可能很有效。重要的是在您的数据集上尝试一系列方法,看看哪种方法效果最好。
杰森先生,
我们可以将以上代码用于图像吗?
不,您应该使用数据增强。
https://machinelearning.org.cn/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/
你好 Jason,感谢你的教程。
使用以下代码行时
# 定义流水线
steps = [(‘over’, SMOTE()), (‘model’, RandomForestClassifier(n_estimators=100, criterion=’gini’, max_depth=None, random_state=1))]
管道 = Pipeline(steps=steps)
# 评估流水线
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=2, random_state=1)
acc = cross_val_score(pipeline, X_new, Y, scoring=’accuracy’, cv=cv, n_jobs=-1)
我假设SMOTE是在每次交叉验证分割时执行的,因此没有数据泄漏,我的理解对吗?谢谢。
没错。这就是我们使用管道的原因。
你好 Jason,
感谢您的帖子。我有一些问题。我的数据集中包含 NaN 值,但由于记录数量较少,我不允许删除它们。如果在数据分割或交叉验证之前用均值或中位数填充值,则会出现信息泄漏。为了解决这个问题,我需要使用包含 SMOT 和模型的管道,并且需要应用交叉验证。现在,我的问题是,如果我有一个巨大的数据集,并且我想应用特征工程(PCA 或 RFE)并希望逐步探索所有步骤,该怎么办?如果我在管道中定义每个步骤,我如何探索哪个方法存在真正的问题?此外,我需要在大型数据集上进行试错方法时需要更多的计算能力。您对此有什么建议?
我的第二个问题是,我不理解您最初定义的 SMOT。
“SMOTE 首先随机选择一个少数类实例 a,并找到其 k 个最近的少数类邻居。然后通过随机选择 k 个最近邻居 b 中的一个,并将 a 和 b 连接起来在特征空间中形成一条线段来创建合成实例。合成实例是作为两个选定实例 a 和 b 的凸组合生成的。”
我无法想象您想说什么。因此,我也不理解边界 SMOT。您能重新措辞并尽可能用一个小例子解释一下吗?
先谢谢您了。
您必须在训练集上拟合插补器,并在交叉验证中将其应用于训练集和测试集,管道会有所帮助。
您也可以手动逐步进行 k 折交叉验证并手动实现管道——这可能对您来说更好,因为您可以跟踪所做的更改以及可能发生的任何问题。
SMOTE 的工作原理是在特征空间中相近的示例之间画线,并选择线上一个随机点作为新实例。
希望这能有所帮助。
你好!一个快速问题,SMOTE 应该在数据准备(例如标准化)之前还是之后应用?或者它无关紧要?
谢谢!
可能在之后。
它正在执行 knn,所以数据应该先进行缩放。
当数据集中的类别只有少数实例时,如何使用SMOTE或任何其他与SMOTE相关的技术,例如ADASYN、Borderline SMOTE?
我的数据集中有些类别只有一个实例,有些有两个实例。使用这些SMOTE技术时,我收到错误“Expected n_neighbors <= n_samples, but n_samples = 2, n_neighbors = 6”。
有什么办法可以克服这个错误吗?使用RandomOversampling代码工作正常……但它似乎没有给出良好的性能。由于这个错误,我无法使用所有基于SMOTE的过采样技术。
我认为使用一个或几个实例的类别来建模问题是不合适的。
也许收集更多数据?
也许删除代表性不足的类别?
也许重新定义问题?
你好,我调整了smote参数(k,采样策略),并以roc_auc作为训练数据的评分,但是我的模型如何在交叉验证评分的同时在测试数据上进行评估(理想情况下不应该在测试数据上应用smote)
你能帮我如何在测试数据上应用最佳模型吗(需要代码)
#使用决策树
Xtrain1=Xtrain.copy()
ytrain1=ytrain.copy()
k_val=[i for i in range(2,9)]
p_proportion=[i for i in np.arange(0.2,0.5,0.1)]
k_n=[]
proportion=[]
score_m=[]
score_var=[]
modell=[]
for k in k_val
for p in p_proportion
oversample=SMOTE(sampling_strategy=p,k_neighbors=k,random_state=1)
Xtrain1,ytrain1=oversample.fit_resample(Xtrain,ytrain)
model=DecisionTreeClassifier()
cv=RepeatedStratifiedKFold(n_splits=10,n_repeats=3,random_state=1)
scores=cross_val_score(model,X1,y1,scoring=’roc_auc’,cv=cv,n_jobs=-1)
k_n.append(k)
proportion.append(p)
score_m.append(np.mean(scores))
score_var.append(np.var(scores))
modell.append(‘DecisionTreeClassifier’)
scorer=pd.DataFrame({‘model’:modell,’k’:k_n,’proportion’:proportion,’scores’:score_m,’score_var’:score_var})
print(scorer)
models.append(model)
models_score.append(scorer[scorer[‘scores’]==max(scorer[‘scores’])].values[0])
models_var.append(scorer[scorer[‘score_var’]==min(scorer[‘score_var’])].values[0])
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
嗨,Jason,
我们可以使用哪种方法来过采样时间序列数据?
好问题,我希望将来能涵盖这个主题。
你好 Jason,
你目前有什么关于如何过采样时间序列数据的想法吗?我想在此期间做一些研究/实验。谢谢!
不,一般来说,我宁愿在做足功课后才提出建议。
非常感谢!
不客气。
您有机会写关于时间序列数据过采样这个主题的文章吗?
感谢您的建议。我们会考虑的。
你好 Jason,
我又来读您的文章了,一如既往。您有没有写过关于时间序列数据过采样/欠采样的文章?
我一直在尝试寻找处理时间序列数据过采样/欠采样的方法,但至今未能找到合适的解决方法……
嗨 Cel…您可能会对以下内容感兴趣
https://web.cs.dal.ca/~branco/PDFfiles/c3.pdf
你好 Jason Brownie,
感谢您详细描述了如何使用 SMOTE 及其替代方法处理不平衡数据集。我知道 SMOTE 仅适用于多类别数据集,但我很想知道您是否有关于将 SMOTE 用于多标签数据集的想法?或者您是否有除 SMOTE 之外的其他方法或想法来处理不平衡的多标签数据集。
很好的问题!
我对多标签数据的方法不熟悉,或许可以查阅相关文献?
我正在处理一个数据集,作为我硕士论文的一部分,它高度不平衡。所以我尝试直接使用 OnevsRestClassifier(没有任何过采样),分类器自然给出了最差的结果(预测了出现次数最多的目标值)。所以我尝试使用随机森林分类器,一次处理一个目标列,并使用随机采样器类进行过采样,过采样后给出了不错的结果。我不确定我是否能以这种方式进行。
也许这里的建议会有所帮助。
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
我还找到了这个解决方案。
https://github.com/scikit-learn-contrib/imbalanced-learn/issues/340
不错。
您好!感谢这篇精彩的教程。SMOTE 可以与用于文本表示的高维嵌入一起使用吗?如果可以,在应用 SMOTE 之前需要进行哪些预处理/降维?
不确定,也许可以尝试一下看看是否有意义。
你好 Jason,我有 3 个输入文本列,其中 2 个是类别型的,1 个是非结构化文本。您能帮我如何进行采样吗?输出列是类别型的并且不平衡。
也许可以使用标签或独热编码处理分类输入,并使用词袋模型处理文本数据。
您可以在博客上看到许多示例,尝试搜索一下。
我使用了 Pipeline 和 columntransformer 来传递多个列作为 X,但对于采样我没有找到任何示例。对于单列,我可以使用 SMOTE,但如何传递多个列作为 X?
您可能需要进行实验,也许是不同的 smote 实例,也许是手动运行管道,等等。
你好,
SMOTE 需要每个类别 6 个示例。
我有一个数据集,其中有 30 个类别 0,和 1 个类别 1。
请提供任何解决方案。
谢谢你
也许尝试从少数类别中获取更多示例?
也许尝试这里列出的替代技术
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
你好 Jason,
非常感谢这篇文章。我发现它非常有趣。
如何在有3个类别的管道中应用相同的过采样比例(1:10)和欠采样比例(1:2)?
多类别采样策略不能设置为浮点数。您会推荐什么?
谢谢你。
约翰
谢谢。
第一步是将类别分组为正和负,然后应用采样。
您能详细说明如何利用 SMOTE 中的 `sampling_strategy` 参数吗?
是的,您具体想了解什么?
嗨,Jason,
非常感谢您的这篇文章,它一如既往地非常有帮助。
我有一个疑问
现在我的数据高度不平衡(99.5%:0.05%)。我的分类问题有超过 40,000 个样本和多个特征(36 个)。我使用 SMOTE 进行过采样以获得平衡数据,但分类器对过采样数据产生高度偏向。我猜这是由于“sampling_strategy”的原因。所以我尝试了 {0.25, 0.5, 0.75,1} 作为“sampling_strategy”。它要么高度偏向于丰富的类别,要么高度偏向于稀有的类别。
您认为问题可能出在哪里?
SMOTE 并非所有不平衡数据集的最佳解决方案。
也许尝试比较替代解决方案
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
请告诉我如何先应用 SMOTE 再应用一种分类学习算法在同一数据集上以获得更好的结果
您可以将 SMOTE 应用于训练集,然后直接应用单类别分类器。
我不认为结合这两种方法会有益处。
先生,那么我应该尝试什么才能通过使用 smote 和另一个算法来获得最佳结果,从而形成一种处理不平衡数据的混合方法呢?
使用试错法来发现最适合您数据集的方法。
嗨,Jason,
首先,感谢您的资料,它非常有价值!
我有一个监督分类问题,需要预测不平衡的类别(事件 = 1/100 非事件)。
我有一种直觉,使用重采样方法(如 SMOTE 或下采样/上采样/ROSE)与朴素贝叶斯模型会影响先验概率,从而导致在测试集上应用时性能下降。
这正确吗?
谢谢。
不客气!
是的。
嗨,博士。
SMOTE 可以应用于将用于馈送 LSTM 的数据吗?(因为顺序很重要,它可能会干扰数据,对吗?)
提前感谢!
不,它只适用于表格数据。
首先,感谢您的回复。抱歉,我想我不明白。也许我错了,但SMOTE可以应用于表格数据,在转换为滑动窗口之前。即使在这种情况下也不建议应用SMOTE吗?
谢谢!
也许吧,但我怀疑时间序列感知的数据生成方法会表现得更好。
谢谢,Jason。您能指出一个时间序列感知数据生成方法的示例吗?
抱歉,目前没有。或许可以在 scholar.google.com 上搜索一下。
你好先生,我们如何处理LSTM的不平衡数据集?我有一个CSV文件,我们可以使用SMOTE技术还是数据生成?您能给我一个链接,说明如何使用过采样吗,因为我有3D数组LSTM输入,非常感谢。
嗨,Said…请参阅以下内容:
https://machinelearning.org.cn/random-oversampling-and-undersampling-for-imbalanced-classification/
Jason,
我有一个高度不平衡的二元(是/否)分类数据集。该数据集目前约有 0.008% 的“是”。
我需要使用 SMOTE 平衡数据集。
我遇到了两种处理不平衡的方法。在我对变量运行 MinMaxScaler 之后,执行以下步骤:
from imblearn.pipeline import Pipeline
oversample = SMOTE(sampling_strategy = 0.1, random_state=42)
undersample = RandomUnderSampler(sampling_strategy=0.5, random_state=42)
steps = [(‘o’, oversample), (‘u’, undersample)]
管道 = Pipeline(steps=steps)
x_scaled_s, y_s = pipeline.fit_resample(X_scaled, y)
这导致数据集大小从 240 万行减少到 732000 行,不平衡度从 0.008% 提高到 33.33%
而这种方法
sm = SMOTE(random_state=42)
X_sm , y_sm = sm.fit_sample(X_scaled, y)
这会将行数从 240 万行增加到 480 万行,不平衡度现在是 50%。
完成这些步骤后,我需要将数据拆分为训练测试数据集……
这里正确的方法是什么?
在选择这些方法之前我需要考虑哪些因素?
我应该在未采样数据上运行 X_test,y_test 吗?这意味着我先拆分数据,然后只在训练数据上进行上采样/下采样。
再次感谢。
不,采样仅应用于训练数据集,而不应用于测试集。例如:先分割,然后采样。
你好 Jason,很棒的文章。我在使用 SMOTE-NC 处理分类数据时遇到一个问题。我只有一个用于分类的特征。
from imblearn.over_sampling import SMOTE
from imblearn.over_sampling import SMOTENC
sm = SMOTENC(random_state=27,categorical_features=[0,])
X_new = np.array(X_train.values.tolist())
Y_new = np.array(y_train.values.tolist())
print(X_new.shape) # (10500,)
print(Y_new.shape) # (10500,)
X_new = np.reshape(X_new, (-1, 1)) # SMOTE 需要 2D 数组,因此改变 X_new 的形状
print(X_new.shape) # (10500, 1)
sm.fit_sample(X_new, Y_new)
但是我收到错误
ValueError: Found array with 0 feature(s) (shape=(10500, 0)) while a minimum of 1 is required.
您能建议一下如果只有一个特征,如何处理 SMOTE 吗?
有意思,我想知道是不是 smote-nc 的 bug?
也许尝试复制列,看看是否有区别?
先生,SMOTE 如何应用于 CSV 文件数据?
按正常方式加载数据
https://machinelearning.org.cn/load-machine-learning-data-python/
然后应用smote。
欠采样多数类别和过采样少数类别的标准是什么?
或者
仅过采样少数类别的标准是什么?
我不是那样处理的。我认为这具有误导性且难以处理。
相反,我建议进行实验,如果它能带来更好的性能,就使用它。
先生,请提供关于数值数据测试时增强的教程
没问题,我写了一篇,安排在下周发布。
先生,我们是先应用特征选择技术还是先进行数据增强?
我的第一想法是先进行特征选择。
我们为什么要对整个数据集“X, y = oversample.fit_resample(X, y)”实施 SMOTE?我们应该只对训练集进行过采样。我说的对吗?应该怎么做才能只对训练集进行过采样,并且我们还想使用分层方法?
没错,我们在教程后面评估模型时会这样做。
在第一个示例中,我让您熟悉 API 和该方法的效果。
您能给我推荐一下那个教程吗,我们在其中只对训练数据应用 smote 并评估模型?我还想知道 RepeatedStratifiedKfold 是否只在训练数据集上工作。
是的,上面教程的“SMOTE for Classification”部分使用了管道来确保 SMOTE 只应用于训练数据。
如果您是管道新手,请参阅此内容:
https://machinelearning.org.cn/data-preparation-without-data-leakage/
cross_val_score 只对训练集数据进行过采样,而不对训练数据进行过采样。我说的对吗?
当使用管道时,转换只应用于训练数据集,这是正确的。
非常感谢。
不客气。
嗨,Jason!
感谢您发表如此精彩的帖子!
我正在处理一个不平衡数据集 (500:1)。我想获得最佳召回性能,并且我尝试了多种分类算法、超参数以及过采样/欠采样技术。我将尝试 SMOTE !!
从上一个问题中,我了解到使用 CV 和管道时,您只对训练集进行了过采样,对吗?
我还有另一个问题。我的不平衡数据集包含大约 500 万条记录,来自 11 个月。它不是时间序列。我使用前十个月的数据进行训练,使用第十一个月的数据进行测试,以便更容易向用户解释,但我感觉这不正确,我猜我应该使用整个数据集中的随机测试分割。这正确吗?
不客气。
正确。使用管道只对训练集进行过采样。
我的最佳建议是,在您期望使用模型的相同条件下评估候选模型。如果您的数据和您期望将来使用模型的方式存在时间元素,请尝试在您的测试工具中捕获这些元素。
希望这能有所帮助。
这里有更多想法:
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
谢谢你
嗨,Jason,
我遵循了您的建议
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
我尝试使用 SMOTE 进行过采样,但我的电脑无法处理。
然后我阅读了您的帖子后,尝试使用决策树和 XGB 处理不平衡数据集
https://machinelearning.org.cn/cost-sensitive-decision-trees-for-imbalanced-classification/
https://machinelearning.org.cn/xgboost-for-imbalanced-classification/
但我仍然得到较低的召回值。
我正在进行随机欠采样,因此我得到了 1:1 的类别关系,我的电脑可以管理。然后我正在进行 XGB/决策树,改变 max_depth 并改变权重以赋予正类别更高的重要性。我的假设是,只要我使用多折和多次迭代的 CV,我就不会过拟合模型。这正确吗?
谢谢
祝贺你的进步!
也许吧。假设可能导致糟糕的结果,测试你所能想到的一切。
谢谢你
不客气。
你好 Jason,对 SMOTE 的解释非常出色,易于理解,并且附带大量示例!
我尝试下载关于不平衡分类的免费迷你课程,但我没有收到 PDF 文件。
请问您能帮我解决这个问题吗?提前感谢!
谢谢。
抱歉听到这个消息,请直接联系我,我会发邮件给您。
https://machinelearning.org.cn/contact/
谢谢,我会的!
不客气。
你好 Jason,感谢你的教程,它一如既往地有用,
我有一个疑问,我直觉上觉得 SMOTE 在高维数据集(即我们的数据集中有许多特征)上的表现不佳。这是真的吗?
嗯,那也会是我的直觉,但总是要进行测试。直觉在高维度下或者在机器学习中通常会失效。测试一切。
嗨
与 gridsearchcv 结合使用时,Smote 是对整个训练集进行过采样还是忽略验证集?
您可以将其作为管道的一部分使用,以确保 SMOTE 仅应用于训练数据集,而不是 val 或测试。
嗨,杰森,
你是说如果在imblearn自己的Pipeline类中使用它就足够了?不需要任何参数吗?
pipe = Pipeline(steps=[(‘coltrans’, coltrans),
(‘scl’,StandardScaler()),
(‘smote’, SMOTE(random_state=42))
]
)
X_smote,y_smote=pipe.fit_resample(X_train,y_train)
是的。
嗨,Jason,
感谢分享。它对我的工作真的很有帮助 🙂
假设您使用训练数据集训练了一个管道,它有 3 个步骤:MinMaxScaler、SMOTE 和 LogisticRegression。
您可以使用相同的管道预处理测试数据吗?
还是应该为测试数据使用一个没有 SMOTE 的不同管道?
pipeline.predict(X_test) 如何知道它不应该执行 SMOTE?
谢谢。
管道经过拟合后,就可以用于对新数据进行预测。
是的,调用 `pipeline.predict()` 以确保在将数据传递给模型之前正确准备数据。
更多信息请看这里:
https://machinelearning.org.cn/data-preparation-without-data-leakage/
你好 Jason,SMOTE 采样是在数据清洗、预处理或特征工程之前/之后进行的吗?我只是想知道我们应该何时进行 SMOTE 采样以及为什么?
这取决于您正在进行的数据准备工作。
可能在之后。
你好,很棒的文章!我认为在“SMOTE for Balancing Data”部分有一个错字:“属于少数类别的大量点(蓝色)”——> 应该改为多数类别,我猜。
谢谢!已修复。
https://stackoverflow.com/questions/58825053/smote-function-not-working-in-make-pipeline
抱歉,我没有能力阅读站外的 stackoverflow 问题。
https://machinelearning.org.cn/faq/single-faq/can-you-comment-on-my-stackoverflow-question
嗨,Jason,
TypeError: 所有中间步骤都应该是转换器并实现 fit 和 transform,或者是一个字符串 ‘passthrough’ ‘SMOTE(k_neighbors=5, n_jobs=None, random_state=None, sampling_strategy=’auto’)’ (type ) 没有实现。
运行 GridSearchCV 时我遇到这个错误。哪里出错了?
也许确认您的管道内容以预测模型结束。
嗨,Jason,
如果我的所有预测变量都是二元的,我还可以使用 SMOTE 吗?SMOTE 似乎只适用于数值预测变量?除了随机欠采样或过采样之外还有其他方法吗?谢谢。
好问题,我相信你可以使用 SMOTE 的扩展版来处理分类输入,叫做 SMOTE-NC
https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.over_sampling.SMOTENC.html
杰出的帖子,Jason!
我想知道,如果我们使用引导(当然是带替换的)将少数类别从 100 上采样到 9,900,我们是否会得到与 SMOTE 相似的结果……我把它列入我的待办事项清单。
谢谢!
可能不会,因为我们正在使用 SMOTE 生成全新的样本。不过,运行实验并比较结果吧!
有意思……我会的。谢谢 Jason!
不客气。
嗨,Jason
感谢您精彩的文章。一如既往地信息丰富。最近我读了一篇关于多类别和不平衡数据集分类的文章。他们对训练集和测试集都使用了 SMOTE,我认为这不是正确的方法,测试数据集不应该被操作。请告诉我我的理解是否错误,您能推荐一些关于使用 SMOTE 的缺点和挑战的参考资料吗?
谢谢你
谢谢!
同意,在测试集上使用 SMOTE 是无效的。
嗨 Jason
问题1:我们是在进行训练/测试分割之后才对训练集应用SMOTE吗?
我猜,如果先进行SMOTE再分割,可能会导致数据泄漏,因为相同的实例可能会同时出现在测试集和训练集中。
问题2:我明白为什么SMOTE比随机过采样少数类别更好。但是,如果类别不平衡比例为1:100,为什么不直接对多数类别进行随机欠采样呢?我不确定SMOTE在这里有什么帮助!
谢谢
维韦克
是的。仅限于训练集。
尝试多种方法,找出最适合您数据集的方法。
嗨,Jason,
如果您的数据集不平衡,但与生产中的实际类别分布相符,该怎么办?假设类别 A 有 1000 行,类别 B 有 400 行,类别 C 有 60 行。这种不平衡的数据集会带来哪些负面影响?假设我使用像朴素贝叶斯这样的分类器,由于先验概率很重要,如果我对类别 C 进行过采样,我就会弄乱先验概率,并偏离生产中的实际概率。我应该尝试获取更多数据或在我拥有的数据上进行数据增强,同时保持这种不平衡分布,还是通过对少数类别进行过采样来改变分布?
谢谢
负面影响将是预测性能不佳。
我建议测试一系列技术,以发现哪种技术最适合您的特定数据集。
这个框架将会有帮助
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
你好,
感谢您的工作,它真的很有用。我有一个关于 SMOTE 和主动学习结合的问题。
我正在尝试使用主动学习技术生成数据集。我从一个未标记的数据池中选择要标记的新点,使用每次迭代中的不确定性。我的问题是类别分布不平衡(1000:1),我当前的算法无法在“是”类别中找到足够的点。您认为我可以使用 SMOTE 生成“是”类别的新点吗?
我正在考虑使用 borderline-SMOTE 来生成新点,然后对其进行标记。我怎么能确定新点不会集中在一个小区域内?
我不确定我是否很好地解释了这个问题。我需要以智能的方式使用标注器找到可行区域,因为标注成本很高。您能给我一些建议吗?
谢谢。
Daniel
或许可以试试看?
我对整个数据集执行 SMOTE,然后对数据集进行归一化。之后,我应用了 cross_val_score。在 cross_val_score 中,SMOTE 只会对训练集进行重采样,这是正确的吗?代码如下:
oversample = SMOTE()
X, Y = oversample.fit_resample(X, Y)
normalized = StandardScaler()
normalized_X = normalized.fit_transform(X)
clf_entropy = DecisionTreeClassifier(random_state = 42)
y_pred = cross_val_predict(clf_entropy, normalized_X, Y, cv=15)
不。如果您使用管道,它将按您所述工作。
嗨,Jason。
感谢您的帖子。关于上面的 SMOTE + 欠采样示例,我有两个问题。
“under = RandomUnderSampler(sampling_strategy=0.5)” 。为什么我们要将多数类别欠采样为 1:2 的比例,而不是让两个类别具有相等的表示?
2. 如果我的不平衡数据中少数类别占 50%,我是否需要使用 PR 曲线 AUC 或 f1 作为度量,而不是 ROC AUC?
“scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)”
谢谢!!
尝试一系列不同的再平衡比例并查看哪种效果最好是一个好主意。经过一些反复试验,我在这个数据集上找到了这个比例。
这将帮助你选择一个指标
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
谢谢杰森。现在正在应用。
谢谢!
杰森,我正在尝试对不平衡数据应用各种平衡方法。但是,对于平衡训练数据集如何使算法在不平衡测试数据上学习并表现良好,我仍然感到不解。这是否取决于特征的质量?意思是,如果我看到在各种平衡训练数据集的方法之后,模型在测试数据上泛化不好,我需要重新审视特征创建吗?
谢谢!!
很难说,我们能做的最好的事情就是通过受控实验来发现哪种方法对给定的数据集效果最好。
谢谢!
不客气。
嗨,Jason,
非常感谢您的解释。我在使用 SMOTE 拟合模型时有一个问题
为什么您使用 .fit_resample 而不是 .fit_sample?这两个函数有什么区别?
另外,在 SMOTE 过采样后,是否有办法知道原始数据集的索引?我如何知道 SMOTE 上采样数据集中哪些数据来自原始数据集?
谢谢!
抱歉,两个函数的区别在 API 中不清楚
https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.over_sampling.SMOTE.html
也许可以两者都尝试一下,比较结果。
你好,我应用了 SMOTE 进行数据平衡。首先,我的数据有 27 个特征,当我在 make_classification 中定义数据集时,我写了 n_features=27 而不是 2,这正确吗?当我的模型目标是预测时,我可以使用 SMOTE 进行数据平衡吗?
其次,我如何将新数据集保存到 CSV 中?
谢谢!
如果您有自己的数据,则无需使用 make_classification,因为它是一个用于创建合成数据集的函数。
好的,我想应用 SMOTE。我的数据包含 1,469 行,类别标签有 Risk= 1219,NoRisk= 250,数据不平衡,我想应用过采样 (SMOTE) 来平衡数据。
首先,我运行这段代码,它显示了类别标签的图表,然后我应用了 SMOTE,
target_count = data[‘Having DRPs’].value_counts()
print(‘Class 1:’, target_count[1])
print(‘Class 0:’, target_count[0])
print(‘Proportion:’, round(target_count[1] / target_count[0], 2), ‘: 1′)
target_count.plot(kind=’bar’, title=’Count (Having DRPs)’);
****
(过采样:SMOTE)
from imblearn.over_sampling import SMOTE
smote = SMOTE(ratio=’minority’)
X_sm, y_sm = smote.fit_sample(X, y)
plot_2d_space(X_sm, y_sm, ‘SMOTE over-sampling’)
它给我一个错误
TypeError: __init__() 得到了一个意外的关键字参数 ‘ratio’
我该如何解决这个问题!
很抱歉听到这个消息,也许这些提示会有帮助。
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
你好,法蒂玛!您能向我解释一下您是如何在数据集上进行 smote 操作的吗?我的数据集有 4 个类别(感染(2555)、无(2552)、两者(621)、缺血(227))
你好 Jason,我对我的数据应用了 SMOTE,并解决了数据不平衡的问题。下一步我想开始深度学习(DL)。在 DL 中,我需要保存新数据(平衡后的数据),然后在新数据上开始 DL 算法吗?
谢谢!
只有训练集应该平衡,测试集不应该平衡。
您可以在拟合模型之前在内存中转换数据。或者如果对您来说更容易,也可以保存它。
你好,法蒂玛!你是怎么对你的数据集应用 smote 的?我的数据集有 4 个类别(无(2552),缺血(227),两者(621)和感染(2555))。我怎么能整合 SMOTE?
亲爱的 Jason,
感谢这篇精彩的文章!
我尝试在我的项目中实现 SMOTE,但 cross_val_score 始终返回 nan。
然后我尝试了您的代码片段
# 在具有 SMOTE 过采样的不平衡数据集上评估的决策树
from numpy import mean
从 sklearn.datasets 导入 make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import SMOTE
# 定义数据集
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# 定义流水线
步骤 = [(‘over’, SMOTE()), (‘model’, DecisionTreeClassifier())]
管道 = Pipeline(steps=steps)
# 评估流水线
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)
print(‘平均 ROC AUC:%.3f’ % scores 的平均值)
这也返回 nan。
我无法弄清楚为什么它返回 nan。在您的文章中,您描述了您确实得到了此代码片段的答案。
非常感谢!
塞缪尔
这令人惊讶,也许可以更改 CV 以在 nan 上引发错误并检查结果。
我也一直收到同样的错误
也许这些提示会有所帮助
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
你好,
我也一直得到 nan 值作为分数。你们解决了吗?如果解决了,能提供一些建议吗?
```
from sklearn.model_selection import StratifiedKFold
from sklearn import metrics
cv = StratifiedKFold(n_splits=10,shuffle=True)
classifier = AdaBoostClassifier(n_estimators=200)
y = df['label'].values
X = df
X = X.drop('label',axis=1)
X = X.values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.10, random_state = 0, stratify = y)
oversampler= sv.CCR()
X_samp, y_samp= oversampler.sample(X_train, y_train)
X_train = X_samp
y_train = y_samp
tprs = []
aucs = []
mean_fpr = np.linspace(0, 1, 100)
plt.figure(figsize=(10,10))
i = 0
# cv.sh
for train, test in cv.split(X_train, y_train)
probas_ = classifier.fit(X_train[train], y_train[train]).predict_proba(X_train[test])
# 计算 ROC 曲线和曲线下面积
fpr, tpr, thresholds = metrics.roc_curve(y_train[test], probas_[:, 1])
tprs.append(np.interp(mean_fpr, fpr, tpr))
tprs[-1][0] = 0.0
roc_auc = metrics.auc(fpr, tpr)
aucs.append(roc_auc)
plt.plot(fpr, tpr, lw=1, alpha=0.3,
label='ROC fold %d (AUC = %0.2f)' % (i, roc_auc))
i += 1
plt.plot([0, 1], [0, 1], linestyle='--', lw=2, color='r',
label='Chance', alpha=.8)
mean_tpr = np.mean(tprs, axis=0)
mean_tpr[-1] = 1.0
mean_auc = metrics.auc(mean_fpr, mean_tpr)
std_auc = np.std(aucs)
plt.plot(mean_fpr, mean_tpr, color='b',
label=r'Mean ROC (AUC = %0.2f $\pm$ %0.2f)' % (mean_auc, std_auc),
lw=2, alpha=.8)
std_tpr = np.std(tprs, axis=0)
tprs_upper = np.minimum(mean_tpr + std_tpr, 1)
tprs_lower = np.maximum(mean_tpr - std_tpr, 0)
plt.fill_between(mean_fpr, tprs_lower, tprs_upper, color='grey', alpha=.2,
label=r'$\pm$ 1 std. dev.')
```
plt.xlim([-0.01, 1.01])
plt.ylim([-0.01, 1.01])
plt.xlabel('False Positive Rate',fontsize=18)
plt.ylabel('True Positive Rate',fontsize=18)
plt.title('ADABOOST 的交叉验证 ROC',fontsize=18)
plt.legend(loc="lower right", prop={'size': 15})
plt.show()
```
检查此输出
https://ibb.co/PYLs8qF
我很困惑,因为在 Adaboost 之后 SMOTE 对训练集效果很好,但测试集效果不好。
https://ibb.co/yPSrLx2
编辑:我使用了 CCR,它是 smote 的一个变体。它也是 CCR+Adaboost。
干得好!
嗨,杰森,我可以问一下吗?我应用了 smote 装袋 svm 和 smote 增强 svm 方法,但总是出错,你能帮我找到 python 代码吗?
抱歉,我无法调试您的代码,也许这些建议会有帮助。
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
嗨 @jasonBrowniee,感谢上面的例子。快速提问,对于 SMOTE,您使用了过采样,然后是随机欠采样,想知道如果我们使用 ADASYN 或 SVMSMOTE,您是否建议我们像 SMOTE 一样使用随机欠采样?
也许可以尝试几种不同的组合,并发现哪种方法对您的特定数据集效果好/最好。
嗨,Jason,
希望您一切顺利!如果我使用分层 k 折叠或重复分层 k 折叠,还需要使用 Smote() 进行上采样吗?我认为我的分层折叠已经处理了类别不平衡。那么在什么情况下您会更喜欢 Smote 而不是分层折叠呢?
谢谢
SMOTE 可以与分层交叉验证一起使用,也可以不使用,它们解决的是不同的问题——训练数据集的采样与模型的评估。
我不相信这种技术在许多情况下“真正”有效。你可以阅读 Jonas Peters 的作品来理解为什么。它实际上是机器学习的魔法戏法,或者是数据科学的创造性一面,将“有效”定义为“我尝试过并看到了改进”的轶事证据。总体而言,不通过分析和逻辑方法严格评估此类方法是不好的。
感谢分享您的想法,迈克尔。
嗨,Jason,
感谢您建议的这些用于平衡数据集的启发式替代方法。
不客气。
嗨,杰森博士。我在几篇文章中看到,作者比较了不平衡类别和重叠类别。您有关于这方面的文章吗?
几乎所有的类都重叠——如果不是,问题就会变得微不足道(例如,线性可分)。
你到底是什么意思?
谢谢博士。
实际上,我刚接触机器学习,对不平衡分类很感兴趣。我正在这里学习机器学习和不平衡分类的基础知识:https://machinelearning.org.cn/start-here/。
然后,我开始阅读其他资料,以加强和验证我的理解。我找到了这篇文章:https://link.springer.com/chapter/10.1007/978-3-642-13059-5_22,它讲述了不平衡和重叠之间的区别。
也许是因为我的基础不是很扎实,我不太明白这篇文章在说什么。所以,我像往常一样来到您的博客(它真的对像我这样的新手很有帮助),希望能找到一篇关于重叠和不平衡之间区别的文章。不幸的是,我找不到。????
感谢分享,抱歉我对这篇文章不熟悉。
好的,杰森博士
顺便问一下,我是否需要了解数据集中重叠问题?有没有关于这方面的文章?
再次感谢博士
我不这么认为,我以前没有听说过这个概念。
好的,博士,非常感谢
嗨,杰森,感谢这篇信息量很大的文章。但我只是想知道,在过采样/欠采样数据集上调整模型超参数是否有意义,像这样?
paramgrid_rf = {‘n_estimators’: [500],
‘max_depth’: [4],
‘random_state’: [0],
‘max_features’: [‘sqrt’],
‘criterion’ :[‘mse’]
}
rfc = GridSearchCV(RandomForestRegressor(), paramgrid, cv=5)
steps = [(‘over’, SMOTE(sampling_strategy=0.2)), (‘model’, rfc)]
管道 = Pipeline(steps=steps)
# 评估流水线
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, x_train, y_train, scoring=’f1′, cv=cv, n_jobs=-1)
也许可以。
尽一切可能在您的测试工具上取得更好的结果。
请指定需要哪些模块。我花了一个小时才找到 numpy 中该死的 where 属性。
本教程将向您展示如何设置您的开发环境
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
我上面的评论看起来太负面了。这太棒了;只是请指定要导入的模块。
感谢您的工作
每个部分末尾的完整代码示例都包含带代码的 import 语句。
这将帮助您从教程中复制代码。
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
嗨,Jason,
这是一个非常有用的教程。
谢谢您。
不客气!
谢谢,但我对在训练数据上应用 SMOTE 还是在 x 和 y 上应用 SMOTE 感到困惑,就像示例中那样,它们之间有什么区别
这会解释 X 和 y
https://machinelearning.org.cn/faq/single-faq/what-are-x-and-y-in-machine-learning
好的,那是 x 和 y(特征和目标),但是为什么你要在它上面应用 smote?在训练数据上应用 smote 是否意味着 x 分成训练和测试,y 保持不变,然后将 smote 应用于 xtrain 和 ytrain?
是的,SMOTE 仅应用于训练数据集。
上面的例子向您展示了如何使用 SMOTE 类及其效果——这样您就可以熟悉它,并开始在自己的项目中使用它。
你好,Jason
我们可以在 imblearn 管道中用 FAMD(prince) 实现 SMOTENC 吗?如果可以,您能提供一些关于方法和代码的参考资料吗?
我不能直接回答,抱歉。也许可以尝试使用原型来探索一下。
谢谢
嗨,杰森,感谢 SMOTE 的精彩内容。我的数据中有一个分类变量,即位置。我可以使用 SMOTENC 在重采样中使用它。但是有没有一种方法可以实现 SMOTE,以便我可以在位置上对少数类别实现同质性。因此,SMOTE 将在最初具有少量少数类别实例的位置生成合成数据。
您可能需要自己实现该算法,以便对算法选择重新采样的位置进行精细控制。
一如既往,感谢您的及时回复!
不客气。
我们也可以将 SMOTE 应用于测试数据集吗?
不,SMOTe 仅应用于训练数据集。
那么如果测试数据不平衡,我该怎么做呢?我将数据集分成 70% 的训练集和 30% 的测试集。在我使用 SMOTE 平衡训练集之后,我想在测试集上测试模型,然后由于测试集不平衡,AUC 会非常低,我该怎么做?非常感谢!
也许 AUC 不是您问题的最佳指标?
也许您可以使用重复的 k 折交叉验证来估计 AUC?
嗨,Json,
这篇关于不平衡类别的文章非常简洁。非常感谢您的文章和原始论文的链接。
谢谢!
你好,文章很棒,但请不要推荐使用 sudo 权限从 pip 安装 python 包!你基本上是在将管理员权限授予从互联网上拉取的一些随机脚本,这真的不是一个好习惯,甚至很危险。更多参考资料,请看这里:https://askubuntu.com/a/802594
非常感谢!
感谢分享。
你好,Jason
我是这里的新手。我正在处理时间序列预测回归问题。这意味着预测模型需要从一系列过去的观测中学习,以预测序列中的下一个值。
我正在使用 1998 年世界杯网站数据集(包含 1998 年 4 月 30 日至 1998 年 7 月 26 日期间对 1998 年世界杯网站发出的所有请求)。这是 FTP 链接:ftp://ita.ee.lbl.gov/html/contrib/WorldCup.html
我通过将同一分钟内发生的所有日志聚合到一个累积记录中来预处理数据集。
我想问一下我的数据集是否不平衡?以及为什么?
谢谢你的帮助。
不。通常不平衡是针对分类任务的,您说您的问题是回归(预测数值)。
你好 Jason,感谢你的文章。
我看到了一篇关于 SMOTE 的文章,我很困惑。这是他们使用的代码
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=42)
X_sm, y_sm = sm.fit_resample(X, y)
X_train, X_test, y_train, y_test = train_test_split(
X_sm, y_sm, test_size=0.25, random_state=42
)
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
preds = model.predict(X_test)
你说 SMOTE 只应用于训练集。所以上面的代码是错误的?
这是文章,如果您想查看的话
https://towardsdatascience.com/how-to-effortlessly-handle-class-imbalance-with-python-and-smote-9b715ca8e5a7
我尽量不评论别人的代码——他们可以做任何他们喜欢的事情。
是的。致命的。
你好,我想感谢你的博客。它真的对我帮助很大。作为一个初学者,我想问你一个问题。使用 SMOTE 进行交叉验证会导致模型出现偏差吗?我的意思是,当你设置管道以应用 SMOTE 然后进行模型拟合时,交叉验证是在原始测试集上进行验证过程还是在过采样测试集上进行?我在 stackoverflow 上看到一个帖子说,当我们使用 SMOTE 时,它应该只在训练集上完成,并且模型应该只在原始数据上进行测试。交叉验证也符合这个标准吗?谢谢。
当在管道中使用 SMOTE 时,它仅应用于训练集,绝不应用于交叉验证评估/测试工具中的测试集。
嗨,首先,我只想感谢您的贡献。我有一个问题
scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)
score = mean(scores)
当您在训练数据上计算 cross_val_score 时,平均值似乎无关紧要,我的意思是当您在测试数据上计算时,AUC 才重要。我的交叉验证 AUC 很高,但在测试数据上只有 0.5。
抱歉,我不明白你的问题。也许你可以重新表述一下?
您好,谢谢您,
我想知道 smote 方法是否适用于文本数据。我正在处理不平衡数据的文本分类。
不,仅限表格数据。
感谢您的精彩帖子。我认为 SMOTE 仅适用于不平衡的表格数据集,这是一个分类问题。您知道任何用于具有表格数据的回归问题的数据增强方法吗?非常感谢!
不客气。
正确。
抱歉,不知道。据我所知,大多数重采样方法都是为不平衡分类(而不是回归)设计的。
希望这能说得通,但我认为 CV 中计算的 ROC 分数不正确。
原因如下:在您的管道代码中,进行了过采样和欠采样。但我希望分数是在原始数据集上计算的,而不是在样本上。如果您生成合成数据,那么您当然可以使合成数据上的 ROC 看起来更好,但我想知道数据集在原始数据上的表现如何。
目前的分数是
score = ROC(sampled(X), sampled(y))
但我想要
score = ROC(X, y)
实际上,我删除了 k 折叠的部分,但你可以明白我的意思。所以我认为代码没有正确地完成工作
ROC 分数仅使用原始数据计算,不使用合成数据。例如,SMOTE 仅用于训练,不用于测试。
管道确保了这一点。
嗨,Jason博士,
我们如何将 SMOTE 方法应用于不平衡分类时间序列数据?另外,repeatedStratefied() 是否应用于时间序列 cv k 折?
谢谢你
SMOTE 不适用于时间序列。
交叉验证也不适用于时间序列,您必须使用诸如逐点验证之类的方法。
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
嗨,Jason,
使用 Smote 平衡了严重不平衡的数据(1:1000)后,我是否需要创建一个集成分类器,以避免因少数类别过采样和多数类别欠采样而导致的过拟合?另外,如果我使用了随机森林(本身就是一个集成),我是否可以创建一个随机森林集成,即集成的集成?这会导致过拟合吗?
谢谢你
尝试一下并比较结果。
关注评估指标。过拟合是结果不佳的一个可能原因。
此外,欠采样和过采样可能导致数据集信息丢失。
您如何将此(Smote)与使用随机森林的权重进行比较?
谢谢你。
也许可以直接比较一个 RF 和一个在 SMOTE 版本数据集上拟合的 RF。
你好 Jason,
感谢您精彩地描述了如何使用 SMOTE 及其替代方法处理不平衡数据集。
在使用 SMOTE 后跟 PCA 时,我有一个小疑问。应用 SMOTE 的最佳方法是什么?是先 PCA 后 SMOTE 还是反之?这背后的原理是什么?
也许可以尝试几种不同的方法/顺序,并发现哪种方法对您的数据集和模型效果最好。
好的!谢谢杰森
你好,杰森,一如既往,感谢您的精彩文章。我正在研究一个疾病进展预测问题。目标是预测未来某个时间点的疾病状态(目标类别之一),给定疾病状况随时间(进展中的时间依赖性)的进展。
我的大部分数据集属于“健康”状况,我只有少量样本代表各种其他疾病状况(其他目标类别)。您能就如何在这种特定情况下对少数类别样本进行过采样提出建议吗?再次感谢。
也许可以尝试上面描述的 SMOTE,并将其结果与不使用 SMOTE 的结果进行比较?
谢谢你,杰森。你是说比较使用 SMOTE 的结果和使用“其他”技术的结果吗?你能详细说明一下吗?再次感谢。
是的,也许是其他过采样方法或不过采样方法。
嗨,Jason,
我有一个关于散点图轴上的数字(-0.5 到 3 和 -3 到 4)的问题。轴值的含义是什么?
它们是输入变量的值,只是 SMOTE 作用的演示。
谢谢您的回答。我想我还没有完全理解
我以为这些值是类标签(输入 = 类标签)。但如何解释 x 轴和 y 轴呢?
再次感谢您?
X 是变量 1,y 是变量 2,颜色是类别标签。
开发人员是否应该始终将预测概率与 SMOTE 或其他再平衡技术结合起来进行校准?
可能不会——只在模型不能原生提供概率时才需要。
嗨,杰森,这是一篇很棒的文章,它真的帮助我理解了 SMOTE。我还有更多关于 K-means SMOTE 和 CURE SMOTE 的问题,您可以在您的论文中添加这两个示例吗?因为我觉得它很难实现,因为外面没有太多例子。提前致谢
感谢您的建议。
我如何将 SMOTE 应用于人类活动数据集等多变量时间序列数据?
谢谢
SMOTE 不适用于时间序列或序列数据。
也许您可以查阅文献,寻找一种适合时间序列数据的过采样方法。
非常感谢!
只是一个快速问题。
在下面的这句话中
“这被称为 Borderline-SMOTE1,而仅对少数类别中的边缘情况进行过采样则被称为 Borderline-SMOTE2。”
我猜如果 1 只影响一个类,而 2 影响两个类,那么 1 和 2 应该互换。
“””Borderline-SMOTE2 不仅从 DANGER 中的每个示例及其在 P 中的正最近邻居生成合成示例,而且还从其在 N 中的最近负邻居生成合成示例。”””
如果我理解错了,请告诉我。
谢谢!
谢谢。
# 定义流水线
步骤 = [(‘over’, SMOTE()), (‘model’, DecisionTreeClassifier())]
管道 = Pipeline(steps=steps)
# 评估流水线
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)
嗨,杰森。在每个折叠中,在仅对训练数据集进行过采样之前,训练和验证数据集的拆分部分在哪里?我不明白。它是隐式的吗?我无法确定过采样过程是否仅应用于训练数据集,而不是在拆分后应用于验证数据集。谢谢。
这里您正在进行 CV。CV 的模型是管道,其中包括 SMOTE 和决策树。它将执行 k 折叠并将拆分输入模型进行训练,然后使用保留集进行测试。所有这些都在 RepeatedStratifiedKFold() 函数内部完成。
# 定义流水线
步骤 = [(‘over’, SMOTE()), (‘model’, DecisionTreeClassifier())]
管道 = Pipeline(steps=steps)
# 评估流水线
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)
嗨,杰森。在这里,您直接将 smote 算法提供给交叉验证分数。这意味着它将首先应用 smote 算法,然后拆分数据集。所以我们也对将用于测试的折叠应用了 SMOTE。难道我们不应该先进行 smote,然后将数据集提供给 cross_val_score 以避免这种情况吗?
不。管道将使用拆分数据集进行拟合,而不是整个数据集。这样做的步骤顺序是为了避免数据泄漏。
好吧,我知道这样做应该不会改变什么,但即使如此,我还是尝试了一下,令我惊讶的是。ROC AUC 分数平均增加了 0.1 个百分点,为什么会这样?
新的 ROC AUC 分数
> k=1,平均 ROC AUC:0.951
> k=2,平均 ROC AUC:0.927
> k=3,平均 ROC AUC:0.925
> k=4,平均 ROC AUC:0.919
> k=5,平均 ROC AUC:0.925
> k=6,平均 ROC AUC:0.909
> k=7,平均 ROC AUC:0.899
使用这里的代码
> k=1,平均 ROC AUC:0.835
> k=2,平均 ROC AUC:0.825
> k=3,平均 ROC AUC:0.840
> k=4,平均 ROC AUC:0.855
> k=5,平均 ROC AUC:0.846
> k=6,平均 ROC AUC:0.830
> k=7,平均 ROC AUC:0.845
我的代码
for k in k_values
# 定义流水线
model = DecisionTreeClassifier()
over = SMOTE(sampling_strategy=0.1, k_neighbors=k)
under = RandomUnderSampler(sampling_strategy=0.5)
steps = [(‘over’, over), (‘under’, under)]
管道 = Pipeline(steps=steps)
X_t,y_t = pipeline.fit_resample(X,y)
# 评估流水线
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X_t, y_t, scoring=’roc_auc’, cv=cv, n_jobs=-1)
score = mean(scores)
print(‘> k=%d,平均 ROC AUC:%.3f’ % (k,分数))
你在这里做得对吗?我看到定义了“pipeline”,但您评估了“model”。
你好 Jason,我正在处理一个平衡但实例很少的数据,每个类有 171 个实例,请指导我如何使用 smote 并增加(过采样)每个类,谢谢。
我没有看到 imblearn 库允许您这样做。但是您可以故意向数据中添加一个虚假的多数类并应用 SMOTE。之后,您只需删除该虚假类。
嗨,杰森,感谢您出色的网站,
我已成功安装 imbalanced-learn,但是当我尝试导入 imblearn 时,它给我以下错误
AttributeError: partially initialized module 'logging' has no attribute 'StreamHandler' (most likely due to a circular import)
你知道我怎么解决这个问题吗?
提前感谢您的回答。
你好侯赛因……您可能会发现以下内容感兴趣
https://imbalanced-learn.org/stable/install.html
嗨,杰森,感谢您所有帖子中清晰且信息丰富的教程。对于这些欠采样/过采样方法或更改权重方法,我有一个问题,在验证/测试步骤中,在训练阶段之后我们不需要进行缩放还原吗?谢谢。
你好伊娃……建议在验证期间计算性能指标时对数据进行逆变换。
大家好。请问一个问题。当我们使用 smote 时,我们得到了类别平衡。在这种情况下,我们可以使用准确率作为我们的指标吗?还是我们仍然必须使用这里的一些指标 https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/ ?
嗨,杰森,我昨天发现了您的网站,我对您的内容感到惊讶。
我有个问题
for label, _ in counter.items()
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
这个循环是如何工作的?
非常感谢。
嗨,托马斯……我的建议是在您的 Python 环境中实现这样的功能,以便最好地理解。换句话说,尝试使用它以了解更多信息。
如果您想在应用 SMOTE 和欠采样后,将数组转换回数据帧并进行特征选择或排名,该怎么做?
嗨,约翰……您可能会发现以下内容感兴趣
https://github.com/scikit-learn-contrib/imbalanced-learn/issues/534
正如 Jason 指出的,当特征是数值时,SMOTE 生成的合成样本是原始样本的凸组合。SMOTE 如何处理分类特征?一种天真的方法是使用组件样本中的主导类别,但我没有在任何论文中看到过这种方法。
感谢 Jason 的精彩解释。
您的博客真的很棒。
感谢您的宝贵反馈!
非常感谢。
我尝试使用“from imblearn.over_sampling import SMOTE”
但是 Python 说
No module named 'imblearn'
于是,我尝试安装它。我使用了以下命令行
“!pip install -U imbalanced-learn”
仍然是同样的错误。
我该怎么办?
提前感谢您的时间
你好阿里……您可能希望在研究纠正本地环境的选项时尝试使用 Google Colab。
很棒的文章和教程,谢谢。
在我的案例中,我有一个 16/84 的不平衡数据集,并使用和不使用 SMOTE 对多个估计器进行了多次测试。我在没有 SMOTE 的情况下总体上取得了更好的结果(F1 和 Matthew Corr)。我应该保持不平衡吗?
嗨,马克……我发现您的建议没有任何问题。您已经实现了您的模型了吗?请告诉我们您的发现。
感谢您的本教程。在 SMOTE 的上一个示例中,数据有两个 x 特征,如果数据集有多个 x,那么散点图中的 x 轴和 y 轴代表什么?
嘿,詹姆斯,
为什么在 SMOTE 中,使用线性近似来复制数据点有效?为什么不能是非线性的?
嗨,Shriraj……还有其他合适的方法可以使用。您是否应用过非线性方法?
你好詹姆斯,谢谢你的辛勤工作!
您知道 SMOTE 方法是否可以应用于无监督学习(聚类)吗?
我正在尝试准备数据以应用聚类,我不明白在这种情况下是否应该“纠正”不平衡数据。
嗨,Marta……非常欢迎您!您可能会发现以下资源很有帮助
https://www.sciencedirect.com/science/article/abs/pii/S0020025521001985
你好 Jason,
希望您能阅读此查询。
想知道如果使用 SMOTE,如何获得最终的生产模型?
一般来说,在交叉验证对结果满意后,我们会结合所有数据拆分,并对整个数据应用/重复使用从交叉验证获得的最佳超参数。在重采样的情况下——我们是否平衡整个数据以获得生产模型?
嗨,Nishant……您可能会发现以下内容很有趣
https://machinelearning.org.cn/a-first-course-on-deploying-python-projects/
谢谢James,感谢您提供的链接。我觉得它很有趣,但并没有回答我的问题。
你好,
非常感谢您分享您的机器学习知识!
假设我们有一个不平衡的数据集(1:100)。由于数据集应该进行分层,训练集、验证集和测试集这三个子集具有相同的比例。现在,如果我们只对训练子集应用SMOTE以获得例如1:2的比例,那么其他两个子集将保持相同的不平衡1:100比例。
我的理解正确吗?
因此,我不明白在存在上述问题的情况下,SMOTE如何能提高性能。
谢谢你,
Mohammad
你好 Mohammad……以下资源可能对何时应用SMOTE感兴趣。
https://analyticsindiamag.com/how-can-smote-technique-improve-the-performance-of-weak-learners/
谢谢你,James。感谢您的回复,但我没有在该网站上找到我的答案。
你好 Jason,感谢您分享本教程
顺便问一下,您能否解释一下您是如何只对训练数据集应用过采样操作的?我没有在您的代码示例中看到训练集-测试集分割。
非常欢迎您,Abitama!以下资源可能对您有所帮助。
https://datascience.stackexchange.com/questions/61858/oversampling-undersampling-only-train-set-only-or-both-train-and-validation-set
https://machinelearning.org.cn/combine-oversampling-and-undersampling-for-imbalanced-classification/
!pip install scikit-learn
!pip install imblearn
from imblearn.over_sampling import SVMSMOTE
显示错误
无法从“sklearn.utils._param_validation”(C:\Users\Acer\anaconda3\Lib\site-packages\sklearn\utils\_param_validation.py)导入名称“_MissingValues”
我无法解决这个问题。
请告诉我如何解决此问题或使用 sklearn 和 imblearn 的替代方法。
你好 Sasadhar……以下资源可能对您有所帮助。
https://stackoverflow.com/questions/76593906/how-to-resolve-cannot-import-name-missingvalues-from-sklearn-utils-param-v
你好,
您有 SMOTE + GAN 采样的示例吗?
你好,
如何检查生成数据的质量?
在使用合成少数过采样技术(SMOTE)时检查生成数据的质量至关重要,以确保合成样本合理且不会将噪声或偏差引入数据集。以下是评估SMOTE生成的合成数据质量的一些步骤和技术。
### 1. 目视检查
– **散点图**:如果特征数量较少,可以在2D或3D空间中绘制原始数据和合成数据。这有助于直观地评估合成样本是否与少数类良好重叠。
rlibrary(ggplot2)
# 假设您有一个数据框“data”,其中包含特征“feature1”和“feature2”
# 以及一个指示类别标签的“Class”列
ggplot(data, aes(x = feature1, y = feature2, color = Class)) +
geom_point() +
theme_minimal() +
ggtitle("原始数据和SMOTE生成数据的散点图")
### 2. 统计度量
– **特征分布比较**:使用Kolmogorov-Smirnov检验等统计测试或直方图和密度图等可视化工具,比较原始数据和合成数据之间的特征分布。
r
# 特征分布的Kolmogorov-Smirnov检验
ks.test(original_data$feature1, synthetic_data$feature1)
– **汇总统计**:比较原始少数类和合成数据中特征的均值、方差、偏度和峰度。
r
summary(original_data$feature1)
summary(synthetic_data$feature1)
### 3. 机器学习性能
– **分类器性能**:在增强数据集上训练分类器,并使用交叉验证评估其性能。F1分数、召回率和精确度等指标的改进表明合成数据质量良好。
rlibrary(caret)
# 假设您有一个训练数据集“trainData”和标签“trainLabels”control <- trainControl(method = "cv", number = 10) model <- train(Class ~ ., data = trainData, method = "rf", trControl = control) print(model)
### 4. 聚类分析
- **聚类技术**:使用聚类算法(例如,k-means,DBSCAN)来查看合成样本是否与原始少数类很好地聚类。聚类不良可能表明合成样本质量较低。
rlibrary(cluster)
clustering <- kmeans(rbind(original_data, synthetic_data), centers = 2) plot(original_data$feature1, original_data$feature2, col = clustering$cluster) points(synthetic_data$feature1, synthetic_data$feature2, col = clustering$cluster, pch = 2)
### 5. 最近邻分析
- **K-最近邻(KNN)距离**:计算合成样本到其在原始少数类中的最近邻居的平均距离。距离过大可能表明合成样本是异常值。
rlibrary(FNN)
knn_distances <- get.knnx(data = original_data[, c("feature1", "feature2")], query = synthetic_data[, c("feature1", "feature2")], k = 5)$nn.dist mean(knn_distances)
### 6. 平衡检查
- **类别比例**:应用SMOTE后,确保类别比例平衡或达到所需水平。SMOTE后不平衡可能表示实施存在问题。
r
table(new_data$Class)
### R语言中的示例实现
以下是在R语言中应用和评估SMOTE的示例:
rlibrary(DMwR)
library(ggplot2)
# 示例数据集data(iris)
iris <- iris[iris$Species != "setosa", ] # 删除一个类别进行二元分类 # 应用SMOTE set.seed(123) smote_data <- SMOTE(Species ~ ., data = iris, perc.over = 200, perc.under = 200) # 目视检查 ggplot(smote_data, aes(x = Petal.Length, y = Petal.Width, color = Species)) + geom_point() + theme_minimal() + ggtitle("原始数据和SMOTE生成数据的散点图") # 统计度量 ks.test(iris$Petal.Length, smote_data$Petal.Length) summary(iris$Petal.Length) summary(smote_data$Petal.Length) # 分类器性能 control <- trainControl(method = "cv", number = 10) model <- train(Species ~ ., data = smote_data, method = "rf", trControl = control) print(model) # 最近邻分析 knn_distances <- get.knnx(data = iris[, c("Petal.Length", "Petal.Width")], query = smote_data[smote_data$Species == "versicolor", c("Petal.Length", "Petal.Width")], k = 5)$nn.dist mean(knn_distances) # 平衡检查 table(smote_data$Species)
这种方法结合了多种方法,以全面评估SMOTE生成的合成数据的质量。