Luong 注意力机制旨在对 Bahdanau 模型进行多项改进,用于神经机器翻译,特别是引入了两种新型的注意力机制:一种是关注所有源词的“全局”方法,另一种是仅关注选定子集词汇的“局部”方法,用于预测目标句子。
在本教程中,您将了解用于神经机器翻译的 Luong 注意力机制。
完成本教程后,您将了解:
- Luong 注意力算法执行的操作
- 全局和局部注意力模型的工作原理。
- Luong 注意力与 Bahdanau 注意力的比较
通过我的书《使用注意力构建 Transformer 模型》**启动您的项目**。它提供了**自学教程**和**可运行代码**,指导您构建一个功能完备的 Transformer 模型,该模型可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

Luong 注意力机制
摄影:Mike Nahlii,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- Luong 注意力简介
- Luong 注意力算法
- 全局注意力模型
- 局部注意力模型
- 与 Bahdanau 注意力的比较
先决条件
本教程假设您已熟悉以下内容:
Luong 注意力简介
Luong 等人(2015)从之前的注意力模型中汲取灵感,提出了两种注意力机制:
在这项工作中,我们秉持着简洁性和有效性的原则,设计了两种新型的基于注意力的模型:一种是始终关注所有源词的全局方法,另一种是每次只查看部分源词的局部方法。
– 《基于注意力的神经机器翻译的有效方法》,2015年。
全局注意力模型类似于Bahdanau 等人(2014)的模型,它关注所有源词,但旨在简化其架构。
局部注意力模型受到Xu 等人(2016)的硬注意力和软注意力模型的启发,只关注少数源位置。
这两种注意力模型在预测当前词的许多步骤上是相似的,但主要区别在于它们计算上下文向量的方式。
让我们首先了解 Luong 注意力算法的整体概况,然后深入探讨全局和局部注意力模型之间的差异。
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Luong 注意力算法
Luong 等人的注意力算法执行以下操作:
- 编码器从输入句子生成一组注释,$H = \mathbf{h}_i, i = 1, \dots, T$。
- 当前的解码器隐藏状态计算为:$\mathbf{s}_t = \text{RNN}_\text{decoder}(\mathbf{s}_{t-1}, y_{t-1})$。这里,$\mathbf{s}_{t-1}$ 表示先前的隐藏解码器状态,$y_{t-1}$ 表示先前的解码器输出。
- 对齐模型 $a(.)$ 使用注释和当前解码器隐藏状态来计算对齐分数:$e_{t,i} = a(\mathbf{s}_t, \mathbf{h}_i)$。
- 对齐分数应用 softmax 函数,有效地将它们归一化为 0 到 1 范围内的权重值:$\alpha_{t,i} = \text{softmax}(e_{t,i})$。
- 结合之前计算的注释,这些权重通过注释的加权和生成一个上下文向量:$\mathbf{c}_t = \sum^T_{i=1} \alpha_{t,i} \mathbf{h}_i$。
- 注意力隐藏状态根据上下文向量和当前解码器隐藏状态的加权拼接计算:$\widetilde{\mathbf{s}}_t = \tanh(\mathbf{W_c} [\mathbf{c}_t \; ; \; \mathbf{s}_t])$。
- 解码器通过输入加权注意力隐藏状态来产生最终输出:$y_t = \text{softmax}(\mathbf{W}_y \widetilde{\mathbf{s}}_t)$。
- 步骤 2-7 重复执行,直到序列结束。
全局注意力模型
全局注意力模型在生成对齐分数,并最终在计算上下文向量时,考虑输入句子中的所有源词。
全局注意力模型的思想是在推导上下文向量 $\mathbf{c}_t$ 时,考虑编码器的所有隐藏状态。
– 《基于注意力的神经机器翻译的有效方法》,2015年。
为此,Luong 等人提出了三种计算对齐分数的替代方法。第一种方法类似于 Bahdanau 的方法,它基于 $\mathbf{s}_t$ 和 $\mathbf{h}_i$ 的拼接,而第二种和第三种方法实现了*乘法*注意力(与 Bahdanau 的*加法*注意力相对)。
- $$a(\mathbf{s}_t, \mathbf{h}_i) = \mathbf{v}_a^T \tanh(\mathbf{W}_a [\mathbf{s}_t \; ; \; \mathbf{h}_i)]$$
- $$a(\mathbf{s}_t, \mathbf{h}_i) = \mathbf{s}^T_t \mathbf{h}_i$$
- $$a(\mathbf{s}_t, \mathbf{h}_i) = \mathbf{s}^T_t \mathbf{W}_a \mathbf{h}_i$$
这里,$\mathbf{W}_a$ 是一个可训练的权重矩阵,类似地,$\mathbf{v}_a$ 是一个权重向量。
直观上,在*乘法*注意力中使用点积可以解释为在所考虑的向量 $\mathbf{s}_t$ 和 $\mathbf{h}_i$ 之间提供相似度度量。
……如果向量相似(即对齐),乘法结果将是一个大值,并且注意力将集中在当前的 t,i 关系上。
—— 使用 Python 进行高级深度学习,2019年。
由此产生的对齐向量 $\mathbf{e}_t$ 的长度根据源词的数量而变化。
局部注意力模型
全局注意力模型在关注所有源词时计算成本高昂,对于翻译更长的句子可能会变得不切实际。
局部注意力模型旨在通过关注源词的一个较小子集来生成每个目标词,从而解决这些限制。为此,它从Xu 等人(2016)的图像字幕生成工作中的*硬*注意力和*软*注意力模型中汲取灵感。
- 软注意力等同于全局注意力方法,其中权重被柔和地分布在所有源图像块上。因此,软注意力考虑了整个源图像。
- 硬注意力每次关注一个图像块。
Luong 等人的局部注意力模型通过计算对齐位置 $p_t$ 为中心的一个窗口内注释集 $\mathbf{h}_i$ 的加权平均值来生成上下文向量。
$$[p_t – D, p_t + D]$$
虽然 $D$ 的值是凭经验选择的,但 Luong 等人考虑了两种计算 $p_t$ 值的方法:
- 单调对齐:假设源句和目标句是单调对齐的,因此 $p_t = t$。
- 预测对齐:其中对齐位置的预测基于可训练模型参数 $\mathbf{W}_p$ 和 $\mathbf{v}_p$ 以及源句子长度 $S$。
$$p_t = S \cdot \text{sigmoid}(\mathbf{v}^T_p \tanh(\mathbf{W}_p, \mathbf{s}_t))$$
在计算对齐权重时,高斯分布以 $p_t$ 为中心,以偏向窗口中心附近的源词。
这次,所得的对齐向量 $\mathbf{e}_t$ 的固定长度为 $2D + 1$。
通过我的书《使用注意力构建 Transformer 模型》**启动您的项目**。它提供了**自学教程**和**可运行代码**,指导您构建一个功能完备的 Transformer 模型,该模型可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
与 Bahdanau 注意力的比较
Bahdanau 模型和 Luong 等人的全局注意力方法大体相似,但两者之间存在关键差异。
虽然我们的全局注意力方法在精神上与 Bahdanau 等人(2015)提出的模型相似,但存在几个关键差异,反映了我们如何从原始模型中进行简化和概括。
– 《基于注意力的神经机器翻译的有效方法》,2015年。
- 最值得注意的是,Luong 全局注意力模型中对齐分数 $e_t$ 的计算取决于当前的解码器隐藏状态 $\mathbf{s}_t$,而不是像 Bahdanau 注意力那样依赖于先前的隐藏状态 $\mathbf{s}_{t-1}$。
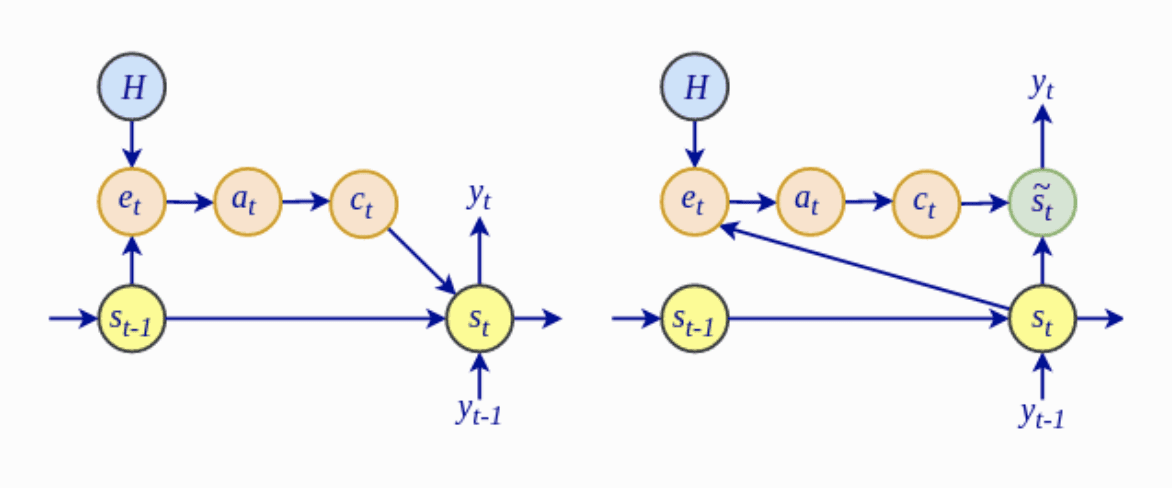
Bahdanau 架构(左)与 Luong 架构(右)
摘自《Python 深度学习进阶》
- Luong 等人放弃了 Bahdanau 模型使用的双向编码器,转而利用顶层 LSTM 层中的隐藏状态进行编码器和解码器。
- Luong 等人的全局注意力模型研究了使用乘法注意力作为 Bahdanau 加法注意力的替代方案。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用 Python 进行高级深度学习, 2019.
论文
- 基于注意力的神经机器翻译的有效方法, 2015.
总结
在本教程中,您了解了用于神经机器翻译的 Luong 注意力机制。
具体来说,你学到了:
- Luong 注意力算法执行的操作
- 全局和局部注意力模型的工作原理
- Luong 注意力与 Bahdanau 注意力的比较
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...






机制的解释和比较令人大开眼界。提到的参考书结束了我对高级深度学习的搜索。感谢如此好的帖子。
谢谢。希望您喜欢。
不错的介绍!
在 [全局注意力模型] 中的 eq.1 应该拼接 s_t 和 h_i,而不是两个 s_t。
感谢您的反馈 Yuanmu!
在 Luong 和 Bahdanau 的情况下,解码器中的第一个 (LSTM) 单元都将编码器的最后一个隐藏状态 (Yt-1) 作为输入吗?
嗨 MG…以下内容您可能感兴趣
https://ai.plainenglish.io/introduction-to-attention-mechanism-bahdanau-and-luong-attention-e2efd6ce22da
尊敬的 Stefania 博士、Tam 博士、Jason 博士或 Carmichael 先生:
tensorflow 包中有一个 Luong 算法的实现。
未来是否会有一个关于 Luong 算法实现的教程,并将其与不带注意力的模型进行比较?
谢谢你,
悉尼的Anthony
我很困惑,在 Bahdanau 教程中,对齐函数接收输入 s_t-1 和 h_i,而在这个教程中是 s_t 和 h_i。
当我们仍在计算当前输出时,如何可能使用当前输出的隐藏状态?
嗨 Darcy…以下资源您可能感兴趣
https://www.baeldung.com/cs/attention-luong-vs-bahdanau
嗨 Darcy,Bahdanau 等人和 Luong 等人使用了不同的架构
在 Bahdanau 等人的方法中,上下文向量首先基于前一步的解码器状态计算(这意味着当前时间步的解码器状态尚不可用)。然后他们继续使用上下文向量(以及其他参数)来计算当前解码器输出。
在 Luong 等人的方法中,当前解码器状态首先基于先前的隐藏解码器状态和先前的解码器输出来计算,这意味着当前解码器状态的初始计算变得可用。上下文向量在之后计算,其计算利用了当前解码器状态。Luong 等人然后使用此上下文向量修改当前解码器状态,然后将其由 softmax 层处理以产生最终的解码器输出。
Bahdanau 等人使用先前的隐藏解码器状态,而 Luong 等人基于当前的隐藏解码器状态进行计算,这是这两种方法之间的主要区别之一。