Tom Mitchell 在其 1997 年的经典著作《机器学习》中,有一章专门介绍了用于评估机器学习模型的统计方法。
统计学为机器学习项目中的每个步骤提供了重要的工具集。如果不对统计方法加以运用,从业人员就无法有效评估机器学习模型的技能。不幸的是,统计学对大多数开发人员和计算机科学毕业生来说是陌生的领域。这使得 Mitchell 的开创性机器学习著作中的这一章成为从业人员必读(如果不是强制性阅读)的内容。
在本文中,您将了解 Mitchell 推荐的用于评估和比较机器学习模型的统计方法。
阅读本文后,你将了解:
- 如何计算分类准确率或错误率的置信区间。
- 计算置信区间的统计基础。
- 如何普遍比较机器学习算法的性能。
通过我的新书 《机器学习统计学》 开启您的项目,书中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。

评估机器学习模型的统计方法
照片由 Pierre (Rennes) 拍摄,保留部分权利。
机器学习书籍
Tom Mitchell 撰写了可能是应用机器学习的经典教材《机器学习》,于 1997 年出版。
他在书中用整整一章的篇幅介绍了评估机器学习模型和算法所需的统计方法。具体来说,就是标题为“评估假设”的第五章。
第五章介绍了统计学和估计理论的基本概念,重点关注如何利用有限的数据样本评估假设的准确性。这包括计算用于估计假设准确性的置信区间以及比较学习方法准确性的方法。
- 第 16 页,《机器学习》,1997 年。
在本文中,我们将仔细研究这一章,并回顾 Mitchell 当时推荐的统计方法。统计方法的基础知识不会改变,在本书出版 20 年后的今天,它们可能仍然同样有用和相关。
需要注意的是,当 Mitchell 提到假设时,他指的是学习到的模型,即在数据集上运行学习算法的结果。评估和比较假设是指比较学习到的模型,这与评估和比较机器学习算法不同,后者可能在同一问题的不同样本或不同问题上进行训练。
关于评估假设的第五章分为 7 部分;它们如下:
- 5.1. 动机
- 5.2. 估计假设的准确性
- 5.3. 抽样理论基础
- 5.4. 导出置信区间的通用方法
- 5.5. 两个假设的误差差异
- 5.6. 比较学习算法
- 5.7. 总结与进阶阅读
我们将花时间逐一查看各部分,并总结所做的统计方法和建议。
需要机器学习统计学方面的帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
动机
本章以阐述评估假设在机器学习中的重要性作为开篇。
经验性地评估假设的准确性是机器学习的基础。
- 第 128 页,《机器学习》,1997 年。
本章由三个问题驱动;它们是:
- 鉴于假设在有限数据样本上的观察准确性,它在更多样本上的准确性估计得有多好?
- 鉴于一个假设在一个数据样本上优于另一个假设,该假设在一般情况下更准确的可能性有多大?
- 当数据有限时,如何最好地利用这些数据来学习一个假设并估计其准确性?
这三个问题都密切相关。
第一个问题引发了对模型技能估计误差的担忧,并促使人们需要置信区间。
第二个问题引发了对基于小样本模型技能做出决策的担忧,并促使人们进行统计假设检验。
最后,第三个问题考虑了小样本的经济使用,并促使人们使用如 k 折交叉验证之类的重采样方法。
本章讨论了评估学习到的假设的方法、比较两个假设的准确性方法以及在数据有限的情况下比较两个学习算法准确性的方法。
- 第 129 页,《机器学习》,1997 年。
动机部分以提醒人们估计假设技能的难度而告终。具体来说,引入了模型技能估计中的偏差和方差。
- 估计偏差。当模型在训练数据上进行评估时,通过在留存测试集上评估模型来克服。
- 估计方差。当模型在独立测试集上进行评估时,通过使用更大的测试集来克服。
估计假设的准确性
模型的技能或预测误差必须进行估计,而作为估计,它将包含误差。
通过区分模型的真实误差和估计的或样本误差,可以清楚地说明这一点。
一个是假设在可用数据样本上的误差率。另一个是假设在整个未知分布 D 的示例上的误差率。
- 第 130 页,《机器学习》,1997 年。
- 样本误差。在数据样本上计算的真实误差的估计值。
- 真实误差。模型错误分类来自域的随机选定示例的概率。
我们想要知道真实误差,但我们必须处理估计值,该估计值是从数据样本中近似得出的。这就引出了一个问题:给定的误差估计值有多好?
一种方法是计算样本误差周围的置信区间,该区间足够大,能够以非常高的概率(例如 95%)覆盖真实误差。
假设误差度量是离散比例,例如分类误差,则置信区间的计算如下:
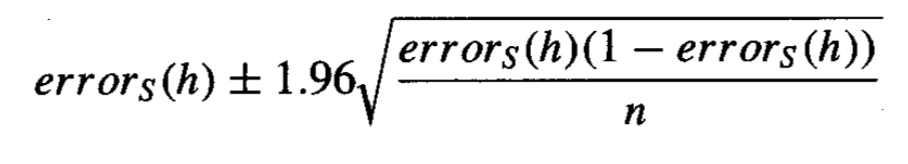
计算分类误差的置信区间
摘自《机器学习》,1997 年。
其中 _error_s_ 是样本误差,_n_ 是用于计算样本误差的测试集中的总实例数,1.96 是高斯分布中 95% 的置信度的临界值。
抽样理论基础
上一节计算置信区间的公式做了许多假设。
本节将探讨这些假设,以提供计算的基础。
本节介绍了统计学和抽样理论的基本概念,包括概率分布、期望值、方差、二项分布和正态分布,以及双侧和单侧区间。
- 第 132 页,《机器学习》,1997 年。
有益的是,提供了一张表格,总结了本节的关键概念,如下所示。

计算置信区间的关键统计概念摘要
摘自《机器学习》,1997 年。
本节为置信区间提供了重要的统计基础,推荐阅读。
为了避免重复所有这些理论,本节的核心内容如下:
- 分类准确率和分类误差等比例值遵循二项分布。
- 二项分布描述了二元事件的概率,例如抛硬币或正确/不正确的分类预测。
- 均值是分布中的期望值,方差是样本与均值的平均距离,标准差是方差按数据样本大小归一化后的值。
- 理想情况下,我们寻求对所需参数的无偏估计,且方差最小。
- 置信区间提供了一种量化总体参数(如均值)不确定性的方法。
- 对于大样本量(例如,30 个或更多观测值),二项分布可以用更简单的正态分布来近似。
- 区间可以以均值为中心,称为双侧区间,也可以是单侧的,例如均值左侧或右侧的半径。
导出置信区间的通用方法
给定计算比例值置信区间的公式以及公式背后的统计推理,我们提出了一种计算置信区间的通用过程。
该过程总结如下。

计算置信区间的通用过程
摘自《机器学习》,1997 年。
还介绍了中心极限定理。它可以概括为以下发现:独立观测值的总和(或归一化总和,就均值而言)将代表高斯分布的样本。例如,模型在不同独立数据样本上的平均技能将是高斯分布的。
这是一个宝贵的发现,因为我们对高斯分布非常了解,并且可以评论两个样本(均值)属于相同或不同高斯分布的可能性,例如在机器学习算法的技能情况下。
中心极限定理是一个非常有用的事实,因为它意味着每当我们定义一个作为样本均值的估计器(例如,errors(h) 是平均误差)时,对于足够大的 n,控制该估计器的分布都可以用正态分布来近似。
- 第 143 页,《机器学习》,1997 年。
两个假设的误差差异
本节将介绍将计算置信区间的通用过程应用于两个模型之间分类误差估计差异的情况。
该方法假设每个模型都在不同的独立数据样本上训练。因此,计算两个模型之间误差差异的置信区间会累加每个模型的方差。
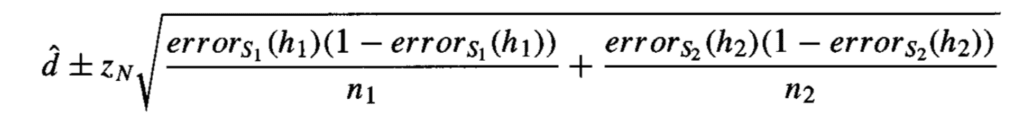
两个模型误差差异的置信区间
摘自《机器学习》,1997 年。
本节还介绍了统计假设检验的概念,作为计算置信区间的替代方法。
在某些情况下,我们对某个特定猜想为真的可能性感兴趣,而不是对某个参数的置信区间感兴趣。
- 第 145 页,《机器学习》,1997 年。
有趣的是,该主题的动机是单侧置信区间包含模型真实误差估计可能性的概率,以确定一个模型优于另一个模型的概率。
我发现这个解释不如它应该的那样清晰。
比较学习算法
本章的最后一个内容部分侧重于比较机器学习算法。
这与比较模型(假设)不同,因为比较算法涉及训练它们并可能在来自该领域的多个不同数据样本上进行评估。
比较两种算法的动机是估计这两种方法之间的预期或平均差异。介绍了一个使用 k 折交叉验证的过程,其中每种算法都在相同的数据分割上进行训练和评估。然后计算最终的平均误差差异,从中可以估计置信区间。
置信区间的计算已更新,以考虑由于每种算法都在相同的测试集上进行评估而导致的自由度减少。
介绍了配对学生 t 检验,这是一种统计假设检验,用于量化两个均值属于相同(或不同)分布的概率。该检验可以与概述的程序一起使用,但前提是每个训练和测试集包含独立样本,而默认的 k 折交叉验证并非如此。
特别地,在这个理想化的方法中,我们修改了表 5.5 的过程,使得在循环的每次迭代中,它会生成一个新的随机训练集 Si 和新的随机测试集 Ti,通过从这个底层的实例分布中抽取,而不是从固定的样本 Do 中抽取。
- 第 148 页,《机器学习》,1997 年。
本节最后概述了比较机器学习算法时的实际考虑。
Mitchell 提醒我们,学生 t 检验在不适用于使用重采样方法的情况下。尽管如此,他还是建议使用 k 折交叉验证或随机抽样来估计模型误差估计的方差,因为它们是唯一可用的方法。
这是不理想的,因为统计检验的预期将被违反,导致 I 类错误增加。
明智的做法是记住,统计模型很少能完美地拟合测试学习算法时的实际约束,尤其是在可用数据有限的情况下。尽管如此,它们确实提供了近似的置信区间,这在解释学习方法的实验比较时非常有用。
- 第 150 页,《机器学习》,1997 年。
总结与进阶阅读
本章最后总结了主要观点、可用于确认对公式理解的练习,以及一份很棒的参考文献和进阶阅读列表。
简而言之,要点是:
- 置信区间可用于量化模型误差的不确定性。
- 置信区间的计算重要地取决于被估计量的分布。
- 模型技能评估中出现错误的一个原因是估计偏差,在训练数据集上评估模型会引入乐观偏差。
- 模型技能评估中出现错误的另一个原因是估计方差,这可以通过增加留存测试集的大小来减小。
- 使用 k 折交叉验证过程的重采样提供了一种有效的方法来比较机器学习算法。
- 在使用统计方法时,我们必须做出假设,例如关于参数分布的假设。即使有置信区间,我们也不知道什么才是真实的,只知道什么可能是真实的。
有趣的是,引用了 Thomas G. Dietterich 的两篇技术报告。Dietterich 后来发表了重要的 1998 年论文“比较监督分类学习算法的近似统计检验”,该论文描述了在将机器学习算法与随机重采样和 k 折交叉验证进行比较时,配对学生 t 检验的不可靠性。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
- 机器学习, 1997.
- Tom Mitchell 主页
- 维基百科上的 Tom M. Mitchell
- 维基百科上的 Thomas Dietterich
- 用于比较监督分类学习算法的近似统计检验, 1998.
总结
在本文中,您了解了用于评估和比较机器学习模型的统计方法。
具体来说,你学到了:
- 如何计算分类准确率或错误率的置信区间。
- 计算置信区间的统计基础
- 如何普遍比较机器学习算法的性能。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。




 for Evaluating GANs")
 for Evaluating GANs")

很好!我认为这是一个非常重要但有时被忽视的主题。
对此主题的贝叶斯方法将非常有趣……您知道任何参考资料吗?
谢谢 Peter。
目前不知道,请尝试在 scholar.google.com 上搜索。
嗨,Jason,
感谢您写下这篇精彩的文章。您是否考虑过撰写一篇关于用于比较机器学习模型的统计检验的博文,其中包含具体的 Python 示例(或案例研究)?
祝好,
Elie
是的,我写了一些并已安排。
感谢这篇信息丰富的文章,我只有几个问题
首先,本文中的方法是否可以用于评估回归算法而不是分类算法?在回归和数据有限的情况下,如何最好地创建置信区间并比较算法?
我的第二个问题是:关于比较算法,如果我没理解错的话,您是在说这种方法是估计模型误差方差的唯一方法,但这种方法打破了假设并且不可靠。那么您建议如何比较算法呢?
以下是您帖子中我引用的部分:
– “Mitchell 提醒我们,学生 t 检验在不适用于使用重采样方法的情况下。尽管如此,他还是建议使用 k 折交叉验证或随机抽样来估计模型误差估计的方差,因为它们是唯一可用的方法。”
– “…在将机器学习算法与随机重采样和 k 折交叉验证进行比较时,配对学生 t 检验的不可靠性。”
谢谢
这些方法侧重于分类模型,不适用于回归。
我有很多关于计算置信区间的通用示例,或许可以从这里开始。
https://machinelearning.org.cn/confidence-intervals-for-machine-learning/
关于比较算法的更多信息,您可以将 5×2 和学生 t 检验用于比较回归算法的误差(MSE/RMSE)。
https://machinelearning.org.cn/statistical-significance-tests-for-comparing-machine-learning-algorithms/
嗨,Jason,
我想知道如何将此方法扩展到 1) 非必等同分布的检验统计量(例如,像 AUC 这样的指标或更复杂的排名指标),以及 2) 双模型比较。
这似乎应该是比较两个模型时的一个常见设置,当正态近似不起作用时,但我还没有找到太多关于这个主题的资源。
谢谢!
很好的问题!
我推荐这个。
https://machinelearning.org.cn/statistical-significance-tests-for-comparing-machine-learning-algorithms/
感谢您的指点。我的理解是,链接的文章和 Dietterich 的论文侧重于检验算法,而不是模型。但是,我想知道是否有方法可以在您想知道哪个模型更好时使用,即使它们来自同一个算法(我认为是 Dietterich 论文中的情况 3 和 4)。
谢谢!
Evan
是的。
比较不同的算法与不同的算法配置是相同的,例如比较样本均值以找出哪种算法/配置表现最好。