抽查算法是一种应用机器学习技术,旨在快速、客观地为新的预测建模问题提供第一组结果。
与旨在寻找最优算法或算法最优配置的网格搜索和其他类型的算法调优不同,抽查的目的是快速评估多样化的算法集,并提供一个粗略的初步结果。这个初步结果可以用来大致了解一个问题或问题表示是否确实可以预测,如果可以,哪些类型的算法值得进一步研究。
抽查是一种方法,旨在克服应用机器学习的“难题”,并鼓励您清晰地思考在任何机器学习项目中进行的高阶搜索问题。
在本教程中,您将发现抽查算法在新的预测建模问题上的有用性,以及如何开发一个标准的Python框架来抽查分类和回归问题的算法。
完成本教程后,您将了解:
- 抽查提供了一种快速发现哪些算法在您的预测建模问题上表现良好的方法。
- 如何开发一个通用的框架来加载数据、定义模型、评估模型和汇总结果。
- 如何将该框架应用于分类和回归问题。
通过我的新书 Python机器学习精要 启动您的项目,其中包含分步教程以及所有示例的Python源代码文件。
让我们开始吧。

如何开发一个可重用的Python抽查算法框架
照片作者: Jeff Turner,部分权利保留。
教程概述
本教程分为五个部分;它们是:
- 抽查算法
- Python中的抽查框架
- 分类抽查
- 回归抽查
- 框架扩展
1. 抽查算法
我们无法提前知道哪些算法在给定的预测建模问题上表现良好。
这是应用机器学习中可以通过系统实验解决的难点。
抽查是解决这个问题的一种方法。
它涉及在问题上快速测试一系列多样化的机器学习算法,以便快速发现哪些算法可能有效以及在哪里集中注意力。
- 它速度快;它绕过了数天或数周的准备和分析以及尝试可能永远不会产生结果的算法。
- 它很客观,让您发现什么可能对问题有效,而不是沿用您上次使用的。
- 它能产生结果;您将实际拟合模型、进行预测,并了解您的问题是否可预测以及基线技能可能是什么样子。
抽查可能需要您使用数据集的小样本,以便快速获得结果。
最后,抽查结果是起点。它们表明了应该在哪里关注问题,而不是什么算法是最好的。这个过程旨在打破您固有的思维和分析方式,转而关注结果。
您可以在以下帖子中了解更多关于抽查的信息
现在我们知道了什么是抽查,让我们看看如何在Python中系统地执行抽查。
2. Python中的抽查框架
在本节中,我们将为脚本构建一个框架,该脚本可用于对分类或回归问题进行机器学习算法的抽查。
框架需要我们开发四个部分;它们是
- 加载数据集
- 定义模型
- 评估模型
- 总结结果
让我们依次看看每一个。
加载数据集
框架的第一步是加载数据。
该函数必须为给定问题实现,并针对该问题进行专门化。它可能涉及从一个或多个CSV文件中加载数据。
我们将此函数命名为load_data();它不接受任何参数,并返回预测问题的输入(X)和输出(y)。
|
1 2 3 4 |
# 加载数据集,返回X和y元素 def load_dataset(): X, y = None, None return X, y |
定义模型
下一步是定义要在预测建模问题上评估的模型。
定义的模型将特定于预测建模问题的类型,例如分类或回归。
定义的模型应具有多样性,包括以下混合
- 线性模型。
- 非线性模型。
- 集成模型。
每个模型都应有机会在问题上表现良好。在某些情况下,这可能意味着尝试参数的几种变体,例如在梯度提升的情况下。
我们将此函数命名为define_models()。它将返回一个字典,其中模型名称映射到scikit-learn模型对象。名称应简短,如“svm”,并可能包含配置详细信息,例如“knn-7”。
该函数还将接受一个字典作为可选参数;如果未提供,将创建一个新字典并进行填充。如果提供了字典,模型将被添加到其中。
这是为了增加灵活性,如果您想拥有多个定义模型的函数,或者添加大量具有不同配置的特定类型模型。
|
1 2 3 4 |
# 创建一个用于评估的标准模型字典 {名称:对象} def define_models(models=dict()): # ... 返回 models |
关键不在于网格搜索模型参数;这可以在以后进行。
相反,每个模型都应有机会表现良好(即,不是最优)。这可能意味着在某些情况下尝试许多参数组合,例如在梯度提升的情况下。
评估模型
下一步是评估在加载的数据集上定义的模型。
scikit-learn库允许在评估期间进行模型流水线操作。这允许在将数据用于拟合模型之前对其进行转换,并且这样做是正确的,因为转换是在训练数据上准备好的,并且应用于测试数据。
我们可以定义一个函数,在评估之前准备给定的模型,以允许在抽查过程中使用特定的转换。它们将以一种通用的方式应用于所有模型。这对于执行标准化、归一化和特征选择等操作很有用。
我们将定义一个名为make_pipeline()的函数,它接受一个已定义的模型并返回一个流水线。下面是一个准备流水线的示例,该流水线将首先对输入数据进行标准化,然后对其进行归一化,然后再拟合模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 为模型创建特征准备流水线 def make_pipeline(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline |
此函数可以扩展以添加其他转换,或简化以返回带有无转换的输入模型。
现在我们需要评估一个准备好的模型。
我们将使用k折交叉验证的标准来评估模型。每个已定义模型的评估将导致一个结果列表。这是因为将拟合和评估10个不同版本的模型,从而得到k个分数的列表。
我们将定义一个名为evaluate_model()的函数,它将接受数据、已定义的模型、折数和用于评估结果的性能指标。它将返回分数列表。
该函数调用已定义模型的make_pipeline()来准备所需的数据转换,然后调用cross_val_score() scikit-learn函数。重要的是,n_jobs参数设置为-1,以便模型评估可以并行进行,利用您硬件上可用的所有核心。
|
1 2 3 4 5 6 7 |
# 评估单个模型 def evaluate_model(X, y, model, folds, metric): # 创建流水线 pipeline = make_pipeline(model) # 评估模型 scores = cross_val_score(pipeline, X, y, scoring=metric, cv=folds, n_jobs=-1) return scores |
模型评估有可能因异常而失败。我尤其在某些statsmodels库的模型中遇到过这种情况。
模型评估也可能产生大量警告消息。尤其在使用XGBoost模型时,我遇到过这种情况。
在抽查时,我们不关心异常或警告。我们只想知道什么有效,什么效果好。因此,我们可以捕获异常并忽略所有警告来评估每个模型。
名为robust_evaluate_model()的函数实现了此行为。evaluate_model()以捕获异常并忽略警告的方式调用。如果发生异常且无法为给定模型获得结果,则返回None结果。
|
1 2 3 4 5 6 7 8 9 10 |
# 评估一个模型并尝试捕获错误并隐藏警告 def robust_evaluate_model(X, y, model, folds, metric): scores = None try: with warnings.catch_warnings(): warnings.filterwarnings("ignore") scores = evaluate_model(X, y, model, folds, metric) except: scores = None return scores |
最后,我们可以定义评估模型列表的顶级函数。
我们将定义一个名为evaluate_models()的函数,它接受模型字典作为参数,并返回模型名称到结果列表的字典。
交叉验证过程中的折数可以通过可选参数指定,默认为10。模型预测计算的指标也可以通过可选参数指定,默认为分类准确率。
有关支持指标的完整列表,请参阅此列表
任何None结果都将被跳过,不会添加到结果字典中。
重要的是,我们提供了一些详细的输出,总结了每个模型在评估后的平均值和标准差。如果数据集上的抽查过程需要几分钟到几小时,这会很有帮助。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 评估一个模型字典 {名称:对象},返回 {名称:分数} def evaluate_models(X, y, models, folds=10, metric='accuracy'): results = dict() for name, model in models.items(): # 评估模型 scores = robust_evaluate_model(X, y, model, folds, metric) # 显示进度 if scores is not None: # 存储一个结果 results[name] = scores mean_score, std_score = mean(scores), std(scores) print('>%s: %.3f (+/-%.3f)' % (name, mean_score, std_score)) else: print('>%s: error' % name) return results |
请注意,如果您出于某种原因想查看警告和错误,您可以更新evaluate_models()以直接调用evaluate_model()函数,绕过稳健的错误处理。我发现这在测试新的方法或静默失败的方法配置时很有用。
总结结果
最后,我们可以评估结果。
实际上,我们只想知道哪些算法表现良好。
总结结果的两种有用方法是
- 排名前10的算法的平均值和标准差的行摘要。
- 排名前10的算法的箱形图和须图。
行摘要快速而精确,但假定分布良好,这可能不合理。
箱形图和须图不假定任何分布,并提供一种直观的方法来直接比较模型得分的分布,包括中位数性能和得分的分布。
我们将定义一个名为summarize_results()的函数,它接受结果字典,打印结果摘要,并创建一个保存到文件的箱形图图像。该函数接受一个参数来指定评估得分是否正在最大化,该参数默认为True。要汇总的结果数量也可以作为可选参数提供,默认为10。
该函数首先对分数进行排序,然后打印摘要并创建箱形图和须图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 打印并绘制前n个结果 def summarize_results(results, maximize=True, top_n=10): # 检查是否无结果 if len(results) == 0: print('无结果') return # 确定要汇总的结果数量 n = min(top_n, len(results)) # 创建一个 (名称, 平均分(分数)) 元组列表 mean_scores = [(k,mean(v)) for k,v in results.items()] # 按平均分对元组进行排序 mean_scores = sorted(mean_scores, key=lambda x: x[1]) # 反转为降序(例如,用于准确性) if maximize: mean_scores = list(reversed(mean_scores)) # 检索前n个用于汇总 names = [x[0] for x in mean_scores[:n]] scores = [results[x[0]] for x in mean_scores[:n]] # 打印前n个 print() for i in range(n): name = names[i] mean_score, std_score = mean(results[name]), std(results[name]) print('Rank=%d, Name=%s, Score=%.3f (+/- %.3f)' % (i+1, name, mean_score, std_score)) # 前n个的箱形图 pyplot.boxplot(scores, labels=names) _, labels = pyplot.xticks() pyplot.setp(labels, rotation=90) pyplot.savefig('spotcheck.png') |
现在我们已经为Python中的抽查算法专门化了一个框架,让我们看看如何将其应用于分类问题。
3. 分类抽查
我们将使用make_classification()函数生成一个二元分类问题。
该函数将生成1000个样本,其中包含20个变量,其中一些是冗余变量,以及两个类别。
|
1 2 3 |
# 加载数据集,返回X和y元素 def load_dataset(): return make_classification(n_samples=1000, n_classes=2, random_state=1) |
作为分类问题,我们将尝试一系列分类算法,特别是
线性算法
- 逻辑回归
- 岭回归
- 随机梯度下降分类器
- 被动侵略分类器
我尝试过LDA和QDA,但它们不幸地在C代码中崩溃了。
非线性算法
- k-近邻
- 分类与回归树
- 极端树
- 支持向量机
- 朴素贝叶斯
集成算法
- AdaBoost
- 装袋决策树
- 随机森林
- 额外树
- 梯度提升机
此外,我为Ridge、kNN和SVM等少数算法添加了多种配置,以给予它们在问题上的良好机会。
完整的define_models()函数如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 创建一个用于评估的标准模型字典 {名称:对象} def define_models(models=dict()): # 线性模型 models['logistic'] = LogisticRegression() alpha = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for a in alpha: models['ridge-'+str(a)] = RidgeClassifier(alpha=a) models['sgd'] = SGDClassifier(max_iter=1000, tol=1e-3) models['pa'] = PassiveAggressiveClassifier(max_iter=1000, tol=1e-3) # 非线性模型 n_neighbors = range(1, 21) for k in n_neighbors: models['knn-'+str(k)] = KNeighborsClassifier(n_neighbors=k) models['cart'] = DecisionTreeClassifier() models['extra'] = ExtraTreeClassifier() models['svml'] = SVC(kernel='linear') models['svmp'] = SVC(kernel='poly') c_values = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for c in c_values: models['svmr'+str(c)] = SVC(C=c) models['bayes'] = GaussianNB() # 集成模型 n_trees = 100 models['ada'] = AdaBoostClassifier(n_estimators=n_trees) models['bag'] = BaggingClassifier(n_estimators=n_trees) models['rf'] = RandomForestClassifier(n_estimators=n_trees) models['et'] = ExtraTreesClassifier(n_estimators=n_trees) models['gbm'] = GradientBoostingClassifier(n_estimators=n_trees) print('定义了 %d 个模型' % len(models)) 返回 models |
这样,我们就可以开始对问题进行算法的抽样检查了。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 |
# 二元分类抽样检查脚本 import warnings from numpy import mean from numpy import std from matplotlib import pyplot from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.preprocessing import StandardScaler 从 sklearn.预处理 导入 MinMaxScaler from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression from sklearn.linear_model import RidgeClassifier from sklearn.linear_model import SGDClassifier from sklearn.linear_model import PassiveAggressiveClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.tree import ExtraTreeClassifier from sklearn.svm import SVC from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import AdaBoostClassifier from sklearn.ensemble import BaggingClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import ExtraTreesClassifier from sklearn.ensemble import GradientBoostingClassifier # 加载数据集,返回X和y元素 def load_dataset(): return make_classification(n_samples=1000, n_classes=2, random_state=1) # 创建一个用于评估的标准模型字典 {名称:对象} def define_models(models=dict()): # 线性模型 models['logistic'] = LogisticRegression() alpha = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for a in alpha: models['ridge-'+str(a)] = RidgeClassifier(alpha=a) models['sgd'] = SGDClassifier(max_iter=1000, tol=1e-3) models['pa'] = PassiveAggressiveClassifier(max_iter=1000, tol=1e-3) # 非线性模型 n_neighbors = range(1, 21) for k in n_neighbors: models['knn-'+str(k)] = KNeighborsClassifier(n_neighbors=k) models['cart'] = DecisionTreeClassifier() models['extra'] = ExtraTreeClassifier() models['svml'] = SVC(kernel='linear') models['svmp'] = SVC(kernel='poly') c_values = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for c in c_values: models['svmr'+str(c)] = SVC(C=c) models['bayes'] = GaussianNB() # 集成模型 n_trees = 100 models['ada'] = AdaBoostClassifier(n_estimators=n_trees) models['bag'] = BaggingClassifier(n_estimators=n_trees) models['rf'] = RandomForestClassifier(n_estimators=n_trees) models['et'] = ExtraTreesClassifier(n_estimators=n_trees) models['gbm'] = GradientBoostingClassifier(n_estimators=n_trees) print('定义了 %d 个模型' % len(models)) 返回 模型 # 为模型创建特征准备流水线 def make_pipeline(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline # 评估单个模型 def evaluate_model(X, y, model, folds, metric): # 创建流水线 pipeline = make_pipeline(model) # 评估模型 scores = cross_val_score(pipeline, X, y, scoring=metric, cv=folds, n_jobs=-1) 返回 分数 # 评估一个模型并尝试捕获错误并隐藏警告 def robust_evaluate_model(X, y, model, folds, metric): scores = None try: with warnings.catch_warnings(): warnings.filterwarnings("ignore") scores = evaluate_model(X, y, model, folds, metric) except: scores = None return scores # 评估一个模型字典 {名称:对象},返回 {名称:分数} def evaluate_models(X, y, models, folds=10, metric='accuracy'): results = dict() for name, model in models.items(): # 评估模型 scores = robust_evaluate_model(X, y, model, folds, metric) # 显示进度 if scores is not None: # 存储一个结果 results[name] = scores mean_score, std_score = mean(scores), std(scores) print('>%s: %.3f (+/-%.3f)' % (name, mean_score, std_score)) else: print('>%s: error' % name) return results # 打印并绘制前n个结果 def summarize_results(results, maximize=True, top_n=10): # 检查是否无结果 if len(results) == 0: print('无结果') return # 确定要汇总的结果数量 n = min(top_n, len(results)) # 创建一个 (名称, 平均分(分数)) 元组列表 mean_scores = [(k,mean(v)) for k,v in results.items()] # 按平均分对元组进行排序 mean_scores = sorted(mean_scores, key=lambda x: x[1]) # 反转为降序(例如,用于准确性) if maximize: mean_scores = list(reversed(mean_scores)) # 检索前n个用于汇总 names = [x[0] for x in mean_scores[:n]] scores = [results[x[0]] for x in mean_scores[:n]] # 打印前n个 print() for i in range(n): name = names[i] mean_score, std_score = mean(results[name]), std(results[name]) print('Rank=%d, Name=%s, Score=%.3f (+/- %.3f)' % (i+1, name, mean_score, std_score)) # 前n个的箱形图 pyplot.boxplot(scores, labels=names) _, labels = pyplot.xticks() pyplot.setp(labels, rotation=90) pyplot.savefig('spotcheck.png') # 加载数据集 X, y = load_dataset() # 获取模型列表 models = define_models() # 评估模型 results = evaluate_models(X, y, models) # 总结结果 summarize_results(results) |
运行示例会为每个评估过的模型打印一行,最后汇总问题上前10种表现最佳的算法。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
我们可以看到,决策树的集成模型在此问题上表现最佳。这暗示了一些信息:
- 决策树的集成模型可能是值得关注的好方向。
- 如果对梯度提升进行进一步调优,它可能会表现得更好。
- 在该问题上,“良好”的表现大约是86%的准确率。
- 岭回归相对较高的性能表明需要进行特征选择。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
... >bag: 0.862 (+/-0.034) >rf: 0.865 (+/-0.033) >et: 0.858 (+/-0.035) >gbm: 0.867 (+/-0.044) 排名=1, 名称=gbm, 分数=0.867 (+/- 0.044) 排名=2, 名称=rf, 分数=0.865 (+/- 0.033) 排名=3, 名称=bag, 分数=0.862 (+/- 0.034) 排名=4, 名称=et, 分数=0.858 (+/- 0.035) 排名=5, 名称=ada, 分数=0.850 (+/- 0.035) 排名=6, 名称=ridge-0.9, 分数=0.848 (+/- 0.038) 排名=7, 名称=ridge-0.8, 分数=0.848 (+/- 0.038) 排名=8, 名称=ridge-0.7, 分数=0.848 (+/- 0.038) 排名=9, 名称=ridge-0.6, 分数=0.848 (+/- 0.038) 排名=10, 名称=ridge-0.5, 分数=0.848 (+/- 0.038) |
还创建了箱线图来总结上前10种表现良好的算法在问题上的结果。
该图显示了由决策树组成的集成方法的结果。该图强化了对这些方法进一步关注是个好主意的观点。
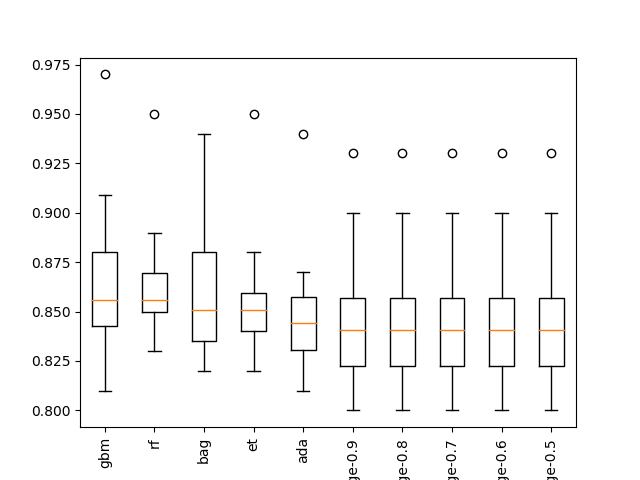
分类问题上前10种抽样检查算法的箱线图
如果这是一个真实的分类问题,我会进行进一步的抽样检查,例如:
- 使用各种不同的特征选择方法进行抽样检查。
- 不使用数据缩放方法进行抽样检查。
- 使用sklearn或XGBoost的梯度提升的粗糙网格配置进行抽样检查。
接下来,我们将了解如何将该框架应用于回归问题。
4. 回归抽样检查
我们可以仅进行非常小的更改,将相同的框架应用于回归预测建模问题。
我们可以使用make_regression()函数来生成一个人为的回归问题,包含1,000个样本和50个特征,其中一些是冗余的。
定义的load_dataset()函数如下所示。
|
1 2 3 |
# 加载数据集,返回X和y元素 def load_dataset(): return make_regression(n_samples=1000, n_features=50, noise=0.1, random_state=1) |
然后,我们可以指定一个get_models()函数来定义一组回归方法。
Scikit-learn确实提供了各种线性回归方法,这非常好。并非所有方法都可能在您的问题中是必需的。我建议至少包括线性回归和弹性网络,后者需要一套良好的alpha和lambda参数。
尽管如此,我们还是会在此问题上测试全部方法,包括:
线性算法
- 线性回归
- Lasso回归
- 岭回归
- 弹性网络回归
- Huber 回归
- LARS回归
- Lasso LARS回归
- Passive Aggressive回归
- RANSAC Regressor
- 随机梯度下降回归
- Theil回归
非线性算法
- k-近邻
- 分类和回归树
- 极端树
- 支持向量回归
集成算法
- AdaBoost
- 装袋决策树
- 随机森林
- 额外树
- 梯度提升机
完整的get_models()函数如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# 创建一个用于评估的标准模型字典 {名称:对象} def get_models(models=dict()): # 线性模型 models['lr'] = LinearRegression() alpha = [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for a in alpha: models['lasso-'+str(a)] = Lasso(alpha=a) for a in alpha: models['ridge-'+str(a)] = Ridge(alpha=a) for a1 in alpha: for a2 in alpha: name = 'en-' + str(a1) + '-' + str(a2) models[name] = ElasticNet(a1, a2) models['huber'] = HuberRegressor() models['lars'] = Lars() models['llars'] = LassoLars() models['pa'] = PassiveAggressiveRegressor(max_iter=1000, tol=1e-3) models['ranscac'] = RANSACRegressor() models['sgd'] = SGDRegressor(max_iter=1000, tol=1e-3) models['theil'] = TheilSenRegressor() # 非线性模型 n_neighbors = range(1, 21) for k in n_neighbors: models['knn-'+str(k)] = KNeighborsRegressor(n_neighbors=k) models['cart'] = DecisionTreeRegressor() models['extra'] = ExtraTreeRegressor() models['svml'] = SVR(kernel='linear') models['svmp'] = SVR(kernel='poly') c_values = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for c in c_values: models['svmr'+str(c)] = SVR(C=c) # 集成模型 n_trees = 100 models['ada'] = AdaBoostRegressor(n_estimators=n_trees) models['bag'] = BaggingRegressor(n_estimators=n_trees) models['rf'] = RandomForestRegressor(n_estimators=n_trees) models['et'] = ExtraTreesRegressor(n_estimators=n_trees) models['gbm'] = GradientBoostingRegressor(n_estimators=n_trees) print('定义了 %d 个模型' % len(models)) 返回 models |
默认情况下,该框架使用分类准确率作为评估模型预测的方法。
这对于回归来说没有意义,我们可以将其更改为更有意义的内容,例如均方误差。我们可以通过在调用evaluate_models()函数时传递metric=’neg_mean_squared_error’参数来实现。
|
1 2 |
# 评估模型 results = evaluate_models(models, metric='neg_mean_squared_error') |
请注意,默认情况下,scikit-learn会反转误差分数,使其最大化而不是最小化。这就是为什么均方误差为负数,并且在汇总时带有负号。由于分数被反转了,我们可以继续假设我们在summarize_results()函数中最大化分数,而无需像使用误差度量那样指定maximize=False。
完整的代码示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 |
# 回归抽样检查脚本 import warnings from numpy import mean from numpy import std from matplotlib import pyplot from sklearn.datasets import make_regression from sklearn.model_selection import cross_val_score from sklearn.preprocessing import StandardScaler 从 sklearn.预处理 导入 MinMaxScaler from sklearn.pipeline import Pipeline 来自 sklearn.linear_model 导入 LinearRegression 来自 sklearn.linear_model 导入 Lasso from sklearn.linear_model import Ridge 来自 sklearn.linear_model 导入 ElasticNet from sklearn.linear_model import HuberRegressor from sklearn.linear_model import Lars from sklearn.linear_model import LassoLars from sklearn.linear_model import PassiveAggressiveRegressor from sklearn.linear_model import RANSACRegressor from sklearn.linear_model import SGDRegressor from sklearn.linear_model import TheilSenRegressor from sklearn.neighbors import KNeighborsRegressor 来自 sklearn.tree 导入 DecisionTreeRegressor from sklearn.tree import ExtraTreeRegressor 来自 sklearn.svm 导入 SVR from sklearn.ensemble import AdaBoostRegressor from sklearn.ensemble import BaggingRegressor from sklearn.ensemble import RandomForestRegressor from sklearn.ensemble import ExtraTreesRegressor from sklearn.ensemble import GradientBoostingRegressor # 加载数据集,返回X和y元素 def load_dataset(): return make_regression(n_samples=1000, n_features=50, noise=0.1, random_state=1) # 创建一个用于评估的标准模型字典 {名称:对象} def get_models(models=dict()): # 线性模型 models['lr'] = LinearRegression() alpha = [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for a in alpha: models['lasso-'+str(a)] = Lasso(alpha=a) for a in alpha: models['ridge-'+str(a)] = Ridge(alpha=a) for a1 in alpha: for a2 in alpha: name = 'en-' + str(a1) + '-' + str(a2) models[name] = ElasticNet(a1, a2) models['huber'] = HuberRegressor() models['lars'] = Lars() models['llars'] = LassoLars() models['pa'] = PassiveAggressiveRegressor(max_iter=1000, tol=1e-3) models['ranscac'] = RANSACRegressor() models['sgd'] = SGDRegressor(max_iter=1000, tol=1e-3) models['theil'] = TheilSenRegressor() # 非线性模型 n_neighbors = range(1, 21) for k in n_neighbors: models['knn-'+str(k)] = KNeighborsRegressor(n_neighbors=k) models['cart'] = DecisionTreeRegressor() models['extra'] = ExtraTreeRegressor() models['svml'] = SVR(kernel='linear') models['svmp'] = SVR(kernel='poly') c_values = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for c in c_values: models['svmr'+str(c)] = SVR(C=c) # 集成模型 n_trees = 100 models['ada'] = AdaBoostRegressor(n_estimators=n_trees) models['bag'] = BaggingRegressor(n_estimators=n_trees) models['rf'] = RandomForestRegressor(n_estimators=n_trees) models['et'] = ExtraTreesRegressor(n_estimators=n_trees) models['gbm'] = GradientBoostingRegressor(n_estimators=n_trees) print('定义了 %d 个模型' % len(models)) 返回 模型 # 为模型创建特征准备流水线 def make_pipeline(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline # 评估单个模型 def evaluate_model(X, y, model, folds, metric): # 创建流水线 pipeline = make_pipeline(model) # 评估模型 scores = cross_val_score(pipeline, X, y, scoring=metric, cv=folds, n_jobs=-1) 返回 分数 # 评估一个模型并尝试捕获错误并隐藏警告 def robust_evaluate_model(X, y, model, folds, metric): scores = None try: with warnings.catch_warnings(): warnings.filterwarnings("ignore") scores = evaluate_model(X, y, model, folds, metric) except: scores = None return scores # 评估一个模型字典 {名称:对象},返回 {名称:分数} def evaluate_models(X, y, models, folds=10, metric='accuracy'): results = dict() for name, model in models.items(): # 评估模型 scores = robust_evaluate_model(X, y, model, folds, metric) # 显示进度 if scores is not None: # 存储一个结果 results[name] = scores mean_score, std_score = mean(scores), std(scores) print('>%s: %.3f (+/-%.3f)' % (name, mean_score, std_score)) else: print('>%s: error' % name) return results # 打印并绘制前n个结果 def summarize_results(results, maximize=True, top_n=10): # 检查是否无结果 if len(results) == 0: print('无结果') return # 确定要汇总的结果数量 n = min(top_n, len(results)) # 创建一个 (名称, 平均分(分数)) 元组列表 mean_scores = [(k,mean(v)) for k,v in results.items()] # 按平均分对元组进行排序 mean_scores = sorted(mean_scores, key=lambda x: x[1]) # 反转为降序(例如,用于准确性) if maximize: mean_scores = list(reversed(mean_scores)) # 检索前n个用于汇总 names = [x[0] for x in mean_scores[:n]] scores = [results[x[0]] for x in mean_scores[:n]] # 打印前n个 print() for i in range(n): name = names[i] mean_score, std_score = mean(results[name]), std(results[name]) print('Rank=%d, Name=%s, Score=%.3f (+/- %.3f)' % (i+1, name, mean_score, std_score)) # 前n个的箱形图 pyplot.boxplot(scores, labels=names) _, labels = pyplot.xticks() pyplot.setp(labels, rotation=90) pyplot.savefig('spotcheck.png') # 加载数据集 X, y = load_dataset() # 获取模型列表 模型 = 获取_模型() # 评估模型 results = evaluate_models(X, y, models, metric='neg_mean_squared_error') # 总结结果 summarize_results(results) |
运行示例会汇总每个评估模型的性能,然后打印上前10种表现良好的算法的性能。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
我们可以看到,许多线性算法可能在此问题上找到了相同的最优解。特别是那些表现良好的方法使用了正则化作为一种特征选择,这使得它们能够聚焦于最优解。
这表明特征选择在对该问题进行建模时很重要,并且线性方法将是值得关注的领域,至少目前是这样。
回顾已评估模型的打印分数,也显示了非线性算法和集成算法在此问题上的表现有多么糟糕。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
... >bag: -6118.084 (+/-1558.433) >rf: -6127.169 (+/-1594.392) >et: -5017.062 (+/-1037.673) >gbm: -2347.807 (+/-500.364) 排名=1, 名称=lars, 分数=-0.011 (+/- 0.001) 排名=2, 名称=ranscac, 分数=-0.011 (+/- 0.001) 排名=3, 名称=lr, 分数=-0.011 (+/- 0.001) 排名=4, 名称=ridge-0.0, 分数=-0.011 (+/- 0.001) 排名=5, 名称=en-0.0-0.1, 分数=-0.011 (+/- 0.001) 排名=6, 名称=en-0.0-0.8, 分数=-0.011 (+/- 0.001) 排名=7, 名称=en-0.0-0.2, 分数=-0.011 (+/- 0.001) 排名=8, 名称=en-0.0-0.7, 分数=-0.011 (+/- 0.001) 排名=9, 名称=en-0.0-0.0, 分数=-0.011 (+/- 0.001) 排名=10, 名称=en-0.0-0.3, 分数=-0.011 (+/- 0.001) |
创建了箱线图,但在此情况下对结果的分析价值不大。
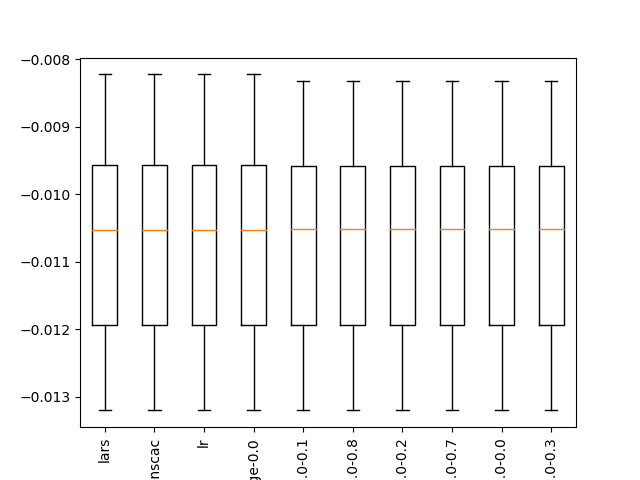
分类问题上前10种抽样检查算法的箱线图
5. 框架扩展
本节,我们将探讨抽样检查框架的一些实用扩展。
梯度提升的粗糙网格搜索
我发现自己经常使用XGBoost和梯度提升进行直接的分类和回归问题。
因此,我喜欢在抽样检查时使用粗糙网格来测试该方法的标准配置参数。
下面是一个实现此功能的函数,可以直接用于抽样检查框架。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 定义梯度提升模型 def define_gbm_models(models=dict(), use_xgb=True): # 定义配置范围 rates = [0.001, 0.01, 0.1] trees = [50, 100] ss = [0.5, 0.7, 1.0] depth = [3, 7, 9] # 添加配置 for l in rates: for e in trees: for s in ss: for d in depth: cfg = [l, e, s, d] if use_xgb: name = 'xgb-' + str(cfg) models[name] = XGBClassifier(learning_rate=l, n_estimators=e, subsample=s, max_depth=d) else: name = 'gbm-' + str(cfg) models[name] = GradientBoostingClassifier(learning_rate=l, n_estimators=e, subsample=s, max_depth=d) print('定义了 %d 个模型' % len(models)) 返回 models |
默认情况下,该函数将使用XGBoost模型,但如果将函数参数use_xgb设置为False,则可以使用sklearn的梯度提升模型。
同样,我们并不想在问题上最优地调整GBM,只是想快速找到配置空间中可能值得进一步研究的区域。
这个函数可以直接用于分类和回归问题,只需将“XGBClassifier”更改为“XGBRegressor”以及“GradientBoostingClassifier”更改为“GradientBoostingRegressor”即可。例如:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 定义梯度提升模型 def get_gbm_models(models=dict(), use_xgb=True): # 定义配置范围 rates = [0.001, 0.01, 0.1] trees = [50, 100] ss = [0.5, 0.7, 1.0] depth = [3, 7, 9] # 添加配置 for l in rates: for e in trees: for s in ss: for d in depth: cfg = [l, e, s, d] if use_xgb: name = 'xgb-' + str(cfg) models[name] = XGBRegressor(learning_rate=l, n_estimators=e, subsample=s, max_depth=d) else: name = 'gbm-' + str(cfg) models[name] = GradientBoostingXGBRegressor(learning_rate=l, n_estimators=e, subsample=s, max_depth=d) print('定义了 %d 个模型' % len(models)) 返回 models |
为了具体说明,以下是更新为也定义XGBoost模型的二元分类示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 |
# 二元分类抽样检查脚本 import warnings from numpy import mean from numpy import std from matplotlib import pyplot from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.preprocessing import StandardScaler 从 sklearn.预处理 导入 MinMaxScaler from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression from sklearn.linear_model import RidgeClassifier from sklearn.linear_model import SGDClassifier from sklearn.linear_model import PassiveAggressiveClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.tree import ExtraTreeClassifier from sklearn.svm import SVC from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import AdaBoostClassifier from sklearn.ensemble import BaggingClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import ExtraTreesClassifier from sklearn.ensemble import GradientBoostingClassifier from xgboost import XGBClassifier # 加载数据集,返回X和y元素 def load_dataset(): return make_classification(n_samples=1000, n_classes=2, random_state=1) # 创建一个用于评估的标准模型字典 {名称:对象} def define_models(models=dict()): # 线性模型 models['logistic'] = LogisticRegression() alpha = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for a in alpha: models['ridge-'+str(a)] = RidgeClassifier(alpha=a) models['sgd'] = SGDClassifier(max_iter=1000, tol=1e-3) models['pa'] = PassiveAggressiveClassifier(max_iter=1000, tol=1e-3) # 非线性模型 n_neighbors = range(1, 21) for k in n_neighbors: models['knn-'+str(k)] = KNeighborsClassifier(n_neighbors=k) models['cart'] = DecisionTreeClassifier() models['extra'] = ExtraTreeClassifier() models['svml'] = SVC(kernel='linear') models['svmp'] = SVC(kernel='poly') c_values = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for c in c_values: models['svmr'+str(c)] = SVC(C=c) models['bayes'] = GaussianNB() # 集成模型 n_trees = 100 models['ada'] = AdaBoostClassifier(n_estimators=n_trees) models['bag'] = BaggingClassifier(n_estimators=n_trees) models['rf'] = RandomForestClassifier(n_estimators=n_trees) models['et'] = ExtraTreesClassifier(n_estimators=n_trees) models['gbm'] = GradientBoostingClassifier(n_estimators=n_trees) print('定义了 %d 个模型' % len(models)) 返回 模型 # 定义梯度提升模型 def define_gbm_models(models=dict(), use_xgb=True): # 定义配置范围 rates = [0.001, 0.01, 0.1] trees = [50, 100] ss = [0.5, 0.7, 1.0] depth = [3, 7, 9] # 添加配置 for l in rates: for e in trees: for s in ss: for d in depth: cfg = [l, e, s, d] if use_xgb: name = 'xgb-' + str(cfg) models[name] = XGBClassifier(learning_rate=l, n_estimators=e, subsample=s, max_depth=d) else: name = 'gbm-' + str(cfg) models[name] = GradientBoostingClassifier(learning_rate=l, n_estimators=e, subsample=s, max_depth=d) print('定义了 %d 个模型' % len(models)) 返回 模型 # 为模型创建特征准备流水线 def make_pipeline(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline # 评估单个模型 def evaluate_model(X, y, model, folds, metric): # 创建流水线 pipeline = make_pipeline(model) # 评估模型 scores = cross_val_score(pipeline, X, y, scoring=metric, cv=folds, n_jobs=-1) 返回 分数 # 评估一个模型并尝试捕获错误并隐藏警告 def robust_evaluate_model(X, y, model, folds, metric): scores = None try: with warnings.catch_warnings(): warnings.filterwarnings("ignore") scores = evaluate_model(X, y, model, folds, metric) except: scores = None return scores # 评估一个模型字典 {名称:对象},返回 {名称:分数} def evaluate_models(X, y, models, folds=10, metric='accuracy'): results = dict() for name, model in models.items(): # 评估模型 scores = robust_evaluate_model(X, y, model, folds, metric) # 显示进度 if scores is not None: # 存储一个结果 results[name] = scores mean_score, std_score = mean(scores), std(scores) print('>%s: %.3f (+/-%.3f)' % (name, mean_score, std_score)) else: print('>%s: error' % name) return results # 打印并绘制前n个结果 def summarize_results(results, maximize=True, top_n=10): # 检查是否无结果 if len(results) == 0: print('无结果') return # 确定要汇总的结果数量 n = min(top_n, len(results)) # 创建一个 (名称, 平均分(分数)) 元组列表 mean_scores = [(k,mean(v)) for k,v in results.items()] # 按平均分对元组进行排序 mean_scores = sorted(mean_scores, key=lambda x: x[1]) # 反转为降序(例如,用于准确性) if maximize: mean_scores = list(reversed(mean_scores)) # 检索前n个用于汇总 names = [x[0] for x in mean_scores[:n]] scores = [results[x[0]] for x in mean_scores[:n]] # 打印前n个 print() for i in range(n): name = names[i] mean_score, std_score = mean(results[name]), std(results[name]) print('Rank=%d, Name=%s, Score=%.3f (+/- %.3f)' % (i+1, name, mean_score, std_score)) # 前n个的箱形图 pyplot.boxplot(scores, labels=names) _, labels = pyplot.xticks() pyplot.setp(labels, rotation=90) pyplot.savefig('spotcheck.png') # 加载数据集 X, y = load_dataset() # 获取模型列表 models = define_models() # 添加gbm模型 models = define_gbm_models(models) # 评估模型 results = evaluate_models(X, y, models) # 总结结果 summarize_results(results) |
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行示例表明,确实一些XGBoost模型在此问题上表现良好。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... >xgb-[0.1, 100, 1.0, 3]: 0.864 (+/-0.044) >xgb-[0.1, 100, 1.0, 7]: 0.865 (+/-0.036) >xgb-[0.1, 100, 1.0, 9]: 0.867 (+/-0.039) 排名=1, 名称=xgb-[0.1, 50, 1.0, 3], 分数=0.872 (+/- 0.039) 排名=2, 名称=et, 分数=0.869 (+/- 0.033) 排名=3, 名称=xgb-[0.1, 50, 1.0, 9], 分数=0.868 (+/- 0.038) 排名=4, 名称=xgb-[0.1, 100, 1.0, 9], 分数=0.867 (+/- 0.039) 排名=5, 名称=xgb-[0.01, 50, 1.0, 3], 分数=0.867 (+/- 0.035) 排名=6, 名称=xgb-[0.1, 50, 1.0, 7], 分数=0.867 (+/- 0.037) 排名=7, 名称=xgb-[0.001, 100, 0.7, 9], 分数=0.866 (+/- 0.040) 排名=8, 名称=xgb-[0.01, 100, 1.0, 3], 分数=0.866 (+/- 0.037) 排名=9, 名称=xgb-[0.001, 100, 0.7, 3], 分数=0.866 (+/- 0.034) 排名=10, 名称=xgb-[0.01, 50, 0.7, 3], 分数=0.866 (+/- 0.034) |
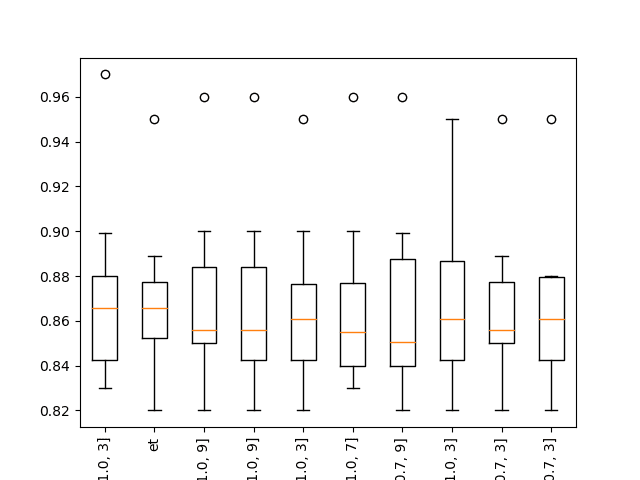
带有XGBoost的分类问题上前10种抽样检查算法的箱线图
重复评估
以上结果也突显了评估的噪声性质,例如,本轮的极端树(extra trees)结果与上一轮不同(0.858 vs 0.869)。
我们使用 k 折交叉验证来产生一组分数,但这个样本量很小,计算出的平均值会很嘈杂。
只要我们将抽样检查的结果视为一个起点,而不是算法在问题上的确定性结果,这样是可以的。这很难做到;它需要从业者具备纪律性。
或者,您可能希望调整框架,使模型评估方案更符合您打算为特定问题使用的模型评估方案。
例如,在评估随机算法(如装袋或提升决策树)时,最好在相同的训练/测试集上多次运行每个实验(称为重复),以便考虑到学习算法的随机性质。
我们可以更新 `evaluate_model()` 函数,让其多次重复评估给定模型,每次使用不同的数据分割,然后返回所有分数。例如,对 10 折交叉验证进行 3 次重复,将从每次获得 30 个分数,以计算模型的平均性能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 评估单个模型 def evaluate_model(X, y, model, folds, repeats, metric): # 创建流水线 pipeline = make_pipeline(model) # 评估模型 scores = list() # 重复模型评估 n 次 for _ in range(repeats): # 执行运行 scores_r = cross_val_score(pipeline, X, y, scoring=metric, cv=folds, n_jobs=-1) # 将分数添加到列表 scores += scores_r.tolist() return scores |
或者,您可能更喜欢计算每次 k 折交叉验证运行的平均分数,然后计算所有运行的总体平均值,如中所述。
然后,我们可以更新 `robust_evaluate_model()` 函数以传递 repeats 参数,并更新 `evaluate_models()` 函数以定义默认值,例如 3。
下面列出了具有三次模型评估重复的二分类示例的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 |
# 二元分类抽样检查脚本 import warnings from numpy import mean from numpy import std from matplotlib import pyplot from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.preprocessing import StandardScaler 从 sklearn.预处理 导入 MinMaxScaler from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression from sklearn.linear_model import RidgeClassifier from sklearn.linear_model import SGDClassifier from sklearn.linear_model import PassiveAggressiveClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.tree import ExtraTreeClassifier from sklearn.svm import SVC from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import AdaBoostClassifier from sklearn.ensemble import BaggingClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import ExtraTreesClassifier from sklearn.ensemble import GradientBoostingClassifier # 加载数据集,返回X和y元素 def load_dataset(): return make_classification(n_samples=1000, n_classes=2, random_state=1) # 创建一个用于评估的标准模型字典 {名称:对象} def define_models(models=dict()): # 线性模型 models['logistic'] = LogisticRegression() alpha = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for a in alpha: models['ridge-'+str(a)] = RidgeClassifier(alpha=a) models['sgd'] = SGDClassifier(max_iter=1000, tol=1e-3) models['pa'] = PassiveAggressiveClassifier(max_iter=1000, tol=1e-3) # 非线性模型 n_neighbors = range(1, 21) for k in n_neighbors: models['knn-'+str(k)] = KNeighborsClassifier(n_neighbors=k) models['cart'] = DecisionTreeClassifier() models['extra'] = ExtraTreeClassifier() models['svml'] = SVC(kernel='linear') models['svmp'] = SVC(kernel='poly') c_values = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for c in c_values: models['svmr'+str(c)] = SVC(C=c) models['bayes'] = GaussianNB() # 集成模型 n_trees = 100 models['ada'] = AdaBoostClassifier(n_estimators=n_trees) models['bag'] = BaggingClassifier(n_estimators=n_trees) models['rf'] = RandomForestClassifier(n_estimators=n_trees) models['et'] = ExtraTreesClassifier(n_estimators=n_trees) models['gbm'] = GradientBoostingClassifier(n_estimators=n_trees) print('定义了 %d 个模型' % len(models)) 返回 模型 # 为模型创建特征准备流水线 def make_pipeline(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline # 评估单个模型 def evaluate_model(X, y, model, folds, repeats, metric): # 创建流水线 pipeline = make_pipeline(model) # 评估模型 scores = list() # 重复模型评估 n 次 for _ in range(repeats): # 执行运行 scores_r = cross_val_score(pipeline, X, y, scoring=metric, cv=folds, n_jobs=-1) # 将分数添加到列表 scores += scores_r.tolist() 返回 分数 # 评估模型并尝试捕获错误和隐藏警告 def robust_evaluate_model(X, y, model, folds, repeats, metric): scores = None try: with warnings.catch_warnings(): warnings.filterwarnings("ignore") scores = evaluate_model(X, y, model, folds, repeats, metric) except: scores = None return scores # 评估一个模型字典 {名称:对象},返回 {名称:分数} def evaluate_models(X, y, models, folds=10, repeats=3, metric='accuracy'): results = dict() for name, model in models.items(): # 评估模型 scores = robust_evaluate_model(X, y, model, folds, repeats, metric) # 显示进度 if scores is not None: # 存储一个结果 results[name] = scores mean_score, std_score = mean(scores), std(scores) print('>%s: %.3f (+/-%.3f)' % (name, mean_score, std_score)) else: print('>%s: error' % name) return results # 打印并绘制前n个结果 def summarize_results(results, maximize=True, top_n=10): # 检查是否无结果 if len(results) == 0: print('无结果') return # 确定要汇总的结果数量 n = min(top_n, len(results)) # 创建一个 (名称, 平均分(分数)) 元组列表 mean_scores = [(k,mean(v)) for k,v in results.items()] # 按平均分对元组进行排序 mean_scores = sorted(mean_scores, key=lambda x: x[1]) # 反转为降序(例如,用于准确性) if maximize: mean_scores = list(reversed(mean_scores)) # 检索前n个用于汇总 names = [x[0] for x in mean_scores[:n]] scores = [results[x[0]] for x in mean_scores[:n]] # 打印前n个 print() for i in range(n): name = names[i] mean_score, std_score = mean(results[name]), std(results[name]) print('Rank=%d, Name=%s, Score=%.3f (+/- %.3f)' % (i+1, name, mean_score, std_score)) # 前n个的箱形图 pyplot.boxplot(scores, labels=names) _, labels = pyplot.xticks() pyplot.setp(labels, rotation=90) pyplot.savefig('spotcheck.png') # 加载数据集 X, y = load_dataset() # 获取模型列表 models = define_models() # 评估模型 results = evaluate_models(X, y, models) # 总结结果 summarize_results(results) |
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行示例可获得更稳健的分数估计。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
... >bag: 0.861 (+/-0.037) >rf: 0.859 (+/-0.036) >et: 0.869 (+/-0.035) >gbm: 0.867 (+/-0.044) 排名=1, 名称=et, 分数=0.869 (+/- 0.035) 排名=2, 名称=gbm, 分数=0.867 (+/- 0.044) 排名=3, 名称=bag, 分数=0.861 (+/- 0.037) 排名=4, 名称=rf, 分数=0.859 (+/- 0.036) 排名=5, 名称=ada, 分数=0.850 (+/- 0.035) 排名=6, 名称=ridge-0.9, 分数=0.848 (+/- 0.038) 排名=7, 名称=ridge-0.8, 分数=0.848 (+/- 0.038) 排名=8, 名称=ridge-0.7, 分数=0.848 (+/- 0.038) 排名=9, 名称=ridge-0.6, 分数=0.848 (+/- 0.038) 排名=10, 名称=ridge-0.5, 分数=0.848 (+/- 0.038) |
报告的平均值仍会有一些方差,但比单次 k 折交叉验证的方差要小。
可以增加重复次数以进一步减小此方差,但这会增加运行时间,而且可能违背抽样检查的初衷。
不同的输入表示
我非常赞同在拟合模型之前避免对数据表示做假设和推荐。
相反,我也喜欢抽样检查输入数据的多种表示和变换,我称之为视图。我将在帖子中对此进行更详细的解释。
我们可以更新框架以抽样检查每种模型的多种不同表示。
一种方法是更新 `evaluate_models()` 函数,以便我们可以为每种定义的模型提供一个 `make_pipeline()` 函数列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 评估一个模型字典 {名称:对象},返回 {名称:分数} def evaluate_models(X, y, models, pipe_funcs, folds=10, metric='accuracy'): results = dict() for name, model in models.items(): # 在每个准备函数下评估模型 for i in range(len(pipe_funcs)): # 评估模型 scores = robust_evaluate_model(X, y, model, folds, metric, pipe_funcs[i]) # 更新名称 run_name = str(i) + name # 显示进度 if scores is not None: # 存储一个结果 results[run_name] = scores mean_score, std_score = mean(scores), std(scores) print('>%s: %.3f (+/-%.3f)' % (run_name, mean_score, std_score)) else: print('>%s: error' % run_name) return results |
然后可以将选择的管道函数传递给 `robust_evaluate_model()` 函数和 `evaluate_model()` 函数,以便使用。
然后,我们可以定义一堆不同的管道函数;例如
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# 无转换管道 def pipeline_none(model): return model # 标准化转换管道 def pipeline_standardize(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline # 归一化转换管道 def pipeline_normalize(model): steps = list() # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline # 标准化和归一化管道 def pipeline_std_norm(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline |
然后创建一个包含这些函数名的列表,可以提供给 `evaluate_models()` 函数。
|
1 2 |
# 定义转换管道 pipelines = [pipeline_none, pipeline_standardize, pipeline_normalize, pipeline_std_norm] |
下面列出了已更新为抽样检查管道转换的分类案例的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 |
# 二元分类抽样检查脚本 import warnings from numpy import mean from numpy import std from matplotlib import pyplot from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.preprocessing import StandardScaler 从 sklearn.预处理 导入 MinMaxScaler from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression from sklearn.linear_model import RidgeClassifier from sklearn.linear_model import SGDClassifier from sklearn.linear_model import PassiveAggressiveClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.tree import ExtraTreeClassifier from sklearn.svm import SVC from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import AdaBoostClassifier from sklearn.ensemble import BaggingClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import ExtraTreesClassifier from sklearn.ensemble import GradientBoostingClassifier # 加载数据集,返回X和y元素 def load_dataset(): return make_classification(n_samples=1000, n_classes=2, random_state=1) # 创建一个用于评估的标准模型字典 {名称:对象} def define_models(models=dict()): # 线性模型 models['logistic'] = LogisticRegression() alpha = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for a in alpha: models['ridge-'+str(a)] = RidgeClassifier(alpha=a) models['sgd'] = SGDClassifier(max_iter=1000, tol=1e-3) models['pa'] = PassiveAggressiveClassifier(max_iter=1000, tol=1e-3) # 非线性模型 n_neighbors = range(1, 21) for k in n_neighbors: models['knn-'+str(k)] = KNeighborsClassifier(n_neighbors=k) models['cart'] = DecisionTreeClassifier() models['extra'] = ExtraTreeClassifier() models['svml'] = SVC(kernel='linear') models['svmp'] = SVC(kernel='poly') c_values = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] for c in c_values: models['svmr'+str(c)] = SVC(C=c) models['bayes'] = GaussianNB() # 集成模型 n_trees = 100 models['ada'] = AdaBoostClassifier(n_estimators=n_trees) models['bag'] = BaggingClassifier(n_estimators=n_trees) models['rf'] = RandomForestClassifier(n_estimators=n_trees) models['et'] = ExtraTreesClassifier(n_estimators=n_trees) models['gbm'] = GradientBoostingClassifier(n_estimators=n_trees) print('定义了 %d 个模型' % len(models)) 返回 模型 # 无转换管道 def pipeline_none(model): return model # 标准化转换管道 def pipeline_standardize(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline # 归一化转换管道 def pipeline_normalize(model): steps = list() # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline # 标准化和归一化管道 def pipeline_std_norm(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline # 评估单个模型 def evaluate_model(X, y, model, folds, metric, pipe_func): # 创建流水线 pipeline = pipe_func(model) # 评估模型 scores = cross_val_score(pipeline, X, y, scoring=metric, cv=folds, n_jobs=-1) 返回 分数 # 评估一个模型并尝试捕获错误并隐藏警告 def robust_evaluate_model(X, y, model, folds, metric, pipe_func): scores = None try: with warnings.catch_warnings(): warnings.filterwarnings("ignore") scores = evaluate_model(X, y, model, folds, metric, pipe_func) except: scores = None return scores # 评估一个模型字典 {名称:对象},返回 {名称:分数} def evaluate_models(X, y, models, pipe_funcs, folds=10, metric='accuracy'): results = dict() for name, model in models.items(): # 在每个准备函数下评估模型 for i in range(len(pipe_funcs)): # 评估模型 scores = robust_evaluate_model(X, y, model, folds, metric, pipe_funcs[i]) # 更新名称 run_name = str(i) + name # 显示进度 if scores is not None: # 存储一个结果 results[run_name] = scores mean_score, std_score = mean(scores), std(scores) print('>%s: %.3f (+/-%.3f)' % (run_name, mean_score, std_score)) else: print('>%s: error' % run_name) return results # 打印并绘制前n个结果 def summarize_results(results, maximize=True, top_n=10): # 检查是否无结果 if len(results) == 0: print('无结果') return # 确定要汇总的结果数量 n = min(top_n, len(results)) # 创建一个 (名称, 平均分(分数)) 元组列表 mean_scores = [(k,mean(v)) for k,v in results.items()] # 按平均分对元组进行排序 mean_scores = sorted(mean_scores, key=lambda x: x[1]) # 反转为降序(例如,用于准确性) if maximize: mean_scores = list(reversed(mean_scores)) # 检索前n个用于汇总 names = [x[0] for x in mean_scores[:n]] scores = [results[x[0]] for x in mean_scores[:n]] # 打印前n个 print() for i in range(n): name = names[i] mean_score, std_score = mean(results[name]), std(results[name]) print('Rank=%d, Name=%s, Score=%.3f (+/- %.3f)' % (i+1, name, mean_score, std_score)) # 前n个的箱形图 pyplot.boxplot(scores, labels=names) _, labels = pyplot.xticks() pyplot.setp(labels, rotation=90) pyplot.savefig('spotcheck.png') # 加载数据集 X, y = load_dataset() # 获取模型列表 models = define_models() # 定义转换管道 pipelines = [pipeline_none, pipeline_standardize, pipeline_normalize, pipeline_std_norm] # 评估模型 results = evaluate_models(X, y, models, pipelines) # 总结结果 summarize_results(results) |
运行示例显示,我们通过在算法描述名称的开头添加管道编号来区分每种管道的结果,例如“0rf”表示使用第一个管道(无转换)的 RF。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
集成树算法在此问题上表现良好,并且这些算法对数据缩放是不变的。这意味着它们在每个管道上的结果将相似(或相同),从而它们将在排名前十的列表中挤掉其他算法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
... >0gbm: 0.865 (+/-0.044) >1gbm: 0.865 (+/-0.044) >2gbm: 0.865 (+/-0.044) >3gbm: 0.865 (+/-0.044) 排名=1, 名称=3rf, 分数=0.870 (+/- 0.034) 排名=2, 名称=2rf, 分数=0.870 (+/- 0.034) 排名=3, 名称=1rf, 分数=0.870 (+/- 0.034) 排名=4, 名称=0rf, 分数=0.870 (+/- 0.034) 排名=5, 名称=3bag, 分数=0.866 (+/- 0.039) 排名=6, 名称=2bag, 分数=0.866 (+/- 0.039) 排名=7, 名称=1bag, 分数=0.866 (+/- 0.039) 排名=8, 名称=0bag, 分数=0.866 (+/- 0.039) 排名=9, 名称=3gbm, 分数=0.865 (+/- 0.044) 排名=10, 名称=2gbm, 分数=0.865 (+/- 0.044) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
- 为什么你应该在机器学习问题上抽查算法
- 在 Python 中使用 scikit-learn 抽查分类机器学习算法
- 在 Python 中使用 scikit-learn 抽查回归机器学习算法
- 如何评估深度学习模型的技能
- 为什么应用机器学习很难
- 将应用机器学习作为一个搜索问题的简明介绍
- 如何充分利用你的机器学习数据
总结
在本教程中,您发现了抽样检查算法在新的预测建模问题中的有用性,以及如何在 Python 中开发一个用于抽样检查分类和回归问题的算法的标准框架。
具体来说,你学到了:
- 抽查提供了一种快速发现哪些算法在您的预测建模问题上表现良好的方法。
- 如何开发一个通用的框架来加载数据、定义模型、评估模型和汇总结果。
- 如何将该框架应用于分类和回归问题。
您是否使用过这个框架,或者您是否有进一步的改进建议?
请在评论中告诉我。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。



")


嗨,Jason,
您是否尝试过使用 autoKeras & Auto-sklearn 包等 AutoML 工具?
(我还使用了 weka 包中的 AutoWeka – 非常有限,以及 Rapidminer Auto-Modelling)。
c
我通常不使用它们。你用过吗?
这在 R 中可能吗?
是的,使用 caret 包。
我甚至在博客上也有示例,搜索“spot check”。
这真的是网络上最好的 ML 资源之一。
谢谢,很高兴它有帮助。
你好先生,
关于抽样检查算法的精彩帖子。这确实是一个很棒的一站式服务!
我在这里有几个基本问题——
1) 如何将类似的方法与管道应用于不同的 Keras 模型 - 顺序模型、函数模型以及 KerasRegressor/KerasClassifier(带有层/dropout/优化器等)?
2) 在构建/应用管道之前,是否需要在 evaluate models 中重置状态/层?
3) 评估和确定模型后,是否需要重新构建模型、编译、拟合来预测测试数据集,还是使用现有的已编译模型进行拟合和预测?由于不同的权重初始化,预测值/分数是否会在每次运行时有所不同?
期待您的回复。
神经网络可能对于这种类型的框架来说太大/太慢了,您可能需要手动进行网格搜索。
无论模型如何,您都应该为每次评估重新定义和重新拟合。
最终确定的模型会在所有可用数据上重新拟合。
先生,这是关于抽样检查算法的最好的文章,我对箱线图有一点疑问。
除了分数之外,您能否解释一下箱线图显示了哪些内容?
谢谢。
箱线图总结了每个算法分数的分布,并允许对分布进行简单比较。
好的,内容详实。
非常希望 Keras 或 TensorFlow 中的(不太深的)神经网络框架也能有类似的抽样检查。
谢谢。
好建议。
一如既往,精彩的帖子。
谢谢!
精彩的文章,先生!先生,请考虑创建一个包含您所有内容的 YouTube 频道!这将帮助数百万人。
感谢您的建议。
非常丰富完整的帖子 Jason!我希望有足够的时间来仔细阅读所有抽样检查算法的细节!谢谢。
无论如何,快速阅读时,我发现这个技巧对具有多个核心的硬件(我的情况就是如此)很有用。
“重要的是,n_jobs 参数设置为 -1,以便模型评估可以并行进行,利用您硬件上可用的所有核心”。
scores = cross_val_score(pipeline, X, y, scoring=metric, cv=folds, n_jobs=-1)
我也明白,这些抽样检查技术适用于模型拟合非常快的情况,因为如果不是这样(例如大数据集、训练、时期等或更复杂的模型),那么这个问题将是抽样检查无法解决的。
谢谢。
是的,对于大型数据集,使用小样本以确保过程及时是很有益的。
亲爱的 Jason,
我的问题是关于 MSE 或 neg_mean_squared_error 等指标的负值。
负结果该如何解释?
提前感谢您!
忽略符号,请看这里。
https://machinelearning.org.cn/faq/single-faq/why-are-some-scores-like-mse-negative-in-scikit-learn
你好 Jason,
根据您的经验,在实际示例中,抽样检查模型通常会导致分数较低(.55),然后我们是否需要通过应用机器学习技术,如特征选择、重要性等来将其提高到可接受的水平?您对此有什么看法?谢谢!
-John
好问题。
这真的取决于具体的数据集。有时我们可以立即获得良好的结果,有时我们需要努力工作,才能从数据中提取出良好的表示。
精彩的文章!谢谢 Jason!!!
谢谢!
谢谢,一如既往的非常有用和适用的教程。
如果我们想应用 PCA,它是否应该放在以下代码之后?
# 归一化
steps.append((‘normalize’, MinMaxScaler()))
提前感谢
使用缩放后的数据(例如,在 MinMaxScaler 或 StandardScaler 之后)使用 PCA 是一个好主意。
Hi Jason, 感谢这篇精彩的文章。
我只想指出 get_gb_models 函数在回归时存在一个错字,您写的是 GradientBoostingXGBRegressor 而不是 GradientBoostingRegressor。
既然我在这里,在 define_models 中,您将一个空字典作为默认变量传递。
def define_models(models=dict())
# …
return models
这并不是一个大问题,除非您调用该函数一次以上。从第二次开始,默认值将是第一次调用后 models 的值,而不是一个空字典。尝试运行这个:
def asd(d=dict())
print(d)
d[1] = 1
return d
感谢 Edo 的反馈!