数据科学体现了视觉叙事艺术、统计分析精度以及数据准备、转换和分析基础之间的微妙平衡。这些领域的交叉点是真正数据炼金术发生的地方——转换和解释数据,以讲述引人入胜的故事,从而推动决策和知识发现。正如列奥纳多·达·芬奇巧妙地将科学观察与艺术天才融合在一起,我们将探索数据科学中讲故事的艺术如何以同样的精确性和美感来阐明洞察力。在这篇文章中,我们将通过我们的数据科学思维导图来解构和简化这一过程,同时提供展示具体示例的链接。
让我们开始吧。

数据的达芬奇密码:掌握数据科学思维导图
图片由 Alexandre Debiève 提供。保留部分权利。
概述
这篇文章分为两部分:
- 掌握数据科学思维导图
- 数据科学中的叙事艺术
掌握数据科学思维导图
在我们掌握数据科学思维导图的过程中,我们强调了每个数据科学家都应熟悉的Python基础包的重要性。这些包构成了我们思维导图的支柱,代表了三个基本技能:数据准备、可视化和统计分析。它们是使我们能够将原始数据转化为引人入胜的叙述的工具和构建模块。接下来,我们将深入探讨每个包在数据科学工作流中的独特作用及其双重或单一功能,探索它们在构建数据故事方面的协同作用和各自的优势。
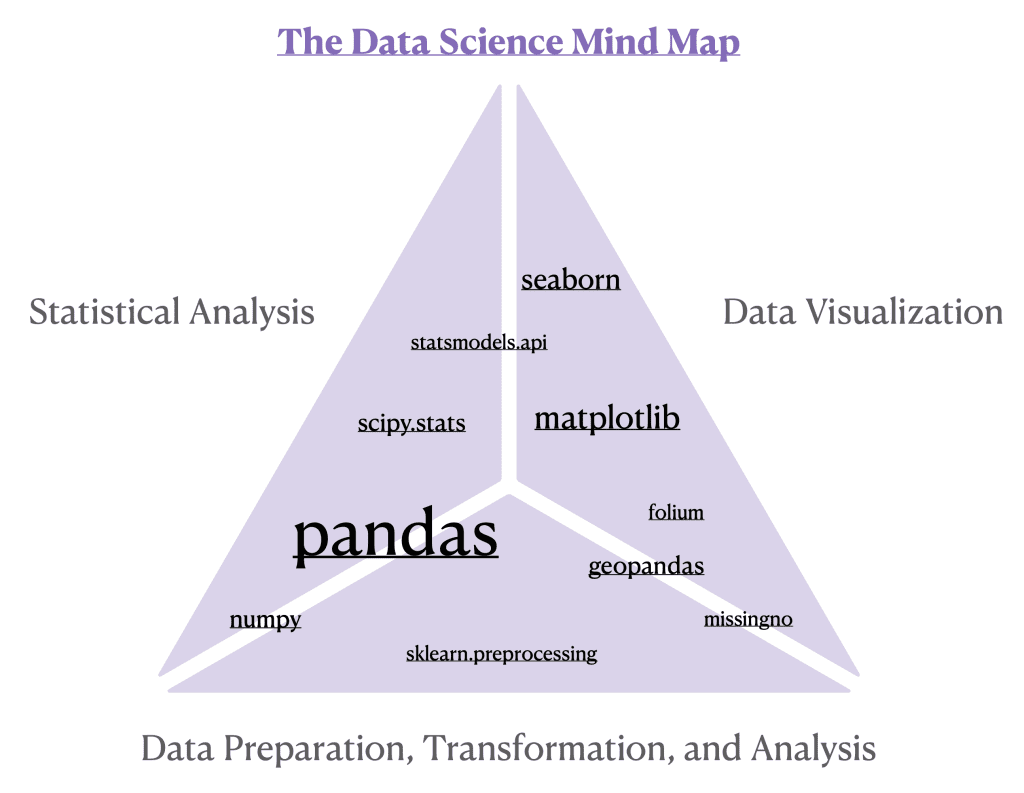
Pandas:pandas 是由 Wes McKinney 构思的,它作为数据整理的基础和通向统计分析的桥梁而脱颖而出。在 pandas 中,DataFrame 不仅仅是一种数据结构;它是数据操作、转换和分析的基石。这种二维、大小可变且可能异构的表格数据结构类似于直接加载到 Python 中的电子表格。通过整齐排列的行和列,DataFrame 使数据操作既直观又高效。每个方法,无论是用于统计摘要的 DataFrame.describe()、用于聚合的 DataFrame.groupby(),还是用于高级重塑的 DataFrame.pivot_tables(),都应用于 DataFrame,从而释放数据的全部潜力。正如我们在关于 用描述性统计解码数据 的详细文章中所示,pandas 允许您高效地将复杂数据集提炼成有意义的统计数据,这是进行任何进一步分析之前的关键一步。此外,了解数据类型至关重要,因为它决定了您可以执行的分析类型。我们关于 分类变量 的文章将引导您完成这个关键阶段,其中 pandas 中的 DataFrame.dtypes 和 DataFrame.select_dtypes() 等方法有助于识别和操纵不同的数据类别。DataFrame.query() 函数让您可以轻松过滤,使 Python 中的复杂 SQL 式查询变得轻而易举,并提供更动态的数据操作方法。有关这些方法的更深入示例和应用,请考虑探索关于转换房地产数据和协调数据技术 此处 的文章中的见解。
Numpy:一个用于 Python 数值计算的基础库,使数据科学家能够轻松快速地执行复杂的数学计算和数据操作。在我们关于 假设检验 的文章中,我们利用 numpy 高效计算了平均值等关键统计量,作为进行假设检验的基础性关键步骤。虽然 pandas 擅长处理表格数据,但 numpy 也通过提供对数组的支持紧随其后,在数据科学工具包中形成了强大的组合。
Sklearn.preprocessing:尽管本系列文章的深度并未扩展到机器学习领域,但值得强调 sklearn.preprocessing 在数据转换中的作用,特别是其 QuantileTransformer() 功能。这项技术已在我们讨论 如何解决偏斜问题 的文章中展示过。
Missingno:missingno 包独特地弥合了数据科学工作流程中预处理、分析和可视化之间的鸿沟。它专门提供数据集中缺失数据的图形表示,从而发挥双重作用:通过视觉识别缺失模式,它有助于数据清洗和准备的早期阶段;通过揭示可能影响后续统计分析的底层结构或异常,它还有助于探索性数据分析。在我们的文章《揭示无形:Python 中缺失数据指南》中,我们深入探讨了如何使用 missingno 有效检测和处理缺失数据,展示了它在确保数据科学项目完整性和鲁棒性方面的关键作用。通过直观的可视化,missingno 不仅增强了数据预处理,还通过揭示数据中经常被掩盖的方面,丰富了分析叙述。
Geopandas:这个包将 pandas 的功能扩展到地理空间数据领域,使其成为地理环境中数据预处理和可视化的不可或缺的工具。它允许数据科学家轻松地操作和分析空间数据,并与用于地理空间分析的其他 Python 库无缝集成。使用 Geopandas,您可以执行复杂的空间操作、合并空间数据集并进行空间连接,同时保持熟悉的 pandas DataFrame 结构。此功能确保处理地理空间数据像处理表格数据一样直观。此外,Geopandas 在可视化地理空间数据方面表现出色,能够创建地图,从而揭示地理模式和关系中引人注目的见解。在我们的文章 从数据到地图:使用 Python 掌握地理空间分析 中,我们展示了 Geopandas 如何将原始地理空间数据转换为信息丰富的地图,突出了它在数据科学工作流程中预处理和视觉解释空间数据的双重作用。
Folium:folium 专注于创建交互式地图这一单一角色,它在 Python 环境中利用了 Leaflet.js 库的地图优势。它擅长构建丰富、交互式的地理空间可视化,允许动态表示叠加在地图上的数据。此功能对于需要直观空间数据探索和展示的项目来说非常宝贵,使 folium 成为 地理空间映射 的首选库。
Matplotlib 和 Seaborn:这两个包作为关键的线索交织在一起,以增强分析叙事结构。Matplotlib 作为基础库,提供了广泛的灵活性和控制,为创建各种静态、动态和交互式可视化奠定了基础。它是 seaborn 的基石,后者通过提供用于绘制美观且信息丰富的统计图形的高级界面来扩展 matplotlib 的功能。seaborn 专注于使复杂的可视化变得易于访问,与 pandas DataFrames 紧密集成,以简化从数据操作到表示的过程。这种协同作用在探索特征关系和揭示数据集中的模式时尤为明显,因为 seaborn 的高级绘图函数,如成对图,建立在 matplotlib 的基础结构之上,提供更丰富、更富有洞察力的视觉叙事。我们关于 探索特征关系 和 利用成对图 的文章深入探讨了 seaborn 和 matplotlib 如何与 pandas 结合,形成一个内聚的可视化套件。这些库共同为数据科学家提供了一个无与伦比的工具包,旨在将复杂的数据洞察转化为引人入胜的视觉故事,突出可视化生态系统中每个包的相互关联性和独特优势。
Statsmodels.api:此工具在统计可视化领域特别有用,通过其 QQ 图(分位数-分位数图)功能,帮助评估数据分布是否符合理论预期,通常是正态分布。我们在 这篇文章 中演示了这项技术。QQ 图的生成涉及将样本数据的排序值与所选理论分布的期望值进行比较,提供了一种图形方法来评估许多参数统计检验至关重要的正态性假设。
Scipy.stats:随着数据科学之旅从描述性统计转向推断性统计,scipy.stats 作为一个关键工具包出现。这个包是进行各种统计测试和分析的基础,这些测试和分析构成了推断性统计的支柱,使数据科学家能够从他们的数据中得出有意义的结论。在 scipy.stats 中,您可以找到大量专为假设检验、置信区间估计等设计的函数,这使得它对于严格的统计调查必不可少。
我们通过各种帖子对统计技术的探索展示了 scipy.stats 的多功能性和强大功能。
- 在 推断性洞察:置信区间 中,我们深入探讨了置信区间如何为未知参数提供一系列合理值,展示了用于根据样本数据计算区间的
t.interval函数。 - 深入假设检验 阐释了推断统计的核心,使用 t 检验等测试来评估我们数据中的假设。
- 我们对 使用埃姆斯住房数据集的卡方检验 的检查使用了
chi2_contingency函数来检验分类变量之间的独立性。 - 利用 ANOVA 和 Kruskal-Wallis 检验 强调了
scipy.stats如何支持参数(ANOVA)和非参数(Kruskal-Wallis)检验,以评估分类变量(“YrSold”)对连续结果(“SalePrice”)的影响。 - 利用非参数 Kolmogorov-Smirnov 检验,我们将转换后的数据与正态分布进行比较,展示了分位数、对数和 Box-Cox 等方法在处理偏斜分布数据方面的转换能力。
因此,Scipy.stats 在将数据科学工作从理解数据中的内容(描述性统计)过渡到推断该数据的含义(推断性统计)方面发挥着至关重要的作用,提供了一套全面的统计测试和分析工具。
数据科学思维导图向您介绍了一系列 Python 库,每个库都在更广泛的数据科学领域中扮演着独特而相互关联的角色。从 pandas 的数据结构能力和 numpy 的数值力量,到 missingno 提供的清理洞察力和 geopandas 的地理智能;从 folium、matplotlib 和 seaborn 提供的迷人可视化,到 statsmodels.api 和 scipy.stats 的分析深度和统计严谨性——每个库都为数据科学的跨学科性质贡献了独特的线索。
通过我的书《数据科学入门指南》启动您的项目。它提供了带有工作代码的自学教程。
数据科学中的叙事艺术
想象一下数据科学中的讲故事过程,就像达芬奇着手创作一幅杰作一样。每一笔画、颜色的选择、光影的运用都有其目的,就像我们数据叙事中的元素一样。让我们探索这个艺术之旅。
勾勒轮廓:在提笔作画之前,列奥纳多会花无数小时进行准备。他解剖人体以了解解剖学,研究光影的特性,并绘制详细的草图。同样,我们在数据讲故事中的第一步是深入研究数据集,理解其变量,并规划我们的分析。这个阶段为准确而引人入胜的叙事奠定了基础。
选择调色板:正如列奥纳多调和颜料以获得完美的色调一样,数据叙述者会从数据科学思维导图中选择工具和技术。选择 Python 包,例如用于数据操作的 pandas、用于可视化的 matplotlib 和 seaborn,或用于统计分析的 scipy.stats,就成为了我们的调色板,使我们能够从数据中阐明洞见。
通过透视创造深度:达芬奇对透视的使用赋予了他的画作深度,使其更逼真、更引人入胜。在数据叙事中,我们通过分析创造深度,从多个角度审视数据以揭示潜在的模式和关系。这种透视帮助我们构建一个能与观众产生共鸣的叙事,为他们提供超越表面的洞察。
用光影突出重点:达芬奇是明暗对比的大师,这种技巧利用光影为他的画作增添戏剧性和焦点。在我们的数据故事中,可视化作为我们的光影,突出关键发现并将观众的注意力吸引到最重要的洞察力上。通过有效的可视化,我们可以使复杂的数据变得易于理解和记忆。
最终杰作:当达芬奇展示他的完成作品时,它不仅仅是一幅画;它是一个被时间捕捉的故事,唤起情感并引发思考。我们的数据故事,最终呈现我们的发现,旨在达到同样的目的。它是我们的准备、分析和可视化相结合,以告知、说服和激励我们的受众采取行动。
正如观众站在达芬奇的画作前,沉浸于它的美感和深度一样,我们邀请您的观众反思您将讲述的数据驱动的故事。这种反思是理解加深的地方,也是您的作品真正影响被感受到的地方,回响着达芬奇艺术的持久遗产。
想开始学习数据科学新手指南吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
进一步阅读
教程
资源
总结
在我们数据科学系列的最后一篇文章中,我们揭示了将原始数据转化为引人入胜、激发行动的叙事的艺术与科学。通过遍历数据科学思维导图,我们看到了基础工具和技术如何作为数据准备、分析和可视化的基石,从而将复杂数据集转化为富有洞察力的故事。通过将列奥纳多·达·芬奇艺术与科学的精妙融合进行类比,我们探索了数据科学中的叙事过程,将其视为一项创造性事业,它就像绘画一幅杰作一样,需要精心准备、合适的工具和敏锐的洞察力,才能揭示数据中隐藏的故事。本文旨在简化数据科学过程,并激励您以科学家的好奇心和艺术家的心灵来对待您的数据。
具体来说,你学到了:
- 数据科学思维导图中所描绘的基础工具的重要作用。
- 数据科学中的叙事过程,从铺垫,到创造深度,最后呈现唤起理解和行动的“杰作”。
您有任何问题吗?请在下面的评论中提出您的问题,我将尽力回答。



 for Machine Learning")

")

暂无评论。