使用 Python 绘制时间序列数据的 6 种方法
时间序列数据天然适合可视化。
按时间顺序绘制观测值的线图很受欢迎,但还有其他一系列图表可用于深入了解您的问题。
您对数据了解得越多,就越有可能开发出更好的预测模型。
在本教程中,您将发现 6 种不同的图表类型,您可以使用它们来可视化 Python 中的时间序列数据。
具体来说,完成本教程后,您将了解
- 如何使用线图、滞后图和自相关图探索时间序列的时间结构。
- 如何使用直方图和密度图理解观测值的分布。
- 如何使用箱须图和热力图来解析间隔期间分布的变化。
启动您的项目,阅读我的新书 《使用 Python 进行时间序列预测》,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。
- 更新于 2019 年 8 月:使用新 API 更新了数据加载和分组。
- 更新于 2019 年 9 月:修复了使用 Grouper 和旧工具 API 的示例中的错误。
时间序列可视化
可视化在时间序列分析和预测中起着重要作用。
原始样本数据的图表可以提供有价值的诊断信息,以识别趋势、周期和季节性等时间结构,这些结构会影响模型的选择。
问题在于,许多时间序列预测领域的新手仅止步于线图。
在本教程中,我们将介绍 6 种不同的可视化图表,您可以在自己的时间序列数据上使用它们。它们是:
- 线图。
- 直方图和密度图。
- 箱须图。
- 热力图。
- 滞后图或散点图。
- 自相关图。
重点是单变量时间序列,但这些技术同样适用于多变量时间序列,当您在每个时间步有多个观测值时。
接下来,让我们看一下本教程中用于演示时间序列可视化的数据集。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
日最低气温数据集
此数据集描述了墨尔本市 10 年(1981-1990 年)的每日最低气温。
单位是摄氏度,共有3650个观测值。数据来源归功于澳大利亚气象局。
下载数据集并将其放入当前工作目录,文件名设置为“daily-minimum-temperatures.csv”。
下面是一个将数据集加载为 Pandas Series 的示例。
|
1 2 3 4 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) print(series.head()) |
运行此示例将加载数据集并打印前 5 行。
|
1 2 3 4 5 6 7 |
日期 1981-01-01 20.7 1981-01-02 17.9 1981-01-03 18.8 1981-01-04 14.6 1981-01-05 15.8 名称:温度,数据类型:float64 |
1. 时间序列线图
时间序列的第一个,也许也是最受欢迎的可视化方法就是线图。
在此图中,x 轴显示时间,y 轴显示观测值。
下面是可视化每日最低气温数据集的 Pandas Series 直接作为线图的示例。
|
1 2 3 4 5 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) series.plot() pyplot.show() |
运行此示例将创建一个线图。
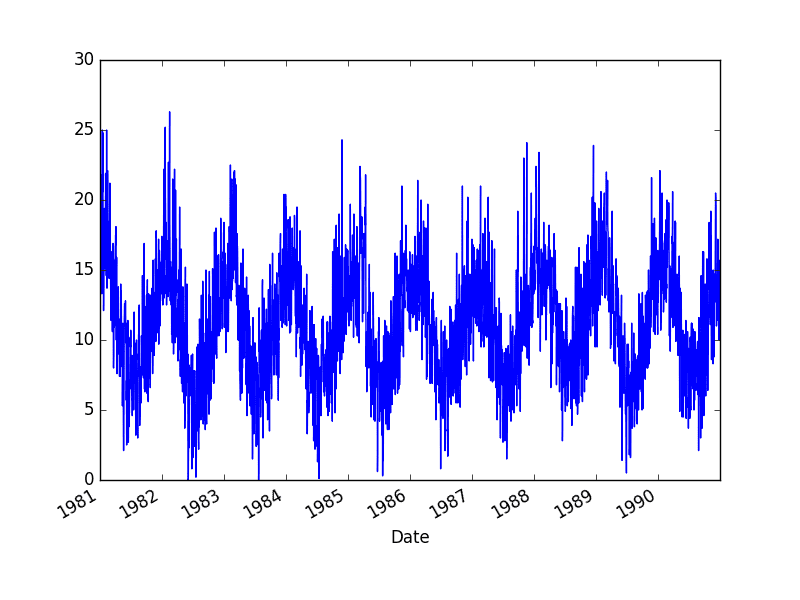
每日最低气温线图
该线图非常密集。
有时改变线图的样式可能会有所帮助;例如,使用虚线或点。
下面是一个示例,展示了如何将线图样式更改为黑色点而不是连接线(style='k.' 参数)。
通过将样式设置为‘k–’,我们可以将此示例更改为使用虚线。
|
1 2 3 4 5 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) series.plot(style='k.') pyplot.show() |
运行此示例将重新创建相同的线图,但显示点而不是连接线。
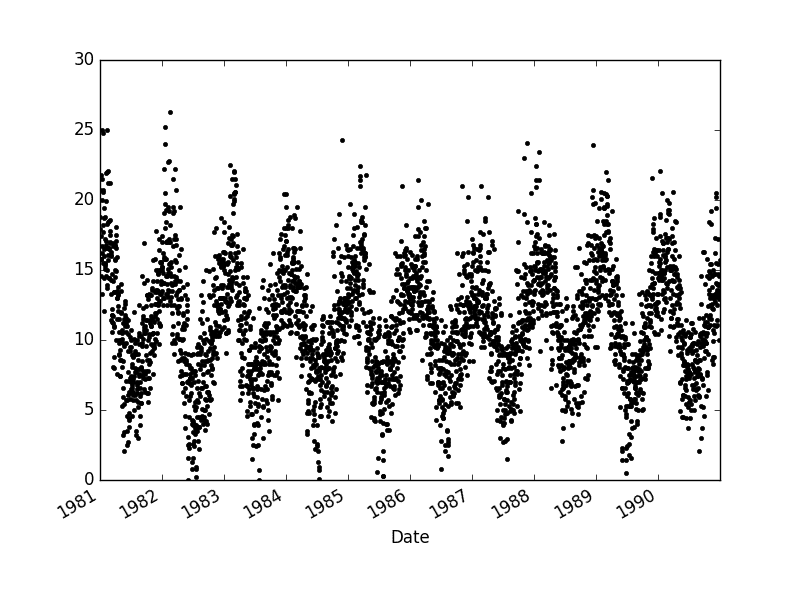
每日最低气温点图
比较同一时间间隔(例如,日与日、月与月、年与年)的线图可能会有所帮助。
每日最低气温数据集跨越 10 年。我们可以按年对数据进行分组,并为每一年创建一条线图以进行直接比较。
下面的示例展示了如何做到这一点。
然后对组进行枚举,并将每年的观测值存储在新 DataFrame 的列中。
最后,创建此人为构造的 DataFrame 的图,其中每列可视化为一个子图,并移除图例以减少混乱。
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import read_csv from pandas import DataFrame from pandas import Grouper from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) groups = series.groupby(Grouper(freq='A')) years = DataFrame() for name, group in groups: years[name.year] = group.values years.plot(subplots=True, legend=False) pyplot.show() |
运行此示例将创建 10 个线图,每个图代表一年,从顶部的 1981 年到底部的 1990 年,每个线图的长度为 365 天。
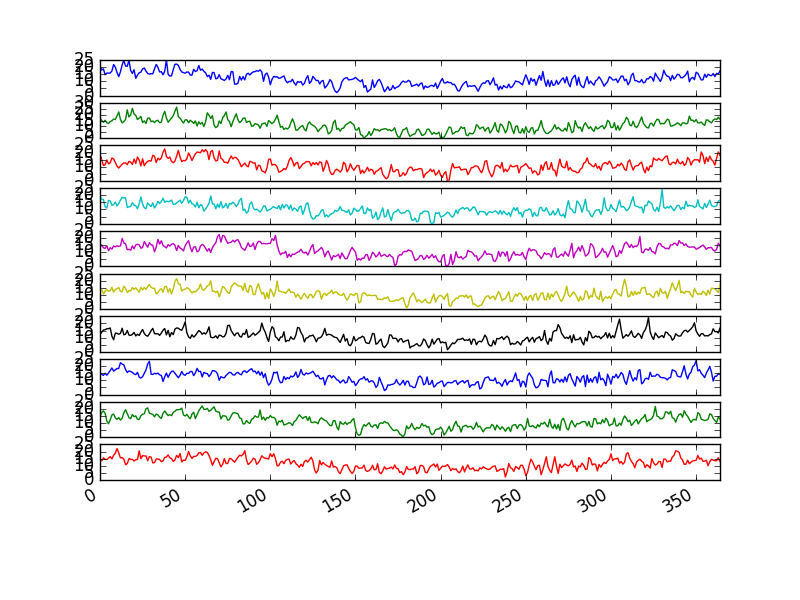
每日最低气温年度线图
2. 时间序列直方图和密度图
另一个重要的可视化是观测值的分布。
这意味着绘制没有时间顺序的值的图。
一些线性时间序列预测方法假设观测值具有良好的分布(即钟形曲线或正态分布)。这可以通过统计假设检验等工具进行显式检查。但图表可以为原始观测值以及执行任何类型的数据转换后的观测值分布提供有用的初步检查。
下面的示例创建了每日最低气温数据集的观测值直方图。直方图将值分组到不同的箱中,每个箱中的观测值的频率或计数可以深入了解观测值的底层分布。
|
1 2 3 4 5 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) series.hist() pyplot.show() |
运行此示例将显示一个看起来非常像高斯分布的分布。绘图函数会自动根据数据中值的分布选择箱的大小。

每日最低气温直方图
通过使用密度图,我们可以更清楚地了解观测值分布的形状。
这类似于直方图,只是使用一个函数来拟合观测值的分布,并使用一条光滑的曲线来总结此分布。
下面是每日最低气温数据集的密度图示例。
|
1 2 3 4 5 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) series.plot(kind='kde') pyplot.show() |
运行此示例将创建一个提供观测值分布更清晰摘要的图。我们可以看到,该分布可能有些不对称,并且可能有些尖锐,不完全是高斯分布。
看到这样的分布可能表明稍后需要探索统计假设检验来正式检查分布是否为高斯分布,并可能进行数据准备技术来重塑分布,例如 Box-Cox 变换。
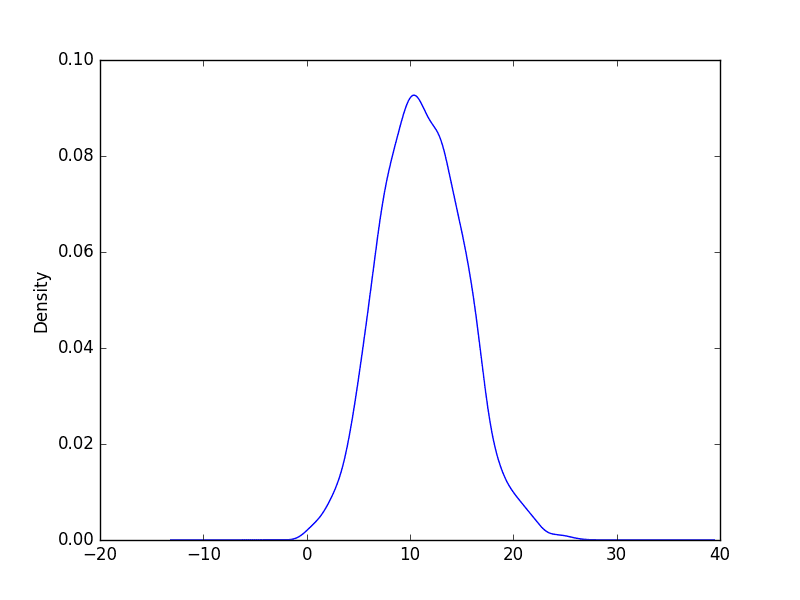
每日最低气温密度图
3. 按时间间隔的时间序列箱须图
直方图和密度图可以洞察所有观测值的分布,但我们也可能对按时间间隔划分的值的分布感兴趣。
另一种可用于总结观测值分布的图表类型是箱须图。此图围绕数据的第 25 和第 75 百分位数绘制一个框,该框捕获了 50% 的观测值。一条线绘制在第 50 百分位数(中位数)处,并在框的上方和下方绘制须来总结观测值的总体范围。超出须或数据范围的异常值会以点绘制。
可以为时间序列中的每个间隔(例如,年、月或日)创建并比较箱须图。
下面是每日最低气温数据集按年份分组的示例,就像在上面的绘图示例中所做的那样。然后为每一年创建一个箱须图,并将它们并排放置以进行直接比较。
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import read_csv from pandas import DataFrame from pandas import Grouper from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) groups = series.groupby(Grouper(freq='A')) years = DataFrame() for name, group in groups: years[name.year] = group.values years.boxplot() pyplot.show() |
按一致的时间间隔比较箱须图是一种有用的工具。在时间间隔内,它可以帮助发现异常值(须上方或下方的点)。
跨时间间隔,在本例中是年份,我们可以寻找多种年份的趋势、季节性和其他可以建模的结构化信息。
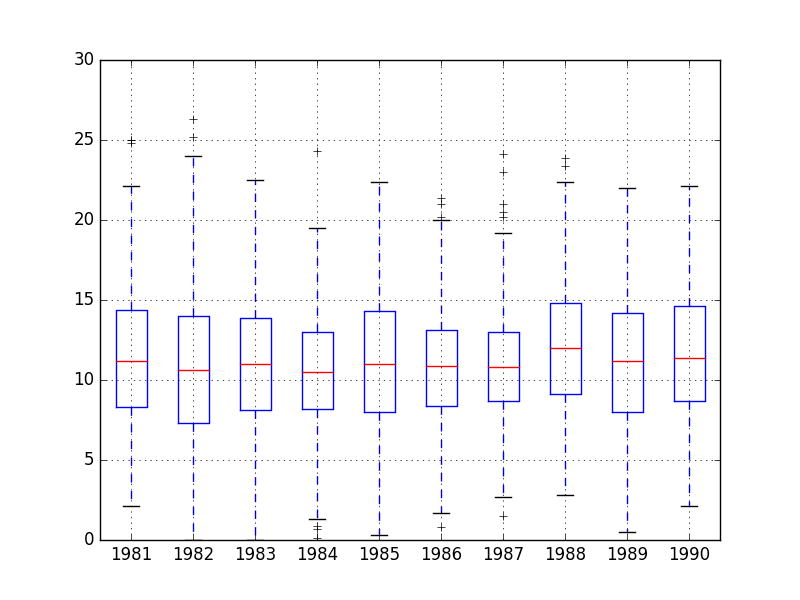
每日最低气温年度箱须图
我们也可能对一年中各个月份的值的分布感兴趣。
下面的示例创建了 12 个箱须图,显示了数据集中最后一年的 1990 年的每个月。
在示例中,首先,仅提取 1990 年的观测值。
然后,按月份对观测值进行分组,并将每个月添加到一个新 DataFrame 中作为一列。
最后,为新构建的 DataFrame 中每个月列创建一个箱须图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 创建月度数据的箱线图 from pandas import read_csv from pandas import DataFrame from pandas import Grouper from matplotlib import pyplot 从 pandas 导入 concat series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) one_year = series['1990'] groups = one_year.groupby(Grouper(freq='M')) months = concat([DataFrame(x[1].values) for x in groups], axis=1) months = DataFrame(months) months.columns = range(1,13) months.boxplot() pyplot.show() |
运行此示例将创建 12 个箱须图,显示了从南半球夏季(一月)到南半球冬季(年中)再到夏季的最低气温分布的显著变化。
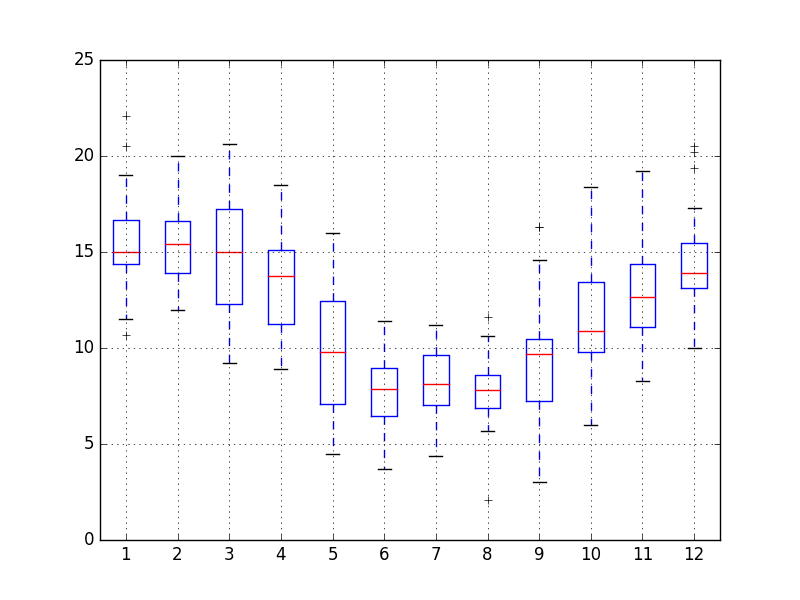
每日最低气温月度箱须图
4. 时间序列热力图
数字矩阵可以绘制为曲面,其中矩阵中每个单元格的值被分配唯一的颜色。
这被称为热力图,因为较大的值可以用较暖的颜色(黄色和红色)绘制,而较小的值可以用较冷的颜色(蓝色和绿色)绘制。
与箱须图类似,我们可以使用热力图来比较时间间隔之间的观测值。
对于每日最低气温,可以将观测值排列成一个矩阵,其中包含年份列和日期行,每个日期的单元格中包含最低气温。然后可以绘制此矩阵的热力图。
下面是创建每日最低气温数据热力图的示例。由于 Pandas 不直接提供热力图支持,因此使用了 matplotlib 库的 matshow() 函数。
为了方便起见,矩阵被旋转(转置),以便每一行代表一年,每一列代表一天。这提供了更直观的、从左到右的数据布局。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from pandas import read_csv from pandas import DataFrame from pandas import Grouper from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) groups = series.groupby(Grouper(freq='A')) years = DataFrame() for name, group in groups: years[name.year] = group.values years = years.T pyplot.matshow(years, interpolation=None, aspect='auto') pyplot.show() |
该图显示了一年中较靠中间的日期的较低的最低气温,以及一年开始和结束时较暖的最低气温,以及它们之间的所有淡入和复杂性。

每日最低气温年度热力图
与上面类似的箱须图示例,我们还可以比较一年中的月份。
下面是 1990 年月份比较的热力图示例。每列代表一个月,行代表该月从第 1 天到第 31 天。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from pandas import read_csv from pandas import DataFrame from pandas import Grouper from matplotlib import pyplot 从 pandas 导入 concat series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) one_year = series['1990'] groups = one_year.groupby(Grouper(freq='M')) months = concat([DataFrame(x[1].values) for x in groups], axis=1) months = DataFrame(months) months.columns = range(1,13) pyplot.matshow(months, interpolation=None, aspect='auto') pyplot.show() |
运行此示例将显示与每年相似的宏观趋势,但从月份到月份的细化程度不同。
我们还可以看到图底部有一些白色斑块。这是由于那些月数少于 31 天的数据丢失造成的,其中 1990 年的二月只有 28 天,是一个明显的异常值。

每日最低气温月度热力图
5. 时间序列滞后散点图
时间序列建模假设观测值与前一个观测值之间存在关系。
时间序列中的前一个观测值称为滞后,前一个时间步的观测值称为滞后1,前两个时间步的观测值称为滞后2,依此类推。
一种探索每个观测值与该观测值的滞后值之间关系的有用的图表类型称为散点图。
Pandas 有一个精确为此目的设计的内置函数,称为滞后图。它将时间 t 的观测值绘制在 x 轴上,将滞后 1 的观测值(t-1)绘制在 y 轴上。
- 如果点沿着从左下到右上的对角线聚集,则表明存在正相关关系。
- 如果点沿着从左上到右下的对角线聚集,则表明存在负相关关系。
- 无论哪种关系,都是有益的,因为它们可以被建模。
更靠近对角线的点表明关系更强,而远离对角线的点表明关系更弱。
中间的球体或在图表上散开的点表明关系很弱或不存在。
下面是每日最低气温数据集的滞后图示例。
|
1 2 3 4 5 6 7 |
# 创建散点图 from pandas import read_csv from matplotlib import pyplot from pandas.plotting import lag_plot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) lag_plot(series) pyplot.show() |
从示例运行创建的图显示了观测值与其滞后 1 值之间存在相对较强的正相关关系。
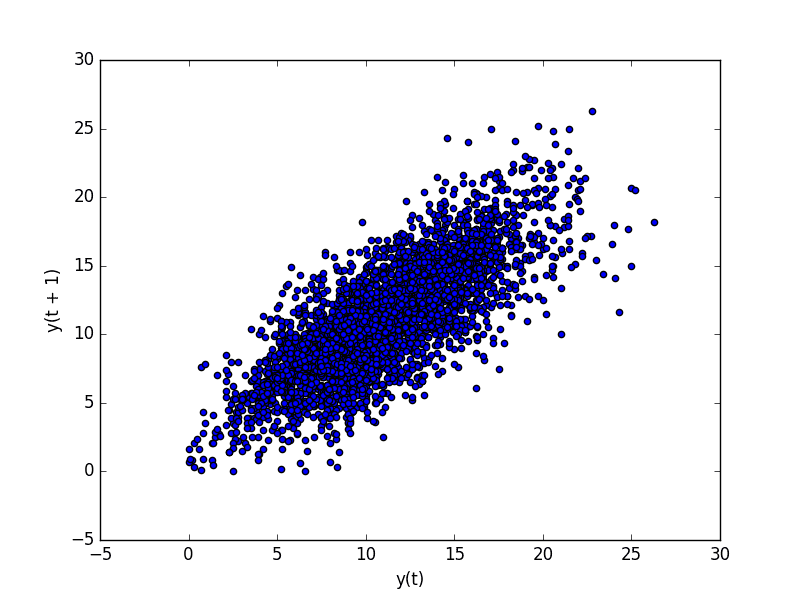
每日最低气温滞后图
我们可以对观测值与任何滞后值重复此过程。也许是与上周、上个月或去年同一时间的观测值,或者任何我们希望探索的其他领域知识。
例如,我们可以创建观测值与过去七天中每个值的散点图。下面是每日最低气温数据集的示例。
首先,创建一个新的 DataFrame,将滞后值作为新列。列被适当地命名。然后创建新的子图,将每个观测值与不同的滞后值绘制出来。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat from matplotlib import pyplot from pandas.plotting import scatter_matrix series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) values = DataFrame(series.values) lags = 7 columns = [values] for i in range(1,(lags + 1)): columns.append(values.shift(i)) dataframe = concat(columns, axis=1) columns = ['t+1'] for i in range(1,(lags + 1)): columns.append('t-' + str(i)) dataframe.columns = columns pyplot.figure(1) for i in range(1,(lags + 1)): ax = pyplot.subplot(240 + i) ax.set_title('t+1 vs t-' + str(i)) pyplot.scatter(x=dataframe['t+1'].values, y=dataframe['t-'+str(i)].values) pyplot.show() |
运行此示例表明,观测值与其滞后 1 值之间存在最强的关系,但总体上与过去一周的每个值都存在良好的正相关。
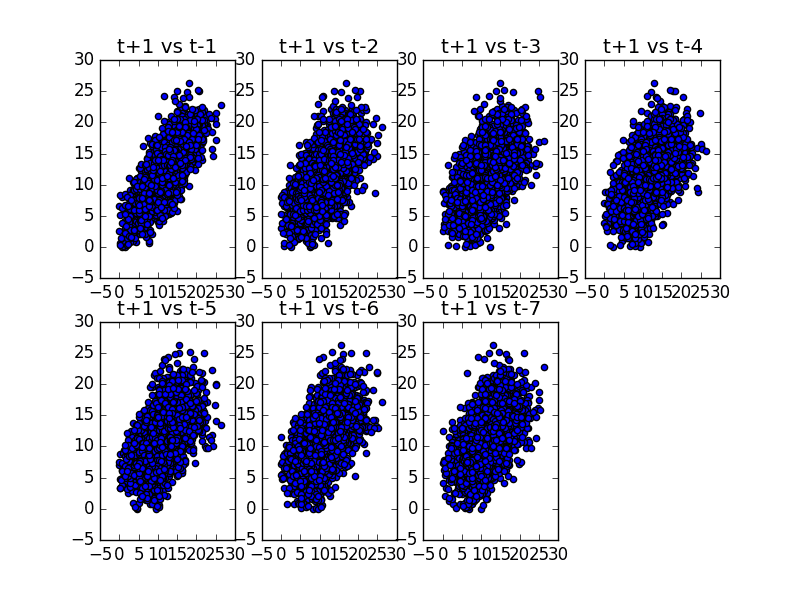
每日最低气温散点图
6. 时间序列自相关图
我们可以量化观测值与其滞后值之间的关系强度和类型。
在统计学中,这称为相关性,当针对时间序列中的滞后值计算时,它称为自相关(自身相关)。
在两组数字(例如,观测值及其滞后 1 值)之间计算的相关值,结果是介于 -1 和 1 之间的数字。该数字的符号分别表示负相关或正相关。接近零的值表示弱相关,而接近 -1 或 1 的值表示强相关。
可以为每个观测值和不同的滞后值计算相关值,称为相关系数。计算后,可以创建图表以帮助更好地理解这种关系如何随着滞后而变化。
这种类型的图表称为自相关图,Pandas 提供了此功能,称为 autocorrelation_plot() 函数。
下面的示例为每日最低气温数据集创建了自相关图
|
1 2 3 4 5 6 7 |
# 创建自相关图 from pandas import read_csv from matplotlib import pyplot from pandas.plotting import autocorrelation_plot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True) autocorrelation_plot(series) pyplot.show() |
生成的图显示 x 轴上的滞后值和 y 轴上的相关性。提供点线,指示超出这些线的任何相关值都具有统计学意义(有意义)。
我们可以看到,对于每日最低气温数据集,我们看到了强烈的负相关和正相关周期。这捕捉了观测值与同一季节或一年中相同和相反时间的前一个观测值之间的关系。像此示例中看到的正弦波是数据集中季节性的强烈标志。
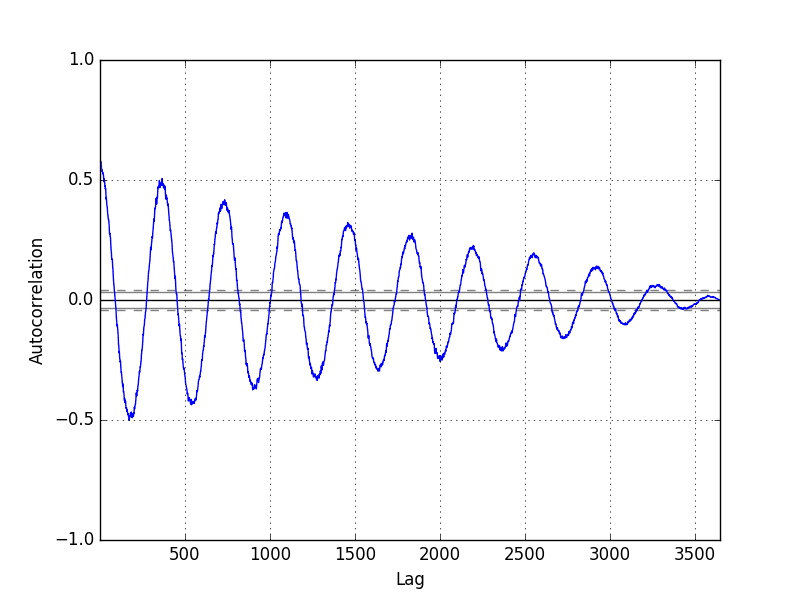
每日最低气温自相关图
进一步阅读
本节提供了一些关于时间序列绘图以及本教程中使用的 Pandas 和 Matplotlib 函数的进一步阅读资源。
总结
在本教程中,您学习了如何在 Python 中探索和更好地理解您的时间序列数据集。
具体来说,你学到了:
- 如何使用线图、散点图和自相关图探索时间关系。
- 如何使用直方图和密度图探索观测值的分布。
- 如何使用箱须图和热力图探索观测值分布的变化。
您对绘图时间序列数据或本教程有任何疑问吗?
在评论中提出您的问题,我会尽力回答。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。



")


很棒的文章和博客,谢谢!我的结论是,自相关图可以作为起点,用于决定例如在 LSTM 模型中应使用多少个先前时间步。我们可以以其他方式利用这些信息吗?例如,我们如何将季节性知识用于 LSTM 模型?
Sebastian,您问了一个很棒的问题,我正在处理一些示例,这些示例将出现在博客和即将出版的书籍/系列中。
自相关图可以帮助配置 ARIMA 等线性模型。
季节性知识对于去除季节性成分(使序列平稳以用于线性模型)以及针对特定季节的特征工程很有用。这些新特征可以用作 LSTM 等非线性模型的输入。
谢谢你的回答!
你好,Jason。
精彩的报告!非常感谢。
您谈到了将线性 ARIMA 输出作为另一个特征实现到非线性 LSTM 模型中(用于预测温度)。
您是否在另一篇报告或书籍中解释过这种方法?
此致
Stephan
我没有这样的例子,我可能会在未来准备一个示例。
您好,感谢您的精彩总结,我有一个小建议:我觉得 matshow 可视化由于视觉插值的原因,有点令人困惑。
来自 matshow 的文档:“如果插值是 None,则默认使用 rc image.interpolation。另请参阅 filternorm 和 filterrad 参数。如果插值是‘none’,则在 Agg、ps 和 pdf 后端上不执行插值。其他后端将回退到‘nearest’”
因此,将插值显式设置为‘nearest’应该能让图表更加清晰。
谢谢你,Luca。
再次,数据源有?,Series.from_csv() 将数据加载为字符串,而不是浮点数。所以无法绘图。
7/20/1982 ?0.2
7/21/1982 ?0.8
我建议在运行示例之前打开文件并删除“?”字符。
我已更新教程以建议这样做。
你好!我刚发现 lag_plot 函数可以带一个 lag 参数来指定滞后。所以你不需要自己写一个函数。你只需要这样做:lag_plot(series,lag=3) 来实现 3 的滞后。尽管这可能值得了解。
太棒了,感谢 Sebastian 的提示。
Jason,干得漂亮。您是否有像机器学习的循序渐进教程一样,为首次进行时间序列分析的读者提供入门指南?https://machinelearning.org.cn/machine-learning-in-python-step-by-step/#comment-384184
类似于一个端到端的简单项目
我将在我即将出版的时间序列预测书中提供一些示例。
您会在您的博客上免费分享一些吗?还是我必须买书才能访问?
您好 Raphael,我可能会在博客上分享一些。这本书将是该主题的最佳资料来源。
增加透明度,突出重叠的点,使第二个散点图更有趣。
min_temp.plot(style=’k.’, alpha=0.4)
一如既往,精彩的帖子。
工作很棒,谢谢。
如果我有一小组词(代表主题的变化)每年
如何每年可视化这些“词”,以可视化给定文本语料库中每年主题的变化?
因此,我的输入将是一系列年份及其相应的主题词。(例如一个 python 字典)
谢谢。
您必须开发一些代码来制作此图。
无法绘制堆积折线图。 # 创建堆积折线图。我只有一年的数据,所以我想为 cc 数据框中的周绘制堆积折线图。我运行了这段代码。
# 创建堆积折线图
from pandas import TimeGrouper
groups = cc.groupby(TimeGrouper(“M”))
years = DataFrame()
for name, group in groups
years.at[name.year] = groups.values
years.plot(subplots=True, legend=False)
pyplot.show()
我收到了这个消息
AttributeError Traceback (最近一次调用)
in ()
8 for name, group in groups
9
—> 10 years.at[name.year] = groups.values
11 years.plot(subplots=True, legend=False)
12 pyplot.show()
C:\Users\ggg\Anaconda3\lib\site-packages\pandas\core\groupby.py in __getattr__(self, attr)
546 return self[attr]
547 if hasattr(self.obj, attr)
–> 548 return self._make_wrapper(attr)
549
550 raise AttributeError(“%r object has no attribute %r” %
C:\Users\ggg\Anaconda3\lib\site-packages\pandas\core\groupby.py in _make_wrapper(self, name)
560 “using the ‘apply’ method”.format(kind, name,
561 type(self).__name__))
–> 562 raise AttributeError(msg)
563
564 # need to setup the selection
AttributeError: Cannot access attribute ‘values’ of ‘DataFrameGroupBy’ objects, try using the ‘apply’ method
如何绘制周和月的多个折线图而不是年?
我很抱歉听到这个,你的 Pandas 库是最新的吗?
非常感谢提供这些内容。
我想为 30 年期间的温度创建热力图(不考虑闰年)。
我一直收到以下错误
TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of ‘Int64Index’
其中
File “C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\resample.py”, line 1085, in _get_resampler
“but got an instance of %r” % type(ax).__name__)
你能帮我通过这个错误来创建图表吗?
约翰
我没见过这个错误。也许你可以尝试将你的所有代码和数据发布到 stackoverflow?
你好!
这篇帖子非常有帮助。谢谢。但是,我未能根据我的需求进行调整。我有一个数据帧,运行了 6 年,频率为半小时。我想为所有年份的每个月制作一个箱形图……并在同一张图上显示它。
您能对此提供建议吗?
谢谢
SBB
帖子中的示例将为您提供一个有用的起点。抱歉,我无法为您编写代码。
你好,
我想问一下,如果我的数据中有一系列零(在你的例子中,假设温度在某些时候变为零),那么如何每周或每月绘制零的计数。
您可以使用 Pandas 库和 Grouper
https://pandas.ac.cn/pandas-docs/stable/generated/pandas.Grouper.html
感谢分享 Python 课程的描述性信息。这对我非常有帮助,因为我正在接受 Python 培训。继续做好这项工作,如果您有兴趣了解更多关于 Python 的信息,请查看这个 Python 教程。https://www.youtube.com/watch?v=XmfgjNoY9PQ
感谢分享。
无法绘制多线图。
这是添加 grouper 后的代码:
代码
df= read_csv(‘D:\\daily-minimum-temperatures.csv’,header=0)
groups = df.groupby(Grouper(key=’Date’))
years = DataFrame()
for n, g in groups
years[n.year] = g.values
years.boxplot()
pyplot.show()
你能评论一下哪里需要纠正吗?
你到底遇到了什么问题?
你好,谢谢分享这个惊人的教程😉
我刚开始探索数据科学,特别是时间序列探索。当尝试运行您的代码并使用我的数据集时,我在尝试绘制我的序列时遇到了这个错误
“ValueError: view limit minimum -36850.1 is less than 1 and is an invalid Matplotlib date value. This often happens if you pass a non-datetime value to an axis that has datetime units”
我的代码(不含绘图)
series = Data[[‘date_mesure’,’valeur_mesure’]]
print(series.head())
series.info()
print(series.describe())
带绘图的代码
series.plot()
plt.show()
我的数据信息
***********测试时间序列图***********
date_mesure valeur_mesure
0 2011-01-07 1.6
1 2011-01-12 4.0
2 2011-01-13 0.9
3 2011-01-17 100.0
4 2011-01-18 10.0
RangeIndex: 999 entries, 0 to 998
Data columns (total 2 columns)
date_mesure 999 non-null datetime64[ns]
valeur_mesure 999 non-null float64
dtypes: datetime64[ns](1), float64(1)
memory usage: 15.7 KB
valeur_mesure
count 999.000000
mean 16.516672
std 40.553837
min 0.000000
25% 1.000000
50% 3.000000
75% 10.000000
max 500.000000
日期类型是错误的原因吗?
我有一些建议可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
代码需要更新为最新的 Panda
谢谢。
嗨,Jason,
一如既往,感谢分享如此精彩的工作!它非常有帮助。
我用洗发水数据集做了同样的事情
https://datamarket.com/data/set/22r0/sales-of-shampoo-over-a-three-year-period#!ds=22r0&display=line
但是,我有一个关于“滞后部分:5.时间序列滞后散点图”的评论,你提到了 t+1-vs t-1, t+1-vs t-2 … t+1vs t-7 而不是 t vs t-1,t vs t-2,…t vs t-7,这是正确的吗?我是否错过了什么?
再次感谢,
Reda
是的,这是所选符号的问题。
感谢 Jason 的快速回复。
嗨,Jason,
在让多图工作方面遇到麻烦
from pandas import Series
from pandas import DataFrame
from pandas import TimeGrouper
from matplotlib import pyplot
series = Series.from_csv(‘daily-minimum-temperatures.csv’, header=0)
#series.index = pd.to_datetime(series.index, unit=’D’)
groups = series.groupby(TimeGrouper(‘A’))
错误
TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of ‘Index’.
我整个上午都在谷歌搜索,但不知道如何解决。
附注
Pandas 版本
pd.__version__
u’0.18.0′
非常感谢,
Gary
也许更新 Pandas?
试试 0.23.4
抱歉!典型的情况——我一发布问题就解决了…
我的数据中不知何故有一行空白。它发生在cleaned out the question marks 的地方。我删除了空白,它就工作了。
谢谢,
Gary
很高兴听到这个消息。
您好。感谢您发布此博客。这非常有帮助。我遇到了以下关于 groups 的 for 循环的问题。我的 pandas 版本是 0.23.4。我确实收到有关 Series 和 TimeGrouper 被弃用的警告,并且我忽略了它们。但是这段代码,特别是将值分配给 years[] 的那一行会引发错误
ValueError: Length of values does not match length of index
我的序列没问题,因为我能够绘制前面的折线图或散点图。您能提供建议吗?按时间段分组是我希望在其他地方使用我的数据的关键功能。
也许可以确认一下数据中的日期时间是否已正确解析?
也许对 Milind 来说太晚了,但也许有人会遇到这个问题。我遇到了相同或非常相似的问题。在我看来,问题在于 for 循环中的赋值要求 group.values 列表对于每一年都具有相同的长度。我的数据是从 1994 年年中开始,到 2019 年年中结束。所以对于这两年,我没有完整的记录数。我通过排除我的时间序列(ts)的第一年和最后一年来解决了这个问题,如下所示
firstyear = str(ts.index.year[1])lastyear = str(ts.index.year[-2])
groups = ts[firstyear:lastyear].groupby(pd.Grouper(freq='A'))
years = pd.DataFrame()
for name, group in groups:
#print(f'name: {name}\tgroup: {group.values}')
years[name.year] = group.values
如果问题与 boxplot() 相关,可以使用 seaborn 版本进行轻松修复,它包含了即时分组的功能
import seabornseaborn.boxplot(series.index.year, series)
plt.show()
简单。而且看起来更好。
很好,谢谢分享!
您的帖子对我帮助很大。我遇到了同样的问题,并通过添加 NaN 到缺失值来解决了。
您好。
非常感谢您的精彩工作!这对于学习 Python 和进行时间序列分析非常有帮助。
我只想留下一个小的说明
看起来应该使用 read_csv(),因为我的环境给了我反馈
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\series.py:3727: FutureWarning: from_csv is deprecated. Please use read_csv(…) instead. Note that some of the default arguments are different, so please refer to the documentation for from_csv when changing your function calls
再次感谢!
谢谢。
你好 Jason,当我执行:years[name.year]=group.values 时,我得到一个错误:Cannot set a frame with no defined index and a value that cannot be converted to a Series
我通过 group.values.tolist() 解决了这个问题
但是当我执行 years.plot() 时
我得到一个错误,Empty ‘DataFrame’: no numeric data to plot site。
我在网上查找,并使用了 years.astype(‘float’),
但是我又得到了一个错误,“setting an array element with a sequence。”,哈哈,你能告诉我怎么解决吗?
您能否确认您使用了相同的数据集并正确加载了它?
您能否确认您的 Pandas 版本是最新的?
并非所有数据问题都会说具有典型的日期时间可以被视为时间序列,除非我们看到有实际时间依赖性的逻辑。
当然可以。
我们如何解决一个问题,其中通常在一个银行的存款每年被视为一个特征,并且做出了对下一年进行预测的预测,在我们有连续 5 年存款的情况下,并且我们必须预测第 6 年的存款,包括将日期时间作为一个特征以及位置详细信息(通常是州、城市和县),我们如何解决这样的时间序列问题,我们是否仍然可以依赖 OLS 方法,如果不行,我们如何确保像州、县和城市信息以及存款年份等列添加了可观的方差?
也许可以原型化一系列问题的框架,并在每个框架上测试一系列方法,看看在您的特定数据集上效果如何?
精彩的文章,感谢所有帮助……这让像我们这样的新手入门!
请继续做好工作!!
Sarang。
很高兴它有帮助。
df = pd.read_csv(‘daily-minimum-temperatures-in-me.csv’)
df.head()[‘Date’]
——————————————-
0 1981-01-01
1 1981-01-02
2 1981-01-03
3 1981-01-04
4 1981-01-05
Name: Date, dtype: object
Date 的数据类型是 object。因此,它无法在其中一个轴上带有日期进行绘图。
您能否帮忙……?
可能是 DateTime。
嗨,Jason!
您的博客一如既往地提供帮助,请继续!
我尝试了我的数据上的 1)时间序列折线图代码,并且工作正常,只是它将我的负值绘制为 0。实际值是 -20,但它被绘制为 0。请问为什么?Matplotlib 不能绘制负值吗?有什么解决方案吗?
我的代码
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
%matplotlib inline
data = pd.read_csv(‘r6.csv’)
data.head()
data.dtypes
from datetime import datetime
con=data[‘Time’]
data[‘Time’]=pd.to_datetime(data[‘Time’])
data.set_index(‘Time’, inplace=True)
#检查索引的数据类型
data.index
#转换为时间序列
ts = data[‘Reading’]
ts [:’2018-01-06′]
plt.plot(ts)
另外,我的数据记录为几毫秒,如下所示;
2018-01-06 00:00:00 -22.277270
2018-01-06 00:00:00 -23.437500
2018-01-06 00:00:00 -23.254395
2018-01-06 00:00:00 -23.071290
2018-01-06 00:00:00 -22.888185
2018-01-06 00:00:00 -22.705080
2018-01-06 00:00:00 -22.521975
2018-01-06 00:00:00 -22.338870
2018-01-06 00:00:00 -22.155765
2018-01-06 00:01:00 -21.972660
2018-01-06 00:01:00 -23.437500
2018-01-06 00:01:00 -21.972660
2018-01-06 00:01:00 -21.606448
2018-01-06 00:01:00 -21.240235
有办法按分钟/小时绘制它吗,因为它已经按天绘制了。
非常感谢!
Matplotlib 可以绘制负值。
是的,您可以按任意时间分辨率进行绘制。
您的书有葡萄牙语版本吗?
抱歉,没有,只有英语。
嗨,Jason,
非常感谢这个有用的教程!
不幸的是,我遇到了和Milind一样的错误,并且找不到原因。
下载数据并删除页脚和包含(W10, notepad++)的每一行后,我得到了错误
…
File “C:\Program Files\Python36\lib\site-packages\pandas\core\internals\construction.py”, line 519, in sanitize_index
raise ValueError(‘Length of values does not match length of index’)
由>groups = series.groupby(TimeGrouper(‘A’))< 语句抛出。
我用正则表达式检查了每一行,结果表明数据文件中的每一行都符合以下格式:
"yyyy-mm-dd",float
.
Python 3.6.6
pandas 0.24.2
笔误
… 下载数据并删除页脚和包含‘?’(在W10, notepad++下)的每一行后,我得到了错误
…
听到这个消息我很难过。
您能确认您下载的是数据集的CVS版本吗?
您能确认数据集已正确加载为序列吗?
Jason,感谢您的回复!
您问题的答案是
您能确认您下载的是数据集的CVS版本吗?
=> 是的,我下载了。没有问号,没有页脚。
您能确认数据集已正确加载为序列吗?
=> 是的。我认为是的——因为“Minimum Daily Temperature Line Plot”和“Minimum Daily Temperature Dot Plot”运行正常——我希望这能证明我的确认。
…
顺便说一下;在执行两个绘图示例时会发出一个警告
“FutureWarning: from_csv已弃用。请使用read_csv(…)代替。请注意,一些默认参数是不同的,因此在更改函数调用时请参考from_csv的文档infer_datetime_format=infer_datetime_format)”
…
运行10行绘图示例时,此警告再次出现,随后又出现一个
FutureWarning: pd.TimeGrouper已弃用并将被移除;请使用pd.Grouper(freq=…)引用以下行:>groups = series.groupby(TimeGrouper(‘A’))TimeGrouper(‘A’)< 因为我无法访问文档,特别是关于‘A’——参数。
希望这有帮助!
wm
另外一个顺便说一下
DataMarket网站声明:“2015年4月15日之后,DataMarket.com将不再可用”。
谢谢。
Series.from_csv()似乎已弃用,并建议使用read_csv()代替。 https://pandas.ac.cn/pandas-docs/version/0.23.4/generated/pandas.Series.from_csv.html
谢谢Elizabeth。
非常全面的可视化!
为了避免一些错误,需要对代码进行一些小的修改——根据我自己的经验,至少在Python 2.7下直接运行这些代码是这样的
将.csv文件名替换为daily-min-temperatures.csv,因为这是当前可下载的实际文件名
from pandas.tools.plotting import lag_plot应写为
pandas.plotting import lag_plot,以便在Python 2.7下工作
适用于Pandas版本0.25
请参阅文档引用
https://pandas.ac.cn/pandas-docs/stable/reference/api/pandas.plotting.lag_plot.html
感谢分享。
最好将所有Pandas调用重写为最新版本和Python 3.X,因为许多已弃用,而且到2021年所有Python 2.7支持都将停止,至少根据我看到的一个消息是这样的。
大家好,我遇到了错误。我使用了以下代码……(Pandas版本‘0.24.2’)
series = read_csv(testroot + ‘daily-min-temperatures.csv’, header=0, index_col=0, parse_dates=[‘Date’])
years = DataFrame()
groups = series.groupby(Grouper(freq=’A’))
for name, group in groups
years[name.year] = [i[0] for i in group.values]
很遗憾听到这个消息,您遇到了什么错误?
Jason您好,这是一篇非常有信息、非常有帮助的文章。我非常感谢。谢谢。
我同意Nadine的说法。我遇到了两个错误,这两个错误通过Nadine的方法(或如下的另一种方法)解决了。Pandas版本‘0.25.1’,numpy版本‘1.17.1’。
问题1. read_csv未显式指定parse_dates=[‘Date’]会导致错误
TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of ‘Index’
解决方案1.1. read_csv并显式指定parse_dates=[‘Date’]
series = read_csv(‘daily-minimum-temperatures.csv’, header=0, index_col=0, parse_dates=[‘Date’])
解决方案1.2. 或者,以下方法也可以。
import pandas as pd
series = pd.read_csv(‘daily-minimum-temperatures.csv’, header=0, index_col=0)
series.index = pd.to_datetime(series.index)
#参见 https://stackoverflow.com/questions/48272540/pandas-typeerror-only-valid-with-datetimeindex-timedeltaindex-or-periodindex?rq=1
问题2. years[name.year] = group.values 会导致错误 Exception: Data must be 1-dimensional
解决方案2.1. years[name.year] = [i[0] for i in group.values]
解决方案2.2. years[name.year] = np.asarray(group[‘Temp’])
import numpy as np
for name, group in groups
years[name.year] = np.asarray(group[‘Temp’])
谢谢,我已经更新并测试了所有示例。
这太棒了,谢谢!我学到了很多。
我知道这是一篇旧文章,但只想指出我不得不使用
“from pandas.plotting import autocorrelation_plot”
来绘制自相关图。只是想留下这个笔记,以防其他用户遇到同样的麻烦。
再次感谢教程!
谢谢。
是的,所有示例现已更新为使用最新的API。
你好,我有一个问题,
如何在python中制作像这样的历史图?
https://www.google.com/url?sa=i&source=images&cd=&ved=2ahUKEwi-_4SJpN_kAhWG4YUKHfrmBcUQjRx6BAgBEAQ&url=https%3A%2F%2Fhome-assistant-china.github.io%2Fblog%2Fposts%2F14%2F&psig=AOvVaw1oYsnnrKNHm8rArsfoA-S6&ust=1569064779779612
我只想显示随时间变化的二进制值(0/1)。
提前感谢,
链接不起作用。
您可以使用matplotlib和plot()函数在Python中进行绘图,并将数据传递进去。
这有帮助吗?
当应用于绘制您使用的数据集的热力图时,出现了以下错误?
raise TypeError(“Image data cannot be converted to float”)
TypeError: Image data cannot be converted to float
很抱歉听到这个消息,我可以确认示例仍然运行正常。
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我认为数据集中有问题。我按照您的所有建议做了。
日期
1981+AC0-01+AC0-01 20.7
1981+AC0-01+AC0-02 17.9
1981+AC0-01+AC0-03 18.8
1981+AC0-01+AC0-04 14.6
1981+AC0-01+AC0-05 15.8
Name: temp, dtype: object
数据类型是object?
哇,你的代码有问题!
也许确认你的statsmodels是最新的?
也许检查一下数据文件的内容?
它应该看起来像
lag_plot是x轴上的y(t)和y轴上的y(t+1)……你说y轴上是t-1,这是不正确的。
一个滞后图是时间对滞后时间,所以滞后时间不在y轴上。
它是y(t+1)对y(t)……也可以写成y(t)对y(t-1)
本质上,它是年度数据对上一年的年度数据
谢谢。
你好,Jason。
感谢这个很棒的教程。请帮我解决这个错误。我无法绘制箱须图。我不知道该怎么办。
数据集是“shampoo-sales.csv”
series = read_csv(‘shampoo-sales.csv’, header=0, index_col=0, parse_dates=True, squeeze=True)
print(series.head())
月份
1-01 266.0
1-02 145.9
1-03 183.1
1-04 119.3
1-05 180.3
名称:销售额,数据类型:float64
groups = series.groupby(Grouper(freq=’M’))
TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of ‘Index’
谢谢你的帮助。
此致
JulianL
很抱歉听到这个消息,也许这个会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
尊敬的Jason博士,
我正在尝试使用pyplot。这与x值的大小有关。x值是dd-mm-yy格式的日期。
问题是,当我绘制数据时,x轴与刻度线不对齐。
以下是为说明问题而构造的数据。
然后我们想绘制数据
当我绘制这个时,x值日期会拥挤,文本与刻度线不对齐。
有没有办法将x值与正确的刻度线对齐?
谢谢你,
悉尼的Anthony
是的,不过您可能需要自己调试绘图。
尊敬的Jason博士,
看来使用pd.DataFrame进行操作可能不是必需的。
一个解决标签与刻度线对齐问题的变通方法是这样的。
谢谢你,
悉尼的Anthony
感谢分享。
我遇到了一些关于不完整年份或闰年的问题——我在StackOverflow上问过,并得到了有用的解决方案
https://stackoverflow.com/questions/61110223/pandas-groupby-with-leap-year-fails
groups = df.groupby(df.index.year)
years = pd.concat([pd.Series(x.values.flatten(), name=y)
for y,x in groups],
axis=1)
years.plot(subplots=True, legend=False)
plt.show()
如果您指的是不连续的数据,这也许会有帮助
https://machinelearning.org.cn/faq/single-faq/how-do-i-handle-discontiguous-time-series-data
感谢Jason的教程。一旦我想用Matplotlib进一步探索数据,它确实……挑战我。您能推荐一些非基于浏览器的替代方案吗?我喜欢Bokeh,但对于数据探索和模型构建,我希望能在Spyder内使用工具,而不是输出到浏览器。
Matplotlib不是基于浏览器的。
我相信您可以在IDE中直接显示绘图,我不用IDE,抱歉。
嗨
几个问题
1) 如何导出自相关图中所绘制的数据点?
2) 在第6节的自相关图中,滞后730(2年)的自相关约为0.4,但如果我手动计算,我会得到高于0.5的数字,如下所示
dataframe3 = concat([values.shift(730), values], axis=1)
dataframe3.columns = [‘t’, ‘t730’]
result = dataframe3.corr()
print(result)
t t730
t 1.000000 0.515314
t730 0.515314 1.000000
这些差异如何解释?
也许您可以手动计算相关性并保存结果?
也许这两个库的计算得分方式不同,或者对得分的归一化方式不同。
有道理。有什么方法可以导出自相关图本身的数据点到数据框中以供进一步检查吗?
暂时没有,我建议您查看API。
这些数据缺少闰年的日期,以调整天数。这主要影响按年堆叠的图。
是否有可能在不排除任何数据的情况下,进行闰年堆叠图?
是的,尽管我认为您需要手动准备数据。