要想在应用机器学习方面有所成就,关键在于练习大量的不同数据集。
这是因为每个问题都不同,需要细微不同的数据准备和建模方法。
在本帖中,您将发现 10 个顶级标准机器学习数据集,可供您练习。
让我们开始吧。
- 更新于 2018 年 3 月:为 Pima Indians 和 Boston Housing 数据集添加了备用下载链接,因为原始链接似乎已被删除。
- 更新于 2019 年 2 月:对保险数据集的预期默认 RMSE 进行了小幅更新。
- 更新于 2021 年 10 月:对小麦种子数据集的描述进行了小幅更新。
概述
结构化方法
每个数据集都以一致的方式进行总结。这使得它们易于比较和导航,以便您练习特定的数据准备技术或建模方法。
您需要了解的关于每个数据集的方面是:
- 名称:如何引用数据集。
- 问题类型:问题是回归还是分类。
- 输入和输出:输入和输出特征的数量和已知名称。
- 性能:使用零规则算法进行比较的基线性能,以及最佳已知性能(如果已知)。
- 样本:原始数据的前 5 行快照。
- 链接:您可以下载数据集并了解更多信息的链接。
标准数据集
下面是我们将在下面介绍的 10 个数据集的列表。
每个数据集都足够小,可以放入内存并在电子表格中进行查看。所有数据集都由表格数据组成,没有(明确的)缺失值。
- 瑞典汽车保险数据集。
- 葡萄酒质量数据集。
- 皮马印第安人糖尿病数据集。
- 声纳数据集。
- 钞票数据集。
- 鸢尾花数据集。
- 鲍鱼数据集。
- 电离层数据集。
- 小麦种子数据集。
- 波士顿房价数据集。
1. 瑞典汽车保险数据集
瑞典汽车保险数据集涉及根据索赔总数预测所有索赔的总支付金额(以瑞典克朗为单位)。
这是一个回归问题。它包含 63 个观测值,1 个输入变量和 1 个输出变量。变量名称如下:
- 索赔次数。
- 所有索赔的总支付金额(以瑞典克朗为单位)。
预测平均值的基线性能是 RMSE 约为 81,000 瑞典克朗。
下面是前 5 行的样本。
|
1 2 3 4 5 |
108,392.5 19,46.2 13,15.7 124,422.2 40,119.4 |
下面是整个数据集的散点图。
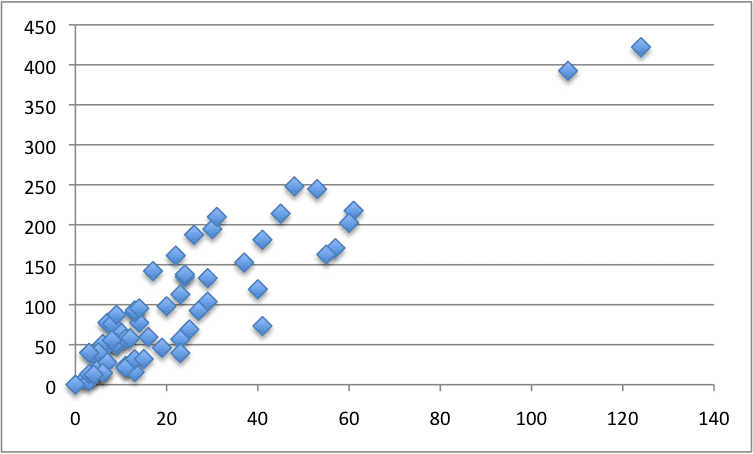
瑞典汽车保险数据集
2. 葡萄酒质量数据集
葡萄酒质量数据集涉及根据每种葡萄酒的化学测量值,按比例预测白葡萄酒的质量。
这是一个多类分类问题,但也可以被视为回归问题。每个类别的观测值数量不平衡。有 4,898 个观测值,11 个输入变量和 1 个输出变量。变量名称如下:
- 固定酸度。
- 挥发性酸度。
- 柠檬酸。
- 残糖。
- 氯化物。
- 游离二氧化硫。
- 总二氧化硫。
- 密度。
- pH 值。
- 硫酸盐。
- 酒精。
- 质量(分数在 0 到 10 之间)。
预测平均值的基线性能是 RMSE 约为 0.148 质量点。
下面是前 5 行的样本。
|
1 2 3 4 5 |
7,0.27,0.36,20.7,0.045,45,170,1.001,3,0.45,8.8,6 6.3,0.3,0.34,1.6,0.049,14,132,0.994,3.3,0.49,9.5,6 8.1,0.28,0.4,6.9,0.05,30,97,0.9951,3.26,0.44,10.1,6 7.2,0.23,0.32,8.5,0.058,47,186,0.9956,3.19,0.4,9.9,6 7.2,0.23,0.32,8.5,0.058,47,186,0.9956,3.19,0.4,9.9,6 |
3. 皮马印第安人糖尿病数据集
皮马印第安人糖尿病数据集涉及根据皮马印第安人的医疗详细信息,预测 5 年内糖尿病的发生。
这是一个二元(2 类)分类问题。每个类别的观测值数量不平衡。有 768 个观测值,8 个输入变量和 1 个输出变量。据信缺失值被编码为零值。变量名称如下:
- 怀孕次数。
- 2 小时内口服葡萄糖耐量试验的血浆葡萄糖浓度。
- 舒张压(mmHg)。
- 肱三头肌皮褶厚度(mm)。
- 2 小时血清胰岛素(μU/ml)。
- 体重指数(体重 kg / 身高 m 的平方)。
- 糖尿病遗传函数。
- 年龄(岁)。
- 类别变量(0 或 1)。
预测最普遍类别的基线性能是分类准确率约为 65%。最高结果的分类准确率约为 77%。
下面是前 5 行的样本。
|
1 2 3 4 5 |
6,148,72,35,0,33.6,0.627,50,1 1,85,66,29,0,26.6,0.351,31,0 8,183,64,0,0,23.3,0.672,32,1 1,89,66,23,94,28.1,0.167,21,0 0,137,40,35,168,43.1,2.288,33,1 |
4. 声纳数据集
声纳数据集涉及根据不同角度的声纳回波强度来预测物体是水雷还是岩石。
这是一个二元(2 类)分类问题。每个类别的观测值数量不平衡。有 208 个观测值,60 个输入变量和 1 个输出变量。变量名称如下:
- 不同角度的声纳回波
- …
- 类别(M 代表水雷,R 代表岩石)
预测最普遍类别的基线性能是分类准确率约为 53%。最高结果的分类准确率约为 88%。
下面是前 5 行的样本。
|
1 2 3 4 5 |
0.0200,0.0371,0.0428,0.0207,0.0954,0.0986,0.1539,0.1601,0.3109,0.2111,0.1609,0.1582,0.2238,0.0645,0.0660,0.2273,0.3100,0.2999,0.5078,0.4797,0.5783,0.5071,0.4328,0.5550,0.6711,0.6415,0.7104,0.8080,0.6791,0.3857,0.1307,0.2604,0.5121,0.7547,0.8537,0.8507,0.6692,0.6097,0.4943,0.2744,0.0510,0.2834,0.2825,0.4256,0.2641,0.1386,0.1051,0.1343,0.0383,0.0324,0.0232,0.0027,0.0065,0.0159,0.0072,0.0167,0.0180,0.0084,0.0090,0.0032,R 0.0453,0.0523,0.0843,0.0689,0.1183,0.2583,0.2156,0.3481,0.3337,0.2872,0.4918,0.6552,0.6919,0.7797,0.7464,0.9444,1.0000,0.8874,0.8024,0.7818,0.5212,0.4052,0.3957,0.3914,0.3250,0.3200,0.3271,0.2767,0.4423,0.2028,0.3788,0.2947,0.1984,0.2341,0.1306,0.4182,0.3835,0.1057,0.1840,0.1970,0.1674,0.0583,0.1401,0.1628,0.0621,0.0203,0.0530,0.0742,0.0409,0.0061,0.0125,0.0084,0.0089,0.0048,0.0094,0.0191,0.0140,0.0049,0.0052,0.0044,R 0.0262,0.0582,0.1099,0.1083,0.0974,0.2280,0.2431,0.3771,0.5598,0.6194,0.6333,0.7060,0.5544,0.5320,0.6479,0.6931,0.6759,0.7551,0.8929,0.8619,0.7974,0.6737,0.4293,0.3648,0.5331,0.2413,0.5070,0.8533,0.6036,0.8514,0.8512,0.5045,0.1862,0.2709,0.4232,0.3043,0.6116,0.6756,0.5375,0.4719,0.4647,0.2587,0.2129,0.2222,0.2111,0.0176,0.1348,0.0744,0.0130,0.0106,0.0033,0.0232,0.0166,0.0095,0.0180,0.0244,0.0316,0.0164,0.0095,0.0078,R 0.0100,0.0171,0.0623,0.0205,0.0205,0.0368,0.1098,0.1276,0.0598,0.1264,0.0881,0.1992,0.0184,0.2261,0.1729,0.2131,0.0693,0.2281,0.4060,0.3973,0.2741,0.3690,0.5556,0.4846,0.3140,0.5334,0.5256,0.2520,0.2090,0.3559,0.6260,0.7340,0.6120,0.3497,0.3953,0.3012,0.5408,0.8814,0.9857,0.9167,0.6121,0.5006,0.3210,0.3202,0.4295,0.3654,0.2655,0.1576,0.0681,0.0294,0.0241,0.0121,0.0036,0.0150,0.0085,0.0073,0.0050,0.0044,0.0040,0.0117,R 0.0762,0.0666,0.0481,0.0394,0.0590,0.0649,0.1209,0.2467,0.3564,0.4459,0.4152,0.3952,0.4256,0.4135,0.4528,0.5326,0.7306,0.6193,0.2032,0.4636,0.4148,0.4292,0.5730,0.5399,0.3161,0.2285,0.6995,1.0000,0.7262,0.4724,0.5103,0.5459,0.2881,0.0981,0.1951,0.4181,0.4604,0.3217,0.2828,0.2430,0.1979,0.2444,0.1847,0.0841,0.0692,0.0528,0.0357,0.0085,0.0230,0.0046,0.0156,0.0031,0.0054,0.0105,0.0110,0.0015,0.0072,0.0048,0.0107,0.0094,R |
5. 钞票数据集
钞票数据集涉及根据照片上采取的许多测量值来预测给定钞票是否为真。
这是一个二元(2 类)分类问题。每个类别的观测值数量不平衡。有 1,372 个观测值,4 个输入变量和 1 个输出变量。变量名称如下:
- 小波变换图像的方差(连续)。
- 小波变换图像的偏度(连续)。
- 小波变换图像的峰度(连续)。
- 图像熵(连续)。
- 类别(0 表示真实,1 表示伪造)。
预测最普遍类别的基线性能是分类准确率约为 50%。
下面是前 5 行的样本。
|
1 2 3 4 5 6 |
3.6216,8.6661,-2.8073,-0.44699,0 4.5459,8.1674,-2.4586,-1.4621,0 3.866,-2.6383,1.9242,0.10645,0 3.4566,9.5228,-4.0112,-3.5944,0 0.32924,-4.4552,4.5718,-0.9888,0 4.3684,9.6718,-3.9606,-3.1625,0 |
6. 鸢尾花数据集
鸢尾花数据集涉及根据鸢尾花测量值预测花卉种类。
这是一个多类分类问题。每个类别的观测值数量是平衡的。有 150 个观测值,4 个输入变量和 1 个输出变量。变量名称如下:
- 花萼长度(厘米)。
- 花萼宽度(厘米)。
- 花瓣长度(厘米)。
- 花瓣宽度(厘米)。
- 类别(鸢尾花setosa、鸢尾花versicolour、鸢尾花virginica)。
预测最普遍类别的基线性能是分类准确率约为 26%。
下面是前 5 行的样本。
|
1 2 3 4 5 |
5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa |
7. 鲍鱼数据集
鲍鱼数据集涉及根据个体物的客观测量值来预测鲍鱼的年龄。
这是一个多类分类问题,但也可以被视为回归问题。每个类别的观测值数量不平衡。有 4,177 个观测值,8 个输入变量和 1 个输出变量。变量名称如下:
- 性别(M、F、I)。
- 长度。
- 直径。
- 高度。
- 总重量。
- 去壳重量。
- 内脏重量。
- 壳重。
- 环数。
预测最普遍类别的基线性能是分类准确率约为 16%。预测平均值的基线性能是 RMSE 约为 3.2 环。
下面是前 5 行的样本。
|
1 2 3 4 5 |
M,0.455,0.365,0.095,0.514,0.2245,0.101,0.15,15 M,0.35,0.265,0.09,0.2255,0.0995,0.0485,0.07,7 F,0.53,0.42,0.135,0.677,0.2565,0.1415,0.21,9 M,0.44,0.365,0.125,0.516,0.2155,0.114,0.155,10 I,0.33,0.255,0.08,0.205,0.0895,0.0395,0.055,7 |
8. 电离层数据集
电离层数据集要求根据电离层自由电子的雷达回波来预测大气中的结构。
这是一个二元(2 类)分类问题。每个类别的观测值数量不平衡。有 351 个观测值,34 个输入变量和 1 个输出变量。变量名称如下:
- 17 对雷达回波数据。
- …
- 类别(g 代表好,b 代表差)。
预测最普遍类别的基线性能是分类准确率约为 64%。最高结果的分类准确率约为 94%。
下面是前 5 行的样本。
|
1 2 3 4 5 |
1,0,0.99539,-0.05889,0.85243,0.02306,0.83398,-0.37708,1,0.03760,0.85243,-0.17755,0.59755,-0.44945,0.60536,-0.38223,0.84356,-0.38542,0.58212,-0.32192,0.56971,-0.29674,0.36946,-0.47357,0.56811,-0.51171,0.41078,-0.46168,0.21266,-0.34090,0.42267,-0.54487,0.18641,-0.45300,g 1,0,1,-0.18829,0.93035,-0.36156,-0.10868,-0.93597,1,-0.04549,0.50874,-0.67743,0.34432,-0.69707,-0.51685,-0.97515,0.05499,-0.62237,0.33109,-1,-0.13151,-0.45300,-0.18056,-0.35734,-0.20332,-0.26569,-0.20468,-0.18401,-0.19040,-0.11593,-0.16626,-0.06288,-0.13738,-0.02447,b 1,0,1,-0.03365,1,0.00485,1,-0.12062,0.88965,0.01198,0.73082,0.05346,0.85443,0.00827,0.54591,0.00299,0.83775,-0.13644,0.75535,-0.08540,0.70887,-0.27502,0.43385,-0.12062,0.57528,-0.40220,0.58984,-0.22145,0.43100,-0.17365,0.60436,-0.24180,0.56045,-0.38238,g 1,0,1,-0.45161,1,1,0.71216,-1,0,0,0,0,0,0,-1,0.14516,0.54094,-0.39330,-1,-0.54467,-0.69975,1,0,0,1,0.90695,0.51613,1,1,-0.20099,0.25682,1,-0.32382,1,b 1,0,1,-0.02401,0.94140,0.06531,0.92106,-0.23255,0.77152,-0.16399,0.52798,-0.20275,0.56409,-0.00712,0.34395,-0.27457,0.52940,-0.21780,0.45107,-0.17813,0.05982,-0.35575,0.02309,-0.52879,0.03286,-0.65158,0.13290,-0.53206,0.02431,-0.62197,-0.05707,-0.59573,-0.04608,-0.65697,g |
9. 小麦种子数据集
小麦种子数据集涉及根据不同品种小麦种子的测量值来预测物种。
这是一个多类(3 类)分类问题。每个类别的观测值数量是平衡的。有 210 个观测值,7 个输入变量和 1 个输出变量。变量名称如下:
- 面积。
- 周长。
- 紧凑度
- 种子长度。
- 种子宽度。
- 不对称系数。
- 种子沟槽长度。
- 类别(1、2、3)。
预测最普遍类别的基线性能是分类准确率约为 28%。
下面是前 5 行的样本。
|
1 2 3 4 5 |
15.26,14.84,0.871,5.763,3.312,2.221,5.22,1 14.88,14.57,0.8811,5.554,3.333,1.018,4.956,1 14.29,14.09,0.905,5.291,3.337,2.699,4.825,1 13.84,13.94,0.8955,5.324,3.379,2.259,4.805,1 16.14,14.99,0.9034,5.658,3.562,1.355,5.175,1 |
10. 波士顿房价数据集
波士顿房价数据集涉及根据房屋及其社区的详细信息预测房屋价格(以千美元为单位)。
这是一个回归问题。有 506 个观测值,13 个输入变量和 1 个输出变量。变量名称如下:
- CRIM:城镇人均犯罪率。
- ZN:划定给超过 25,000 平方英尺地块的住宅用地比例。
- INDUS:城镇非零售商业用地亩数比例。
- CHAS:查尔斯河虚拟变量(= 1 如果地块临河;否则为 0)。
- NOX:一氧化氮浓度(百万分之十)。
- RM:每户平均房间数。
- AGE:1940 年前建造的自住单元比例。
- DIS:到五个波士顿就业中心的加权距离。
- RAD:通往辐射状高速公路的可达性指数。
- TAX:每 10,000 美元的全部财产税率。
- PTRATIO:城镇师生比例。
- B:1000(Bk – 0.63)^2,其中 Bk 是城镇黑人比例。
- LSTAT:人口中的低收入者百分比。
- MEDV:自住房屋的中位数价值(以千美元计)。
预测平均值的基线性能是 RMSE 约为 9.21 千美元。
下面是前 5 行的样本。
|
1 2 3 4 5 |
0.00632 18.00 2.310 0 0.5380 6.5750 65.20 4.0900 1 296.0 15.30 396.90 4.98 24.00 0.02731 0.00 7.070 0 0.4690 6.4210 78.90 4.9671 2 242.0 17.80 396.90 9.14 21.60 0.02729 0.00 7.070 0 0.4690 7.1850 61.10 4.9671 2 242.0 17.80 392.83 4.03 34.70 0.03237 0.00 2.180 0 0.4580 6.9980 45.80 6.0622 3 222.0 18.70 394.63 2.94 33.40 0.06905 0.00 2.180 0 0.4580 7.1470 54.20 6.0622 3 222.0 18.70 396.90 5.33 36.20 |
总结
在本帖中,您了解了 10 个顶级标准数据集,可用于练习应用机器学习。
您的下一步是:
- 选择一个数据集。
- 使用您喜欢的工具(如 Weka、scikit-learn 或 R)
- 看看您能将标准分数提高多少。
- 在下面的评论中报告您的结果。






谢谢 Jason。我将使用这些数据集进行练习。
告诉我你的进展,Benson。
谢谢。请推荐一些具有多个输出变量的数据集。
瑞典汽车保险数据格式已更改。它不再是 CSV 格式,并且数据开头有额外的行。
您可以从该页面复制粘贴数据到一个文件,然后在 Excel 中加载,再转换为 CSV。
https://www.math.muni.cz/~kolacek/docs/frvs/M7222/data/AutoInsurSweden.txt
您的帖子非常有帮助。您能推荐一个我可以用来练习聚类和 PCA 的数据集吗?
谢谢。
也许是所有特征都具有相同单位的数据集,例如鸢尾花数据集?
您好,关于瑞典汽车数据,是否无法使用 Scikit-Learn 执行线性回归?我收到弃用错误,要求我重塑数据。当我重塑时,我收到错误,提示样本大小不同。我缺少什么,请?谢谢。
抱歉,我不知道 Joe。也许试试将你的代码和错误发布到 stackoverflow?
先生,对于小麦数据集,我得到了这样的结果:
0.97619047619
[[ 9 0 1]
[ 0 20 0]
[ 0 0 12]]
精确率 召回率 f1分数 支持数
1.0 1.00 0.90 0.95 10
2.0 1.00 1.00 1.00 20
3.0 0.92 1.00 0.96 12
平均/总计 0.98 0.98 0.98 42
这是正确的吗,先生?
你说的正确是什么意思?
先生,我得到的混淆矩阵和准确率,可以接受吗?是对的吗?
这很大程度上取决于问题。抱歉,我对问题了解不够深入,也许可以与其他算法的混淆矩阵进行比较。
谢谢您,先生
我会做的。
非常感谢。
不客气。
谢谢这些数据集,它们将帮助我学习 ML。
不客气。
数值癌症和临床癌症有什么区别?或者两者相同吗?我需要白血病、肺癌、结肠癌数据集来进行我的工作。我还需要图像数据集来进行我的研究。哪里可以找到这些数据集?
也许可以谷歌搜索一下?
非常感谢分享,Jason!
我在我的第一个 Python 笔记本中将 sklearn 的随机森林和 SVM 分类器应用于了小麦种子数据集!😀 每次执行的错误在 10% 到 20% 之间波动。如果有人感兴趣,我可以分享。
再见
干得好!
我对小麦种子数据集的 SVM 分类器感兴趣。你说你很乐意分享。
对于声纳数据集,准确率达到了 90.47%。
干得好!
谢谢 Jason
我在银行票据数据集上使用了具有 70% 训练和 30% 测试的决策树分类器。
准确率达到了 99%。
[准确率:0.9902912621359223]
干得好!
在鸢尾花数据集上使用 75% 训练和 25% 测试的 k-最近邻分类器。准确率达到 0.973684。
干得好!
在鸢尾花数据集上使用 75% 训练和 25% 测试的 k-最近邻分类器。准确率达到 0.9970845481049563。
99.71%
非常好。
您是否有这些问题的已解决示例供我参考?
是的,博客上有其中大多数的解决方案,您可以尝试在博客中搜索。
您好,我使用了支持向量分类器和 KNN 分类器对小麦种子数据集(80% 训练数据,20% 测试数据)进行分类。
SVC 的准确率得分:0.9047619047619048
KNN 的准确率得分:0.8809523809523809
干得好!
您好!我在鸢尾花数据中发现了一些令人难以置信的拓扑趋势,我希望在另一个多类问题中重现它们。
人们通常是在对性别进行分类,还是将环数作为离散输出?
在鲍鱼数据集中*
该数据集的目标是年龄,但您可以为练习而构建任何预测建模问题。
您好,先生,我正在寻找用于 SVM 回归算法的小麦生产数据集。所以请给我一个适合机器学习的合适数据集。
在这里搜索数据集。
https://machinelearning.org.cn/faq/single-faq/where-can-i-get-a-dataset-on-___
大家好,我是 ML 新手。
感谢这组数据!
有人能解决葡萄酒质量问题吗?
我的结果太糟糕了。
谢谢
我做到了,请看这个。
https://machinelearning.org.cn/results-for-standard-classification-and-regression-machine-learning-datasets/
我需要一个数据集
至少包含 5 个维度/特征,包括至少一个类别维度和一个数值维度。
• 包含清晰的类标签属性(二元或多标签)。
• 具有简单的表格结构(即,没有时间序列、多媒体等)。
• 大小合理,且至少包含 2K 个元组。
这个可能会有帮助
https://machinelearning.org.cn/faq/single-faq/where-can-i-get-a-dataset-on-___
还有这个。
https://machinelearning.org.cn/generate-test-datasets-python-scikit-learn/
我在哪里可以找到问题的默认结果,以便与我的结果进行比较?
这里有很多。
https://machinelearning.org.cn/results-for-standard-classification-and-regression-machine-learning-datasets/
感谢这篇文章——非常有帮助!
我想知道是否有人知道一个分类数据集,其中特征对输出类别的重要性是已知的。例如:特征 1 是类别 1 的良好指标,或者特征 3、4、5 是类别 2 的良好指标……
希望有人能帮忙 😉
不客气。
通常,我们让模型自行发现重要性以及如何最佳地使用输入特征。
非常感谢您的回答。我之所以问,是因为我想通过全局敏感性分析(Sobol 指数)来验证我的特征重要性访问方法。为了做到这一点,我正在寻找一个具有所述属性的数据集(或虚拟数据集)。
什么是“Sobol指数”?
这是一种基于方差的全局敏感性分析(ANOVA)。它与置换重要性排序非常相似,但可以通过计算所谓的“总效应指数”来揭示特征的交叉相关性。如果您对该主题感兴趣,我推荐以下论文
https://www.researchgate.net/publication/306326267_Global_Sensitivity_Estimates_for_Neural_Network_Classifiers
这里提供了一些用于直接计算sobol指数的Python代码
https://salib.readthedocs.io/en/latest/api.html#sobol-sensitivity-analysis
回到我的第一个问题:您知道具有这些属性的数据集吗?或者您知道如何构建一个具有已知特征重要性输出的虚拟数据集吗?
谢谢。
是的,您可以使用make_classification()函数来构造具有相关/不相关输入的(Synthetic)数据集。我一直在使用它。
除此之外,您可能需要自己构建问题。特征重要性不是客观的!
第四天课程
代码:-
import pandas as pd
url = “https://goo.gl/bDdBiA”
names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
data = pd.read_csv(url, names=names)
description = data.describe()
print(description)
输出:-
preg plas pres skin test mass pedi age class
count 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000
768.000000 768.000000 768.000000
mean 3.845052 120.894531 69.105469 20.536458 79.799479 31.992578
0.471876 33.240885 0.348958
std 3.369578 31.972618 19.355807 15.952218 115.244002 7.884160 0.331329
11.760232 0.476951
min 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.078000
21.000000 0.000000
25% 1.000000 99.000000 62.000000 0.000000 0.000000 27.300000 0.243750
24.000000 0.000000
50% 3.000000 117.000000 72.000000 23.000000 30.500000 32.000000
0.372500 29.000000 0.000000
75% 6.000000 140.250000 80.000000 32.000000 127.250000 36.600000
0.626250 41.000000 1.000000
max 17.000000 199.000000 122.000000 99.000000 846.000000 67.100000
2.420000 81.000000 1.000000
输出未能正确地放入评论部分
干得好!
你好,
非常感谢这篇帖子!
我是一个初学者,有些我不确定。我已经用直线拟合了数据(第一个数据集),但我们如何衡量准确性?
我们应该剔除一些数据点,然后用来测试,还是什么?
好问题,这可能会有帮助
https://machinelearning.org.cn/regression-metrics-for-machine-learning/
谢谢,我正在按照帖子内容,但使用的是我自己的代码
mean = np.mean(Y)
l = Y.shape[1]
res = Y-mean
rmse = np.sqrt(np.dot(res,res.T)/l)
我计算了rmse,结果是
python
>>> rmse
array([[86.63170447]])
另外,葡萄酒质量的值最高为8,而不是10,至少我是这样得到的。
感谢您的帮助
rmse 是针对瑞典克朗的
您能告诉我葡萄酒数据集中的1.48是怎么来的吗?我计算了均方误差,结果是0.034,使用
np.sqrt(np.mean(Y)/len(Y))还是这是sqrt(sum^m (y-y_i)*(y-y_i)/m)?
这可能是模型预测训练数据均值的RMSE。
RMSE的计算方法在这里
https://machinelearning.org.cn/regression-metrics-for-machine-learning/
嗨,Jason,
葡萄酒质量数据集是一个多分类问题。我们如何得到RMSE作为指标?这是一个错误还是我遗漏了什么?
你好Amit…是的,该数据集可用于分类,但是为了达到这一点,RMSE可以用来确定预测的准确性,这取决于对特征所代表的每个数量的平均值的比较。
从头开始编写的线性模型得到了
朴素估计rmse: [[86.63170447]]
模型rmse: [[35.44597361]]
我还在这里对模型的演变进行了简单的可视化
https://imgur.com/1X7h7gC
干得好!
非常感谢,Jason。今天我一直在寻找这些数据集来练习。
不客气。
非常感谢!我将使用其中一些来练习
顺便说一句,在小麦种子数据集中,它被描述为一个二元分类问题,然而,却有3个类别。这是错误还是什么?谢谢
是的,那是一个错误。感谢您的指正。
我发现葡萄酒的评估数据集与这里的数据集不一致
https://machinelearning.org.cn/results-for-standard-classification-and-regression-machine-learning-datasets/#:~:text=https%3A//raw.githubusercontent.com/jbrownlee/Datasets/master/wine.csv
感谢您的反馈,Yao!