Keras Python深度学习库支持有状态和无状态的长短期记忆(LSTM)网络。
在使用有状态LSTM网络时,我们可以精细地控制LSTM网络的内部状态何时被重置。因此,了解在拟合和进行LSTM网络预测时管理此内部状态的不同方法,以影响网络的技能,这一点非常重要。
在本教程中,您将探讨Keras中有状态和无状态LSTM网络在时间序列预测方面的性能。
完成本教程后,您将了解:
- 如何为时间序列预测比较和对比有状态和无状态LSTM网络。
- 无状态LSTM中的批量大小与有状态LSTM网络的关系。
- 如何评估和比较有状态LSTM网络的各种状态重置机制。
开始您的项目,阅读我的新书《时间序列预测深度学习》,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。

有状态和无状态 LSTM 用于 Python 时间序列预测
照片由m01229拍摄,保留部分权利。
教程概述
本教程分为7个部分,它们是:
- 洗发水销售数据集
- 实验测试框架
- A vs A 测试
- 有状态 vs 无状态
- 大批量无状态 vs 无状态
- 有状态重置 vs 无状态
- 结果回顾
环境
本教程假定您已安装 Python SciPy 环境。您可以使用 Python 2 或 3。
本教程假定您已安装 Keras v2.0 或更高版本,并使用 TensorFlow 或 Theano 后端。
本教程还假定您已安装 scikit-learn、Pandas、NumPy 和 Matplotlib。
如果您需要帮助设置 Python 环境,请参阅此帖子
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
洗发水销售数据集
此数据集描述了 3 年期间洗发水月销量。
单位是销售计数,共有 36 个观测值。原始数据集归功于 Makridakis、Wheelwright 和 Hyndman (1998)。
以下示例加载并创建加载数据集的图表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 加载并绘制数据集 from pandas import read_csv from pandas import datetime from matplotlib import pyplot # 加载数据集 def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # 总结前几行 print(series.head()) # 线图 series.plot() pyplot.show() |
运行该示例将数据集作为 Pandas Series 加载并打印前 5 行。
|
1 2 3 4 5 6 7 |
月份 1901-01-01 266.0 1901-02-01 145.9 1901-03-01 183.1 1901-04-01 119.3 1901-05-01 180.3 名称:销售额,数据类型:float64 |
然后创建该系列的线图,显示出明显的上升趋势。
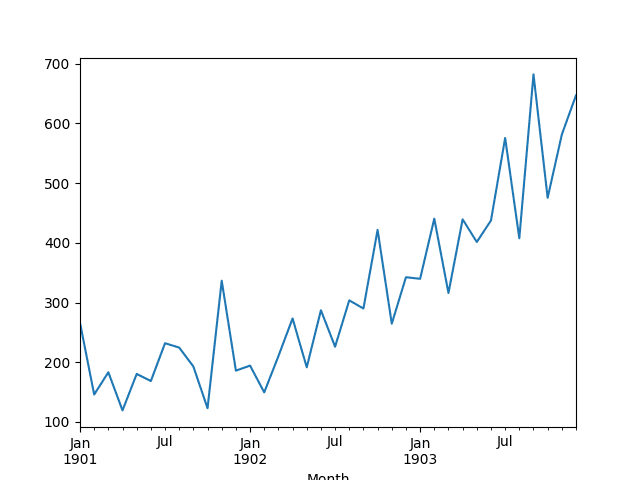
洗发水销售数据集的折线图
接下来,我们将看看实验中使用的LSTM配置和测试框架。
实验测试框架
本节将介绍本教程中使用的测试框架。
数据分割
我们将把洗发水销售数据集分为两部分:训练集和测试集。
前两年的数据将用于训练数据集,剩下的一年数据将用于测试集。
模型将使用训练数据集进行开发,并对测试数据集进行预测。
在测试数据集上的持久性预测(朴素预测)实现了136.761个月洗发水销量的误差。这为测试集上的性能提供了一个可接受的较低界限。
模型评估
将使用滚动预测方案,也称为向前验证模型。
测试数据集的每个时间步将逐一进行。模型将用于预测时间步,然后从测试集中获取实际期望值,并将其提供给模型以进行下一个时间步的预测。
这模拟了现实世界场景,其中每个月都会有新的洗发水销售观察值,并用于预测下个月。
这将通过训练和测试数据集的结构进行模拟。
将收集测试数据集上的所有预测,并计算误差分数来总结模型的技能。将使用均方根误差(RMSE),因为它会惩罚大的误差,并且得出的分数与预测数据的单位相同,即月度洗发水销量。
数据准备
在我们使用 LSTM 模型拟合数据集之前,我们必须转换数据。
在拟合模型和进行预测之前,对数据集执行以下三种数据转换。
- 转换时间序列数据使其平稳。具体来说,进行 lag=1 的差分以消除数据中不断增长的趋势。
- 将时间序列转换为监督学习问题。具体来说,是将数据组织成输入和输出模式,其中前一个时间步的观测值用作当前时间步观测值的预测输入。
- 转换观测值以具有特定比例。具体来说,将数据重新缩放到-1到1之间的值,以满足LSTM模型的默认双曲正切激活函数。
在计算误差分数之前,这些转换将被应用于预测中,以将它们恢复到其原始尺度。
LSTM 模型
我们将使用一个基础的状态LSTM模型,包含1个神经元,训练1000个周期。
需要批量大小为1,因为我们将使用前向验证,并对测试数据最后12个月的每个月进行单步预测。
批量大小为1意味着模型将使用在线训练(而不是批量训练或小批量训练)进行拟合。因此,预计模型拟合会存在一些方差。
理想情况下,会使用更多的训练周期(例如1500个),但为了使运行时间合理,此处截断为1000个。
模型将使用高效的ADAM优化算法和均方误差损失函数进行拟合。
实验运行
每个实验场景将运行10次。
这样做的原因是,LSTM网络的随机初始条件每次训练给定配置时都可能导致非常不同的结果。
让我们开始实验。
A vs A 测试
一个很好的首次实验是评估我们的测试机制的噪声或可靠性。
这可以通过运行相同的实验两次并比较结果来评估。这在A/B测试的世界中通常被称为A vs A测试,我发现这个名称很有用。其思想是找出实验中的任何明显缺陷,并掌握平均值的预期方差。
我们将运行一个在网络上使用有状态LSTM的实验两次。
完整的代码列表如下。
此代码也为本教程中所有实验提供了基础。由于后续部分中为每个变体重复列出代码会比较冗长,因此我只列出已更改的函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 |
from pandas import DataFrame from pandas import Series 从 pandas 导入 concat from pandas import read_csv from pandas import datetime from sklearn.metrics import mean_squared_error 从 sklearn.预处理 导入 MinMaxScaler from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 LSTM from math import sqrt import matplotlib import numpy from numpy import concatenate # 用于加载数据集的日期时间解析函数 def parser(x): return datetime.strptime('190'+x, '%Y-%m') # 将序列构造成监督学习问题 def timeseries_to_supervised(data, lag=1): df = DataFrame(data) columns = [df.shift(i) for i in range(1, lag+1)] columns.append(df) df = concat(columns, axis=1) return df # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return Series(diff) # 反转差分值 def inverse_difference(history, yhat, interval=1): return yhat + history[-interval] # 将训练和测试数据缩放到 [-1, 1] def scale(train, test): # 拟合缩放器 scaler = MinMaxScaler(feature_range=(-1, 1)) scaler = scaler.fit(train) # 转换训练集 train = train.reshape(train.shape[0], train.shape[1]) train_scaled = scaler.transform(train) # 转换测试集 test = test.reshape(test.shape[0], test.shape[1]) test_scaled = scaler.transform(test) return scaler, train_scaled, test_scaled # 预测值的逆缩放 def invert_scale(scaler, X, yhat): new_row = [x for x in X] + [yhat] array = numpy.array(new_row) array = array.reshape(1, len(array)) inverted = scaler.inverse_transform(array) return inverted[0, -1] # 训练一个 LSTM 网络 def fit_lstm(train, batch_size, nb_epoch, neurons): X, y = train[:, 0:-1], train[:, -1] X = X.reshape(X.shape[0], 1, X.shape[1]) model = Sequential() model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True)) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') for i in range(nb_epoch): model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False) model.reset_states() return model # 进行一步预测 def forecast_lstm(model, batch_size, X): X = X.reshape(1, 1, len(X)) yhat = model.predict(X, batch_size=batch_size) return yhat[0,0] # 运行重复实验 def experiment(repeats, series): # 将数据转换为平稳 raw_values = series.values diff_values = difference(raw_values, 1) # 将数据转换为监督学习 supervised = timeseries_to_supervised(diff_values, 1) supervised_values = supervised.values[1:,:] # 将数据分割成训练集和测试集 train, test = supervised_values[0:-12, :], supervised_values[-12:, :] # 转换数据尺度 scaler, train_scaled, test_scaled = scale(train, test) # 运行实验 error_scores = list() for r in range(repeats): # 拟合基础模型 lstm_model = fit_lstm(train_scaled, 1, 1000, 1) # 预测测试数据集 predictions = list() for i in range(len(test_scaled)): # 预测 X, y = test_scaled[i, 0:-1], test_scaled[i, -1] yhat = forecast_lstm(lstm_model, 1, X) # 反转缩放 yhat = invert_scale(scaler, X, yhat) # 反转差分 yhat = inverse_difference(raw_values, yhat, len(test_scaled)+1-i) # 存储预测 predictions.append(yhat) # 报告性能 rmse = sqrt(mean_squared_error(raw_values[-12:], predictions)) print('%d) Test RMSE: %.3f' % (r+1, rmse)) error_scores.append(rmse) return error_scores # 执行实验 def run(): # 加载数据集 series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # 实验 repeats = 10 results = DataFrame() # 运行实验 results['results'] = experiment(repeats, series) # 总结结果 print(results.describe()) # 保存结果 results.to_csv('experiment_stateful.csv', index=False) # 入口点 run() |
运行实验会将结果保存到名为“experiment_stateful.csv”的文件中。
再次运行实验,并将实验写入的文件名更改为“experiment_stateful2.csv”,以避免覆盖第一次运行的结果。
现在,您应该在当前工作目录的文件中有两组结果:
- experiment_stateful.csv
- experiment_stateful2.csv
我们现在可以加载并比较这两个文件。执行此操作的脚本如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from pandas import DataFrame from pandas import read_csv from matplotlib import pyplot # 加载结果到数据框 filenames = ['experiment_stateful.csv', 'experiment_stateful2.csv'] results = DataFrame() for name in filenames: results[name[11:-4]] = read_csv(name, header=0) # 总结所有结果 print(results.describe()) # 箱线图 results.boxplot() pyplot.show() |
此脚本加载结果文件,并首先计算每次运行的描述性统计信息。
注意:您的结果可能因算法或评估程序的随机性,或数值精度的差异而有所不同。请考虑运行示例几次并比较平均结果。
我们可以看到,平均结果和标准差是相对接近的值(分别约为103-106和7-10)。这是一个好迹象,但并不完美。如果增加重复实验的次数从10增加到30、100甚至1000,预计会产生几乎相同的汇总统计数据。
|
1 2 3 4 5 6 7 8 9 |
stateful stateful2 count 10.000000 10.000000 平均值 103.142903 106.594624 标准差 7.109461 10.687509 最小值 94.052380 91.570179 25% 96.765985 101.015403 50% 104.376252 102.425406 75% 107.753516 115.024920 最大值 114.958430 125.088436 |
该比较还创建了一个箱形图来比较这两个分布。
该图显示了每次实验的 10 个测试 RMSE 结果的第 25、50(中位数)和第 75 百分位数。箱体显示了数据的中间 50%,绿色线显示了中位数。
该图显示,尽管描述性统计数据相当接近,但分布确实显示出一些差异。
尽管如此,这两个分布确实存在重叠,只要我们不纠结于均值上的微小差异,对不同实验设置的均值和标准差进行比较是合理的。
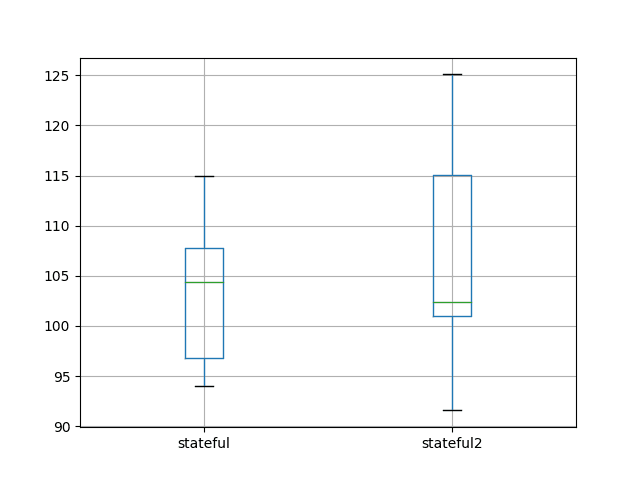
A vs A 实验结果的箱形图
对本次分析的一个很好的后续是,回顾具有不同样本量的分布的标准误差。这首先需要创建一个更大的实验运行池(100 或 1000),这将很好地说明一个稳健的重复次数和一个预期的均值误差,以便进行结果比较。
有状态 vs 无状态 LSTM
一个好的首次实验是探索在 LSTM 中保持状态是否比不保持状态更有价值。
在本节中,我们将对比
- 有状态 LSTM(上一节的第一个结果)。
- 具有相同配置的无状态 LSTM。
- 在训练期间进行洗牌的无状态 LSTM。
LSTM 网络的好处是它们能够维护状态并学习序列。
- 预期 1:预期有状态 LSTM 的性能将优于无状态 LSTM。
为了提高 MLP 网络在训练期间的泛化能力,通常会在每个批次或每个周期对输入模式进行洗牌。无状态 LSTM 在训练期间不会对输入模式进行洗牌,因为网络旨在学习模式的序列。我们将测试一个带和不带洗牌的无状态 LSTM。
- 预期 2:预期不进行洗牌的无状态 LSTM 将优于进行洗牌的无状态 LSTM。
使上述有状态 LSTM 示例无状态的代码更改涉及在 LSTM 层中设置 `stateful=False`,并使用自动训练周期训练而不是手动训练。结果被写入一个名为“experiment_stateless.csv”的新文件中。更新的 `fit_lstm()` 函数列在下面。
|
1 2 3 4 5 6 7 8 9 10 |
# 训练一个 LSTM 网络 def fit_lstm(train, batch_size, nb_epoch, neurons): X, y = train[:, 0:-1], train[:, -1] X = X.reshape(X.shape[0], 1, X.shape[1]) model = Sequential() model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=False)) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.fit(X, y, epochs=nb_epoch, batch_size=batch_size, verbose=0, shuffle=False) return model |
带洗牌的无状态实验涉及在调用 `fit_lstm()` 函数中的 `fit` 时将 `shuffle` 参数设置为 `True`。此实验的结果被写入名为“experiment_stateless_shuffle.csv”的文件中。
下面列出了完整的更新的 `fit_lstm()` 函数。
|
1 2 3 4 5 6 7 8 9 10 |
# 训练一个 LSTM 网络 def fit_lstm(train, batch_size, nb_epoch, neurons): X, y = train[:, 0:-1], train[:, -1] X = X.reshape(X.shape[0], 1, X.shape[1]) model = Sequential() model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=False)) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.fit(X, y, epochs=nb_epoch, batch_size=batch_size, verbose=0, shuffle=True) return model |
运行这些实验后,您应该有三个结果文件用于比较
- experiment_stateful.csv
- experiment_stateless.csv
- experiment_stateless_shuffle.csv
我们现在可以加载并比较这些结果。比较结果的完整示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from pandas import DataFrame from pandas import read_csv from matplotlib import pyplot # 加载结果到数据框 filenames = ['experiment_stateful.csv', 'experiment_stateless.csv', 'experiment_stateless_shuffle.csv'] results = DataFrame() for name in filenames: results[name[11:-4]] = read_csv(name, header=0) # 总结所有结果 print(results.describe()) # 箱线图 results.boxplot() pyplot.show() |
运行示例首先会计算并打印每个实验的描述性统计数据。
注意:您的结果可能因算法或评估程序的随机性,或数值精度的差异而有所不同。请考虑运行示例几次并比较平均结果。
平均结果表明,无状态 LSTM 配置的性能可能优于有状态配置。如果结果可靠,这一发现是相当令人惊讶的,因为它不符合状态的增加会提高性能的预期。
对于无状态 LSTM,训练样本的洗牌似乎没有产生大的差异。如果结果是可靠的,那么训练顺序的洗牌对无状态 LSTM 似乎提供了一些好处。
总而言之,这些发现可能进一步表明,所选的 LSTM 配置更侧重于学习输入-输出对,而不是序列中的依赖关系。
仅根据这些有限的结果,人们会考虑在此问题上探索无状态 LSTM。
|
1 2 3 4 5 6 7 8 9 |
stateful stateless stateless_shuffle 计数 10.000000 10.000000 10.000000 平均值 103.142903 95.661773 96.206332 标准差 7.109461 1.924133 2.138610 最小值 94.052380 94.097259 93.678941 25% 96.765985 94.290720 94.548002 50% 104.376252 95.098050 95.804411 75% 107.753516 96.092609 97.076086 最大值 114.958430 100.334725 99.870445 |
还创建了一个箱形图来比较分布。
与无状态情况相比,有状态配置的数据分布看起来要大得多。当我们查看标准差分数时,这在描述性统计中也存在。
这表明无状态配置可能更稳定。
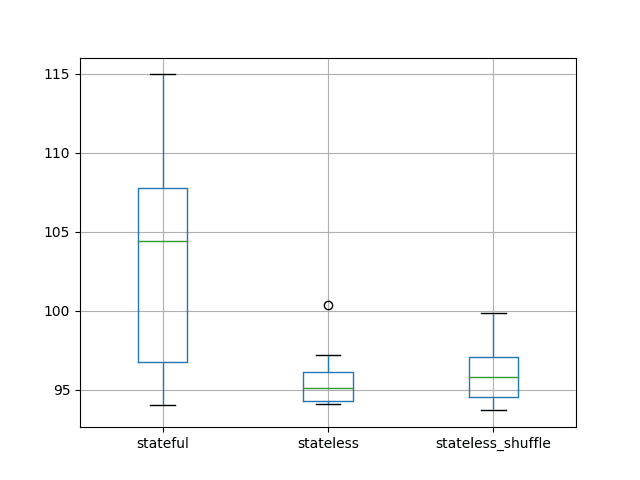
有状态 vs 无状态 LSTM 结果的测试 RMSE 箱形图
无状态大批次 vs 无状态
理解有状态和无状态 LSTM 之间差异的关键是“何时重置内部状态”。
- 无状态:在无状态 LSTM 配置中,在每次训练批次或进行预测时,内部状态都会被重置。
- 有状态:在有状态 LSTM 配置中,内部状态仅在调用 `reset_state()` 函数时重置。
如果这是唯一的区别,那么使用大批次大小的无状态 LSTM 可能会模拟有状态 LSTM。
- 预期 3:当使用相同的批次大小时,无状态和有状态 LSTM 应该产生几乎相同的 결과。
我们可以使用洗发水销售数据集来实现这一点,将训练数据截断为仅 12 个月,而测试数据保留 12 个月。这将允许无状态 LSTM 使用批次大小为 12。如果训练和测试是单次执行的(一个函数调用),那么“stateless”LSTM 的内部状态可能不会被重置,并且两种配置都会产生等效的结果。
我们将使用第一个实验的有状态结果作为起点。修改 `forecast_lstm()` 函数以一步预测一年的观测值。修改 `experiment()` 函数以将训练数据集截断为 12 个月的数据,使用批次大小为 12,并处理从 `forecast_lstm()` 函数返回的批处理预测。这些更新后的函数列在下面。结果被写入文件“experiment_stateful_batch12.csv”。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# 进行一步预测 def forecast_lstm(model, batch_size, X): X = X.reshape(1, 1, len(X)) yhat = model.predict(X, batch_size=batch_size) return yhat[0,0] # 运行重复实验 def experiment(repeats, series): # 将数据转换为平稳 raw_values = series.values diff_values = difference(raw_values, 1) # 将数据转换为监督学习 supervised = timeseries_to_supervised(diff_values, 1) supervised_values = supervised.values[1:,:] # 将数据分割成训练集和测试集 train, test = supervised_values[-24:-12, :], supervised_values[-12:, :] # 转换数据尺度 scaler, train_scaled, test_scaled = scale(train, test) # 运行实验 error_scores = list() for r in range(repeats): # 拟合基础模型 batch_size = 12 lstm_model = fit_lstm(train_scaled, batch_size, 1000, 1) # 预测测试数据集 test_reshaped = test_scaled[:,0:-1] test_reshaped = test_reshaped.reshape(len(test_reshaped), 1, 1) output = lstm_model.predict(test_reshaped, batch_size=batch_size) predictions = list() for i in range(len(output)): yhat = output[i,0] X = test_scaled[i, 0:-1] # 反转缩放 yhat = invert_scale(scaler, X, yhat) # 反转差分 yhat = inverse_difference(raw_values, yhat, len(test_scaled)+1-i) # 存储预测 predictions.append(yhat) # 报告性能 rmse = sqrt(mean_squared_error(raw_values[-12:], predictions)) print('%d) Test RMSE: %.3f' % (r+1, rmse)) error_scores.append(rmse) return error_scores |
我们将使用上一实验中无状态 LSTM 配置,并且关闭了训练模式洗牌的设置作为起点。该实验使用了相同的 `forecast_lstm()` 和 `experiment()` 函数。结果被写入名为“experiment_stateless_batch12.csv”的文件中。
运行此实验后,您将获得两个结果文件
- experiment_stateful_batch12.csv
- experiment_stateless_batch12.csv
我们现在可以比较这些实验的结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from pandas import DataFrame from pandas import read_csv from matplotlib import pyplot # 加载结果到数据框 filenames = ['experiment_stateful_batch12.csv', 'experiment_stateless_batch12.csv'] results = DataFrame() for name in filenames: results[name[11:-4]] = read_csv(name, header=0) # 总结所有结果 print(results.describe()) # 箱线图 results.boxplot() pyplot.show() |
运行比较脚本首先计算并打印每个实验的描述性统计数据。
注意:您的结果可能因算法或评估程序的随机性,或数值精度的差异而有所不同。请考虑运行示例几次并比较平均结果。
每个实验的平均结果表明,具有相同批次大小的无状态和有状态配置之间具有等效的结果。这证实了我们的预期。
如果此结果是可靠的,那么它表明 Keras 中无状态和有状态 LSTM 网络之间除了内部状态重置的时间之外,没有其他实现细节上的差异。
|
1 2 3 4 5 6 7 8 9 |
stateful_batch12 stateless_batch12 计数 10.000000 10.000000 平均值 97.920126 97.450757 标准差 6.526297 5.707647 最小值 92.723660 91.203493 25% 94.215807 93.888928 50% 95.770862 95.640314 75% 99.338368 98.540688 最大值 114.567780 110.014679 |
还创建了一个箱形图来比较分布。
该图证实了描述性统计中的说法,也许只是突显了实验设计的可变性。
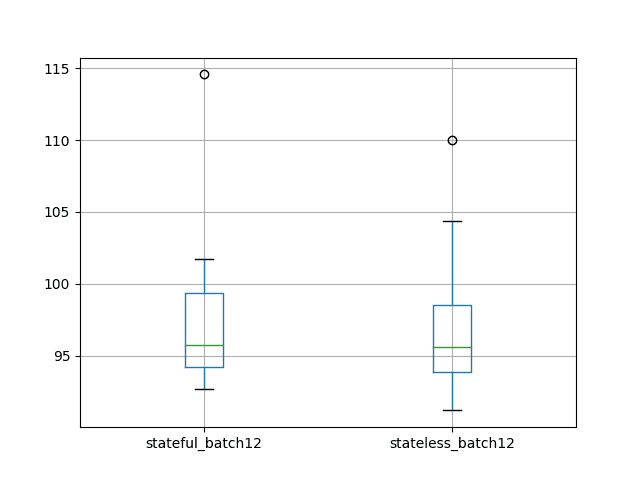
有状态 vs 无状态大批次大小 LSTM 结果的测试 RMSE 箱形图
有状态重置 vs 无状态
关于有状态 LSTM 的另一个问题是执行重置状态的最佳机制。
通常,我们期望在每次呈现序列后重置状态是一个好主意。
- 预期 4:每次训练周期后重置状态可提高测试性能。
这会引发一个问题,即如何最好地管理状态以进行预测。例如,是否应该通过首先在训练数据集上进行预测来为网络播种状态?
- 预期 5:通过在测试数据集上进行预测之前在训练数据集上进行预测来播种 LSTM 状态可提高测试性能。
我们也期望在测试集上进行一次性预测时,不重置 LSTM 状态会是一个好主意。
- 预期 6:在测试集上进行一次性预测时,不重置状态可提高测试集性能。
此外,还有是否重置状态的问题。在本节中,我们将尝试找出这些问题的答案。
我们将再次使用所有可用数据和批次大小为 1 进行一次性预测。
总结来说,我们将比较以下实验设置
无播种
- noseed_1:每次训练周期后重置状态,测试时不重置(第一个实验中的有状态结果,在 `experiment_stateful.csv` 中)。
- noseed_2:每次训练周期后重置状态,并且在每次一次性预测后重置状态(`experiment_stateful_reset_test.csv`)。
- noseed_3:训练或进行一次性预测后不重置状态(`experiment_stateful_noreset.csv`)。
播种
- seed_1:每次训练周期后重置状态,在进行测试数据集的一次性预测之前,使用训练数据集的预测来播种状态(`experiment_stateful_seed_train.csv`)。
- seed_2:每次训练周期后重置状态,在进行测试数据集的一次性预测之前,使用训练数据集的预测来播种状态,并在训练和测试集上每次一次性预测后重置状态(`experiment_stateful_seed_train_resets.csv`)。
- seed_3:在进行一次性预测之前,在训练数据集上播种状态,在训练或预测期间不重置状态(`experiment_stateful_seed_train_no_resets.csv`)。
第一个“A vs A”实验中的有状态实验代码用作基础。
下面列出了创建这些 6 个实验所需的各种重置/不重置和播种/不播种的修改。
我们可以通过在每次测试后添加 `reset_states()` 的调用来更新 `forecast_lstm()` 函数,以便在每次预测后更新模型。更新的 `forecast_lstm()` 函数列在下面。
|
1 2 3 4 5 6 |
# 进行一步预测 def forecast_lstm(model, batch_size, X): X = X.reshape(1, 1, len(X)) yhat = model.predict(X, batch_size=batch_size) model.reset_states() return yhat[0,0] |
我们可以通过删除 `reset_states()` 的调用来更新 `fit_lstm()` 函数,使其在每个周期后不重置。完整的函数列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 训练一个 LSTM 网络 def fit_lstm(train, batch_size, nb_epoch, neurons): X, y = train[:, 0:-1], train[:, -1] X = X.reshape(X.shape[0], 1, X.shape[1]) model = Sequential() model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True)) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') for i in range(nb_epoch): model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False) return model |
我们可以通过循环遍历训练数据集并进行一次性预测来播种 LSTM 的状态,即在训练后使用训练数据集上的预测状态。这可以在进行测试数据集的一次性预测之前添加到 `run()` 函数中。更新的 `run()` 函数列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# 运行重复实验 def experiment(repeats, series): # 将数据转换为平稳 raw_values = series.values diff_values = difference(raw_values, 1) # 将数据转换为监督学习 supervised = timeseries_to_supervised(diff_values, 1) supervised_values = supervised.values[1:,:] # 将数据分割成训练集和测试集 train, test = supervised_values[0:-12, :], supervised_values[-12:, :] # 转换数据尺度 scaler, train_scaled, test_scaled = scale(train, test) # 运行实验 error_scores = list() for r in range(repeats): # 拟合基础模型 lstm_model = fit_lstm(train_scaled, 1, 1000, 1) # forecast train dataset for i in range(len(train_scaled)): X, y = train_scaled[i, 0:-1], train_scaled[i, -1] yhat = forecast_lstm(lstm_model, 1, X) # 预测测试数据集 predictions = list() for i in range(len(test_scaled)): # 预测 X, y = test_scaled[i, 0:-1], test_scaled[i, -1] yhat = forecast_lstm(lstm_model, 1, X) # 反转缩放 yhat = invert_scale(scaler, X, yhat) # 反转差分 yhat = inverse_difference(raw_values, yhat, len(test_scaled)+1-i) # 存储预测 predictions.append(yhat) # 报告性能 rmse = sqrt(mean_squared_error(raw_values[-12:], predictions)) print('%d) Test RMSE: %.3f' % (r+1, rmse)) error_scores.append(rmse) return error_scores |
至此,完成了创建这 6 个实验代码所需的所有分段修改。
运行这些实验后,您将获得以下结果文件
- experiment_stateful.csv
- experiment_stateful_reset_test.csv
- experiment_stateful_noreset.csv
- experiment_stateful_seed_train.csv
- experiment_stateful_seed_train_resets.csv
- experiment_stateful_seed_train_no_resets.csv
我们现在可以比较结果,使用下面的脚本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from pandas import DataFrame from pandas import read_csv from matplotlib import pyplot # 加载结果到数据框 filenames = ['experiment_stateful.csv', 'experiment_stateful_reset_test.csv', 'experiment_stateful_noreset.csv', 'experiment_stateful_seed_train.csv', 'experiment_stateful_seed_train_resets.csv', 'experiment_stateful_seed_train_no_resets.csv'] results = DataFrame() for name in filenames: results[name] = read_csv(name, header=0) results.columns = ['noseed_1', 'noseed_2', 'noseed_3', 'seed_1', 'seed_2', 'seed_3'] # 总结所有结果 print(results.describe()) # 箱线图 results.boxplot() pyplot.show() |
运行比较后,将打印每组结果的描述性统计数据。
注意:您的结果可能因算法或评估程序的随机性,或数值精度的差异而有所不同。请考虑运行示例几次并比较平均结果。
无播种的结果表明,在测试数据集上进行预测后重置状态与不重置状态之间差异不大。这表明从一次预测到另一次预测积累的任何状态都没有增加价值,或者该状态已通过 Keras API 隐式清除。这是一个令人惊讶的结果。
无播种案例的结果也表明,训练期间不重置状态会导致比在每个周期结束时重置状态更差的平均性能和更大的方差。这证实了在每个训练周期结束时重置状态是一个好习惯的预期。
播种实验的平均结果表明,在测试数据集上进行预测之前,使用训练数据集的预测来播种 LSTM 状态是中性的,如果不是略差的话。
在训练和测试集上每次预测后重置状态似乎能获得稍好的性能,而训练或测试期间不重置状态似乎能获得最佳性能。
关于播种的这些结果令人惊讶,但我们应该注意到,平均值都在每月洗发水销售的 5 个测试 RMSE 范围内,可能是统计噪声。
|
1 2 3 4 5 6 7 8 9 |
noseed_1 noseed_2 noseed_3 seed_1 seed_2 seed_3 计数 10.000000 10.000000 10.000000 10.000000 10.000000 10.000000 平均值 103.142903 101.757034 110.441021 105.468200 100.093551 98.766432 标准差 7.109461 14.584442 24.539690 5.206674 4.157095 11.573366 最小值 94.052380 91.264712 87.262549 97.683535 95.913385 90.005843 25% 96.765985 93.218929 94.610724 100.974693 96.721924 91.203879 50% 104.376252 96.144883 99.483971 106.036240 98.779770 95.079716 75% 107.753516 105.657586 121.586508 109.829793 103.082791 100.500867 最大值 114.958430 138.752321 166.527902 112.691046 108.070145 128.261354 |
还创建了一个箱形图来比较分布。
该图讲述了与描述性统计相同的故事。它突显了在没有播种的情况下,对无状态 LSTM 不进行重置时数据散布的增加。它还突显了播种 LSTM 状态的实验的普遍紧密散布。
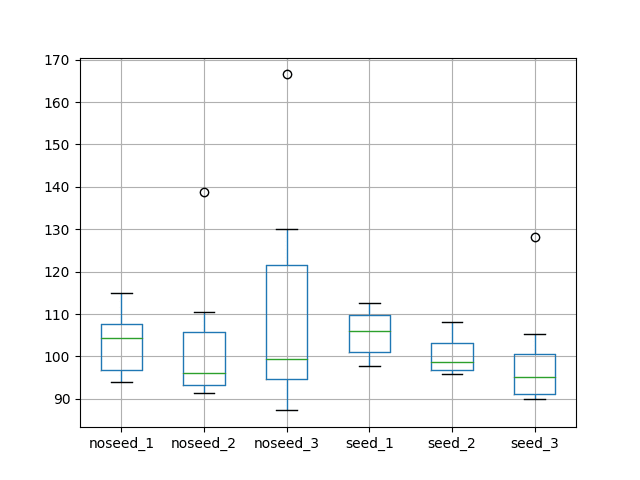
有状态 LSTM 中重置机制的测试 RMSE 箱形图
结果回顾
在本节中,我们回顾了整个教程中的发现。
- 对选定配置的实验重复 10 次,会导致测试 RMSE 的均值和标准差出现一些变化,大约为每月洗发水销售额的 3 个单位。更多的重复有望收紧这一点。
- 对于这个问题,具有相同配置的无状态 LSTM 可能比有状态版本表现更好。
- 在无状态 LSTM 中不对训练模式进行洗牌可能导致性能略有提高。
- 当使用大批次大小时,可以使用无状态 LSTM 来模拟有状态 LSTM。
- 在使用有状态 LSTM 进行一次性预测时重置状态可能会提高测试集的性能。
- 通过在测试数据集上进行预测之前,在训练数据集上进行预测来播种有状态 LSTM 的状态,并不会在测试集上带来明显的性能提升。
- 拟合一个有状态 LSTM,并在训练数据集上对其进行播种,并且在训练或预测期间不进行任何状态重置,可能会在测试集上获得更好的性能。
必须指出的是,这些发现应通过增加每个实验的重复次数并使用统计显著性检验确认差异是否显著来使其更加稳健。
还应指出的是,这些结果适用于这个特定问题、其表述方式以及所选的 LSTM 配置参数,包括拓扑结构、批次大小和训练周期。
总结
在本教程中,您将了解如何在 Python 中使用 Keras 对时间序列预测的有状态 vs 无状态 LSTM 网络的影响进行调查。
具体来说,你学到了:
- 如何比较用于时间序列预测的无状态 vs 有状态 LSTM 网络。
- 如何确认无状态 LSTM 和具有大批次大小的有状态 LSTM 的等效性。
- 如何评估 LSTM 状态在训练期间重置以及在使用 Keras LSTM 网络进行时间序列预测时如何影响性能。
您有任何问题吗?在评论区提问,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。






嗨,Jason,
主题和文章都很棒。
当数据有多个特征/标签对时间序列有强烈的相关性(假定很强)时,我们该如何处理?例如
年份 月份 产量 销售额
1999 1 洗发水 $400
1999 1 护发素 $300
1999 2 洗发水 $410
1999 2 护发素 $305
在这种情况下,我们希望构建一个单一模型来预测洗发水/护发素的销售额。
这是否通过将批次设置为 2 个有状态(或无状态情况下的 24 个)来配置,还是我完全看错了?
与其他算法一样。
探索在模型中使用所有特征,探索移除高度相关的特征,看看这对模型有何影响。
嗨,Jason,
我一直关注您关于 LSTM 和时间序列的博客文章,我很喜欢。我有一个关于不太符合博客文章内容的问题,但也许您愿意分享您的想法,因为我在这方面相对较新。我有一个由 61 个多变量时间序列组成的数据集。在预处理中,我为每个时间序列分配了一个标签(0、1 或 2)。
我想使用 LSTM 进行多类分类。
作为起点,我使用了以下代码:
model.add(LSTM(61, input_shape=(1, 61)))
model.add(Dense(3, activation=’softmax’))
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
并以批次大小 1 训练了 150 个周期。数据集分为训练集和测试集。
我已经获得了 97% 的准确率。我认为这部分是由于数据分布,因为标签一的发生频率约为 94%,而其他两个标签的频率大致相等。尽管如此,这仍然比始终预测标签一要好。
在接下来的步骤中,我将首先调整批次大小,并管理内存单元。
您是否有其他建议可以提高准确率,或者根据您的经验,是否有其他事情可以做得更好?或者是否有理由将问题转变为预测问题?
总的来说,我有 3 个问题
1) 预测的标签与真实标签并非 100% 重叠。我认为这不太糟糕。
2) 我有一些标签在两个标签之间跳跃/振荡。我认为这可以通过其他参数设置来改善。但总的来说,是否有推荐的标准技术来处理这些标签,例如移动平均?
3) 完全错误的标签区域
您会建议调整数据分布,使每个标签出现的频率相等吗?
致以诚挚的问候,
chris
你好 Chris,
如果您的类别不平衡,请考虑使用不同的度量标准而不是准确率来真正了解模型的技能,例如混淆矩阵、对数损失或 AUC。
尝试量化模型究竟在犯哪种类型的错误。
如果数据存在冲突,请找到解决冲突的方法,也许可以使用时间轴或其他变量(特征工程)。
我知道的大多数重新平衡数据的方法都不适用于时间序列数据,例如
https://machinelearning.org.cn/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
我在提高深度学习模型的技能方面有一套通用想法,请参阅此处。
https://machinelearning.org.cn/improve-deep-learning-performance/
希望这些能作为一个开始有所帮助。
早上好,感谢您的快速回复。我昨天开始使用混淆矩阵????。对对数损失我还没想过。
特征工程的想法听起来真的很好,因为我的 0 和 2 标签总是有相同大小的范围。我认为,我将在稍后研究重新平衡,并首先尝试其他方法。感谢您的建议!我会随时向您汇报。
做得好,让我知道进展如何。
嗨,Jason,
再次感谢您最后的建议。
目前我得到了相当不错的结果。每个类别的 AUC 都在 96-99 之间,F-Measure 也比以前使用的所有模型都要好。
我仍然有一些标签的跳跃,但我认为我肯定可以减少它们。
我现在的问题是,我目前使用了 37 个甚至 62 个不同的特征。
我想进行特征选择。不幸的是,我还没有在 Keras/神经网络中找到任何东西。您是否知道有什么可用于神经网络,甚至有经验的?或者对于神经网络来说这不是一个标准实践?谢谢
你好 Chris,
我建议在建模之前(预处理阶段)使用 sklearn 进行特征选择。
https://machinelearning.org.cn/feature-selection-machine-learning-python/
你好 Jason,在 PyCharm 中运行第二个(较大的)代码块时,我得到“UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xf6 in position 22: invalid start byte”,在 Spyder 中似乎可以工作,但
此致 George
我建议从命令行运行所有代码。
嗨,Jason,
很棒的文章!也许您能帮我解决我的问题?
我有一个表示雷达记录的移动目标的序列数据。某些目标的序列比其他目标长。
例如,
我有汽车及其速度、加速度等的标记数据。
“c”代表具有三维特征向量的汽车,“age”是雷达记录目标次数的次数。“Label”表示不同类型的汽车,例如卡车等。
c1 = [2,3,5], 标签 = 0, 年龄 = 1
c2 = [2,4,7], 标签 = 1, 年龄 = 1
c3 = [5,6,3], 标签 = 2, 年龄 = 1
c1 = [4,5,7], 标签 = 0, 年龄 = 2
c1 = [5,7,8], 标签 = 0, 年龄 = 3
c2 = [6,7,4], 标签 = 1, 年龄 = 2
c1 = [1,3,8], 标签 = 0, 年龄 = 4
c3 = [5,6,3], 标签 = 2, 年龄 = 2
正如你所见,某些目标的序列比其他目标长。
我的问题是,在创建 LSTM 模型时,如何处理这种情况?
例如,选择窗口大小为 2,我将得到 [c1, c2, c3]、[c2, c3, c1] 等……
在这种情况下,标签会发生什么?
这是一个分类问题,那么有状态网络还是无状态网络更合适?
谢谢你,
Kris
抱歉,我不太明白。
可以考虑将整个序列作为输入时间步。
还可以考虑填充序列以使其长度相同,如果时间步数不同。
嗨 Jason!我对无状态 LSTM 有些想法。
LSTM 的主要目的是利用其记忆属性。基于此,无状态 LSTM 的存在意义是什么?我们不是通过这样做将其“转换为”简单的神经网络吗?
换句话说……无状态 LSTM 的使用是否旨在对输入数据中的序列(窗口)进行建模(如果我们将在 Keras 的 fit 层中设置 shuffle=False)——(例如,对于一个时间步为 10 的窗口,捕捉 10 个字符单词之间的任何模式)?如果是,为什么我们不将初始输入数据转换为与正在检查的序列的形式匹配,然后使用普通神经网络(通过向原始数据集添加额外的列并移位)?
如果我们选择 shuffle = True,那么我们是不是会丢失我们数据中可能存在的任何信息(例如时间序列数据——序列)?那样的话,我期望它表现得像一个普通的神经网络,并且通过设置相同的随机种子,我们可以从两者中获得相同的结果。
我是否遗漏了什么?
“无状态” LSTM 仅仅意味着每个批次的内部状态都会被重置,这在许多问题上实际上效果很好。
事实上,保持状态是反向传播通过时间(BPTT)和输入序列长度权衡的一部分。
Shuffle 适用于批次内的样本。BPTT 实际上查看的是样本内的时间步,然后对批次中的梯度进行平均。
这有帮助吗?
关于文档中提到的洗牌,“shuffle: boolean or str (for ‘batch’). Whether to shuffle the samples at each epoch”。所以它首先重新采样数据(即改变原始顺序),然后在新的顺序上创建批次。我理解得对吗?
让我重申一下我之前的问题,因为我可能让你感到困惑了。假设数据集只有一个变量 X 和一个标签 Y。我想知道批次大小为 5 且时间步长为 1 的无状态 LSTM 是否等同于一个接收 X 和 X.shift(1) 作为输入的神经网络(总共 2 个输入(2 列),尽管它们指向我数据集的同一个原始 X 列,并且批次大小也为 5)。
提前感谢,并祝贺你的有用网站!
即使你以相同的方式为 LSTM 和 MLP 解决序列问题,每个网络中的单元也不同(例如,LSTM 具有记忆和门)。反过来,结果可能会有所不同。
我鼓励你在你的问题上测试这两种网络,最重要的是,头脑风暴多种不同的方法来解决你的序列预测问题,看看哪种方法最有效。
我的问题与 LSTM 没有太大关系。
“转换观测值以具有特定的尺度。特别是,将数据重缩放到 -1 到 1 之间的值,以满足 LSTM 模型默认的双曲正切激活函数。”
我经常遇到这个评论,即数据应该准备好以适应激活函数的 Y 范围。因此,我一直在尝试找到这种转换的直觉或理论原因,但除了 SO 上的讨论之外,一无所获。
我将非常感谢您能就以下问题提供您的见解。
a) 为什么需要进行这种转换
b) 这种转换是否适用于所有其他激活函数(例如,sigmoid 为 [0,1] 等)?
诚挚地,
YJ
总的来说,标准化或标准化数据确实有助于神经网络。我建议测试是否进行以及不进行此操作,看看它如何影响模型技能。
嗨,Jason,
你觉得使用回调来重置状态以允许在整个数据集上使用 model.fit() 怎么样?有什么理由不这样做吗?
此致
如果它非常适合你的模型/设置,那就去做吧。
你好,
感谢这篇精彩的文章。
我有两个关于在训练 LSTM 网络时如何处理这些长序列的问题。
假设我有一个序列分类任务,我有一组 100 个序列,每个序列的长度各不相同,范围在 1000 到 2000 个样本之间。我需要序列分类任务以固定的间隔(例如,每 10 或 20 个样本)识别序列中的序列。
输入序列
序列 1:s1_1,s1_2,s1_3………………….s1_1000
序列 2:s2_1,s2_2,s2_3………………….s2_1500
序列 3:s3_1,s3_2,s3_3………………….s3_2000
.
.
.
序列 100:s100_1,s100_2,s100_3………………….s100_1100
a. 我如何预处理数据,即如何将数据分解成子序列进行训练?子序列长度是根据输出对输入样本数量的依赖性来确定的吗?
b. 如果我的序列分类输出取决于序列中的最后 20 个样本,我该如何分割输入数据序列进行训练?
i. 应该是这样吗:重叠子序列和无状态 LSTM
s1_1,s1_2,…….s1_20
s1_2,s1_3……..s1_21
s1_3,s1_4……..s1_22
ii. 还是应该是这样:不重叠子序列和有状态 LSTM
s1_1,s1_2,…….s1_20
s1_21,s1_22……..s1_40
s1_41,s1_42……..s1_60
以上两种方法(i 和 ii)哪种是正确的?为什么?
方法 ii. 是否能学习到比 20 个样本更长的依赖关系……因为状态在每个子序列之后都会被传递?如果可以,最多能学习到多少个样本……例如 60 或 100?
c. 如果我的序列分类输出取决于序列中的最后 900 个样本,LSTM 能解决/处理这个问题吗?如果可以,在这种情况下,单个训练序列的分割是什么样的,LSTM 实现是什么(有状态或无状态)?
这篇文章将为你提供有关如何准备数据的想法。
https://machinelearning.org.cn/reshape-input-data-long-short-term-memory-networks-keras/
还有这篇文章
https://machinelearning.org.cn/prepare-univariate-time-series-data-long-short-term-memory-networks/
我认为你指的是 20 个时间步,而不是 20 个样本。
我将进一步鼓励你探索你的序列分类问题的许多不同框架,看看哪种最适合你的特定数据。
嗨,Jason博士,
非常感谢你的教程,它们非常有帮助。
我正在尝试实现一个无状态 LSTM,不进行洗牌。我基本使用了你的代码,只做了你建议的修改,但不幸的是,我遇到了以下错误:
GPU sync failed
你是否知道我为什么会收到此错误?
谢谢你
Nat
这看起来像是你的 Python 环境有问题。也许可以把错误发到 stackoverflow 上?
嗨,Jason,
我正在处理一个行业问题,我们正试图根据大量数据集(机器数据、传感器数据等)来预测制造生产线上的废品率。一种方法是将问题建模为 RNN 中的时间序列(序列)回归问题。我经常使用你的博客作为非常有用的资源(谢谢!)。
原型设计在 Keras 中完成,因此,我有以下问题:
两个参数建议会影响序列学习问题
– batch_size in model.fit(batch_size)
– time_steps in layers.LSTM(input_shape(samples,time_steps,obs)
-> 如果 batch_size < time_steps,内部状态是否会被过于频繁地重置,并导致 BPTT 出问题?
例如,假设我们有一个长度为 50(time_steps=50)的序列和一个训练批次大小为 25(例如,用于随机梯度下降 batch_size=25)。即使 TBPTT(50,50) 设置为从 50 个时间步学习序列模式,内部状态也能保留信息吗?
非常感谢,来自德国的问候
最大值
时间步长和批次大小无关。批次大小涵盖样本数量,而时间步长指的是一个样本。
这有帮助吗?
嗨,Jason,
有状态 LSTM 的可变批次大小怎么样?
https://stackoverflow.com/questions/53489606/keras-variable-batch-size-for-stateful-lstm
也许你能为我总结一下链接的内容?
哦,我会尝试在这里总结,所以如果有什么不清楚的,请告诉我。
首先,我已经在链接中解决了我的问题,这要归功于你关于为不同批次大小的 LSTM 进行预测保存权重的教程,但我有一个准确性问题。
其次,我有 4 个特征,我使用最后一个特征进行训练,也作为目标。感谢你的教程,我能够重塑数据并构建以下有状态架构,注意其窗口大小为 10。
n_batch = X_train[0].shape[0]
n_epoch = 25
n_neurons = 256
model = Sequential()
model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X_train[0].shape[1], X_train[0].shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss=’mae’, optimizer=’adam’, metrics=[‘accuracy’])
# 拟合网络
for i in range(len(X_train))
if X_train[i].shape[0] == 250
model.fit(X_train[i], y_train[i], epochs=n_epoch, batch_size=n_batch, verbose=1, shuffle=False)
#model.reset_states()
注意,注释掉 reset_states() 或不注释它都不会影响准确性。
第三,我不确定我是否正确计算了准确率和损失,是否使用了正确的优化器,是否使用了什么激活函数,是否应该堆叠更多的 LSTM。为什么有状态 LSTM 不影响学习。
此外,最后一个特征具有很大的正值和负值,不超过 1000。那么如何正确地进行归一化呢。
我尝试使用下面的行进行归一化,但没有任何改变,仍然是 0% 的准确率!
m15 = m15.assign(NormDirHeight=(m15[‘DirHeight’]-m15[‘DirHeight’].mean())/m15[‘DirHeight’].std())
如果你的问题是回归(预测一个数量而不是一个标签),你无法计算准确率,更多内容请看这里。
https://machinelearning.org.cn/classification-versus-regression-in-machine-learning/
也许可以使用 scikit-learn 库中的 MinMaxScaler 对数据进行归一化?
首先,非常感谢你,你的教程非常棒,也超级有趣,这是我想说的。
抱歉在这里倾倒日志。
好的,所以使用 mae 作为指标,我得到了以下结果,没有使用 MinMaxScaler。
Epoch 1/25
250/250 [==============================] – 1s 3ms/step – loss: 140.9831 – mean_absolute_error: 140.9831
Epoch 2/25
250/250 [==============================] – 0s 440us/step – loss: 140.9362 – mean_absolute_error: 140.9362
Epoch 3/25
250/250 [==============================] – 0s 464us/step – loss: 140.8762 – mean_absolute_error: 140.8762
Epoch 4/25
250/250 [==============================] – 0s 456us/step – loss: 140.8182 – mean_absolute_error: 140.8182
Epoch 5/25
250/250 [==============================] – 0s 464us/step – loss: 140.7660 – mean_absolute_error: 140.7660
Epoch 6/25
250/250 [==============================] – 0s 440us/step – loss: 140.7117 – mean_absolute_error: 140.7117
Epoch 7/25
250/250 [==============================] – 0s 456us/step – loss: 140.6606 – mean_absolute_error: 140.6606
Epoch 8/25
250/250 [==============================] – 0s 440us/step – loss: 140.6121 – mean_absolute_error: 140.6121
Epoch 9/25
250/250 [==============================] – 0s 512us/step – loss: 140.5622 – mean_absolute_error: 140.5622
Epoch 10/25
好的,使用 mae 作为准确率指标,我得到了以下结果,使用了 MinMaxScaler(-1,1)。
Epoch 1/25
250/250 [==============================] – 1s 3ms/step – loss: 0.0601 – mean_absolute_error: 0.0601
Epoch 2/25
250/250 [==============================] – 0s 444us/step – loss: 0.1010 – mean_absolute_error: 0.1010
Epoch 3/25
250/250 [==============================] – 0s 456us/step – loss: 0.0610 – mean_absolute_error: 0.0610
Epoch 4/25
250/250 [==============================] – 0s 456us/step – loss: 0.0732 – mean_absolute_error: 0.0732
Epoch 5/25
250/250 [==============================] – 0s 480us/step – loss: 0.0759 – mean_absolute_error: 0.0759
Epoch 6/25
250/250 [==============================] – 0s 524us/step – loss: 0.0619 – mean_absolute_error: 0.0619
Epoch 7/25
250/250 [==============================] – 0s 480us/step – loss: 0.0597 – mean_absolute_error: 0.0597
Epoch 8/25
250/250 [==============================] – 0s 484us/step – loss: 0.0613 – mean_absolute_error: 0.0613
Epoch 9/25
但是,如果我不计算准确率,我怎么知道这是好是坏?
另外,为什么无论是否使用 reset_states() 结果都一样?
有状态 LSTM 非常令人困惑,尽管如此,从这里到使用 TimeDistributed 预测多个步长又是另一段有趣的旅程了 xD
好问题,我在这里回答
https://machinelearning.org.cn/faq/single-faq/how-to-know-if-a-model-has-good-performance
我能够显示实际值和预测值,在应用了逆变换之后,显然这是一团糟。是数据的问题还是架构的问题,我怎么知道?
>预期=182.0, 预测=-3.9
>预期=-73.0, 预测=-31.3
>预期=-49.0, 预测=-10.6
>预期=48.0, 预测=-7.8
>预期=46.0, 预测=-12.8
>预期=-41.0, 预测=-19.9
>预期=-66.0, 预测=-13.6
>预期=22.0, 预测=-1.8
>预期=87.0, 预测=-14.1
>预期=47.0, 预测=-33.3
>预期=31.0, 预测=-30.5
好的,我还有最后一个问题,我怎么知道问题不在我的数据上?
我的意思是,我总是得到相同的糟糕的准确率,是数据有问题吗?是否有任何方法可以检查数据的连贯性,使其能够用 LSTM 进行回归函数?
从一个简单的基线开始,然后评估模型相对于该基线的表现,看看它们是否具有技巧性。我在这里解释了这个过程。
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
非常感谢,我仔细阅读了这篇文章,分析了我完成了多少内容,以及我跳过了哪些步骤,并制定了一个行动计划。你真是个很棒的博客,感谢你出色且快速的回复!
谢谢。
感谢这篇精彩的文章!
我有一个问题。我尝试在信号上训练一个 LSTM 自编码器。我想知道以下两者之间的区别:
1)我使用一个无状态网络并将整个信号作为输入,并将批次大小设置为 1。
2)我使用一个有状态网络,并在 for 循环中,在 train_on_batch en 每个输入信号之后重置状态。
??
区别不大。
嗨,Jason,
在有状态模型中,Keras 的回调(EarlyStopping、ReduceLROnPlateau 和 ModelCheckpoint)不起作用。
因为我们在每次迭代后重置状态,并且每次迭代之间只有一个 epoch,因此 Keras 无法找到前几个 epoch 的日志,因此无法应用上述回调。
那么,我该如何实现 EarlyStopping、ReduceLROnPlateau 和 ModelCheckpoint?
如果你是手动驱动 epoch,那么也许回调是不需要的(只是一个想法?),你也可以手动运行它们的操作。例如,评估模型并查看下一迭代是否需要。
您好,布朗利,
你读过任何讨论有状态和无状态实现的论文吗?
谢谢
你具体指的是什么?
先生,
多变量时间序列数据集是否可能使用有状态和无状态 LSTM?
是的。
谢谢……有用的博客……有用的文章……太棒了。
谢谢。很高兴有帮助。
嗨,Jason,
感谢您分享的所有资源,它们非常棒。
我正在尝试将自定义损失函数应用于 LSTM 网络,没什么特别的,只是 RMSE 加上反向最小最大缩放器,使用以下函数:
def RMSE_inverse(y_true, y_pred)
y_true = (y_true – K.constant(scaler.min_)) / K.constant(scaler.scale_)
y_pred = (y_pred – K.constant(scaler.min_)) / K.constant(scaler.scale_)
return K.sqrt(K.mean(K.square(y_pred – y_true)))
出于某种原因,我的损失值与你示例中的 RMSE 计算不同。
纪元 1/1
22/22 [==============================] – 0s 4ms/step – loss: 75.2212 – val_loss: 113.2487
1)测试 RMSE:138.084
几乎所有其他代码都与你的示例相同。
任何帮助都将是极好的!
谢谢。
谢谢!
我认为 epoch 损失是所有批次的平均值。
啊,好的,这有道理。
我正在尝试将 LSTM 与简单的预测进行比较。你认为 epoch 损失还是测试 RMSE 更适合比较?
谢谢!
使用损失来调整学习,使用 RMSE 进行比较。
嗨,Jason,
很棒的教程。我只有一个问题,在数据准备的第 3 步中,你说:
“转换观测值以具有特定的尺度。特别是,将数据重缩放到 -1 到 1 之间的值,以满足 LSTM 模型默认的双曲正切激活函数。”
你为什么要把输入缩放到 -1 到 1 之间?tanh 的定义域是整个实数线,范围是 -1 到 1,所以为什么不缩放到 [0,1] 或其他范围?我知道 tanh 的活动区域是 [-2, 2],但我不明白你的逻辑。
将数据缩放到 LSTM 层输出的范围内是一个好习惯。
我不再这样做,我发现缩放到 0-1 甚至不缩放就足够了。请参阅这里的教程。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
嗨,Jason,
又一篇精彩的文章。我有一个关于预测样本大小的疑问。假设在训练期间我的 batch_size=32,并且是一个 stateful=True 网络,我需要在输入层本身指定 batch_size。
现在在预测时,它期望批次大小与训练时使用的相同。但如果我想预测少于 32 条记录,我是否需要填充整个序列直到大小为 32?提前感谢。
此致,Tanmay
谢谢。
好问题!!!
是的,我在这里有一个解决方案。
https://machinelearning.org.cn/use-different-batch-sizes-training-predicting-python-keras/
尊敬的Jason博士,
非常感谢您的教程。
我遇到了一个错误,而且我无法弄清楚哪里出错了。
当我尝试加载这些文件时:“experiment_stateful.csv”和“experiment_stateful2.csv”
我像你的脚本一样加载它,但在这些行中抛出了错误“ValueError: Cannot set a frame with no defined index and a value that cannot be converted to a Series”。
[for name in filenames
results[name[11:-4]] = read_csv(name, header=0)]
我正在使用 panda 1.0.1 和 Python 3.7,抱歉,我相对来说是这个领域的新手,我希望你能帮助我解释并提供其他补充教程的建议。
非常感谢!
此致,Hazard
我很遗憾听到这个消息,你是否有可能跳过了一些代码或步骤?
这个可能会有帮助
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
谢谢你的回复,代码的前两部分运行顺利,并给了我两个预期的输出文件。但是,在这一行:
results[name[11:-4]] = read_csv(name, header=0)
我认为 index[11:-4] 包含一个未定义的索引,如显示的错误所示。您能否建议我可能出错了什么,或者在哪里可以进一步查找?
提前感谢。
您必须在教程的第一部分运行实验代码,以创建教程第二部分所需的CSV文件。
感谢您的回复。我运行了第一部分,并从我第一次评论时就获得了CSV文件,但是在我加载文件进行比较的部分,遇到了提到的错误。再次抱歉,因为我在这个领域缺乏经验而占用您的时间。我设法修改了代码,并使用pandas concat方法显示如下:
for name in filenames
df = read_csv(name, header=0)
df[‘name’] = name
results = pd.concat([results, df])
# 总结所有结果
print(results.describe())
# 箱线图
results.boxplot(by=’name’)
pyplot.show()
您能帮我理解您脚本中的“results[name[11:-4]]”出了什么问题吗?
它从相应的文件名中提取字符串“stateful”和“stateful2”,并将它们用作结果字典中的键。
太好了!非常感谢您的时间和帮助。我通过在代码中添加[]使其生效了
results[[name[11:-4]]] = read_csv(name, header=0)
我认为更新后的pandas版本可能有些变化。Jason博士的教程太棒了!
说得有理。
不是pandas,是Python 3的字符串切片。
我漏掉了一些东西。我明白这个模型试图预测一个“已知的”销售额。我不明白的是,你将如何使用它来预测“已知”销售历史之外的销售额?你如何使用这个模型在最后“已知”销售日期之后继续进行预测?
在所有数据上拟合模型,然后调用predict()以进行样本外预测。
也许这会有帮助。
https://machinelearning.org.cn/make-predictions-long-short-term-memory-models-keras/
嗨 Jason,这是一篇很棒的文章。
我认为在“Expectation:2”行之后有一个错别字。
“将stateful LSTM示例代码更改为stateless,涉及在LSTM层中设置stateless=False”
您写了“stateless=False”,而那里应该是“stateful=False”。
谢谢!已修复。
你好,我还没有看到有人在训练中使用stateful LSTM时在验证数据上评估损失函数。这可能吗?我不确定状态是如何处理的,因为在使用stateful网络时,您可能需要为训练数据和验证数据使用不同的状态,对吗?
您必须手动为每个epoch执行此操作——我会这样做。
那么,在每个epoch之后重置模型并在验证数据上进行评估?这有道理,但我担心在Keras中这会使训练非常缓慢。
谢谢你
当然会!
您好,布朗利先生,
感谢这篇精彩的文章。我从中获益良多。我有一个关于多元化问题的问题。我的输出(例如O1)看起来与这里显示的非常相似,有自己的趋势和季节性,但我的输入信号不同(例如I1, I2)。在这种情况下,是否应该使所有输入和输出信号都平稳(无论I1和I2是否有季节性),然后尝试通过stateful LSTM来处理,还是您推荐其他方法?
期待您的回复。
此致,
Gopal。
不客气。
是的,尝试在建模前使数据平稳,并与在原始数据上拟合的模型进行比较。在您的数据集中使用效果更好的方法。
布朗利先生您好,
感谢您的回复。我将继续尝试这种方法。不过还有一个小问题。我有多个包含此类时间序列数据的Excel文件。您能否帮助我理解如何将这些多个数据文件用于训练LSTM网络?将它们拼接在一起会导致突然的下降,因为一个文件的结尾值远低于下一个文件的开头值。所以,我不确定这是否是正确的做法。我将非常感谢您的帮助。
谢谢你,
Gopal
也许每个文件都是一个单独的样本?例如,您可以跨样本学习。
这可能有帮助
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
嘿,杰森!
对于文本分类,哪种方法最好?stateless还是stateful?
我推荐CNN进行文本分类。
https://machinelearning.org.cn/best-practices-document-classification-deep-learning/
在您最初的stateful与stateless的尝试中,您似乎获得了stateless更好的结果,但随后您又展示了当batch size相同时它们给出相同的结果。但对于最初的尝试,您没有显示两者的batch size。在第一次尝试中,您为stateful和stateless设置的batch size是多少?
谢谢。
我相信batch size是1,但我不确定stateless。
我相信batch size是1。
非常感谢您的知识分享!!!
我有一个关于其中一个实验的问题,实验结论是对于stateful模型,每次epoch后重置状态比stateless更好。
在这种情况下,这与stateless模型有什么不同,因为我们显式地重置了状态?
不客气。
区别在于状态是否被重置。也许我不明白你的问题?
如果我们显式地重置stateful模型的状态,那么我们实际上是在做stateless会做的事情。那么,为什么我们要在这里使用stateful而不是stateless呢?
上面的教程对比了这两种方法,stateless与stateful。
Stateless会在每个batch后重置状态,而stateful在上面示例的每个epoch后重置状态。
非常感谢您的文章!
但我错过了一些重要的事情
为什么您也对Y(目标)进行缩放?有必要吗?
我确信——我们只需要缩放X到-1,1或0,1……
Vsevolod你好…以下内容希望能带来一些启发。
https://machinelearning.org.cn/how-to-improve-neural-network-stability-and-modeling-performance-with-data-scaling/
非常感谢,James,现在关于缩放已经清楚了!
关于这篇文章还有另一个问题:为什么使用“difference”函数?我本以为模型应该自己预测任何趋势?为什么我们需要通过这种方式通过移位X来准备?
……另外,您能否建议在哪里可以进一步阅读有关使用-LSTM/TimeDistributed/return_sequences=True在模拟典型目标趋势(非常类似于sin()函数——我可以看到周期)方面的特殊性?
大家好,
我需要一点帮助。
我正在开发一个LSTM网络,它可以仅通过输入当前、电压和环境温度来预测温度。
它在学习第一个输出应该是环境温度方面遇到了困难。那么我如何初始化第一个隐藏/单元状态呢?
我通过Epoch -> Files -> Batches循环。我当然尝试过“model.reset_states(states=[batch size, time steps, features])”但在“Files”循环开始时它不起作用。
数组的形状需要是什么?
提前非常感谢!
Mike你好…以下资源可能有助于阐明如何重塑数据。
https://machinelearning.org.cn/reshape-input-data-long-short-term-memory-networks-keras/
事实上,当我将model.reset_states(states=None)传递到“File”循环的开头时,我得到了“TypeError: reset_states() got an unexpected keyword argument ‘states'”。
我已经设置了stateful=True。
Mike你好…你是复制粘贴的代码还是自己输入的?另外,您可能想在Google Colab中尝试一下,看看是否遇到相同的问题。我认为这有助于排除输入错误。
你好。
在本教程中,您在每次预测后重置。
在其他教程中,他们在训练期间在每个epoch后重置。
哪种方式是正确的?或者有什么区别?