时间序列预测是一个过程,要想获得良好的预测,唯一的方法就是实践这个过程。
在本教程中,您将学习如何使用 Python 预测法国香槟的月度销量。
完成本教程将为您提供一个框架,用于处理您自己的时间序列预测问题,并掌握相应的步骤和工具。
完成本教程后,您将了解:
- 如何确认您的 Python 环境并仔细定义时间序列预测问题。
- 如何创建评估模型的测试平台,开发一个基准预测,并通过时间序列分析工具更好地理解您的问题。
- 如何开发一个自回归积分移动平均模型,将其保存到文件,并在以后加载它以对新的时间步长进行预测。
我的新书《使用 Python 进行时间序列预测》包含分步教程和所有示例的 Python 源代码文件,助您启动项目。
让我们开始吧。
- 2017 年 3 月更新:修复了代码示例中的一个错别字。
- 2019 年 4 月更新:更新了数据集链接。
- 2019 年 8 月更新:更新了数据加载和日期分组以使用新的 API。
- 更新于2020年2月:更新了to_csv()以消除警告。
- 2020 年 2 月更新:修复了数据准备和加载问题。
- 2020 年 5 月更新:修复了进行预测时的一个小错别字。
- **2020 年 12 月更新**:针对 API 更改更新了建模。

使用 Python 进行时间序列预测研究 – 法国香槟的月度销量
图片由 Basheer Tome 提供,部分权利保留。
概述
在本教程中,我们将端到端地完成一个时间序列预测项目,从下载数据集和定义问题到训练最终模型和进行预测。
这个项目并非详尽无遗,但它展示了如何通过系统地解决一个时间序列预测问题来快速获得良好结果。
我们将通过的项目步骤如下:
- 环境。
- 问题描述。
- 测试平台。
- 持久性。
- 数据分析。
- ARIMA 模型。
- 模型验证。
这将为解决时间序列预测问题提供一个模板,您可以将其用于您自己的数据集。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
1. 环境
本教程假定已安装并运行SciPy环境及相关依赖项,包括:
- SciPy
- NumPy
- Matplotlib
- Pandas
- scikit-learn
- statsmodels
如果您需要帮助在工作站上安装 Python 和 SciPy 环境,请考虑 Anaconda 发行版,它可以为您处理大部分工作。
此脚本将帮助您检查这些库的已安装版本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 检查关键Python库的版本 # scipy import scipy print('scipy: %s' % scipy.__version__) # numpy import numpy print('numpy: %s' % numpy.__version__) # matplotlib import matplotlib print('matplotlib: %s' % matplotlib.__version__) # pandas import pandas print('pandas: %s' % pandas.__version__) # statsmodels import statsmodels print('statsmodels: %s' % statsmodels.__version__) # scikit-learn import sklearn print('sklearn: %s' % sklearn.__version__) |
在编写本教程的工作站上,我的结果如下:
|
1 2 3 4 5 6 |
scipy: 1.5.4 numpy: 1.18.5 matplotlib: 3.3.3 pandas: 1.1.4 statsmodels: 0.12.1 sklearn: 0.23.2 |
2. 问题描述
问题是预测 Perrin Freres 品牌(以法国一个地区命名)香槟的月度销量。
数据集提供了从 1964 年 1 月到 1972 年 9 月的香槟月度销量,即不到 10 年的数据。
这些值是百万销量的计数,共有 105 个观测值。
该数据集归功于 Makridakis 和 Wheelwright,1989 年。
将数据集下载为 CSV 文件并将其放置在当前工作目录中,文件名为“champagne.csv”。
3. 测试平台
我们必须开发一个测试平台来研究数据和评估候选模型。
这涉及两个步骤
- 定义验证数据集。
- 开发模型评估方法。
3.1 验证数据集
该数据集不是最新的。这意味着我们无法轻易收集更新的数据来验证模型。
因此,我们将假定现在是 1971 年 9 月,并保留最后一年数据不进行分析和模型选择。
这一年的数据将用于验证最终模型。
下面的代码将加载数据集为一个Pandas Series,并将其分为两部分:一部分用于模型开发(dataset.csv),另一部分用于验证(validation.csv)。
|
1 2 3 4 5 6 7 8 |
# 分离出一个验证数据集 from pandas import read_csv series = read_csv('champagne.csv', header=0, index_col=0, parse_dates=True, squeeze=True) split_point = len(series) - 12 dataset, validation = series[0:split_point], series[split_point:] print('数据集 %d, 验证集 %d' % (len(dataset), len(validation))) dataset.to_csv('dataset.csv', header=False) validation.to_csv('validation.csv', header=False) |
运行该示例会创建两个文件,并打印出每个文件中的观测数量。
|
1 |
数据集 93, 验证集 12 |
这些文件的具体内容是:
- dataset.csv:1964 年 1 月至 1971 年 9 月的观测值(93 个观测值)
- validation.csv:1971 年 10 月至 1972 年 9 月的观测值(12 个观测值)
验证数据集约占原始数据集的 11%。
请注意,保存的数据集没有标题行,因此我们稍后处理这些文件时无需考虑这一点。
3.2. 模型评估
模型评估仅在上一节准备的dataset.csv文件中进行。
模型评估包括两个要素:
- 性能度量。
- 测试策略。
3.2.1 性能度量
观测值是香槟销量的计数,单位为百万瓶。
我们将使用均方根误差(RMSE)来评估预测的性能。这将为严重错误的预测提供更高的权重,并且其单位与原始数据相同。
在计算和报告RMSE之前,必须撤销对数据进行的任何转换,以便不同方法之间的性能可以直接进行比较。
我们可以使用 scikit-learn 库中的辅助函数 mean_squared_error() 计算 RMSE,该函数计算预期值列表(测试集)和预测列表之间的均方误差。然后,我们可以取该值的平方根,得到 RMSE 分数。
例如
|
1 2 3 4 5 6 7 8 |
from sklearn.metrics import mean_squared_error from math import sqrt ... test = ... predictions = ... mse = mean_squared_error(test, predictions) rmse = sqrt(mse) print('RMSE: %.3f' % rmse) |
3.2.2 测试策略
候选模型将使用前向验证进行评估。
这是因为问题定义要求使用滚动预测类型的模型。在这种情况下,需要根据所有可用数据进行一步预测。
前向验证将按以下方式工作:
- 数据集的前50%将保留用于训练模型。
- 剩余50%的数据集将被迭代并用于测试模型。
- 对于测试数据集中的每一步:
- 将训练一个模型。
- 进行一步预测,并将预测存储起来以供以后评估。
- 测试数据集中实际的观测值将在下一次迭代中添加到训练数据集中。
- 在测试数据集迭代期间进行的预测将被评估并报告 RMSE 分数。
鉴于数据量较小,我们将允许模型在每次预测之前使用所有可用数据进行重新训练。
我们可以使用简单的NumPy和Python代码来编写测试平台的代码。
首先,我们可以直接将数据集拆分为训练集和测试集。我们总是小心地将加载的数据集转换为 float32,以防加载的数据仍包含一些 String 或 Integer 数据类型。
|
1 2 3 4 5 |
# 准备数据 X = series.values X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] |
接下来,我们可以遍历测试数据集中的时间步长。训练数据集存储在 Python 列表中,因为我们需要在每次迭代时轻松附加新的观测值,而 NumPy 数组连接似乎有点多余。
模型做出的预测根据惯例称为 yhat,因为结果或观测值称为 y,而 yhat(带帽子的“y”)是 y 变量预测的数学符号。
每次观测值都会打印预测值和观测值,以便在模型存在问题时进行健全性检查预测。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 步进验证 history = [x for x in train] predictions = list() for i in range(len(test)): # 预测 yhat = ... predictions.append(yhat) # 观测 obs = test[i] history.append(obs) print('>预测值=%.3f, 实际值=%3.f' % (yhat, obs)) |
4. 持久性
在深入进行数据分析和建模之前,第一步是建立一个性能基准。
这将为使用提出的测试平台评估模型提供一个模板,并为所有更复杂的预测模型提供一个性能比较基准。
时间序列预测的基准预测称为朴素预测,或持久性预测。
这是将前一个时间步长的观测值用作下一个时间步长观测值的预测。
我们可以将其直接插入上一节定义的测试平台。
完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from pandas import read_csv from sklearn.metrics import mean_squared_error from math import sqrt # 加载数据 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 准备数据 X = series.values X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] # 步进验证 history = [x for x in train] predictions = list() for i in range(len(test)): # 预测 yhat = history[-1] predictions.append(yhat) # 观测 obs = test[i] history.append(obs) print('>预测值=%.3f, 实际值=%3.f' % (yhat, obs)) # 报告表现 mse = mean_squared_error(test, predictions) rmse = sqrt(mse) print('RMSE: %.3f' % rmse) |
运行测试平台会打印测试数据集每次迭代的预测值和观测值。
示例最后会打印模型的RMSE。
在这种情况下,我们可以看到持久性模型实现了 3186.501 的 RMSE。这意味着平均而言,模型在每次预测中都存在约 3186 百万销量的误差。
|
1 2 3 4 5 6 7 |
... >预测值=4676.000,实际值=5010 >预测值=5010.000,实际值=4874 >预测值=4874.000,实际值=4633 >预测值=1659.000,实际值=5951 >预测值=5951.000,实际值=5951 RMSE: 3186.501 |
我们现在有了基准预测方法和性能;现在我们可以开始深入挖掘我们的数据了。
5. 数据分析
我们可以使用汇总统计数据和数据图表来快速了解预测问题的结构。
在本节中,我们将从五个角度审视数据
- 汇总统计。
- 折线图。
- 季节性线图
- 密度图。
- 箱线图。
5.1 汇总统计
汇总统计数据可以快速了解观测值的范围。它可以帮助我们快速了解我们正在处理的数据。
下面的示例计算并打印时间序列的汇总统计数据。
|
1 2 3 |
from pandas import read_csv series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) print(series.describe()) |
运行该示例会提供一系列汇总统计数据供您查看。
从这些统计数据中可以观察到:
- 观测数量(count)与我们的预期相符,这意味着我们正确地处理了数据。
- 平均值约为 4641,我们可能将其视为该序列的水平值。
- 标准差(与平均值的平均差)相对较大,为 2486 销量。
- 百分位数和标准差确实表明数据分布范围很大。
|
1 2 3 4 5 6 7 8 |
计数 93.000000 平均值 4641.118280 标准差 2486.403841 最小值 1573.000000 25% 3036.000000 50% 4016.000000 75% 5048.000000 最大值 13916.000000 |
5.2 线图
时间序列的线图可以提供对问题的大量洞察。
下面的示例创建并显示了数据集的折线图。
|
1 2 3 4 5 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) series.plot() pyplot.show() |
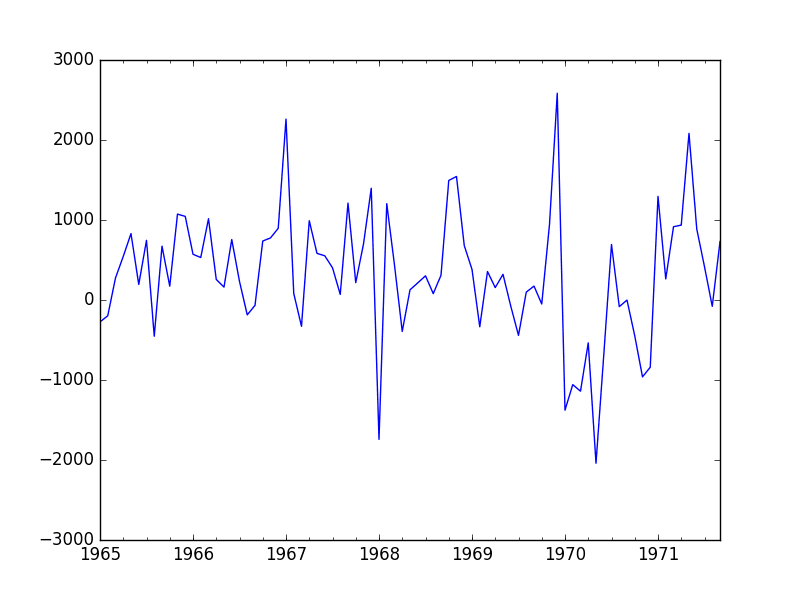
运行示例并查看图表。注意序列中任何明显的时序结构。
从图表中可以观察到:
- 销量可能随时间呈增长趋势。
- 每年的销量似乎都有系统性的季节性。
- 季节性信号似乎随时间增长,表明存在乘法关系(变化增加)。
- 似乎没有明显的异常值。
- 季节性表明该序列几乎肯定是非平稳的。
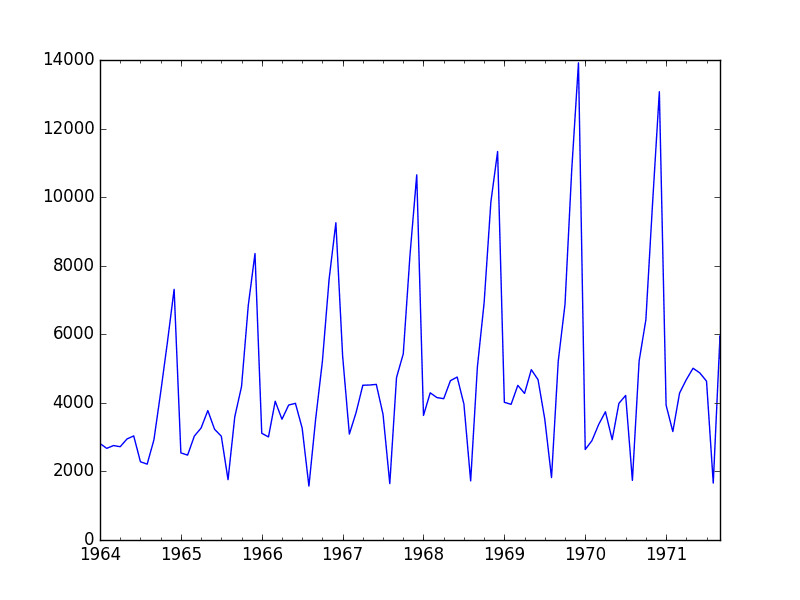
香槟销量线图
明确地对季节性成分建模并将其移除可能会有好处。您也可以探索使用一或两级的差分以使序列平稳。
季节性成分的增长趋势可能暗示使用对数或其他幂变换。
5.3 季节性线图
我们可以通过目视检查按年份划分的数据集的线图来确认季节性是年度循环的假设。
下面的示例将 7 年的完整数据作为单独的组,并为每个组创建一个线图。线图垂直对齐,以帮助发现任何逐年模式。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from pandas import read_csv from pandas import DataFrame from pandas import Grouper from matplotlib import pyplot series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) groups = series['1964':'1970'].groupby(Grouper(freq='A')) years = DataFrame() pyplot.figure() i = 1 n_groups = len(groups) for name, group in groups: pyplot.subplot((n_groups*100) + 10 + i) i += 1 pyplot.plot(group) pyplot.show() |
运行示例会创建 7 个线图堆栈。
我们可以清楚地看到每年八月销量下降,然后从八月到十二月销量上升。这种模式每年都相同,尽管水平不同。
这将有助于以后进行任何明确基于季节的建模。
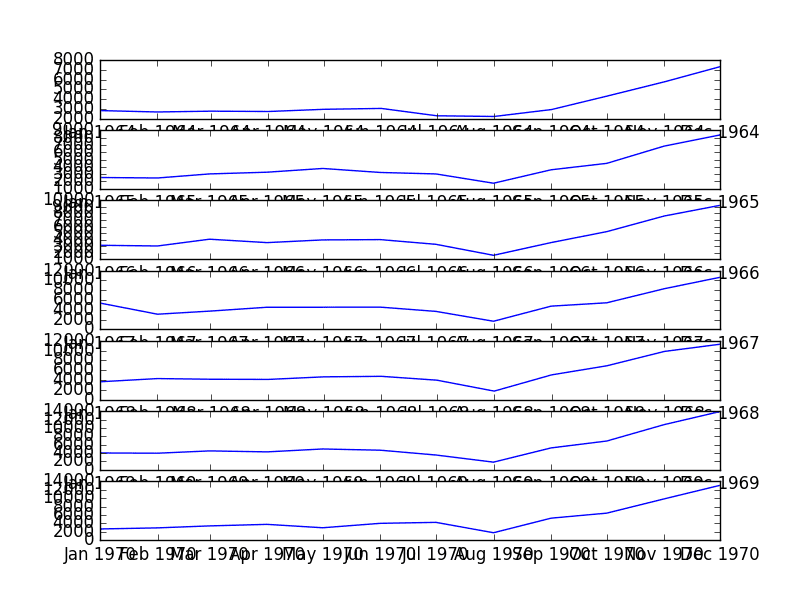
每年季节性线图
如果所有季节线图都添加到同一个图表中,可能更容易对比每年的数据。
5.4 密度图
审视观测值密度图可以为数据结构提供进一步的见解。
下面的示例创建了观测值的直方图和密度图,而不考虑任何时间结构。
|
1 2 3 4 5 6 7 8 9 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) pyplot.figure(1) pyplot.子图(211) series.hist() pyplot.子图(212) series.plot(kind='kde') pyplot.show() |
运行示例并查看图表。
从图表中可以观察到:
- 分布不是高斯分布。
- 该形状具有长右尾,可能表明是指数分布
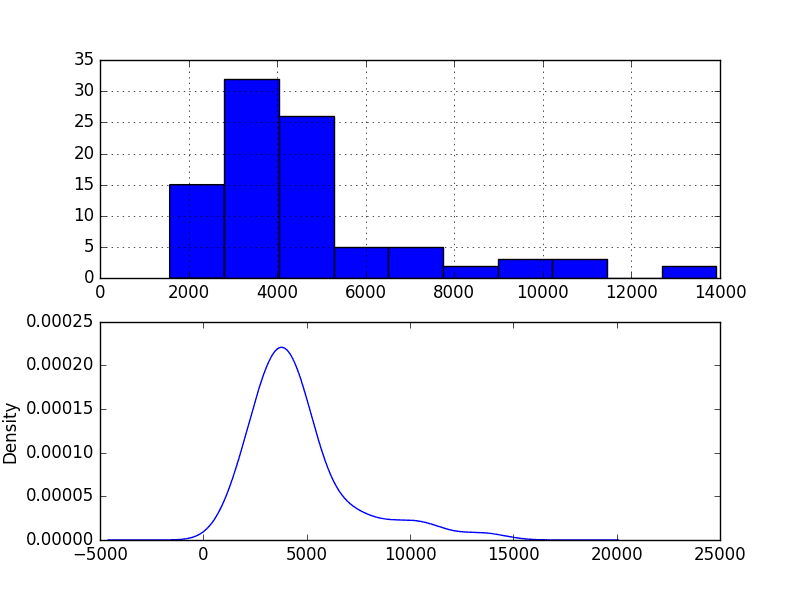
这进一步支持在建模之前探索数据的某些幂变换。
5.5 箱线图
我们可以按年份对月度数据进行分组,并了解每年观测值的分布情况以及它可能如何变化。
我们预计会看到一些趋势(均值或中位数增加),但查看分布的其余部分如何变化可能会很有趣。
下面的示例按年份对观测值进行分组,并为每年的观测值创建一个箱线图。最后一年(1971 年)只包含 9 个月,可能与其他年份的 12 个月观测值不具有可比性。因此,只绘制了 1964 年至 1970 年之间的数据。
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import read_csv from pandas import DataFrame from pandas import Grouper from matplotlib import pyplot series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) groups = series['1964':'1970'].groupby(Grouper(freq='A')) years = DataFrame() for name, group in groups: years[name.year] = group.values years.boxplot() pyplot.show() |
运行示例会创建 7 个并排的箱线图,每个图对应所选数据的 7 年中的一年。
回顾这些图可以得出一些观察结果:
- 每年中位数(红线)可能呈增长趋势。
- 数据的分布或中间 50%(蓝色方框)似乎相当稳定。
- 每年都有异常值(黑色十字);这些可能是季节性周期的顶部或底部。
- 去年,1970 年,看起来与前几年的趋势不同
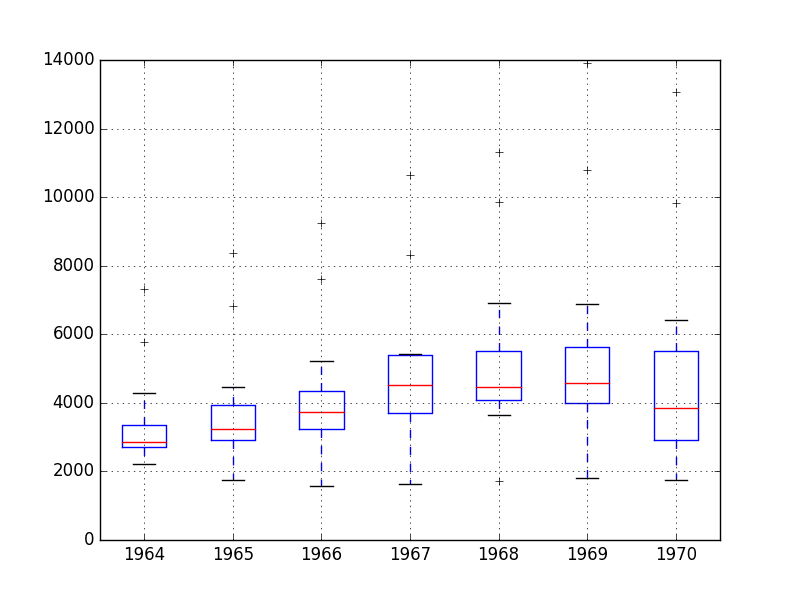
香槟销量箱线图
观测结果表明,可能存在多年的增长趋势和可能是季节性周期一部分的异常值。
这种数据的年度视图是一个有趣的途径,可以通过查看逐年汇总统计数据和逐年汇总统计数据的变化来进一步研究。
6. ARIMA模型
在本节中,我们将为该问题开发自回归综合移动平均 (ARIMA) 模型。
我们将通过手动和自动配置 ARIMA 模型来建模。之后,将是检查所选模型残差错误的第三步。
因此,本节分为 3 个步骤:
- 手动配置 ARIMA。
- 自动配置 ARIMA。
- 审查残差错误。
6.1 手动配置ARIMA
ARIMA(p,d,q) 模型需要三个参数,传统上是手动配置的。
时间序列数据的分析假设我们处理的是平稳时间序列。
时间序列几乎肯定是非平稳的。我们可以通过首先对序列进行差分并使用统计检验来确认结果是平稳的,从而使其平稳。
序列中的季节性似乎是逐年的。季节性数据可以通过从上一周期的同一时间(在本例中为上一年同一月份)的观测值中减去该观测值来差分。这意味着我们将失去第一年的观测值,因为没有上一年可供差分。
下面的示例创建了一个去季节化的序列版本,并将其保存到文件 stationary.csv。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
from pandas import read_csv from pandas import Series from statsmodels.tsa.stattools import adfuller from matplotlib import pyplot # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return Series(diff) series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) X = series.values X = X.astype('float32') # 差分数据 months_in_year = 12 stationary = difference(X, months_in_year) stationary.index = series.index[months_in_year:] # 检查是否平稳 result = adfuller(stationary) print('ADF 统计量: %f' % result[0]) print('p-值: %f' % result[1]) print('Critical Values:') for key, value in result[4].items(): print('\t%s: %.3f' % (key, value)) # 保存 stationary.to_csv('stationary.csv', header=False) # 绘图 stationary.plot() pyplot.show() |
运行示例会输出对差分序列是否平稳的统计显著性检验结果。具体来说,是增广迪基-富勒检验。
结果显示检验统计量值 -7.134898 小于 1% 的临界值 -3.515。这表明我们可以在低于 1% 的显著性水平下拒绝原假设(即结果是统计侥幸的概率很低)。
拒绝零假设意味着该过程没有单位根,进而意味着时间序列是平稳的或不具有时间相关结构。
|
1 2 3 4 5 6 |
ADF 统计量:-7.134898 p值:0.000000 临界值 5%: -2.898 1%: -3.515 10%: -2.586 |
作为参考,可以通过加上上一年同一月份的观测值来反转季节性差分操作。这在模型对季节性差分数据进行拟合后需要进行预测的情况下是必需的。为了完整性,反转季节性差分操作的函数如下所示。
|
1 2 3 |
# 反转差分值 def inverse_difference(history, yhat, interval=1): return yhat + history[-interval] |
还创建了差分数据集的图。
该图没有显示任何明显的季节性或趋势,表明季节性差分数据集是建模的良好起点。
我们将使用此数据集作为 ARIMA 模型的输入。它还表明可能不需要进一步的差分,并且 d 参数可以设置为 0。
季节性差分香槟销量线图
下一步是选择自回归 (AR) 和移动平均 (MA) 参数 p 和 q 的滞后值。
我们可以通过查看自相关函数(ACF)和偏自相关函数(PACF)图来做到这一点。
请注意,我们现在使用季节性差分的 stationary.csv 作为我们的数据集。
下面的示例为序列生成了 ACF 和 PACF 图。
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import read_csv from statsmodels.graphics.tsaplots import plot_acf from statsmodels.graphics.tsaplots import plot_pacf from matplotlib import pyplot series = read_csv('stationary.csv', header=None, index_col=0, parse_dates=True, squeeze=True) pyplot.figure() pyplot.子图(211) plot_acf(series, ax=pyplot.gca()) pyplot.子图(212) plot_pacf(series, ax=pyplot.gca()) pyplot.show() |
运行示例并查看图表,以了解如何为 ARIMA 模型设置 p 和 q 变量。
以下是图表中的一些观察结果。
- ACF 显示 1 个月有显著滞后。
- PACF 显示 1 个月有显著滞后,可能在 12 和 13 个月处也有一些显著滞后。
- ACF 和 PACF 都显示在同一点下降,可能表明 AR 和 MA 的混合。
p 和 q 值的一个良好起点也是 1。
PACF 图也表明差分数据中仍然存在一些季节性。
我们可能会考虑一种更好的季节性建模方法,例如直接建模并明确将其从模型中删除,而不是季节性差分。
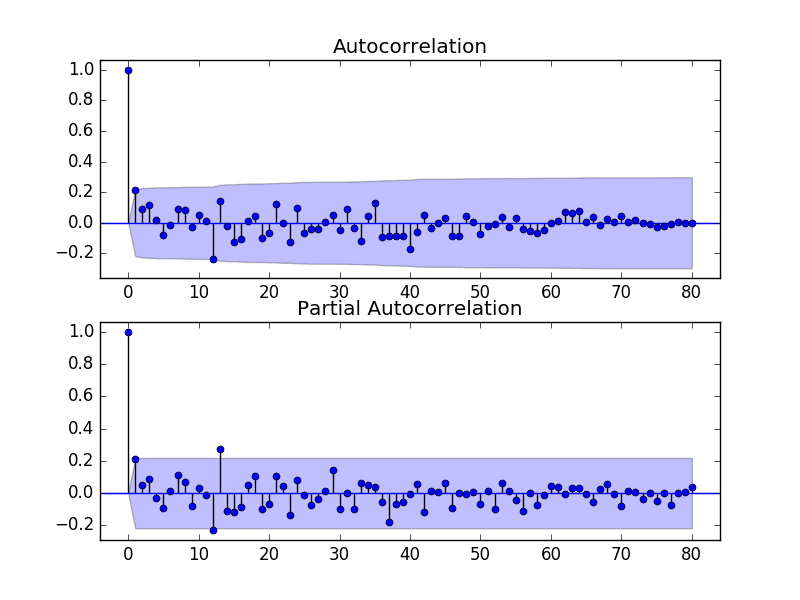
季节性差分香槟销量的 ACF 和 PACF 图
这种快速分析表明,在平稳数据上使用 ARIMA(1,0,1) 或类似模型可能是一个好的起点。
在拟合每个 ARIMA 模型之前,历史观测值将进行季节性差分。所有预测的差分都将反转,以使它们直接与原始销售计数单位中的预期观测值进行比较。
实验表明,这种 ARIMA 配置无法收敛,并导致底层库出现错误。进一步的实验表明,对平稳数据增加一个差分级别使模型更加稳定。模型可以扩展到 ARIMA(1,1,1)。
我们还将通过在调用 fit() 时将“trend”参数设置为“nc”(无常数)来禁用模型中趋势常数的自动添加。根据经验,我发现这可以在某些问题上带来更好的预测性能。
下面的示例演示了此 ARIMA 模型在测试工具上的性能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# 评估手动配置的 ARIMA 模型 from pandas import read_csv from sklearn.metrics import mean_squared_error from statsmodels.tsa.arima.model import ARIMA from math import sqrt # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return diff # 反转差分值 def inverse_difference(history, yhat, interval=1): return yhat + history[-interval] # 加载数据 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 准备数据 X = series.values X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] # 步进验证 history = [x for x in train] predictions = list() for i in range(len(test)): # 差分数据 months_in_year = 12 diff = difference(history, months_in_year) # 预测 model = ARIMA(diff, order=(1,1,1)) model_fit = model.fit() yhat = model_fit.forecast()[0] yhat = inverse_difference(history, yhat, months_in_year) predictions.append(yhat) # 观测 obs = test[i] history.append(obs) print('>预测值=%.3f, 实际值=%.3f' % (yhat, obs)) # 报告表现 rmse = sqrt(mean_squared_error(test, predictions)) print('RMSE: %.3f' % rmse) |
请注意,您可能会看到来自底层线性代数库的警告消息;目前可以忽略。
运行此示例会得到 956.942 的 RMSE,这比持久性 RMSE 3186.501 显著提高。
|
1 2 3 4 5 6 7 |
... >预测值=3157.018,实际值=5010 >预测值=4615.082,实际值=4874 >预测值=4624.998,实际值=4633 >预测值=2044.097,实际值=1659 >预测值=5404.428,实际值=5951 RMSE: 956.942 |
这是一个很好的开始,但我们可能可以通过配置更好的 ARIMA 模型获得更好的结果。
6.2 网格搜索 ARIMA 超参数
ACF 和 PACF 图表明 ARIMA(1,0,1) 或类似模型可能是我们能做到的最好模型。
为了确认此分析,我们可以网格搜索一套ARIMA超参数,并检查没有模型能产生更好的样本外RMSE性能。
在本节中,我们将搜索p、d和q的值以进行组合(跳过那些未能收敛的),并找到在测试集上产生最佳性能的组合。我们将使用网格搜索来探索整数值子集中的所有组合。
具体来说,我们将搜索以下参数的所有组合
- p:0到6。
- d:0到2。
- q:0到6。
这相当于(7 * 3 * 7),即147次潜在的测试运行,执行将需要一些时间。
评估滞后12或13的MA模型可能会很有趣,因为从审查ACF和PACF图来看,这些模型可能具有潜在的趣味性。实验表明,这些模型可能不稳定,导致底层数学库出现错误。
带有网格搜索版本测试框架的完整示例代码如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
# 时间序列的 ARIMA 参数网格搜索 import warnings from pandas import read_csv from statsmodels.tsa.arima.model import ARIMA from sklearn.metrics import mean_squared_error from math import sqrt import numpy # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return numpy.array(diff) # 反转差分值 def inverse_difference(history, yhat, interval=1): return yhat + history[-interval] # 评估给定阶数 (p,d,q) 的 ARIMA 模型,并返回 RMSE def evaluate_arima_model(X, arima_order): # 准备训练数据集 X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] history = [x for x in train] # 进行预测 predictions = list() for t in range(len(test)): # 差分数据 months_in_year = 12 diff = difference(history, months_in_year) model = ARIMA(diff, order=arima_order) model_fit = model.fit() yhat = model_fit.forecast()[0] yhat = inverse_difference(history, yhat, months_in_year) predictions.append(yhat) history.append(test[t]) # 计算样本外误差 rmse = sqrt(mean_squared_error(test, predictions)) return rmse # 评估 ARIMA 模型的 p、d 和 q 值组合 def evaluate_models(dataset, p_values, d_values, q_values): dataset = dataset.astype('float32') best_score, best_cfg = float("inf"), None for p in p_values: for d in d_values: for q in q_values: order = (p,d,q) try: rmse = evaluate_arima_model(dataset, order) if rmse < best_score: best_score, best_cfg = rmse, order print('ARIMA%s RMSE=%.3f' % (order,rmse)) except: continue print('Best ARIMA%s RMSE=%.3f' % (best_cfg, best_score)) # 加载数据集 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 评估参数 p_values = range(0, 7) d_values = range(0, 3) q_values = range(0, 7) warnings.filterwarnings("ignore") evaluate_models(series.values, p_values, d_values, q_values) |
运行示例会遍历所有组合,并报告那些没有错误收敛的组合的结果。该示例在现代硬件上运行需要两分钟多一点。
结果显示,发现的最佳配置是ARIMA(0, 0, 1),RMSE为939.464,略低于上一节中手动配置的ARIMA。这种差异可能具有统计显著性,也可能不具有。
|
1 2 3 4 5 6 7 |
... ARIMA(5, 1, 2) RMSE=1003.200 ARIMA(5, 2, 1) RMSE=1053.728 ARIMA(6, 0, 0) RMSE=996.466 ARIMA(6, 1, 0) RMSE=1018.211 ARIMA(6, 1, 1) RMSE=1023.762 最佳ARIMA(0, 0, 1) RMSE=939.464 |
我们将继续选择此ARIMA(0, 0, 1)模型。
6.3 检查残差误差
对模型进行良好最终检查是检查残差预测误差。
理想情况下,残差误差的分布应为零均值的正态分布。
我们可以通过使用汇总统计数据和图表来调查ARIMA(0, 0, 1)模型的残差误差来检查这一点。下面的示例计算并汇总了残差预测误差。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
# 汇总ARIMA预测残差 from pandas import read_csv from pandas import DataFrame from statsmodels.tsa.arima.model import ARIMA from matplotlib import pyplot # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return diff # 反转差分值 def inverse_difference(history, yhat, interval=1): return yhat + history[-interval] # 加载数据 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 准备数据 X = series.values X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] # 步进验证 history = [x for x in train] predictions = list() for i in range(len(test)): # 差分数据 months_in_year = 12 diff = difference(history, months_in_year) # 预测 model = ARIMA(diff, order=(0,0,1)) model_fit = model.fit() yhat = model_fit.forecast()[0] yhat = inverse_difference(history, yhat, months_in_year) predictions.append(yhat) # 观测 obs = test[i] history.append(obs) # 误差 residuals = [test[i]-predictions[i] for i in range(len(test))] residuals = DataFrame(residuals) print(residuals.describe()) # 绘图 pyplot.figure() pyplot.子图(211) residuals.hist(ax=pyplot.gca()) pyplot.子图(212) residuals.plot(kind='kde', ax=pyplot.gca()) pyplot.show() |
运行示例首先描述残差的分布。
我们可以看到,分布有向右的偏移,并且平均值非零,为165.904728。
这可能表明预测存在偏差。
|
1 2 3 4 5 6 7 8 |
count 47.000000 mean 165.904728 std 934.696199 min -2164.247449 25% -289.651596 50% 191.759548 75% 732.992187 max 2367.304748 |
还绘制了残差误差的分布图。
图表显示了高斯样分布,左尾凹凸不平,进一步证明了幂变换可能值得探索。
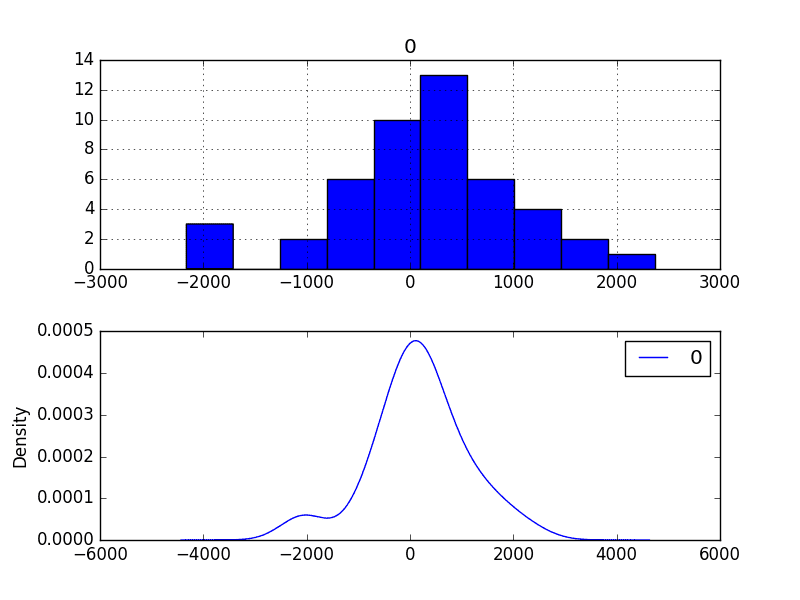
残差预测误差密度图
我们可以利用这些信息,通过在每个预测中加上平均残差误差165.904728来校正预测的偏差。
下面的示例执行了这种偏差关联。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
# 偏差校正预测的残差误差图 from pandas import read_csv from pandas import DataFrame from statsmodels.tsa.arima.model import ARIMA from matplotlib import pyplot from sklearn.metrics import mean_squared_error from math import sqrt # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return diff # 反转差分值 def inverse_difference(history, yhat, interval=1): return yhat + history[-interval] # 加载数据 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 准备数据 X = series.values X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] # 步进验证 history = [x for x in train] predictions = list() bias = 165.904728 for i in range(len(test)): # 差分数据 months_in_year = 12 diff = difference(history, months_in_year) # 预测 model = ARIMA(diff, order=(0,0,1)) model_fit = model.fit() yhat = model_fit.forecast()[0] yhat = bias + inverse_difference(history, yhat, months_in_year) predictions.append(yhat) # 观测 obs = test[i] history.append(obs) # 报告表现 rmse = sqrt(mean_squared_error(test, predictions)) print('RMSE: %.3f' % rmse) # 误差 residuals = [test[i]-predictions[i] for i in range(len(test))] residuals = DataFrame(residuals) print(residuals.describe()) # 绘图 pyplot.figure() pyplot.子图(211) residuals.hist(ax=pyplot.gca()) pyplot.子图(212) residuals.plot(kind='kde', ax=pyplot.gca()) pyplot.show() |
预测的性能从939.464略微提高到924.699,这可能具有统计显著性,也可能不具有。
预测残差误差的摘要显示,平均值确实非常接近零。
|
1 2 3 4 5 6 7 8 9 10 |
RMSE: 924.699 count 4.700000e+01 mean 4.965016e-07 std 9.346962e+02 min -2.330152e+03 25% -4.555563e+02 50% 2.585482e+01 75% 5.670875e+02 max 2.201400e+03 |
最后,残差误差的密度图确实显示出向零的小幅偏移。
这种偏差校正是否值得商榷,但我们暂时会使用它。
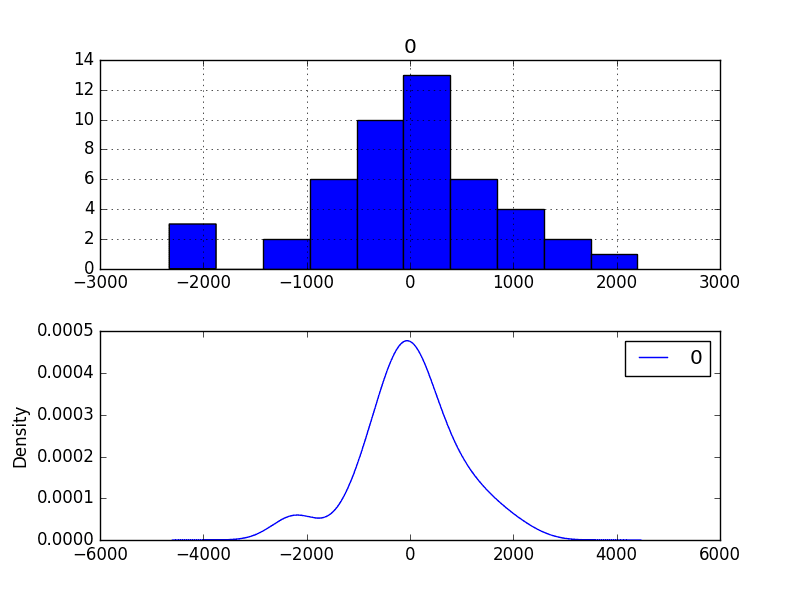
偏差校正后的残差预测误差密度图
检查残差误差的时间序列是否存在任何类型的自相关也是一个好主意。如果存在,则表明模型有更多机会对数据中的时间结构进行建模。
下面的示例重新计算残差误差,并创建ACF和PACF图以检查是否存在任何显著的自相关。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
# 偏差校正预测残差误差的ACF和PACF图 from pandas import read_csv from pandas import DataFrame from statsmodels.tsa.arima.model import ARIMA from matplotlib import pyplot from statsmodels.graphics.tsaplots import plot_acf from statsmodels.graphics.tsaplots import plot_pacf # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return diff # 反转差分值 def inverse_difference(history, yhat, interval=1): return yhat + history[-interval] # 加载数据 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 准备数据 X = series.values X = X.astype('float32') train_size = int(len(X) * 0.50) train, test = X[0:train_size], X[train_size:] # 步进验证 history = [x for x in train] predictions = list() for i in range(len(test)): # 差分数据 months_in_year = 12 diff = difference(history, months_in_year) # 预测 model = ARIMA(diff, order=(0,0,1)) model_fit = model.fit() yhat = model_fit.forecast()[0] yhat = inverse_difference(history, yhat, months_in_year) predictions.append(yhat) # 观测 obs = test[i] history.append(obs) # 误差 residuals = [test[i]-predictions[i] for i in range(len(test))] residuals = DataFrame(residuals) print(residuals.describe()) # 绘图 pyplot.figure() pyplot.子图(211) plot_acf(residuals, ax=pyplot.gca()) pyplot.子图(212) plot_pacf(residuals, ax=pyplot.gca()) pyplot.show() |
结果表明,时间序列中存在的少量自相关已被模型捕获。
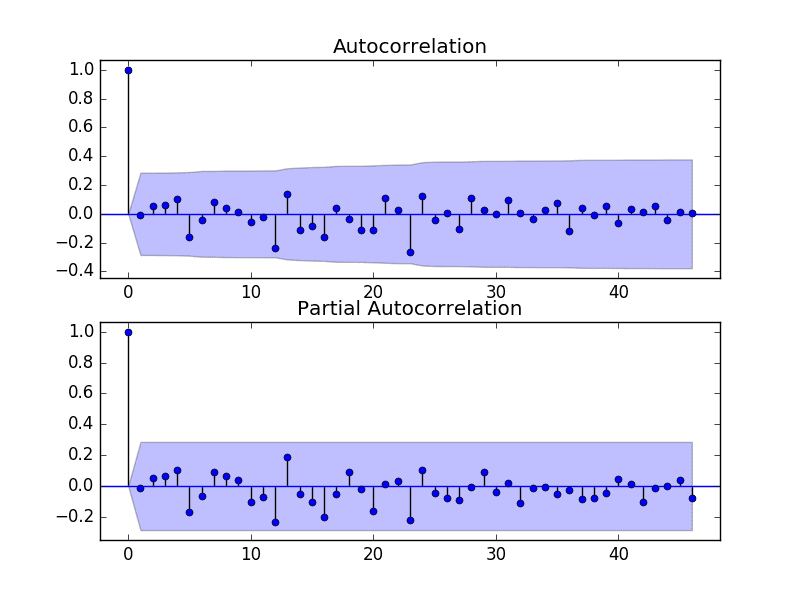
残差预测误差ACF和PACF图
7. 模型验证
在模型开发和选定最终模型后,必须对其进行验证和定稿。
验证是该过程的可选部分,但它提供了一个“最后检查”,以确保我们没有欺骗或误导自己。
本节包括以下步骤:
- 最终确定模型:训练并保存最终模型。
- 进行预测:加载已定型的模型并进行预测。
- 验证模型:加载并验证最终模型。
7.1 最终确定模型
模型的最终确定涉及在整个数据集上拟合ARIMA模型,在本例中是在整个数据集的转换版本上。
一旦拟合,模型可以保存到文件中以供以后使用。
下面的示例在数据集上训练ARIMA(0,0,1)模型,并将整个拟合对象和偏差保存到文件中。
下面的示例将拟合模型以正确的状态保存到文件中,以便以后可以成功加载。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 保存最终确定的模型 from pandas import read_csv from statsmodels.tsa.arima.model import ARIMA import numpy # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return diff # 加载数据 series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) # 准备数据 X = series.values X = X.astype('float32') # 差分数据 months_in_year = 12 diff = difference(X, months_in_year) # 拟合模型 model = ARIMA(diff, order=(0,0,1)) model_fit = model.fit() # 偏差常数,可以根据样本内平均残差计算 bias = 165.904728 # 保存模型 model_fit.save('model.pkl') numpy.save('model_bias.npy', [bias]) |
运行示例将创建两个本地文件:
- model.pkl 这是从调用ARIMA.fit()返回的ARIMAResult对象。它包括系数和拟合模型时返回的所有其他内部数据。
- model_bias.npy 这是作为一行一列NumPy数组存储的偏差值。
7.2 进行预测
一个自然的需求可能是加载模型并进行单次预测。
这相对简单,涉及恢复保存的模型和偏差并调用forecast()方法。为了反转季节性差分,还必须加载历史数据。
下面的示例加载模型,预测下一个时间步,并打印预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 加载最终模型并进行预测 from pandas import read_csv from statsmodels.tsa.arima.model import ARIMAResults import numpy # 反转差分值 def inverse_difference(history, yhat, interval=1): return yhat + history[-interval] series = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) months_in_year = 12 model_fit = ARIMAResults.load('model.pkl') bias = numpy.load('model_bias.npy') yhat = float(model_fit.forecast()[0]) yhat = bias + inverse_difference(series.values, yhat, months_in_year) print('Predicted: %.3f' % yhat) |
运行示例会打印出大约6794的预测值。
|
1 |
预测值:6794.773 |
如果我们查看validation.csv,我们可以看到下一时间段第一行的值为6981。
这个预测值大概是正确的。
7.3 验证模型
我们可以加载模型并以模拟的实际操作方式来使用它。
在测试套件部分,我们将原始数据集的最后12个月保存在一个单独的文件中,以验证最终模型。
我们现在可以加载这个validation.csv文件,并用它来查看我们的模型在“未见”数据上的表现如何。
我们有两种可能的方法:
- 加载模型并使用它预测未来12个月。超出前一两个月的预测技能会迅速下降。
- 加载模型并以滚动预测的方式使用它,为每个时间步更新转换和模型。这是首选方法,因为它是在实践中使用此模型的方式,因为它将实现最佳性能。
与前面章节中的模型评估一样,我们将以滚动预测的方式进行预测。这意味着我们将遍历验证数据集中的提前期,并将观测值作为历史的更新。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
# 在验证数据集上加载并评估最终模型 from pandas import read_csv from matplotlib import pyplot from statsmodels.tsa.arima.model import ARIMA from statsmodels.tsa.arima.model import ARIMAResults from sklearn.metrics import mean_squared_error from math import sqrt import numpy # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return diff # 反转差分值 def inverse_difference(history, yhat, interval=1): return yhat + history[-interval] # 加载和准备数据集 dataset = read_csv('dataset.csv', header=None, index_col=0, parse_dates=True, squeeze=True) X = dataset.values.astype('float32') history = [x for x in X] months_in_year = 12 validation = read_csv('validation.csv', header=None, index_col=0, parse_dates=True, squeeze=True) y = validation.values.astype('float32') # 加载模型 model_fit = ARIMAResults.load('model.pkl') bias = numpy.load('model_bias.npy') # 进行第一次预测 predictions = list() yhat = float(model_fit.forecast()[0]) yhat = bias + inverse_difference(history, yhat, months_in_year) predictions.append(yhat) history.append(y[0]) print('>Predicted=%.3f, Expected=%.3f' % (yhat, y[0])) # 滚动预测 for i in range(1, len(y)): # 差分数据 months_in_year = 12 diff = difference(history, months_in_year) # 预测 model = ARIMA(diff, order=(0,0,1)) model_fit = model.fit() yhat = model_fit.forecast()[0] yhat = bias + inverse_difference(history, yhat, months_in_year) predictions.append(yhat) # 观测 obs = y[i] history.append(obs) print('>预测值=%.3f, 实际值=%.3f' % (yhat, obs)) # 报告表现 rmse = sqrt(mean_squared_error(y, predictions)) print('RMSE: %.3f' % rmse) pyplot.plot(y) pyplot.plot(predictions, color='red') pyplot.show() |
运行示例将打印出验证数据集中时间步长的每个预测值和期望值。
验证期的最终RMSE预测为3.6111亿销售额。
这比每月超过9.24亿销售额的误差预期要好得多。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
>预测值=6794.773,期望值=6981 >预测值=10101.763,期望值=9851 >预测值=13219.067,期望值=12670 >预测值=3996.535,期望值=4348 >预测值=3465.934,期望值=3564 >预测值=4522.683,期望值=4577 >预测值=4901.336,期望值=4788 >预测值=5190.094,期望值=4618 >预测值=4930.190,期望值=5312 >预测值=4944.785,期望值=4298 >预测值=1699.409,期望值=1413 >预测值=6085.324,期望值=5877 RMSE: 361.110 |
同时还提供了预测与验证数据集的比较图。
在此图的尺度上,12个月的预测销售数据看起来非常棒。
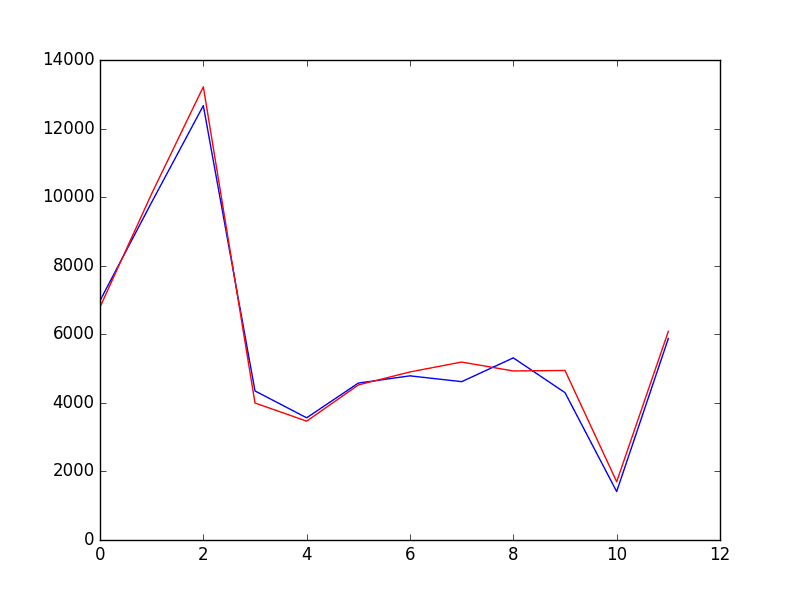
香槟销量验证数据集预测
总结
在本教程中,您发现了使用 Python 进行时间序列预测项目的步骤和工具。
本教程涵盖了大量内容;具体而言
- 如何开发具有性能度量和评估方法的测试框架,以及如何快速开发基线预测和技能。
- 如何使用时间序列分析来提出关于如何最佳地对预测问题进行建模的想法。
- 如何开发 ARIMA 模型、保存它,然后稍后加载它以对新数据进行预测。
您做得怎么样?您对本教程有任何疑问吗?
在下面的评论中提出你的问题,我会尽力回答。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。






谢谢你,Jason。
您会向初学者推荐这个例子吗?我完全是编程和机器学习的新手,目前正在学习Python语法并理解所用算法的基本术语。
此致,
本森
您好,Benson,本教程是时间序列预测初学者的一个示例,但确实假设您首先了解Python(或者您可以快速掌握)。
当然,这肯定是一个陡峭的学习曲线,让你走出舒适区,但这正是学习的方式。?
当然。投入其中吧!
你好,Jason,我能联系你讨论一下吗?需要解释一下。
您可以通过联系页面随时通过电子邮件联系我
https://machinelearning.org.cn/contact/
Jason,感谢您关于如何构建模型的详细说明。当我在验证集中(手动)添加一些额外的周期用于数据集之外的短期预测时,模型无法运行,直到我提供一些“虚假”目标(预期y)。然而,当我提供一些虚假目标时,我看到模型会迅速根据这些目标进行调整。我尝试了不同级别的y值,我看到模型相应地进行了预测,难道预测不应该与它看到的目标无关吗?
您不需要虚假目标,Viral。
您可以通过在所有可用数据上训练模型并进行一步预测来预测一个新的样本外数据点。例如:
Jason,非常感谢您的回复。我想表达的是,模型应该预测相同的输出,无论观测结果如何。例如,当我更改验证集中的y值(模型未曾见过的最后12个月)时,我的预测会发生变化,并且模型每次都能给我一个非常好的RMSE。如果模型训练得当,那么无论我在验证集中的y值如何,它都应该对未来12个月给出相同的输出。我认为如果您也更改验证集中的y值,您会很快看到这种效果。除非模型只对一个周期有效,并且需要根据上一周期的观测值进行持续调整。
在这种特定情况下,我们使用带有为一步预测训练的模型的滚动式验证。
这意味着当我们遍历验证数据集时,观测值从验证集移到训练集,并重新拟合模型。这是为了模拟在对时间步进行预测后有新的观测值可用,并且我们能够相应地更新模型。
我想您所说的是多步预测,例如在所有训练数据上拟合模型,然后预测接下来的n个时间步。这不是这里的实验设置,但欢迎您尝试。
你好 Jason,
如果您不介意我问,下面的代码行应该放在哪里?
yhat = model_fit.forecast()[0]
你好本森,
在所有数据上拟合ARIMA模型。
之后,通过调用forecast()函数对下一个时间步进行预测。
是时候升级到matplotlib 2.0了,颜色更漂亮了 🙂
我同意Juanlu!我最近也升级了。
亲爱的 Jason,
谢谢你的帖子。清晰、简洁且有效。
你有没有考虑过使用SARIMA模型来预测TS,而不是先减去季节性再添加回来?事实上,statsmodel在它的开发版本中已经集成了这个功能。(https://statsmodels.cn/dev/generated/statsmodels.tsa.statespace.sarimax.SARIMAX.html)
我很好奇是否有可能在Python中使用分层结构,例如将法国香槟的月度销售预测分解为目的地市场的子预测。
谢谢,请继续发帖!
嗨,Hugo,是的,我熟悉SARIMA,但我决定将示例限制在ARIMA。
是的,只要您有数据来训练/验证模型。我建议从每个案例的独立模型开始,使用所有可用数据,然后在此之后进一步优化。
感谢您精彩的帖子,Jason,
两个小问题
1.
当我用您的示例进行Grid Search ARIMA超参数调整时,我的机器上速度很慢,花了大约1分钟。然而,参数范围和数据一点都不大。是不是我的机器速度慢?我担心模型太慢而无法使用。
2.
ARIMA支持多步预测吗?例如,如果我一直将预测值用于下一次预测,会不会过拟合?
谢谢!
您的时间听起来没问题。如果对您来说太慢,可以考虑使用数据的一个子样本。
您可以直接进行多步预测(forecast()函数)或递归使用ARIMA模型
https://machinelearning.org.cn/multi-step-time-series-forecasting/
提前感谢。
你好,Jason
感谢您对时间序列的精彩实践。但我有一个疑问。
我从日期列中提取了年份和月份作为模型的特征。然后我建立了一个线性回归模型和一个随机森林模型。我的最终预测是这两个模型的加权平均。我得到了366的RMSE(与您的361在验证数据上相似)。
这种方法可以替代ARIMA模型吗?这种方法可能有哪些缺点?
感谢您的评论
谢谢
干得好。如果模型复杂性在项目中很重要,ARIMA可能是一个更简单的模型。
嗨,只是一个小小的建议,您考虑过在evaluate_models()函数中使用itertools吗?
https://pastebin.com/w0apb6Tg
在Python中,嵌套循环可读性不太好。
感谢您的建议。
Jason,我刚详细阅读了“Python时间序列预测入门”,有两个问题
* 您是否计划很快推出“Python时间序列预测中级课程”?
* 您在前几章中讨论了如何使用滞后特征将时间序列问题重新构建为典型的机器学习问题。然而,在后面的章节中,您只使用ARIMA模型,这消除了显式生成滞后特征的必要性。将显式生成的时间序列特征与其他机器学习算法(如SVM或XGBoost)结合使用的最佳方法是什么?
(我尝试了几个带有XGB的AR滞后,并获得了不错的结果,但不知道如何结合MA部分)。
感谢您的任何见解。
我将来可能会有一本更高级的时间序列书籍。
好问题。您需要手动计算MA特征。
嗨,Jason,
是不是如果一年中缺少月份,TimeGrouper()就无法工作?另外,TimeGrouper()没有可用的文档。您将来可以在示例中使用pd.Grouper吗?
此致
我认为它确实适用于缺失数据,允许您重新采样。
TimeGrouper没有文档,但Grouper有,这是一个很好的开始
https://pandas.ac.cn/pandas-docs/stable/generated/pandas.Grouper.html
你好,
感谢这个关于时间序列的精彩链接。
我无法访问存储在以下位置的数据集:- https://datamarket.com/data/set/22r5/perrin-freres-monthly-champagne-sales-millions-64-72#!ds=22r5&display=line
此致,
Sambit
很抱歉听到这个消息,这是完整的数据集
你好,
我遇到了以下错误
X = X.astype(‘float32’)
ValueError: could not convert string to float: ‘1972-09’
您能帮帮我吗?
谢谢
看起来您可能遗漏了一些代码行。确认您都已复制。
嗨,Jason,我也遇到了同样的错误。我检查了代码行,它们都存在。Python如何将“yyyy-mm”转换为float32?
我从您上面给出的datamarket链接下载了csv文件。
我错过了什么?
谢谢
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨 Jason,时间序列预测方法很棒。感谢您的这篇文章。
只是有一个小疑问,这里我们使用RMSE作为度量在测试数据上调整ARIMA参数,但通常我们会在训练(训练+验证)数据上调整参数,然后通过使用测试数据来检查这些参数是否很好地泛化。这样对吗?
因为我担心的是,如果我们在特定的测试数据上选择参数,这些参数是否会泛化到即将到来的新测试数据?我觉得在选择参数时会有偏差,因为我们专门选择那些对该测试数据产生较低RMSE的参数。这里我们没有检查我们的模型是否对训练数据工作/拟合良好?
如果我错了,请纠正我。请告诉我基于测试数据进行参数调整的逻辑是什么?
是的,那是一种偏差较小的模型准备方式。
更多信息在这里
https://machinelearning.org.cn/difference-test-validation-datasets/
非常感谢Jason。
不客气,sandip。
嗨,Jason,
感谢您这篇详细而清晰的教程。
我有一个关于寻找ARIMA参数的问题。我不明白为什么我们有一个嵌套的“for”循环,我们考虑了所有p值,而不是所有q值。
如果问题不清楚,请提问。
先谢谢您了。
请再次查看示例,我们对p、d和q值进行网格搜索。
嗨,Jason,
感谢这个很棒的例子!它帮了我很多!但是,如果您不介意,我有一个关于预测循环的问题。
在预测循环中,您为什么使用`history.append(obs)`而不是`history.append(yhat)`?看起来您将观察(测试中的真实数据)添加到历史中。而`yhat = bias + inverse_difference(history, yhat, months_in_year)`是基于历史数据的。但实际上,在解决实际问题时我们并没有这些观察数据。
我尝试在我的模型中使用`history.append(yhat)`,但结果比使用`history.append(obs)`差。
感谢您的评论
谢谢,
Ella
好问题,因为在这种情况下,我们假设在每次预测之后,新的真实观测值都是可用的。
假设我们每天运行一次此循环,并且我们今天早上获得了昨天的观测值,以便我们可以准确预测明天。
非常感谢您的解释!!
不客气。
你好,
非常感谢这项工作。
我有一个关于步进式验证的讨论点。
我看到您在每次迭代时都用测试集中的值填充历史部分
.....
# 观察
obs = test[i]
history.append(obs)
....
我们真的必须这样做,还是必须使用为下一次预测计算出的新 yhat?
确实,当我们必须对某个日期范围进行未来预测时,我们没有历史值……
谨致问候,并提前感谢您的反馈
Simo
这取决于您的模型和项目目标。
在这种情况下,我们假设在每个建模步骤之后,真实的观测值都可用,并且可以用于下一次预测的制定,这是一个合理的假设,但通常不是必需的。
如果您使用输出作为输入(例如递归多步预测),误差将累积,情况会更快地变得更糟(例如模型技能会下降)。请参阅此帖子
https://machinelearning.org.cn/multi-step-time-series-forecasting/
抱歉,我刚看了Ella的问题……所以对于长期未来预测,我们必须使用yhat……
谢谢
您可以选择这样做。
你好,
这些步骤之后我得到了NAN
from pandas import Series
series = Series.from_csv(‘champagne.csv’, header=0)
print(len(series))
split_point = len(series) – 12
print(split_point)
dataset, validation = series[0:split_point], series[split_point:]
print(dataset)
print(‘Dataset %d, Validation %d’ % (len(dataset), len(validation)))
dataset.to_csv(‘dataset.csv’)
validation.to_csv(‘validation.csv’)
我很抱歉听到这个消息。
确保您已复制所有代码,并且已从数据文件中删除页脚。另请确认您的环境是最新的。
嗨,Jason,
这非常有用。非常感谢!
我想知道您是否能提供完整的代码,以将预测延长一年。我知道您上面提到有一个预测函数,但是当我运行
yhat = model_fit.forecast()[0]
pyplot.plot(y)
pyplot.plot(yhat, color=’green’)
pyplot.plot(predictions, color='red')
pyplot.show()
我的代码中没有任何绿线。我确信我在这里遗漏了很多东西,但我不知道是什么。
再次感谢,非常感谢!
这篇文章将帮助您进行长期预测
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
嗨,Jason,
我正在使用这些建模步骤来解决我的问题。当我传入从网格搜索中获得的最佳参数进行预测时,我得到了线性代数错误,有时甚至不收敛。
因此我无法预测值。
我的第二个问题是,如果网格搜索出现这种情况,我如何在生产环境中自动化脚本。假设我需要为50000个不同的站点预测一些值,那么实现这个目标的最佳方法是什么?
很抱歉听到这个消息,也许您没有将所有参数都设置为与网格搜索中使用的相同?
我这里有一些关于生产中模型的笔记,可能会有帮助
https://machinelearning.org.cn/deploy-machine-learning-model-to-production/
嗨,Jason,
感谢您的帖子,对我非常有帮助。太棒了!
我有一个小问题
在帖子中,您使用了2个数据集:dataset.csv 和 validation.csv
+ 在 dataset.csv 中,您将其拆分并使用步进式验证 -> 我完全同意。
+ 在 validation.csv 中,您仍然使用步进式验证重新训练 ARIMA 模型 (model_fit = model.fit(trend=’nc’, disp=0) – 第7.3节第45行) -> 我认为这是用于测试的未见数据,所以我们不在这里训练模型,只测试模型的性能。这样对吗?
在步进式验证的情况下,我们假设在预测时间之后,真实的观测值是可用的。
您可以在评估模型时做出不同的假设。
嗨,Jason
首先,感谢您精彩的教程。
到目前为止(第5.4部分),我只有一个疑问:为什么您在没有首先去除趋势的情况下绘制了直方图/核密度估计?如果目标是查看分布形状是否与高斯分布相似,难道趋势不会改变数据的分布吗?
谢谢
Navid
好问题,在那个时候我们处于分析的早期阶段。通常,我建议在使序列平稳之前和之后查看密度图。
如果我们进行简单的线性操作,趋势消除通常不会影响分布的形式。
嗨,Jason,
感谢您精彩的帖子。如果我只有一年的数据,您能解释一下如何在函数 `difference` 中设置 'interval' 吗?我的数据集以半小时为单位记录,从2016年6月到2017年6月。这些数据在夏季很大,冬季很小,即冬季在0-2000之间,但夏季在5000-14000之间。
嗨,Jason,
感谢您的发帖。我想实现“ARIMA”函数,而不是使用内置函数。
您知道在哪里可以找到实现“ARIMA”函数的算法以及详细理解它的信息吗?
一本关于数学的好教材是这本:http://amzn.to/2zvfIcB
嗨,Jason,
感谢您关于时间序列预测的简要教程。我在运行ARIMA模型代码片段时收到了错误“给定一个pandas对象,索引不包含日期”。
请确保您已精确复制所有示例代码,包括缩进,并确保您已准备好数据,包括从文件中删除页脚信息。
亲爱的 Jason,
感谢您精彩的教程!
我唯一的问题是当我运行滚动预测时。
我使用了一个不同的数据集,其中包含一天中每分钟的温度值。我用前四天的数据训练模型,并用最后一天的数据作为测试数据集。我的问题可能是我将测试观察值添加到了历史记录中,并且我的ARIMA返回以下错误:`raise ValueError("The computed initial AR coefficients are not "`
ValueError:计算出的初始 AR 系数不平稳
您应该引入平稳性,选择不同的模型顺序,或者您可以
传递您自己的 start_params。
for i in range(0, len(x_test))
# 差分数据
diff = difference(history, minutes)
# 预测
model = importer.ARIMA(diff, order=(5, 0, 1))
model_fit = model.fit(trend=’nc’, disp=0)
yhat = model_fit.forecast()[0]
yhat = inverse_difference(history, yhat, minutes)
predictions.append(yhat)
# 观察
obs = x_test[i]
history.append(obs)
print(‘Predicted=%.6f, Expected=%.6f’ % (yhat, obs))
我的 x_test 数据集包含 1440 行,我在循环的第 1423 次迭代时得到错误。直到第 1423 次迭代,每个 ARIMA 模型都没有问题。
您的帮助对我来说非常宝贵。
再次感谢!
最诚挚的问候,
Makis
您是否确认您的数据集是平稳的?也许仍然存在一些趋势或季节性结构?
我有很多关于去趋势和季节性调整的帖子可能会有帮助。
亲爱的 Jason,
感谢您的回复!
我改为使用了不同的超参数(Arima 5,1,1),然后一切都正常了。我不知道这是否正确,因为5,0,1和5,1,1的RMSE完全相同。您对此有何看法?请问,最后一个问题,我现在的结果非常好,RMSE小于0.01。图中的预测线几乎与真实数据线重叠。这是否与history.append(obs)有关?我不太明白为什么测试观测值会被添加到历史记录中。在for循环中为每一步使用新模型进行预测与在一个模型中使用steps参数进行预测有什么区别?
抱歉问题很长!
您的教程甚至比我目前正在阅读的书籍还要好!
来自希腊的问候。
干得好。我建议使用技能高且稳定的模型。
嘿,Jason!我想说的是,也许好的预测是因为我将 y 观测值附加到历史记录中。我们为什么要这样做?目的是什么?如果我们不附加 y 观测值,结果仍然有效吗?
在测试设置中,我们假设在每次预测之后都会进行实际观测,我们可以反过来利用这些观测进行下一次预测。
您的问题的具体框架可能有所不同,我鼓励您设计一个测试工具来捕获这一点。
嘿,Jason,再次感谢您的反馈!
我马上会采纳您的建议 🙂
感谢一切
此致,
Makis
嘿,Jason,最后一个问题。
既然我采用滚动预测方式,并且每次迭代都引入一个新模型,那么我为什么需要保存一个模型并以此进行第一次预测呢?
我可以直接将滚动预测循环从0开始而不是1吗?
当然可以。
嗨,Jason,
非常感谢您这篇精彩的教程。它真的帮助我学习了时间序列预测,并为我的新工作做准备。我是一个数据分析/科学的完全初学者,因为我目前正在从工程学转到数据分析。
但是我在这篇教程中遇到的问题是,当我运行代码时,我卡在了最后一步,“验证模型”。我尝试多次重新复制和重新运行示例代码,但似乎都没有用。这是错误。
>预测值=10101.763,期望值=9851
>预测值=13219.067,期望值=12670
>预测值=3996.535,期望值=4348
>预测值=3465.934,期望值=3564
>预测值=4522.683,期望值=4577
>预测值=4901.336,期望值=4788
>预测值=5190.094,期望值=4618
>预测值=4930.190,期望值=5312
>预测值=4944.785,期望值=4298
>预测值=1699.409,期望值=1413
>预测值=6085.324,期望值=5877
>Predicted=7135.720, Expected=nan
ValueError 回溯 (最近一次调用)
in ()
56
57 # 报告性能
—> 58 mse = mean_squared_error(y, predictions)
59 rmse = sqrt(mse)
60 print(‘RMSE: %.3f’ % rmse)
/Users/amir/Library/Enthought/Canopy/edm/envs/User/lib/python3.5/site-packages/sklearn/metrics/regression.py in mean_squared_error(y_true, y_pred, sample_weight, multioutput)
229 “””
230 y_type, y_true, y_pred, multioutput = _check_reg_targets(
–> 231 y_true, y_pred, multioutput)
232 output_errors = np.average((y_true – y_pred) ** 2, axis=0,
233 weights=sample_weight)
/Users/amir/Library/Enthought/Canopy/edm/envs/User/lib/python3.5/site-packages/sklearn/metrics/regression.py in _check_reg_targets(y_true, y_pred, multioutput)
73 “””
74 check_consistent_length(y_true, y_pred)
—> 75 y_true = check_array(y_true, ensure_2d=False)
76 y_pred = check_array(y_pred, ensure_2d=False)
77
/Users/amir/Library/Enthought/Canopy/edm/envs/User/lib/python3.5/site-packages/sklearn/utils/validation.py in check_array(array, accept_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, warn_on_dtype, estimator)
405 % (array.ndim, estimator_name))
406 if force_all_finite
–>> 407 _assert_all_finite(array)
408
409 shape_repr = _shape_repr(array.shape)
/Users/amir/Library/Enthought/Canopy/edm/envs/User/lib/python3.5/site-packages/sklearn/utils/validation.py in _assert_all_finite(X)
56 and not np.isfinite(X).all())
57 raise ValueError(“Input contains NaN, infinity”
—> 58 ” or a value too large for %r.” % X.dtype)
59
60
ValueError: 输入包含 NaN、无穷大或对于 dtype('float32') 来说太大的值。
您能帮我解决这个问题吗?
非常感谢。
Amir
我不确定您错误的原因,抱歉。
请确保您的库是最新的,并且您已精确复制了所有代码?
csv文件包含一些术语文本,在将文件读取为列表之前应将其删除。
嗨,Jason,
在预测区域,您将观测值添加到历史记录中,然后运行循环以查找 ARIMA 结果。
即
model = ARIMA(history, order=(4,1,2))
model_fit = model.fit(disp=0)
output = model_fit.forecast()
yhat = output[0]
predictions.append(yhat)
obs = test[t]
history.append(obs)
这里,如果我们把yhat加到历史记录中会怎么样,当我把yhat加到历史记录中时,我的结果真的很差,请帮帮我..
因为根据我的模型,我们需要仅使用训练数据来预测测试数据,所以我们不能使用obs附加到历史记录中,希望您理解我的意思。
是的,那将被称为递归多步预测。这很有挑战性。您可以在这里了解更多信息
https://machinelearning.org.cn/multi-step-time-series-forecasting/
概念上我理解什么是递归多步预测,这和我之前回复的代码中使用的方法一样,我把观测值(obs)追加到历史数据中,所以这意味着每次循环运行时,它都会使用现有的训练数据 + 下一个观测值,这应该能正常工作并正确预测,但我的结果非常糟糕。
或者你的意思是,为此我们需要在循环中绘制 ACF、PACF 图来确定 p、d、q 值,然后根据这些 p、d、q 值运行 ARIMA 函数,如果真是这样,请帮助我们找到一种在循环中确定 p、d、q 值的方法。
通常,在递归模型中使用预测具有挑战性,您可能需要对您的模型进行创新。
你好 Jason,
感谢您的清晰直白的帖子!
我也有和 Nick 一样的问题——关于微分间隔的选择。
在您的示例中,您根据数据的预期周期将其设置为 12。
然而,在更具问题性的情况下,数据似乎并未暗示一个清晰的周期(尽管有 ACF 和 PACF 图)。
在我的案例中,我发现将间隔设置为 12 比我默认的 1 产生了更好的结果。我能理解为什么选择一个小的间隔通常不好——随机噪声太占主导地位。我更难理解如何为我的数据校准理想的间隔值(除了暴力破解法。也许我不应该校准?那可能会导致过拟合。无论如何,我仍然应该找到一个普遍合适的值)。
如果数据量相对较小,可以考虑对不同的值进行网格搜索,看看哪种效果最好。
还有另一个问题。我应用了网格搜索来选择我的 ARIMA 模型的超参数。我担心在这种情况下偏差校正可能会适得其反。
您对此有什么见解吗?您会同时执行两者(网格搜索后进行偏差校正)吗?答案是否依赖于数据?
我只会在它提高模型技能时(例如,如果模型有偏差)执行偏差校正。
嗨,Jason,
我有大约 1000 多种产品。我有每种产品过去 7 年的年度销售历史数据。我想开发一个模型,通过它我可以预测未来 3 年的销售额。
请您帮我,我该如何进行评估、预测、验证和解释这些数据。
提前感谢。
也许从这里开始
https://machinelearning.org.cn/start-here/#timeseries
(菜鸟的并行化问题,可能)
有没有人知道 statmodels ARIMA 是否使用多线程或任何其他类型的并行化?
我正在尝试在我的笔记本电脑上运行基于多个 ARIMA 拟合的分析,而线程并行化反而增加了总运行时间而不是减少。看来单个 ARIMA 拟合(单个线程的一部分)一次使用了几个处理器……
谢谢,
乌迪
我认为它是单线程的。
嗨,Jason,
这是一篇非常棒的文章,非常有帮助。我有两个关于扩展的问题,可能已经被问过,但在阅读评论后,我不确定相同的建议是否适用于我。我的问题与 Nirmal 的最相似。
1. 我有一个包含多种“葡萄酒”的数据集,每种葡萄酒都有自己的历史销售数据
2. 这个数据集还有其他不只是时间相关的变量。
例如,
第 1 个月销售额 第 2 个月销售额 第 3 个月销售额 在线评论,
葡萄酒 A
葡萄酒 B
葡萄酒 C
葡萄酒 D
我想知道这个时间序列模型是否有扩展版可以考虑其他变量和其他历史数据实例。如果需要澄清,请告诉我。
感谢您抽出时间进行澄清。
是的,也许您可以单独建模每个序列,或一组序列,或全部一起,或所有这三种方法并集合结果。
另外,我建议转向其他模型,例如机器学习或甚至 MLP 模型。
我希望很快能更详细地讨论这个话题。
感谢您的快速回复。
我会尝试你的第一个方法。
但是您有什么好的 ML/MLP 模型/教程可以开始吗?没有也没关系!我注意到您在这里有一篇关于多元时间序列的好文章
https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/
我还没读完,但我认为它只考虑了一个变量的多个实例的历史数据。
我认为找出如何整合我的结果会很有趣
#1. 历史数据的一个实例(葡萄酒 A 最近 3 个月的销售额)
#2. 非历史变量的一个实例(葡萄酒 A 的在线评论、类型等)
对我来说,#1 的输出是用于 #2 的 ML 模型中的一个“变量”。如果这说得通,你认为这是处理事情的正确方式吗?
感谢您的及时回复!
我希望很快能更详细地讨论这个话题——也许写一本关于这个话题的书,从许多不同的方向处理一个数据集。
感谢 Jason!真正让像我这样的机器学习从业者在机器学习领域表现出色。
在这篇博客中,您提到结果表明时间序列中存在的微小自相关已被模型捕获。
如果存在高度自相关,下一步该怎么做?
提前感谢。
很好的问题!
一些想法
——也许尝试其他模型。
——也许改进数据准备。
——也许尝试下游模型以进一步校正预测。
嗨,Jason,
这是一篇非常有见地的文章!我正在尝试对每周数据进行预测。有什么改进模型的技巧吗,因为每周数据很难预测。另外,用于差分的“months_in_year = 12”是否应该更改为“weeks_in_month = 4”以适应每周频率?
谢谢
我最好的建议是尝试多种数据准备技术,并使用网格搜索调整 ARIMA。
嗨,Jason,
感谢您的精彩教程!
只有一个快速问题:您能为第一种情况(非滚动向前预测)提供解决方案吗?
——加载模型并用它来预测未来 12 个月。超过前一两个月的预测能力将迅速下降。
谢谢~
是的,这会有帮助
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
嗨 Jason
我的时间序列数据也是非平稳的,我尝试了高达 3 阶的差分,之后由于数据耗尽,我无法继续。它有 3 个计算点,在进行 Fuller 检验以检查平稳性时,它报错“maxlag should be < nobs”。我该怎么办?
听起来您的序列数据可能不够。也许您需要更多的观测值?
您好,谢谢。
我想知道 Python 的预测是否比 Aperia 等其他预测软件更好。
为了预测销售额,我们必须以历史数据和基线为基础,但实际上,在工业中,有许多因素会使我们预测的计算复杂化,例如营销活动、特殊客户订单等。我们如何在预测中考虑这些干扰,以确保良好的准确性值。
谢谢您的回答。
什么是 Aperia?
额外的元素可以在模型中用作外生变量。
Jason,
我拥有的数据集需要进行二次差分才能使其平稳,所以我使用了
diff1 = difference(history, 12)
diff2 = difference(diff1, 12),
它奏效了,并通过 ADF 测试使其平稳,但是,我该如何将其反向转换回来呢?
谢谢你
把这些值加回去。这需要您保留原始数据和第一次差分后的数据。
谢谢,那么函数会是这样吗?
yhat = inverse_difference(diff1, yhat, interval)
yhat = inverse_difference(history, yhat, interval) ?
谢谢!
正确。
首先,这是一篇很棒的文章,写得很好,很详细。我有一个关于在所有分析中使用测试集的问题。将此模型投入生产会怎么样?您不会有每次迭代的“test[i]”(或“y[i]”)添加到“history”列表中以获得真正泛化的预测。
我的观点是,与其添加测试集中的值(“y[i]”、“test[i]”),您宁愿将正在进行的预测添加到训练集中,以进行真正的随机游走。
再次感谢您的资源以及提供这些内容的所有帮助。
最终模型将通过对所有可用数据进行训练,然后用它来预测未来。
您可以在此处了解有关最终模型的更多信息
https://machinelearning.org.cn/train-final-machine-learning-model/
您可以在此处了解有关进行样本外预测的更多信息
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
我一直收到错误
—————————————————————————
TypeError Traceback (most recent call last)
in ()
9 obs = test[i]
10 history.append(obs)
—> 11 print('Predicted=%.3f, Expected=%3.f' % (yhat, obs))
TypeError: must be real number, not ellipsis
即:# 预测
yhat = …
这三个点(省略号)会抛出错误。
代码中到处都是…有什么办法可以修复这个错误吗?
带有“……”的代码只是示例代码,不用于执行。跳过它。
詹姆斯,也许应该更仔细地阅读一下教程?
我在第 6.3 节“绘制残差”中残差的 PACF 图中遇到了问题。我完全按照您的代码操作,ACF 图与此处显示的完美匹配,而 PACF 在 36-38 滞后处绘制的值接近 8。有什么可能导致这种情况的吗?
嗨,Jason,
非常感谢这个教程。不过有一件事。由于 series.from_csv 已被弃用,因此在打开数据集时日期格式会丢失,例如在尝试生成季节性折线图时。您是否知道一种在使用 read_csv 而不是 from_csv 时可以保留日期格式的解决方法?
谢谢!
是的,您可以使用 pandas.read_csv() 并传入相同的参数。
如何提高每年季节性折线图的可读性(尤其是在轴方面)?我将不胜感激您的帮助。
也许每个图创建一张图片?
我宁愿比较所有子图。
也许将它们全部绘制在同一张图上?
也许计算差异并绘制出来?
嗨,Jason,
我能够进行预测,图表看起来不错。只是想知道我们如何预测未来,我的意思是如果我想看下个月的预测,我们该怎么做?
谢谢,
欣坦
我在这里展示如何做
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
嗨 Jason,我处理每日数据集。当我尝试 months_in_year = 364 时有什么问题?我的意思是当我设置 months_in_year = 364 时,它并没有抛出 best_arima。我能知道原因吗?
你为什么要进行这种更改?我不明白?
亲爱的 Jason,
非常感谢您的教程。我想将其应用于一个流程,预测一些流程变量。时间间隔不是基于月度的,如您的示例所示,而是短得多,例如几天,数据收集大约每三秒一次。
现在我想问一些问题。
您认为这个模型也能同样好地工作吗?
我应该在“months_in_year”的位置放什么?目前我放了 7,这是我数据集中不同天数的数量。
2000 多个点的情况下,寻求最优参数的矩阵分析需要很长时间是正常的吗?(例如,30 分钟后才得到一个三元组)如果是这样,我如何提高代码速度?
再次感谢您,
祝好,
帕特里克。
试试看吧。
2K 个点可能对于这种方法来说太多了,也许可以尝试减少到最多几百个。
嗨
上面的代码中的列“A”来自哪里?
groups = series['1964':'1970'].groupby(TimeGrouper('A'))
y
打印出来的组只包含每年头 6 个月的数据,为什么?
就在那里
https://pandas.ac.cn/pandas-docs/stable/timeseries.html#offset-aliases
嗨
如果我们不自己定义差分函数,而是直接传入 d=12 的值,那会有什么问题吗?
model = ARIMA(diff, order=(0,12,1))
这样不是一样的吗?
谢谢!
应该是一样的。
嗨 Jeson,在运行您的代码时,我收到此错误
raise ValueError(“计算出的初始 MA 系数不可逆”)。
ValueError: The computed initial MA coefficients are not invertible
您应该强制执行可逆性,选择不同的模型顺序,或者您可以
传递您自己的 start_params。
我该如何解决呢?谢谢。
听到这个消息我很难过。
也许确认您的 statsmodels 和其他库是最新的?
也许确认您按照顺序复制了所有代码?
也许尝试替代的模型配置?
好的,我修改了 ARIMA 参数,现在可以了,谢谢!
很高兴听到这个消息!
这是我的数据:例如……
名称 月份 数量 单位
线材总量 2007 年 1 月 93798 吨
线材总量 2007 年 2 月 86621 吨
线材总量 2007 年 3 月 93118 吨
我的代码是
import pandas as pd
from sklearn.metrics import mean_squared_error
from math import sqrt
# 加载数据
path_to_file = “C:/Users\ARAVIND\Desktop\jupyter notebook\project\datasets.csv”
data = pd.read_csv(path_to_file, encoding='utf-8')
# 准备数据
X = data.values
X = X.astype(‘float32’)
train_size = int(len(X) * 0.50)
train, test = X[0:train_size], X[train_size:]
# 步进验证
history = [x for x in train]
predictions = list()
for i in range(len(test))
# 预测
yhat = history[-1]
predictions.append(yhat)
# 观察
obs = test[i]
history.append(obs)
print('Predicted=%.3f, Expected=%3.f' % (yhat, obs))
# 报告表现
mse = mean_squared_error(test, predictions)
rmse = sqrt(mse)
print('RMSE: %.3f' % rmse)
当我运行此命令时,它显示“ValueError: 无法将字符串转换为浮点数”……所以有没有人可以告诉我如何根据我的数据集将字符串转换为浮点数……我想将“名称、月份和单位”列转换为浮点数。
或许移除文本和日期数据?
好的先生。谢谢
嗨 Jason,感谢这个精彩的教程。
但是,当我在时间序列上运行它时,我收到了以下错误
ValueError: The computed initial MA coefficients are not invertible
您应该强制执行可逆性,选择不同的模型顺序,或者您可以
传递您自己的 start_params。
我刚刚看到这个问题已经得到了解答,并且我按照答案操作后成功了。谢谢!
也许尝试不同的 q/d/p 变量配置用于模型?
这确实是一个非常有用的教程。谢谢你 Jason!!
我有一个小问题。我执行此代码后收到 TypeError: a float is required 错误——
history = [x for x in train]
predictions = list()
for i in range(len(test))
# 预测
yhat = …
predictions.append(yhat)
# 观察
obs = test[i]
history.append(obs)
print('Predicted=%.3f, Expected=%3.f' % (yhat, obs))
你能帮帮我吗?
也许确认您已将数据正确加载为浮点数?
嗨,Jason,
当我们使用 ARIMAX 等技术预测大约 12 个月的长期预测并带有外生变量时,应该采取什么方法?我们应该预测协变量然后将其添加到模型中吗?
此致,
Varun
也许您可以构建您的模型,使其仅根据可用观测值预测 +12 个月?
嗨,Jason,
明确地说,如果我添加回归变量并训练模型,我需要未来的值吗?例如,auto.arima 中的 xreg 参数等等。如何在不使用我用于训练的回归变量的情况下预测 +12 个月?
您可以训练一个新的预测模型,该模型只需要 t-12 数据即可进行预测。
嗨!
太棒了,谢谢!
您能给我这个项目的所有文件吗?我无法自己构建它。
您可以从文章中复制它们,方法如下
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
嗨!
太棒了,谢谢!
实际上,我想开发一个模型,用于确定我们呼叫中心每天预计会接到多少电话?
听起来很棒。
也许从这里开始
https://machinelearning.org.cn/start-here/#timeseries
嗨 Jason Brownlee,
非常感谢您的回复,我还需要一个帮助
您能用一些例子解释一下如何在 ARIMA 中使用季节性吗?
谢谢
您可以使用博客搜索框。
这里有一个例子
https://machinelearning.org.cn/sarima-for-time-series-forecasting-in-python/
这里还有一篇
https://machinelearning.org.cn/how-to-grid-search-sarima-model-hyperparameters-for-time-series-forecasting-in-python/
嗨,Jason,
这是一篇非常有用的文章。我的时间序列是每日销售点数据(例如,沃尔玛每天销售多少瓶百事可乐)。当百事可乐根本没有销售时,会出现缺失的日期。我想要预测的是未来3/4天每天销售的百事可乐瓶数。最好的方法/算法可能是什么?
谢谢。
可能是像 SARIMA 或 ETS 这样的线性模型。
我在这里有一些建议
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
嗨,Jason,
我收到了这样的错误,这个错误是什么意思?
TypeError Traceback (most recent call last)
in
test = ...
predictions = ...
mse = mean_squared_error(test, predictions)
rmse = sqrt(mse)
print('RMSE: %.3f' % rmse)
TypeError: 预期序列或类数组对象,得到
这很令人惊讶,您是否完全复制了所有代码?
嗨,Jason,
我需要构建一个包含附加预测因子的预测模型,我应该使用什么,以及我需要做的是周预测?
也许可以遵循上面教程中概述的步骤?
嗨 Jason,不错的文章。
我对最后一个验证代码示例有一个问题。
1) 第一次预测的目的是什么?
# 加载模型
#进行第一次预测
2) 我删除了上面两段代码,得到了相同的结果
这是否意味着只有顺序 (0,0,1) 和偏差 (165.904728) 重要,而不需要保存和加载模型?
它只是一个我们如何普遍使用偏差校正的例子。
你好,
我得到了与增广迪基-富勒检验完全相同的结果,但是我的 PACF 图看起来大不相同,它在滞后50到80之间有很多尖峰,甚至有一个达到了-120。
有没有什么想法或以前的经验可以解释为什么它看起来这么奇怪?
感谢您与我们分享您的知识。
他们最近改变了绘图。
尝试将绘图中的时间步数大幅缩小。
我认真地尝试了您的教程。不幸的是,我遇到了错误。
其中一个就是这个错误。这可能是我的问题的症结所在。因为我怎么也无法单独使用您的代码解决它。我不得不修改它——请参阅解释。
series = Series.from_csv(‘dataset.csv’)
AttributeError: 类型对象‘Series’没有属性‘from_csv’
我通过实现以下代码解决了这个问题
panda import pd
series = pd.read_csv(‘dataset.csv’)
series.iloc[0]
一旦我克服了这个障碍,我又遇到了这个障碍。
dataset = dataset.astype(‘float32’)
ValueError: 无法将字符串转换为浮点数:‘1964-01’
更像是我的操作出了问题。
是否有可能访问完整的代码?我复制粘贴的尝试显然没有帮助我。
我想我可能遗漏了代码的某些内在部分。或者我完全搞混了。
没问题,改为
我已更新教程中的所有示例。
就这么简单——天哪……我会试试的。感谢您抽出时间回答我的问题。您的书在亚马逊上有售吗?
我的书不在亚马逊上,只在我的网站上,我在这里解释原因(他们抽成很高)
https://machinelearning.org.cn/faq/single-faq/why-arent-your-books-on-amazon
它像魔法一样奏效。谢谢。
我发现的另一个问题是关于5.3节季节性线图的代码。
from pandas import TimeGrouper
from pandas import DataFrame
似乎pandas不再支持TimeGrouper,DataFrame了!!
https://pandas.ac.cn/pandas-docs/stable/whatsnew/v0.25.0.html#deprecations
移除了之前已弃用的TimeGrouper (GH16942)
移除了之前已弃用的DataFrame.reindex_axis和Series.reindex_axis (GH17842)
干得好!
您可以使用
我更新了示例,谢谢!
你好 jason,
我想知道您是否使用过fbprophet进行销售预测。我们直接从postgresql获取数据,并且似乎遇到了一个错误
超出范围的纳秒时间戳:1-08-11 00:00:00
这似乎与pandas版本兼容性有关。
您能调查一下并尝试找出问题的原因吗?
我没有,抱歉。
嘿 Jason,
我正在运行以下代码:
series=read_csv(r’D:\industrial engineering\Thesis\monthly_champagne_sales.csv’,header=0,index_col=0)
我得到的是一个数据框,而不是一个 Series,我该怎么办?
尝试添加 squeeze=True 参数。
尊敬的先生
我正在滚动窗口框架中运行以下代码,但是,我无法看到分析结果。它只显示一个值。您能告诉我需要修复什么以及在哪里修复才能获得这些结果吗?
##熵
from entropy import *
import numpy as np
np.random.seed(1234567)
x = np.random.rand(3000)
n = len(x)
result = list()
block = 250
for a in range(1, n-block+1)
DATA = x[a:a+249]
results = perm_entropy(DATA, order=3, normalize=True)
result.append(results)
return Series(result)
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
嗨,Jason,
我想问一下关于重复日期的时间序列。例如,我有一个包含不同类型交易的数据集,并且交易根据其协议具有不同的时间段。这意味着,当绘制平稳图时,每个日期可能有一个以上的观测值(在我的情况下是收入)。例如,2018年2月11日可能来自不同交易的多个收入。因此,图表草图非常令人困惑,因为同一日期有许多/很少重复。我的想法是按日期汇总收入,但这会影响模型的准确性吗,因为预测应该按交易进行?非常感谢您的想法和回复。此致
嗯,不深入研究数据很难说,但也许可以探索自己构建问题框架。
这将作为第一步提供帮助
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
还有这个。
https://machinelearning.org.cn/time-series-forecasting-supervised-learning/
我正在进行预测,这个函数用于未来预测,结果出现了 NotImplemented Error
def forcasting_future_months(monthly, no_of_months)
monthly_perdict = monthly.reset_index()
mon = monthly_perdict[‘Year_Month’]
mon = mon + pd.DateOffset(months = no_of_months)
future_dates = mon[-no_of_months -1:]
monthly_perdict = monthly_perdict.set_index(‘Year_Month’)
future = pd.DataFrame(index=future_dates, columns= monthly_perdict.columns)
monthly_perdict = pd.concat([monthly_perdict, future])
monthly_perdict[‘forecast’] = results.predict(start = 222, end = 233, dynamic= True)
monthly_perdict[[‘No of accidents’, ‘forecast’]].iloc[-no_of_months – 12:].plot(figsize=(12, 8))
plt.show()
return monthly_perdict[-no_of_months:]
我的 Kaggle 笔记中出现了错误,可以在这里看到
https://www.kaggle.com/jithu10/kerala-road-accidents-kerala-police-2001-2019
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
X = dataset.values.astype(‘float32’) 应该是:
X = series.values.astype(‘float32’)
嗨,Jason,
非常感谢您发表这篇文章。我找到的大多数文章只是告诉用户如何在其特定示例的每个字段中输入内容,而没有真正深入解释参数的含义或用法。结果,我无法理解在我的情况下应该输入什么。您的文章很好地解释了您是如何得出参数的。不过,我有一个问题。对于小型数据集我应该如何做才能有所不同?我只有大约30个月的数据来预测。为了完成本教程,我伪造了一些数据。这样做,它为我提供了负销售预测。这些数据是否足以提供准确的预测?
另外一点,在 7.3 节中,您有以下代码:
series = read_csv(‘dataset.csv’, header=None, index_col=0, parse_dates=True, squeeze=True)
X = dataset.values.astype(‘float32’)
我认为它应该是
series = read_csv(‘dataset.csv’, header=None, index_col=0, parse_dates=True, squeeze=True)
X = series.values.astype(‘float32’)
再次感谢这篇出色的教程!
谢谢!
已修复。
除了仔细选择评估模型的方式外,不会有太大变化。
嗨,Jason,
非常棒的练习。很喜欢……
就一个简短的问题
如何生成未来 12 个间隔的预测,并生成包含训练、测试和预测结果的图表?
谢谢!
调用 forecast() 并指定 12 个时间步。
大家好
读完您的精彩文章(一如既往),我有几个问题。
首先是关于残差。您手动计算了它们,然后使用数据框进行后续处理。但是,我读到 arima.fit 结果有一个名为 residuals 的成员。在阅读您的文章之前,我一直在使用这些残差处理不同的序列。然后我像您一样手动操作了。但是两者是不同的,而且差异不小。两者应该相似吗?因为我认为它们应该相似,而且我多次在我的代码中寻找一个错误。
第二个是关于差异的。当你对序列进行差分时,你会根据滞后损失一些元素。你可以保留原始数据,这样就可以进行积分。这在学术上是完美的。但是当你只有最终模型时该怎么办?我的意思是当你恢复新数据并想进行新预测时,模型会为你提供转换后的数据上的预测,你需要重新缩放。如果你使用了标准化,你可以获得去转换的值,但是你如何进行积分?信息丢失了……
谢谢你。
也许可以检查 ARIMA 在残差属性中到底存储了什么,例如检查代码或 API。
新数据必须以与训练数据相同的方式准备,例如差分、缩放等。
嗨,Jason。
不明白为什么偏置会加到预测值中。
“yhat = bias + inverse_difference(history, yhat, months_in_year)” 。
另外,当我运行代码时,是否有可能无法得到与此帖子中显示的确切值?有什么原因吗?
非常感谢!
是的,考虑到算法的随机性和不同硬件带来的精度差异,我们可以预期会得到不同的结果。
谢谢。你能告诉我为什么要把偏差加到预测值上吗?
为了提升预测的准确性。
谢谢 Jason。
不客气。
嘿 Jason,我喜欢你的例子,我只是想问一个关于输入我自己的数据的问题。我的数据包含2019年和2020年到目前为止每天的访问次数。我想知道,既然这是每天而不是每月,那么 months_in_year = 12 我是否应该将 months_in_year = 12 更改为 days_in_year = 365?
或许可以试试看?
嘿 Jason,我对你的投入印象深刻,你介意给我展示一下销售数据集的特征/属性,以使用深度学习/LSTM算法预测超市的未来销售额吗?
当然,从这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
嗨 Jason – 如果数据集包含多种葡萄酒(或产品)的历史数据,是否可以使用相同的 Python 代码?
当然。但 ARIMA 模型每个序列一个模型。
嗨,Jason,
感谢您的教程。确实非常有帮助。经过差分后,我使序列平稳,现在对于 ARIMA,我想绘制 ACF 和 PACF。这是我的代码 –
1) 用于差分以使数据平稳的代码
from pandas import read_csv
from statsmodels.tsa.stattools import adfuller
from numpy import diff
X = diff(X)
result = adfuller(X)
print(‘ADF统计量:%f’ % result[0])
print(‘p值:%f’ % result[1])
for key, value in result[4].items()
print(‘\t%s: %.3f’ % (key, value))
2) 绘制 ACF 和 PACF 的代码
from pandas import read_csv
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
from matplotlib import pyplot
series = read_csv(‘X.csv’, header=None, index_col=0, parse_dates=True, squeeze=True)
pyplot.figure()
pyplot.subplot(211)
plot_acf(series, ax=pyplot.gca())
pyplot.subplot(212)
plot_pacf(series, ax=pyplot.gca())
pyplot.show()
运行第二段代码后,我收到了一个错误,即 –
FileNotFoundError Traceback (最近一次调用)
in
3 from statsmodels.graphics.tsaplots import plot_pacf
4 from matplotlib import pyplot
—-> 5 series = read_csv(‘X.csv’, header=None, index_col=0, parse_dates=True, squeeze=True)
6 pyplot.figure()
7 pyplot.subplot(211)
~\anaconda3\lib\site-packages\pandas\io\parsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
674 )
675
–> 676 return _read(filepath_or_buffer, kwds)
677
678 parser_f.__name__ = name
~\anaconda3\lib\site-packages\pandas\io\parsers.py in _read(filepath_or_buffer, kwds)
446
447 # 创建解析器。
–> 448 parser = TextFileReader(fp_or_buf, **kwds)
449
450 if chunksize or iterator
~\anaconda3\lib\site-packages\pandas\io\parsers.py in __init__(self, f, engine, **kwds)
878 self.options[“has_index_names”] = kwds[“has_index_names”]
879
–> 880 self._make_engine(self.engine)
881
882 def close(self)
~\anaconda3\lib\site-packages\pandas\io\parsers.py in _make_engine(self, engine)
1112 def _make_engine(self, engine=”c”)
1113 if engine == “c”
-> 1114 self._engine = CParserWrapper(self.f, **self.options)
1115 else
1116 if engine == “python”
~\anaconda3\lib\site-packages\pandas\io\parsers.py in __init__(self, src, **kwds)
1889 kwds[“usecols”] = self.usecols
1890
-> 1891 self._reader = parsers.TextReader(src, **kwds)
1892 self.unnamed_cols = self._reader.unnamed_cols
1893
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader.__cinit__()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source()
FileNotFoundError: [Errno 2] 文件 X.csv 不存在:‘X.csv’
请让我知道我哪里错了。
看起来您的文件无法加载。
也许检查一下您的文件是否与您的代码在同一目录中,或者在您预期的路径中。
嗨,Jason,
请帮帮我。我正在按照您的教程学习。这是我的代码。
#1 (运行成功)
from pandas import read_csv
from matplotlib import pyplot
series = read_csv(‘D:/Management Books/BSE Index Daily Closing.csv’, header=0, parse_dates=True, index_col=0, squeeze=True)
diff = series.diff()
pyplot.plot(diff)
pyplot.show()
#2 (运行成功但有错误)
from pandas import read_csv
from numpy import diff
result = adfuller(diff(X))
print(‘ADF统计量:%f’ % result[0])
print(‘p值:%f’ % result[1])
for key, value in result[4].items()
print(‘\t%s: %.3f’ % (key, value))
diff.to_csv(‘diff.csv’, header = False)
AttributeError Traceback (最近一次调用)
in
6 for key, value in result[4].items()
7 print(‘\t%s: %.3f’ % (key, value))
—-> 8 diff.to_csv(‘diff.csv’, header = False)
AttributeError: ‘function’ 对象没有属性 ‘to_csv’
#3 (显示错误)
from pandas import read_csv
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
from matplotlib import pyplot
X.to_csv(‘X.csv’, header=False)
series = read_csv(‘X.csv’, header=None, index_col=0, parse_dates=True, squeeze=True)
pyplot.figure()
pyplot.subplot(211)
plot_acf(series, ax=pyplot.gca())
pyplot.subplot(212)
plot_pacf(series, ax=pyplot.gca())
pyplot.show()
AttributeError Traceback (最近一次调用)
in
3 from statsmodels.graphics.tsaplots import plot_pacf
4 from matplotlib import pyplot
—-> 5 X.to_csv(‘X.csv’, header=False)
6 series = read_csv(‘X.csv’, header=None, index_col=0, parse_dates=True, squeeze=True)
7 pyplot.figure()
AttributeError: ‘numpy.ndarray’ 对象没有属性 ‘to_csv’
我已经看过已解决的示例,然后正在尝试。
请帮帮我。
很抱歉听到您遇到了麻烦。
也许尝试复制给定部分末尾列出的完整示例?
也许这些技巧会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我没有复制您的代码。此外,前几段代码运行成功了。我想知道为什么这段代码不工作。
您好,我是 Python 新手,正在从您的博客学习。
您介意解释一下您以下代码的含义吗?我不明白 obs 是什么。yhat 是预测结果吗?
obs = test[i]
history.append(obs)
print('Predicted=%.3f, Expected=%3.f' % (yhat, obs))
非常感谢这个非常有教育意义的逐步博客!!
yhat 是预测模型做出的预测。
在代码中,我们将实际观测值存储在历史记录中——我们假装实际观测值在我们做出预测后刚刚可用,因此我们在下一次迭代中将其添加到训练数据中。
你好,
我有一个疑问。如果我只有10年的数据集,我能预测吗?如果能,我将如何把我的数据集分成训练集和测试集?
请告诉我。
是的。
你想怎么分割数据就怎么分割——只要能让你相信模型有足够的数据进行训练和评估。
你好,
我有一个请求。我正在寻找一个用于绘制 ACF 和 PACF 的 Ljung Box 检验的 Python 代码。请告诉我。
手头没有,也许这可以帮助你入门
https://machinelearning.org.cn/gentle-introduction-autocorrelation-partial-autocorrelation/
嗨,感谢您提供如此信息丰富的文章!!!
我发现使用 p、d、q 参数范围进行滚动预测验证需要花费数小时,而且是在 Google Colab 上。有什么可能的优化方法吗?
不客气。
这些建议可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/how-do-i-speed-up-the-training-of-my-model
你好,希望你能指导我,我是机器学习新手。
在 4. 持续性 (Persistence) 中,当我应用以下代码时,我遇到了一个错误
应用的代码
# 报告表现
mse = mean_squared_error(test, predictions)
rmse = sqrt(mse)
print('RMSE: %.3f' % rmse)
错误
—————————————————————————
NameError Traceback (最近一次调用)
in
1 # 报告性能
—-> 2 mse = mean_squared_error(test, predictions)
3 rmse = sqrt(mse)
4 print(‘RMSE: %.3f’ % rmse)
NameError: name ‘mean_squared_error’ is not defined
所有之前的步骤都正常工作。请问问题出在哪里?
提前感谢。
错误提示您没有导入该函数。
你是不是跳过了一些代码行?
你好,我不知道更好的联系方式。我想我在这里发现有人抄袭你的作品:https://towardsdatascience.com/time-series-analysis-modeling-validation-386378cd3369。你看完后我会删除这条评论。谢谢。
谢谢你告诉我,这种事经常发生。
谢谢杰森,很棒的帖子
快速提问,我在运行手动 ARIMA 模型时没有得到相同的结果。您的结果是 956.942,而我的是 961。在此之前,所有其他内容都匹配,但我遇到了自相关图只显示 21 个观测值而不是 81 个观测值的问题。任何帮助都将不胜感激。
# 评估手动配置的 ARIMA 模型
from pandas import read_csv
from sklearn.metrics import mean_squared_error
来自 statsmodels.tsa.arima.model 导入 ARIMA
from math import sqrt
# 创建差分序列
def difference(dataset, interval=1)
diff = list()
for i in range(interval, len(dataset))
value = dataset[i] – dataset[i – interval]
diff.append(value)
返回差分
# 反转差分值
def inverse_difference(history, yhat, interval=1)
return yhat + history[-interval]
# 加载数据
series = read_csv(‘dataset.csv’, header=None, index_col=0, parse_dates=True, squeeze=True)
# 准备数据
X = series.values
X = X.astype(‘float32’)
train_size = int(len(X) * 0.50)
train, test = X[0:train_size], X[train_size:]
# 步进验证
history = [x for x in train]
predictions = list()
for i in range(len(test))
# 差分数据
months_in_year = 12
diff = difference(history, months_in_year)
# 预测
model = ARIMA(diff, order=(1,1,1))
model_fit = model.fit()
yhat = model_fit.forecast()[0]
yhat = inverse_difference(history, yhat, months_in_year)
predictions.append(yhat)
# 观察
obs = test[i]
history.append(obs)
print(‘>预测值=%.3f, 实际值=%.3f’ % (yhat, obs))
# 报告表现
rmse = sqrt(mean_squared_error(test, predictions))
print('RMSE: %.3f' % rmse)
———- 结果
>预测值=8076.987, 实际值=8314.000
>预测值=9747.154, 实际值=10651.000
>预测值=5994.362, 实际值=3633.000
>预测值=3820.287, 实际值=4292.000
>预测值=4041.968, 实际值=4154.000
>预测值=4990.405, 实际值=4121.000
>预测值=5129.641, 实际值=4647.000
>预测值=5031.196, 实际值=4753.000
>预测值=4133.285, 实际值=3965.000
>预测值=2095.321, 实际值=1723.000
>预测值=5216.271, 实际值=5048.000
>预测值=5866.317, 实际值=6922.000
>预测值=8591.060, 实际值=9858.000
>预测值=11028.649, 实际值=11331.000
>预测值=4090.352, 实际值=4016.000
>预测值=4767.109, 实际值=3957.000
>预测值=4656.326, 实际值=4510.000
>预测值=4577.708, 实际值=4276.000
>预测值=5108.656, 实际值=4968.000
>预测值=5202.831, 实际值=4677.000
>预测值=4423.982, 实际值=3523.000
>预测值=2162.388, 实际值=1821.000
>预测值=5463.233, 实际值=5222.000
>预测值=7331.345, 实际值=6872.000
>预测值=10258.650, 实际值=10803.000
>预测值=11732.476, 实际值=13916.000
>预测值=4552.498, 实际值=2639.000
>预测值=4578.764, 实际值=2899.000
>预测值=4914.578, 实际值=3370.000
>预测值=4545.624, 实际值=3740.000
>预测值=5229.775, 实际值=2927.000
>预测值=4287.729, 实际值=3986.000
>预测值=3153.080, 实际值=4217.000
>预测值=1827.778, 实际值=1738.000
>预测值=5134.493, 实际值=5221.000
>预测值=6806.278, 实际值=6424.000
>预测值=10643.889, 实际值=9842.000
>预测值=13606.245, 实际值=13076.000
>预测值=2265.432, 实际值=3934.000
>预测值=2936.318, 实际值=3162.000
>预测值=3341.109, 实际值=4286.000
>预测值=3881.790, 实际值=4676.000
>预测值=3156.601, 实际值=5010.000
>预测值=4693.892, 实际值=4874.000
>预测值=4663.923, 实际值=4633.000
>预测值=2045.499, 实际值=1659.000
>预测值=5440.863, 实际值=5951.000
RMSE: 961.548
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
TypeError: only size-1 arrays can be converted to Python scalars
我在运行法国香槟的持久性模型时遇到了这个错误
听到这个消息很遗憾,也许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
没关系,是数据导入的方式问题。
很高兴听到这个!
嗨,Jason,非常感谢。我想知道为什么ARIMA模型要使用季节性差分数据。我查阅了之前的例子(抢劫数据集),ARIMA模型没有使用差分。
这背后的原因是什么?
嗨,Saheed……希望以下内容能提供清晰的解释
https://stats.stackexchange.com/questions/195038/assessing-seasonality-when-to-use-seasonal-arima-instead-of-non-seasonal-arima
https://machinelearning.org.cn/sarima-for-time-series-forecasting-in-python/
很棒的教程。顺便问一下,如果我的数据时间长度不一致怎么办?比如我有2019年8个月的销售数据,2020年6个月的销售数据,2021年10个月的销售数据。我该如何使用不相等月数的数据构建模型呢?非常感谢您的时间!
嗨,Jishan……有些时间序列数据是不连续的。
这意味着观测值之间的时间间隔不一致,可能会有所不同。
您可以在这篇文章中了解更多关于连续与不连续时间序列数据集的信息
时间序列预测问题分类
处理这种形式数据的方法有很多,您必须找到适合或最适合您的特定数据集和所选方法的方法。
最常见的方法是将不连续时间序列视为连续的,并将新观测时间点的观测值视为缺失(例如,具有缺失值的连续时间序列)。
您可能想要探索的一些想法包括
忽略问题的非连续性并按原样建模数据。
重采样数据(例如上采样)以使观测值之间具有一致的间隔。
插补观测值以形成一致的时间间隔。
填充观测值以形成一致的间隔,并使用遮罩层忽略填充值。
嗨,詹姆斯,谢谢你的回复。这里的问题是商店的开业取决于当年的天气状况。它每年开业的时间都不一样,而是变化的!它在2019年只开了8个月,2020年开了6个月,2021年开了10个月。我们该如何将这视为缺失值问题呢?如果能有一个解决教程就太好了!感谢你的时间!谢谢!
您好,我想请教一个问题,因为我的数据集是记录植物的收获数据,月份相对固定,所以每年只有两个月的数据,例如2021年有48天的数据,2022年有50天,那么基于此,我是否应该用零填充所有没有数据的日期?这是否也意味着一个季节性数字?如果我使用SARIMAX进行预测,我的周期应该如何处理?