我们编写程序来解决问题或创建一个工具,我们可以反复解决类似的问题。对于后者,我们不可避免地会回顾我们编写的程序,或者其他人会重用我们编写的程序。我们还有可能遇到在编写程序时未预见到的数据。毕竟,我们仍然希望我们的程序能够**正常工作**。我们可以通过一些技术和心态来编写更健壮的代码。
完成本教程后,你将学到:
- 如何为意外情况准备代码
- 如何为代码无法处理的情况发出适当的信号
- 编写更健壮程序的最佳实践是什么
通过我的新书Python for Machine Learning快速启动您的项目,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧!
编写更优 Python 代码的技巧
照片来源:Anna Shvets。部分权利保留。
概述
本教程分为三个部分;它们是:
- 净化和断言式编程
- 护栏和防御性编程
- 避免错误的最佳实践
净化和断言式编程
当我们在 Python 中编写函数时,我们通常会接收一些参数并返回一些值。毕竟,函数应该就是这样的。由于 Python 是一种鸭子类型语言,很容易发现一个接受数字的函数被用字符串调用。例如:
|
1 2 3 4 |
def add(a, b): return a + b c = add("one", "two") |
这段代码可以正常工作,因为 Python 字符串中的 `+` 运算符表示连接。因此没有语法错误;这只是我们对该函数的不当使用。
这本身不是大问题,但如果函数很长,我们不应该在后期才发现问题。例如,在训练机器学习模型数小时后,我们的程序因这种错误而失败并终止,浪费了我们数小时的等待时间。如果我们能够主动验证我们所做的假设,那就更好了。这也有助于我们向阅读我们代码的其他人传达我们对代码的期望。
一个相当长的代码中常见的做法是**净化输入**。例如,我们可以将上面的函数重写为如下形式:
|
1 2 3 4 |
def add(a, b): if not isinstance(a, (int, float)) or not isinstance(b, (int, float)) or not isinstance(c, (int, float)): raise ValueError("Input must be numbers") return a + b |
或者,更好的是,在可能的情况下将输入转换为浮点数
|
1 2 3 4 5 6 7 |
def add(a, b): try: a = float(a) b = float(b) except ValueError: raise ValueError("Input must be numbers") return a + b |
这里的关键是在函数开头进行一些“净化”,这样之后,我们就可以假设输入是某种格式。这不仅让我们更有信心我们的代码能够按预期工作,而且由于净化可以排除一些情况,它还可以简化我们的主算法。为了说明这一点,我们可以看看如何重新实现内置的 `range()` 函数
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def range(a, b=None, c=None): if c is None: c = 1 if b is None: b = a a = 0 values = [] n = a while n < b: values.append(n) n = n + c return values |
这是 Python 内置库中 `range()` 的简化版本。但通过函数开头的两个 `if` 语句,我们知道变量 `a`、`b` 和 `c` 始终有值。然后,`while` 循环就可以这样编写。否则,我们必须考虑三种不同的调用 `range()` 的情况,即 `range(10)`、`range(2,10)` 和 `range(2,10,3)`,这将使我们的 `while` 循环更加复杂且容易出错。
净化输入的另一个原因是**规范化**。这意味着我们应该将输入格式化为标准化格式。例如,URL 应以“http://”开头,文件路径应始终是绝对路径,如 `/etc/passwd`,而不是像 `/tmp/../etc/././passwd` 这样的路径。规范化的输入更容易检查一致性(例如,我们知道 `/etc/passwd` 包含敏感的系统数据,但我们不确定 `/tmp/../etc/././passwd`)。
您可能会想,是否有必要通过添加这些净化来增加代码长度。当然,这是您需要决定的权衡。通常,我们不会在每个函数上都这样做,以节省精力,也不会损害计算效率。我们只在可能出错的地方这样做,即在我们作为 API 暴露给其他用户的接口函数中,或者在我们从用户命令行获取输入的函数中。
但是,我们想指出以下方法是错误的,但却是常见的净化方法:
|
1 2 3 4 |
def add(a, b): assert isinstance(a, (int, float)), "`a` 必须是一个数字" assert isinstance(b, (int, float)), "`b` 必须是一个数字" return a + b |
Python 中的 `assert` 语句会在第一个参数不为 `True` 时引发 `AssertError` 异常(附带提供的可选消息)。虽然引发 `AssertError` 和引发 `ValueError` 在处理意外输入时没有实际区别,但使用 `assert` 不被推荐,因为我们可以通过在 Python 命令中使用 `-O` 选项来“优化掉”我们的代码,即:
|
1 |
$ python -O script.py |
在这种情况下,`script.py` 代码中的所有 `assert` 都将被忽略。因此,如果我们的目的是停止代码执行(包括您想在更高层面捕获异常),您应该使用 `if` 并显式引发异常,而不是使用 `assert`。
`assert` 的正确用法是在开发代码时帮助我们进行调试。例如:
|
1 2 3 4 5 6 7 |
def evenitems(arr): newarr = [] for i in range(len(arr)): if i % 2 == 0: newarr.append(arr[i]) assert len(newarr) * 2 >= len(arr) return newarr |
在开发此函数时,我们不确定我们的算法是否正确。有很多事情需要检查,但在这里我们想确保如果我们从输入中提取了所有偶数索引的项,它的长度应该至少是输入数组的一半。当我们尝试优化算法或完善代码时,此条件不得失效。我们将 `assert` 语句保留在战略位置,以确保在修改代码后我们没有破坏它。您可以将此视为单元测试的一种不同方式。但通常,当我们在检查函数输入和输出是否符合预期时,我们称之为单元测试。以这种方式使用 `assert` 是为了检查函数内部的步骤。
如果我们编写复杂的算法,添加 `assert` 来检查**循环不变量**(即循环应满足的条件)会很有帮助。考虑以下在已排序数组中进行二分搜索的代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def binary_search(array, target): """在数组中二分搜索目标值 参数 array: 已排序数组 target: 要搜索的元素 返回 数组索引 n,使得 array[n]==target 如果未找到目标,则返回 -1 """ s,e = 0, len(array) while s < e: m = (s+e)//2 if array[m] == target: return m elif array[m] > target: e = m elif array[m] < target: s = m+1 assert m != (s+e)//2, "我们没有移动我们的中点" return -1 |
最后一个 `assert` 语句用于维护我们的循环不变量。这是为了确保我们在更新起始游标 `s` 和结束游标 `e` 的逻辑上没有出错,从而在中点 `m` 在下一次迭代中不会更新。如果我们用 `s = m` 替换了最后一个 `elif` 分支中的 `s = m+1`,并在数组中不存在某些目标时使用该函数,断言语句将警告我们此错误。这就是为什么这项技术可以帮助我们编写更好的代码。
护栏和防御性编程
Python 内置了 `NotImplementedError` 异常,这一点令人惊叹。这对于我们所谓的**防御性编程**很有用。
虽然输入净化是为了帮助将输入对齐到我们的代码所期望的格式,但有时很难净化所有内容,或者这会给未来的开发带来不便。例如,在以下代码中,我们定义了一个注册装饰器和一些函数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import math REGISTRY = {} def register(name): def _decorator(fn): REGISTRY[name] = fn return fn return _decorator @register("relu") def rectified(x): return x if x > 0 else 0 @register("sigmoid") def sigmoid(x): return 1/(1 + math.exp(-x)) def activate(x, funcname): if funcname not in REGISTRY: raise NotImplementedError(f"函数 {funcname} 未实现") else: func = REGISTRY[funcname] return func(x) print(activate(1.23, "relu")) print(activate(1.23, "sigmoid")) print(activate(1.23, "tanh")) |
我们在 `activate()` 函数中用自定义的错误消息引发了 `NotImplementedError`。运行此代码将为您打印前两个调用的结果,但第三个调用会失败,因为我们还没有定义 `tanh` 函数。
|
1 2 3 4 5 6 7 8 |
1.23 0.7738185742694538 回溯(最近一次调用) File "/Users/MLM/offensive.py", line 28, in <module> print(activate(1.23, "tanh")) File "/Users/MLM/offensive.py", line 21, in activate raise NotImplementedError(f"Function {funcname} is not implemented") NotImplementedError: Function tanh is not implemented |
您可以想象,我们可以在条件不完全无效的地方引发 `NotImplementedError`,但只是因为我们还没有准备好处理这些情况。这在我们逐步开发程序时很有用,我们一次实现一种情况,稍后处理一些边缘情况。拥有这些护栏可以确保我们尚未完成的代码不会被以错误的方式使用。这也是一种使代码更难被滥用的好方法,即不要让变量在没有通知的情况下超出我们预期的范围。
事实上,Python 的异常处理系统非常成熟,我们应该使用它。当您从不期望输入为负数时,请引发带有适当消息的 `ValueError`。同样,当发生意外情况时,例如您创建的临时文件在中间过程消失了,请引发 `RuntimeError`。在这些情况下,您的代码无论如何都不会正常工作,而引发适当的异常可以帮助未来的重用。从性能角度来看,您还会发现引发异常比使用 if 语句进行检查更快。这就是为什么在 Python 中,我们更倾向于“请求原谅比请求许可更容易”(EAFP),而不是“三思而后行”(LBYL)。
这里的原则是,您永远不应该让异常静默进行,因为您的算法将无法正确运行,有时还会产生危险的影响(例如,删除错误的文件或产生网络安全问题)。
想开始学习机器学习 Python 吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
避免错误的最佳实践
我们编写的代码不可能没有错误。它就像我们测试它一样好,但我们不知道我们不知道的事情。总是有可能以意想不到的方式破坏代码。但是,有一些实践可以促进编写高质量、错误更少代码。
首先是使用函数式范式。虽然我们知道 Python 有一些结构允许我们用函数式语法编写算法,但函数式编程的原则是在函数调用中不产生副作用。我们从不修改任何内容,也不使用在函数外部声明的变量。“无副作用”原则非常强大,可以避免许多错误,因为我们永远不会错误地更改某些内容。
当我们用 Python 编写时,有一些常见的意外情况是我们无意中修改了数据结构。考虑以下示例:
|
1 2 3 |
def func(a=[]): a.append(1) return a |
很容易看出这个函数的作用。但是,当我们调用此函数而不带任何参数时,将使用默认值并返回 `[1]`。当我们再次调用它时,将使用不同的默认值并返回 `[1,1]`。这是因为我们在函数声明中创建的列表 `[]` 是 `a` 参数的默认值,它是一个已初始化的对象。当我们向其追加值时,该对象将被修改。下次调用该函数时将看到已修改的对象。
除非我们明确想要这样做(例如,原地排序算法),否则我们不应将函数参数用作变量,而应将它们用作只读。并且在合适的情况下,我们应该制作一份副本。例如:
|
1 2 3 4 5 6 7 8 9 10 |
LOGS = [] def log(action): LOGS.append(action) data = {"name": None} for n in ["Alice", "Bob", "Charlie"]: data["name"] = n ... # do something with `data` log(data) # keep a record of what we did |
这段代码的意图是将操作记录在 `LOGS` 列表中,但它没有这样做。当我们处理“Alice”、“Bob”然后“Charlie”的名字时,`LOGS` 中的三个记录都将是“Charlie”,因为我们将可变字典对象保存在那里。它应该被更正为如下:
|
1 2 3 4 5 |
import copy def log(action): copied_action = copy.deepcopy(action) LOGS.append(copied_action) |
然后我们将在日志中看到这三个不同的名字。总而言之,如果传递给函数的参数是可变对象,我们应该小心。
避免错误的另一种技术是不要重复造轮子。在 Python 中,我们有许多很棒的容器和优化的操作。您永远不应该尝试自己创建堆栈数据结构,因为列表支持 `append()` 和 `pop()`。您的实现不会更快。同样,如果您需要队列,我们在标准库的 `collections` 模块中有 `deque`。Python 没有提供平衡搜索树或链表。但是字典经过了高度优化,我们应该尽可能考虑使用字典。同样的心态也适用于函数。我们有一个 JSON 库,我们不应该编写自己的。如果您需要一些数值算法,请检查是否可以从 NumPy 获取。
避免错误的另一种方法是使用更好的逻辑。具有大量循环和分支的算法很难理解,甚至可能让我们自己感到困惑。如果我们可以使代码更清晰,那么更容易发现错误。例如,创建一个函数来检查矩阵的上三角部分是否包含任何负数,代码如下:
|
1 2 3 4 5 6 7 8 9 10 |
def neg_in_upper_tri(matrix): n_rows = len(matrix) n_cols = len(matrix[0]) for i in range(n_rows): for j in range(n_cols): if i > j: continue # 我们不在上三角区域 if matrix[i][j] < 0: return True return False |
但我们也使用 Python 生成器将其分解为两个函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def get_upper_tri(matrix): n_rows = len(matrix) n_cols = len(matrix[0]) for i in range(n_rows): for j in range(n_cols): if i > j: continue # 我们不在上三角区域 yield matrix[i][j] def neg_in_upper_tri(matrix): for element in get_upper_tri(matrix): if element[i][j] < 0: return True return False |
我们多写了几行代码,但我们让每个函数都专注于一个主题。如果函数更复杂,将嵌套循环拆分为生成器可以帮助我们使代码更易于维护。
让我们考虑另一个例子:我们想写一个函数来检查输入字符串是否看起来像有效的浮点数或整数。我们要求字符串为“0.12”,但不接受“.12”。我们需要整数像“12”,但不是“12.”。我们也无法接受科学计数法,如“1.2e-1”或千位分隔符,如“1,234.56”。为了简化,我们也不考虑符号,如“+1.23”或“-1.23”。
我们可以编写一个函数,从第一个字符扫描到最后一个字符,并记住到目前为止我们看到的内容。然后检查我们看到的内容是否符合我们的预期。代码如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
def isfloat(floatstring): if not isinstance(floatstring, str): raise ValueError("Expects a string input") seen_integer = False seen_dot = False seen_decimal = False for char in floatstring: if char.isdigit(): if not seen_integer: seen_integer = True elif seen_dot and not seen_decimal: seen_decimal = True elif char == ".": if not seen_integer: return False # 例如,“.3456” elif not seen_dot: seen_dot = True else: return False # 例如,“1..23” else: return False # 例如,“foo” if not seen_integer: return False # 例如,“” if seen_dot and not seen_decimal: return False # 例如,“2.” return True print(isfloat("foo")) # False print(isfloat(".3456")) # False print(isfloat("1.23")) # True print(isfloat("1..23")) # False print(isfloat("2")) # True print(isfloat("2.")) # False print(isfloat("2,345.67")) # False |
上面的 `isfloat()` 函数在 for 循环中有许多嵌套的分支,看起来很混乱。即使在 for 循环之后,确定布尔值的逻辑也不是完全清楚。事实上,我们可以使用不同的方式来编写代码,使其不那么容易出错,例如使用状态机模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
def isfloat(floatstring): if not isinstance(floatstring, str): raise ValueError("Expects a string input") # 状态:“开始”、“整数”、“点”、“小数” state = "start" for char in floatstring: if state == "start": if char.isdigit(): state = "integer" else: return False # 过渡无效,无法继续 elif state == "integer": if char.isdigit(): pass # 保持在同一状态 elif char == ".": state = "dot" else: return False # 过渡无效,无法继续 elif state == "dot": if char.isdigit(): state = "decimal" else: return False # 过渡无效,无法继续 elif state == "decimal": if not char.isdigit(): return False # 过渡无效,无法继续 if state in ["integer", "decimal"]: return True else: return False print(isfloat("foo")) # False print(isfloat(".3456")) # False print(isfloat("1.23")) # True print(isfloat("1..23")) # False print(isfloat("2")) # True print(isfloat("2.")) # False print(isfloat("2,345.67")) # False |
视觉上,我们将下面的图表转换为代码。我们维护一个状态变量,直到我们完成扫描输入字符串。状态将决定是否接受输入中的字符并移至另一个状态,或拒绝字符并终止。此函数仅在停止在可接受状态(即“整数”或“小数”)时返回 True。这段代码更容易理解,也更有条理。
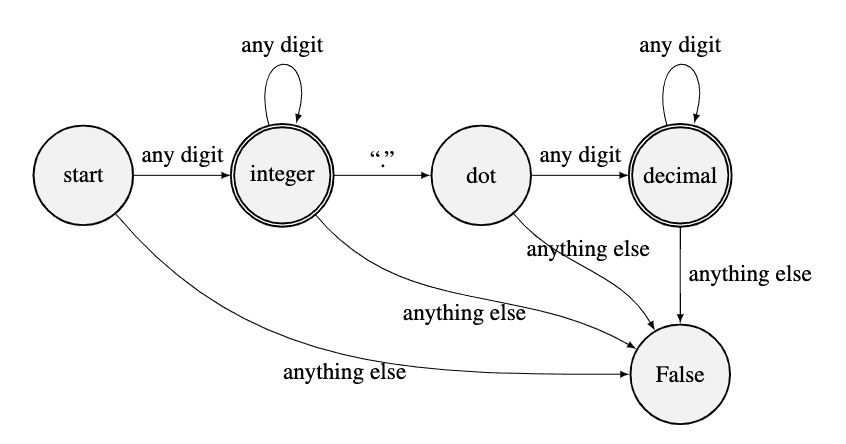
事实上,更好的方法是使用正则表达式来匹配输入字符串,即,
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import re def isfloat(floatstring): if not isinstance(floatstring, str): raise ValueError("Expects a string input") m = re.match(r"\d+(\.\d+)?$", floatstring) return m is not None print(isfloat("foo")) # False print(isfloat(".3456")) # False print(isfloat("1.23")) # True print(isfloat("1..23")) # False print(isfloat("2")) # True print(isfloat("2.")) # False print(isfloat("2,345.67")) # False |
然而,正则表达式匹配器在后台也在运行一个状态机。
关于这个主题还有很多可以探讨的。例如,我们如何更好地分离函数和对象的职责,以使我们的代码更易于维护和理解。有时,使用不同的数据结构可以让我们编写更简单的代码,这有助于使我们的代码更健壮。这不是一门科学,但几乎总是,如果代码更简单,就可以避免错误。
最后,考虑为您的项目采用一种编码风格。拥有一个写代码的一致方式是在以后阅读自己写的东西时,可以分担一些精神负担的第一步。这也使您更容易发现错误。
延伸阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
书籍
- Building Secure Software by John Viega and Gary R. McGraw
- Building Secure and Reliable Systems by Heather Adkins et al
- The Hitchhiker’s Guide to Python by Kenneth Reitz and Tanya Schlusser
- The Practice of Programming by Brian Kernighan and Rob Pike
- Refactoring, 2nd Edition, by Martin Fowler
总结
在本教程中,您已经了解了使代码更好的高级技术。它可以为不同的情况做好更好的准备,因此它能更严格地工作。它也更容易阅读、维护和扩展,因此适合将来重用。这里提到的一些技术也适用于其他编程语言。
具体来说,你学到了:
- 为什么我们要对输入进行清理,以及它如何帮助我们简化程序
- 正确使用 `assert` 作为辅助开发的工具
- 如何恰当地使用 Python 异常来在意外情况中发出信号
- Python 编程中处理可变对象的陷阱
掌握机器学习 Python!

更自信地用 Python 编写代码
...从学习实用的 Python 技巧开始
在我的新电子书中探索如何实现
用于机器学习的 Python
它提供自学教程和数百个可运行的代码,为您提供包括以下技能:
调试、性能分析、鸭子类型、装饰器、部署等等...


")



如何将我们的机器学习代码转换为简单的软件,包含文件、编辑和退出,非常感谢。
如果您想构建一个 UI 来与生产环境中的模型进行交互,有几种 Python GUI 框架可用,例如 pyGUI
很棒的教程,谢谢!
在函数中
def neg_in_upper_tri(matrix)
for element in get_upper_tri(matrix)
if element[i][j] < 0
return True
return False
它应该是 element (而不是 element[i][j]),对吗?
你好 Eric…不客气!你收到提供的代码错误了吗?请分享你的发现。