堆叠(Stacking)或堆叠泛化(Stacked Generalization)是一种集成机器学习算法。
它使用元学习算法来学习如何最好地结合两个或多个基础机器学习算法的预测。
堆叠的优点是,它可以在分类或回归任务中利用一系列表现良好的模型的能力,并做出比集成中任何单个模型性能更好的预测。
在本教程中,您将学习 Python 中的堆叠泛化集成或堆叠。
完成本教程后,您将了解:
- 堆叠是一种集成机器学习算法,它学习如何最好地结合来自多个表现良好的机器学习模型的预测。
- scikit-learn 库在 Python 中提供了堆叠集成的标准实现。
- 如何将堆叠集成用于回归和分类预测建模。
通过我的新书《Python 集成学习算法》启动您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2020 年 8 月更新:改进了代码示例,添加了更多参考资料。

使用 Python 的堆叠集成机器学习
照片由 lamoix 提供,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 堆叠泛化
- Scikit-Learn API 中的堆叠
- 用于分类的堆叠
- 用于回归的堆叠
堆叠泛化
堆叠泛化,简称“堆叠”,是一种集成机器学习算法。
它涉及结合来自同一数据集的多个机器学习模型的预测,类似于装袋和提升。
堆叠解决了这个问题:
- 给定多个在问题上表现出色但方式不同的机器学习模型,您如何选择使用(信任)哪个模型?
解决这个问题的办法是使用另一个机器学习模型,该模型学习何时使用或信任集成中的每个模型。
- 与装袋不同,在堆叠中,模型通常是不同的(例如,不都是决策树),并且在同一数据集上进行拟合(例如,而不是训练数据集的样本)。
- 与提升不同,在堆叠中,使用单个模型来学习如何最好地组合来自贡献模型的预测(例如,而不是一系列模型来纠正先前模型的预测)。
堆叠模型的架构包括两个或更多个基础模型(通常称为 level-0 模型)和一个组合基础模型预测的元模型(称为 level-1 模型)。
- Level-0 模型(基础模型):在训练数据上拟合的模型,其预测被编译。
- Level-1 模型(元模型):学习如何最好地组合基础模型预测的模型。
元模型在基础模型对样本外数据(即未用于训练基础模型的数据)所做的预测上进行训练。将样本外数据输入到基础模型中,进行预测,然后这些预测与预期输出一起,为用于拟合元模型的训练数据集提供输入和输出对。
在回归情况下,用作元模型输入的基模型的输出可以是实数值;在分类情况下,可以是概率值、类似概率的值或类别标签。
为元模型准备训练数据集最常用的方法是通过基模型的 k 折交叉验证,其中 折外预测 用作元模型训练数据集的基础。
元模型的训练数据还可以包括基础模型的输入,例如训练数据的输入元素。这可以为元模型提供额外的上下文,以便更好地组合来自元模型的预测。
一旦为元模型准备好训练数据集,元模型就可以在这个数据集上独立训练,而基础模型则可以在整个原始训练数据集上进行训练。
当多个不同的机器学习模型在数据集上表现出色,但方式不同时,堆叠是合适的。另一种说法是,模型所做的预测或模型预测中的误差不相关或相关性较低。
基础模型通常复杂多样。因此,通常最好使用一系列对如何解决预测建模任务做出截然不同假设的模型,例如线性模型、决策树、支持向量机、神经网络等。其他集成算法也可以用作基础模型,例如随机森林。
- 基础模型:使用各种不同的模型,它们对预测任务做出不同的假设。
元模型通常很简单,提供对基础模型所做预测的平滑解释。因此,线性模型通常用作元模型,例如用于回归任务(预测数值)的线性回归和用于分类任务(预测类别标签)的逻辑回归。尽管这很常见,但并非必需。
- 回归元模型:线性回归。
- 分类元模型:逻辑回归。
将简单的线性模型用作元模型,通常使堆叠具有口语化的名称“混合”。这意味着预测是基础模型所做预测的加权平均或混合。
超级学习器可以被认为是堆叠的一种特殊类型。
堆叠旨在提高建模性能,尽管不能保证在所有情况下都能带来改进。
能否实现性能提升取决于问题的复杂性,以及它是否被训练数据充分表示,并且复杂到足以通过组合预测来学习更多东西。它还取决于基础模型的选择以及它们是否足够熟练并且它们的预测(或误差)是否足够不相关。
如果基础模型的性能与堆叠集成一样好或更好,则应使用基础模型,因为其复杂性较低(例如,描述、训练和维护更简单)。
想开始学习集成学习吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Scikit-Learn API 中的堆叠
堆叠可以从头开始实现,尽管这对于初学者来说可能具有挑战性。
有关在 Python 中从头开始实现堆叠的示例,请参阅教程
有关从头开始实现深度学习堆叠的示例,请参阅教程
scikit-learn Python 机器学习库提供了堆叠的实现。
它在库的 0.22 版本及更高版本中可用。
首先,通过运行以下脚本确认您正在使用该库的现代版本
|
1 2 3 |
# 检查 scikit-learn 版本 import sklearn print(sklearn.__version__) |
运行脚本将打印您的 scikit-learn 版本。
您的版本应该相同或更高。如果不是,您必须升级您的 scikit-learn 库版本。
|
1 |
0.22.1 |
堆叠通过 StackingRegressor 和 StackingClassifier 类提供。
这两个模型的操作方式相同,并接受相同的参数。使用该模型需要您指定一个估计器列表(level-0 模型)和一个最终估计器(level-1 或元模型)。
level-0 模型或基础模型的列表通过“estimators”参数提供。这是一个 Python 列表,其中列表中的每个元素都是一个元组,包含模型的名称和已配置的模型实例。
例如,下面定义了两个 level-0 模型
|
1 2 3 |
... models = [('lr',LogisticRegression()),('svm',SVC()) stacking = StackingClassifier(estimators=models) |
列表中的每个模型也可以是 Pipeline,包括在训练数据集上拟合模型之前所需的任何数据准备。例如
|
1 2 3 |
... models = [('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC())) stacking = StackingClassifier(estimators=models) |
level-1 模型或元模型通过“final_estimator”参数提供。默认情况下,回归任务设置为 LinearRegression,分类任务设置为 LogisticRegression,这些都是合理的默认值,您可能不想更改。
元模型的数据集是使用交叉验证准备的。默认情况下,使用 5 折交叉验证,但可以通过“cv”参数更改,并设置为数字(例如,10 表示 10 折交叉验证)或交叉验证对象(例如,StratifiedKFold)。
有时,如果为元模型准备的数据集也包含 level-0 模型的输入(例如,输入训练数据),则可以实现更好的性能。这可以通过将“passthrough”参数设置为 True 来实现,默认情况下未启用。
现在我们熟悉了 scikit-learn 中的堆叠 API,接下来我们看一些实际示例。
用于分类的堆叠
在本节中,我们将介绍如何将堆叠用于分类问题。
首先,我们可以使用 make_classification() 函数 创建一个包含 1,000 个示例和 20 个输入特征的合成二元分类问题。
完整的示例如下所示。
|
1 2 3 4 5 6 |
# 测试分类数据集 from sklearn.datasets import make_classification # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1) # 汇总数据集 print(X.shape, y.shape) |
运行示例会创建数据集并总结输入和输出组件的形状。
|
1 |
(1000, 20) (1000,) |
接下来,我们可以在数据集上评估一系列不同的机器学习模型。
具体来说,我们将评估以下五种算法
- 逻辑回归。
- k-近邻。
- 决策树。
- 支持向量机。
- 朴素贝叶斯。
每种算法都将使用默认模型超参数进行评估。下面的 get_models() 函数创建我们希望评估的模型。
|
1 2 3 4 5 6 7 8 9 |
# 获取要评估的模型列表 定义 获取_模型(): models = dict() models['lr'] = LogisticRegression() models['knn'] = KNeighborsClassifier() models['cart'] = DecisionTreeClassifier() models['svm'] = SVC() models['bayes'] = GaussianNB() 返回 models |
每个模型都将使用重复的 k 折交叉验证进行评估。
下面的 evaluate_model() 函数接受一个模型实例,并返回三次重复分层 10 折交叉验证的分数列表。
|
1 2 3 4 5 |
# 使用交叉验证评估给定模型 def evaluate_model(model, X, y): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise') return scores |
然后我们可以报告每种算法的平均性能,并创建箱线图来比较每种算法的准确性分数分布。
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
# 比较二分类的独立模型 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.naive_bayes import GaussianNB from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() models['lr'] = LogisticRegression() models['knn'] = KNeighborsClassifier() models['cart'] = DecisionTreeClassifier() models['svm'] = SVC() models['bayes'] = GaussianNB() 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise') 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model, X, y) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例首先报告每个模型的平均准确度和标准差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的 结果可能会有所不同。考虑多次运行示例并比较平均结果。
我们可以看到,在这种情况下,SVM 表现最好,平均准确度约为 95.7%。
|
1 2 3 4 5 |
>lr 0.866 (0.029) >knn 0.931 (0.025) >cart 0.821 (0.050) >svm 0.957 (0.020) >bayes 0.833 (0.031) |
然后创建一个箱线图,比较每个模型的准确性分数分布,使我们能够清楚地看到 KNN 和 SVM 平均表现优于 LR、CART 和 Bayes。
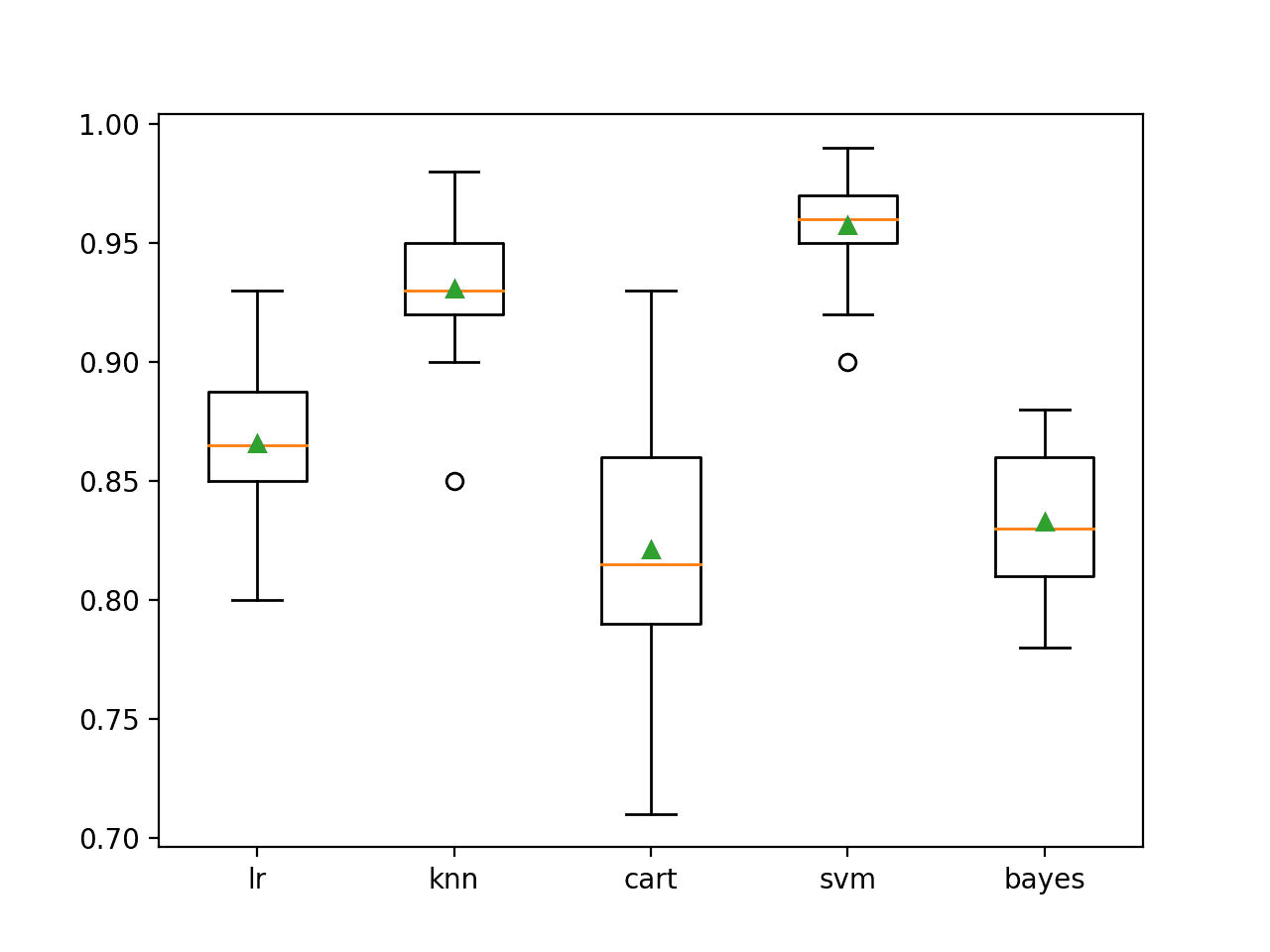
二分类独立模型准确性箱线图
这里有五种不同的算法,它们在这个数据集上表现良好,大概以不同的方式。
接下来,我们可以尝试使用堆叠将这五个模型组合成一个单一的集成模型。
我们可以使用逻辑回归模型来学习如何最好地组合来自这五个独立模型的预测。
下面的 get_stacking() 函数通过首先定义一个包含五个基础模型的元组列表,然后定义逻辑回归元模型,使用 5 折交叉验证来组合来自基础模型的预测,从而定义 StackingClassifier 模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 获取模型的堆叠集成 def get_stacking(): # 定义基础模型 level0 = list() level0.append(('lr', LogisticRegression())) level0.append(('knn', KNeighborsClassifier())) level0.append(('cart', DecisionTreeClassifier())) level0.append(('svm', SVC())) level0.append(('bayes', GaussianNB())) # 定义元学习器模型 level1 = LogisticRegression() # 定义堆叠集成 model = StackingClassifier(estimators=level0, final_estimator=level1, cv=5) return model |
我们可以将堆叠集成和独立模型一起包含在要评估的模型列表中。
|
1 2 3 4 5 6 7 8 9 10 |
# 获取要评估的模型列表 定义 获取_模型(): models = dict() models['lr'] = LogisticRegression() models['knn'] = KNeighborsClassifier() models['cart'] = DecisionTreeClassifier() models['svm'] = SVC() models['bayes'] = GaussianNB() models['stacking'] = get_stacking() 返回 models |
我们的预期是堆叠集成将比任何单个基础模型表现更好。
并非总是如此,如果不是这种情况,则应优先使用基础模型而不是集成模型。
评估堆叠集成模型和独立模型的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# 比较集成模型与每个基线分类器 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import StackingClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1) 返回 X, y # 获取模型的堆叠集成 def get_stacking(): # 定义基础模型 level0 = list() level0.append(('lr', LogisticRegression())) level0.append(('knn', KNeighborsClassifier())) level0.append(('cart', DecisionTreeClassifier())) level0.append(('svm', SVC())) level0.append(('bayes', GaussianNB())) # 定义元学习器模型 level1 = LogisticRegression() # 定义堆叠集成 model = StackingClassifier(estimators=level0, final_estimator=level1, cv=5) return model # 获取要评估的模型列表 定义 获取_模型(): models = dict() models['lr'] = LogisticRegression() models['knn'] = KNeighborsClassifier() models['cart'] = DecisionTreeClassifier() models['svm'] = SVC() models['bayes'] = GaussianNB() models['stacking'] = get_stacking() 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise') 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model, X, y) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例首先报告每个模型的性能。这包括每个基础模型的性能,然后是堆叠集成。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的 结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到堆叠集成平均表现优于任何单个模型,准确度约为 96.4%。
|
1 2 3 4 5 6 |
>lr 0.866 (0.029) >knn 0.931 (0.025) >cart 0.820 (0.044) >svm 0.957 (0.020) >bayes 0.833 (0.031) >stacking 0.964 (0.019) |
创建了一个箱线图,显示模型分类准确性的分布。
在这里,我们可以看到堆叠模型的平均准确度和中位数略高于 SVM 模型。
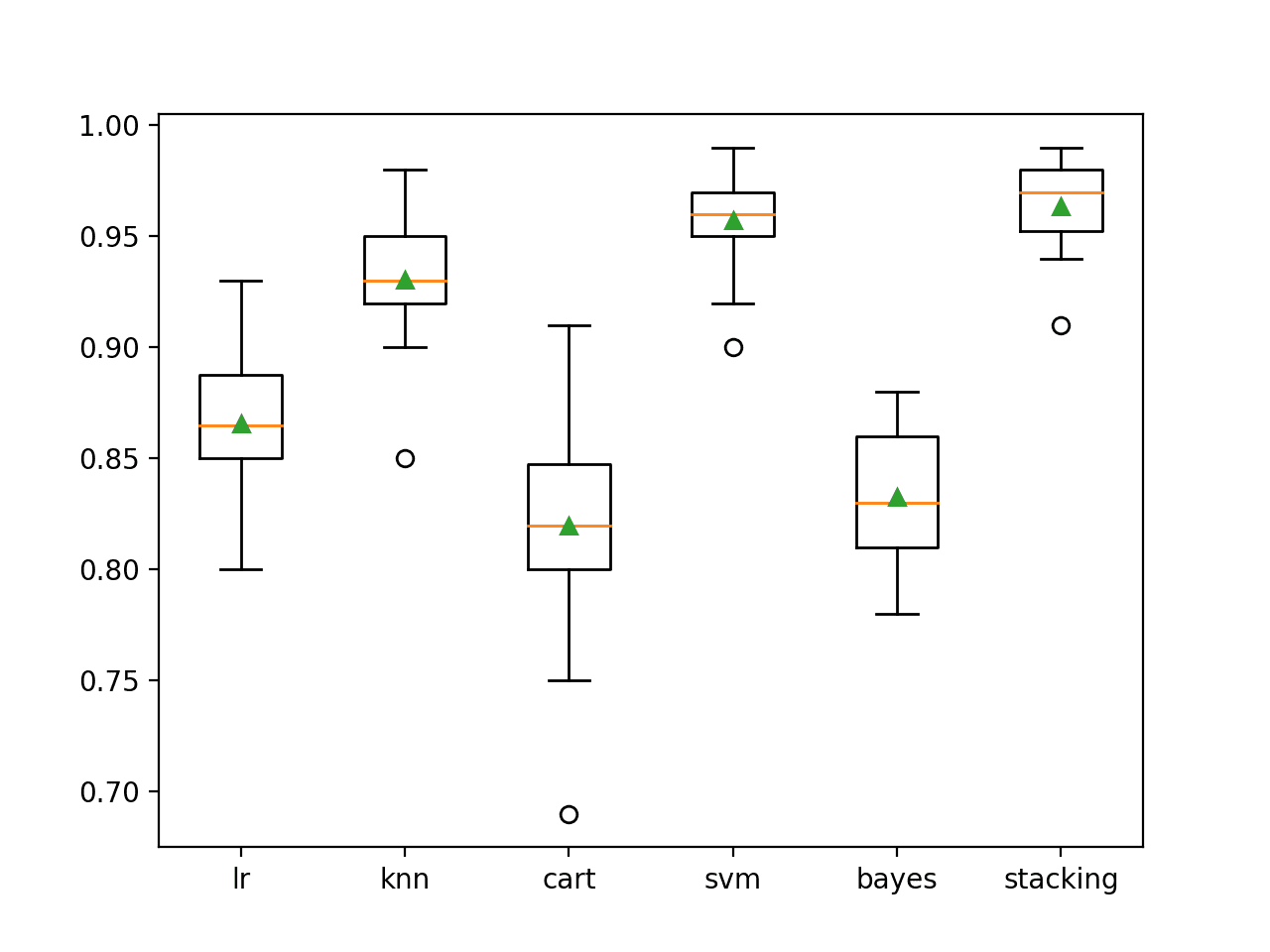
二分类独立模型和堆叠模型准确性箱线图
如果选择堆叠集成作为最终模型,我们可以像其他任何模型一样拟合并使用它来对新数据进行预测。
首先,在所有可用数据上拟合堆叠集成,然后可以调用 predict() 函数对新数据进行预测。
以下示例在我们的二元分类数据集上演示了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 使用堆叠集成进行预测 from sklearn.datasets import make_classification from sklearn.ensemble import StackingClassifier from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.naive_bayes import GaussianNB # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1) # 定义基础模型 level0 = list() level0.append(('lr', LogisticRegression())) level0.append(('knn', KNeighborsClassifier())) level0.append(('cart', DecisionTreeClassifier())) level0.append(('svm', SVC())) level0.append(('bayes', GaussianNB())) # 定义元学习器模型 level1 = LogisticRegression() # 定义堆叠集成 model = StackingClassifier(estimators=level0, final_estimator=level1, cv=5) # 在所有可用数据上拟合模型 model.fit(X, y) # 对一个示例进行预测 data = [[2.47475454,0.40165523,1.68081787,2.88940715,0.91704519,-3.07950644,4.39961206,0.72464273,-4.86563631,-6.06338084,-1.22209949,-0.4699618,1.01222748,-0.6899355,-0.53000581,6.86966784,-3.27211075,-6.59044146,-2.21290585,-3.139579]] yhat = model.predict(data) print('Predicted Class: %d' % (yhat)) |
运行示例在整个数据集上拟合堆叠集成模型,然后用于对新数据行进行预测,就像在应用程序中使用模型时一样。
|
1 |
预测类别:0 |
用于回归的堆叠
在本节中,我们将介绍如何将堆叠用于回归问题。
首先,我们可以使用 make_regression() 函数 创建一个包含 1,000 个示例和 20 个输入特征的合成回归问题。
完整的示例如下所示。
|
1 2 3 4 5 6 |
# 测试回归数据集 from sklearn.datasets import make_regression # 定义数据集 X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=1) # 汇总数据集 print(X.shape, y.shape) |
运行示例会创建数据集并总结输入和输出组件的形状。
|
1 |
(1000, 20) (1000,) |
接下来,我们可以在数据集上评估一系列不同的机器学习模型。
具体来说,我们将评估以下三种算法
- k-近邻。
- 决策树。
- 支持向量回归。
注意:测试数据集可以使用线性回归模型轻松解决,因为该数据集是在内部使用线性模型创建的。因此,我们将该模型排除在示例之外,以便演示堆叠集成方法的优势。
每种算法都将使用默认模型超参数进行评估。下面的 get_models() 函数创建我们希望评估的模型。
|
1 2 3 4 5 6 7 |
# 获取要评估的模型列表 定义 获取_模型(): models = dict() models['knn'] = KNeighborsRegressor() models['cart'] = DecisionTreeRegressor() models['svm'] = SVR() 返回 models |
每个模型都将使用重复的 k 折交叉验证进行评估。下面的 evaluate_model() 函数接受一个模型实例,并返回三次重复 10 折交叉验证的分数列表。
|
1 2 3 4 5 |
# 使用交叉验证评估给定模型 def evaluate_model(model, X, y): cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise') return scores |
然后我们可以报告每种算法的平均性能,并创建箱线图来比较每种算法的准确性分数分布。
在这种情况下,模型性能将使用平均绝对误差(MAE)报告。scikit-learn 库对该误差的符号进行了反转,使其最大化,从 -无穷大到 0 表示最佳分数。
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# 比较回归的机器学习模型 from numpy import mean from numpy import std from sklearn.datasets import make_regression from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedKFold 来自 sklearn.linear_model 导入 LinearRegression from sklearn.neighbors import KNeighborsRegressor 来自 sklearn.tree 导入 DecisionTreeRegressor 来自 sklearn.svm 导入 SVR from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=1) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() models['knn'] = KNeighborsRegressor() models['cart'] = DecisionTreeRegressor() models['svm'] = SVR() 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise') 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model, X, y) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例首先报告每个模型的平均和标准差 MAE。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的 结果可能会有所不同。考虑多次运行示例并比较平均结果。
我们可以看到,在这种情况下,KNN 表现最好,平均负 MAE 约为 -100。
|
1 2 3 |
>knn -101.019 (7.161) >cart -148.100 (11.039) >svm -162.419 (12.565) |
然后创建一个箱线图,比较每个模型的负 MAE 分布。
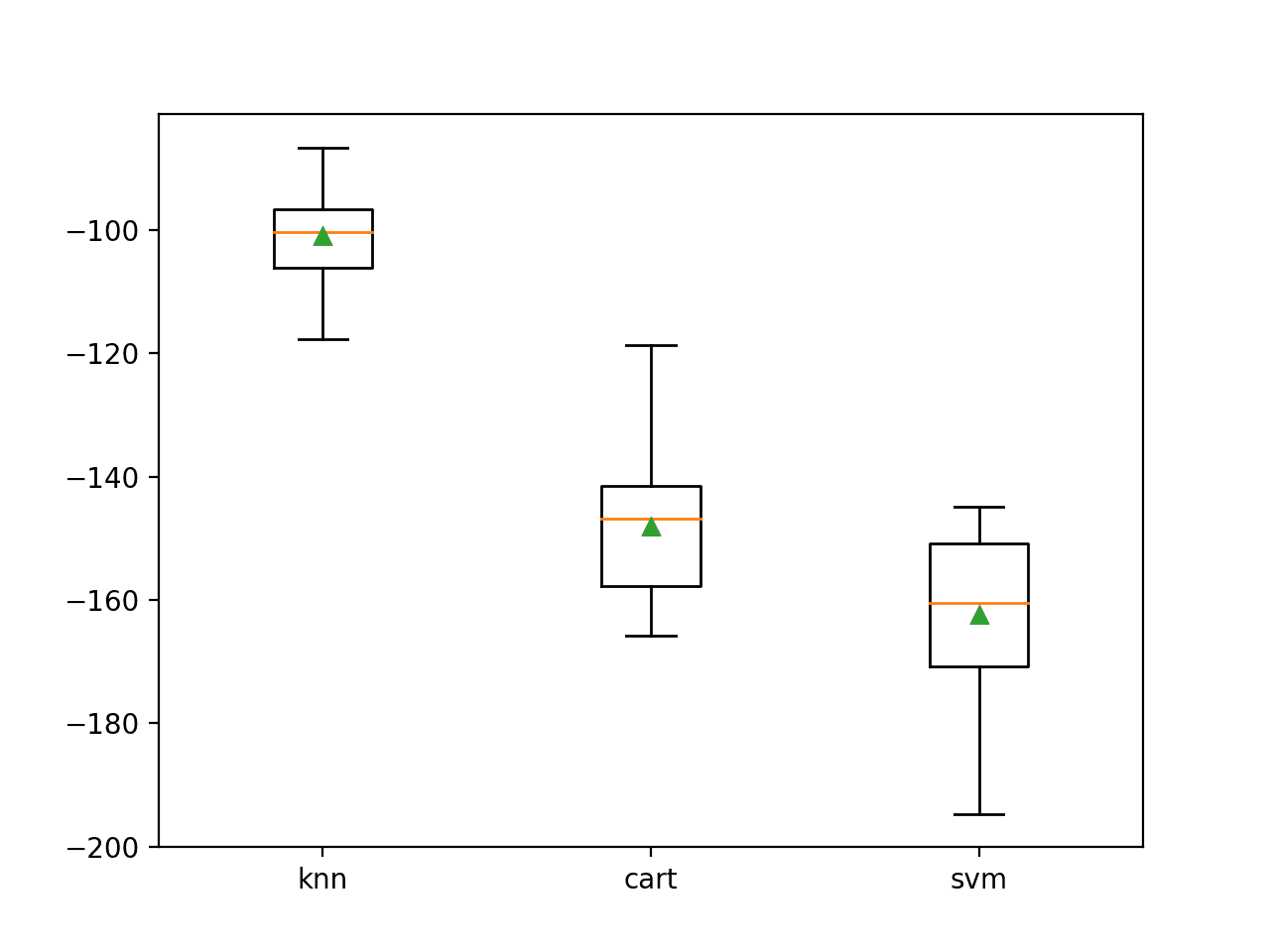
回归的独立模型负平均绝对误差箱线图
这里有三种不同的算法,它们在这个数据集上表现良好,大概以不同的方式。
接下来,我们可以尝试使用堆叠将这三个模型组合成一个单一的集成模型。
我们可以使用线性回归模型来学习如何最好地组合来自这三个独立模型的预测。
下面的 get_stacking() 函数通过首先定义一个包含三个基础模型的元组列表,然后定义线性回归元模型,使用 5 折交叉验证来组合来自基础模型的预测,从而定义 StackingRegressor 模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 获取模型的堆叠集成 def get_stacking(): # 定义基础模型 level0 = list() level0.append(('knn', KNeighborsRegressor())) level0.append(('cart', DecisionTreeRegressor())) level0.append(('svm', SVR())) # 定义元学习器模型 level1 = LinearRegression() # 定义堆叠集成 model = StackingRegressor(estimators=level0, final_estimator=level1, cv=5) return model |
我们可以将堆叠集成和独立模型一起包含在要评估的模型列表中。
|
1 2 3 4 5 6 7 8 |
# 获取要评估的模型列表 定义 获取_模型(): models = dict() models['knn'] = KNeighborsRegressor() models['cart'] = DecisionTreeRegressor() models['svm'] = SVR() models['stacking'] = get_stacking() 返回 models |
我们的预期是堆叠集成将比任何单个基础模型表现更好。
并非总是如此,如果不是这种情况,则应优先使用基础模型而不是集成模型。
评估堆叠集成模型和独立模型的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
# 比较回归的集成模型与每个独立模型 from numpy import mean from numpy import std from sklearn.datasets import make_regression from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedKFold 来自 sklearn.linear_model 导入 LinearRegression from sklearn.neighbors import KNeighborsRegressor 来自 sklearn.tree 导入 DecisionTreeRegressor 来自 sklearn.svm 导入 SVR from sklearn.ensemble import StackingRegressor from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=1) 返回 X, y # 获取模型的堆叠集成 def get_stacking(): # 定义基础模型 level0 = list() level0.append(('knn', KNeighborsRegressor())) level0.append(('cart', DecisionTreeRegressor())) level0.append(('svm', SVR())) # 定义元学习器模型 level1 = LinearRegression() # 定义堆叠集成 model = StackingRegressor(estimators=level0, final_estimator=level1, cv=5) return model # 获取要评估的模型列表 定义 获取_模型(): models = dict() models['knn'] = KNeighborsRegressor() models['cart'] = DecisionTreeRegressor() models['svm'] = SVR() models['stacking'] = get_stacking() 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise') 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model, X, y) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例首先报告每个模型的性能。这包括每个基础模型的性能,然后是堆叠集成。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的 结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到堆叠集成模型平均表现优于任何单个模型,平均负 MAE 约为 -56。
|
1 2 3 4 |
>knn -101.019 (7.161) >cart -148.017 (10.635) >svm -162.419 (12.565) >stacking -56.893 (5.253) |
创建了一个箱线图,显示模型误差分数的分布。在这里,我们可以看到堆叠模型的平均值和中位数分数远高于任何单个模型。
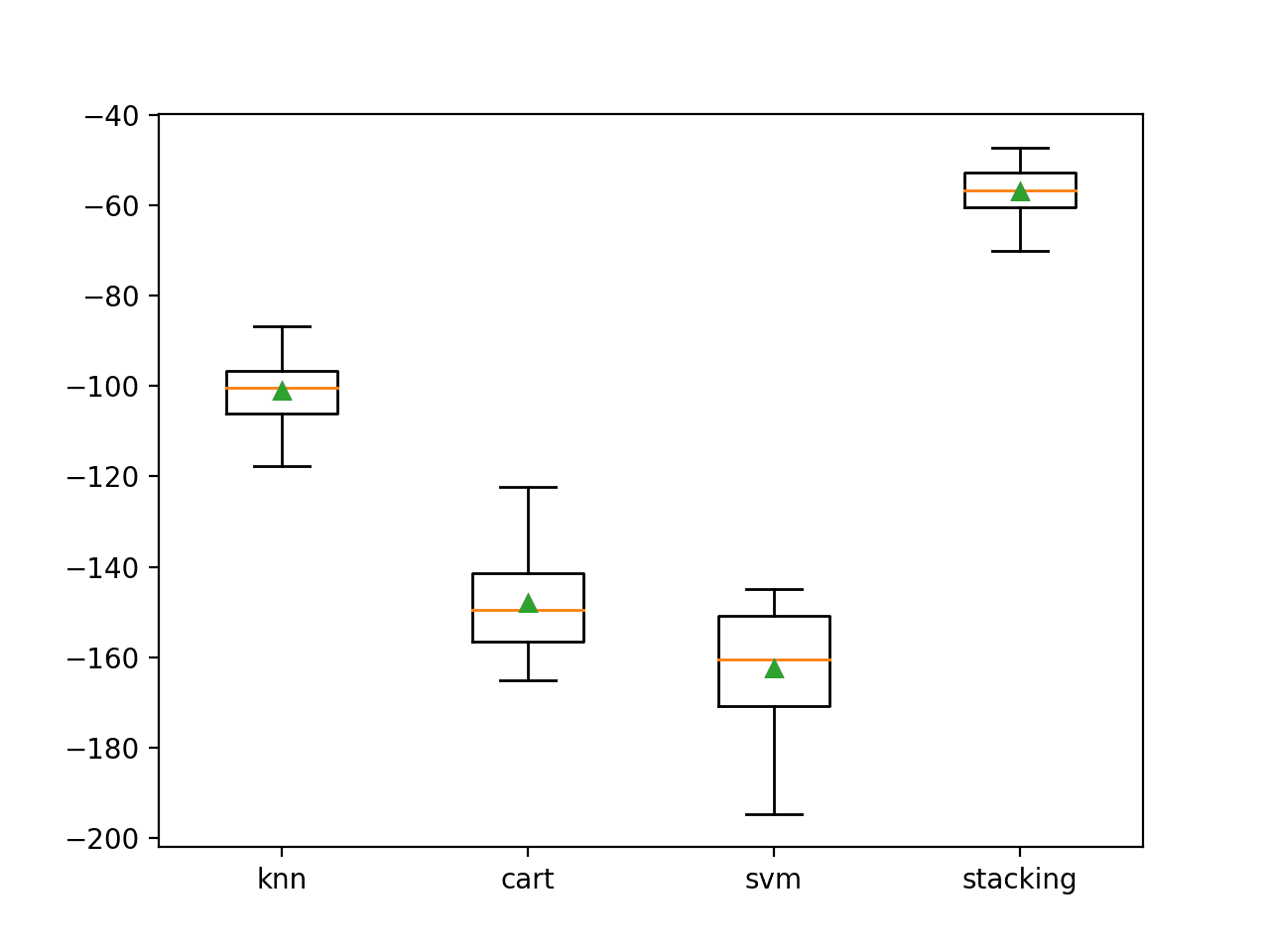
回归的独立模型和堆叠模型负平均绝对误差箱线图
如果选择堆叠集成作为最终模型,我们可以像其他任何模型一样拟合并使用它来对新数据进行预测。
首先,在所有可用数据上拟合堆叠集成,然后可以调用 predict() 函数对新数据进行预测。
以下示例在我们的回归数据集上演示了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 使用堆叠集成进行预测 from sklearn.datasets import make_regression 来自 sklearn.linear_model 导入 LinearRegression from sklearn.neighbors import KNeighborsRegressor 来自 sklearn.tree 导入 DecisionTreeRegressor 来自 sklearn.svm 导入 SVR from sklearn.ensemble import StackingRegressor # 定义数据集 X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=1) # 定义基础模型 level0 = list() level0.append(('knn', KNeighborsRegressor())) level0.append(('cart', DecisionTreeRegressor())) level0.append(('svm', SVR())) # 定义元学习器模型 level1 = LinearRegression() # 定义堆叠集成 model = StackingRegressor(estimators=level0, final_estimator=level1, cv=5) # 在所有可用数据上拟合模型 model.fit(X, y) # 对一个示例进行预测 data = [[0.59332206,-0.56637507,1.34808718,-0.57054047,-0.72480487,1.05648449,0.77744852,0.07361796,0.88398267,2.02843157,1.01902732,0.11227799,0.94218853,0.26741783,0.91458143,-0.72759572,1.08842814,-0.61450942,-0.69387293,1.69169009]] yhat = model.predict(data) print('Predicted Value: %.3f' % (yhat)) |
运行示例在整个数据集上拟合堆叠集成模型,然后用于对新数据行进行预测,就像在应用程序中使用模型时一样。
|
1 |
预测值:556.264 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
相关教程
- 如何用 Python 从零开始实现堆叠泛化(Stacking)
- 如何在 Python 中使用 Keras 为深度学习神经网络开发堆叠集成
- 如何在 Python 中开发超级学习器集成
- 如何在机器学习中使用折外预测
- k折交叉验证入门详解
论文
- 堆叠泛化, 1992.
- 堆叠泛化:何时有效?, 1997.
- 堆叠泛化中的问题, 1999.
书籍
- 《数据挖掘:实用机器学习工具与技术》(Data Mining: Practical Machine Learning Tools and Techniques), 2016.
- 统计学习基础, 2017.
- 机器学习:概率视角, 2012.
API
- sklearn.ensemble.StackingClassifier API.
- sklearn.ensemble.StackingRegressor API.
- sklearn.datasets.make_classification API.
- sklearn.datasets.make_regression API.
文章
总结
在本教程中,您学习了 Python 中的堆叠泛化集成或堆叠。
具体来说,你学到了:
- 堆叠是一种集成机器学习算法,它学习如何最好地结合来自多个表现良好的机器学习模型的预测。
- scikit-learn 库在 Python 中提供了堆叠集成的标准实现。
- 如何将堆叠集成用于回归和分类预测建模。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌握现代集成学习!

在几分钟内改进您的预测
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 实现集成学习算法
它提供**自学教程**,并附有关于以下内容的**完整工作代码**:
堆叠、投票、提升、装袋、混合、超级学习器等等……



 From Scratch With Python")

")
感谢您的精彩解释。
我有一个问题,如何将特定类型的数据(例如特定类别)传递给特定算法,其中每个模型从其特定数据中学习。然后将所有模型(堆叠)收集起来进行预测
此致,
您可以手动拟合不同的模型,然后使用另一个模型来组合预测。例如,全部手动操作。
嗨,Jason,感谢您的博客和所有经过消化的信息,我是一个各方面的新手,我真的看到了使用堆叠方法的优势。我还没有开始我的第一个项目,但在此之前,我计划尽可能多地阅读您的文章。
谢谢您,请保重,我希望从您这里学到尽可能多的东西。
来自墨西哥的问候!!
不客气。
这需要大量编码,可以使用 AutoMLPipeline 简化为几行代码:https://github.com/IBM/AutoMLPipeline.jl
感谢分享。
很棒的文章,Jason!请继续发布。谢谢!
不客气!
感谢分享。我猜当向 StackingClassifier 提供 cv=n 参数时,它隐含地在训练数据上训练基础模型,然后使用基础模型对样本外数据的预测来训练 StackingClassifier,对吗?
它通过内部交叉验证过程找到参数。
非常感谢您的信息!但我有一个问题
我尝试了您的分类堆叠在给定数据集上,我使用前 800 个样本进行训练并生成了箱线图,但是,当我测试每个模型在 200 个测试样本上的准确性结果时,堆叠模型没有提供最佳结果,您对此有什么解释吗?
是的,堆叠不保证优于基础模型。
这就是为什么我们必须使用受控实验作为模型选择的基础。
嗨 Jason Brownlee,您的文章多次帮了我大忙。
在一段中您提到:“也就是说,未用于训练基础模型的数据被馈送到基础模型,进行预测,并且这些预测,以及预期输出,提供了用于拟合元模型的训练数据集的输入和输出对。”
这里您说的预期输出是什么意思??
很高兴听到这个!
预期输出是数据集中的目标值。
所以您的意思是,在 model.fit(x_train,y_train)(训练阶段)期间,元模型不会学习任何东西,只有在 model.score(x_test,y_test)(测试阶段)时,元模型才会在测试输入和基估计器所做的预测值/标签上进行训练。
我的理解正确吗?
不,我不太理解你的总结。
堆叠模型在调用 fit() 期间拟合。调用 cross_val_score() 将拟合并评估 k 个模型,这在内部涉及调用 fit()。
好文!
我正在尝试回答之前的问题,但我又有一个问题
为什么不使用 train_0 拟合 0 级模型,然后使用 0 级预测(使用 train_0 训练,使用 train_1 验证)训练元模型,并使用 X_valid 评估元模型?
这会是更好的方法吗,因为我们总是使用未见过的数据进行训练?
嗨,Victor……非常欢迎!您的观点很好!我们很乐意了解您的模型根据您的建议表现如何。
嗨,Jason,感谢您的精彩教程!
我想在 Level0 估计器中使用 CalibratedClassifier,然后堆叠它们。我尝试了这个,但不确定。这正确吗?
模型1=XGBClassifier()
模型2=…..
calibrated1 = CalibratedClassifierCV(model1, cv=5)
calibrated1.fit(X_train, y_train)
calibrated2 = ….
calibrated2.fit(….)
estimators = [(‘xgb’, calibrated1),(‘…’, calibrated2)]
clf = StackingClassifier(estimators=estimators, final_estimator=LogisticRegression())
谢谢。
对我来说,校准 Level0 分类器没有意义,抱歉。你可能需要一些尝试和错误才能使其工作。
嗨,Jason!感谢您的分享。我将本教程用于我的二分类任务。我有 1000 个图像样本,每个样本有 4000 个由 CNN 提取的维度。然而,堆叠结果低于 lr 或贝叶斯分类器,也低于您另一篇教程中的超学习。您能告诉我原因吗?期待您的回复。非常感谢!
回答“为什么”问题太难/难以处理。
我们能做的最好的事情通常是使用受控实验并提供结果来支持选择哪个模型或建模管道效果好/最好。
感谢您的精彩教程。
我看到本教程中每个基础学习器都使用默认模型超参数进行评估。在实际操作中,我能否通过超参数调优实现基础学习器,从而从元模型中获得更好的准确性?
我们能否在 0 级或作为基础学习器中使用 Boosting 和 Bagging 分类器?
谢谢!
是的,调优是个好主意。
如果你愿意,可以使用集成模型作为基础模型。
谢谢你。
1. 从您在本教程中使用的以下代码片段来看,我认为我们正在获取测试数据集的准确性,请确认?
# 使用交叉验证评估给定模型
def evaluate_model(model)
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring=’neg_mean_absolute_error’, cv=cv, n_jobs=-1, error_score=’raise’)
return scores
2. 我正在处理一个分类问题,请查看我下面不同的分类算法结果。
方法 训练准确性 测试准确性
0 逻辑回归 0.8504762 0.8426966
1 KNN 0.9330952 0.9550562
2 朴素贝叶斯 0.7882540 0.7640449
3 SVM 0.9573810 0.9775281
4 决策树 1.0000000 0.9438202
5 随机森林 0.9477778 0.9550562
6 堆叠 1.0000000 0.9775281
基础学习器 – 0 到 5,元模型 – 6
如果您查看堆叠分类器,它在训练数据上完全过拟合,我不认为这是要考虑的最佳模型,对吗?
注意:我尝试从我的基础学习器列表中删除决策树,因为它在训练数据上过拟合,但我仍然从堆叠分类器中获得以下结果。所以这仍然不是最佳模型,对吗?
训练数据集准确性:1.0000 %
测试数据集准确性:0.9888 %
也许我会选择 SVM 作为我的最终模型。
没有训练/测试集。相反,我们使用重复的 k 折交叉验证来估计模型性能。
我不确定我会同意它过拟合了。您可以关注保留集的性能来选择模型。
抱歉,您能解释一下什么是“保留集性能”吗?
另外,请回答下面的问题。
1. 从您在本教程中使用的以下代码片段来看,我认为我们正在获取测试数据集的准确性,请确认?
# 使用交叉验证评估给定模型
def evaluate_model(model)
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring=’neg_mean_absolute_error’, cv=cv, n_jobs=-1, error_score=’raise’)
return scores
不,我们正在使用交叉验证。
是的,你可以在这里了解更多关于交叉验证的工作原理
https://machinelearning.org.cn/k-fold-cross-validation/
你可以在这里了解更多关于折外预测(在保留集上)的信息
https://machinelearning.org.cn/out-of-fold-predictions-in-machine-learning/
你好,
首先,很棒的指南。我发现它非常有用。
如果我对堆叠分类器使用 predict_proba,它会使用整个数据集的概率作为 level1 模型吗?还是只使用每次交叉验证运行中每个测试分割的概率?我不确定我是否说得很清楚。我正在看这个指南和集成模型的折外预测部分,我想了解这是否是相同的想法,如果不是,哪个更可取?此外,两者是否都可以集成到一个也进行特征选择的管道中?
我有点不熟悉机器学习和 Python。
非常感谢!
谢谢你。
无论预测标签还是概率,元模型都是基于基础模型折外预测进行拟合的。
这有帮助吗?
是的,谢谢。那么,告诉我我是否理解正确,因为我想确定:在本指南中,元模型是在折外预测上拟合的,就像您关于折外预测的另一篇指南中一样。我问是因为在本指南中您没有像那篇指南中那样创建元数据集。这是由堆叠分类器完成的吗?
两个方面都正确。
sklearn 隐藏了复杂性,使这种复杂的集成算法“例行化”。我喜欢它!
我正在处理一个多类别分类问题,数据集不平衡,我使用了 SMOTE 进行过采样。使用 xgboost 经过调优后,我可以达到大约 90.67 的 f1 分数。堆叠分类器和 xgboost 是否有助于提高 f1 分数。
也许可以尝试一下。
感谢 Jason 先生的指导。我使用上述代码在 Titanic 数据集上实现了堆叠模型。对于超参数调优,我使用了 GrisearchCV。如何提取最佳堆叠模型?如何使用它来预测测试集上的结果?
谢谢你。
不客气。
做得好!gridsearchcv 将提供对最佳配置的访问,如下所示
然后,您可以使用打印的配置拟合新模型,在所有可用数据上拟合您的模型,并为新数据调用 predict()。
如果进行预测对您来说是新的,请参阅此
https://machinelearning.org.cn/make-predictions-scikit-learn/
尊敬的Jason博士,
再次感谢您的教程。
我理解标题“评估堆叠集成模型与独立模型的完整示例如下所示”下面的列表
我从 get_models() 和 get_stacking() 的模型中学到了什么。
* get_stacking 是一个模型。
* get_models 获取模型列表。这包括 get_stacking,它是一个模型。
* 我可以使用“评估堆叠集成模型以及独立模型的完整示例”下的代码进行预测。
* 所以预测可以在箱线图下方的行中完成。
通过遵循“评估堆叠集成模型以及独立模型的完整示例”中的示例,我们可以理解 get_stacked() 是一个由 level 0 模型和 level1 LR 模型组成的堆叠模型。
谢谢你,
来自悉尼的安东尼
谢谢。
尊敬的Jason博士,
感谢您对堆叠的解释。我有一个关于它的问题。几天前我做了一个实验,为每个基础模型制作了最佳参数,为每个基础模型制作了默认参数。在我看来,如果每个基础模型都能实现更好的性能,那么元模型将通过基础模型生成的预测组合的训练数据获得更高的准确性。但事实上,结果却差了一点。那么您能帮我解释一下这个复杂的现象吗?
此致,
这很常见。
原因是高度优化的模型对微小变化很脆弱。
嗨 Jason
我发现您的脚本和解释非常有帮助,因为我是这个领域的新手。
不确定如何在我的手稿中引用您的脚本。
我是否像引用任何普通网站一样引用它,还是有其他方法?
祝好,
Neeraj Gaur
谢谢!
这可以帮助您引用博客文章
https://machinelearning.org.cn/faq/single-faq/how-do-i-reference-or-cite-a-book-or-blog-post
你好..
如何从堆叠集成中获取特征重要性?
我试过但不行。
恕我直言,我认为堆叠不提供此功能。
你觉得我怎么才能做到呢?
我是初学者,请帮我如何编写代码
是的!
这会帮助您安装所需的东西
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
这会帮助您复制代码
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
这会帮助您运行它
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
嗨,Jason,
非常感谢您的教程。请在这里帮助我
我想在执行特征选择后堆叠 3 种不同的算法。但是,所选算法的特征略有不同。
我需要使用相同的特征来训练我的子模型吗?
响应变量是作物产量。我有 24 个不同的预测变量。使用随机森林 (%IncMSE) 的最佳拟合模型从 24 个变量中选取 8 个变量。Lasso 选取 10 个变量,Xgboost 选取 6 个……如果我想堆叠这些模型,我该如何训练它们?
不,只要这 3 个模型具有相同的训练数据,您就可以为每个模型以任何您喜欢的方式转换训练数据。
谢谢您的及时回复……但是,我不确定您是否理解我的意思。我的数据有 24 个独立变量。特征选择导致随机森林有 8 个变量,lasso 有 10 个变量,XGBoost 有 6 个变量……我的问题是:在堆叠模型之前,我是否需要在我的 3 个模型中的每个模型中使用相同数量和相同的独立变量。
我的最佳拟合模型(RF、Lasso 和 XGB)在不同的独立变量上进行训练:RF 使用 8 个独立变量,Lasso 使用 10 个独立变量,XGB 使用 6 个独立变量……我不是指数据分割。
问题:我需要在这 3 个模型中使用相同的独立变量吗?而不是 8、6 和 10……我必须使用相同的独立变量来训练模型……在所有 3 个模型中都相同吗?
响应变量是玉米产量。RF 用 8 个变量训练:肥料、降雨量、温度、种子类型、田地大小、海拔、坡度、土壤 pH 值、农民性别
我必须在所有 3 个子模型中使用相同的变量吗?……如上所述,用 10 个和 6 个变量训练其他模型可以吗?
我相信我明白了。
不,您不需要为每个模型使用相同的独立变量,只要每个模型都使用相同的训练数据集(行)开始——即使每个模型使用不同的独立变量(列)。
随机森林从 24 个变量中抽取了 8 个变量
Lasso 从 24 个变量中选取了 10 个变量
Xgb 从 24 个变量中选取了 10 个变量
这 24 个与 8、6 和 10 没有任何关系……除了我总共有 24 个独立变量。应用了不同的特征选择方法,它们分别选择了 8、10 和 6 个变量
是的,没关系。只要您在训练期间未使用的数据上测试模型即可。
你好,詹森博士,根据您的代码,您将数据分成 5 部分是正确的吗?我仍然不明白为什么堆叠和交叉验证中会有两次交叉折叠验证。
你好,Fara……以下资源可能对您有用
https://machinelearning.org.cn/repeated-k-fold-cross-validation-with-python/
嗨,Jason,
非常感谢您对堆叠的详细解释;这对我很有帮助。
请问我有一个关于您文章中这段话的问题
“元模型是在基础模型对样本外数据所做的预测上进行训练的。也就是说,未用于训练基础模型的数据被馈送给基础模型,进行预测,这些预测以及预期输出提供了用于拟合元模型的训练数据集的输入和输出对。”
根据以上段落,我的理解如下
1. 给定一个训练数据集 (X_{train}, Y_{train}),在训练期间,基础模型只接收 X_{train}。
2. 基础模型根据接收到的数据 X_{train} 进行预测,Xbase_{prediction}。
3. 然后将 Xbase_{prediction} 作为输入馈送给元模型。但是,它还将具有预测 Y_{train} 的期望输出。这样,元模型就拟合了训练数据集。
4. 然后重复第 1 到 3 组几次。
请问我对您文章中以上段落的理解是否正确?
谢谢
Mark
交叉验证用于将基础模型的样本外预测作为堆叠模型的输入。
好的,谢谢。
假设我使用 RandomSearchCV 来识别模型的最佳超参数——但我将评分参数设置为优化“精确度”。(我只关心消除假阳性;假阴性的存在不会伤害我)。
StackingClassifier 的文档不包含评分参数。文档只提到训练集成以获得最佳*准确度*。
这是否意味着 StackingClassifier 将优化我不希望优化的指标(准确度)而不是我希望优化的指标(精确度)?
如果是这样,在所有情况下预测正类并获得最佳精度。
堆叠集成本身不优化分数。我想您指的是 score() 函数,这是评估模型的一种方式。
sklearn 已经安装并更新了,如何解决这个错误
没有名为“sklearn.cross_validation”的模块
您必须更新 scikit-learn 库的版本。
非常感谢。这无疑是我见过的最好的解释方式。
谢谢!
对于堆叠模型,除了交叉验证 cv=5,我们是否可以使用训练测试分割而不是 60:40?
如果你喜欢的话。
那将被称为混合
https://machinelearning.org.cn/blending-ensemble-machine-learning-with-python/
嗨,Jason,
如何最好地集成 3 个具有 3 个不同数据集的随机森林?你能帮助我吗?
谢谢!
再次抱歉,问题有 3 个类别
也许可以从模型的平均值开始。
嗨,Jason,
我有一个不平衡的多类别数据集,我将数据集平衡到 3 个数据集,之后我应用了特征选择方法。因此,我想创建 3 个随机森林,它们将具有不同的数据和不同的列数,然后集成这三个数据集。最好的方法是什么?你能帮我吗?
评估一系列方法并发现哪种方法最适合您的数据集。
你好 Jason Brownlee
请问如何使用 RMSE 评估结果?
能给我一些例子吗?
请参阅此教程,了解如何计算 RMSE 等指标
https://machinelearning.org.cn/regression-metrics-for-machine-learning/
布朗利博士,您好,
感谢您的精彩教程。我正在研究堆叠架构,我卡在一个特定的想法上。我的所有级别 0 模型都需要不同的阈值才能进行最佳预测。有没有办法在堆叠架构中单独设置阈值或解决这个问题?
谢谢!
不客气。
据我所知,没有。
您可以手动实现堆叠并使用传递到下一级别的阈值。
或者,您可以放弃您的阈值,让级别 1 模型学习如何最好地使用级别 0 的预测。
感谢分享
不客气!
感谢分享如此精彩的教程。您如何保存模型以供以后使用?Joblib 或 pickle 在尝试在另一个代码中重用模型进行预测时会报错。
好问题,这会教您如何操作
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
谢谢你,杰森,这篇精彩的文章。它对我的研究帮助很大。
我想在这里留下一个关于我们撰写的关于堆叠泛化的论文链接。具体来说,它是关于如何结合基础模型和可视化指导来构建强大而多样化的堆叠集成。
StackGenVis:https://doi.org/10.1109/TVCG.2020.3030352
感谢分享。
嗨,Jason,
感谢您的教程,它真的很有趣。
您能做一个教程来展示在堆叠模型进行回归后如何进行随机搜索和网格搜索吗?
谢谢!
感谢您的建议!
不客气!
嗨,杰森!非常感谢你的教程!
我有一个问题——如果我使用一个需要评估集进行早期停止的基础模型,我将如何在一个堆叠集成中使用它?
您可能只需使用单独的数据集作为验证集。
谢谢杰森,
只是为了澄清——你是说要使用单独的验证集来预先找到所需的估算器数量,对吗?然后使用这个数量运行堆栈模型
也许吧。可能需要一些实验。
尊敬的Jason博士,
我将折叠数 cv 从 2 更改为 20,在以下行中:
发现当 cv = 2, 5, 10, 20 时,分数的平均值和标准差变化很小。
平均值在 cv=2 时为 0.962,cv = 5, 10, 20 时为 0.964
谢谢你
悉尼的Anthony
干得好!听起来系统很稳定。
尊敬的Jason博士,
我通过结合堆叠回归器的最后两个部分,将每个模型的评估和预测结合起来
各自的输出产生了显著不同的预测
预测范围从 31 到 556
教训:必须使用具有最低分数的模型范围。在这种情况下,堆叠回归模型产生的分数最小。
谢谢你,
悉尼的Anthony
感谢分享。
尊敬的Jason博士,
关于何时在使用重采样技术进行 cv 时使用 RepeatedKFold 和 RepeatedStratifiedKFold 的另一个观察。
RepeatedKFold – 用于连续输出,例如堆叠回归器
RepeatedStratifiedKFold – 用于离散输出,例如堆叠分类器
谢谢你,
悉尼的Anthony
是的,这些描述可能在 API 文档中。
您好,喜欢您的作品。是否可以使用预训练的回归模型(例如 XGBoost 和 Catboost)进行堆叠回归?我正在努力优化预测,并且我有一组在误差指标 mae、mape 方面表现良好的模型。我如何组合它们以获得优化的预测?是否可以使用预训练模型?线性回归可以工作吗?
谢谢。
您可能需要编写自定义代码,我不认为 scikit-learn 可以处理预训练模型。
嗨,你能指点一下我该怎么做吗,Jason?我对整个概念还比较陌生。有没有我可以参考的代码?提前谢谢!
抱歉,我没有类似这样的示例。您可能需要开发一些原型才能找到最佳的前进路径。
你好,
应用堆叠后是否可以显示混淆矩阵?如果可以,如何显示?因为这里只显示了准确度参数,如果我们想显示其他性能指标,如何获取这些?
是的,使用整个模型对新数据进行预测并计算预测的混淆矩阵。
很棒的课程!谢谢。
不客气。
嗨,Jason,
非常感谢您的指导。这对我确实很有帮助。但是,我尝试在 IsolationForest、OCSVM 和 LOF 上实现堆叠集成分类。
但我通常会遇到以下错误。
“ValueError: 估计器 IsolationForest 应该是一个分类器”。
我的问题是:这是否意味着 Isolation Forest 和 OneClass SVM 不是像 KNN、逻辑回归、SVM、决策树分类器那样的分类器?
希望有人能尽快回复。谢谢
这些模型不是分类器,您可能需要编写自定义代码来堆叠它们的输出。
嗨 Jason
您的文章总是很有帮助,谢谢!
您对如何调整堆叠模型的超参数有什么见解吗?(例如,是否需要先调整基础模型,然后调整元模型)。
谢谢!
不客气!
是的,它只是不同级别的 0 模型和不同级别的 1 模型。
很棒的帖子!一个问题——如果我想检查每个基础模型和堆叠模型之间性能(准确度)差异的统计显著性,我该怎么做?也就是说,如果我们有 5 个基础模型,那么这 5 个基础模型中的每一个与堆叠模型的性能有多大差异。请指导。谢谢
谢谢!
这会有帮助
https://machinelearning.org.cn/statistical-significance-tests-for-comparing-machine-learning-algorithms/
晚上好,先生,
我正在研究堆叠集成学习。您能告诉我这种算法在分类方面的研究挑战是什么吗?
我不知道。也许您可以阅读文献来发现当前的挑战。
一如既往,内容很棒!
我认为这种算法的主要缺点是元模型和每个基础模型的参数是分开估计的(在我们的例子中有六个不同的优化)。对整个结构进行单次优化可能会提高准确性。我们如何实现这种方法?
谢谢,
Assaf
我认为 scikit-learn 不允许这样做。毕竟,让所有模型在训练中相互独立是集成思想。
我从这一行得到 tpeError:????
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
字符串格式化期间并非所有参数都已转换。
请问我该如何解决这个挑战?
只需执行 print(name, mean(scores), std(scores)) 并查看哪些无法转换。
谢谢先生。
终于对我来说成功了。
????
除了使用 cross_val_score(),如何实现 GridSearchCV 并使用其自定义评分指标?
当然,请查看:https://scikit-learn.cn/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
查看“scoring”参数。
如果基础学习器 A 显著优于基础学习器 B,堆叠是否无法进一步提高性能。这里,“显著”意味着 A 的 ROC 曲线包含了 B 的 ROC 曲线。
感谢您的反馈,Jian!继续努力!
您好,感谢这篇精彩的文章,我几乎在一个地方找到了所有关于堆叠的信息,并且解释得非常好。不过我有一个疑问,对于足够大的数据集,使用堆叠模型是否明智?
嗨,詹姆斯,非常感谢您为我们这样的研究人员所做的努力。
我有一个问题,假设我们集成 XGBOOST + LGBM 回归模型作为 level 0,并且我们想将它们的结果与 level 1 元层的 LSTM 堆叠起来,用于回归问题。
您的任何想法都将不胜感激。
谢谢
你好,穆罕默德……不客气!请详细说明您的问题,以便我更好地协助您。您是否已实施此想法或正在遇到特定的错误?
你好,喜欢你的作品!
这个想法对我的项目很有用。但我有一个问题。
是否可以在生产环境中重新训练?
我尝试了“partial_fit”、“refit”等,但无法将其应用于模型(堆叠)
有什么解决办法吗?
你好,Kang……以下内容可能对您有用
https://machinelearning.org.cn/update-neural-network-models-with-more-data/
嗨,杰森。很棒的帖子。
如何找到堆叠模型的最佳组合?我们有各种不同的模型/算法可用,我们可以在堆叠中使用它们的任何组合。那么我该如何选择哪种特定组合最适合给定任务?
您好 Ankit… 我们非常感谢您的支持和反馈!以下资源可能对您有用
https://www.analyticsvidhya.com/blog/2015/10/trick-right-model-ensemble/
嗨,James Carmichael 先生
为什么我们在 MAE 中使用“负数”?
您好,James Carmichael 先生
我们如何将“负数”用于 MAE
你好,Vahid……一些模型评估指标,如均方误差(MSE)或MAE,在scikit-learn中计算时是负数。
这令人困惑,因为像 MSE 这样的误差分数实际上不能为负,最小值为零或无误差。
scikit-learn 库有一个统一的模型评分系统,它假设所有模型分数都最大化。为了使这个系统适用于最小化的分数,如 MSE 和其他误差度量,最小化的分数通过使它们变为负数来反转。
这也可以在指标的规范中看到,例如,在指标名称“neg_mean_squared_error”中使用了“neg”。
在解释负误差分数时,你可以忽略符号并直接使用它们。
你可以在这里了解更多
模型评估:量化预测质量
你好 Jason,
感谢您的教程。目前,我正在使用 OLS 和随机森林对一组决定因素(收入、家庭规模等)进行家庭支出(目标变量)的回归研究。在我的研究中,结果显示 OLS 回归(0.853)在使用 r2 分数时略优于随机森林回归(0.850)。然而,随机森林是另一个不错的选择,因为我的一些决定因素与目标变量存在非线性关系,这些变量在 OLS 中被归类为不显著变量(使用 t 检验)。
我正在寻找一个教程来开发一个混合模型,该模型利用 OLS(准确性)和随机森林(能够区分非线性关系)的优点。我尝试了本教程中提到的堆叠回归,并且在使用随机森林作为基础和 OLS 作为最终估计器时,r2 分数略有提高(0.855)。我想知道堆叠回归是否真的整合了我提到的两种优点,还是我应该参考其他关于开发混合模型的教程/文献?
谢谢
你好 Jason,
感谢您的教程。目前,我正在使用 OLS 和随机森林对一组决定因素(收入、家庭规模等)进行家庭支出(目标变量)的回归研究。在我的研究中,结果显示 OLS 回归(0.853)在使用 r2 分数时略优于随机森林回归(0.850)。然而,随机森林是另一个不错的选择,因为我的一些决定因素与目标变量存在非线性关系,这些变量在 OLS 中被归类为不显著变量(使用 t 检验)。
我正在寻找一个教程来开发一个混合模型,该模型利用 OLS(准确性)和随机森林(能够区分非线性关系)的优点。我尝试了本教程中提到的堆叠回归,并且在使用随机森林作为基础和 OLS 作为最终估计器时,r2 分数略有提高(0.855)。我想知道堆叠回归是否真的整合了我提到的两种优点,还是我应该参考其他关于开发混合模型的教程/文献?
嗨 agario…以下资源是回答您问题的一个很好的起点
https://machinelearning.org.cn/ensemble-machine-learning-with-python-7-day-mini-course/
嗨 James,
非常感谢您的教程。我有一个问题。假设我将使用神经网络作为元模型。正如您所提到的,我们可以将原始输入(我们馈送给基础模型的输入)包含在元模型的输入中,以及基础模型的输出。您能解释一下我该怎么做吗?我的意思是,您认为我应该如何结合这两种类型的输入并将其馈送给元模型。
我正在根据这段话来说明:“元模型的训练数据还可以包括基础模型的输入,例如训练数据的输入元素。这可以为元模型提供额外的上下文,以便如何最好地组合元模型的预测。”
提前感谢
嗨,迈克……非常欢迎!我推荐以下资源作为起点,以澄清您查询的一些主题
https://machinelearning.org.cn/ensemble-machine-learning-with-python-7-day-mini-course/
嗨,Jason,
感谢您完成这项伟大的工作。
您提到“用作元模型输入的基础模型输出可以是回归情况下的实数值,以及分类情况下的概率值、类似概率的值或类别标签。”
有没有办法确保基础模型输出“仅用于分类的概率值、类似概率的值”?
我在 Scikit-learn 的 StackingClassifier 文档中没有看到这样的参数。
你好,ARM…不客气!softmax 函数可能会有帮助
https://machinelearning.org.cn/softmax-activation-function-with-python/