时间序列预测是一个过程,要想获得良好的预测,唯一的方法就是实践这个过程。
在本教程中,您将学习如何使用Python预测波士顿月度武装抢劫案的数量。
完成本教程将为您提供一个框架,用于处理您自己的时间序列预测问题,并掌握相应的步骤和工具。
完成本教程后,您将了解:
- 如何检查您的Python环境并仔细定义时间序列预测问题。
- 如何创建评估模型的测试平台,开发一个基准预测,并通过时间序列分析工具更好地理解您的问题。
- 如何开发一个自回归积分移动平均模型,将其保存到文件,并在以后加载它以对新的时间步长进行预测。
通过我的新书 《Python时间序列预测入门》 启动您的项目,书中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 更新于2018年7月:修复了ACF/PACF图准备中的一个拼写错误(感谢Patrick Wolf)。
- 2019 年 4 月更新:更新了数据集链接。
- 2019年8月更新:更新了数据加载以使用新的API。
- 更新于2020年2月:更新了to_csv()以消除警告。
- **2020 年 12 月更新**:针对 API 更改更新了建模。

Python时间序列预测案例研究——波士顿月度武装抢劫案
摄影:Tim Sackton,部分权利保留。
概述
在本教程中,我们将端到端地完成一个时间序列预测项目,从下载数据集和定义问题到训练最终模型和进行预测。
这个项目并非详尽无遗,但它展示了如何通过系统地解决一个时间序列预测问题来快速获得良好结果。
我们将要完成的本项目的步骤如下:
- 环境。
- 问题描述。
- 测试平台。
- 持久性。
- 数据分析。
- ARIMA模型
- 模型验证
这将为解决时间序列预测问题提供一个模板,您可以将其用于您自己的数据集。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
1. 环境
本教程假定已安装并运行SciPy环境及相关依赖项,包括:
- SciPy
- NumPy
- Matplotlib
- Pandas
- scikit-learn
- statsmodels
我使用的是Python 2.7。您使用的是Python 3吗?请在评论区告诉我您的经验。
此脚本将帮助您检查这些库的已安装版本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 检查关键Python库的版本 # scipy import scipy print('scipy: %s' % scipy.__version__) # numpy import numpy print('numpy: %s' % numpy.__version__) # matplotlib import matplotlib print('matplotlib: %s' % matplotlib.__version__) # pandas import pandas print('pandas: %s' % pandas.__version__) # statsmodels import statsmodels print('statsmodels: %s' % statsmodels.__version__) # scikit-learn import sklearn print('sklearn: %s' % sklearn.__version__) |
在编写本教程的工作站上,我的结果如下:
|
1 2 3 4 5 6 |
scipy: 1.5.4 numpy: 1.18.5 matplotlib: 3.3.3 pandas: 1.1.4 statsmodels: 0.12.1 sklearn: 0.23.2 |
2. 问题描述
问题是预测美国波士顿月度武装抢劫案的数量。
该数据集提供了1966年1月至1975年10月,即不到10年的波士顿月度武装抢劫案数量。
数值为计数,有118个观测值。
该数据集归功于McCleary & Hay (1980)。
下载数据集为CSV文件,并将其放入当前工作目录,文件名为“robberies.csv”。
3. 测试平台
我们必须开发一个测试平台来研究数据和评估候选模型。
这涉及两个步骤
- 定义验证数据集。
- 开发模型评估方法。
3.1 验证数据集
该数据集不是最新的。这意味着我们无法轻易收集更新的数据来验证模型。
因此,我们将假装是1974年10月,并将最后一年的数据保留起来用于分析和模型选择。
最后一年数据将用于验证最终模型。
下面的代码将加载数据集为一个Pandas Series,并将其分为两部分:一部分用于模型开发(dataset.csv),另一部分用于验证(validation.csv)。
|
1 2 3 4 5 6 7 |
from pandas import read_csv series = read_csv('robberies.csv', header=0, index_col=0) split_point = len(series) - 12 dataset, validation = series[0:split_point], series[split_point:] print('Dataset %d, Validation %d' % (len(dataset), len(validation))) dataset.to_csv('dataset.csv'<span class="crayon-sy">,</span> <span class="crayon-v">index</span><span class="crayon-o">=</span><span class="crayon-t">False, header=False</span>) validation.to_csv('validation.csv'<span class="crayon-sy">,</span> <span class="crayon-v">index</span><span class="crayon-o">=</span><span class="crayon-t">False, header=False</span>) |
运行该示例会创建两个文件,并打印出每个文件中的观测数量。
|
1 |
数据集 106,验证集 12 |
这些文件的具体内容是:
- dataset.csv:从1966年1月到1974年10月的观测值(106个观测值)
- validation.csv:从1974年11月到1975年10月的观测值(12个观测值)
验证数据集占原始数据集的10%。
请注意,保存的数据集不包含标题行,因此我们以后在处理这些文件时无需考虑这一点。
3.2. 模型评估
模型评估仅在上一节准备的dataset.csv文件中进行。
模型评估包括两个要素:
- 性能度量。
- 测试策略。
3.2.1 性能度量
观测值是抢劫案的数量。
我们将使用均方根误差(RMSE)来评估预测的性能。这将为严重错误的预测提供更高的权重,并且其单位与原始数据相同。
在计算和报告RMSE之前,必须撤销对数据进行的任何转换,以便不同方法之间的性能可以直接进行比较。
我们可以使用scikit-learn库中的帮助函数mean_squared_error()来计算RMSE,该函数计算预期值列表(测试集)和预测值列表之间的平均平方误差。然后,我们可以取该值的平方根,得到RMSE分数。
例如
|
1 2 3 4 5 6 7 8 |
from sklearn.metrics import mean_squared_error from math import sqrt ... test = ... predictions = ... mse = mean_squared_error(test, predictions) rmse = sqrt(mse) print('RMSE: %.3f' % rmse) |
3.2.2 测试策略
候选模型将使用前向验证进行评估。
这是因为问题定义要求使用滚动预测类型的模型。在这种情况下,需要根据所有可用数据进行一步预测。
前向验证将按以下方式工作:
- 数据集的前50%将保留用于训练模型。
- 剩余50%的数据集将被迭代并用于测试模型。
- 对于测试数据集中的每一步:
- 将训练一个模型。
- 进行一步预测,并将预测存储起来以供以后评估。
- 测试数据集中实际的观测值将在下一次迭代中添加到训练数据集中。
- 在测试数据集迭代过程中进行的预测将被评估,并报告RMSE分数。
鉴于数据量较小,我们将允许模型在每次预测之前使用所有可用数据进行重新训练。
我们可以使用简单的NumPy和Python代码来编写测试平台的代码。
首先,我们可以直接将数据集分割成训练集和测试集。我们小心地将加载的数据集始终转换为float32,以防加载的数据仍然具有某些字符串或整数数据类型。
|
1 2 3 4 5 |
# 准备数据 X = series.values X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] |
接下来,我们可以迭代测试数据集中的时间步长。训练数据集存储在Python列表中,因为我们需要在每次迭代中轻松地追加一个新观测值,而NumPy数组拼接感觉有些过度。
模型进行的预测根据惯例称为yhat,因为结果或观测值被称为y,而yhat(一个带有标记的“y”)是变量y预测的数学表示。
每次观测值都会打印预测值和观测值,以便在模型存在问题时进行健全性检查预测。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 步进验证 history = [x for x in train] predictions = list() for i in range(len(test)): # 预测 yhat = ... predictions.append(yhat) # 观测 obs = test[i] history.append(obs) print('>Predicted=%.3f, Expected=%3.f' % (yhat, obs)) |
4. 持久性
在深入进行数据分析和建模之前,第一步是建立一个性能基准。
这将为使用提出的测试平台评估模型提供一个模板,并为所有更复杂的预测模型提供一个性能比较基准。
时间序列预测的基准预测称为朴素预测,或持久性预测。
这是将前一个时间步长的观测值用作下一个时间步长观测值的预测。
我们可以将其直接插入上一节定义的测试平台。
完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from pandas import read_csv from sklearn.metrics import mean_squared_error from math import sqrt # 加载数据 series = read_csv('dataset.csv') # 准备数据 X = series.values X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] # 步进验证 history = [x for x in train] predictions = list() for i in range(len(test)): # 预测 yhat = history[-1] predictions.append(yhat) # 观测 obs = test[i] history.append(obs) print('>Predicted=%.3f, Expected=%3.f' % (yhat, obs)) # 报告表现 mse = mean_squared_error(test, predictions) rmse = sqrt(mse) print('RMSE: %.3f' % rmse) |
运行测试平台会打印测试数据集每次迭代的预测值和观测值。
示例最后会打印模型的RMSE。
在这种情况下,我们可以看到持久性模型达到了51.844的RMSE。这意味着平均而言,该模型在每次预测时都偏离了大约51个抢劫案。
|
1 2 3 4 5 6 7 |
... >预测值=241.000, 实际值=287 >预测值=287.000, 实际值=355 >预测值=355.000, 实际值=460 >预测值=460.000, 实际值=364 >预测值=364.000, 实际值=487 RMSE: 51.844 |
我们现在有了基准预测方法和性能;现在我们可以开始深入挖掘我们的数据了。
5. 数据分析
我们可以使用汇总统计数据和数据图表来快速了解预测问题的结构。
在本节中,我们将从四个角度审视数据:
- 汇总统计。
- 折线图。
- 密度图。
- 箱线图。
5.1 汇总统计。
在文本编辑器中打开数据dataset.csv文件或原始robberies.csv文件,查看数据。
快速检查表明没有明显的缺失观测值。如果我们尝试强制将值转换为浮点数,并且数据中存在NaN或“?”之类的值,我们可能早就注意到了。
汇总统计数据可以快速了解观测值的范围。它可以帮助我们快速了解我们正在处理的数据。
下面的示例计算并打印时间序列的汇总统计数据。
|
1 2 3 |
from pandas import read_csv series = read_csv('dataset.csv') print(series.describe()) |
运行该示例会提供一系列汇总统计数据供您查看。
从这些统计数据中可以观察到:
- 观测数量(count)与我们的预期相符,这意味着我们正确地处理了数据。
- 平均值约为173,我们可以将其视为该序列的水平。
- 标准差(平均值与均值的偏差)相对较大,为112起抢劫案。
- 百分位数以及标准差确实表明数据的范围很大。
|
1 2 3 4 5 6 7 8 |
count 106.000000 mean 173.103774 std 112.231133 min 29.000000 25% 74.750000 50% 144.500000 75% 271.750000 max 487.000000 |
如果这种大的数据范围是由于随机波动(例如非系统性)引起的,那么要实现非常准确的预测可能会很困难。
5.2 折线图
时间序列的折线图可以为问题提供很多见解。
下面的示例创建并显示了数据集的折线图。
|
1 2 3 4 5 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('dataset.csv') series.plot() pyplot.show() |
运行示例并查看图表。注意序列中任何明显的时序结构。
从图表中可以观察到:
- 随着时间的推移,抢劫案有增加的趋势。
- 似乎没有明显的异常值。
- 年复一年的波动相对较大,有升有降。
- 后期年份的波动似乎比早期年份的波动更大。
- 这种趋势意味着数据集几乎肯定是非平稳的,而波动的变化也可能加剧这种情况。
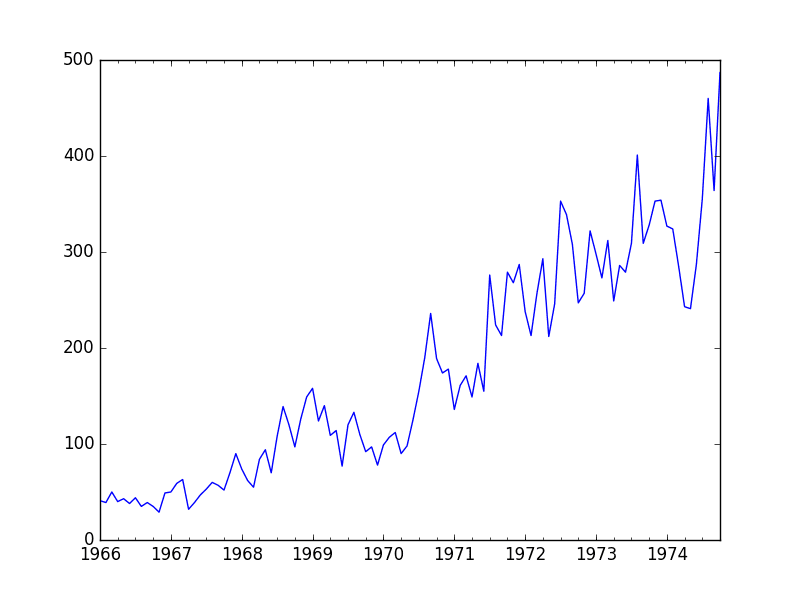
波士顿月度抢劫案折线图
这些简单的观察表明,我们可能会从对趋势进行建模并从中移除时间序列中获益。
或者,我们可以使用差分使序列平稳以便建模。如果后期年份的波动存在增长趋势,我们甚至可能需要进行两级差分。
5.3 密度图
审视观测值密度图可以为数据结构提供进一步的见解。
下面的示例创建了观测值的直方图和密度图,而不考虑任何时间结构。
|
1 2 3 4 5 6 7 8 9 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('dataset.csv') pyplot.figure(1) pyplot.子图(211) series.hist() pyplot.子图(212) series.plot(kind='kde') pyplot.show() |
运行示例并查看图表。
从图表中可以观察到:
- 分布不是高斯分布。
- 分布是左偏的,可能是指数分布或双高斯分布。
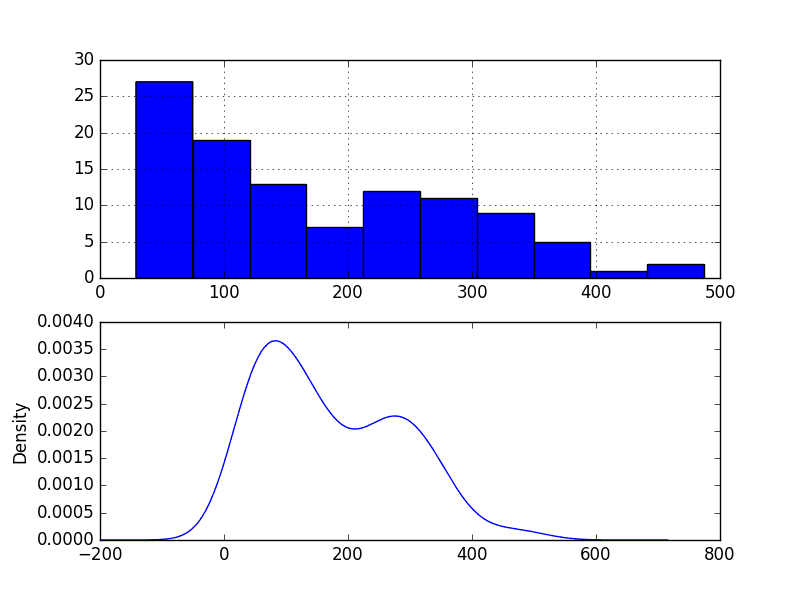
波士顿月度抢劫案密度图
我们可能会从在建模之前探索数据的某些幂变换中获益。
5.4 箱线图
我们可以按年份对月度数据进行分组,并了解每年的观测值范围以及这种范围如何变化。
我们预计会看到一些趋势(均值或中位数增加),但查看分布的其余部分如何变化可能会很有趣。
下面的示例按年份对观测值进行分组,并为每年的观测值创建一个箱线图。最后一年(1974年)只有10个月,可能与其他年份的12个月观测值没有可比性。因此,只绘制了1966年至1973年的数据。
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import read_csv from pandas import DataFrame from pandas import Grouper from matplotlib import pyplot series = read_csv('dataset.csv') groups = series['1966':'1973'].groupby(Grouper(freq='A')) years = DataFrame() for name, group in groups: years[name.year] = group.values years.boxplot() pyplot.show() |
运行该示例会创建8个并排的箱线图,每个图代表选定数据的8年中的一年。
从审查图表中可以观察到:
- 每年的中位数(红线)显示出可能不是线性的趋势。
- 数据的范围,或中间50%(蓝框),有所不同,但可能随时间不一致。
- 早期年份,可能前两年,与其余数据集有很大不同。
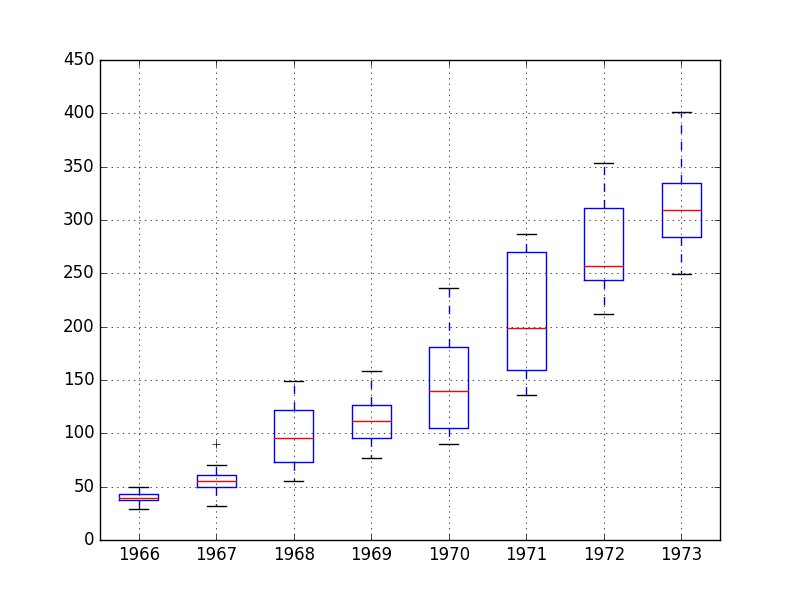
波士顿月度抢劫案箱线图
这些观察表明,年复一年的波动可能不是系统性的,难以建模。它们还表明,如果早期两年数据确实非常不同,那么在建模时可能需要将其剔除。
这种年度数据视图是一个有趣的途径,可以通过查看逐年的汇总统计数据以及年度汇总统计数据的变化来进一步深入研究。
接下来,我们可以开始研究该序列的预测模型。
6. ARIMA模型
在本节中,我们将为该问题开发自回归积分移动平均(ARIMA)模型。
我们将分四个步骤进行:
- 开发手动配置的ARIMA模型。
- 使用ARIMA网格搜索寻找优化模型。
- 分析预测残差误差以评估模型的任何偏差。
- 通过幂变换探索模型改进。
6.1 手动配置ARIMA
非季节性ARIMA(p,d,q)需要三个参数,并且传统上是手动配置的。
时间序列数据的分析假设我们处理的是平稳时间序列。
该时间序列几乎肯定是非平稳的。我们可以通过首先对序列进行差分并使用统计检验来确认结果是平稳的,从而使其平稳。
下面的示例创建了该序列的平稳版本,并将其保存到文件stationary.csv。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from pandas import read_csv from statsmodels.tsa.stattools import adfuller # 创建差分 def difference(dataset): diff = list() for i in range(1, len(dataset)): value = dataset[i] - dataset[i - 1] diff.append(value) return Series(diff) series = read_csv('dataset.csv') X = series.values # 差分数据 stationary = difference(X) stationary.index = series.index[1:] # 检查是否平稳 result = adfuller(stationary) print('ADF Statistic: %f' % result[0]) print('p-value: %f' % result[1]) print('Critical Values:') for key, value in result[4].items(): print('\t%s: %.3f' % (key, value)) # 保存 stationary.to_csv('stationary.csv'<span class="crayon-t">, header=False</span>) |
运行示例将输出一个统计显著性检验的结果,该检验用于确定序列是否是平稳的。具体来说,是增广迪基-福勒检验。
结果显示,检验统计量值为 -3.980946,小于 5% 临界值 -2.893。这表明我们可以在 5% 的显著性水平下拒绝原假设(即结果是统计巧合的概率很低)。
拒绝零假设意味着该过程没有单位根,进而意味着时间序列是平稳的或不具有时间相关结构。
|
1 2 3 4 5 6 |
ADF 统计量:-3.980946 p 值:0.001514 临界值 5%: -2.893 1%: -3.503 10%: -2.584 |
这表明至少需要一个差分阶数。我们 ARIMA 模型中的 *d* 参数至少应为 1。
下一步是为自回归(AR)和移动平均(MA)参数 p 和 q 选择滞后值。
我们可以通过查看自相关函数(ACF)和偏自相关函数(PACF)图来做到这一点。
下面的示例为序列生成了 ACF 和 PACF 图。
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import read_csv from statsmodels.graphics.tsaplots import plot_acf from statsmodels.graphics.tsaplots import plot_pacf from matplotlib import pyplot series = read_csv('stationary.csv') pyplot.figure() pyplot.子图(211) plot_acf(series, ax=pyplot.gca()) pyplot.子图(212) plot_pacf(series, ax=pyplot.gca()) pyplot.show() |
运行示例并查看图表,以了解如何为 ARIMA 模型设置 p 和 q 变量。
以下是图表中的一些观察结果。
- ACF 显示 1 个月有显著滞后。
- PACF 显示大约 2 个月有显著滞后,并且在长达大约 12 个月的时间里滞后点零星出现。
- ACF 和 PACF 都在同一点下降,这可能表明 AR 和 MA 的混合。
p 和 q 值的良好起点是 1 或 2。
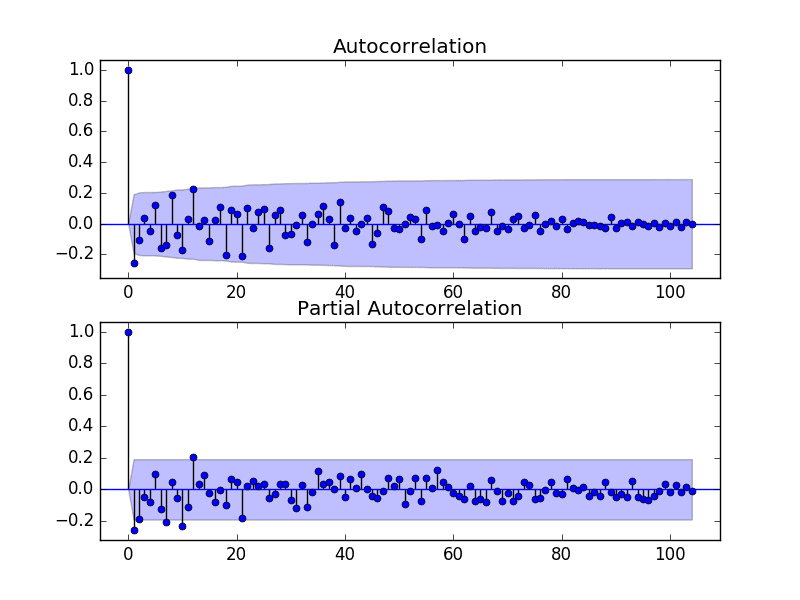
波士顿月度抢劫案 ACF 和 PACF 图
这个快速分析表明,在原始数据上使用 ARIMA(1,1,2) 可能是一个好的起点。
实验表明,这种 ARIMA 配置无法收敛,并导致底层库出现错误。一些实验表明,该模型似乎不稳定,同时定义了非零的 AR 和 MA 阶数。
该模型可以简化为 ARIMA(0,1,2)。下面的示例演示了此 ARIMA 模型在测试框架上的性能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 评估手动配置的 ARIMA 模型 from pandas import read_csv from sklearn.metrics import mean_squared_error from statsmodels.tsa.arima.model import ARIMA from math import sqrt # 加载数据 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 准备数据 X = series.values X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] # 步进验证 history = [x for x in train] predictions = list() for i in range(len(test)): # 预测 model = ARIMA(history, order=(0,1,2)) model_fit = model.fit() yhat = model_fit.forecast()[0] predictions.append(yhat) # 观测 obs = test[i] history.append(obs) print('>Predicted=%.3f, Expected=%.3f' % (yhat, obs)) # 报告表现 rmse = sqrt(mean_squared_error(test, predictions)) print('RMSE: %.3f' % rmse) |
运行此示例将产生 49.821 的 RMSE,这低于持久性模型。
|
1 2 3 4 5 6 7 |
... >Predicted=280.614, Expected=287 >Predicted=302.079, Expected=355 >Predicted=340.210, Expected=460 >Predicted=405.172, Expected=364 >Predicted=333.755, Expected=487 RMSE:49.821 |
这是一个好的开始,但我们可能可以通过更好的 ARIMA 模型配置来获得改进的结果。
6.2 网格搜索 ARIMA 超参数
许多 ARIMA 配置在此数据集上不稳定,但可能存在其他超参数可以产生性能良好的模型。
在本节中,我们将搜索 p、d 和 q 的值,找出不导致错误的组合,并找到产生最佳性能的组合。我们将使用网格搜索来探索子集整数值中的所有组合。
具体来说,我们将搜索以下参数的所有组合
- p:0 到 12。
- d:0 到 3。
- q:0 到 12。
这是 (13 * 4 * 13),即 676 次测试框架运行,在现代硬件上执行需要一些时间。
带有网格搜索版本测试框架的完整示例代码如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
# 时间序列的 ARIMA 参数网格搜索 import warnings from pandas import read_csv from statsmodels.tsa.arima.model import ARIMA from sklearn.metrics import mean_squared_error from math import sqrt # 评估给定阶数 (p,d,q) 的 ARIMA 模型,并返回 RMSE def evaluate_arima_model(X, arima_order): # 准备训练数据集 X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] history = [x for x in train] # 进行预测 predictions = list() for t in range(len(test)): model = ARIMA(history, order=arima_order) model_fit = model.fit() yhat = model_fit.forecast()[0] predictions.append(yhat) history.append(test[t]) # 计算样本外误差 rmse = sqrt(mean_squared_error(test, predictions)) return rmse # 评估 ARIMA 模型的 p、d 和 q 值组合 def evaluate_models(dataset, p_values, d_values, q_values): dataset = dataset.astype('float32') best_score, best_cfg = float("inf"), None for p in p_values: for d in d_values: for q in q_values: order = (p,d,q) try: rmse = evaluate_arima_model(dataset, order) if rmse < best_score: best_score, best_cfg = rmse, order print('ARIMA%s RMSE=%.3f' % (order,rmse)) except: continue print('Best ARIMA%s RMSE=%.3f' % (best_cfg, best_score)) # 加载数据集 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 评估参数 p_values = range(0,13) d_values = range(0, 4) q_values = range(0, 13) warnings.filterwarnings("ignore") evaluate_models(series.values, p_values, d_values, q_values) |
运行示例将遍历所有组合,并报告收敛且无错误的组合结果。
该示例在现代硬件上运行大约需要不到 2 个小时。
结果显示,发现的最佳配置是 ARIMA(0, 1, 2);巧合的是,这在上一节中已经演示过。
|
1 2 3 4 5 6 7 |
... ARIMA(6, 1, 0) MSE=52.437 ARIMA(6, 2, 0) MSE=58.307 ARIMA(7, 1, 0) MSE=51.104 ARIMA(7, 1, 1) MSE=52.340 ARIMA(8, 1, 0) MSE=51.759 最佳 ARIMA(0, 1, 2) MSE=49.821 |
6.3 检查残差误差
对模型进行良好最终检查是检查残差预测误差。
理想情况下,残差误差的分布应为零均值的正态分布。
我们可以通过绘制残差的直方图和密度图来检查这一点。
下面的示例计算测试集上的预测的残差误差,并创建这些密度图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# 绘制 ARIMA 模型的残差误差 from pandas import read_csv from pandas import DataFrame from statsmodels.tsa.arima.model import ARIMA from matplotlib import pyplot # 加载数据 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 准备数据 X = series.values X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] # 步进验证 history = [x for x in train] predictions = list() for i in range(len(test)): # 预测 model = ARIMA(history, order=(0,1,2)) model_fit = model.fit() yhat = model_fit.forecast()[0] predictions.append(yhat) # 观测 obs = test[i] history.append(obs) # 误差 residuals = [test[i]-predictions[i] for i in range(len(test))] residuals = DataFrame(residuals) pyplot.figure() pyplot.子图(211) residuals.hist(ax=pyplot.gca()) pyplot.子图(212) residuals.plot(kind='kde', ax=pyplot.gca()) pyplot.show() |
运行示例创建了两个图。
图表显示了类似正态的分布,但右尾较长。
这可能表明预测存在偏差,在这种情况下,在建模之前对原始数据进行基于幂的转换可能是有用的。
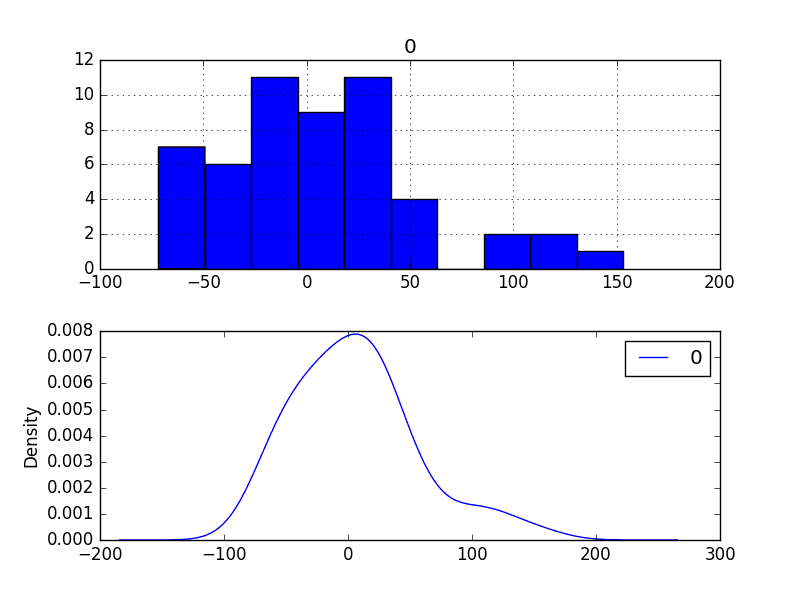
残差误差密度图
检查残差误差时间序列是否存在任何类型的自相关也是一个好主意。如果存在,则表明模型有更多机会对数据中的时间结构进行建模。
下面的示例重新计算残差误差,并创建 ACF 和 PACF 图以检查任何显著的自相关。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# 预测残差误差的 ACF 和 PACF 图 from pandas import read_csv from pandas import DataFrame from statsmodels.tsa.arima.model import ARIMA from statsmodels.graphics.tsaplots import plot_acf from statsmodels.graphics.tsaplots import plot_pacf from matplotlib import pyplot # 加载数据 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 准备数据 X = series.values X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] # 步进验证 history = [x for x in train] predictions = list() for i in range(len(test)): # 预测 model = ARIMA(history, order=(0,1,2)) model_fit = model.fit() yhat = model_fit.forecast()[0] predictions.append(yhat) # 观测 obs = test[i] history.append(obs) # 误差 residuals = [test[i]-predictions[i] for i in range(len(test))] residuals = DataFrame(residuals) pyplot.figure() pyplot.子图(211) plot_acf(residuals, lags=25, ax=pyplot.gca()) pyplot.子图(212) plot_pacf(residuals, lags=25, ax=pyplot.gca()) pyplot.show() |
结果表明,时间序列中存在的少量自相关已被模型捕获。
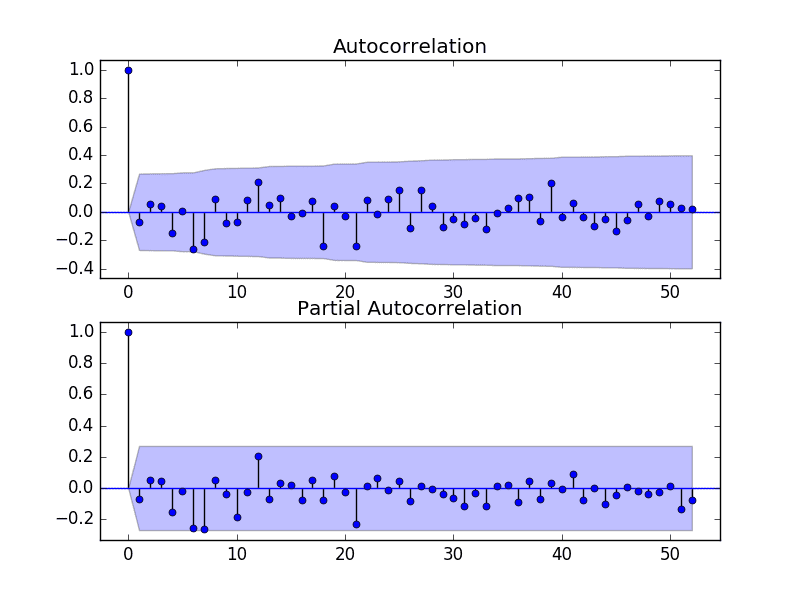
残差误差 ACF 和 PACF 图
6.4 Box-Cox 变换数据集
Box-Cox 变换是一种能够评估一系列幂变换的方法,包括但不限于对数据进行对数、平方根和倒数变换。
下面的示例执行对数据的对数变换,并生成一些图来查看对时间序列的影响。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from pandas import read_csv from pandas import DataFrame from scipy.stats import boxcox from matplotlib import pyplot from statsmodels.graphics.gofplots import qqplot series = read_csv('dataset.csv') X = series.values transformed, lam = boxcox(X) print('Lambda: %f' % lam) pyplot.figure(1) # 线图 pyplot.subplot(311) pyplot.plot(transformed) # 直方图 pyplot.subplot(312) pyplot.hist(transformed) # Q-Q 图 pyplot.subplot(313) qqplot(transformed, line='r', ax=pyplot.gca()) pyplot.show() |
运行示例将创建三个图:转换后的时间序列的折线图、显示转换后值分布的直方图以及显示值分布与理想高斯分布比较的 Q-Q 图。
这些图中的一些观察结果如下:
- 时间序列的折线图中已移除大幅波动。
- 直方图显示了更平坦或更均匀(表现良好)的值分布。
- Q-Q 图尚可,但仍未完全符合高斯分布。
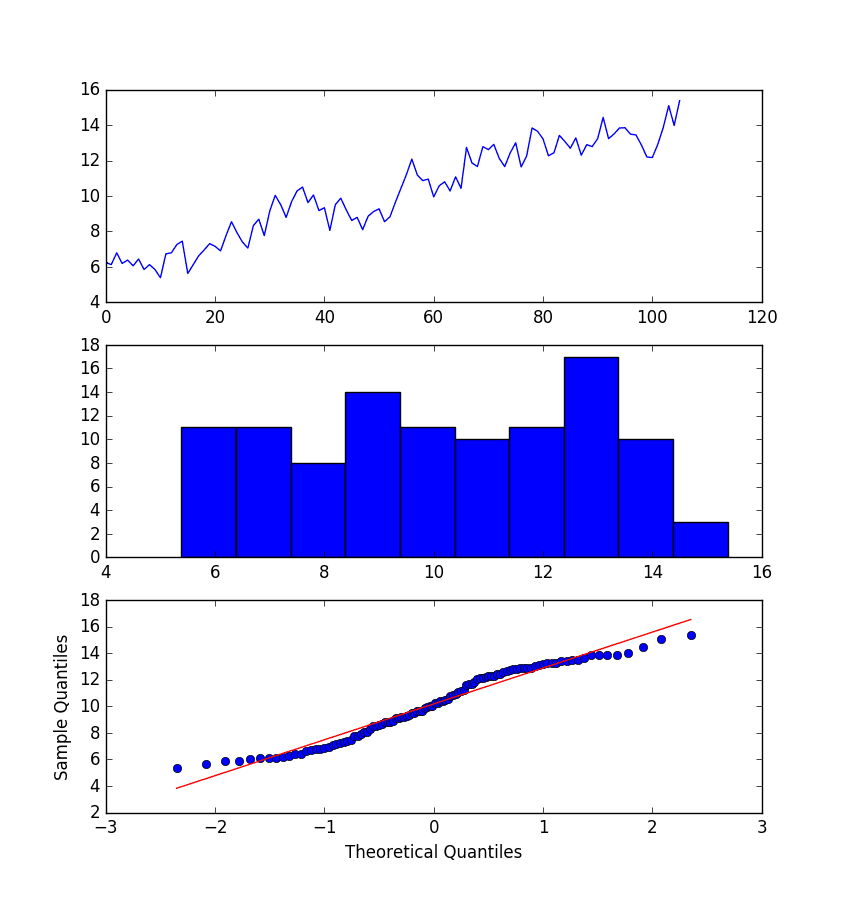
BoxCox 变换的月度波士顿抢劫案图
毫无疑问,Box-Cox 变换对时间序列产生了一定的影响,并且可能有用。
在继续使用变换后的数据测试 ARIMA 模型之前,我们必须有一种方法来反转变换,以便将使用在变换数据上训练的模型所做的预测转换回原始尺度。
示例中使用的 `boxcox()` 函数通过优化成本函数来查找理想的 lambda 值。
Lambda 用于以下函数来变换数据:
|
1 2 |
如果 lambda == 0,则 transform = log(x) 如果 lambda != 0,则 transform = (x^lambda - 1) / lambda |
此变换函数可以直接反转,如下所示:
|
1 2 |
如果 lambda == 0,则 x = exp(transform) x = exp(log(lambda * transform + 1) / lambda) |
此逆 Box-Cox 变换函数可以在 Python 中实现如下:
|
1 2 3 4 5 6 7 |
# 反转 box-cox 变换 from math import log from math import exp def boxcox_inverse(value, lam): if lam == 0: return exp(value) return exp(log(lam * value + 1) / lam) |
我们可以用 Box-Cox 变换重新评估 ARIMA(0,1,2) 模型。
这包括在拟合 ARIMA 模型之前先转换历史数据,然后对预测进行变换反转,再将其存储起来以便稍后与预期值进行比较。
`boxcox()` 函数可能会失败。在实践中,我遇到过这种情况,它似乎是通过返回小于 -5 的 lambda 值来指示的。按照惯例,lambda 值在 -5 到 5 之间进行评估。
会添加一个检查,以防 lambda 值小于 -5。如果发生这种情况,则假定 lambda 值为 1,并使用原始历史数据来拟合模型。lambda 值为 1 等同于“无变换”,因此逆变换不起作用。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
# 使用 box-cox 变换时间序列评估 ARIMA 模型 from pandas import read_csv from sklearn.metrics import mean_squared_error from statsmodels.tsa.arima.model import ARIMA from math import sqrt from math import log from math import exp from scipy.stats import boxcox # 反转 box-cox 变换 def boxcox_inverse(value, lam): if lam == 0: return exp(value) return exp(log(lam * value + 1) / lam) # 加载数据 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 准备数据 X = series.values X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] # 步进验证 history = [x for x in train] predictions = list() for i in range(len(test)): # 变换 transformed, lam = boxcox(history) if lam < -5: transformed, lam = history, 1 # 预测 model = ARIMA(transformed, order=(0,1,2)) model_fit = model.fit() yhat = model_fit.forecast()[0] # 反转变换后的预测 yhat = boxcox_inverse(yhat, lam) predictions.append(yhat) # 观测 obs = test[i] history.append(obs) print('>Predicted=%.3f, Expected=%.3f' % (yhat, obs)) # 报告表现 rmse = sqrt(mean_squared_error(test, predictions)) print('RMSE: %.3f' % rmse) |
运行示例将打印每次迭代的预测值和预期值。
注意,您可能会看到使用 boxcox() 变换函数时出现警告;例如:
|
1 2 |
RuntimeWarning: overflow encountered in square llf -= N / 2.0 * np.log(np.sum((y - y_mean)**2. / N, axis=0)) |
这些现在可以忽略。
变换后数据上的模型最终 RMSE 为 49.443。这比未变换数据的 ARIMA 模型误差要小,但仅略微减小,可能在统计上不显著。
|
1 2 3 4 5 6 7 |
... >Predicted=276.253, Expected=287 >Predicted=299.811, Expected=355 >Predicted=338.997, Expected=460 >Predicted=404.509, Expected=364 >Predicted=349.336, Expected=487 RMSE:49.443 |
我们将使用带有 Box-Cox 变换的模型作为最终模型。
7. 模型验证
在模型开发和选定最终模型后,必须对其进行验证和定稿。
验证是过程的可选部分,但它提供了“最后一次检查”,以确保我们没有欺骗自己。
本节包括以下步骤:
- 最终确定模型:训练并保存最终模型。
- 进行预测:加载已定型的模型并进行预测。
- 验证模型:加载并验证最终模型。
7.1 最终确定模型
最终确定模型涉及在整个数据集上拟合 ARIMA 模型,在本例中,是在整个数据集的变换版本上进行拟合。
拟合后,可以将模型保存到文件中以供将来使用。由于还对数据进行了 Box-Cox 变换,因此我们需要知道所选的 lambda 值,以便将模型预测转换回原始、未变换的尺度。
下面的示例在 Box-Cox 变换数据集上拟合 ARIMA(0,1,2) 模型,并将整个拟合对象和 lambda 值保存到文件中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 最终确定模型并保存到文件(带有解决方法) from pandas import read_csv from statsmodels.tsa.arima.model import ARIMA from scipy.stats import boxcox import numpy # 加载数据 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 准备数据 X = series.values X = X.astype('float32') # 转换数据 transformed, lam = boxcox(X) # 拟合模型 model = ARIMA(transformed, order=(0,1,2)) model_fit = model.fit() # 保存模型 model_fit.save('model.pkl') numpy.save('model_lambda.npy', [lam]) |
运行示例将创建两个本地文件:
- model.pkl 这是 `ARIMA.fit()` 调用返回的 ARIMAResult 对象。它包括系数和拟合模型时返回的所有其他内部数据。
- model_lambda.npy 这是存储为单行单列 NumPy 数组的 lambda 值。
这可能有点矫枉过正,而且对于实际应用来说,真正需要的是模型中的 AR 和 MA 系数、差分次数的 d 参数,或许还有滞后观测值和模型残差,以及用于变换的 lambda 值。
7.2 进行预测
一个自然的需求可能是加载模型并进行单次预测。
这相对直接,包括恢复保存的模型和 lambda 值,并调用 forecast() 方法。
下面的示例加载模型,对下一个时间步进行预测,对 Box-Cox 变换进行逆变换,并打印预测结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 加载最终模型并进行预测 from statsmodels.tsa.arima.model import ARIMAResults from math import exp from math import log import numpy # 反转 box-cox 变换 def boxcox_inverse(value, lam): if lam == 0: return exp(value) return exp(log(lam * value + 1) / lam) model_fit = ARIMAResults.load('model.pkl') lam = numpy.load('model_lambda.npy') yhat = model_fit.forecast()[0] yhat = boxcox_inverse(yhat, lam) print('Predicted: %.3f' % yhat) |
运行示例将打印出约 452 的预测值。
如果我们查看 validation.csv,可以看到下一时间段的第一行的值为 452。模型 100% 准确,这令人印象深刻(或幸运)。
|
1 |
Predicted: 452.043 |
7.3 验证模型
我们可以加载模型并以模拟的实际操作方式来使用它。
在测试框架部分,我们将原始数据集的最后 12 个月保存在一个单独的文件中,以验证最终模型。
我们现在可以加载这个 validation.csv 文件,并用它来查看我们的模型在“未见过”的数据上的表现。
我们有两种可能的方法:
- 加载模型并使用它来预测未来 12 个月。超过前一两个月的预测会很快开始失去准确性。
- 加载模型并以滚动预测的方式使用它,为每个时间步更新变换和模型。这是首选方法,因为它也是人们在实践中将如何使用此模型,并且能实现最佳性能。
与前面几节中的模型评估一样,我们将以滚动预测的方式进行预测。这意味着我们将遍历验证数据集中的提前期,并将观测值作为历史的更新。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
# 在验证数据集上评估最终模型 from pandas import read_csv from matplotlib import pyplot from statsmodels.tsa.arima.model import ARIMA from statsmodels.tsa.arima.model import ARIMAResults from scipy.stats import boxcox from sklearn.metrics import mean_squared_error from math import sqrt from math import exp from math import log import numpy # 反转 box-cox 变换 def boxcox_inverse(value, lam): if lam == 0: return exp(value) return exp(log(lam * value + 1) / lam) # 加载和准备数据集 dataset = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) X = dataset.values.astype('float32') history = [x for x in X] validation = read_csv('validation.csv', header=None, index_col=0, parse_dates=True, squeeze=True) y = validation.values.astype('float32') # 加载模型 model_fit = ARIMAResults.load('model.pkl') lam = numpy.load('model_lambda.npy') # 进行第一次预测 predictions = list() yhat = model_fit.forecast()[0] yhat = boxcox_inverse(yhat, lam) predictions.append(yhat) history.append(y[0]) print('>Predicted=%.3f, Expected=%.3f' % (yhat, y[0])) # 滚动预测 for i in range(1, len(y)): # 变换 transformed, lam = boxcox(history) if lam < -5: transformed, lam = history, 1 # 预测 model = ARIMA(transformed, order=(0,1,2)) model_fit = model.fit() yhat = model_fit.forecast()[0] # 反转变换后的预测 yhat = boxcox_inverse(yhat, lam) predictions.append(yhat) # 观测 obs = y[i] history.append(obs) print('>Predicted=%.3f, Expected=%.3f' % (yhat, obs)) # 报告表现 rmse = sqrt(mean_squared_error(y, predictions)) print('RMSE: %.3f' % rmse) pyplot.plot(y) pyplot.plot(predictions, color='red') pyplot.show() |
运行示例将打印出验证数据集中时间步长的每个预测值和期望值。
验证期的最终 RMSE 预测为 53 起抢劫案。这与预期的误差 49 起相差不大,但我认为这与简单的持续性模型相比也相差不大。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
>Predicted=452.043, Expected=452 >Predicted=423.088, Expected=391 >Predicted=408.378, Expected=500 >Predicted=482.454, Expected=451 >Predicted=445.944, Expected=375 >Predicted=413.881, Expected=372 >Predicted=413.209, Expected=302 >Predicted=355.159, Expected=316 >Predicted=363.515, Expected=398 >Predicted=406.365, Expected=394 >Predicted=394.186, Expected=431 >Predicted=428.174, Expected=431 RMSE: 53.078 |
同时还提供了预测与验证数据集的比较图。
该预测具有持续性预测的特征。这确实表明,尽管该时间序列有明显的趋势,但它仍然是一个相当困难的问题。
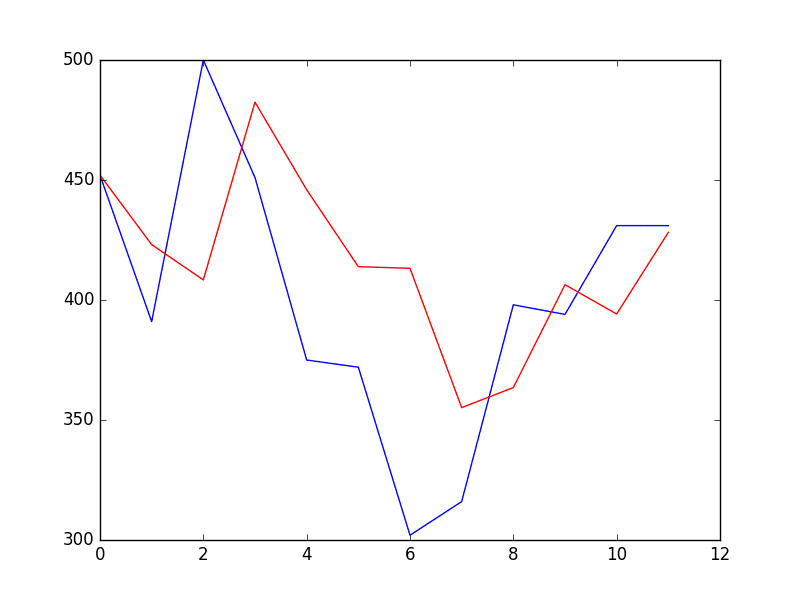
验证时间步长的预测
教程扩展
本教程并不详尽,可能还有更多可以改进结果的方法。
本节列出了一些想法。
- 统计显著性检验。使用统计检验来检查不同模型结果之间的差异是否具有统计学意义。学生 t 检验将是一个不错的起点。
- 带数据变换的网格搜索。在 ARIMA 超参数中重复网格搜索,并使用 Box-Cox 变换,看看是否可以获得不同且更好的参数集。
- 检查残差。调查带 Box-Cox 变换的最终模型的残差预测误差,看看是否存在可以解决的进一步偏差和/或自相关。
- 精简模型保存。简化模型保存,仅存储所需的系数,而不是整个 ARIMAResults 对象。
- 手动处理趋势。直接使用线性或非线性模型对趋势进行建模,并将其显式地从序列中移除。如果趋势是非线性的并且可以比线性情况更好地建模,这可能会带来更好的性能。
- 置信区间。在验证数据集上显示预测的置信区间。
- 数据选择。考虑在不使用前两年数据的情况下对问题进行建模,看看这对预测技能有何影响。
您是否实现了这些扩展中的任何一个?您是否能够获得更好的结果?
在下面的评论中分享您的发现。
总结
在本教程中,您发现了使用 Python 进行时间序列预测项目的步骤和工具。
本教程涵盖了很多内容,特别是
- 如何开发具有性能度量和评估方法的测试框架,以及如何快速开发基线预测和技能。
- 如何使用时间序列分析来提出关于如何最佳地对预测问题进行建模的想法。
- 如何开发 ARIMA 模型、保存它,然后稍后加载它以对新数据进行预测。
您做得怎么样?您对本教程有任何疑问吗?
在下面的评论中提出你的问题,我会尽力回答。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。


")
")
")

哇!惊人的教程!谢谢!
谢谢!
这是我遇到的最全面的教程,
非常感谢!
谢谢 Arthur。
Jason,谢谢教程。
如果我的数据高度相关,例如自相关在 40 个时间单位处有显著滞后,会发生什么?ARIMA 是一个好模型吗?我该如何利用高度相关的数据?
我怀疑 p 参数不会是 40,我该如何估计它?
我尝试使用 ARIMA 预测比特币价格,使用不同的采样频率。但是,无论我选择 (0,1,2) 还是 (1,1,2) 的 pdq,模型似乎都遵循原始数据,但有滞后,并且表现很差。
再次感谢,
价格可能是一个随机游走
https://machinelearning.org.cn/gentle-introduction-random-walk-times-series-forecasting-python/
计算机速度很快,ARIMA 模型也很容易拟合。可以尝试一系列模型参数
https://machinelearning.org.cn/grid-search-arima-hyperparameters-with-python/
使用 model.resid 计算残差与通过找出预测值与观测值之间的差异来显式计算残差有什么区别?
它们可能是完全相同的。
我有一条时间序列,但是尝试了。它不起作用,你能解释一下吗?
series = Series.from_csv(‘dataset.csv’)
groups = series[‘1966′:’1973’].groupby(TimeGrouper(‘A’))
years = DataFrame()
for name, group in groups
years[name.year] = group.values
years.boxplot()
pyplot.show()
问题究竟是什么?
这是一个很棒的教程!谢谢!
很高兴它有帮助!
嘿 Jason,很棒的教程。如何将 ARIMA 用于多序列预测(例如,同时预测 10 种产品的销量),其中数据是每日的?
谢谢
我希望将来能涵盖这个话题。
嗨,Jason,
我正在阅读您的博客。涵盖的主题以及您的解释风格都非常棒。非常感谢您的努力!
关于本教程,我注意到第 6.1 章下的 acf 和 pacf 图无法通过使用 dataset.csv(依我看)重现。此代码行是错误的
series = Series.from_csv(‘dataset.csv’)
要读取的 csv 文件应该是“stationary.csv”(因为我们必须使用更正后的数据集)。
这是我在 Python 3.x 中使用的代码(Series.from_csv 已弃用)
df = pd.read_csv(‘stationary.csv’,header=None,sep=’,’)
df.columns = [‘Date’,’Robberies’]
series = pd.Series(data=df[‘Robberies’])
series.index = pd.to_datetime(df[‘Date’])
来自德国汉堡的问候
Patrick
谢谢 Patrick,已修复。
我也在使用 Python 3。谢谢 Patrick。解决了我的问题。
你好,
是的,感谢您的建模和撰写。它非常出色!我是 Python 新手,预测主题一直是一个挑战。
问题
为什么这行:X = X.astype(‘float32’)
会产生这个
ValueError: could not convert string to float: Oct-75
在 Python 2.7 中
看起来您正在尝试将日期数据(字符串)转换为数字。
是的,我删除了包含观察值编号列表的第 0 列。转换现在可以了!
很高兴听到这个消息。
这是我的初步工作站结果
scipy: 1.1.0
numpy: 1.14.5
matplotlib: 2.2.2
pandas: 0.23.3
sklearn: 0.19.2
statsmodels: 0.9.0
我正在尝试替换
series = Series.from_csv(‘robberies.csv’, header=0)
并用
read_csv
命令替换。有人能告诉我需要替换什么才能跟上教程吗?
谢谢
抱歉,到目前为止,这似乎有效
from pandas import read_csv
series = read_csv(‘dataset.csv’, header=0, parse_dates=[0], index_col=0, squeeze=True)
不过,我仍在处理月份和年份格式…。
它确实可以,但对于 6.1-6.3 部分不起作用。
这是错误消息
回溯(最近一次调用)
File “/Users/adampatel/Documents/Test ARIMA Inputs.py”, line 47, in
series = read_csv(‘dataset.csv’, header=0, parse_dates=[0], index_col=0, squeeze=True)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 678, in parser_f
return _read(filepath_or_buffer, kwds)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 440, in _read
parser = TextFileReader(filepath_or_buffer, **kwds)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 787, in __init__
self._make_engine(self.engine)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 1014, in _make_engine
self._engine = CParserWrapper(self.f, **self.options)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 1708, in __init__
self._reader = parsers.TextReader(src, **kwds)
File “pandas/_libs/parsers.pyx”, line 384, in pandas._libs.parsers.TextReader.__cinit__
File “pandas/_libs/parsers.pyx”, line 695, in pandas._libs.parsers.TextReader._setup_parser_source
IOError: File dataset.csv does not exist
Jason 的代码和我唯一的区别是
series = Series.from_csv(‘robberies.csv’, header=0)
并用
from pandas import read_csv
series = read_csv(‘dataset.csv’, header=0, parse_dates=[0], index_col=0, squeeze=True)
有人能帮忙吗?
检查您的文件路径。
因为您还没有创建 dataset.csv。
您必须按顺序遵循教程步骤。
也许打印加载的数据以确认它已正确加载?
您可以使用它
当我在尝试运行整个数据集时,使用 plot_pacf 函数,我收到了错误
警告(来自警告模块)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/statsmodels/regression/linear_model.py”, line 1283
return rho, np.sqrt(sigmasq)
RuntimeWarning: invalid value encountered in sqrt
以及上面记录结果的变体。
如果我将滞后限制为 50,我得到的与上面前 50 个滞后相同的观察结果。
有人能解释一下吗?
我建议限制滞后,ACF/PACF 甚至是 ARIMA 模型通常都假设输出是最近观测值的一个函数,而不是整个数据集的一个函数。
嘿,当我像下面这样运行 pacf 函数时
import numpy as np
from pandas import Series
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
from matplotlib import pyplot
series = Series.from_csv(‘stationary.csv’)
pyplot.figure()
pyplot.subplot(212)
plot_pacf(series, ax=pyplot.gca())
pyplot.show()
我收到了以下错误,任何帮助都将是有用的
ipython-input-68-f01e5d803de5> in ()
7 pyplot.figure()
8 pyplot.subplot(212)
—-> 9 plot_pacf(series, ax=pyplot.gca())
10 pyplot.show()
~/.local/lib/python3.5/site-packages/statsmodels/graphics/tsaplots.py in plot_pacf(x, ax, lags, alpha, method, use_vlines, title, zero, vlines_kwargs, **kwargs)
221 acf_x = pacf(x, nlags=nlags, alpha=alpha, method=method)
222 else
–> 223 acf_x, confint = pacf(x, nlags=nlags, alpha=alpha, method=method)
224
225 _plot_corr(ax, title, acf_x, confint, lags, irregular, use_vlines,
~/.local/lib/python3.5/site-packages/statsmodels/tsa/stattools.py in pacf(x, nlags, method, alpha)
599 ret = pacf_ols(x, nlags=nlags)
600 elif method in [‘yw’, ‘ywu’, ‘ywunbiased’, ‘yw_unbiased’]
–> 601 ret = pacf_yw(x, nlags=nlags, method=’unbiased’)
602 elif method in [‘ywm’, ‘ywmle’, ‘yw_mle’]
603 ret = pacf_yw(x, nlags=nlags, method=’mle’)
~/.local/lib/python3.5/site-packages/statsmodels/tsa/stattools.py in pacf_yw(x, nlags, method)
518 pacf = [1.]
519 for k in range(1, nlags + 1)
–> 520 pacf.append(yule_walker(x, k, method=method)[0][-1])
521 return np.array(pacf)
522
~/.local/lib/python3.5/site-packages/statsmodels/regression/linear_model.py in yule_walker(X, order, method, df, inv, demean)
1259 if method not in [“unbiased”, “mle”]
1260 raise ValueError(“ACF estimation method must be ‘unbiased’ or ‘MLE'”)
-> 1261 X = np.array(X, dtype=np.float64)
1262 if demean
1263 X -= X.mean() # automatically demean’s X
ValueError: could not convert string to float: ‘[0.98]’
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨 Jason
感谢这篇教程。
如果数据包含犯罪地点怎么办?如果地点是犯罪发生的特定城市街区,那么不同区域的犯罪之间可能存在关联。例如,罪犯可能抢劫一个地方,然后在几分钟后抢劫另一个地方。
如果添加位置数据,您将如何处理这个问题?
这取决于具体的数据集。
或许可以对问题进行几种不同的原型设计,以找出最有效的方法。
Jason,谢谢您的教程!非常有帮助。
波动可能可以用外生变量来解释,您是否计划在教程中也涵盖 SARIMAX?
我在这里展示了如何使用 SARIMA
https://machinelearning.org.cn/how-to-grid-search-sarima-model-hyperparameters-for-time-series-forecasting-in-python/
我在这里展示了如何向 SARIMA 添加外生变量(例如 SARIMAX)
https://machinelearning.org.cn/time-series-forecasting-methods-in-python-cheat-sheet/
你好——你如何保存(p,d,q)以便以后可以将其应用于你的数据?
你可以保存模型结果
https://machinelearning.org.cn/save-arima-time-series-forecasting-model-python/
数据链接无效。我在这个网站上找到了数据
https://rstudio-pubs-static.s3.amazonaws.com/153780_a9970c82ef5546479e0ceedc3efef520.html
它需要一些手动操作才能将其转换为 csv
## 一月 二月 三月 四月 五月 六月 七月 八月 九月 十月 十一月 十二月
## 1966 41 39 50 40 43 38 44 35 39 35 29 49
## 1967 50 59 63 32 39 47 53 60 57 52 70 90
## 1968 74 62 55 84 94 70 108 139 120 97 126 149
## 1969 158 124 140 109 114 77 120 133 110 92 97 78
## 1970 99 107 112 90 98 125 155 190 236 189 174 178
## 1971 136 161 171 149 184 155 276 224 213 279 268 287
## 1972 238 213 257 293 212 246 353 339 308 247 257 322
## 1973 298 273 312 249 286 279 309 401 309 328 353 354
## 1974 327 324 285 243 241 287 355 460 364 487 452 391
## 1975 500 451 375 372 302 316 398 394 431 431
这是直接链接
https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-robberies.csv
是否有可以处理多个差分并反转以进行预测的函数或包,例如 ARIMA 模型中的 5 个滞后?
考虑 SARIMA 模型,它增加了季节性差分
https://machinelearning.org.cn/sarima-for-time-series-forecasting-in-python/
很棒的教程!我有一个问题。将模型保存到 pkl 文件后,如果我想将其部署到网站或应用程序,这个 ARIMA 预测模型的输入是什么?它是预测范围(预测未来 6 个月或 12 个月),所以我需要输入 6 或 12。还是它有一个默认范围,它将预测固定的月数。或者需要输入日期序列,等等,等等。预先感谢!
谢谢!
是的,您可以指定预测的步数。
本教程提供了一个示例
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
一如既往的出色教程!
谢谢!
在“Box-Cox 变换数据集”中
如果 lambda == 0,则 transform = log(x)
transform = (x^lambda – 1) / lambda,如果 lambda != 0
当“lambda==0”时,应该是“transformed=history-1”,但你的代码是“transformed=history”。
是我的理解错了?
我写错了数字
当“lambda==1”时,应该是“transformed=history-1”,但你的代码是“transformed=history”
你为什么要这么说呢?
在第 6.4 节中,你说 lambda 值在 -5 和 5 之间进行评估,所以你写了以下代码
if lam < -5
transformed, lam = history, 1
但根据公式“transform = (x^lambda – 1) / lambda,如果 lambda != 0”,为什么代码不应该是这样的
if lam < -5
transformed, lam = history-1, 1
从帖子中
是的,你可以随意更改它。
您好。
精彩的教程……很棒的博客。我对我迄今为止的所有文章都感到满意。
作为初学者,我有一个问题。它与 ad fuller 结果有关,可能很琐碎,因为以前没有人问过,但它让我感到困惑。
你说
“结果表明,检验统计量值 -3.980946 小于 5% 的临界值 -2.893。
这表明我们可以拒绝零假设,其显著性水平小于 5%。
(即结果是统计上的偶然事件的概率很低)。”
拒绝零假设意味着该过程没有单位根,
反过来,这意味着时间序列是平稳的或没有时间依赖性结构。
好的,因为这个原因,并且 pValue = 0.001514 << 0.5。那么它是平稳序列……不是吗?
之后,给出了数值,用于 ad fuller 测试
你立即说:“这表明至少需要一个级别的差分。”
我们的 ARIMA 模型中的 d 参数至少应为 1。
好的,我同意,因为它能运行。ACF 也指向这个方向……
但是……为什么?如果我们进行差分是为了使序列平稳,而它已经平稳了……
我错过了什么?
再次感谢你的工作。它真的很有用
谢谢!
为什么问题真的很难。也许序列并不平稳,结果是准确的,并且低概率真的发生了,或者也许该测试由于某种我没有想到的原因而对数据不适用。或者其他原因。
我更喜欢关注实际——什么有效——什么能给我们项目带来可用的结果。工程,而非科学。
根据你的代码,我认为是因为你在进行 adf 测试之前应用了第一次差分。
是的!!!!你说得对。只是为了去除趋势。这就是原因。我读了这篇文章好几次……我错过了这一点。谢谢
哦!!那么我能推断出 ad fuller 测试的结果可能不是神圣的吗?我是说它可能因为各种原因而出错,并且为了更确定地进行另一种测试可能很方便。如果是这样,那么你给了我一个重要的教训,因为任何人都倾向于只做一个测试。谢谢。
这是一个概率统计检验,不是事实。
用下面这行
dataset.to_csv(‘dataset.csv’, index=False, header=False)
我收到以下错误:
文件“”,第 1 行
dataset.to_csv(‘dataset.csv’, index=False, header=False)
^
SyntaxError: invalid syntax
我使用的是 Python 3 和我的版本
scipy: 1.1.0
numpy: 1.15.4
matplotlib: 3.0.3
pandas: 0.23.4
sklearn: 0.20.1
statsmodels: 0.11.1
很抱歉听到这个消息,这可能会有所帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
stationary.to_csv(‘stationary.csv’, header=False)
嗨,Jason,
首先,我要感谢你清晰的解释。我真的很喜欢你展示教程的方式,并列出了开发完整预测项目所需的不同步骤。
我目前正在研究你的案例研究,我注意到你为我手动配置的 ARIMA 模型使用了文件 ‘dataset.csv’。根据我的理解,这是不正确的,因为 ARIMA 模型需要一个平稳序列才能按预期工作。我们不是应该使用 ‘stationary.csv’ 数据集吗?
再次非常感谢。
来自德国的问候!
Ana Debroy
我还注意到,实际上你只使用了 ‘dataset.csv’ 文件,即使在生成了 ‘stationary.csv’ 文件之后。
我的问题是
– 在初步分析完数据集后,我们不应该也使用 ‘stationar.csv’ 进行所有后续代码吗?
– 在验证模型之前,我们是否也需要对 ‘validation.csv’ 数据集进行差分?
根据我的理解,如果我们尝试将一个已分化数据集生成的预测与未分化验证数据进行比较,我们会得到更多错误。
请记住,ARIMA 有一个 d 参数,可用于对序列进行差分并使其平稳。
我们只在教程的手动配置部分使用 stationary.csv。
嗨,Jason,
感谢又一篇教程。
但我不知道你是否在确定模型的 p 和 q 时混淆了 ACF 和 PACF。
你说
“ACF 显示 1 个月有显著的滞后。
PACF 显示大约 2 个月有显著滞后,并且在长达大约 12 个月的时间里滞后点零星出现。
ACF 和 PACF 都在同一点下降,这可能表明 AR 和 MA 的混合。
p 和 q 值的良好起点是 1 或 2。”
如果 PACF 显示 2 个月的显著滞后,那么 p 值应为 2,q 应为 1,因为我们使用 PACF 来评估 p,使用 ACF 来评估 q。
https://www.itl.nist.gov/div898/handbook/pmc/section4/pmc446.htm
此致,
Ivan。
不客气。
我不这么认为。另请参阅此内容以解释这些术语
https://machinelearning.org.cn/gentle-introduction-autocorrelation-partial-autocorrelation/