集成决策树的一种简单技术是根据训练数据集的子样本来训练树。
可以从训练数据中抽取行子集来训练单个树,这称为 bagging。当在计算每个分割点时也从训练数据中抽取行子集时,这称为随机森林。
这些技术也可以用于梯度树提升模型中,这种技术称为随机梯度提升。
在这篇文章中,您将了解随机梯度提升以及如何使用 XGBoost 和 Python 中的 scikit-learn 调整采样参数。
阅读本文后,您将了解
- 在数据子样本上训练树的原理以及如何在梯度提升中使用它。
- 如何使用 scikit-learn 在 XGBoost 中调整基于行的子采样。
- 如何在 XGBoost 中按树和分割点调整基于列的子采样。
通过我的新书《XGBoost With Python》启动您的项目,其中包括所有示例的分步教程和 Python 源代码文件。
让我们开始吧。
- 2017 年 1 月更新:已更新以反映 scikit-learn API 0.18.1 版本中的更改。

在 Python 中使用 XGBoost 和 scikit-learn 进行随机梯度提升
图片由 Henning Klokkeråsen 提供,保留部分权利。
在 Python 中使用 XGBoost 需要帮助吗?
参加我的免费 7 天电子邮件课程,探索 xgboost(含示例代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
随机梯度提升
梯度提升是一种贪婪的过程。
新的决策树被添加到模型中以纠正现有模型的残差误差。
每棵决策树都是通过贪婪搜索过程创建的,以选择最能最小化目标函数的分割点。这可能导致树一次又一次地使用相同的属性,甚至相同的分割点。
Bagging 是一种技术,其中创建了一组决策树,每棵树都来自训练数据中不同的行随机子集。其效果是,由于样本中的随机性允许创建略有不同的树,从而增加了集成预测的方差,因此树的集成获得了更好的性能。
随机森林更进一步,允许在选择分割点时对特征(列)进行子采样,从而进一步增加了树集成的方差。
这些相同的技术可以用于梯度提升中决策树的构建,这是一种称为随机梯度提升的变体。
通常使用训练数据的激进子样本,例如 40% 到 80%。
教程概述
在本教程中,我们将研究不同子采样技术在梯度提升中的效果。
我们将调整 Python 中 XGBoost 库支持的三种不同风格的随机梯度提升,特别是:
- 在创建每棵树时对数据集中的行进行子采样。
- 在创建每棵树时对数据集中的列进行子采样。
- 在创建每棵树时对数据集中每个分割点的列进行子采样。
问题描述:Otto 数据集
在本教程中,我们将使用 Otto Group 产品分类挑战数据集。
此数据集可从 Kaggle 免费获取(您需要注册 Kaggle 才能下载此数据集)。您可以从数据页面下载训练数据集 train.csv.zip,并将解压后的 train.csv 文件放入您的工作目录中。
此数据集描述了超过 61,000 种产品在 10 个产品类别(例如时尚、电子产品等)中的 93 个模糊细节。输入属性是某种不同事件的计数。
目标是为新产品做出预测,作为每个 10 个类别的概率数组,模型使用多类对数损失(也称为交叉熵)进行评估。
这项竞赛于 2015 年 5 月完成,此数据集对 XGBoost 来说是一个很好的挑战,因为它具有非平凡的示例数量、问题的难度以及几乎不需要数据准备(除了将字符串类变量编码为整数)。
在 XGBoost 中调整行子采样
行子采样涉及从训练数据集中无放回地选择一个随机样本。
行子采样可以在 XGBoost 类的 scikit-learn 包装器中通过 subsample 参数指定。默认值为 1.0,表示不进行子采样。
我们可以使用 scikit-learn 中内置的网格搜索功能来评估不同子采样值(从 0.1 到 1.0)对 Otto 数据集的影响。
|
1 |
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 1.0] |
子采样有 9 种变体,每个模型将使用 10 折交叉验证进行评估,这意味着需要训练和测试 9×10 或 90 个模型。
完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 在 Otto 数据集上使用 XGBoost,调整子样本 from pandas import read_csv from xgboost import XGBClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import LabelEncoder import matplotlib matplotlib.use('Agg') from matplotlib import pyplot # 加载数据 data = read_csv('train.csv') dataset = data.values # 将数据拆分为 X 和 y X = dataset[:,0:94] y = dataset[:,94] # 将字符串类值编码为整数 label_encoded_y = LabelEncoder().fit_transform(y) # 网格搜索 model = XGBClassifier() subsample = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 1.0] param_grid = dict(subsample=subsample) kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold) grid_result = grid_search.fit(X, label_encoded_y) # 总结结果 print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) # 绘图 pyplot.errorbar(subsample, means, yerr=stds) pyplot.title("XGBoost subsample vs Log Loss") pyplot.xlabel('subsample') pyplot.ylabel('Log Loss') pyplot.savefig('subsample.png') |
运行此示例将打印最佳配置以及每个测试配置的对数损失。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
我们可以看到,获得的最佳结果是 0.3,即使用训练数据集的 30% 样本训练树。
|
1 2 3 4 5 6 7 8 9 10 |
最佳:-0.000647 使用 {'subsample': 0.3} -0.001156 (0.000286) 伴随:{'subsample': 0.1} -0.000765 (0.000430) 伴随:{'subsample': 0.2} -0.000647 (0.000471) 伴随:{'subsample': 0.3} -0.000659 (0.000635) 伴随:{'subsample': 0.4} -0.000717 (0.000849) 伴随:{'subsample': 0.5} -0.000773 (0.000998) 伴随:{'subsample': 0.6} -0.000877 (0.001179) 伴随:{'subsample': 0.7} -0.001007 (0.001371) 伴随:{'subsample': 0.8} -0.001239 (0.001730) 伴随:{'subsample': 1.0} |
我们可以绘制这些平均值和标准差对数损失值,以便更好地了解性能如何随子样本值变化。
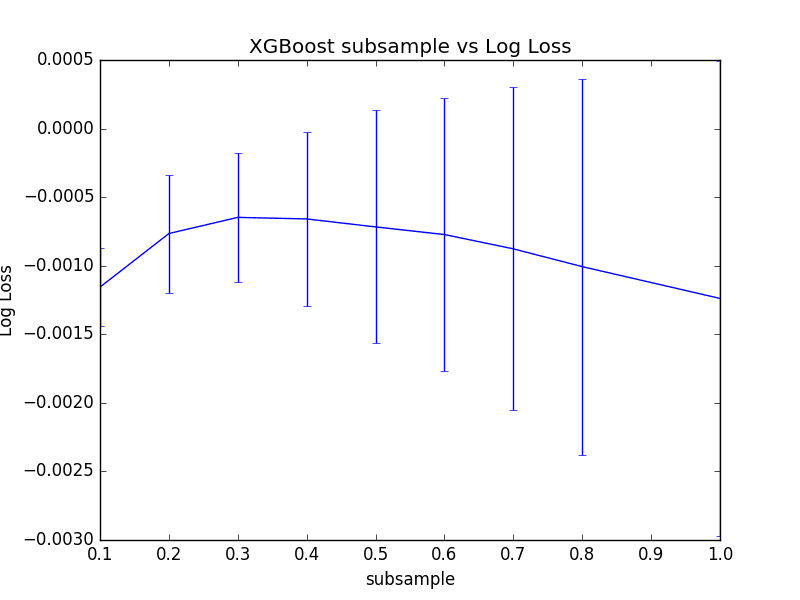
XGBoost 中行采样率调整的图
我们可以看到,30% 确实具有最佳的平均性能,但我们也可以看到,随着比率的增加,性能的方差显著增加。
有趣的是,所有 subsample 值的平均性能都优于没有子采样(subsample=1.0)的平均性能。
按树调整 XGBoost 中的列子采样
我们还可以创建特征(或列)的随机样本,以便在 boosted 模型中创建每个决策树之前使用。
在 scikit-learn 的 XGBoost 封装器中,这由 colsample_bytree 参数控制。
默认值为 1.0,表示每个决策树都使用所有列。我们可以评估 colsample_bytree 在 0.1 到 1.0 之间以 0.1 为增量的值。
|
1 |
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 1.0] |
完整的代码清单如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 在 Otto 数据集上使用 XGBoost,调整 colsample_bytree from pandas import read_csv from xgboost import XGBClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import LabelEncoder import matplotlib matplotlib.use('Agg') from matplotlib import pyplot # 加载数据 data = read_csv('train.csv') dataset = data.values # 将数据拆分为 X 和 y X = dataset[:,0:94] y = dataset[:,94] # 将字符串类值编码为整数 label_encoded_y = LabelEncoder().fit_transform(y) # 网格搜索 model = XGBClassifier() colsample_bytree = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 1.0] param_grid = dict(colsample_bytree=colsample_bytree) kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold) grid_result = grid_search.fit(X, label_encoded_y) # 总结结果 print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) # 绘图 pyplot.errorbar(colsample_bytree, means, yerr=stds) pyplot.title("XGBoost colsample_bytree vs Log Loss") pyplot.xlabel('colsample_bytree') pyplot.ylabel('Log Loss') pyplot.savefig('colsample_bytree.png') |
运行此示例将打印最佳配置以及每个测试配置的对数损失。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
我们可以看到模型的最佳性能是 colsample_bytree=1.0。这表明在此问题上对列进行子采样没有增加价值。
|
1 2 3 4 5 6 7 8 9 10 |
最佳:-0.001239 使用 {'colsample_bytree': 1.0} -0.298955 (0.002177) 伴随:{'colsample_bytree': 0.1} -0.092441 (0.000798) 伴随:{'colsample_bytree': 0.2} -0.029993 (0.000459) 伴随:{'colsample_bytree': 0.3} -0.010435 (0.000669) 伴随:{'colsample_bytree': 0.4} -0.004176 (0.000916) 伴随:{'colsample_bytree': 0.5} -0.002614 (0.001062) 伴随:{'colsample_bytree': 0.6} -0.001694 (0.001221) 伴随:{'colsample_bytree': 0.7} -0.001306 (0.001435) 伴随:{'colsample_bytree': 0.8} -0.001239 (0.001730) 伴随:{'colsample_bytree': 1.0} |
绘制结果,我们可以看到模型的性能在 0.5 到 1.0 之间的值趋于平稳(至少在此尺度下)。
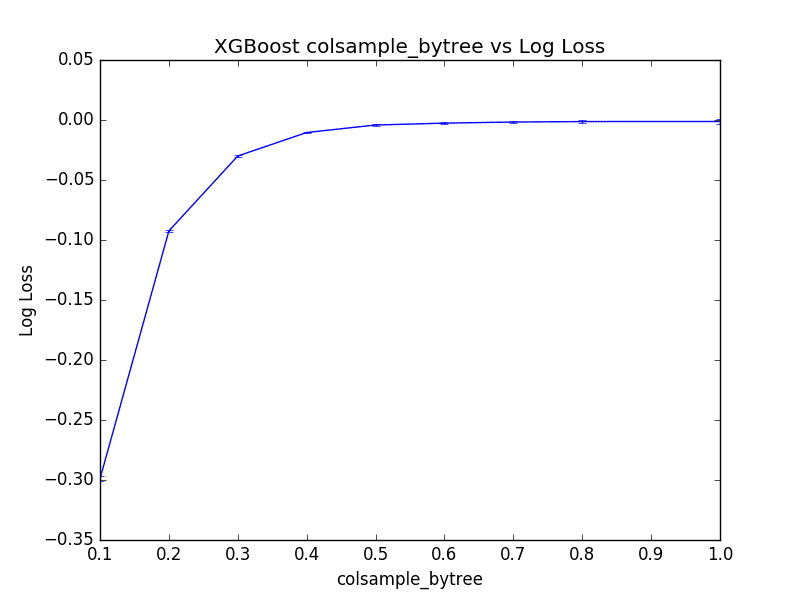
XGBoost 中每棵树的列采样调整图
按分割调整 XGBoost 中的列子采样
与其为每棵树一次对列进行子采样,不如在决策树的每个分割点对列进行子采样。原则上,这是随机森林中使用的方法。
我们可以在 scikit-learn 的 XGBoost 封装类中的 colsample_bylevel 参数中设置每个分割点使用的列样本大小。
和以前一样,我们将比率从 10% 改变到默认值 100%。
完整的代码清单如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 在 Otto 数据集上使用 XGBoost,调整 colsample_bylevel from pandas import read_csv from xgboost import XGBClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import LabelEncoder import matplotlib matplotlib.use('Agg') from matplotlib import pyplot # 加载数据 data = read_csv('train.csv') dataset = data.values # 将数据拆分为 X 和 y X = dataset[:,0:94] y = dataset[:,94] # 将字符串类值编码为整数 label_encoded_y = LabelEncoder().fit_transform(y) # 网格搜索 model = XGBClassifier() colsample_bylevel = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 1.0] param_grid = dict(colsample_bylevel=colsample_bylevel) kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold) grid_result = grid_search.fit(X, label_encoded_y) # 总结结果 print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) # 绘图 pyplot.errorbar(colsample_bylevel, means, yerr=stds) pyplot.title("XGBoost colsample_bylevel vs Log Loss") pyplot.xlabel('colsample_bylevel') pyplot.ylabel('Log Loss') pyplot.savefig('colsample_bylevel.png') |
运行此示例将打印最佳配置以及每个测试配置的对数损失。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
我们可以看到,通过将 colsample_bylevel 设置为 70% 获得了最佳结果,导致(反向)对数损失为 -0.001062,这优于将每棵树的列采样设置为 100% 时看到的 -0.001239。
这表明,如果每棵树的结果表明使用 100% 的列,不要放弃列子采样,而是尝试每个分割点的列子采样。
|
1 2 3 4 5 6 7 8 9 10 |
最佳:-0.001062 使用 {'colsample_bylevel': 0.7} -0.159455 (0.007028) 伴随:{'colsample_bylevel': 0.1} -0.034391 (0.003533) 伴随:{'colsample_bylevel': 0.2} -0.007619 (0.000451) 伴随:{'colsample_bylevel': 0.3} -0.002982 (0.000726) 伴随:{'colsample_bylevel': 0.4} -0.001410 (0.000946) 伴随:{'colsample_bylevel': 0.5} -0.001182 (0.001144) 伴随:{'colsample_bylevel': 0.6} -0.001062 (0.001221) 伴随:{'colsample_bylevel': 0.7} -0.001071 (0.001427) 伴随:{'colsample_bylevel': 0.8} -0.001239 (0.001730) 伴随:{'colsample_bylevel': 1.0} |
我们可以绘制每个 colsample_bylevel 变体的性能。结果显示方差相对较低,并且在此尺度下,在值 0.3 之后性能似乎趋于平稳。
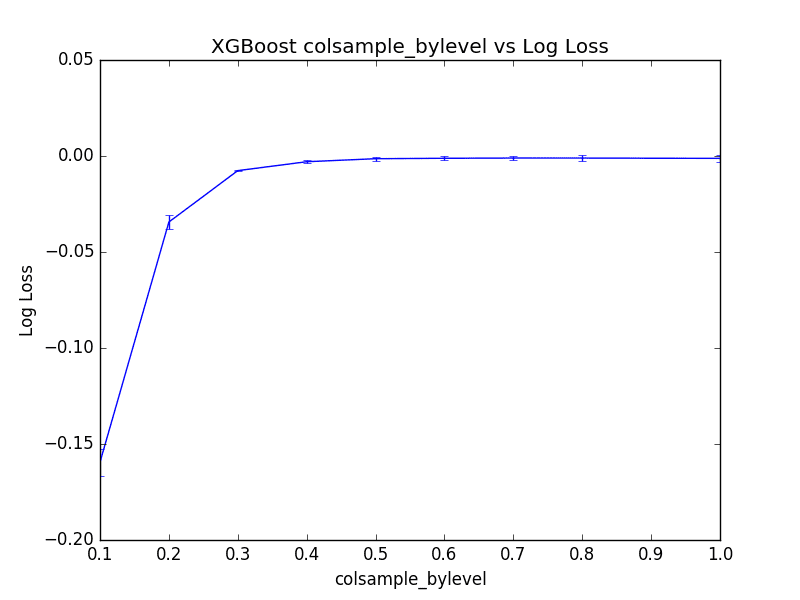
XGBoost 中每个分割点的列采样调整图
总结
在这篇文章中,您了解了 Python 中使用 XGBoost 进行随机梯度提升。
具体来说,你学到了:
- 关于随机提升以及如何对训练数据进行子采样以提高模型泛化能力。
- 如何在 Python 和 scikit-learn 中使用 XGBoost 调整行子采样。
- 如何在 XGBoost 中按树和按分割点调整列子采样。
您对随机梯度提升或本文有任何疑问吗?请在评论中提出您的问题,我将尽力回答。
发现赢得竞赛的算法!

在几分钟内开发您自己的 XGBoost 模型
...只需几行 Python 代码
在我的新电子书中探索如何实现
使用 Python 实现 XGBoost
它涵盖了自学教程,例如:
算法基础、缩放、超参数等等……
将 XGBoost 的强大功能带入您自己的项目
跳过学术理论。只看结果。






博士您好,
先生您好。我如何同时绘制两个变量的调整,例如 gamma 和 learning_rate。此致。
考虑将值保存到文件以便以后绘图。
不同级别模型的准确度是多少?
您所说的“不同级别”是什么意思?
您知道如何从梯度提升树中获取概率分布函数“pdf”吗?例如,对于随机森林,我们可以使用每棵树的预测分布作为 pdf 的代理,对于 AdaBoost,我们可以通过树的权重来加权每棵树的预测,以获得“pdf”。
我没有找到关于梯度提升树的任何资料…
有趣的想法。不,抱歉,您可能需要编写一些自定义代码。
又一篇精彩的文章!谢谢。:)
您提到随机梯度提升(通过分割实现列子采样)与随机森林的运行方式非常相似。区别似乎在于:
对于随机森林,分割基于选择导致最均匀分割结果的列(一种贪婪算法)。
对于实现按分割进行列子采样的随机梯度提升,分割基于随机选择要分割的列。
我对这两种方法的区别理解正确吗?
谢谢!
我相信是的。
嗨,Jason,
您有计划写一本关于在时间序列问题/预测中使用 XGBoost 的书或教程吗?
好建议。目前没有,但我喜欢这个主意!
那太棒了。
非常感谢。
伙计,您的工作太棒了,您应该获得一枚奖章。多亏了您,我的机器学习技能大大提高了。
问题:如果我同时在同一个单元格中调整多个参数,我会损失什么?
例如,在同一个单元格中调整子样本、colsample_bytree 和 colsample_bylevel,使用相同的参数样本选择方法,将它们保存在字典中,然后解析 KFold 和 GridSearchCV。
谢谢 Ted!很高兴这些帖子有帮助。
您可以同时调整多个参数——这是一个好主意,只是运行起来会很慢——计算成本高昂。
非常好的文章。我的问题是,为什么您没有“保留”找到的最优参数(行子采样为 0.3)用于后续步骤?
最后,我们希望找到行、树、列和级别的子采样参数的最佳组合。在 GridSearch 中一次性测试所有参数非常耗时。但是,如果您迭代地进行,那么在测试其他类型的子采样时,保留先前找到的最优参数不是更有意义吗?
是的,但在此教程中,我们正在演示超参数的效果,而不是试图最佳地解决预测问题。
嗨,Jason,
我有个问题。在调整多个超参数以试图最佳地解决预测问题时,同时调整所有超参数会准确但缓慢。如果每次调整超参数的子集都能获得最佳解决方案吗?
提前感谢您!
是的,一次性完成很慢,一个一个地可能错过组合。这是一种权衡。
嗨,Jason,
训练集和验证集或测试集之间的 auc 分数差异会更好吗?我的意思是模型会以高分预测其他样本。我训练了一个模型,训练集的 auc 为 0.87,验证集的 auc 为 0.81,测试集的 auc 为 0.83。但是预测其他集的 auc 只有 0.6。您能给我一些建议吗?提前谢谢您。
如果您正在执行模型选择,那么您只需要考虑模型在样本外(测试)数据集上的性能。
谢谢您的回复。在构建模型时预测测试数据集的性能很好。但是使用模型预测实际数据集却被证明效果很差!我该怎么办?
也许确认您的测试集是否具有代表性?
也许尝试重复 k 折交叉验证来估计性能?
也许新数据与您使用的数据非常不同?
也许确保您以与训练数据完全相同的方式准备新数据?