随机爬山算法(Stochastic Hill Climbing)是一种优化算法。
它在搜索过程中利用了随机性。这使得该算法适用于非线性目标函数,而其他局部搜索算法在这种情况下表现不佳。
它也是一种局部搜索算法,这意味着它修改单个解决方案并在搜索空间的相对局部区域进行搜索,直到找到局部最优解。这意味着它适用于单峰优化问题,或在应用全局优化算法之后使用。
在本教程中,您将了解用于函数优化的爬山优化算法。
完成本教程后,您将了解:
- 爬山算法是一种用于函数优化的随机局部搜索算法。
- 如何在 Python 中从零开始实现爬山算法。
- 如何应用爬山算法并检查算法的结果。
通过我的新书《机器学习优化》开启您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
在 Python 中从零开始实现随机爬山法
图片由John拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 爬山算法
- 爬山算法实现
- 应用爬山算法的示例
爬山算法
随机爬山算法是一种随机局部搜索优化算法。
它接受一个初始点作为输入和一个步长,其中步长是搜索空间内的距离。
该算法将初始点作为当前最佳候选解决方案,并在给定点的步长距离内生成一个新点。生成的新点经过评估,如果它等于或优于当前点,则将其作为当前点。
新点的生成使用了随机性,通常被称为随机爬山。这意味着算法可以在搜索过程中跳过响应表面的颠簸、噪声、不连续或欺骗性区域。
随机爬山算法从所有上坡移动中随机选择;选择的概率可能随上坡移动的陡峭程度而变化。
— 第 124 页,《人工智能:一种现代方法》,2009。
重要的是,接受评估值相同的不同点,因为它允许算法继续探索搜索空间,例如跨越响应表面的平坦区域。限制这些所谓的“横向”移动以避免无限循环也可能有所帮助。
如果我们总是在没有上坡移动时允许横向移动,那么当算法到达一个不是肩部的平坦局部最大值时,就会发生无限循环。一个常见的解决方案是限制允许的连续横向移动的数量。例如,我们可以允许最多 100 次连续横向移动。
— 第 123 页,《人工智能:一种现代方法》,2009。
此过程将持续到满足停止条件,例如最大函数评估次数或在给定函数评估次数内没有改进。
该算法的名称来源于它将(随机地)爬升响应表面的“山”以达到局部最优解。这并不意味着它只能用于最大化目标函数;这只是一个名称。事实上,通常我们是最小化函数而不是最大化它们。
爬山搜索算法(最陡峭上升版本)……它只是一个不断朝着价值增加方向(即上坡)移动的循环。当它到达一个“峰值”时终止,在该峰值处没有邻居具有更高的价值。
— 第 122 页,《人工智能:一种现代方法》,2009。
作为一种局部搜索算法,它可能会陷入局部最优解。然而,多次重启可能允许算法找到全局最优解。
随机重启爬山……从随机生成的初始状态进行一系列爬山搜索,直到找到目标。
— 第 124 页,《人工智能:一种现代方法》,2009。
步长必须足够大,以便能够找到搜索空间中更好的附近点,但又不能太大,以至于搜索跳出包含局部最优解的区域。
想要开始学习优化算法吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
爬山算法实现
在撰写本文时,SciPy 库不提供随机爬山算法的实现。
尽管如此,我们可以自己实现它。
首先,我们必须定义目标函数以及目标函数的每个输入变量的边界。目标函数只是一个我们将命名为 `objective()` 的 Python 函数。边界将是一个二维数组,每个输入变量有一个维度,用于定义变量的最小值和最大值。
例如,一维目标函数和边界将定义如下:
|
1 2 3 4 5 6 |
# 目标函数 def objective(x): return 0 # 定义输入范围 bounds = asarray([[-5.0, 5.0]]) |
接下来,我们可以将初始解生成为问题边界内的随机点,然后使用目标函数对其进行评估。
|
1 2 3 4 5 |
... # 生成初始点 solution = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 评估初始点 solution_eval = objective(solution) |
现在我们可以循环执行算法预定义迭代次数“n_iterations”,例如 100 或 1,000 次。
|
1 2 3 4 |
... # 执行爬山算法 for i in range(n_iterations): ... |
算法迭代的第一步是迈出一步。
这需要一个预定义的“step_size”参数,它与搜索空间的边界相关。我们将以高斯分布随机迈出一步,其中均值是我们的当前点,标准差由“step_size”定义。这意味着大约 99% 的步长将在当前点的(3 * step_size)范围内。
|
1 2 3 |
... # 迈出一步 candidate = solution + randn(len(bounds)) * step_size |
我们不必以这种方式迈步。您可能希望使用介于 0 和步长之间的均匀分布。例如:
|
1 2 3 |
... # 迈出一步 candidate = solution + rand(len(bounds)) * step_size |
接下来,我们需要使用目标函数评估新的候选解决方案。
|
1 2 3 |
... # 评估候选点 candidte_eval = objective(candidate) |
然后我们需要检查这个新点的评估是否与当前最佳点一样好或更好,如果是,则用这个新点替换我们当前的最佳点。
|
1 2 3 4 5 6 7 |
... # 检查是否应该保留新点 if candidte_eval <= solution_eval: # 存储新点 solution, solution_eval = candidate, candidte_eval # 报告进度 print('>%d f(%s) = %.5f' % (i, solution, solution_eval)) |
就是这样。
我们可以将此爬山算法实现为一个可重用函数,该函数将目标函数的名称、每个输入变量的边界、总迭代次数和步长作为参数,并返回找到的最佳解决方案及其评估结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 爬山局部搜索算法 def hillclimbing(objective, bounds, n_iterations, step_size): # 生成初始点 solution = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 评估初始点 solution_eval = objective(solution) # 运行爬山算法 for i in range(n_iterations): # 迈出一步 candidate = solution + randn(len(bounds)) * step_size # 评估候选点 candidte_eval = objective(candidate) # 检查是否应该保留新点 if candidte_eval <= solution_eval: # 存储新点 solution, solution_eval = candidate, candidte_eval # 报告进度 print('>%d f(%s) = %.5f' % (i, solution, solution_eval)) return [solution, solution_eval] |
现在我们知道了如何在 Python 中实现爬山算法,接下来我们看看如何用它来优化目标函数。
应用爬山算法的示例
在本节中,我们将爬山优化算法应用于一个目标函数。
首先,我们定义目标函数。
我们将使用一个简单的一维 x^2 目标函数,其边界为 [-5, 5]。
下面的示例定义了该函数,然后为输入值的网格创建了函数响应曲面的线图,并用红线标记了 f(0.0) = 0.0 的最优解。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 凸单峰优化函数 from numpy import arange from matplotlib import pyplot # 目标函数 def objective(x): return x[0]**2.0 # 定义输入范围 r_min, r_max = -5.0, 5.0 # 以 0.1 为增量均匀采样输入范围 inputs = arange(r_min, r_max, 0.1) # 计算目标值 results = [objective([x]) for x in inputs] # 绘制输入与结果的线图 pyplot.plot(inputs, results) # 定义最优输入值 x_optima = 0.0 # 在最优输入处画一条竖线 pyplot.axvline(x=x_optima, ls='--', color='red') # 显示绘图 pyplot.show() |
运行示例将创建目标函数的线图,并清晰地标记出函数的最优解。
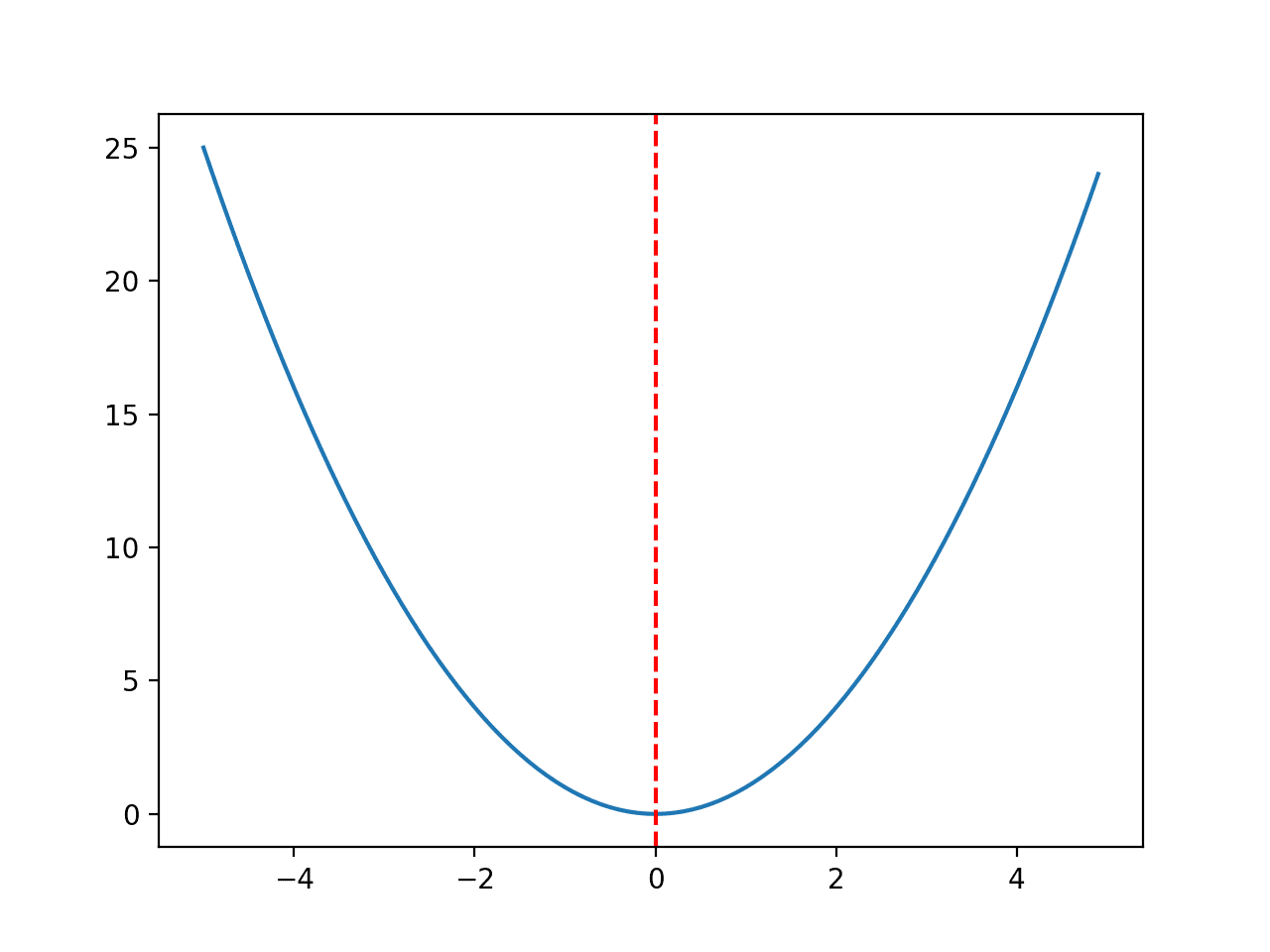
目标函数的线图,最优解用红色虚线标记。
接下来,我们可以将爬山算法应用于目标函数。
首先,我们将设置伪随机数生成器的种子。这通常不是必需的,但在本例中,我希望确保每次运行算法时都能获得相同的结果(相同的随机数序列),以便稍后绘制结果。
|
1 2 3 |
... # 播种伪随机数生成器 seed(5) |
接下来,我们可以定义搜索的配置。
在这种情况下,我们将搜索 1,000 次算法迭代,并使用 0.1 的步长。鉴于我们使用高斯函数生成步长,这意味着大约 99% 的步长将位于给定点 (0.1 * 3) 的距离内,例如三个标准差。
|
1 2 3 4 |
... n_iterations = 1000 # 定义最大步长 step_size = 0.1 |
接下来,我们可以执行搜索并报告结果。
|
1 2 3 4 5 |
... # 执行爬山搜索 best, score = hillclimbing(objective, bounds, n_iterations, step_size) print('Done!') print('f(%s) = %f' % (best, score)) |
将所有这些结合起来,完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# 一维目标函数的爬山搜索 from numpy import asarray from numpy.random import randn from numpy.random import rand from numpy.random import seed # 目标函数 def objective(x): return x[0]**2.0 # 爬山局部搜索算法 def hillclimbing(objective, bounds, n_iterations, step_size): # 生成初始点 solution = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 评估初始点 solution_eval = objective(solution) # 运行爬山算法 for i in range(n_iterations): # 迈出一步 candidate = solution + randn(len(bounds)) * step_size # 评估候选点 candidte_eval = objective(candidate) # 检查是否应该保留新点 if candidte_eval <= solution_eval: # 存储新点 solution, solution_eval = candidate, candidte_eval # 报告进度 print('>%d f(%s) = %.5f' % (i, solution, solution_eval)) return [solution, solution_eval] # 播种伪随机数生成器 seed(5) # 定义输入范围 bounds = asarray([[-5.0, 5.0]]) # 定义总迭代次数 n_iterations = 1000 # 定义最大步长 step_size = 0.1 # 执行爬山搜索 best, score = hillclimbing(objective, bounds, n_iterations, step_size) print('Done!') print('f(%s) = %f' % (best, score)) |
运行示例会报告搜索的进展,包括迭代次数、函数的输入以及每次检测到改进时目标函数的回应。
在搜索结束时,找到最佳解决方案并报告其评估结果。
在这种情况下,我们可以看到在算法的 1,000 次迭代中大约有 36 次改进,并且解决方案非常接近最优输入 0.0,其评估结果为 f(0.0) = 0.0。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
>1 f([-2.74290923]) = 7.52355 >3 f([-2.65873147]) = 7.06885 >4 f([-2.52197291]) = 6.36035 >5 f([-2.46450214]) = 6.07377 >7 f([-2.44740961]) = 5.98981 >9 f([-2.28364676]) = 5.21504 >12 f([-2.19245939]) = 4.80688 >14 f([-2.01001538]) = 4.04016 >15 f([-1.86425287]) = 3.47544 >22 f([-1.79913002]) = 3.23687 >24 f([-1.57525573]) = 2.48143 >25 f([-1.55047719]) = 2.40398 >26 f([-1.51783757]) = 2.30383 >27 f([-1.49118756]) = 2.22364 >28 f([-1.45344116]) = 2.11249 >30 f([-1.33055275]) = 1.77037 >32 f([-1.17805016]) = 1.38780 >33 f([-1.15189314]) = 1.32686 >36 f([-1.03852644]) = 1.07854 >37 f([-0.99135322]) = 0.98278 >38 f([-0.79448984]) = 0.63121 >39 f([-0.69837955]) = 0.48773 >42 f([-0.69317313]) = 0.48049 >46 f([-0.61801423]) = 0.38194 >48 f([-0.48799625]) = 0.23814 >50 f([-0.22149135]) = 0.04906 >54 f([-0.20017144]) = 0.04007 >57 f([-0.15994446]) = 0.02558 >60 f([-0.15492485]) = 0.02400 >61 f([-0.03572481]) = 0.00128 >64 f([-0.03051261]) = 0.00093 >66 f([-0.0074283]) = 0.00006 >78 f([-0.00202357]) = 0.00000 >119 f([0.00128373]) = 0.00000 >120 f([-0.00040911]) = 0.00000 >314 f([-0.00017051]) = 0.00000 完成! f([-0.00017051]) = 0.000000 |
检查搜索的进展,通过线图显示每次改进时最佳解决方案评估的变化,会很有趣。
我们可以更新 `hillclimbing()` 以跟踪每次改进时的目标函数评估,并返回此分数列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 爬山局部搜索算法 def hillclimbing(objective, bounds, n_iterations, step_size): # 生成初始点 solution = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 评估初始点 solution_eval = objective(solution) # 运行爬山算法 scores = list() scores.append(solution_eval) for i in range(n_iterations): # 迈出一步 candidate = solution + randn(len(bounds)) * step_size # 评估候选点 candidte_eval = objective(candidate) # 检查是否应该保留新点 if candidte_eval <= solution_eval: # 存储新点 solution, solution_eval = candidate, candidte_eval # 记录得分 scores.append(solution_eval) # 报告进度 print('>%d f(%s) = %.5f' % (i, solution, solution_eval)) return [solution, solution_eval, scores] |
然后我们可以创建这些分数的线图,以查看搜索过程中发现的每次改进的目标函数相对变化。
|
1 2 3 4 5 6 |
... # 最佳分数的线图 pyplot.plot(scores, '.-') pyplot.xlabel('Improvement Number') pyplot.ylabel('Evaluation f(x)') pyplot.show() |
将这些结合起来,下面列出了执行搜索并在搜索过程中绘制改进解决方案的目标函数分数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
# 一维目标函数的爬山搜索 from numpy import asarray from numpy.random import randn from numpy.random import rand from numpy.random import seed from matplotlib import pyplot # 目标函数 def objective(x): return x[0]**2.0 # 爬山局部搜索算法 def hillclimbing(objective, bounds, n_iterations, step_size): # 生成初始点 solution = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 评估初始点 solution_eval = objective(solution) # 运行爬山算法 scores = list() scores.append(solution_eval) for i in range(n_iterations): # 迈出一步 candidate = solution + randn(len(bounds)) * step_size # 评估候选点 candidte_eval = objective(candidate) # 检查是否应该保留新点 if candidte_eval <= solution_eval: # 存储新点 solution, solution_eval = candidate, candidte_eval # 记录得分 scores.append(solution_eval) # 报告进度 print('>%d f(%s) = %.5f' % (i, solution, solution_eval)) return [solution, solution_eval, scores] # 播种伪随机数生成器 seed(5) # 定义输入范围 bounds = asarray([[-5.0, 5.0]]) # 定义总迭代次数 n_iterations = 1000 # 定义最大步长 step_size = 0.1 # 执行爬山搜索 best, score, scores = hillclimbing(objective, bounds, n_iterations, step_size) print('Done!') print('f(%s) = %f' % (best, score)) # 最佳分数的线图 pyplot.plot(scores, '.-') pyplot.xlabel('Improvement Number') pyplot.ylabel('Evaluation f(x)') pyplot.show() |
运行示例将执行搜索并像以前一样报告结果。
创建了一个线图,显示了爬山搜索过程中每次改进的目标函数评估。我们可以看到在搜索过程中目标函数评估发生了大约 36 次变化,最初变化很大,而在搜索结束时,随着算法收敛到最优解,变化非常小甚至难以察觉。
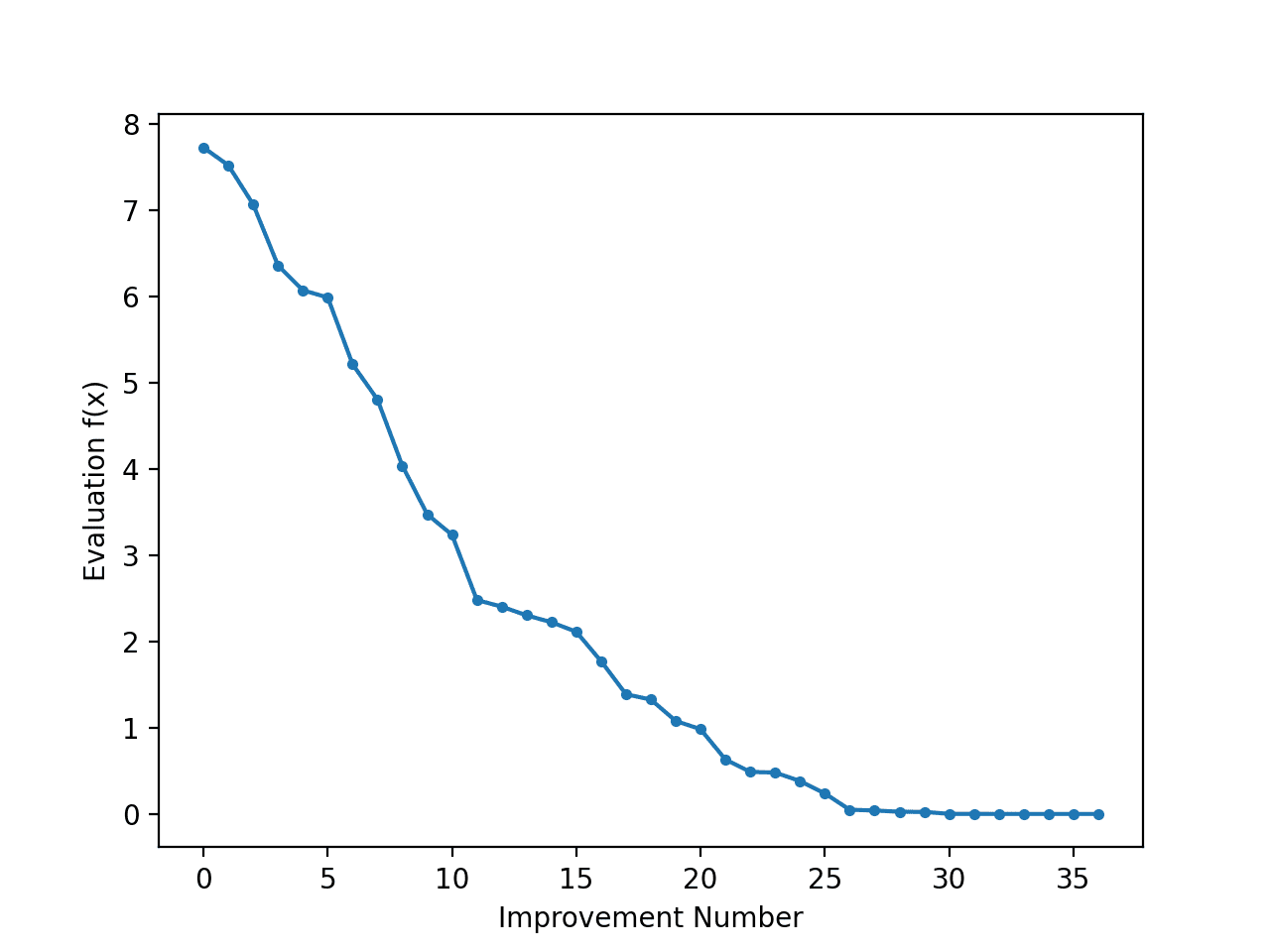
爬山搜索过程中每次改进的目标函数评估线图
鉴于目标函数是一维的,像上面那样绘制响应曲面非常简单。
通过将搜索过程中找到的最佳候选解决方案作为响应曲面上的点进行绘制,可以有趣地回顾搜索的进展。我们期望一系列点沿着响应曲面下降到最优解。
这可以通过首先更新 `hillclimbing()` 函数来实现在搜索过程中跟踪每个最佳候选解决方案,然后返回最佳解决方案列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 爬山局部搜索算法 def hillclimbing(objective, bounds, n_iterations, step_size): # 生成初始点 solution = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 评估初始点 solution_eval = objective(solution) # 运行爬山算法 solutions = list() solutions.append(solution) for i in range(n_iterations): # 迈出一步 candidate = solution + randn(len(bounds)) * step_size # 评估候选点 candidte_eval = objective(candidate) # 检查是否应该保留新点 if candidte_eval <= solution_eval: # 存储新点 solution, solution_eval = candidate, candidte_eval # 记录解决方案 solutions.append(solution) # 报告进度 print('>%d f(%s) = %.5f' % (i, solution, solution_eval)) return [solution, solution_eval, solutions] |
然后我们可以像以前一样创建目标函数响应曲面的图,并标记最优解。
|
1 2 3 4 5 6 7 |
... # 以 0.1 为增量均匀采样输入范围 inputs = arange(bounds[0,0], bounds[0,1], 0.1) # 绘制输入与结果的线图 pyplot.plot(inputs, [objective([x]) for x in inputs], '--') # 在最优输入处画一条竖线 pyplot.axvline(x=[0.0], ls='--', color='red') |
最后,我们可以将搜索找到的候选解序列绘制为黑点。
|
1 2 3 |
... # 将样本绘制为黑色圆圈 pyplot.plot(solutions, [objective(x) for x in solutions], 'o', color='black') |
将这些结合起来,下面列出了在目标函数响应曲面上绘制改进解决方案序列的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
# 一维目标函数的爬山搜索 from numpy import asarray from numpy import arange from numpy.random import randn from numpy.random import rand from numpy.random import seed from matplotlib import pyplot # 目标函数 def objective(x): return x[0]**2.0 # 爬山局部搜索算法 def hillclimbing(objective, bounds, n_iterations, step_size): # 生成初始点 solution = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 评估初始点 solution_eval = objective(solution) # 运行爬山算法 solutions = list() solutions.append(solution) for i in range(n_iterations): # 迈出一步 candidate = solution + randn(len(bounds)) * step_size # 评估候选点 candidte_eval = objective(candidate) # 检查是否应该保留新点 if candidte_eval <= solution_eval: # 存储新点 solution, solution_eval = candidate, candidte_eval # 记录解决方案 solutions.append(solution) # 报告进度 print('>%d f(%s) = %.5f' % (i, solution, solution_eval)) return [solution, solution_eval, solutions] # 播种伪随机数生成器 seed(5) # 定义输入范围 bounds = asarray([[-5.0, 5.0]]) # 定义总迭代次数 n_iterations = 1000 # 定义最大步长 step_size = 0.1 # 执行爬山搜索 best, score, solutions = hillclimbing(objective, bounds, n_iterations, step_size) print('Done!') print('f(%s) = %f' % (best, score)) # 以 0.1 为增量均匀采样输入范围 inputs = arange(bounds[0,0], bounds[0,1], 0.1) # 绘制输入与结果的线图 pyplot.plot(inputs, [objective([x]) for x in inputs], '--') # 在最优输入处画一条竖线 pyplot.axvline(x=[0.0], ls='--', color='red') # 将样本绘制为黑色圆圈 pyplot.plot(solutions, [objective(x) for x in solutions], 'o', color='black') pyplot.show() |
运行该示例将执行爬山搜索并像以前一样报告结果。
像之前一样创建了一个响应曲面图,显示了函数熟悉的碗形,并用垂直红线标记了函数的最优解。
搜索过程中找到的最佳解决方案序列以黑点显示,沿着碗形向下移动到最优解。
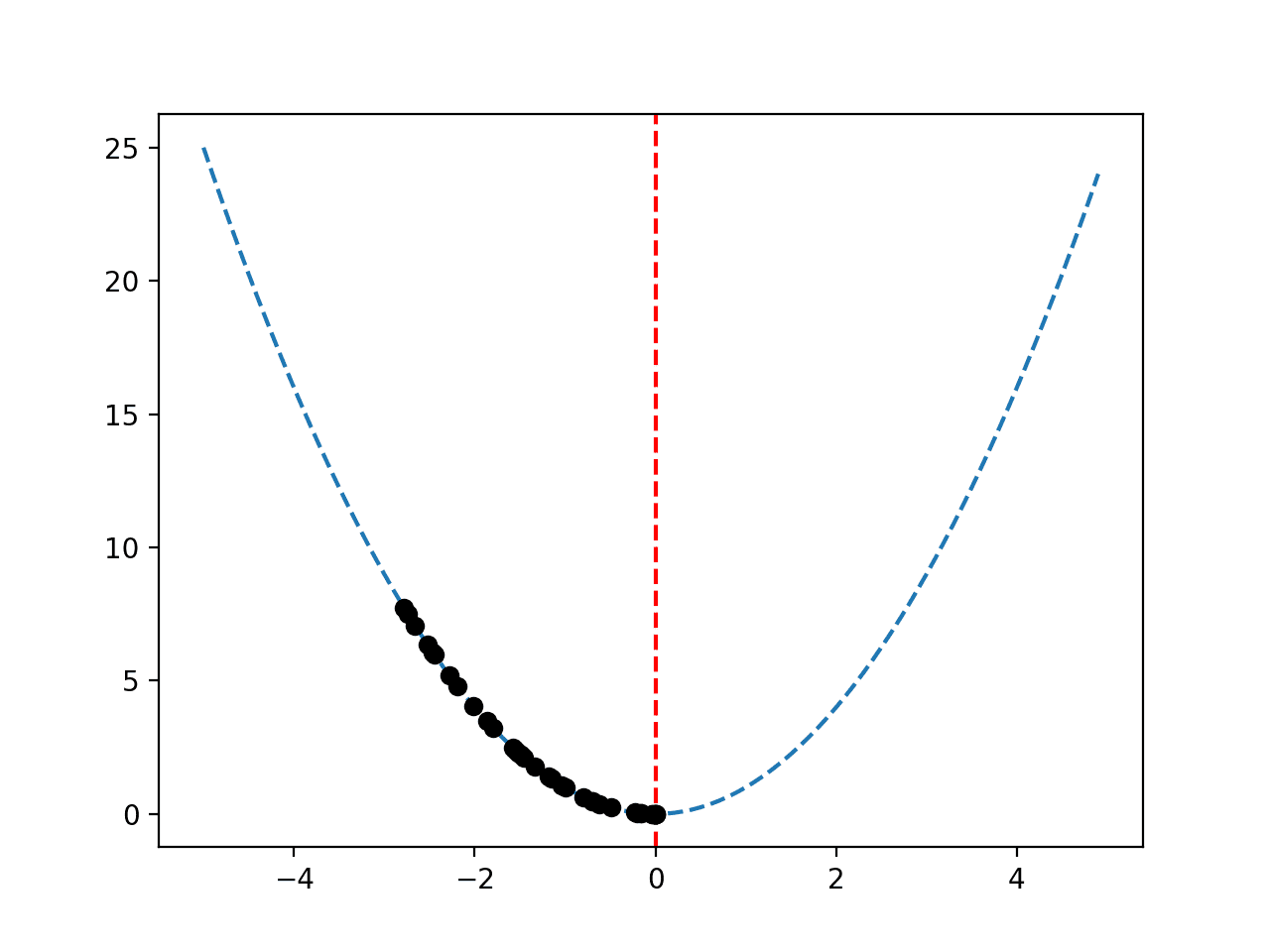
目标函数响应曲面图,最佳解决方案序列以黑点绘制。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
书籍
API
文章
总结
在本教程中,您学习了用于函数优化的爬山优化算法。
具体来说,你学到了:
- 爬山算法是一种用于函数优化的随机局部搜索算法。
- 如何在 Python 中从零开始实现爬山算法。
- 如何应用爬山算法并检查算法的结果。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







实验方法。如果我们有具有 784 个输入变量的普通数学函数,我们可以进行实验,提前知道全局最小值。然后作为实验,采样 100 个点作为机器学习函数 y = model(X) 的输入。在 yt,Xt 上训练以达到全局最小值。损失 = 0。这可能有助于训练超参数吗?
当然可以。
尊敬的Jason博士,
如果你有一个函数,例如像微积分问题中那样有多个极小值和极大值,该怎么办?极小值和极大值图的示例:https://scientificsentence.net/Equations/CalculusII/extrema.jpg 。
请问:
(1) 爬山算法能否确定方程的极大值和极小值?
(2) 我知道牛顿法求解极小值(例如)。它是一种迭代算法,形式为:
当差值 x(n) – f(x(n))/f'(x(n)) 小于给定值时,迭代停止。
换句话说,爬山算法比牛顿法有什么优势?
谢谢你,
悉尼的Anthony
爬山算法通常适用于单峰(单一最优解)问题。
您可以多次应用它来寻找最优解,但您也可以对域进行网格搜索。
爬山算法不需要一阶或二阶导数,也不要求目标函数可微。
尊敬的Jason博士,
要点——爬山算法是单峰的,不需要导数,即微积分。对于多个极小值和极大值,请使用网格搜索。
谢谢,对此深表感谢。
悉尼的Anthony
第一部分是肯定的,第二部分则不完全是。
有数十种(数百种)替代算法可用于多峰优化问题,包括重复应用爬山算法(例如,多次重启的爬山算法)。网格搜索可能是搜索域效率最低的方法之一,但如果您有一个小域或大量的计算/时间,那将非常棒。
尊敬的Jason博士,
谢谢你,
悉尼的Anthony