使用深度学习进行预测建模是现代开发人员需要掌握的一项技能。
TensorFlow 是由 Google 开发和维护的领先的开源深度学习框架。虽然直接使用 TensorFlow 可能具有挑战性,但现代的 tf.keras API 将 Keras 的简洁性和易用性带入了 TensorFlow 项目。
使用 tf.keras,您只需几行代码即可设计、训练、评估和使用深度学习模型进行预测。它使得诸如分类和回归预测建模等常见的深度学习任务对希望完成工作的普通开发人员来说变得易于使用。
在本教程中,您将发现使用 tf.keras API 在 TensorFlow 中开发深度学习模型的循序渐进指南。
完成本教程后,您将了解:
- Keras 和 tf.keras 之间的区别以及如何安装和验证 TensorFlow 是否正常工作
- tf.keras 模型生命周期的 5 个步骤以及如何使用顺序 API 和函数式 API
- 如何使用 tf.keras 为回归、分类和时间序列预测开发 MLP、CNN 和 RNN 模型
- 如何使用 tf.keras API 的高级功能来检查和诊断您的模型
- 如何通过减少过拟合和加速训练来提高 tf.keras 模型的性能
这是一个冗长的教程,而且非常有趣。您可能想将其收藏。
示例代码精简且有针对性;您大约可以在 60 分钟内完成本教程。
通过我的新书《Python 深度学习》开启您的项目,其中包含分步教程以及所有示例的Python 源代码文件。
让我们开始吧。
- 更新于 2020 年 6 月:已针对 TensorFlow 2.2.0 中的 API 更改进行了更新。

如何使用 tf.keras 开发深度学习模型
照片由 Stephen Harlan 拍摄,保留部分权利。
TensorFlow 教程概述
本教程旨在成为您深度学习项目的 tf.keras 的完整入门指南。
重点是使用该 API 进行常见的深度学习模型开发任务;您不会深入研究深度学习的数学和理论。对于这方面,我推荐从这本出色的书开始。
在 Python 中学习深度学习的最佳方法是动手实践。立即开始。您可以稍后再回头学习更多理论。
每个代码示例都旨在遵循最佳实践并且是独立的,因此您可以直接将其复制并粘贴到您的项目中,并根据您的具体需求进行调整。这将使您比仅从官方文档中摸索 API 的情况领先一大步。
这是一个广泛的教程,因此它分为五个部分;它们是
- 安装 TensorFlow 和 tf.keras
- 什么是 Keras 和 tf.keras?
- 如何安装 TensorFlow
- 如何确认 TensorFlow 已安装
- 深度学习模型生命周期
- 模型生命周期的 5 个步骤
- 顺序模型 API (简单)
- 函数式模型 API (高级)
- 如何开发深度学习模型
- 开发多层感知机模型
- 开发卷积神经网络模型
- 开发循环神经网络模型
- 如何使用高级模型功能
- 如何可视化深度学习模型
- 如何绘制模型学习曲线
- 如何保存和加载您的模型
- 如何获得更好的模型性能
- 如何通过 Dropout 减少过拟合
- 如何通过 Batch Normalization 加速训练
- 如何通过早停法在正确的时间停止训练
您可以在 Python 中进行深度学习!
按照您自己的进度完成教程。
您不必立即理解所有内容。您的目标是端到端地完成教程并获得结果。您不必在第一遍就理解所有内容。边做边记下您的问题。大量使用 API 文档来了解您正在使用的所有函数。
您不必先了解数学。数学是一种简洁地描述算法工作原理的方法,特别是来自线性代数、概率和统计学的工具。这些并不是您可以用来了解算法如何工作的唯一工具。您还可以使用代码,并通过不同的输入和输出来探索算法行为。了解数学并不能告诉您选择哪种算法或如何最好地配置它。您只能通过仔细、受控的实验来发现这一点。
您不必了解算法的工作原理。了解深度学习算法的局限性和如何配置它们很重要。但是学习算法可以稍后进行。您需要花费很长时间来慢慢积累这种算法知识。今天,先熟悉平台。
您不必是 Python 程序员。如果您不熟悉 Python 语言,其语法可能很直观。与其他语言一样,专注于函数调用(例如,function())和赋值(例如,a = “b”)。这将帮助您大部分时间。您是一名开发者,所以您知道如何快速掌握一门语言的基础知识。现在就开始,稍后深入细节。
您不必是深度学习专家。您以后可以了解各种算法的优点和局限性。有很多帖子可以供您以后阅读,以巩固深度学习项目的步骤以及使用交叉验证评估模型技能的重要性。
1. 安装 TensorFlow 和 tf.keras
在本节中,您将了解 tf.keras 是什么,如何安装它,以及如何确认它已正确安装。
1.1 什么是 Keras 和 tf.keras?
Keras 是一个用 Python 编写的开源深度学习库。
该项目由 Francois Chollet 于 2015 年启动。它很快成为开发人员的热门框架,成为最受欢迎的深度学习库之一,如果不是最受欢迎的。
在 2015 年到 2019 年之间,使用 TensorFlow、Theano 和 PyTorch 等数学库开发深度学习模型非常繁琐,需要数十甚至数百行代码才能完成最简单的任务。这些库的重点是研究、灵活性和速度,而不是易用性。
Keras 之所以流行,是因为其 API 简洁明了,能够用几行代码定义、训练和评估标准的深度学习模型。
Keras 流行起来的另一个原因是,它允许您使用一系列流行的深度学习数学库作为后端(例如,用于执行计算),例如 TensorFlow、Theano,以及后来的 CNTK。这使得能够利用这些库(例如 GPU)的强大功能,同时拥有一个非常简洁明了的界面。
2019 年,Google 发布了其 TensorFlow 深度学习库的新版本(TensorFlow 2),该版本直接集成了 Keras API,并将此接口作为该平台深度学习开发的默认或标准接口。
这种集成通常被称为tf.keras 接口或 API(“tf”是“TensorFlow”的缩写)。这是为了将其与所谓的独立 Keras 开源项目区分开来。
- 独立 Keras: 支持 TensorFlow、Theano 和 CNTK 后端的独立开源项目
- tf.keras: 集成到 TensorFlow 2 中的 Keras API
如今,由于 TensorFlow 2 的其他后端功能相形见绌,最新的 Keras 库仅支持 TensorFlow,并且这两者是相同的。
Keras 中的 Keras API 实现被称为“tf.keras”,因为这是引用 API 时使用的 Python 习惯用法。首先,导入 TensorFlow 模块并将其命名为“tf”;然后,通过调用 tf.keras 来访问 Keras API 元素;例如
|
1 2 3 4 5 |
# tf.keras Python 习惯用法的示例 import tensorflow as tf # 使用 keras API model = tf.keras.Sequential() ... |
鉴于 TensorFlow 是 Keras 开源项目的实际标准后端,这次集成意味着现在可以使用一个库而不是两个单独的库。此外,独立 Keras 项目现在建议所有未来的 Keras 开发都使用 tf.keras API。
目前,我们建议使用多后端 Keras 和 TensorFlow 后端的用户切换到 TensorFlow 2.0 中的 tf.keras。tf.keras 维护得更好,并且与 TensorFlow 功能(例如,即时执行、分布式支持等)的集成更好。
—— Keras 项目主页,2019 年 12 月访问。
1.2 如何安装 TensorFlow
在安装 TensorFlow 之前,请确保您已安装 Python,例如 Python 3.6 或更高版本。
如果您没有安装 Python,可以使用 Anaconda 安装。本教程将向您展示如何操作
安装 TensorFlow 开源深度学习库的方法有很多。
在您的工作站上安装 TensorFlow 的最常见、也许也是最简单的方法是使用 pip。
例如,在命令行中,您可以输入
|
1 |
sudo pip install tensorflow |
如果您更喜欢使用特定于您的平台或包管理器的安装方法,您可以在此处查看完整的安装说明列表
现在无需设置 GPU。
本教程中的所有示例在现代 CPU 上都能正常运行。如果您想为 GPU 配置 TensorFlow,可以在完成本教程后进行。不要分心!
1.3 如何确认 TensorFlow 已安装
安装 TensorFlow 后,确认该库已成功安装并且您可以使用它非常重要。
不要跳过此步骤.
如果 TensorFlow 未正确安装或在此步骤中引发错误,您将无法运行后面的示例。
创建一个名为 versions.py 的新文件,并将以下代码复制粘贴到该文件中。
|
1 2 3 |
# 检查版本 import tensorflow print(tensorflow.__version__) |
保存文件,然后打开您的命令行,并将目录更改为您保存文件的位置。
然后输入
|
1 |
python versions.py |
然后您应该会看到以下输出
|
1 |
2.2.0 |
这可以确认 TensorFlow 已正确安装,并且您正在使用与本教程相同的版本。
您获得了什么版本?
请在下方的评论中发布您的输出。
这还向您展示了如何从命令行运行 Python 脚本。您应该以这种方式从命令行运行所有代码,而不是从笔记本或 IDE 运行。
如果您收到警告消息
有时在使用 tf.keras API 时,您可能会看到打印的警告。
这可能包括您的硬件支持 TensorFlow 安装未配置使用的功能的消息。
您工作站上的一些示例如
|
1 2 3 |
您的 CPU 支持此 TensorFlow 二进制文件未编译使用的指令:AVX2 FMA XLA 服务 0x7fde3f2e6180 在平台 Host 上执行计算。设备 StreamExecutor 设备 (0): Host, Default Version |
这不是您的错。您没有做错任何事。
这些是信息消息,不会阻止您的代码执行。目前您可以安全地忽略此类消息。
这是 TensorFlow 团队有意做出的设计决策,用于显示这些警告消息。此决定的一个缺点是它会混淆初学者,并使开发人员习惯于忽略所有消息,包括那些可能影响执行的消息。
既然您已经了解了 tf.keras 是什么、如何安装 TensorFlow 以及如何确认您的开发环境正常工作,那么让我们来看一下 TensorFlow 中深度学习模型的生命周期。
2. 深度学习模型生命周期
在本节中,您将了解深度学习模型的生命周期以及您可以使用来定义模型的两个 tf.keras API。
2.1 模型生命周期的 5 个步骤
模型有一个生命周期,而这个非常简单的知识为对数据集进行建模和理解 tf.keras API 提供了基础。
生命周期中的五个步骤如下:
- 定义模型
- 编译模型
- 拟合模型
- 评估模型
- 进行预测
让我们依次仔细研究每个步骤。
定义模型
定义模型需要首先选择所需的模型类型,然后选择架构或网络拓扑。
从 API 的角度来看,这包括定义模型的层、使用节点数和激活函数配置每个层,并将这些层连接成一个连贯的模型。
模型可以通过顺序 API 或函数式 API 来定义,下一节将介绍这两种。
|
1 2 3 |
... # 定义模型 model = ... |
编译模型
编译模型需要首先选择要优化的损失函数,例如均方误差或交叉熵。
它还要求您选择一个算法来执行优化过程,通常是随机梯度下降或其现代变体,例如 Adam。它也可能要求您选择在模型训练过程中要跟踪的任何性能指标。
从 API 的角度来看,这包括调用一个函数来以选定的配置编译模型,这将准备好适当的数据结构,以有效利用您已定义的模型。
优化器可以指定为已知优化器类的字符串,例如,随机梯度下降的“sgd”,或者您可以配置优化器类的实例并使用它。
有关支持的优化器列表,请参阅此
|
1 2 3 4 |
... # 编译模型 opt = SGD(learning_rate=0.01, momentum=0.9) model.compile(optimizer=opt, loss='binary_crossentropy') |
三个最常见的损失函数是
- “binary_crossentropy”用于二元分类
- “sparse_categorical_crossentropy”用于多类分类
- “mse”(均方误差)用于回归
|
1 2 3 |
... # 编译模型 model.compile(optimizer='sgd', loss='mse') |
有关支持的损失函数列表,请参阅
指标定义为已知指标函数的字符串列表或要调用的用于评估预测的函数列表。
有关支持的指标列表,请参阅
|
1 2 3 |
... # 编译模型 model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy']) |
训练模型
训练模型需要您首先选择训练配置,例如训练轮数(遍历训练数据集的次数)和批次大小(每个训练轮中用于估计模型误差的样本数)。
训练应用选定的优化算法来最小化选定的损失函数,并使用误差反向传播算法更新模型。
训练模型是整个过程中耗时最长的部分,可能需要几秒钟到几小时甚至几天,具体取决于模型的复杂性、您使用的硬件以及训练数据集的大小。
从 API 的角度来看,这包括调用一个函数来执行训练过程。此函数将阻塞(不返回),直到训练过程完成。
|
1 2 3 |
... # 拟合模型 model.fit(X, y, epochs=100, batch_size=32) |
有关如何选择批次大小的帮助,请参阅本教程
在训练模型时,进度条将总结每个训练轮和整个训练过程的状态。可以通过将“verbose”参数设置为 2 来简化,只需报告每个训练轮的模型性能。通过将“verbose”设置为 0,可以在训练期间关闭所有输出。
|
1 2 3 |
... # 拟合模型 model.fit(X, y, epochs=100, batch_size=32, verbose=0) |
评估模型
评估模型需要您首先选择用于评估模型的预留数据集。这应该是未用于训练过程的数据,以便您可以获得模型在新数据上进行预测的无偏性能估计。
模型评估的速度与您要用于评估的数据量成正比,尽管它的速度比训练快得多,因为模型没有改变。
从 API 的角度来看,这包括使用预留数据集调用一个函数,并获得可以报告的损失和其他指标。
|
1 2 3 |
... # 评估模型 loss = model.evaluate(X, y, verbose=0) |
进行预测
进行预测是生命周期的最后一步。这也是我们最初想要模型的原因。
它要求您拥有需要进行预测的新数据,例如,您没有目标值的情况。
从 API 的角度来看,您只需调用一个函数即可预测类别标签、概率或数值,无论您设计模型来预测什么。
您可能希望保存模型,并在以后加载它以进行预测。您也可以选择在开始使用模型之前,在所有可用数据上训练模型。
现在您已经熟悉了模型生命周期,让我们来看看使用 tf.keras API 构建模型的两种主要方法:顺序和函数式。
|
1 2 3 |
... # 进行预测 yhat = model.predict(X) |
2.2 顺序模型 API (简单)
顺序模型 API 是最简单的,也是推荐的 API,尤其是在刚开始学习时。
它之所以被称为“顺序”,是因为它涉及定义一个 Sequential 类,并以线性方式逐个将层添加到模型中,从输入到输出。
下面的示例定义了一个顺序 MLP 模型,该模型接受八个输入,有一个包含 10 个节点的隐藏层,然后是一个具有一个节点以预测数值的输出层。
|
1 2 3 4 5 6 7 |
# 使用顺序 API 定义模型的示例 from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense # 定义模型 model = Sequential() model.add(Dense(10, input_shape=(8,))) model.add(Dense(1)) |
请注意,网络的可见层由第一个隐藏层上的“input_shape”参数定义。在上面的示例中,模型期望一个样本的输入是一个包含八个数字的向量。
顺序 API 易于使用,因为您可以一直调用 model.add() 直到添加完所有层。
例如,这里有一个包含五个隐藏层的深度 MLP。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 使用顺序 API 定义模型的示例 from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense # 定义模型 model = Sequential() model.add(Dense(100, input_shape=(8,))) model.add(Dense(80)) model.add(Dense(30)) model.add(Dense(10)) model.add(Dense(5)) model.add(Dense(1)) |
2.3 函数式模型 API (高级)
函数式 API 更复杂,但也更灵活。
它涉及将一个层的输出显式地连接到另一个层的输入。每个连接都需要指定。
首先,必须通过 Input 类定义一个输入层,并指定输入样本的形状。在定义模型时,我们必须保留对输入层的引用。
|
1 2 3 |
... # 定义层 x_in = Input(shape=(8,)) |
接下来,可以通过调用该层并传入输入层来将全连接层连接到输入。这将返回对此新层中输出连接的引用。
|
1 2 |
... x = Dense(10)(x_in) |
然后,我们可以以相同的方式将其连接到输出层。
|
1 2 |
... x_out = Dense(1)(x) |
连接完成后,我们定义一个 Model 对象并指定输入和输出层。完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 |
# 使用函数式 API 定义模型的示例 from tensorflow.keras import Model from tensorflow.keras import Input from tensorflow.keras.layers import Dense # 定义层 x_in = Input(shape=(8,)) x = Dense(10)(x_in) x_out = Dense(1)(x) # 定义模型 model = Model(inputs=x_in, outputs=x_out) |
因此,它允许更复杂的模型设计,例如可能具有多个输入路径(单独的向量)的模型以及具有多个输出路径(例如,一个单词和一个数字)的模型。
一旦您熟悉了函数式 API,它会很有趣。
有关函数式 API 的更多信息,请参阅
现在我们熟悉了模型生命周期和可用于定义模型的两种 API,让我们来开发一些标准模型。
3. 如何开发深度学习模型
在本节中,您将了解如何开发、评估和预测标准深度学习模型,包括多层感知机(MLP)、卷积神经网络(CNN)和循环神经网络(RNN)。
3.1 开发多层感知机模型
多层感知器模型,简称 MLP,是一种标准的完全连接神经网络模型。
它由节点层组成,其中每个节点都连接到前一层的所有输出,每个节点的输出都连接到下一层节点的所有输入。
MLP 是使用一个或多个 Dense 层创建的。此模型适用于表格数据,即数据外观如表格或电子表格,每列代表一个变量,每行代表一个样本。您可能想通过 MLP 探索三种预测建模问题:二元分类、多类分类和回归。
让我们为每种情况拟合一个真实数据集的模型。
请注意,本节中的模型是有效的,但尚未优化。看看您是否可以提高它们的性能。请在下方的评论中发布您的发现。
用于二元分类的 MLP
我们将使用 Ionosphere 二元(两类)分类数据集来演示用于二元分类的 MLP。
该数据集涉及根据雷达回波预测一个结构是否在大气层中。
数据集将使用 Pandas 自动下载,但您可以在此处了解更多关于它的信息。
我们将使用 LabelEncoder 将字符串标签编码为整数值 0 和 1。模型将使用 67% 的数据进行训练,其余 33% 将用于评估,使用 train_test_split() 函数进行分割。
使用“relu”激活和“he_normal”权重初始化是一个好习惯。这种组合在克服训练深度神经网络模型时梯度消失问题方面大有裨益。有关 ReLU 的更多信息,请参阅教程
模型预测类别 1 的概率,并使用 sigmoid 激活函数。模型使用随机梯度下降的 Adam 版本进行优化,并旨在最小化 交叉熵损失。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# 用于二元分类的 MLP from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense # 加载数据集 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/ionosphere.csv' df = read_csv(path, header=None) # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 确保所有数据都是浮点值 X = X.astype('float32') # 将字符串编码为整数 y = LabelEncoder().fit_transform(y) # 分割为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) # 确定输入特征的数量 n_features = X_train.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(8, activation='relu', kernel_initializer='he_normal')) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) # 拟合模型 model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=0) # 评估模型 loss, acc = model.evaluate(X_test, y_test, verbose=0) print('Test Accuracy: %.3f' % acc) # 进行预测 row = [1,0,0.99539,-0.05889,0.85243,0.02306,0.83398,-0.37708,1,0.03760,0.85243,-0.17755,0.59755,-0.44945,0.60536,-0.38223,0.84356,-0.38542,0.58212,-0.32192,0.56971,-0.29674,0.36946,-0.47357,0.56811,-0.51171,0.41078,-0.46168,0.21266,-0.34090,0.42267,-0.54487,0.18641,-0.45300] yhat = model.predict([row]) print('Predicted: %.3f' % yhat) |
运行示例首先报告数据集的形状,然后拟合模型并在测试数据集上对其进行评估。最后,对单行数据进行预测。
注意:您看到的结果可能会有所不同,因为算法或评估程序具有随机性,或者数值精度存在差异。可以尝试运行示例几次,然后比较平均结果。
您得到了什么结果?您能否更改模型使其表现更好?
请在下面的评论中发布您的发现。
在这种情况下,我们可以看到模型获得了大约94%的分类准确率,然后预测该行数据属于类别1的概率为0.9。
|
1 2 3 |
(235, 34) (116, 34) (235,) (116,) Test Accuracy: 0.940 Predicted: 0.991 |
MLP用于多类别分类
我们将使用鸢尾花多类别分类数据集来演示用于多类别分类的MLP。
此问题涉及根据花的测量值来预测鸢尾花的种类。
该数据集将使用 Pandas 自动下载,但您可以在此处了解更多信息。
鉴于这是一个多类别分类问题,模型必须在输出层有对应于每个类别的节点,并使用 softmax 激活函数。损失函数为 ‘sparse_categorical_crossentropy‘,这对于整数编码的类别标签(例如,一个类别为0,下一个类别为1,依此类推)是合适的。
下面列出了在鸢尾花数据集上拟合和评估MLP的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# mlp for multiclass classification from numpy import argmax from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense # 加载数据集 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv' df = read_csv(path, header=None) # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 确保所有数据都是浮点值 X = X.astype('float32') # 将字符串编码为整数 y = LabelEncoder().fit_transform(y) # 分割为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) # 确定输入特征的数量 n_features = X_train.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(8, activation='relu', kernel_initializer='he_normal')) model.add(Dense(3, activation='softmax')) # 编译模型 model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 拟合模型 model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=0) # 评估模型 loss, acc = model.evaluate(X_test, y_test, verbose=0) print('Test Accuracy: %.3f' % acc) # 进行预测 row = [5.1,3.5,1.4,0.2] yhat = model.predict([row]) print('Predicted: %s (class=%d)' % (yhat, argmax(yhat))) |
运行示例首先报告数据集的形状,然后拟合模型并在测试数据集上对其进行评估。最后,对单行数据进行预测。
注意:您看到的结果可能会有所不同,因为算法或评估程序具有随机性,或者数值精度存在差异。可以尝试运行示例几次,然后比较平均结果。
您得到了什么结果?您能否更改模型使其表现更好?
请在下面的评论中发布您的发现。
在这种情况下,我们可以看到模型获得了大约98%的分类准确率,然后预测一行数据属于每个类别的概率,尽管类别0的概率最高。
|
1 2 3 |
(100, 4) (50, 4) (100,) (50,) Test Accuracy: 0.980 Predicted: [[0.8680804 0.12356871 0.00835086]] (class=0) |
MLP用于回归
我们将使用波士顿房价回归数据集来演示用于回归预测建模的MLP。
此问题涉及根据房屋和社区的属性来预测房屋价值。
该数据集将使用 Pandas 自动下载,但您可以在此处了解更多信息。
这是一个回归问题,涉及预测单个数值。因此,输出层有一个节点,并使用默认的线性激活函数(无激活函数)。在拟合模型时,最小化均方误差(mse)损失。
请记住,这是一个回归问题,而不是分类问题;因此,我们无法计算分类准确率。有关更多信息,请参阅教程。
下面列出了在波士顿房价数据集上拟合和评估MLP的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# mlp for regression from numpy import sqrt from pandas import read_csv from sklearn.model_selection import train_test_split from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense # 加载数据集 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/housing.csv' df = read_csv(path, header=None) # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 分割为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) # 确定输入特征的数量 n_features = X_train.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(8, activation='relu', kernel_initializer='he_normal')) model.add(Dense(1)) # 编译模型 model.compile(optimizer='adam', loss='mse') # 拟合模型 model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=0) # 评估模型 error = model.evaluate(X_test, y_test, verbose=0) print('MSE: %.3f, RMSE: %.3f' % (error, sqrt(error))) # 进行预测 row = [0.00632,18.00,2.310,0,0.5380,6.5750,65.20,4.0900,1,296.0,15.30,396.90,4.98] yhat = model.predict([row]) print('Predicted: %.3f' % yhat) |
运行示例首先报告数据集的形状,然后拟合模型并在测试数据集上对其进行评估。最后,对单行数据进行预测。
注意:您看到的结果可能会有所不同,因为算法或评估程序具有随机性,或者数值精度存在差异。可以尝试运行示例几次,然后比较平均结果。
您得到了什么结果?您能否更改模型使其表现更好?
请在下面的评论中发布您的发现。
在这种情况下,我们可以看到模型获得了约60的MSE,即约7(单位为千美元)的RMSE。然后,对于单个样本,预测值为约26。
|
1 2 3 |
(339, 13) (167, 13) (339,) (167,) MSE: 60.751, RMSE: 7.794 Predicted: 26.983 |
3.2 开发卷积神经网络模型
卷积神经网络(CNN)是一种专为图像输入设计的网络。
它们由提取特征(称为特征图)的卷积层和将特征提炼为最显著元素(称为池化层)的模型组成。
CNN最适合图像分类任务,尽管它们也可用于处理需要图像作为输入的各种任务。
一个流行的图像分类任务是MNIST手写数字分类。它包含数万个手写数字,必须将它们分类为0到9之间的数字。
tf.keras API 提供了一个方便的函数来直接下载和加载此数据集。
下面的示例加载数据集并绘制前几个图像。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# example of loading and plotting the mnist dataset from tensorflow.keras.datasets.mnist import load_data from matplotlib import pyplot # 加载数据集 (trainX, trainy), (testX, testy) = load_data() # 总结已加载的数据集 print('Train: X=%s, y=%s' % (trainX.shape, trainy.shape)) print('Test: X=%s, y=%s' % (testX.shape, testy.shape)) # 绘制前几张图片 for i in range(25): # 定义子图 pyplot.subplot(5, 5, i+1) # 绘制原始像素数据 pyplot.imshow(trainX[i], cmap=pyplot.get_cmap('gray')) # 显示图 pyplot.show() |
运行示例加载MNIST数据集,然后汇总默认的训练和测试数据集。
|
1 2 |
训练集:X=(60000, 28, 28), y=(60000,) 测试集:X=(10000, 28, 28), y=(10000,) |
然后创建一个图,显示训练数据集中手写图像示例的网格。

MNIST 数据集的手写数字图
我们可以训练一个CNN模型来对MNIST数据集中的图像进行分类。
请注意,图像是灰度像素数据数组;因此,在将图像用作模型输入之前,我们必须添加一个通道维度。原因是CNN模型期望图像采用通道在后格式;也就是说,网络接收的每个示例的维度为 [行, 列, 通道],其中通道代表图像数据的颜色通道。
在训练CNN时,将像素值从默认的0-255范围缩放到0-1也是个好主意。有关缩放像素值的更多信息,请参阅教程。
下面列出了在MNIST数据集上拟合和评估CNN模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# example of a cnn for image classification from numpy import asarray from numpy import unique from numpy import argmax from tensorflow.keras.datasets.mnist import load_data from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPool2D from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Dropout # 加载数据集 (x_train, y_train), (x_test, y_test) = load_data() # reshape data to have a single channel x_train = x_train.reshape((x_train.shape[0], x_train.shape[1], x_train.shape[2], 1)) x_test = x_test.reshape((x_test.shape[0], x_test.shape[1], x_test.shape[2], 1)) # determine the shape of the input images in_shape = x_train.shape[1:] # 确定类别数量 n_classes = len(unique(y_train)) print(in_shape, n_classes) # 归一化像素值 x_train = x_train.astype('float32') / 255.0 x_test = x_test.astype('float32') / 255.0 # 定义模型 model = Sequential() model.add(Conv2D(32, (3,3), activation='relu', kernel_initializer='he_uniform', input_shape=in_shape)) model.add(MaxPool2D((2, 2))) model.add(Flatten()) model.add(Dense(100, activation='relu', kernel_initializer='he_uniform')) model.add(Dropout(0.5)) model.add(Dense(n_classes, activation='softmax')) # define loss and optimizer model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 拟合模型 model.fit(x_train, y_train, epochs=10, batch_size=128, verbose=0) # 评估模型 loss, acc = model.evaluate(x_test, y_test, verbose=0) print('Accuracy: %.3f' % acc) # 进行预测 image = x_train[0] yhat = model.predict(asarray([image])) print('Predicted: class=%d' % argmax(yhat)) |
运行示例首先报告数据集的形状,然后拟合模型并在测试数据集上对其进行评估。最后,对单个图像进行预测。
注意:您看到的结果可能会有所不同,因为算法或评估程序具有随机性,或者数值精度存在差异。可以尝试运行示例几次,然后比较平均结果。
您得到了什么结果?您能否更改模型使其表现更好?
请在下面的评论中发布您的发现。
首先,报告每个图像的形状以及类别数;我们可以看到每个图像是28x28像素,并且有10个类别,正如我们所料。
在这种情况下,我们可以看到模型在测试数据集上获得了约98%的分类准确率。然后,我们可以看到模型为训练集中的第一个图像预测了类别5。
|
1 2 3 |
(28, 28, 1) 10 准确率:0.987 Predicted: class=5 |
3.3 开发循环神经网络模型
循环神经网络(RNN)是用于处理数据序列而设计的。
它们在自然语言处理问题中被证明非常有效,因为它们将文本序列作为输入提供给模型。RNN在时间序列预测和语音识别方面也取得了一些适度的成功。
最流行的RNN类型是长短期记忆网络(LSTM)。LSTM可以用于模型中,以接受输入数据序列并进行预测,例如分配类别标签或预测序列中的数值(如下一个值或值)。
您将使用汽车销售数据集来演示用于单变量时间序列预测的LSTM RNN。
此问题涉及预测每月汽车销量。
该数据集将使用 Pandas 自动下载,但您可以在此处了解更多信息。
让我们将问题定义为使用过去五个月的数据窗口来预测当前月份的数据。
为了实现这一点,您需要定义一个名为 *split_sequence()* 的新函数,该函数将输入序列拆分为适合拟合LSTM等监督学习模型的数据窗口。
例如,如果序列是
|
1 |
1, 2, 3, 4, 5, 6, 7, 8, 9, 10 |
那么用于训练模型的样本将是
|
1 2 3 4 5 |
输入 输出 1, 2, 3, 4, 5 6 2, 3, 4, 5, 6 7 3, 4, 5, 6, 7 8 ... |
使用过去12个月的数据作为测试数据集。
LSTM期望数据中的每个样本都有两个维度;第一个是时间步的数量(在本例中为5),第二个是每个时间步的观测值数量(在本例中为1)。
由于这是一个回归型问题,我们将在线性激活函数(无激活函数)的输出层中使用它,并优化均方误差损失函数。我们还将使用平均绝对误差(MAE)指标来评估模型。
下面列出了在单变量时间序列预测问题上拟合和评估LSTM的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
# lstm for time series forecasting from numpy import sqrt from numpy import asarray from pandas import read_csv from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import LSTM # 将单变量序列分成样本 def split_sequence(sequence, n_steps): X, y = list(), list() for i in range(len(sequence)): # 找到此模式的末尾 end_ix = i + n_steps # 检查是否超出序列 if end_ix > len(sequence)-1: break # 收集模式的输入和输出部分 seq_x, seq_y = sequence[i:end_ix], sequence[end_ix] X.append(seq_x) y.append(seq_y) return asarray(X), asarray(y) # 加载数据集 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv' df = read_csv(path, header=0, index_col=0, squeeze=True) # retrieve the values values = df.values.astype('float32') # specify the window size n_steps = 5 # 分割成样本 X, y = split_sequence(values, n_steps) # 重塑为 [样本数, 时间步数, 特征数] X = X.reshape((X.shape[0], X.shape[1], 1)) # 分割成训练/测试集 n_test = 12 X_train, X_test, y_train, y_test = X[:-n_test], X[-n_test:], y[:-n_test], y[-n_test:] print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) # 定义模型 model = Sequential() model.add(LSTM(100, activation='relu', kernel_initializer='he_normal', input_shape=(n_steps,1))) model.add(Dense(50, activation='relu', kernel_initializer='he_normal')) model.add(Dense(50, activation='relu', kernel_initializer='he_normal')) model.add(Dense(1)) # 编译模型 model.compile(optimizer='adam', loss='mse', metrics=['mae']) # 拟合模型 model.fit(X_train, y_train, epochs=350, batch_size=32, verbose=2, validation_data=(X_test, y_test)) # 评估模型 mse, mae = model.evaluate(X_test, y_test, verbose=0) print('MSE: %.3f, RMSE: %.3f, MAE: %.3f' % (mse, sqrt(mse), mae)) # 进行预测 row = asarray([18024.0, 16722.0, 14385.0, 21342.0, 17180.0]).reshape((1, n_steps, 1)) yhat = model.predict(row) print('Predicted: %.3f' % (yhat)) |
运行示例首先报告数据集的形状,然后拟合模型并在测试数据集上对其进行评估。最后,对单个示例进行预测。
注意:您看到的结果可能会有所不同,因为算法或评估程序具有随机性,或者数值精度存在差异。可以尝试运行示例几次,然后比较平均结果。
您得到了什么结果?您能否更改模型使其表现更好?
请在下面的评论中发布您的发现。
首先,将显示训练集和测试集的形状,确认最后 12 个示例用于模型评估。
在这种情况下,模型实现了大约 2,800 的平均绝对误差,并预测了测试集中序列的下一个值为 13,199,而预期值为 14,577(非常接近)。
|
1 2 3 |
(91, 5, 1) (12, 5, 1) (91,) (12,) MSE: 12755421.000, RMSE: 3571.473, MAE: 2856.084 Predicted: 13199.325 |
注意:在拟合模型之前对序列进行缩放并使其平稳化是一个好习惯。我建议将其作为一项扩展,以获得更好的性能。有关准备时间序列数据进行建模的更多信息,请参阅教程
4. 如何使用高级模型功能
在本节中,您将了解如何使用一些更高级的模型功能,例如查看学习曲线和保存模型以供以后使用。
4.1 如何可视化深度学习模型
深度学习模型的架构可能很快变得庞大而复杂。
因此,清晰地了解模型中的连接和数据流非常重要。如果您使用的是函数式 API,这一点尤其重要,以确保您确实按照预期的方式连接了模型的层。
您可以使用两个工具来可视化模型:文本描述和绘图。
模型文本描述
可以通过调用模型上的 summary() 函数来显示模型的文本描述。
下面的示例定义了一个具有三个层的小型模型,然后汇总了结构。
|
1 2 3 4 5 6 7 8 9 10 |
# 汇总模型的示例 from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(8,))) model.add(Dense(8, activation='relu', kernel_initializer='he_normal')) model.add(Dense(1, activation='sigmoid')) # 总结模型 model.summary() |
运行该示例将打印每个层的摘要以及总摘要。
这是检查模型输出形状和参数数量(权重)的宝贵诊断工具。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
模型: "sequential" _________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= dense (Dense) (None, 10) 90 _________________________________________________________________ dense_1 (Dense) (None, 8) 88 _________________________________________________________________ dense_2 (Dense) (None, 1) 9 ================================================================= 总参数:187 可训练参数:187 不可训练参数: 0 _________________________________________________________________ |
模型架构图
您可以通过调用 plot_model() 函数来创建模型的图。
这将创建一个图像文件,其中包含模型中层的框线图。
下面的示例创建了一个小型三层模型,并将模型架构图保存到“model.png”,其中包括输入和输出形状。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 绘制模型的示例 from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.utils import plot_model # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(8,))) model.add(Dense(8, activation='relu', kernel_initializer='he_normal')) model.add(Dense(1, activation='sigmoid')) # 总结模型 plot_model(model, 'model.png', show_shapes=True) |
运行示例将显示模型的图,其中每个层都有一个框,其中包含形状信息以及连接层的箭头,显示数据在网络中的流向。
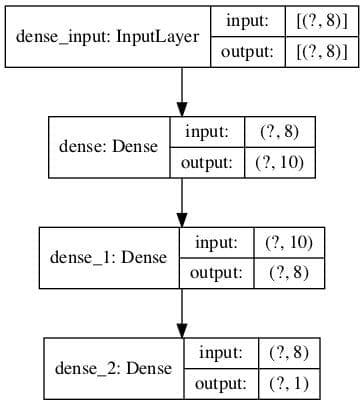
神经网络架构图
4.2 如何绘制模型学习曲线
学习曲线是神经网络模型性能随时间变化的图,例如在每个训练周期结束时计算的那些。
学习曲线图可深入了解模型的学习动态,例如模型是否学习得好、欠拟合训练数据集或过拟合训练数据集。
有关学习曲线的入门介绍以及如何使用它们来诊断模型的学习动态,请参阅教程
您可以轻松地为深度学习模型创建学习曲线。
首先,您必须更新对 fit 函数的调用,以包含对 验证数据集的引用。这是训练集中未用于拟合模型的一部分,而是用于在训练期间评估模型的性能。
您可以手动拆分数据并指定 validation_data 参数,或者您可以使用 validation_split 参数并指定训练数据集的百分比拆分,然后让 API 为您执行拆分。后者目前更简单。
fit 函数将返回一个 history 对象,其中包含在每个训练周期结束时记录的性能指标的跟踪。这包括所选的损失函数和配置的每个指标,例如准确率,以及为训练集和验证集计算的每个损失和指标。
学习曲线是训练数据集和验证数据集上损失的图。我们可以使用 Matplotlib 库从 history 对象创建此图。
下面的示例在合成二分类问题上拟合了一个小型神经网络。使用 30% 的验证拆分来评估训练期间的模型,然后使用折线图绘制训练集和验证集上的 交叉熵损失。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 绘制学习曲线的示例 from sklearn.datasets import make_classification from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.optimizers import SGD from matplotlib import pyplot # 创建数据集 X, y = make_classification(n_samples=1000, n_classes=2, random_state=1) # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 sgd = SGD(learning_rate=0.001, momentum=0.8) model.compile(optimizer=sgd, loss='binary_crossentropy') # 拟合模型 history = model.fit(X, y, epochs=100, batch_size=32, verbose=0, validation_split=0.3) # 绘制学习曲线 pyplot.title('学习曲线') pyplot.xlabel('Epoch') pyplot.ylabel('交叉熵') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='val') pyplot.legend() pyplot.show() |
运行示例将对数据集进行模型拟合。在运行结束时,将返回 history 对象,并用作创建折线图的基础。
训练集的交叉熵损失通过“loss”键访问,验证集的损失通过 history 对象 history 属性上的“val_loss”键访问。
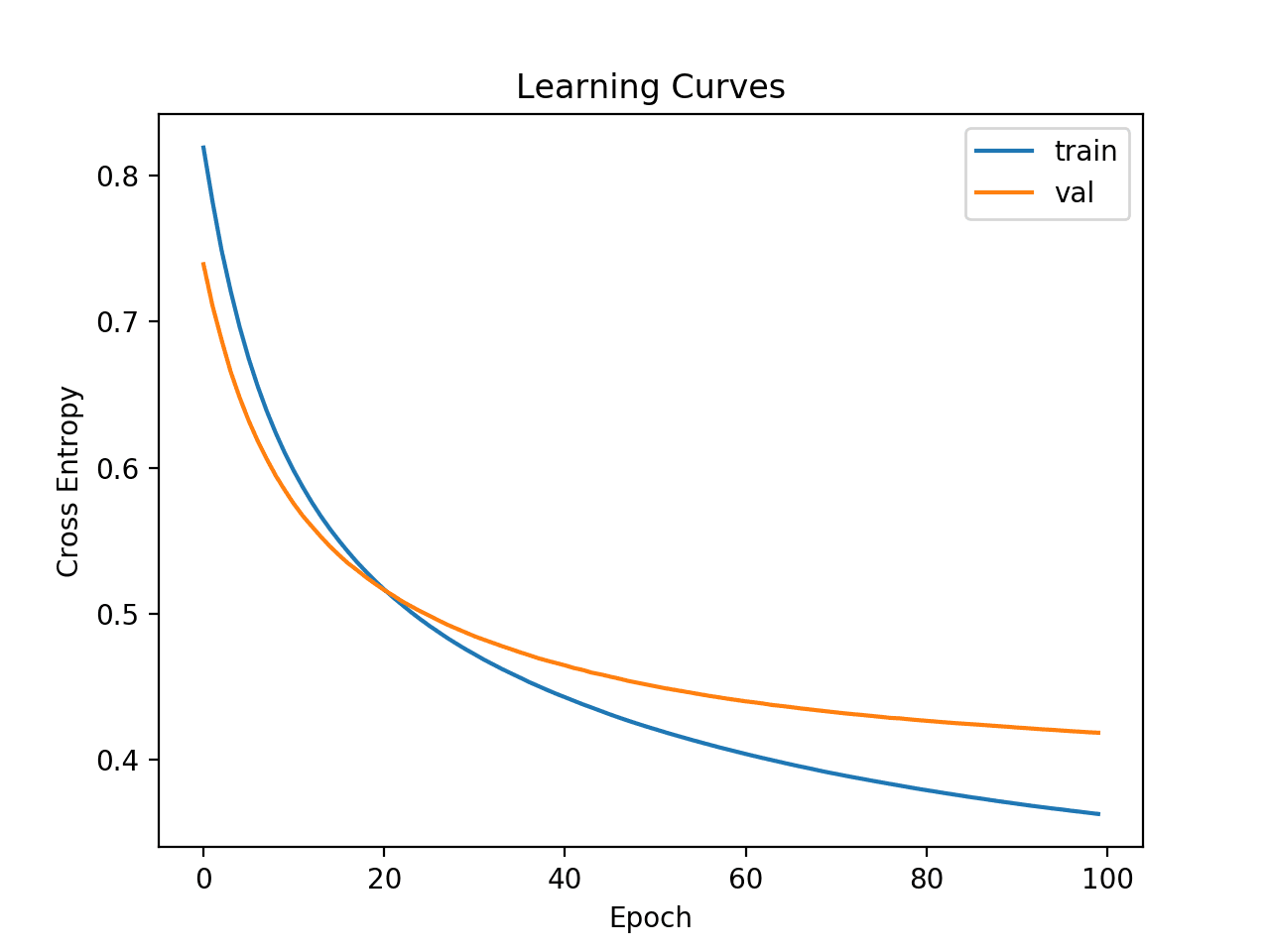
深度学习模型的交叉熵损失学习曲线
4.3 如何保存和加载您的模型
训练和评估模型很棒,但我们可能希望以后使用模型,而无需每次都重新训练。
这可以通过将模型保存到文件,以后加载它,并使用它来进行预测来实现。
这可以通过在模型上调用 save() 函数来保存模型来实现。以后可以使用 load_model() 函数加载它。
模型以 H5 格式保存,这是一种高效的数组存储格式。因此,您必须确保您的工作站上安装了 h5py 库。例如,可以使用 pip 来实现:
|
1 |
pip install h5py |
下面的示例在合成二分类问题上拟合了一个简单模型,然后保存了模型文件。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 保存已拟合模型的示例 from sklearn.datasets import make_classification from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.optimizers import SGD # 创建数据集 X, y = make_classification(n_samples=1000, n_features=4, n_classes=2, random_state=1) # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 sgd = SGD(learning_rate=0.001, momentum=0.8) model.compile(optimizer=sgd, loss='binary_crossentropy') # 拟合模型 model.fit(X, y, epochs=100, batch_size=32, verbose=0, validation_split=0.3) # 将模型保存到文件 model.save('model.h5') |
运行示例将拟合模型并将其保存到名为“model.h5”的文件中。
然后,您可以加载模型并使用它来做出预测、继续训练它,或者随心所欲地处理它。
下面的示例加载模型并使用它来做出预测。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 加载已保存模型的示例 from sklearn.datasets import make_classification from tensorflow.keras.models import load_model # 创建数据集 X, y = make_classification(n_samples=1000, n_features=4, n_classes=2, random_state=1) # 从文件加载模型 model = load_model('model.h5') # 进行预测 row = [1.91518414, 1.14995454, -1.52847073, 0.79430654] yhat = model.predict([row]) print('Predicted: %.3f' % (yhat[0])) |
运行示例将从文件中加载图像,然后使用它对新数据行进行预测并打印结果。
|
1 |
Predicted: 0.831 |
5. 如何获得更好的模型性能
在本节中,您将了解可用于提高深度学习模型性能的一些技术。
提高深度学习性能的一个重要部分是通过减慢学习过程或在正确的时间停止学习过程来避免过拟合。
5.1 如何通过 Dropout 减少过拟合
Dropout 是一种巧妙的正则化方法,可以减少训练数据集的过拟合,并使模型更加健壮。
这是在训练期间实现的,其中一些层的输出被随机忽略或“丢弃”。这会使该层看起来像—并且被视为—一个具有不同节点数量且与前一层连接不同的层。
Dropout 会使训练过程变得嘈杂,迫使层内的节点通过概率承担更多的输入责任。
有关 Dropout 如何工作的更多信息,请参阅此教程
您可以在模型中添加 Dropout 作为新层,放在您希望丢弃输入连接的层之前。
这涉及添加一个名为 Dropout() 的层,该层接受一个参数,指定前一层每个输出被丢弃的概率,例如,0.4 表示在每次模型更新时将丢弃 40% 的输入。
您可以在 MLP、CNN 和 RNN 模型中添加 Dropout 层,尽管也有专门用于 CNN 和 RNN 模型的 Dropout 版本,您也可以探索一下。
下面的示例在合成二分类问题上拟合了一个小型神经网络模型。
在第一个隐藏层和输出层之间插入了一个具有 50% Dropout 的 Dropout 层。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 使用 Dropout 的示例 from sklearn.datasets import make_classification from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Dropout from matplotlib import pyplot # 创建数据集 X, y = make_classification(n_samples=1000, n_classes=2, random_state=1) # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') # 拟合模型 model.fit(X, y, epochs=100, batch_size=32, verbose=0) |
5.2 如何通过 Batch Normalization 加速训练
输入到层的规模和分布对该层可以被训练的难易程度或速度有很大影响。
这通常是为什么在用神经网络模型对输入数据进行建模之前对其进行缩放是个好主意。
Batch normalization 是一种用于训练非常深的神经网络的技术,它对每个 mini-batch 的层输入进行标准化。这可以稳定学习过程,并大大减少训练深度网络所需的训练周期数。
有关 Batch normalization 如何工作的更多信息,请参阅此教程
您可以通过在您希望具有标准化输入的层之前添加 BatchNormalization 层来在网络中使用 Batch normalization。您可以在 MLP、CNN 和 RNN 模型中使用 Batch normalization。
这可以通过直接添加 BatchNormalization 层来实现。
下面的示例定义了一个用于二分类预测问题的小型 MLP 网络,在第一个隐藏层和输出层之间添加了一个 Batch normalization 层。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 使用 Batch Normalization 的示例 from sklearn.datasets import make_classification from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import BatchNormalization from matplotlib import pyplot # 创建数据集 X, y = make_classification(n_samples=1000, n_classes=2, random_state=1) # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(BatchNormalization()) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') # 拟合模型 model.fit(X, y, epochs=100, batch_size=32, verbose=0) |
此外,tf.keras 还有一系列其他您可能想探索的归一化层;请参阅
5.3 如何在正确的时间停止训练(提前停止)
神经网络很难训练。
训练太少,模型会欠拟合;训练太多,模型会过拟合训练数据集。这两种情况都会导致模型的效果不如它本可以达到的。
解决这个问题的一种方法是使用提前停止。这涉及监视训练数据集和验证数据集(训练集中未用于拟合模型的一部分)上的损失。一旦验证集的损失开始显示过拟合的迹象,就可以停止训练过程。
有关提前停止的更多信息,请参阅教程
您可以通过首先确保您有一个 验证数据集来使用提前停止。您可以通过 fit() 函数的 validation_data 参数手动定义验证数据集,或者您可以使用 validation_split 并指定要保留用于验证的训练数据集的比例。
然后,您可以定义一个 EarlyStopping 并指示它监视哪个性能度量,例如验证数据集上的损失“val_loss”,以及在采取行动之前观察过拟合的周期数,例如 5。
这个配置好的 EarlyStopping 回调可以通过“callbacks”参数提供给 fit() 函数,该参数接受一个回调列表。
这使您可以将周期数设置为较大的值,并确信一旦模型开始过拟合,训练就会结束。您可能还想创建一个学习曲线,以发现有关运行的学习动态以及何时停止训练的更多见解。
下面的示例在合成二分类问题上演示了一个小型神经网络,该网络使用提前停止来停止训练,一旦模型开始过拟合(大约 50 个周期后)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 使用提前停止的示例 from sklearn.datasets import make_classification from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.callbacks import EarlyStopping # 创建数据集 X, y = make_classification(n_samples=1000, n_classes=2, random_state=1) # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') # 配置提前停止 es = EarlyStopping(monitor='val_loss', patience=5) # 拟合模型 history = model.fit(X, y, epochs=200, batch_size=32, verbose=0, validation_split=0.3, callbacks=[es]) |
tf.keras API 提供了一些您可能想探索的回调,您可以在此处了解更多信息
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
- 如何通过批次大小控制神经网络训练的稳定性
- ReLU(修正线性单元)简介
- 机器学习中分类与回归的区别
- 如何为深度学习手动缩放图像像素数据
- 用于时间序列预测的 4 种常见机器学习数据转换
- 如何使用学习曲线诊断机器学习模型性能
- 深度神经网络正则化中的 Dropout 简介
- 深度神经网络 Batch Normalization 入门指南
- 避免神经网络过拟合的提前停止简介
书籍
- 深度学习, 2016.
指南
- TensorFlow 2 安装指南.
- TensorFlow Core: Keras
- Tensorflow Core: Keras 概述指南
- TensorFlow 中的 Keras 函数式 API
- 保存和加载模型
- 归一化层指南.
API
总结
在本教程中,您了解了使用 tf.keras API 在 TensorFlow 中开发深度学习模型的逐步指南。
具体来说,你学到了:
- Keras 和 tf.keras 之间的区别以及如何安装和验证 TensorFlow 是否正常工作
- tf.keras 模型生命周期 5 步以及如何使用顺序式和函数式 API
- 如何使用 tf.keras 为回归、分类和时间序列预测开发 MLP、CNN 和 RNN 模型
- 如何使用 tf.keras API 的高级功能来检查和诊断您的模型
- 如何通过减少过拟合和加速训练来提高 tf.keras 模型的性能
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
")

")
")


嗨
感谢这篇很棒的博文。
对于 MLP 回归示例,如果我将第一个隐藏层的激活函数从 'relu' 改为 'sigmoid',我总是能得到更好的结果:以下是几次尝试该更改后的结果
MSE: 1078.271, RMSE: 32.837
Predicted: 154.961
MSE: 1306.771, RMSE: 36.149
Predicted: 153.267
MSE: 2511.747, RMSE: 50.117
Predicted: 142.649
你知道为什么吗?
抱歉,我指的是反过来,也就是从 'sigmoid' 到 'relu'。
同意。
我发现了一样的事情,并相应地更新了示例。
谢谢 Markus!
不客气。
好发现,我会进一步研究并更新博文。
原因。我猜测数据在缩放之前需要进行转换。
嗨
谢谢。
您能否详细说明一下您的答案,因为我没有理解?那个模型没有任何像 CNN 示例那样的缩放。
是的,我认为如果数据在拟合模型之前进行了缩放(归一化),模型使用 sigmoid 激活会表现得更好。
relu 更健壮,对归一化输入的需要更少。
Jason,这是一个关于 TF 2.0 的很棒的教程!
关于 'Relu' 与 'Sigmoid' 输出函数的讨论,'Relu' 在 'Sigmoid' 之后使用,对于深度结构网络,如 30-100 层,存在梯度消失的问题。这里使用的特定示例实际上比人们如今在实际项目中更多使用的“深层”网络要“浅层”得多。所以,'sigmoid' 函数效果不错甚至更好也就不足为奇了。
谢谢!
是的,这提供了一个例子
https://machinelearning.org.cn/how-to-fix-vanishing-gradients-using-the-rectified-linear-activation-function/
# mlp for regression
为什么使用 y = LabelEncoder().fit_transform(y)?这并非必需,而且 yhat() 的预测值比 y(最大值为 50.0)大得多。
你说得对,看起来是个 bug!
谢谢 Todd。
已更新。
最后一个示例中的一个小 bug
from
from keras.callbacks import EarlyStopping
推广到
from tensorflow.keras.callbacks import EarlyStopping
谢谢,已修复!
在拟合模型之前设置种子是必要的吗?
不行。
解释得很清楚,非常喜欢。我请求您能否使用以下步骤写一篇博文?
1) tf.keras.layers.GRUCell()
2) tf.keras.layers.LSTMCell()
3) tf.nn.RNNCellDropoutWrapper()
4) tf.keras.layers.RNN()
很棒的建议!
太棒了。它包含有关 TensorFlow 2 的非常有用的信息。用于商业智能的深度学习模型开发的最佳指南。感谢分享!
谢谢!
很好的指南!非常感谢!
我有一个关于 MLP 二元分类问题的疑问。
在评估过程中,我将 verbose 参数更改为 2,得到了这个结果:
116/1 – 0s – loss: 0.1011 – accuracy: 0.9483
我添加了一个打印命令来显示测试损失行:
print(‘Test loss: %.3f’ % loss)
print(‘Test Accuracy: %.3f’ % acc)
我得到了这个结果:
Loss Test: 0.169
Test Accuracy: 0.948
为什么它与 evaluate 函数报告的不同?
你已经将精度截断到小数点后 3 位。
此外,epoch 结束时的损失/准确率是批次上的平均值,最好在运行结束时调用 `evaluate()` 以获得在保留数据集上模型性能的真实估计。
非常感谢您的博客,为学习者提供了大量信息。
请提供更多关于使用 RNN 进行预测的信息。
不客气!
请看这里的教程:
https://machinelearning.org.cn/start-here/#deep_learning_time_series
嗨,Jason,
在 CNN 示例中,不是应该用 MaxPool2D 吗,而不是 MaxPooling2D?
我认为你是对的。
https://tensorflowcn.cn/api_docs/python/tf/keras/layers/MaxPool2D
谢谢 Jason Brownlee!
我从开始我的机器学习/深度学习之旅以来就一直在关注您的教程,它真的帮了我很多。由于深度学习模型越来越大,需要多 GPU 支持。如果您能写一篇关于 tf.keras 的多 GPU 教程,最好是像 CycleGAN 或 MUNIT 这样的 GAN 模型,那就太好了。谢谢。
感谢您的建议!
嗨 Israr 和 Jason,是的,我赞同,关于使用 Keras 的多 GPU 教程会很棒。尽管如此,我还是读到了一些关于多 GPU 在许多 TensorFlow 后端版本中无法正常工作的问题。谢谢,Mark
谢谢。
又一篇很棒的文章,谢谢!
在函数式模型 API 部分,您提到这允许有多个输入路径。我的问题与此有关。我的 MLP 模型的输出将被重塑并与图像(网络中途的另一个数据输入)进行 2D 卷积。如何将此结果保留在整个模型中以供进一步处理?(model.add(intermediate_result)?)
谢谢。
是的,您可以为每个需要的元素设置一个输出,例如,每个产生您想要的输出的层都将是一个“输出”层。
看这里
https://machinelearning.org.cn/keras-functional-api-deep-learning/
没关系,我自己弄明白了,函数式 API 确实让它变得容易!
干得好!
这篇博客写得太好了,让我百感交集!
我现在每月捐款。我建议大家回馈这个很棒的博客,以保持它的运行!
感谢 Jason 的这项精彩倡议,您简直在创造就业!
谢谢!!!
嗨
对于 Dense 层的 `input_shape` 参数,似乎可以传递列表而不是元组。
model.add(Dense(10, input_shape=[8]))
而不是
model.add(Dense(10, input_shape=(8,)))
我的问题是
这是否相同?
为什么两者都有效?
可能对于任何具有 `input_shape` 参数的层类型(我还没有测试过)都可能如此。
谢谢
我认为我找到了答案,但如果我错了,请纠正我。它发生在
https://github.com/keras-team/keras/blob/master/keras/engine/base_layer.py#L163
所以,无论你传递的是列表还是元组对象,
tuple(kwargs[‘input_shape’])
的返回值将始终与元组对象相同,因为:
>>> tuple((2,))
(2,)
>>> tuple([2])
(2,)
我这样做对吗?
谢谢。
相同。
嗨 Jason
谢谢你的回复。
您是什么意思?抱歉,我的英语不太好。
等价的。它们做同样的事情。
嗨,Jason,
在 Ionosphere 数据代码块的第 32 行,应该是
yhat = model.predict(([row],)) 而不是 yhat = model.predict([row])?
只是为了匹配 `input_shape`,它要求是一个单元素的元组?
模型需要 2D 输入:行、列或样本、特征。
嗨 Jason
很棒的教程!它很好地总结了各种 MLP、CNN 和 RNN 模型(包括通过几行代码处理的数据集案例)。恭喜!
1.) 这是我的结果,目前我只研究了 Ionosphere 和 Iris 数据案例(我将继续研究其他的),但我先分享前两个。
1.1) 在第一个 Ionosphere 研究案例(MLP 模型用于二元分类)中,我应用了一些与您的代码互补的差异,例如:
80% 训练数据,10% 验证数据(我已包含在 `model.fit` 数据中)和 10% 测试数据(未用于准确率评估)。此外,我为每个密集层添加了 `batchnormalization` 和 `dropout` (0.5) 层(用于正则化目的),并为 2 个隐藏层分别使用了 34 个单元和 8 个单元。
我获得了 97.2%(比您的 94.% 准确率稍好)的未见测试准确率,以及 97.3% 的良好类别(对于给出的示例)。
1.2) 在第二个 Iris 研究案例(MLP 多分类)中,我应用了一些与您的代码互补的差异,例如:
80% 训练数据,10% 验证数据(我已包含在 `model.fit` 数据中)和 10% 测试数据(未用于准确率评估)。此外,我为每个密集层添加了 `batchnormalization` 和 `dropout` (0.5) 层(用于正则化目的),并为现在 3 个隐藏层分别使用了 64 个单元、32 个单元和 8 个单元。
我获得了 100.%(比您的 98.% 准确率稍好)的未见测试准确率,以及 99.9% 的 Iris-setosa 类别(对于给出的示例)。
2.) 这是我的持续疑问,如果您能帮助我。
2.1) 如果应用 tf.keras 的新封装器在 tf. 2.x 版本上,是否只会影响库的导入方式,例如将此 Keras 示例替换为
from keras.utils import plot_model
使用 tf.keras 封装器的新示例
from tensorflow.keras.utils import plot_model
是否强烈建议直接应用 `tf.keras`,因为 Google/TensorFlow 团队提供更好的维护保障?您同意吗?
2.2) 您是否期望使用 `tf.keras` 与 `keras` 之间存在任何效率提升(例如在执行时间方面)?我应用了,但没有看到任何变化。您同意吗?
2.3) 我看到您在多分类(例如 Iris 研究案例)中已将 `loss` 参数从您以前教程中的 `categorical_crossentropy` 更改为新的 `sparse_categorical_crossentropy`。我认为第二个更好。您同意吗?
非常感谢您为我们制作这些精彩的教程!
我将继续进行本教程中的其余研究案例!
致敬
JG
做得很好,但测试/验证集非常小。我猜我们应该使用重复的 10 折交叉验证。
是的,我们应该尽快切换到 `tf.keras`。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-keras-and-tf-keras
不确定效率差异。没有。
它们做同样的事情,我使用了稀疏损失,这样我就不必进行独热编码。
感谢您宝贵的建议!
我沉迷于您的教程!
谢谢!
嗨,Jason,
我花了一些时间为 MNIST 数字多分类实现了不同的模型。
我在这里分享我的主要评论:
我将 10,000 个测试图像分为 5,000 个用于验证(除了训练图像)和另外 5,000 个用于测试(未用于 `model.evaluate()` 的图像),所以我认为这更客观。
1.) 复制您相同的模型架构,我获得了 98.3% 的准确率,如果我将第一个 `Conv2D` 层的 32 个滤波器替换为“784”个滤波器,我获得了 98.2% 的准确率,但 2 分钟的 CPU 时间增加到 45 分钟。
2.) 我定义了一个新的模型,包含“4 个块”,具有递增的滤波器数量 [16,32,64,128] 的 `conv2D` 加上 `batchnormalization`+`MaxPoool2D`+`Dropout` 层作为正则化器。但我得到了一个较差的结果(97.2%,如果我将批次大小从 128 替换为 32,则为 97.4%)。
3.) 我对您的模型应用了“数据增强”(由于 28×28 分辨率差,具有软图像失真),但我分别获得了 96.7%、97.3% 和 97.9% 的 `width_shift_range` 和相似的 `height_shift_range` 参数值 0.1、0.05 和 0.01。
3.1) 但也通过“重新训练”(从 10 个 epoch 到 20 个 epoch 甚至 40 个 epoch)我获得了 98.2% 的准确率,非常接近您的模型。
我注意到 `tensorflow.keras…` 即使使用 `ImageDataGenerator` 也应用了 `model.fit()` 的唯一方法。所以 `keras` 的 `model.fit_genetator()` 用于图像迭代器将要被弃用!
4.) 我应用了“迁移学习”,使用了 VGG16。
但首先我必须将每个 28×28 像素的图像扩展到 32×32(VGG16 的要求),用零填充图像的其余行和列。我还从 1 通道黑/白扩展到 3 通道(VGG16 的要求),将相同的图像堆叠 3 次(`np.stack()` 用于新轴),并且,
4.1) 在冻结整个 VGG16(5 个块)并仅使用头部密集层作为可训练时,我获得了 95.2% 的准确率,结果不佳。
4.2) 我重新训练了更多的 epoch + 10 + 10 等。我获得了中等的准确率结果,如 96.2% 和 96.7%。
4.3) 我决定“解冻”(使其可训练)VGG16 的最后一个块(第 5 个块),并且对于 10 个 epoch 我获得了 97.2%,但 CPU 时间从 2 分钟增加到 45 分钟,并且可训练权重也从 52 K 增加到 7.1 M。
4.3) 我决定也“解冻”倒数第二个块(第 4 个块)(因此第 4 和第 5 个块是可训练的),并且 CPU 时间从 45 分钟增加到 85 分钟,可训练参数从 7.1 M 增加到 13. M。但准确率达到了 98.4%。
4.4) 最后,我“重新训练”了 VGG16(解冻第 4 和第 5 个块),又训练了 20 个 epoch,又训练了 20 个 epoch,我获得了 99.4% 和 99.4%,还将‘Adam’优化器替换为更柔和的“SGD”进行微调。
代价是 CPU 时间从 45 分钟增加到 85 分钟。
我的结论是:
a) 您的简单模型非常高效且鲁棒(无需实现任何复杂性,如 `data_augmentation`)。
b) 我可以超越您的结果,获得最佳的 99.4%,代价是实现 VGG16 迁移学习,以及解冻 VGG16 的第 4 和第 5 个块。代价是更高的复杂性和更长的 CPU 时间。
c) 这些模型对从最初的 10 个 epoch 到 40 个 epoch 的重新训练很敏感,在此之后系统不再学习。
此致,
JG
非常酷的实验,学到了很多!
感谢分享您的发现。
您展示了如何预测一个数据实例,但如何对所有测试数据集执行相同的操作?而不是传递 `yhat = model.predict([row])`,我们应该怎么做才能从测试数据集中获取所有预测?
将所有行传入 `predict()` 函数以对它们进行预测。
如果需要,这会有帮助:
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
嗨 Jason,非常感谢您提供有用的主题。
我有一个问题需要您的帮助。
根据 keras.io 的建议和您的主题,我转向使用“tf.keras”而不是“keras”来构建我的深度神经网络模型。我正在尝试为我的模型定义一个自定义损失函数。
首先,我查看了“tf.keras”和“keras”如何定义(通过代码)它们的损失函数,以便我可以遵循我的自定义损失函数。我以 `MeanSquaredError()` 为例进行观察,发现它们的结果似乎不完全相同。特别是:
我的第一个案例 ===========================================================
”
import numpy as np
import tensorflow as tf
y_t = np.array([[1, 2, 3, 4], [8, 9, 1, 5], [7, 8, 7, 13]])
y_p = np.array([[4, 5, 23, 14], [18, 91, 7, 10], [3, 6, 5, 7]])
mse = tf.keras.losses.MeanSquaredError()
loss1 = mse(y_t, y_p)
print(‘—‘)
print(‘tf.keras.losses:’, loss1)
”
结果是
— tf.keras.losses: tf.Tensor(621, shape=(), dtype=int32) —
我的第二个案例 =========================================================
”
import numpy as np
import keras
y_t = np.array([[1, 2, 3, 4],[8, 9, 1, 5],[7, 8, 7, 13]])
y_p = np.array([[4, 5, 23, 14],[18, 91, 7, 10],[3, 6, 5, 7]])
mse2 = keras.losses.MeanSquaredError()
loss2 = mse2(y_t, y_p)
print(‘—‘)
print(‘keras.losses:’, loss2)
”
结果是
— keras.losses: tf.Tensor(621.9167, shape=(), dtype=float32) —
======================================================================
前者给出“dtype=int32”,后者给出“dtype=float32”,尽管它们使用了相同的数据输入。
那么,有什么解释可以说明这种差异吗?
我认为,当模型训练时,损失值不太可能是整数,那么如果我使用“tf.keras.losses.MeanSquaredError()”作为我的模型,这有问题吗?
最后,如果模型是通过 `tf.keras.Sequential()` 构建的,使用 `keras.losses` 中的一些损失函数来 `model.compile()` 是否有问题?
我通常建议暂时坚持使用独立的 Keras。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-keras-and-tf-keras
抱歉,我无法帮助您调试转换。
谢谢您的回复 Jason!
我花了好几天时间尝试实现这个,但都没有成功。
我收到了错误:ERROR
root:Internal Python error in the inspect module.
以下是此内部错误的堆栈跟踪。
回溯(最近一次调用)
File “C:\ProgramData\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py”, line 3331, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File “”, line 1, in
model = tf.keras.Sequential()
AttributeError: module ‘tensorflow’ has no attribute ‘keras’
搞定了。
(235, 34) (116, 34) (235,) (116,)
WARNING:tensorflow:From D:\Anaconda3\lib\site-packages\tensorflow\python\ops\resource_variable_ops.py:435: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating
Colocations handled automatically by placer.
WARNING:tensorflow:From D:\Anaconda3\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating
Use tf.cast instead.
Test Accuracy: 0.914
回溯(最近一次调用)
File “D:\tflowdata\untitled3.py”, line 44, in
yhat = model.predict([row])
File “D:\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\training.py”, line 1096, in predict
x, check_steps=True, steps_name=’steps’, steps=steps)
干得好!
我认为您需要将 TensorFlow 的版本升级到 2.0 或更高版本。
我复制代码并得到了这个错误:
我怎么会出错?
import tensorflow
print(tensorflow.__version__)# 顺序 API 定义的模型示例
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
# 定义模型
model = Sequential()
model.add(Dense(100, input_shape=(8,0)))
model.add(Dense(80))
model.add(Dense(30))
model.add(Dense(10))
model.add(Dense(5))
model.add(Dense(1))
2.1.0
—————————————————————————
InternalError Traceback (most recent call last)
in
6 # 定义模型
7 model = Sequential()
—-> 8 model.add(Dense(100, input_shape=(8,0)))
9 model.add(Dense(80))
10 model.add(Dense(30))
~\Anaconda3\lib\site-packages\tensorflow_core\python\training\tracking\base.py in _method_wrapper(self, *args, **kwargs)
455 self._self_setattr_tracking = False # pylint: disable=protected-access
456 try
–> 457 result = method(self, *args, **kwargs)
458 finally
459 self._self_setattr_tracking = previous_value # pylint: disable=protected-access
~\Anaconda3\lib\site-packages\tensorflow_core\python\keras\engine\sequential.py in add(self, layer)
183 # 并创建将当前层连接到
184 # 我们刚刚创建的输入层的节点。
–> 185 layer(x)
186 set_inputs = True
187
~\Anaconda3\lib\site-packages\tensorflow_core\python\keras\engine\base_layer.py in __call__(self, inputs, *args, **kwargs)
746 # 如果适用,构建层(如果 `build` 方法已被
747 # 重写)。
–> 748 self._maybe_build(inputs)
749 cast_inputs = self._maybe_cast_inputs(inputs)
750
~\Anaconda3\lib\site-packages\tensorflow_core\python\keras\engine\base_layer.py in _maybe_build(self, inputs)
2114 # 操作。
2115 with tf_utils.maybe_init_scope(self)
-> 2116 self.build(input_shapes)
2117 # 我们必须设置 `self.built`,因为用户定义的 `build` 函数不受
2118 # 约束来设置 `self.built`。
您有自定义代码,这可能会有帮助。
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
我找到了问题。
我以前成功地使用了 TensorFlow-GPU 1 和 Keras。
当我升级到 2 时,相同的代码失败了。
这是因为我的 NVIDIA CUDA 驱动程序需要更新才能支持 TF 2。
抱歉提问,但这可能对其他人有帮助。
干得好,解决了你的问题!
要从模型进行预测,我需要像这样设置测试观察行:
row = [[0.00632],[18.00],[2.310],[0],[0.5380],[6.5750],[65.20],[4.0900],[1],[296.0],[15.30],[396.90],[4.98]]
yhat = model.predict(np.array(row).T)
这不像本篇文章那样工作:
row = [0.00632,18.00,2.310,0,0.5380,6.5750,65.20,4.0900,1,296.0,15.30,396.90,4.98]
yhat = model.predict([row])
为什么?
你确定吗?也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我猜是 TensorFlow 版本导致了这个问题。其他代码工作正常(除了预测)。
很棒。
出色的博客。它涵盖了 TF 中的所有内容。再次感谢您的精彩博客。
谢谢!
在批标准化部分,您创建了一个密集层,用 relu 激活它,然后执行批标准化。
因此,层 -> 激活 -> 批标准化
在像resnet50这样的模型中,顺序是这样的:
层 -> 批归一化 -> 激活(relu)
这两种方式是否一样,或者顺序很重要?如果重要,重要程度如何?
您能否回答这些问题……
很好的问题!
顺序可能很重要。一些模型倾向于先批归一化再ReLU。可以尝试实验,找出最适合您的模型和数据集的方法。
你好 Jason,在你关于波士顿房价预测的回归示例中,MSE 大约是 60。预测的均方误差值很大,这正常吗?抱歉打扰。
好问题,请看这个
https://machinelearning.org.cn/faq/single-faq/how-to-know-if-a-model-has-good-performance
在使用 MNIST CNN 模型时,我得到了一个很好的“拟合”数据。当我运行时
# 进行预测
image = x_train[0]
yhat = model.predict([[image]])
print(‘Predicted: class=%d’ % argmax(yhat))
在模型末尾,“yhat = model.predict([[image]])” 我得到了一个 ValueError
ValueError 回溯 (最近一次调用)
in
41 #yhat = model.predict([[image]]) 所有这些都产生了错误
42 #yhat = model.predict([image])
—> 43 yhat = model.predict(image)
44 print(‘Predicted: class={0}’.format(argmax(yhat)))
45 #应该得到输出
~\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\training.py in _method_wrapper(self, *args, **kwargs)
86 raise ValueError(‘{} is not supported in multi-worker mode.’.format(
87 method.__name__))
—> 88 return method(self, *args, **kwargs)
89
90 return tf_decorator.make_decorator(
~\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\training.py in predict(self, x, batch_size, verbose, steps, callbacks, max_queue_size, workers, use_multiprocessing)
1266 for step in data_handler.steps()
1267 callbacks.on_predict_batch_begin(step)
-> 1268 tmp_batch_outputs = predict_function(iterator)
1269 # Catch OutOfRangeError for Datasets of unknown size.
1270 # This blocks until the batch has finished executing.
~\Anaconda3\lib\site-packages\tensorflow\python\eager\def_function.py in __call__(self, *args, **kwds)
578 xla_context.Exit()
579 else
–> 580 result = self._call(*args, **kwds)
581
582 if tracing_count == self._get_tracing_count()
~\Anaconda3\lib\site-packages\tensorflow\python\eager\def_function.py in _call(self, *args, **kwds)
625 # This is the first call of __call__, so we have to initialize.
626 initializers = []
–> 627 self._initialize(args, kwds, add_initializers_to=initializers)
628 finally
629 # At this point we know that the initialization is complete (or less
~\Anaconda3\lib\site-packages\tensorflow\python\eager\def_function.py in _initialize(self, args, kwds, add_initializers_to)
504 self._concrete_stateful_fn = (
505 self._stateful_fn._get_concrete_function_internal_garbage_collected( # pylint: disable=protected-access
–> 506 *args, **kwds))
507
508 def invalid_creator_scope(*unused_args, **unused_kwds)
~\Anaconda3\lib\site-packages\tensorflow\python\eager\function.py in _get_concrete_function_internal_garbage_collected(self, *args, **kwargs)
2444 args, kwargs = None, None
2445 with self._lock
-> 2446 graph_function, _, _ = self._maybe_define_function(args, kwargs)
2447 return graph_function
2448
~\Anaconda3\lib\site-packages\tensorflow\python\eager\function.py in _maybe_define_function(self, args, kwargs)
2775
2776 self._function_cache.missed.add(call_context_key)
-> 2777 graph_function = self._create_graph_function(args, kwargs)
2778 self._function_cache.primary[cache_key] = graph_function
2779 return graph_function, args, kwargs
~\Anaconda3\lib\site-packages\tensorflow\python\eager\function.py in _create_graph_function(self, args, kwargs, override_flat_arg_shapes)
2665 arg_names=arg_names,
2666 override_flat_arg_shapes=override_flat_arg_shapes,
-> 2667 capture_by_value=self._capture_by_value),
2668 self._function_attributes,
2669 # Tell the ConcreteFunction to clean up its graph once it goes out of
~\Anaconda3\lib\site-packages\tensorflow\python\framework\func_graph.py in func_graph_from_py_func(name, python_func, args, kwargs, signature, func_graph, autograph, autograph_options, add_control_dependencies, arg_names, op_return_value, collections, capture_by_value, override_flat_arg_shapes)
979 _, original_func = tf_decorator.unwrap(python_func)
980
–> 981 func_outputs = python_func(*func_args, **func_kwargs)
982
983 # invariant:
func_outputscontains only Tensors, CompositeTensors,~\Anaconda3\lib\site-packages\tensorflow\python\eager\def_function.py in wrapped_fn(*args, **kwds)
439 # __wrapped__ allows AutoGraph to swap in a converted function. We give
440 # the function a weak reference to itself to avoid a reference cycle.
–> 441 return weak_wrapped_fn().__wrapped__(*args, **kwds)
442 weak_wrapped_fn = weakref.ref(wrapped_fn)
443
~\Anaconda3\lib\site-packages\tensorflow\python\framework\func_graph.py in wrapper(*args, **kwargs)
966 except Exception as e: # pylint:disable=broad-except
967 if hasattr(e, “ag_error_metadata”)
–> 968 raise e.ag_error_metadata.to_exception(e)
969 else
970 raise
ValueError:在用户代码中
C:\Users\James\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\training.py:1147 predict_function *
… 更多…
听到这个消息很抱歉,这可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
现在我更改了用于“预测”的程序末尾,并且成功了。
很高兴听到这个消息。
另外,当我获取 x_test[0] 的类别时,它是“7”,当我打印 y_test[0] 时也是“7”。我建议检查您的代码。
我看到你在预测步骤中使用了 x_train[0]。我得到类别 = 5,y_train = 5,就像你一样。
这没有帮助。代码是从网站上复制的。除了 model.predict 步骤之外,代码都可以正常工作。
我是您教程的忠实粉丝……我从您的教程中学到了很多……请接受我对您的感激,并真心感谢您以最好的方式分享知识……。
一个更新
“开发卷积神经网络模型”的代码有一个小错误,与模型输入维度与预测输入维度不匹配有关,在第 41 行
yhat = model.predict([[image]])
正确的行应该是
—————————–
from numpy import array
yhat = model.predict(array([image]))
我已经运行了代码,现在发布此更新。
附注:我可能是错的……如果是这样,请纠正我
谢谢,已修复!
我为我的研究工作做了这个实验……我收到了以下错误,有谁能帮忙吗?
values = dataframe.values.astype(‘float32′)
# specify the window size
n_steps = 3
# 分割成样本
X, Y = split_sequence(values, n_steps)
# 重塑为 [样本数, 时间步数, 特征数]
X = X.reshape((46017, 3, 4))
n_test = 36804
X_train, Y_train, X_test, Y_test = X[:-n_test], X[:-n_test], Y[-n_test:], Y[-n_test:]
print(X_train.shape, Y_train.shape, X_test.shape, Y_test.shape)
# 定义模型
model = Sequential()
model.add(LSTM(100, activation=’relu’, kernel_initializer=’he_normal’, input_shape=(n_steps,1)))
model.add(Dense(50, activation=’relu’, kernel_initializer=’he_normal’))
model.add(Dense(50, activation=’relu’, kernel_initializer=’he_normal’))
model.add(Dense(1))
# 编译模型
model.compile(optimizer=’Adamax’, loss=’mse’, metrics=[‘mae’])
model.fit(X_train, Y_train, epochs=3, batch_size=32, verbose=1, validation_data=(X_test, Y_test))
ValueError: Input 0 is incompatible with layer sequential_5: expected shape=(None, None, 1), found shape=[None, 3, 4]
抱歉,您需要调试自己的自定义代码,或者可以尝试将代码发布到 stackoverflow 上。
嗨,Jason,
感谢您的贡献。
我有一个菜鸟问题
当 model.fit() 完成时,深度模型是否具有在训练期间找到的最佳模型的权重?
或者我应该使用 ModelCheckpoint 回调,将 save_best_only=True,并在 .fit() 之后加载“最佳”权重,然后 .evaluate(X_test, y_test) 来获取一些指标?
先谢谢您了。
Maria。
fit 结束时的模型将具有运行结束时的权重。
您需要在调用模型之前从检查点加载模型。
非常感谢,我一直在为数字回归的神经网络输入层而苦苦挣扎,离子层神经网络帮助很大:)
很高兴听到这个消息。
嘿,非常感谢您创建这样的教程,我真的很需要它,并且找到了它。我从您的教程中学到了很多,您能用 ML 和 Django 创建一个 Web 应用吗?我需要它。
不客气。
抱歉,我对 Django 一无所知。
嗨 Jason。感谢您的分享!我有一个问题,在卷积神经网络模型中,您为什么使用训练图像 (x_train[0]) 进行预测,难道不应该使用未见过的图像吗?
不客气。
好问题。我使用了一个可用的图像作为示例。您可以预测任何您喜欢的图像。
只想说您的教程是最棒的。非常有帮助。感谢您提供这些。
谢谢!
嗨,
那么现在使用 tensorflow 2,model = Sequential() 和 model = tf.keras.models.Sequential 被认为是相同的吗?
谢谢你
是的。
嗨 Jason。我正在做 MLP 进行二分类,并且在我的代码中遇到了这个
model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=1)
ValueError: Data cardinality is ambiguous
x 的大小:234
y 的大小:116
请提供具有相同第一个维度的数据。
为什么会出现这个错误?如何修复?
提前感谢!
我找到了我犯的错误。
我写了
X_train, y_train,X_test, y_test = train_test_split(X, y, test_size=0.33) 而不是 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
很棒的教程!我刚开始学习 DL,而且我只参考您的内容,因为它非常清晰!再次感谢。
抱歉,我没有见过这个错误。也许可以尝试将您的代码和错误发布到 stackoverflow.com
嗨 Jason。我不明白这一行
#CNN
x_train = x_train.reshape((x_train.shape[0], x_train.shape[1], x_train.shape[2], 1))
您能解释一下这是做什么的吗?谢谢
是的,它将数据重塑为 3D 形状。
您可以在此处了解更多关于重塑数组的信息
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
您可以在这里了解更多关于此要求的信息
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
感谢这篇精彩的教程!
谢谢!
感谢这篇优秀的教程。
在“MLP for Binary Classification”部分,代码有这一行
model.compile(optimizer=’adam’, loss=’binary_crossentropy’, metrics=[‘accuracy’])
为什么使用“accuracy”作为指标?根据这份文档,对于二分类模型,使用“binary_accuracy”似乎更合适
https://tensorflowcn.cn/api_docs/python/tf/keras/metrics/BinaryAccuracy
我在 metrics=['accuracy'] 和 metrics=['binary_accuracy'] 之间来回切换,似乎在结果质量方面没有区别,所以我不太确定两者的预期区别是什么。
它们做同样的事情。
运行以下测试代码显示了 Accuracy 和 BinaryAccuracy 指标之间的行为差异。
#####
import tensorflow as tf
y_true = [[1], [1], [0], [0]]
y_pred = [[0.89], [1.0], [0.31], [0.57]]
model = tf.keras.metrics.Accuracy()
model.update_state(y_true, y_pred)
print(“Accuracy: “, model.result().numpy())
model = tf.keras.metrics.BinaryAccuracy()
model.update_state(y_true, y_pred)
print(“Binary Accuracy: “, model.result().numpy())
#####
运行此代码将产生以下结果。
Accuracy: 0.25
Binary Accuracy: 0.75
我不明白为什么这种行为差异没有体现在本教程的二分类模型中。看起来切换模型的指标从“accuracy”到“binary_accuracy”应该会产生巨大差异,正如上面的测试代码所示,但实际上它没有明显差异。我肯定有些根本性的误解。
我不确定,我建议您查看 API 文档。
我误解的根源似乎是我认为以下两项等效。
metrics=[‘accuracy’]
metrics=[tf.keras.metrics.Accuracy()]
但它们并不等效;它们产生截然不同的结果。
但是,以下所有三项似乎都等效。
metrics=[‘accuracy’]
metrics=[‘binary_accuracy’]
metrics=[tf.keras.metrics.BinaryAccuracy()]
再次感谢您网站上的精彩教程。
干得好,感谢分享!
嗨 Jason,非常感谢这个很棒的教程!
我有一个关于 CNN 示例中 Dropout 正则化的问题(关于数字)。我已经尝试了相同的模型,但我将 Dropout 替换为 L2 正则化,但准确率约为 0.981,略低于 Dropout 的准确率 (0.987)。所以我想知道是否有办法知道哪种正则化技术可能最适合我们的训练集。
是的,您必须尝试一系列方法,并找出最适合您的数据集和模型的方法。
这正是我想要的。出色的教程,谢谢。
谢谢,很高兴听到这个!
嗨 Jason,感谢您的教程
我有一些菜鸟问题
在代码中,权重的初始化在哪里?
我们可以不使用 Keras 而使用 TensorFlow 构建模型吗?
是的,您可以在不使用 Keras 的情况下开发模型。
抱歉,但我没有理解权重的初始化在哪里??在上面的模型中,或者任何深度学习模型中??
在一些代码中,权重是随机初始化的!!但我没看到任何关于权重的说明!
“kernel_initializer”参数用于在层上设置权重初始化方法。
好的,如果您不指定“kernel_initializer”,初始化会是什么?我看到有些代码是这样的
默认情况下,我认为它使用 Xavier 方法。您可以查看 API 文档以确保。
有人告诉我,如果我们不指定权重初始化,它将使用学习率的值作为模型所有权重的初始化值,然后通过训练进行更新?
这取决于层。例如,Dense 层将使用 glorot_uniform,如其文档所示:https://tensorflowcn.cn/api_docs/python/tf/keras/layers/Dense
亲爱的 Jason,
x_train = x_train.reshape((x_train.shape[0], x_train.shape[1], x_train.shape[2], 1))
当我们把数据重塑成行、列、通道的形式时。为什么最后一行是1?它是用来展平每个图像的吗?
谢谢你
这是模型以通道列表格式所期望的形状,请参阅此
https://machinelearning.org.cn/a-gentle-introduction-to-channels-first-and-channels-last-image-formats-for-deep-learning/
很棒的教程!
如何将 log loss 指标添加到 mlp_multiclass_classification?这不起作用:model.compile(optimizer=’adam’, loss=’sparse_categorical_crossentropy’, metrics=[‘log_loss’])
如何将 r2 指标添加到 mlp_regression?这不起作用:model.compile(optimizer=’adam’, loss=’mse’, metrics=[tfa.metrics.r_square.RSquare()])
您不应该称之为 log loss,它被命名为“binary_crossentropy”。
另外,对于 R^2,请参阅此处的实现:https://stackoverflow.com/questions/45250100/kerasregressor-coefficient-of-determination-r2-score
使用手动编写的 r2_square,我得到了这类错误:“NotImplementedError: Cannot convert a symbolic Tensor (ExpandDims:0) to a numpy array. This error may indicate that you’re trying to pass a Tensor to a NumPy call, which is not supported”?!…
使用 sklearn.metrics.r2_square,我得到“OperatorNotAllowedInGraphError: using a
tf.Tensoras a Pythonboolis not allowed: AutoGraph did convert this function. This might indicate you are trying to use an unsupported feature。”奇怪的是 TensorFlow 没有 r2 指标?!…
但是使用 Keras 模块(https://stackoverflow.com/questions/45250100/kerasregressor-coefficient-of-determination-r2-score),它奏效了?!…
是的,我已验证。除了我会在函数内删除 import 语句。TensorFlow 的 Keras 并不总是有所有指标函数,特别是对于那些可能误导小型批次的函数(例如 R^2 和 F1)。
我在干净安装的机器上尝试了前 3 个代码示例,每个示例都产生一个类似于“ValueError: Error when checking input: expected dense_input to have shape (13,) but got array with shape (1,)”的错误(这来自第 3 个示例)。我错过了什么?
嗨 Shawn……请确保您使用的是“完整示例”中提供的完整代码列表。
你好,
感谢这篇文章,它很好地概述了深度学习和 TensorFlow 2!
您能否解释一下可训练参数和不可训练参数的区别?
祝您有美好的一天 :)
嗨 Jason,感谢您的教程。我注意到您在进行训练/测试分割之前使用了 LabelEncoder(),但这通常被视为数据泄露。我的理解是正确的吗?
你好 Daniel…以下资源可能对您感兴趣
https://machinelearning.org.cn/data-preparation-without-data-leakage/
2.9.1
MLP分类拯救了我于论文写作的疯狂之中。非常感谢您,愿您的灵魂得到祝福!
感谢 Gabriel 的支持和反馈!祝您在机器学习的旅程中一切顺利!
哇,这是一份非常详尽的学习指南,Jason。作为一个刚接触 TensorFlow 和深度学习的新手,我很庆幸能偶然发现这个教程!我很高兴您还强调了 Keras 和 tf.keras 之间的区别;这帮我理清了一些之前让我感到困惑的地方。
我特别觉得安装 TensorFlow 和 tf.keras 的分步方法很有用。现在整个过程看起来不那么令人生畏了,我期待在屏幕上看到成功安装后出现的版本号。
感谢您强调这是一份实践指南,并且我不必一次性理解所有内容,这消除了我很大的学习焦虑。我期待深入研究代码,通过实践来学习,我同意,根据我的经验,这是学习编程最有效的方法之一。
我特别期待最终能够理解如何开发多层感知机模型、卷积神经网络模型和循环神经网络模型。了解改进模型性能的方法也激起了我的兴趣!
只是有一个问题,在我深入学习的过程中,我想知道在开始接触 TensorFlow 和深度学习时,有哪些常见的陷阱或误解我需要注意的?
总之,这是一篇很棒的文章,Jason!我准备好开始这次深度学习之旅了,您的指南将是我的指南针。我迫不及待地想加深理解,并将这些关键知识应用到实际问题中。感谢您分享您的专业知识,并让像我这样的初学者更容易接触深度学习!
你好 AI…感谢您的反馈和支持!一个常见的陷阱是,在不首先考虑经过时间考验的技术和模型的情况下,就应用“最新最棒”的 AI 工具或技术。
以下资源是开始您使用我们内容的机器学习之旅的绝佳起点
https://machinelearning.org.cn/start-here/