数据集可能存在缺失值,这会给许多机器学习算法带来问题。
因此,在对预测任务进行建模之前,最好识别并替换输入数据中每列的缺失值。这称为缺失数据插补,或简称插补。
数据插补的一种流行方法是为每列计算一个统计值(例如均值),然后用该统计值替换该列的所有缺失值。这是一种流行的方法,因为该统计值易于使用训练数据集计算,并且通常能带来良好的性能。
在本教程中,您将学习如何使用统计插补策略来处理机器学习中的缺失数据。
完成本教程后,您将了解:
- 缺失值必须用 NaN 值标记,并可以用统计量替换以计算值列。
- 如何加载带有缺失值的 CSV 值,并用 NaN 值标记缺失值,并报告每列缺失值的数量和百分比。
- 如何在评估模型时以及将最终模型拟合到新数据以进行预测时,将缺失值与统计量一起作为数据准备方法进行插补。
通过我的新书《机器学习数据准备》**启动您的项目**,其中包括**分步教程**和所有示例的 **Python 源代码文件**。
让我们开始吧。
- 2020年6月更新:更改了示例中用于预测的列。

机器学习中缺失值的统计插补
照片由Bernal Saborio拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 统计插补
- 马疝气数据集
- 使用 SimpleImputer 进行统计插补
- SimpleImputer 数据转换
- SimpleImputer 和模型评估
- 比较不同的插补统计量
- 进行预测时的 SimpleImputer 转换
统计插补
一个数据集可能包含缺失值。
这些是数据行,其中一行中的一个或多个值或列不存在。这些值可能完全缺失,也可能用特殊字符或值(例如问号“?”)标记。
这些值可以通过多种方式表示。我见过它们以空值出现[……],一个空字符串[……],显式字符串NULL或undefined或N/A或NaN,以及数字0等等。无论它们在您的数据集中如何出现,了解预期内容并检查数据是否符合预期将减少您开始使用数据时的问题。
— 第10页,《坏数据手册》,2012年。
值可能因多种原因而缺失,通常特定于问题领域,可能包括测量损坏或数据不可用等原因。
它们可能由于多种原因而发生,例如测量设备故障、数据收集期间实验设计变更以及合并几个相似但不完全相同的数据集。
— 第63页,《数据挖掘:实用机器学习工具和技术》,2016年。
大多数机器学习算法需要数值输入,并且数据集中的每一行和每一列都需要存在一个值。因此,缺失值会给机器学习算法带来问题。
因此,通常会在数据集中识别缺失值并将其替换为数值。这称为数据插补,或缺失数据插补。
一种简单而流行的数据插补方法是使用统计方法从现有值中估计某一列的值,然后用计算出的统计值替换该列中所有缺失的值。
它之所以简单,是因为统计计算速度快;它之所以流行,是因为它通常非常有效。
常见的计算统计量包括:
- 列平均值。
- 列中位数。
- 列众数。
- 一个常数。
现在我们熟悉了缺失值插补的统计方法,接下来让我们看一个包含缺失值的数据集。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
马疝气数据集
马疝气数据集描述了患有疝气的马匹的医学特征以及它们是存活还是死亡。
有300行和26个输入变量,一个输出变量。这是一个二元分类预测任务,涉及预测马匹存活为1,死亡为2。
在这个数据集中,我们可以选择预测许多字段。在这种情况下,我们将预测问题是否为手术(列索引23),使其成为一个二元分类问题。
数据集中许多列都有大量缺失值,每个缺失值都用问号字符(“?”)标记。
下面提供了数据集中带有标记缺失值的行示例。
|
1 2 3 4 5 |
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2 1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2 2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1 1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1 ... |
你可以在此处了解更多关于此数据集的信息:
无需下载数据集,我们将在工作示例中自动下载。
在加载的数据集中使用 Python 将缺失值标记为 NaN(非数字)是一种最佳实践。
我们可以使用 read_csv() Pandas 函数加载数据集,并指定 “na_values” 将值 ‘?‘ 加载为缺失值,标记为 NaN 值。
|
1 2 3 4 |
... # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv' dataframe = read_csv(url, header=None, na_values='?') |
加载后,我们可以查看加载的数据,以确认“?”值已标记为 NaN。
|
1 2 3 |
... # 总结前几行 print(dataframe.head()) |
然后我们可以枚举每一列,并报告该列中带有缺失值的行数。
|
1 2 3 4 5 6 7 |
... # 汇总每列中具有缺失值的行数 for i in range(dataframe.shape[1]): # 计算缺失值行数 n_miss = dataframe[[i]].isnull().sum() perc = n_miss / dataframe.shape[0] * 100 print('> %d, Missing: %d (%.1f%%)' % (i, n_miss, perc)) |
总而言之,下面列出了加载和汇总数据集的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 总结马疝气数据集 from pandas import read_csv # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv' dataframe = read_csv(url, header=None, na_values='?') # 总结前几行 print(dataframe.head()) # 汇总每列中具有缺失值的行数 for i in range(dataframe.shape[1]): # 计算缺失值行数 n_miss = dataframe[[i]].isnull().sum() perc = n_miss / dataframe.shape[0] * 100 print('> %d, Missing: %d (%.1f%%)' % (i, n_miss, perc)) |
运行该示例首先加载数据集并总结前五行。
我们可以看到,原来用“?”字符标记的缺失值已经被NaN值取代了。
|
1 2 3 4 5 6 7 8 |
0 1 2 3 4 5 6 ... 21 22 23 24 25 26 27 0 2.0 1 530101 38.5 66.0 28.0 3.0 ... NaN 2.0 2 11300 0 0 2 1 1.0 1 534817 39.2 88.0 20.0 NaN ... 2.0 3.0 2 2208 0 0 2 2 2.0 1 530334 38.3 40.0 24.0 1.0 ... NaN 1.0 2 0 0 0 1 3 1.0 9 5290409 39.1 164.0 84.0 4.0 ... 5.3 2.0 1 2208 0 0 1 4 2.0 1 530255 37.3 104.0 35.0 NaN ... NaN 2.0 2 4300 0 0 2 [5 行 x 28 列] |
接下来,我们可以看到数据集中所有列的列表,以及缺失值的数量和百分比。
我们可以看到,有些列(例如列索引1和2)没有缺失值,而其他列(例如列索引15和21)有许多甚至大部分缺失值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
> 0,缺失:1 (0.3%) > 1,缺失:0 (0.0%) > 2,缺失:0 (0.0%) > 3,缺失:60 (20.0%) > 4,缺失:24 (8.0%) > 5,缺失:58 (19.3%) > 6,缺失:56 (18.7%) > 7,缺失:69 (23.0%) > 8,缺失:47 (15.7%) > 9,缺失:32 (10.7%) > 10,缺失:55 (18.3%) > 11,缺失:44 (14.7%) > 12,缺失:56 (18.7%) > 13,缺失:104 (34.7%) > 14,缺失:106 (35.3%) > 15,缺失:247 (82.3%) > 16,缺失:102 (34.0%) > 17,缺失:118 (39.3%) > 18,缺失:29 (9.7%) > 19,缺失:33 (11.0%) > 20,缺失:165 (55.0%) > 21,缺失:198 (66.0%) > 22,缺失:1 (0.3%) > 23,缺失:0 (0.0%) > 24,缺失:0 (0.0%) > 25,缺失:0 (0.0%) > 26,缺失:0 (0.0%) > 27,缺失:0 (0.0%) |
现在我们熟悉了包含缺失值的马疝气数据集,接下来我们来看看如何使用统计插补。
使用 SimpleImputer 进行统计插补
scikit-learn 机器学习库提供了支持统计插补的 SimpleImputer 类。
在本节中,我们将探讨如何有效地使用 SimpleImputer 类。
SimpleImputer 数据转换
SimpleImputer 是一种数据转换,首先根据为每列计算的统计量类型(例如均值)进行配置。
|
1 2 3 |
... # 定义插补器 imputer = SimpleImputer(strategy='mean') |
然后将插补器拟合到数据集上,以计算每列的统计量。
|
1 2 3 |
... # 拟合数据集 imputer.fit(X) |
然后将拟合好的插补器应用于数据集,以创建一个数据集副本,其中每列的所有缺失值都替换为统计值。
|
1 2 3 |
... # 转换数据集 Xtrans = imputer.transform(X) |
我们可以通过在转换前后汇总数据集中缺失值的总数,来演示其在马疝气数据集上的用法并确认其有效性。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 马疝气数据集的统计插补转换 from numpy import isnan from pandas import read_csv from sklearn.impute import SimpleImputer # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv' dataframe = read_csv(url, header=None, na_values='?') # 分割输入和输出元素 data = dataframe.values ix = [i for i in range(data.shape[1]) if i != 23] X, y = data[:, ix], data[:, 23] # 打印总缺失值 print('缺失: %d' % sum(isnan(X).flatten())) # 定义插补器 imputer = SimpleImputer(strategy='mean') # 拟合数据集 imputer.fit(X) # 转换数据集 Xtrans = imputer.transform(X) # 打印总缺失值 print('缺失: %d' % sum(isnan(Xtrans).flatten())) |
运行该示例首先加载数据集并报告数据集中缺失值的总数为1,605。
转换被配置、拟合和执行,结果新数据集没有缺失值,确认其按预期执行。
每个缺失值都用其列的平均值代替。
|
1 2 |
缺失:1605 缺失:0 |
SimpleImputer 和模型评估
使用k折交叉验证在数据集上评估机器学习模型是一种良好的实践。
为了正确应用统计缺失数据插补并避免数据泄露,需要仅在训练数据集上计算每列的统计量,然后将这些统计量应用于数据集中每个折叠的训练集和测试集。
如果我们使用重采样来选择调优参数值或估计性能,则插补应包含在重采样中。
— 第42页,《应用预测建模》,2013年。
这可以通过创建一个建模管道来实现,其中第一步是统计插补,然后第二步是模型。这可以使用 Pipeline 类来实现。
例如,下面的*Pipeline*使用了一个策略为“*mean*”的*SimpleImputer*,后面跟着一个随机森林模型。
|
1 2 3 4 5 |
... # 定义建模管道 model = RandomForestClassifier() imputer = SimpleImputer(strategy='mean') pipeline = Pipeline(steps=[('i', imputer), ('m', model)]) |
我们可以使用重复的10折交叉验证来评估马疝气数据集的均值插补和随机森林建模管道。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 评估马疝气数据集的均值插补和随机森林 from numpy import mean from numpy import std from pandas import read_csv from sklearn.ensemble import RandomForestClassifier from sklearn.impute import SimpleImputer from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.pipeline import Pipeline # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv' dataframe = read_csv(url, header=None, na_values='?') # 分割输入和输出元素 data = dataframe.values ix = [i for i in range(data.shape[1]) if i != 23] X, y = data[:, ix], data[:, 23] # 定义建模管道 model = RandomForestClassifier() imputer = SimpleImputer(strategy='mean') pipeline = Pipeline(steps=[('i', imputer), ('m', model)]) # 定义模型评估 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1) print('平均准确度: %.3f (%.3f)' % (mean(scores), std(scores))) |
运行该示例会正确地将数据插补应用于交叉验证过程的每个折叠。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
该管道通过三次重复的10折交叉验证进行评估,并报告数据集的平均分类准确率约为86.3%,这是一个不错的得分。
|
1 |
平均准确度:0.863 (0.054) |
比较不同的插补统计量
我们如何知道使用“均值”统计策略对这个数据集来说是好的或最好的?
答案是,我们不知道,它只是任意选择的。
我们可以设计一个实验来测试每种统计策略,并发现哪种策略最适合这个数据集,比较均值、中位数、众数(最频繁)和常数(0)策略。然后可以比较每种方法的平均准确率。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 比较马疝气数据集的统计插补策略 from numpy import mean from numpy import std from pandas import read_csv from sklearn.ensemble import RandomForestClassifier from sklearn.impute import SimpleImputer from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.pipeline import Pipeline from matplotlib import pyplot # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv' dataframe = read_csv(url, header=None, na_values='?') # 分割输入和输出元素 data = dataframe.values ix = [i for i in range(data.shape[1]) if i != 23] X, y = data[:, ix], data[:, 23] # 评估数据集上的每种策略 results = list() strategies = ['mean', 'median', 'most_frequent', 'constant'] for s in strategies: # 创建建模管道 pipeline = Pipeline(steps=[('i', SimpleImputer(strategy=s)), ('m', RandomForestClassifier())]) # 评估模型 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 存储结果 results.append(scores) print('>%s %.3f (%.3f)' % (s, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=strategies, showmeans=True) pyplot.show() |
运行该示例会使用重复交叉验证评估马疝气数据集上的每种统计插补策略。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
每次都会报告每种策略的平均准确率。结果表明,使用常数值(例如0)会带来最佳性能,约为88.1%,这是一个出色的结果。
|
1 2 3 4 |
>平均 0.860 (0.054) >中位数 0.862 (0.065) >最频繁 0.872 (0.052) >常数 0.881 (0.047) |
运行结束时,会为每组结果创建一个箱线图和须状图,以便比较结果的分布。
我们可以清楚地看到,常数策略的准确率分数分布优于其他策略。
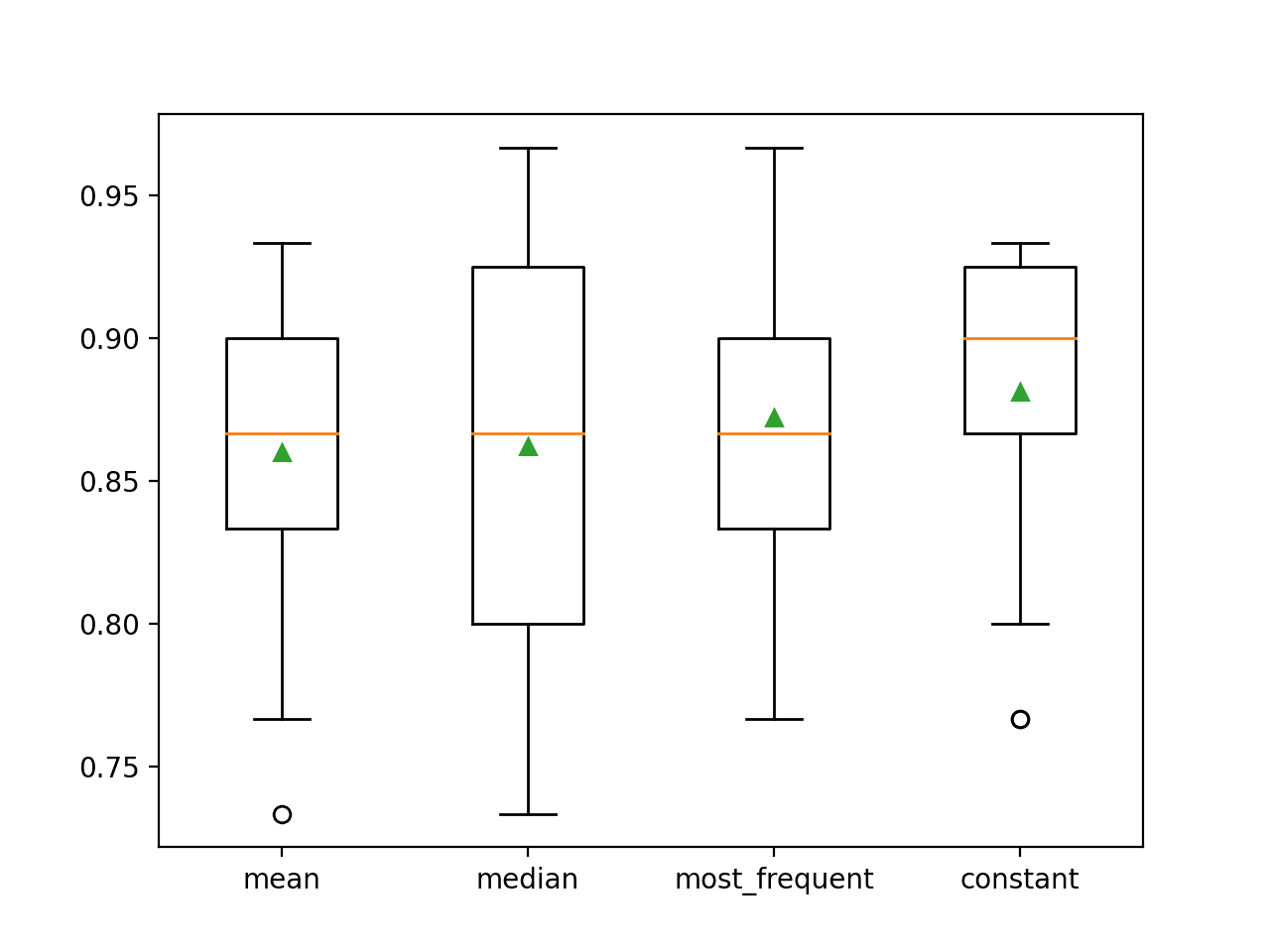
马疝气数据集应用统计插补策略的箱线图和须状图
进行预测时的 SimpleImputer 转换
我们可能希望使用常数插补策略和随机森林算法创建一个最终的建模管道,然后对新数据进行预测。
这可以通过定义管道并在所有可用数据上拟合它,然后调用 `predict()` 函数并将新数据作为参数传入来实现。
重要的是,新数据行必须使用 NaN 值标记任何缺失值。
|
1 2 3 |
... # 定义新数据 row = [2, 1, 530101, 38.50, 66, 28, 3, 3, nan, 2, 5, 4, 4, nan, nan, nan, 3, 5, 45.00, 8.40, nan, nan, 2, 11300, 00000, 00000, 2] |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 马疝气数据集的常数插补策略和预测 from numpy import nan from pandas import read_csv from sklearn.ensemble import RandomForestClassifier from sklearn.impute import SimpleImputer from sklearn.pipeline import Pipeline # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv' dataframe = read_csv(url, header=None, na_values='?') # 分割输入和输出元素 data = dataframe.values ix = [i for i in range(data.shape[1]) if i != 23] X, y = data[:, ix], data[:, 23] # 创建建模管道 pipeline = Pipeline(steps=[('i', SimpleImputer(strategy='constant')), ('m', RandomForestClassifier())]) # 拟合模型 pipeline.fit(X, y) # 定义新数据 row = [2, 1, 530101, 38.50, 66, 28, 3, 3, nan, 2, 5, 4, 4, nan, nan, nan, 3, 5, 45.00, 8.40, nan, nan, 2, 11300, 00000, 00000, 2] # 进行预测 yhat = pipeline.predict([row]) # 总结预测 print('预测类别: %d' % yhat[0]) |
运行该示例会在所有可用数据上拟合建模管道。
定义了一个新的数据行,其中缺失值标记为 NaN,并进行了分类预测。
|
1 |
预测类别:2 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
相关教程
书籍
- 坏数据手册, 2012.
- 《数据挖掘:实用机器学习工具与技术》(Data Mining: Practical Machine Learning Tools and Techniques), 2016.
- 应用预测建模, 2013.
API
数据集 (Dataset)
总结
在本教程中,您学习了如何使用统计插补策略来处理机器学习中的缺失数据。
具体来说,你学到了:
- 缺失值必须用 NaN 值标记,并可以用统计量替换以计算值列。
- 如何加载带有缺失值的 CSV 值,并用 NaN 值标记缺失值,并报告每列缺失值的数量和百分比。
- 如何在评估模型时以及将最终模型拟合到新数据以进行预测时,将缺失值与统计量一起作为数据准备方法进行插补。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







你好,
试图将标记为“?”的缺失值替换为 NaN 值,但我收到错误消息;
……….
…………….
KeyError:“[Int64Index([0], dtype=’int64′)] 中的任何一个都不在 [列] 中”
请帮忙。
谢谢
很抱歉听到这个消息,您能确认您的库是最新的,您完全复制了代码并且使用了相同的数据集吗?
更多建议在这里
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
for i in range(dataframe.shape[1])
# 计算缺失值行数
n_miss = dataframe.isnull().sum()[i] # 更改此行
perc = n_miss / dataframe.shape[0] * 100
print('>> %d, 缺失: %d (%.1f%%)' % (i, n_miss, perc))
这样修改这一行,
n_miss = dataframe.isnull().sum()[i] # 更改此行
嗨,Jason,好帖子!你能否解释一下为什么常数插补比中位数/均值插补效果更好?从我的角度来看,这种简单的技术比适合每个独立特征的统计方法带来更好的分数,这有点反直觉。
在应用机器学习中,我们不擅长回答“为什么”的问题,我们没有很好的理论。
我可以说一些普遍性的话,比如这取决于数据集和所选模型的具体情况。我们可以深入研究模型,找出为什么常数在这个数据集中能比均值带来更好的性能。但这可能是一项艰巨的工作。
好文章!
谢谢!
好作品!
如此深刻,
谢谢!
SimpleImputer 类使用单一策略(例如,均值、中位数等)。如何在不同列中使用不同策略为单个数据集插补缺失值?实际上,每列可能需要不同的策略来插补缺失值。
很好的问题!
您可以将每列/特征分开,并以您希望的任何方式进行准备,然后将准备好的列重新组合成一个数据集以拟合/评估模型。
一种有用的方法可能是使用 ColumnTransformer
https://machinelearning.org.cn/columntransformer-for-numerical-and-categorical-data/
嗨,Jason!
好文章!
但我有一个疑问。您正在尝试填充缺失值的4个统计量,然后根据它们各自的准确性进行验证。您不认为您应该专注于找出特征值是正态还是非正态性质,然后分别插补均值和中位数吗?您只关注最终结果,而不是采用正确的方法?如果我错了,请指正。
谢谢!
也许吧。网格搜索不同的插补策略可能比理解每个变量的分布更快。
嗨,Jason,
一如既往,又一篇精彩的帖子 🙂
您能给我一些关于基于模型的插补的详细信息吗,例如使用 KNN 或任何其他机器学习模型进行插补,而不是统计插补?
如果您能添加模型优于统计模型或反之的优缺点,那将更有帮助。
谢谢你,
戈皮
是的,请看这个
https://machinelearning.org.cn/knn-imputation-for-missing-values-in-machine-learning/
先生,您好,
我如何通过取相应月份的平均值来填充时间序列数据中的缺失值?您有关于 Python 中此方面的教程吗?
这个可能会有帮助
https://machinelearning.org.cn/handle-missing-timesteps-sequence-prediction-problems-python/
我认为拟合然后转换的整个想法确实是为了避免数据泄露,但这主要是在 K 折交叉验证的情况下。让我解释一下。
在 K 折交叉验证中,您每次在 K-1 折或子集上拟合或训练模型,然后使用剩下的一个进行验证,即衡量训练模型在验证数据上的性能。然后计算 MSEs 或 MAEs 的平均值以获得整体模型性能。
现在,如果您的数据集中有 NaN,并且您进行了插补,将发生以下情况:
1- 您取 K-1 折来训练数据。
2- 您使用剩下的折或子集进行验证,但在训练集的插补中,您考虑了剩下的信息。例如,如果将均值用作插补策略,那么您已经考虑了来自剩余数据集的信息来拟合您的训练数据。这根据定义就是数据泄露。
我认为同样适用于留一法交叉验证。
现在的问题是(老实说,这让我很困惑):对于剩下的数据集或验证数据集中的 NaN 插补怎么办?如果我们将训练数据中的拟合插补用于填充验证数据集的 NaN,我们也在泄露数据。因为我的模型会表现得更好,因为训练数据已经泄露到验证数据中。
如果我们使用拟合到训练数据的插补器,对于测试数据来说,情况会更糟。
这确实是 Kaggle 练习中建议的,那么我错过了什么?
您在博客中提到,预处理的错误在于在分割数据进行验证和测试之前进行预处理。为什么?因为我们会泄露到训练数据中。但反过来也会发生同样的情况,不是吗?
假设我有 NaN 值,为了在测试期间不让模型过拟合,更好的选择是什么?
现在,同样的问题:用训练数据拟合插补器并使用测试数据填充 NaN(比如用均值)呢?
抱歉,我没听懂这个问题,您能重新措辞或详细说明一下吗?
无论用于评估模型的程序是什么(训练/测试/验证、K折等),像插补这样的数据转换都应该在训练数据集上拟合,并应用于所有数据集,例如训练集、测试集、验证集、新数据集等。
竞赛不同,因为您拥有所有可用的输入数据,您可以打破这条规则。
我的观点是,当未见数据或测试数据泄露到训练数据中时,就会发生数据泄露。那会使模型表现过度。
那为什么反过来就不是问题呢?数据从训练集泄露到测试集、验证集等……
我没有看到任何解释?为什么这会是一个规则呢?对我来说,使用训练数据来拟合测试数据也会让模型在测试数据上的性能看起来很好。
而且为什么我根本需要用训练数据来拟合测试数据呢?用它自己的数据拟合不是更好吗?
训练数据集代表在进行预测之前“已知”的内容。系统可以在进行预测之前以任何和所有方式充分利用这些数据。
这是归纳学习/推理的前提
https://zh.wikipedia.org/wiki/归纳推理
是的,绝对正确,但在我们的案例中,测试数据是“已知”的 🙂
我认为整个想法是,在现实生活中,当我们使用新数据进行预测时,我们应该使用训练数据进行 NaN 拟合或预处理,主要原因有两个:
1- 如果我们只有 1 个观测值,那么用它进行预处理是不切实际的。
2- 通常,新数据“小于”训练数据,因此用训练数据估计策略(无论是均值、中位数等)是最好的……而且如果我们用测试数据本身来拟合它,对模型来说是不公平的,因为这会为 NaN 填充有偏差的值。
让我困惑的是,在竞赛中,我们已经掌握了大量数据,这些数据在实践中应该能很好地估计均值、中位数等……
无论如何,感谢您的反馈 🙂
比赛不是“现实生活”情况,模型评估的常规良好实践可能不相关。
例如,你可以做一些疯狂的事情,比如训练测试集
https://machinelearning.org.cn/train-to-the-test-set-in-machine-learning/
并且爬坡测试集
https://machinelearning.org.cn/hill-climb-the-test-set-for-machine-learning/
哇,那真是太疯狂了 🙂
谢谢您的信息!
不客气。
亲爱的Jason
你能更详细地解释一下你的箱线图吗?
你是如何根据须状图发现常数插补策略的?图中空心圆是什么,是异常值还是其他?
为什么你总是使用随机森林分类器来评估插补?这种算法有什么特别之处吗?
谢谢
默认情况下,常数策略填充值为 0,您可以在这里了解更多信息
https://scikit-learn.cn/stable/modules/generated/sklearn.impute.SimpleImputer.html
箱线图上的点表示异常值
https://en.wikipedia.org/wiki/Box_plot
我在此教程中使用随机森林是因为它在大量不同问题上表现良好。请使用最适合您的数据集的算法。
你好,
如果数据集中有分类特征,处理缺失数据的最佳时机是什么时候?
在将分类特征转换为数值特征之前还是之后?
这并不重要,只要您不允许数据泄露。也许在序数编码之后。
嗨,谢谢您的回复
编码也必须在训练数据上进行以避免数据泄露吗?还是数据泄露与其他数据准备技术相关?
任何数据准备都必须仅在训练数据集上拟合,然后应用于训练集和测试集以避免数据泄露。或者您可以使用管道自动完成此操作。
你好,
感谢您的精彩帖子。
缺失值插补应该在去除异常值之后进行还是在异常值处理之前进行?
也许之后。实验并发现什么最适合您的特定数据集和模型。
嗨
谢谢您的信息。
然而,当我在我的数据集上尝试实现这个时,当我进行验证时,它返回一个错误“ValueError: Input contains NaN, infinity or a value too large for dtype('float64')”。我认为 X/Y 仍然有 NAN 值
也许你的 Y 有一些零,所以 X/Y 得到 NaN?尝试在您使用这些值之前进行一些预处理来替换它们。
好帖子,谢谢 Jason
非常欢迎您!我们非常感谢您的支持!
Jason,错误数据是否可以归类为缺失值,以及我们如何处理它们,提前感谢
当模型在缺失值为常数0的情况下进行训练时,为什么需要将新数据中的缺失值设置为NaN?
嗨,itsme……处理缺失数据的方法有很多。以下资源可能会引起您的兴趣
https://machinelearning.org.cn/handle-missing-data-python/
作为一名在插补方面有一些专业知识的统计学家,我会告诫读者不要使用简单的均值插补。简单地用均值替换缺失值,存在诸多问题,包括但不限于:
1. 偏差 – 如果数据不是完全随机缺失 (MCAR),均值插补可能会在数据集中引入偏差,因为它没有考虑数据的底层分布。
2. 人为降低变异性 – 均值插补倾向于降低数据集的变异性,因为它用常数替换缺失值。这可能导致低估标准差和其他离散度度量。
3. 假设同质缺失性 – 均值插补不考虑不同变量之间的关系,并假设缺失值与数据集中其他变量之间存在同质关系。然而,缺失性通常与其他变量相关联。
4. 不反映不确定性 – 均值插补不考虑与缺失值相关的不确定性。它将所有插补值视为已知,这可能导致标准误差较小,并可能导致对插补数据执行的统计测试得出不正确的结论。
5. 过拟合的可能性 – 如果在预测建模中使用均值插补,可能会导致过拟合,因为模型可能会从插补值创建的人工结构中学习。
6. 对相关性的影响 – 使用均值可能会扭曲变量之间的相关性,因为它可以通过同质化值人为地夸大关系。
我鼓励读者使用统计上合理的方法进行插补,例如多重插补,或其他方法,如热/冷甲板插补、分数热甲板插补或最近邻比例插补。甚至可以更复杂,使用 Semiparametric imputation using latent sparse conditional Gaussian mixtures for multivariate mixed outcomes by S Sugasawa, JK Kim, and K Morikawa (2021) 中描述的插补方法。
感谢 Mark 对我们讨论的贡献!