您应该使用哪种机器学习算法?
这是应用机器学习中的一个核心问题。
在 Randal Olson 等人的一篇论文中,他们试图回答这个问题,并为您提供一个指南,建议您在尝试更广泛的算法之前,先尝试特定的算法和参数。
在这篇文章中,您将发现一项研究及其成果,该研究评估了大量机器学习算法在大量机器学习数据集上的表现,并根据该研究提出了建议。
阅读本文后,你将了解:
- 集成树算法在各种数据集上表现良好。
- 测试一套算法对一个问题至关重要,因为没有万能的算法。
- 测试一套针对给定算法的配置至关重要,因为这可以为某些问题带来高达50%的改进。
通过我的新书《XGBoost With Python》启动您的项目,其中包括所有示例的分步教程和 Python 源代码文件。
让我们开始吧。

从梯度提升开始,但始终要抽样测试算法和配置
照片由 Ritesh Man Tamrakar 拍摄,部分权利保留。
论文
2017年,Randal Olson 等人发布了一篇题为“数据驱动的建议,用于将机器学习应用于生物信息学问题”的预印本。
他们工作的目标是解决每位从业者在开始预测建模问题时面临的问题;即
我应该使用哪种算法?
作者将这个问题描述为选择过载,如下所述
虽然有几种现成的机器学习算法实现对寻求超越简单统计学的生物信息学研究人员来说是有利的,但许多研究人员会经历“选择过载”,并发现难以选择适合其当前问题的机器学习算法。
他们通过在大量标准的机器学习数据集上运行一大部分算法来解决这个问题,以了解哪些算法和参数通常效果最好。
他们将他们的论文描述为
……对13种最先进的、常用的机器学习算法在165个公开可用的分类问题集上进行的全面分析,以向当前研究人员提供数据驱动的算法建议。
在方法和发现方面,这与论文“我们是否需要数百种分类器来解决现实世界的分类问题?”和文章“使用随机森林:在121个数据集上测试179种分类器”非常相似。
机器学习算法的神秘面纱
研究共选择了13种不同的算法。
选择算法是为了提供不同类型或底层假设的混合。
目标是代表文献中最常见的算法类别,以及最新的最先进算法。
完整的算法列表如下。
- 高斯朴素贝叶斯 (GNB)
- 伯努利朴素贝叶斯 (BNB)
- 多项式朴素贝叶斯 (MNB)
- 逻辑回归 (LR)
- 随机梯度下降 (SGD)
- 被动攻击分类器 (PAC)
- 支持向量分类器 (SVC)
- K近邻 (KNN)
- 决策树 (DT)
- 随机森林 (RF)
- 极端随机树分类器 (ERF)
- AdaBoost (AB)
- 梯度树提升 (GTB)
scikit-learn库被用于这些算法的实现。
每种算法都有零个或多个参数,并对每种算法的合理参数值进行了网格搜索。
对于每种算法,都使用固定的网格搜索来调整超参数。
下表列出了算法和评估的超参数,摘自该论文。
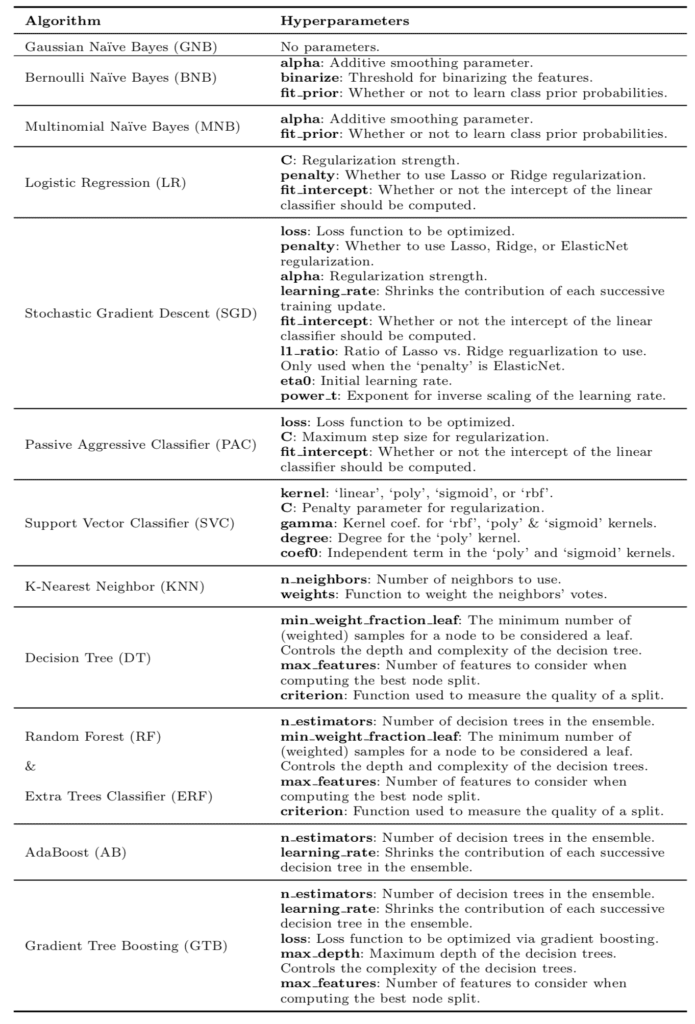
算法和参数表
算法使用10折交叉验证和平衡准确度指标进行评估。
交叉验证未重复,可能在结果中引入了一些统计噪声。
机器学习数据集
研究选择了165个标准机器学习问题。
其中许多问题来自生物信息学领域,但并非所有数据集都属于此研究领域。
所有预测问题都是具有两个或多个类别的分类问题。
算法在来自宾夕法尼亚州机器学习基准(PMLB)的165个监督分类数据集上进行了比较。 […] PMLB 是一个公开可用的分类问题集合,这些问题已标准化为相同的格式,并在一个中心位置收集,通过 Python 轻松访问。
数据集来自宾夕法尼亚州机器学习基准(PMLB)集合,该项目以统一的格式提供标准机器学习数据集,并通过简单的 Python API 提供。您可以在 GitHub 项目中了解更多关于这个数据集目录的信息。
所有数据集在拟合模型之前都已标准化。
在评估每种机器学习算法之前,我们通过减去均值并将特征缩放到单位方差来缩放每个数据集的特征。
未进行其他数据准备、特征选择或特征工程。
结果分析
进行的实验数量庞大,产生了大量的技能分数需要分析。
结果的分析处理得很好,提出了有趣的问题,并以易于理解的图表形式提供了发现。
整个实验设计总共进行了超过550万次机器学习算法和参数评估,从而产生了一套丰富的数据,并从多个角度进行了分析……
每个数据集的算法性能都进行了排名,然后计算出每种算法的平均排名。
这提供了一个粗略且易于理解的关于哪些算法在平均表现好或不好的想法。
结果显示,梯度提升和随机森林的排名最低(表现最佳),而朴素贝叶斯方法的排名最高(表现最差)。
事后检验强调了梯度树提升的卓越性能,其表现显著优于除随机森林以外的所有算法(p < 0.01)。
这通过论文中的一个图表得到了证明。
算法平均排名
没有一种算法表现最好或最差。
这是机器学习从业者所熟知的道理,但对于该领域的初学者来说却难以理解。
没有万能的解决方案,您必须在给定的数据集上测试一套算法,才能找出最适合的。
……值得注意的是,没有一种机器学习算法能在所有165个数据集中都表现最好。例如,有9个数据集上的多项式朴素贝叶斯表现与梯度树提升相当甚至更好,尽管它们分别是整体排名最差和最好的算法。因此,在将机器学习应用于新数据集时,考虑不同的机器学习算法仍然很重要。
此外,选择正确的算法还不够。您还必须为您的数据集选择正确的算法配置。
……选择正确的机器学习算法和调整其参数对于大多数问题都至关重要。
研究发现,调整算法可以提升方法技能3%到50%,具体取决于算法和数据集。
研究结果表明了为什么使用默认机器学习算法超参数是不明智的:调整通常能将算法的准确性提高3-5%,具体取决于算法。在某些情况下,参数调整使交叉验证准确性提高了50%。
论文中的一个图表展示了参数调整对每种算法的改进幅度,证明了这一点。
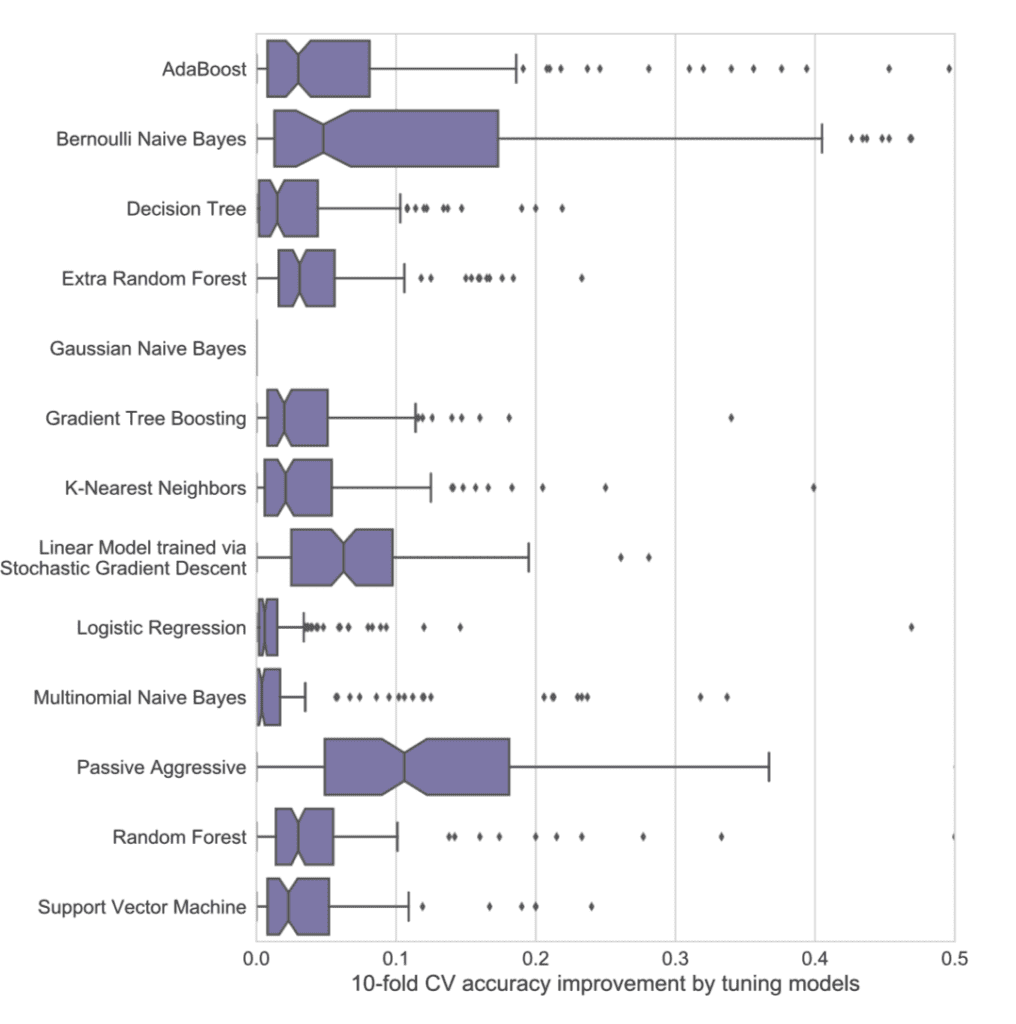
算法通过参数调整性能提升
并非所有算法都必需。
研究发现,五种算法和特定参数在165个测试数据集中的106个数据集上达到了前1%的性能。
这五种算法被推荐为在生物信息学中的给定数据集上进行算法抽样测试的起点,但我建议也更普遍地
- 梯度提升
- 随机森林
- 支持向量分类器
- 额外树
- 逻辑回归
论文提供了一个这些算法的表格,包括推荐的参数设置和覆盖的数据集数量,例如算法和配置达到前1%性能的数据集。
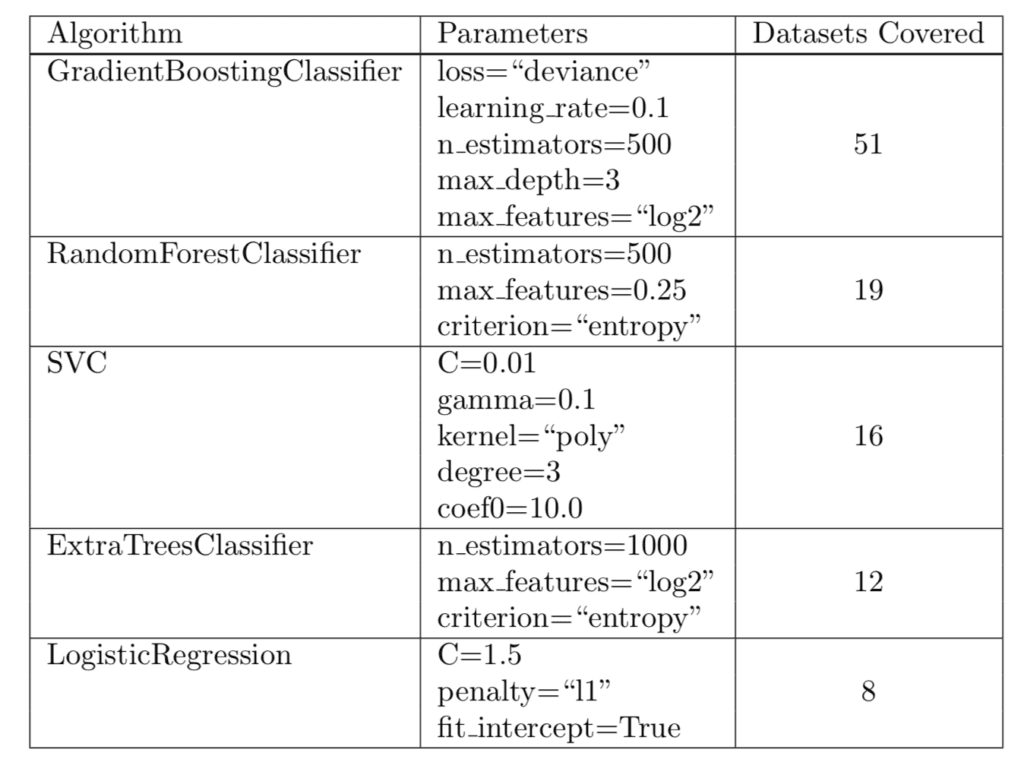
建议的算法
实践发现
本论文中有两个对从业者非常有价值的重大发现,尤其是那些刚起步的从业者,或者那些在自己的预测建模问题上需要快速取得结果的人。
1. 使用集成树
如果您不确定或时间紧迫,请在您的数据集上使用集成树算法,如梯度提升和随机森林。
该分析展示了最先进的基于树的集成算法的优势,同时也显示了机器学习算法性能与问题相关的特性。
2. 抽样测试和调整
没有人能根据您的问题告诉您使用哪种算法,而且没有万能的算法。
您必须测试一套算法和每种算法的一套参数,以找出最适合您特定问题的方法。
此外,分析表明,选择正确的机器学习算法并彻底调整其参数可以显著提高大多数问题的预测准确性,并且是每个机器学习应用的关键步骤。
我一直在谈论这一点;例如,请参阅文章
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
- 数据驱动的建议,用于将机器学习应用于生物信息学问题
- scikit-learn在GitHub上的基准测试
- 宾夕法尼亚州机器学习基准
- 在大量机器学习数据集上对scikit-learn的预测模型进行定量比较:一个好的开始
- 使用随机森林:在 121 个数据集上测试 179 个分类器
总结
在这篇文章中,您了解了一项研究及其成果,该研究评估了大量机器学习算法在大量机器学习数据集上的表现。
具体来说,你学到了:
- 集成树算法在各种数据集上表现良好。
- 测试一套算法对一个问题至关重要,因为没有万能的算法。
- 测试一套针对给定算法的配置至关重要,因为这可以为某些问题带来高达50%的改进。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
发现赢得竞赛的算法!

在几分钟内开发您自己的 XGBoost 模型
...只需几行 Python 代码
在我的新电子书中探索如何实现
使用 Python 实现 XGBoost
它涵盖了自学教程,例如:
算法基础、缩放、超参数等等……
将 XGBoost 的强大功能带入您自己的项目
跳过学术理论。只看结果。




")

嗨,Jason,
好文章!
一个问题
->何时使用深度学习与梯度提升/随机森林?
和
->无监督学习用于涵盖分类主题
例子
https://github.com/curiousily/Credit-Card-Fraud-Detection-using-Autoencoders-in-Keras
您能否在您的博客上涵盖无监督学习?我们有很多文章,但关于无监督学习的却少之又少……
您能否也涵盖创建简单的聊天机器人(例如使用您发布的seq2seq翻译器)?
感谢您的建议。
我一直避免使用无监督方法,因为从历史上看,我发现它们对于预测建模(机器学习的有用部分)没有帮助。我将来会涵盖它们。
尊敬的Jason博士,
根据图表“参数调整为每种算法提供的改进幅度”,难道被动/攻击性算法是最好的,因为箱线图没有任何异常值?但它不是“前1%”。
换句话说,您如何解释此图中的箱线图集?
谢谢你,
Anthony of Belield
我建议查看分布的中位数或均值,并使用统计假设检验来解释分布之间的差异。
这或多或少就是datarobot.com所宣称的,对吧?
抱歉,我不知道。
Oskar,是的,DataRobot会根据数据和响应变量生成模型评分。Rapidminer刚刚推出了他们的AutoModeler产品。它非常相似。
两者都是非常好的产品,具体取决于您的预期目标。
感谢分享。我预计亚马逊/谷歌的机器学习API服务也会做类似的事情。
很棒的文章,写得很好,组织得也很好。
我刚开始接触这些东西,非常感谢像这样的资源。
谢谢。希望它有帮助。
感谢Jason带来的这篇文章。关于简单神经网络用于分类数据集,您怎么看?我认为它们的表现会优于所有13种机器学习算法。如果这是真的,那么您如何看待机器学习与深度学习(DL)的未来?因为几乎不需要特征提取就能获得更好的结果(前提是拥有足够的数据集和处理能力)。
没有一种算法在所有问题上都是最好的。
随机梯度提升非常适合表格数据,而神经网络则非常适合文本/图像和其他模拟数据。
好文!
谢谢。
我目前正在使用R studio进行宏观经济和金融变量的预测。
现在我想探索时间序列预测的机器学习。
太棒了!
嗨,Jason,
您是否计划提供XGBOOST多分类问题的示例?或者您能推荐一个可靠的来源吗?
谢谢
您可以将任何二分类示例改编为多分类。
嗨,Jason,
感谢您出色的博客。我有一个关于回归和梯度提升的问题。
我有一个变量X,它随时间变化,但我们也知道X取决于诸如温度、流量等不同特征以及污垢。我们希望根据给定的温度、流量等来校正X值……目标是最终只比较不同污垢随时间的变化(针对给定的温度、流量等)。如何做到这一点?因为如果我使用梯度提升之类的回归,我认为如果我丢失了污垢信息(例如,如果有过拟合)。
谢谢,
听起来您想用xgboost对时间序列数据进行建模。
在这种情况下,过去的观察将成为输入特征。这将有所帮助。
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/