时间序列预测是一个在机器学习中既难建模又难解决的问题。
在本帖中,您将了解如何使用 Keras 深度学习库在 Python 中开发用于时间序列预测的神经网络模型。
阅读本文后,你将了解:
- 关于航空乘客单变量时间序列预测问题
- 如何将时间序列预测构建为回归问题并为其开发神经网络模型
- 如何构建具有时间滞后特性的时间序列预测并为其开发神经网络模型
立即开始您的项目,阅读我的新书 深度学习时间序列预测,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2016 年 7 月:首次发布
- 更新于 2016 年 10 月:已替换为更准确的图表
- 更新于 2017 年 3 月:更新至 Keras 2.0.2、TensorFlow 1.0.1 和 Theano 0.9.0
- 更新于 2019 年 4 月:已更新数据集链接
- 更新于 2019 年 9 月:更新至 Keras 2.2.5
- 更新于 2022 年 7 月:已更新以支持 TensorFlow 2.x
问题描述
本帖中您将要研究的问题是国际航空乘客预测问题。
这是一个问题,给定年份和月份,任务是预测国际航空旅客数量(单位为千人)。数据范围为 1949 年 1 月至 1960 年 12 月,即 12 年,共 144 个观测值。
- 下载数据集(另存为“airline-passengers.csv”)。
下面是文件前几行的示例。
|
1 2 3 4 5 |
"月份","乘客数" "1949-01",112 "1949-02",118 "1949-03",132 "1949-04",129 |
您可以使用 Pandas 库轻松加载此数据集。由于每个观测值之间间隔相同(一个月),您不需要关注日期。因此,在加载数据集时,可以排除第一列。
加载后,您可以轻松绘制整个数据集。加载和绘制数据集的代码如下所示。
|
1 2 3 4 5 |
import pandas as pd import matplotlib.pyplot as plt dataset = pd.read_csv('airline-passengers.csv', usecols=[1], engine='python') plt.plot(dataset) plt.show() |
您可以在图表中看到一个上升趋势。
您还可以看到数据集中存在某种周期性,这可能对应于北半球的夏季假期。
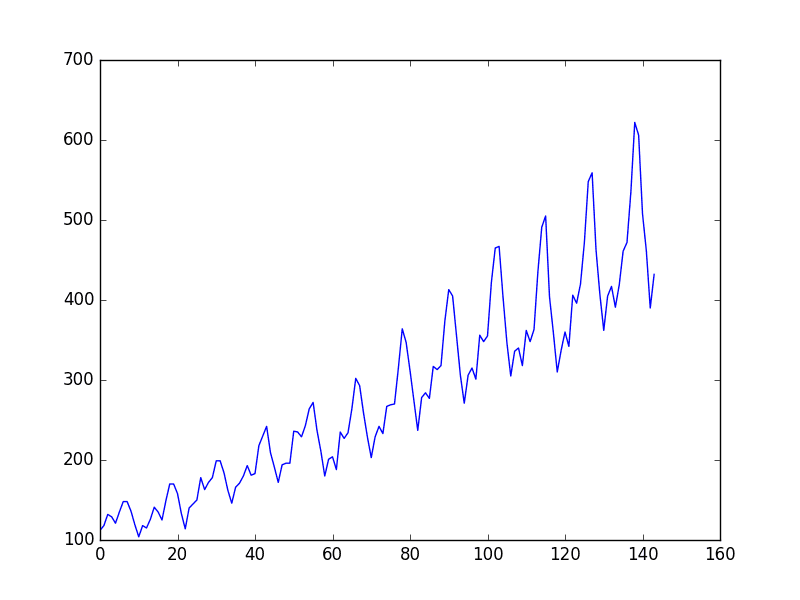
航空旅客数据集图
我们保持简单,按原样处理数据。
通常,研究各种数据准备技术以重新缩放数据并使其平稳是一个好主意。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
多层感知机回归
您想将时间序列预测问题构建为回归问题。
也就是说,给定本月的乘客数量(以千为单位),下个月的乘客数量是多少?
您可以编写一个简单的函数,将单列数据转换为两列数据集:第一列包含本月(t)的乘客数量,第二列包含下个月(t+1)要预测的乘客数量。
在开始之前,我们先导入所有您需要使用的函数和类。这假定您有一个可用的 SciPy 环境,并且已安装 Keras 深度学习库。
|
1 2 3 4 5 |
import numpy as np import matplotlib.pyplot as plt import pandas as pd from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense |
您也可以使用上一节的代码将数据集加载为 Pandas 数据帧。然后,您可以从数据帧中提取 NumPy 数组,并将整数值转换为浮点值,这更适合神经网络建模。
|
1 2 3 4 5 |
... # 加载数据集 dataframe = pd.read_csv('airline-passengers.csv', usecols=[1], engine='python') dataset = dataframe.values dataset = dataset.astype('float32') |
在对数据进行建模并估计模型在训练数据集上的技能后,您需要了解模型在新数据上的技能。对于普通的分类或回归问题,您会使用交叉验证。然而,对于时间序列数据,值 的顺序很重要。一个简单的方法是:将有序数据集分割成训练集和测试集。下面的代码计算分割点的索引,并将数据分成训练集(使用 67% 的观测值训练模型),剩余的 33% 用于测试模型。
对于时间序列数据,值的顺序很重要。您可以使用的一种简单方法是将有序数据集拆分为训练集和测试集。下面的代码计算拆分点的索引,并将数据分为训练集(使用 67% 的观测值来训练模型),剩余的 33% 用于测试模型。
|
1 2 3 4 5 6 |
... # 拆分为训练集和测试集 train_size = int(len(dataset) * 0.67) test_size = len(dataset) - train_size train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:] print(len(train), len(test)) |
现在,您可以定义一个函数来创建上面描述的新数据集。该函数接受两个参数:数据集,即您要转换的 NumPy 数组,以及 **look_back**,即要用作输入变量以预测下一个时间段的先前时间步长数,此处默认为 1。
此默认设置将创建一个数据集,其中 X 是给定时间(t)的乘客数量,Y 是下一时间(t + 1)的乘客数量。
它可以进行配置,并且您将在下一节中了解如何构建形状不同的数据集。
|
1 2 3 4 5 6 7 8 9 |
... # 将值数组转换为数据集矩阵 def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back-1): a = dataset[i:(i+look_back), 0] dataX.append(a) dataY.append(dataset[i + look_back, 0]) return np.array(dataX), np.array(dataY) |
让我们看一下此函数对数据集前几行的影响。
|
1 2 3 4 5 6 |
X Y 112 118 118 132 132 129 129 121 121 135 |
如果将这前五行与上一节中列出的原始数据集样本进行比较,您可以看到数字中的 X=t 和 Y=t+1 模式。
让我们使用此函数为训练和测试数据集准备模型。
|
1 2 3 4 5 |
... # 重塑为 X=t 和 Y=t+1 look_back = 1 trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) |
我们现在可以拟合一个多层感知机模型到训练数据。
我们使用一个简单的网络,它有一个输入层、一个包含八个神经元隐藏层和一个输出层。该模型使用均方误差进行拟合,如果对其取平方根,您将得到一个以数据集单位表示的误差分数。
我尝试了一些粗略的参数,并确定了下面的配置,但这绝不是对网络进行的优化。
|
1 2 3 4 5 6 7 |
... # 创建并拟合多层感知机模型 model = Sequential() model.add(Dense(8, input_shape=(look_back,), activation='relu')) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.fit(trainX, trainY, epochs=200, batch_size=2, verbose=2) |
模型拟合完成后,您可以估计模型在训练集和测试集上的性能。这将为您提供一个与新模型进行比较的基准。
|
1 2 3 4 5 6 |
... # 评估模型性能 trainScore = model.evaluate(trainX, trainY, verbose=0) print('训练得分:%.2f MSE (%.2f RMSE)' % (trainScore, math.sqrt(trainScore))) testScore = model.evaluate(testX, testY, verbose=0) print('测试得分:%.2f MSE (%.2f RMSE)' % (testScore, math.sqrt(testScore))) |
最后,您可以为训练集和测试集使用模型生成预测,以直观地了解模型的技能。
由于数据集的准备方式,您必须移动预测结果以使其在 x 轴上与原始数据集对齐。准备好后,将绘制数据,显示蓝色为原始数据集,绿色为训练预测,红色为未见过的测试数据集的预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
... # 为训练生成预测 trainPredict = model.predict(trainX) testPredict = model.predict(testX) # 移动训练预测以进行绘图 trainPredictPlot = np.empty_like(dataset) trainPredictPlot[:, :] = np.nan trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict # 移动测试预测以进行绘图 testPredictPlot = np.empty_like(dataset) testPredictPlot[:, :] = np.nan testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict # 绘制基线和预测 plt.plot(dataset) plt.plot(trainPredictPlot) plt.plot(testPredictPlot) plt.show() |
将所有这些结合起来,完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
# 多层感知机预测国际航空乘客 (t+1,给定 t、t-1、t-2) import numpy as np import matplotlib.pyplot as plt from pandas import read_csv import math from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense # 将值数组转换为数据集矩阵 def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back-1): a = dataset[i:(i+look_back), 0] dataX.append(a) dataY.append(dataset[i + look_back, 0]) return np.array(dataX), np.array(dataY) # 加载数据集 dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python') dataset = dataframe.values dataset = dataset.astype('float32') # 拆分为训练集和测试集 train_size = int(len(dataset) * 0.67) test_size = len(dataset) - train_size train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:] # 重塑数据集 look_back = 3 trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) # 创建并拟合多层感知机模型 model = Sequential() model.add(Dense(12, input_shape=(look_back,), activation='relu')) model.add(Dense(8, activation='relu')) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.fit(trainX, trainY, epochs=400, batch_size=2, verbose=2) # 评估模型性能 trainScore = model.evaluate(trainX, trainY, verbose=0) print('训练得分:%.2f MSE (%.2f RMSE)' % (trainScore, math.sqrt(trainScore))) testScore = model.evaluate(testX, testY, verbose=0) print('测试得分:%.2f MSE (%.2f RMSE)' % (testScore, math.sqrt(testScore))) # 为训练生成预测 trainPredict = model.predict(trainX) testPredict = model.predict(testX) # 移动训练预测以进行绘图 trainPredictPlot = np.empty_like(dataset) trainPredictPlot[:, :] = np.nan trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict # 移动测试预测以进行绘图 testPredictPlot = np.empty_like(dataset) testPredictPlot[:, :] = np.nan testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict # 绘制基线和预测 plt.plot(dataset) plt.plot(trainPredictPlot) plt.plot(testPredictPlot) plt.show() |
运行示例会报告模型性能。
注意:由于算法或评估程序的随机性质,或数值精度的差异,您的结果可能有所不同。考虑运行示例几次并比较平均结果。
通过对性能估计值取平方根,您可以看到模型在训练数据集上的平均误差为 22(千)名乘客,在测试数据集上的平均误差为 46(千)名乘客。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... 第 395/400 轮 46/46 - 0s - loss: 513.2617 - 13ms/epoch - 275us/step Epoch 396/400 46/46 - 0s - loss: 494.1868 - 12ms/epoch - 268us/step Epoch 397/400 46/46 - 0s - loss: 483.3908 - 12ms/epoch - 268us/step Epoch 398/400 46/46 - 0s - loss: 501.8111 - 13ms/epoch - 281us/step Epoch 399/400 46/46 - 0s - loss: 523.2578 - 13ms/epoch - 280us/step Epoch 400/400 46/46 - 0s - loss: 513.7587 - 12ms/epoch - 263us/step 训练得分:487.39 MSE (22.08 RMSE) 测试得分:2070.68 MSE (45.50 RMSE) |
从图中可以看出,模型在拟合训练集和测试集方面都表现不佳。它基本上将相同的输入值预测为输出。
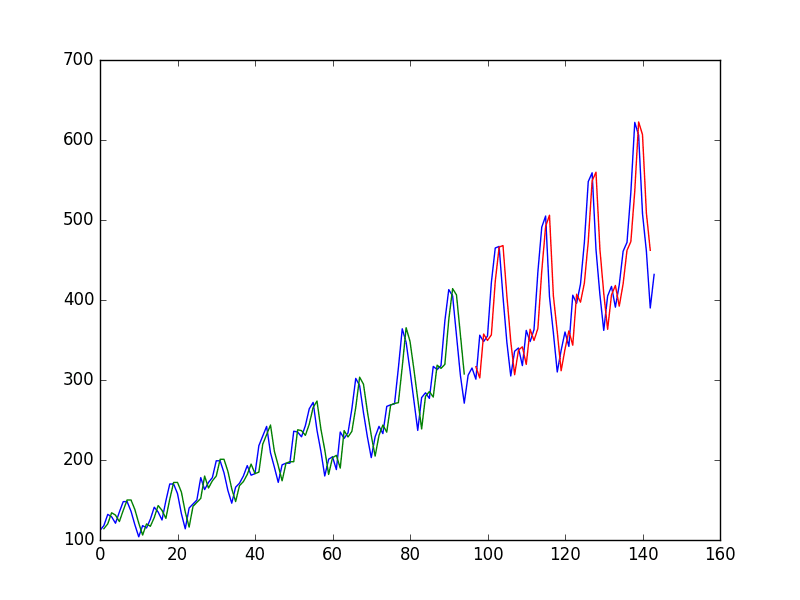
神经网络的朴素时间序列预测
蓝色=整个数据集,绿色=训练,红色=预测
使用窗口方法的多层感知机
您还可以将问题构建为使用多个近期时间步来预测下一个时间步。
这被称为窗口方法,窗口大小是每个问题都可以调整的参数。
例如,给定当前时间(t)以预测序列中下一个时间(t + 1)的值,您可以使用当前时间(t)以及之前的两个时间(t-1 和 t-2)。
当将其表述为回归问题时,输入变量是 t-2、t-1 和 t,输出变量是 t+1。
上一节中使用的 **create_dataset()** 函数允许您通过将 **look_back** 参数从 1 增加到 3 来创建时间序列问题的这种表述。
此表述的数据集样本如下所示
|
1 2 3 4 5 6 |
X1 X2 X3 Y 112 118 132 129 118 132 129 121 132 129 121 135 129 121 135 148 121 135 148 148 |
您可以通过使用更大的窗口大小来重新运行上一节中的示例。您将增加网络容量以处理额外信息。第一个隐藏层增加到 14 个神经元,并添加了一个包含 8 个神经元的第二个隐藏层。训练轮数也增加到 400 轮。
为了完整起见,下面列出了仅更改了窗口大小的完整代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
# 多层感知机预测国际航空乘客 (t+1,给定 t、t-1、t-2) import numpy as np import matplotlib.pyplot as plt from pandas import read_csv import math from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense # 将值数组转换为数据集矩阵 def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back-1): a = dataset[i:(i+look_back), 0] dataX.append(a) dataY.append(dataset[i + look_back, 0]) return np.array(dataX), np.array(dataY) # 加载数据集 dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python') dataset = dataframe.values dataset = dataset.astype('float32') # 拆分为训练集和测试集 train_size = int(len(dataset) * 0.67) test_size = len(dataset) - train_size train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:] # 重塑数据集 look_back = 3 trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) # 创建并拟合多层感知机模型 model = Sequential() model.add(Dense(12, input_dim=look_back, activation='relu')) model.add(Dense(8, activation='relu')) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.fit(trainX, trainY, epochs=400, batch_size=2, verbose=2) # 评估模型性能 trainScore = model.evaluate(trainX, trainY, verbose=0) print('训练得分:%.2f MSE (%.2f RMSE)' % (trainScore, math.sqrt(trainScore))) testScore = model.evaluate(testX, testY, verbose=0) print('测试得分:%.2f MSE (%.2f RMSE)' % (testScore, math.sqrt(testScore))) # 为训练生成预测 trainPredict = model.predict(trainX) testPredict = model.predict(testX) # 移动训练预测以进行绘图 trainPredictPlot = np.empty_like(dataset) trainPredictPlot[:, :] = np.nan trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict # 移动测试预测以进行绘图 testPredictPlot = np.empty_like(dataset) testPredictPlot[:, :] = np.nan testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict # 绘制基线和预测 plt.plot(dataset) plt.plot(trainPredictPlot) plt.plot(testPredictPlot) plt.show() |
注意:由于算法或评估程序的随机性质,或数值精度的差异,您的结果可能有所不同。考虑运行示例几次并比较平均结果。
运行该示例将提供以下输出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
第 395/400 轮 46/46 - 0s - loss: 419.0309 - 14ms/epoch - 294us/step Epoch 396/400 46/46 - 0s - loss: 429.3398 - 14ms/epoch - 300us/step Epoch 397/400 46/46 - 0s - loss: 412.2588 - 14ms/epoch - 298us/step Epoch 398/400 46/46 - 0s - loss: 424.6126 - 13ms/epoch - 292us/step Epoch 399/400 46/46 - 0s - loss: 429.6443 - 14ms/epoch - 296us/step Epoch 400/400 46/46 - 0s - loss: 419.9067 - 14ms/epoch - 301us/step 训练得分:393.07 MSE (19.83 RMSE) 测试得分:1833.35 MSE (42.82 RMSE) |
您可以看到,与上一节相比,误差并没有显著降低。
从图中可以看出,预测结果中出现了更多的结构。
同样,窗口大小和网络架构都没有进行调优;这只是展示了如何构建预测问题。
对性能分数取平方根,可以看到训练数据集上的平均误差为每月 20(千)名乘客,而未见过的测试集上的平均误差为每月 43(千)名乘客。
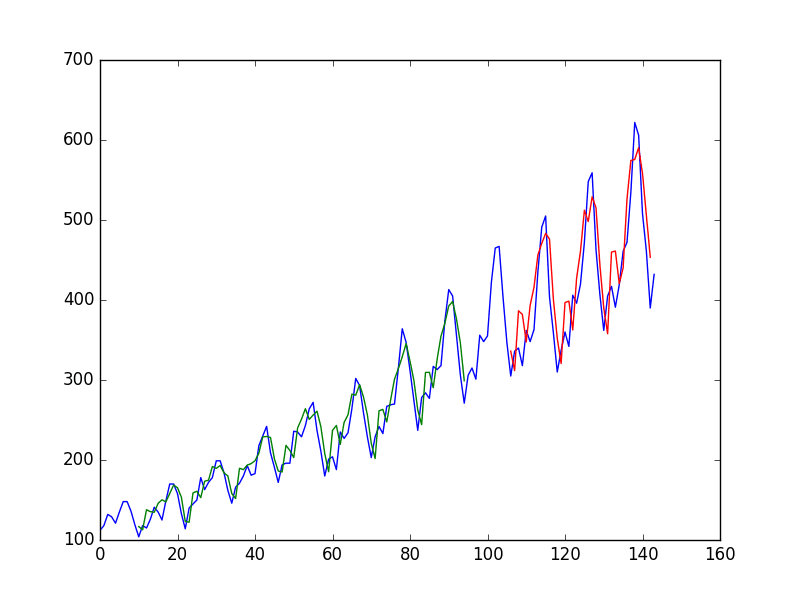
用于神经网络时间序列预测的窗口方法
蓝色=整个数据集,绿色=训练,红色=预测
总结
在本帖中,您了解了如何使用 Keras 深度学习库为时间序列预测问题开发神经网络模型。
通过学习本教程,您现在知道了
- 关于国际航空乘客预测时间序列数据集
- 如何将时间序列预测问题构建为回归问题并开发神经网络模型
- 如何使用窗口方法构建时间序列预测问题并开发神经网络模型
您对神经网络时间序列预测或本帖有任何疑问吗?
请在下面的评论中提问,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。





嗨,Jason,
这对我来说是一个新工具,所以这是一篇有趣的入门帖!
在我看来,您第一种方法的图表似乎是错误的。由于您只提供前一个时间点来预测下一个时间点,模型将会拟合(接近)一条直线,而不会像图表所示的那样提取周期性。红线几乎完美的拟合蓝线,这也不能反映模型分数所暗示的更糟糕的拟合!
希望这会有所帮助。
嗨,Jason,
如何使用此技术预测未来?
谢谢!
此示例正在预测未来的 t+1。
为了预测 t+2、t+3、t+n……,是否建议将之前的预测(t+1)用作假设数据点。
例如,如果我想预测 t+2,我会使用可用数据,包括我对 t+1 的预测。
我理解误差会随着预测的进行而增加,因为依赖于预测作为数据点。
有什么想法?
是的,使用此方法将提供多个未来数据点。正如您所建议的,未来越远,误差累积的可能性越大。
试试看,最好是尝试这些模型并了解它们的能力。
另外,在使用窗口方法的完整代码片段时,生成的图表与显示的图表不匹配。
这是我得到的结果
http://imgur.com/a/NaoYE
我对绘图代码做了一些小改动,但没有相应地更新图像。我会尽快更新它们。
你能举一个有几个额外特征的例子吗?比如,你想预测有多少乘客,而你知道温度和星期几(周一至周日)。
嗨 Andy,
是的,我目前正在研究更复杂的时间序列教程,它们应该很快就会发布到博客上。
期待这些多特征时间序列预测的例子——你预计什么时候将它们发布到你的博客上?
一如既往,感谢这个宝贵的资源和分享你的经验!
也许一个月。不敢保证。我正在花时间确保它们是好的。
先生,请分享一些关于 TensorFlow 的教程,以及在 TensorFlow 和 Keras 中制作模型的区别。谢谢
TensorFlow 就像汇编语言编程,Keras 就像 Python 编程。
Keras 更简单,能让你更高效,但牺牲了一些速度和灵活性,这对大多数应用来说是值得的。
先生,您是否做过时间序列预测中多列(例如股票数据)的示例?如果有,请分享链接。谢谢
请看这里
https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/
太棒了!很快就会花些时间研究一下。非常感谢,Jason!
你好,
感谢您的精彩文章。我有一个很大的疑问,这也与前面评论中发布的图表有关,该图表显示了预测的某种滞后。在这里,我们正在用 t 来训练模型以获得 t+1 的预测。
考虑到这一点,我应该假设当模型看到输入 112 时,它应该预测大约 118(训练集中的第一个数据点)。但预测结果并非如此。复制该帖子中提供的第一个示例代码生成的顶部 5 个训练点及其后续预测
trainX[:5] trainPredict[:5]
[ 112.], [112.56],
[ 118.], [118.47],
[ 132.], [132.26],
[ 129.], [129.55],
[ 121.] [121.57],
我正试图从模型的角度理解为什么它会以滞后方式进行预测!
谢谢 Keshav,我已经更新了描述和图表。
正如 Steve Buckley 所指出的,您的第一种方法似乎是错误的。模型确实只是拟合了一条直线( yPred = a*X+b),这可以通过对 arange(200) 等输入进行预测来验证。
由于您之后移动了结果再进行绘图,因此结果看起来非常好。然而,从概念上讲,仅根据 X_t 来正确预测 X_t+1 是不可能的,因为前者不包含趋势或季节性信息。
以下是我尝试重现您的结果后的结果
X Y yPred
0 112.0 118.0 112.897537
1 118.0 132.0 118.847107
2 132.0 129.0 132.729446
3 129.0 121.0 129.754669
....
如您所见,yPred 差得很远(它应该等于 Y),但当移动一个周期后看起来不错。
是的,说得对,Jev,谢谢。我已经更新了描述和图表。
嗨,Jason
我也同意Jev的看法,我本以为使用predict(trainX)会得到更接近trainY的值,而不是trainX的值。
是的,Max,你说得对。我已经更新了图表,以更好地反映实际的预测结果。
嗨,Jason,
感谢如此精彩的教程!
我只是想知道在create_dataset函数中,循环是否应该使用range(len(dataset)-1)?因此,对于绘图逻辑,它应该是
…
trainPredictPlot[lb:len(train),:] = trainPredict
…
testPredictPlot[len(train)+lb:len(dataset),:] = testPredict
我对于索引有些困惑,并且对于look_back=3的情况得到了有些不同的图表:http://imgur.com/a/DMbOU
你好,感谢这个非常有用的教程,你有没有想过为什么这个方法比姊妹教程中使用的RNN和LSTM时间序列预测效果更好?我的直觉认为恰恰相反。
很高兴你喜欢它,Veltzer。
好问题,LSTM可能需要更多的微调,我猜是这样。
trainPredictPlot = numpy.empty_like(dataset)
trainPredictPlot[:, :] = numpy.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# 移动测试预测以进行绘图
testPredictPlot = numpy.empty_like(dataset)
testPredictPlot[:, :] = numpy.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1
我需要对这部分代码进行解释
谁能解释一下吗
据我回忆,它会绘制训练数据集的折线图,然后是测试数据集的预测图。
这是个糟糕的实现,现在有更简单的方法可以做到。
你好!很棒的博客和文章——这些例子真的很有帮助!我是这方面的新手,所以如果有什么愚蠢的问题,请原谅——我想基于相同的输入来预测接下来的三个输出。这在LSTM框架下可行吗?这是为了预测未来3天的水温。
是的,这被称为序列到序列预测。
我认为有两种主要选择
——运行LSTM 3次,并将输出作为输入。
——将LSTM更改为输出3个数字。
这个特定的时间序列具有很强的季节性和指数级趋势。实际上,这个时间序列的增长率更重要。你能画出年同比增长率吗?
我对数据的平稳版本进行建模会有好处,我同意。
我同意Steve Buckley的看法。代码预测的是 x[i+1] = x[i] (近似),所以代码的最后部分,本应修正偏移,却没有正确地进行偏移。
尝试以下方法:选择测试集中的任何一个点,例如test X[i],使用模型预测test Y[i],然后不要使用test X[i+1],而是使用test Y[i]作为model.predict()的输入参数,依此类推。你最终会得到一条近似直线。
感谢您关于神经网络的精彩帖子,在我学习神经网络时帮助了我很多。然而,这个特定的代码是不正确的。
感谢精彩的文章!它对我来说真的很有帮助。我有一个问题。如果我有两个额外的变量,该怎么做?举个例子,我的数据看起来是这样的:
日期 风速 雨量 价格
20160101 10 100 1000
20160102 10 80 1010
…
我想预测价格。
你好Jeremy,每个输入都会是一个特征。然后你可以使用窗口方法将多个特征的多个时间步构造成新的特征。
例如
嗨,Jason,
感谢您的精彩讲解!
我有一个像Jeremy一样的问题。如果我想预测2个变量,有什么建议吗?数据框如下所示
日期 X1 X2 X3 X4 Y1 Y2
我想预测Y1和Y2。另外,Y1和Y2之间存在一些相关性。
你好Shimin,
是的,这通常被称为深度学习中的序列预测问题,或时间序列预测中的多步预测问题。
您可以使用具有两个输出的LSTM或具有两个输出的MLP来建模此问题。请确保将数据准备成此形式。
希望这能有所帮助。
Jason,
关于使用Keras处理TS数据的精彩文章。我的数据集如下:#打印
日期 时间 Power1 Power2 Power3 Meter1 Meter2
12/02/2012 02:53:00 2.423 0.118 0.0303 0.020 1.1000
我的特征向量/预测变量是日期、时间、Power1、Power2、Power3、Meter1。我正在尝试预测Meter 2。
我想用RNN/LSTM而不是MLP来做上述时间序列预测。
你能建议一下是否可行吗?如果可行,有什么提示吗?
谢谢
Sunny
你好Sunny,本教程将帮助你入门。
https://machinelearning.org.cn/time-series-prediction-lstm-recurrent-neural-networks-python-keras/
你好,教程很棒。
我有一个问题:实时数据是否有用?比如说,我能访问一些实时数据(软件下载量、股票价格……),当有新数据可用时,是否需要每次都重新训练模型?
我同意,nicoad,一个实时示例会很棒。我会研究一下。
神经网络的一个优点是它们可以通过新数据进行更新,而不必从头开始重新训练。
你好,你的原始帖子代码是使用1(或3)维X来预测后续的1维Y。如果我想使用48维X来预测第49和第50维怎么办?我的意思是,我增加了预测的时间单位,预测3个甚至10个时间单位。在这种情况下:这是否意味着我只需要更改最后一个输出层的output_dime?
model.add(Dense(
output_dim=3))
这样对吗?
是的,看起来是对的。让我知道你的进展。
你好Jason,我在jupyter notebook上做了一个快速实验,并发布在github上。
github:https://github.com/sherlockhoatszx/TimeSeriesPredctionUsingDeeplearning
代码可以工作。
但是,如果你非常仔细地查看trainPredict数据(notebook的IN[18])。
前3个数组是
array([[ 128.60112 , 127.5030365 ],
[ 121.16256714, 122.3662262 ],
[ 144.46884155, 145.67802429]
列表中的[ 128.6,127.5 ] [121,2,122,3]看起来不像t+1和t+2。
**相反,**它看起来像是对1个单位的2个可能预测。
我的意思是[128.6,127.5]不是t+1和t+2的预测,它很可能是t+1的2种可能的预测。
一个具有2个维度的输出单元和2个具有1个维度的输出单元是不同的。
我和github上的其他人讨论过。
https://github.com/Vict0rSch/deep_learning/issues/11
似乎我应该使用seq2seq或timedistributed wrapper。
我还在探索这个问题,还没有找到一个解决方案。
您有什么建议?
这听起来是个好建议。将问题视为序列到序列的问题。
你好Jason,我在jupyter notebook上做了一个实验,并发布在github上。代码可以输出2列数据。
https://github.com/sherlockhoatszx/TimeSeriesPredctionUsingDeeplearning/blob/master/README.md
但是!如果你非常仔细地查看trainPredict数据(notebook的IN[18])。
前3个数组是
array([[ 128.60112 , 127.5030365 ],
[ 121.16256714, 122.3662262 ],
[ 144.46884155, 145.67802429]
列表中的[ 128.6,127.5 ] [121,2,122,3]看起来不像t+1和t+2。
**相反,**它看起来像是对1个单位的2个可能预测。
我的意思是[128.6,127.5]不是t+1和t+2的预测,它很可能是t+1的2种可能的预测。
1个具有2个维度的输出单元和2个具有1个维度的输出单元是不同的。
输入维度和输出维度对于神经网络来说会很棘手。
感谢Jason的概念解释。我有一个关于KERAS包的问题。
看起来你将原始数据(x=118等)输入到了KERAS。你知道KERAS是否需要标准化数据到(0,1)或(-1,1)或某个均值为0的分布吗?
— Xiao
好问题Xiao,
在处理神经网络时,标准化数据或归一化数据是个好主意。在你的问题上试试看,看看它是否会影响你模型的性能。
这个帖子早期版本的数据不是被归一化了吗?
我不这么认为,Satoshi。
不过,总的来说,归一化对于处理神经网络是个好主意。
我一直收到这个错误 dt = datetime.datetime.fromordinal(ix).replace(tzinfo=UTC)
ValueError: ordinal must be >= 1
抱歉charith,我之前没见过这个错误。
在你的文字中你说,窗口大小是3,但在你的代码中你使用了loop_back = 10?
谢谢Trex。
那是我之前做实验时的一个笔误。已修复。
没关系,
我还有个问题
算法现在预测1个值。我想用这个MLP预测n个值。
这该怎么做?
重新构建你的训练数据集以匹配你的需求,并更改输出层中的神经元数量为你想要的输出数量。
您好,
很棒的教程。
我正在尝试为时间序列预测构建一个NN。但我的数据与您的不同。
我想预测一整天。但一整天定义为48个值。
空白数据的一些行
2016-11-10 05:00:00.000 0
2016-11-10 05:30:00.000 0
2016-11-10 06:00:00.000 1
2016-11-10 06:30:00.000 3
2016-11-10 07:00:00.000 12
2016-11-10 07:30:00.000 36
2016-11-10 08:00:00.000 89
2016-11-10 08:30:00.000 120
2016-11-10 09:00:00.000 209
2016-11-10 09:30:00.000 233
2016-11-10 10:00:00.000 217
2016-11-10 10:30:00.000 199
2016-11-10 11:00:00.000 244
一整天的每半小时都有一个值。
我想预测未来几天每半小时的值。这怎么可能?
你能做一个多元时间序列的例子吗?🙂
是的,博客上安排了一些教程。一旦发布,我会链接给您。
为什么reLu激活函数不需要输入数据在0到1之间归一化?
如果我使用sigmoid激活函数,输入数据必须被归一化。
但是为什么reLu不需要呢?
通常是因为sigmoid函数对值施加了硬性限制,使其超出0-1的范围。
整流函数是完全不同的,你可以在这里了解它。
https://en.wikipedia.org/wiki/Rectifier_(neural_networks)
我建议在excel或Python中实现它,并尝试输入和输出来玩。
另一个问题
你的输入层使用reLu作为激活函数。
但是为什么你的输出层没有激活函数?如果我没有给出参数,Keras是否有一个默认的激活函数?如果有,是什么?如果没有,为什么一个层可以没有激活函数?
谢谢 🙂
是的,默认是线性,这对于回归问题来说是一种理想的激活函数。
作为参数*没有给出
一个愚蠢的问题,先生。
假设我有一个包含两个字段的数据集:“date”(时间戳),“amount”(float32)描述了一年。
每个月的第1天,金额设置为-200。
这对于11个月都是如此,除了第12个月(12月)。
是否有办法训练一个NN,使其返回12,标记12月在其第一天没有该金额?
抱歉Dmitry,我不太明白你的问题。
也许你能换个方式问,或者提供一个小的例子?
是否常见只预测一个时间点?或者有没有预测未来2、3、4个时间点的方法/途径,如果有,如何评估这些预测的表现指标?
好问题Thomas。
预测时间范围是特定于问题的。你可以使用具有多个输出神经元的MLP或LSTM来预测多个时间步。
评估是特定于问题的,但可以是整个预测的RMSE,或每个预测超前时间的RMSE。
感谢Jason的帖子,我从中受益匪浅。现在我有一个问题:我如何获得1961-01的乘客数量?期待您的回复。
你可以用所有可用数据训练你的模型,然后调用model.predict()来预测下一个样本外观测值。
模型似乎无法预测下个月的未来?
zhou,你具体指的是什么?
抱歉。我想预测未来的乘客数量,我该怎么做?
感谢Jason的教程,非常有用。如果我们知道如何选择MLP的各种参数,以及如何优化它们,那就更好了。
谢谢Viktor,我希望涵盖更多关于这个主题的教程。
你可以看看这篇关于如何最佳调整MLP的文章。
https://machinelearning.org.cn/improve-deep-learning-performance/
在第一种情况下。如果我把模型向左移动,它将是一个很好的预测模型,因为预测值与原始数据非常吻合。可以这样做吗?
你能举个例子说明你的意思吗?
激活函数是否有任何特定条件?如何决定哪个激活函数更适合线性或非线性数据集?
有一些规则。
隐藏层使用Relu,因为它效果很好。Sigmoid用于二元输出,线性用于回归输出,softmax用于多类分类。
通常你可以转换你的数据以适应给定的激活函数的边界(例如,sigmoid是0,1,tanh是-1,1等)。
希望这些能作为一个开始有所帮助。
如何决定优化器?它与激活函数有关吗?
不是真的。这似乎是一种品味问题(速度与时间)。
你在本教程中使用的是哪种验证?是交叉验证吗?
不,是训练-测试分割。
还有其他可以用于时间序列预测的深度学习算法吗?为什么选择多层感知器进行时间序列预测?
是的,您可以使用长短期记忆(LSTM)网络。
嗨,Jason,
我一直有一个疑问,如果我们只预测一个时间步(t+1),那么准确的预测结果就是复制t的值,正如第一个图所示。当我们添加更多输入(如 t-2、t-1、t)时,预测结果会变差。即使与其他预测方法如 ARIMA、RNN 相比,这个结论可能仍然是正确的。为了更好地展示这些预测方法的强大之处,我们是否应该尝试预测更多时间步 t+2、t+3……?
谢谢
使输入数据平稳化并进行缩放是个好主意。然后需要为问题调整网络。
亲爱的杰森。
感谢您在此分享您的信息。不过,我无法重现您的最后一张图。在我的机器上,它看起来仍然是“糟糕”的那张图。
https://www2.pic-upload.de/img/32978063/auto.png
我使用了上面提到的代码。我的理解有什么错误吗?
https://pastebin.com/EzvjnvGv
谢谢!
我真是太笨了 :)
也许可以尝试让网络拟合更长时间?
感谢这篇帖子……实际上我正在为我的工作参考这个。我的数据集是线性的。我可以使用 softplus 或 elu 作为线性数据的激活函数吗?
可以,但您的模型可能比需要的更复杂。事实上,线性模型(如线性回归或逻辑回归)可能更适合您。
首先,谢谢 Jason。我尝试在我的时间序列数据上使用 MLP 和 LSTM 模型,并得到了一些 RMSE 值。(例如,训练 RMSE 为 10,测试 RMSE 为 11)(我的示例计数为 1400,最小值:21,最大值:210)RMSE 的可接受值是多少?
干得好!
可接受的 RMSE 取决于您的问题以及您可以容忍的误差大小。
好文章,谢谢。
是否可以构建一个具有多个输出的 DNN?例如,输出层有几个神经元负责不同的飞行方向。可能会出现哪些困难?
是的,试试看。
未来时间步的技能通常会很快下降。
您好,Jason,我是一名学生,最近我正在学习您的博客。您能否在此文章中展示深度学习模型的训练历史?如果您能做到,我将非常感激,因为我是新手。谢谢!
这个例子展示了如何显示训练历史。
https://machinelearning.org.cn/display-deep-learning-model-training-history-in-keras/
有人知道如何将此示例代码的观测值存储到一个变量中,以便该变量可以用于预测航空数据集之外的(一个时间步的)未来数据吗?或者有什么代码片段吗?
将 testX 数组扩展为例如 [0,0,0] 以预测未见数据/未来一个时间步,这在逻辑上是否正确?
这不需要。
在所有可用数据上拟合您的模型。当出现新观测值时,适当地缩放它,将其与模型所需的其他滞后观测值一起收集作为输入,然后调用 model.predict()。
是否有神奇的方法来获取基于观测值的预测的正确数组格式?
我总是得到错误的格式。
obsv1 = testPredict[4]
obsv2 = testPredict[5]
obsv3 = testPredict[6]
dataset = obsv1, obsv2, obsv3
dataX = []
dataX.append(dataset)
#dataX.append(obsv2)
#dataX.append(obsv3)
myNewX = numpy.array(dataX)
更新
经过几天,我终于能够在此示例(下方代码)上对未见数据进行预测了。
这种方式正确吗?
应该使用多少个观测值才能对未见数据进行良好的预测?
是否有标准工具可以衡量相应的性能并建议观测值数量?
这个主题是否与选择时间序列分析的正确窗口大小相同,或者有什么区别?
代码
obsv1 = float(testPredict[4])
obsv2 = float(testPredict[5])
obsv3 = float(testPredict[6])
dataX = []
myNewX = []
dataX.append(obsv1)
dataX.append(obsv2)
dataX.append(obsv3)
myNewX.append(dataX)
myNewX = numpy.array(myNewX)
futureStepPredict = model.predict(myNewX)
print(futureStepPredict)
看起来不错。
所需的观测值数量取决于您如何配置模型。
对于给定的问题,“最佳”窗口大小是未知的,您必须通过反复试验来发现它,请参阅此帖子。
https://machinelearning.org.cn/a-data-driven-approach-to-machine-learning/
是否有方法或反复试验策略来找出多少个滞后观测值对于预测未见数据是“最佳”的?
look_back(窗口大小)和滞后观测值之间有关联吗?
理论上,我可以使用所有观测值来预测未见数据的一个时间步。这有用吗?
look-back 定义了滞后。
您可以使用 ACF 和 PACF 图来发现最相关的滞后观测值。
https://machinelearning.org.cn/gentle-introduction-autocorrelation-partial-autocorrelation/
LSTM 的“承诺”是它们可以学习适当的时间依赖结构,而无需显式指定。
如果我向模型输入 3 个观测值,我将得到 3 个未见数据的预测/数据点。
如果我只想预测未来一个时间步,我应该对这 3 个预测步骤的结果取平均值,
还是应该只使用最后一个预测步骤?
谢谢你。
如果只需要预测一个时间步,我建议将模型更改为只进行一次预测。
您会如何在此方面更改此网站的多层感知器模型?
我这里有个误解。不要犯同样的错误,读者!
通过“obsv(n) = float(testPredict[n])”,我将测试数据集的预测作为观测值。
这是错误的!
相反,我们应该始终采用原始数据的某个分区作为 x/观测值,然后用训练/拟合好的模型来预测未见数据。
就像在 R 中一样
https://machinelearning.org.cn/finalize-machine-learning-models-in-r/#comment-401949
这是对的吗 Jason?
如果您需要一个具有 1 行和 2 列的二维数组,您可以这样做:
你好先生,
我是来自马来西亚的 Arman。我是 Multimedia University 的一名学生。我想做一个“使用深度学习对 Hadoop 进行自适应性能调整”。那么对于这类问题,我应该考虑哪个框架?比如 DBM、DBN、CNN、RNN?
我需要您的建议。
致以最诚挚的问候
Arman
我建议遵循这个过程。
https://machinelearning.org.cn/start-here/#process
关于这段代码还有其他需要注意的地方吗?或者它是否已更新并且在技术上是正确的?
我们总能做得更好。
对于这个例子,我建议探索将数据作为时间步输入,并尝试更适合更多 epoch 的大型网络。
嗯,我不确定我是否理解正确。
我相信我已经以这种方式输入了时间步
返回 datetime.strptime(x, ‘%Y-%m-%d’)
我的原始数据项有一个不错的日期列。您是指这个吗?
我们如何探索更适合更多 epoch 的大型网络?
我现在(管道)中所有参数都在一个中央批处理文件中。
我应该增加 epoch 以...?
model.fit(trainX, trainY, epochs=myEpochs, batch_size=myBatchSize, verbose=0)
谢谢你。
我正在尝试改编来自
https://machinelearning.org.cn/time-series-forecasting-long-short-term-memory-network-python/
……并在脚本的上下文中构建名为 EXPECTED 的变量。
不幸的是,我不知道如何正确地做到这一点。我现在有点沮丧。
for i in range(len(test)): <-- 我应该在这里使用什么更好?
expected = dataset[len(train) + i + 1] <-- 我应该在这里使用什么更好?
print(expected)
到目前为止这看起来很酷,我能不能用索引来检索一个名为 EXPECTED 的变量?
for i in range(len(testPredict))
pre = '%.3f' % testPredict[i]
print(pre)
代码示例将有助于解决我的索引混淆问题。
这是一个很好的例子,说明机器学习不仅仅是知道如何使用算法/库。理解我们正在处理的数据总是很重要的。对于这个例子,由于它是 1 维的,所以幸运的是它相对容易做到。
在第一个例子中,我们给算法一个前一个值,并问它“下一个值是什么?”。
由于我们使用的是不考虑任何时间行为的神经网络,因此该系统是高度超定的。例如,y 值为 290 的值有很多。其中一半的值在下降,一半的值在上升。如果我们不给算法任何指示,它怎么会知道测试数据点的方向会是什么?信息量太少了。
一种想法可能是另外给算法提供梯度,这将有助于决定后续值是上升还是下降(这某种程度上就是我们通过增加 lookback 为 2 来做的)。然而,结果显然没有显著改善。
在这里,我想回到“理解你正在处理的数据”。如果我们看看图表,有两个特征是明显的。一个普遍的上升趋势和一个周期性。我们希望算法能够覆盖这两者。只有这样,预测才会准确。我们看到有一个明显的 12 个月周期性(想想暑假、圣诞节)。如果我们希望算法在不包含模型知识(因为我们使用的是 ANN)的情况下覆盖该周期性,我们至少必须以一种可以推断出该属性的格式提供数据。
因此:将 lookback 扩展到 12 个月(X 中的 12 个数据点)将导致“提前 1 个月”的预测得到显著改进!但现在,我们有了更高的特征维度,由于计算原因这可能不是期望的(对于这个玩具示例无关紧要,但还是)。接下来,我们只取 3 个月为 lookback 步(仍然回溯 12 个月,但在数据中跳过 2 个月)。我们仍然覆盖了周期性,但减少了特征量。算法在“提前 1 个月”预测方面提供了几乎相同的性能。
另一个可能性无疑是添加月份(一月、二月等)作为分类特征。
谢谢 Stefan,非常有见地。
您好 Jason!感谢您提供这个很棒的例子!我一直在寻找这样的例子。
我最近在学习神经网络,并尝试像这个例子一样预测温度这样的数字,但我有更多的输入来预测温度。
那么,如果我有 5 个输入,我应该编辑 pandas.read.csv(..., usecols[1], ...) 为 usecols[0:4] 吗?
提前感谢!
祝好,
保罗
我的意思是像下面这样的
X1 X2 X3 X4 X5 Y1
380 17.00017 9.099979 4 744 889.7142
谢谢!
这篇帖子可能会帮助您构建预测问题。
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
感谢您回复我!:) 并且抱歉迟回复。
当我点击您写的链接时,它需要用户名和密码.. :'(
抱歉,已修复。请重试。
没关系。我发现链接是 `machinelearningmastery` 而不是 `mlmastery.staging.wpengine.com` 🙂
谢谢。:)
祝好,
保罗
是的,出于某种原因我链接到了我网站的暂存版本,抱歉。
嗨,我正在尝试做一个没有给出测试用例但模型应该预测时间序列的所谓未来。因此,我编写了一个代码,该代码获取训练数据的最后一行并预测一个值,然后将预测值放在该行的末尾并再次进行预测。执行此过程 len(testX) 次后。它最终形成了一个指数图。如果您想查看,我可以上传它。我的代码如下。我不明白为什么它会这样工作。希望您能阐明。
prediction=numpy.zeros((testX.shape[0],1))
test_initial=trainX[-1].copy()
testPredictFirst = model.predict(test_initial.reshape(1,3))
new_=create_pred(test_initial,testPredictFirst[0][0])
prediction[0]=testPredictFirst
for k in range(1,len(testX))
testPredict=model.predict(new_.reshape(1,3))
new_=create_pred(new_,testPredict[0][0]) #这段代码是这样的:如果 new_ 是 [1,2,3] 并且 testPredict[0][0] 是 4,则输出是 [2,3,4]
prediction[k]=testPredict
真的非常棒且有用
谢谢。
你好,
这是一篇很棒的文章。非常有帮助。我在我的分类时间序列预测问题中实现了这些概念。但是得到的结果非常出乎意料。
我的时间序列只能取 0 到 9 的 10 个值。我大约有 15k 行数据。我想预测时间序列中的下一个值。
但是问题是“1”在时间序列中出现频率最高。因此,从第 2 或第 3 个 epoch 开始,LSTM 就会预测出“1”,无论输入是什么。我尝试了更改超参数,但没有奏效。您能指出可能解决该问题的方法吗?
也许您的问题对所选模型来说太具挑战性了。
尝试使用具有较大窗口大小的 MLP 进行测试。调整模型的超参数。
我对编码是新手。我如何从您的示例代码中预测 t+1?我的意思是,从您的代码中,我想要 t+1 的值,或者您能否更详细地解释预测 t+1 的代码?
如果您是编程新手,也许可以从更简单的东西开始,例如更简单的线性模型。
https://machinelearning.org.cn/start-here/#timeseries
嗨,Jason,
为什么您认为使数据平稳化在这个方法中是一个好主意?我知道 ARIMA 假设数据是平稳的,但这对于神经网络来说也普遍有效吗?我以为归一化就足够了。
是的,这将使建模问题更容易。
我收到了这个错误
帮帮我,我是新手。我正在使用 tensorflow。
回溯(最近一次调用)
File “international-airline-passengers.py”, line 49, in
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
ValueError: could not broadcast input array from shape (94,1) into shape (46,1)
我解决了我的错误。这是一个愚蠢的错误。
谢谢
很高兴听到您解决了问题。
嗨,Jason,
非常感谢您提供所有这些信息。我有一个问题!为什么使用 theano、tensorflow 或 keras 训练的回归模型的准确性(以 MSE 计)不好?然而,如果我们尝试使用 MATLAB 的神经网络工具箱来训练 MLP 或任何其他模型,模型就会在 e 的负幂值方面显示出非常好的准确性。为什么会这样?
准确度是用于分类算法预测标签的分数,RMSE 是用于回归算法预测数量的分数。
你好,首先感谢您的教程。我在实现这个功能时遇到了一个错误。
–> 128 testPredictPlot[len(trainPredict)+(look_back*2)+1:len(Y1)-1] =
> testPredict
of: ValueError: could not broadcast input array from shape (19) into shape
> (0))
我的完整代码是:https://stackoverflow.com/questions/51401060/valueerror-could-not-broadcast-input-array-from-shape-19-into-shape-0/51403185#51403185
如果您能提供帮助,我将非常感激,因为我知道这可能是一个小问题,但我无法解决。谢谢。
嗨,Jason,
也许是我没有理解什么。
你说的话像是
“我们可以看到,该模型在拟合训练和测试数据集方面表现非常糟糕。它基本上预测的输入值与输出值相同。”
在谈论第一张图片时。我不明白为什么这样的预测很糟糕。在我看来,它看起来非常好。我问这个问题是因为我用我自己的数据集试了你的代码,并且得到了类似的结果,也就是说,它看起来很完美,只是稍微有点偏移。但它为什么很糟糕呢?
另外,在接下来的部分,你说
“从图中可以看出,预测结果中存在更多的结构。”
我们如何看到这种结构?在我看来,它看起来比第一个差。
如果我重复引用了您两次,请原谅,但我真的不理解……
如果模型不能比预测输入值与输出值相同做得更好,那么这个模型就没有什么技能,你也可以直接使用一个持久性模型。
https://machinelearning.org.cn/persistence-time-series-forecasting-with-python/
嗨 Jason
您知道如何在PyCharm中使用Dynamic CNN进行训练吗?
请给我们更多解释……
谢谢你
嗨,Jason,
我觉得我有点困惑。
您的帖子似乎解决了如何从 t 预测 t+1 的问题。
然而,输出看起来相当糟糕,因为它最终表现得像一个持久性模型。
那么,使用 Keras 来达到与持久性模型相同的目标有什么价值呢?
您将如何修改您的网络,使其表现优于普通的持久性模型?
模型结构会是什么样的?
提前感谢!
我建议使用针对该问题进行调整的 MLP,并将许多滞后变量作为输入。
嗨 Jason,感谢您的精彩教程,但我找不到 t+1 的值。我们能用它来预测股票价格吗?
使用持久性模型来预测短期股票价格。
https://machinelearning.org.cn/gentle-introduction-random-walk-times-series-forecasting-python/
嗨,Jason,
这篇文章以及随后的评论都非常有帮助。我尝试过用更多的滞后(例如 10~30)或更多的层来预测股票价格。但在网络中增加一层后,损失就更难/更慢地减小,这使得在 10,000 多个 epoch 中结果很差。您对此有什么想法吗?
谢谢你。
我相信证券价格是随机游走的,是不可预测的。
https://machinelearning.org.cn/gentle-introduction-random-walk-times-series-forecasting-python/
感谢您的及时回复。
是的,我相信预测股票价格非常困难。但是,我在本篇文章中通过一个具有 8 个神经元和 ReLU 函数的隐藏层,在几个 epoch 后就能获得与您类似的结果。所以这可能只是巧合?
亲爱的 Jason,
我正在学习时间序列预测,当看到您在航空公司乘客预测问题上的结果时,我感到很震惊。我对如此复杂的非线性问题的预测如此完美感到惊叹!
但是,当我查看代码时,我意识到您展示的并不是真正的预测,或者至少是不公平的。事实上,当您预测测试数据的结果时,您只预测了下一个时间戳的结果,而不是整个序列。
换句话说,您预测的是给定前一个数据点的情况下下一个时间戳的未来。
也许我误解了问题的目标,但根据我的理解,您试图预测给定过去某个时间点的未来乘客数量。
为了进行公平的比较,看看当网络仅根据过去的数据进行预测时会发生什么会很有趣。例如,您可以用最后一个训练点来预测第一个测试点,然后使用之前的预测来继续预测。我尝试这样做,结果简直是一团糟 :)
我现在想知道如何编写一个能够根据过去事件实际预测未来事件的网络。我也尝试了您提供的 LSTM 示例,但结果仍然令人失望……
祝好,
Alessandro
观点很好,我在这里列出了更好的例子。
https://machinelearning.org.cn/start-here/#lstm
你好,我想问你一个问题,verbose写一个epoch到底是什么意思?
例如,我有“0s – loss: 23647.2512”,这个数字是什么意思?
好问题。
它报告了 epoch 所花费的时间(秒)以及该 epoch 在训练集样本上的损失(误差度量)。
但是为什么每个 epoch 的损失都那么大?
例如:– 0s – loss: 543.4524 – val_loss: 2389.2405
……为什么损失这么大?最终的图表中训练和测试数据与默认数据集非常相似?
好问题,我无法回答。我怀疑这与您数据的尺度有关。也许您需要重新调整您的数据。
明白了,最后一个问题,请。这个数据集代表哪个国家的航空公司乘客?只是出于好奇 :)
我不知道,抱歉。
感谢教程!
是否会影响数据的随机打乱?例如使用‘numpy.random.shuffle(train_test_data’ 来随机选择训练和测试数据?
(如在此处使用)
https://stackoverflow.com/questions/42786129/keras-doesnt-make-good-predictions/51234143#51234143
一般来说,对时间序列来说,是的。您不应该随机打乱时间序列数据。
在这里了解更多
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
你好,
感谢您的教程。但是,在使用 loop_back=3 的情况下使用完全相同的代码时,图似乎比第二个图(loop_back=1)更相似!另外,比较测试和训练的误差是否有点令人困惑,因为在数据集的后半部分,斜率更陡?我的意思是,如果我们训练数据集是后 67%,测试数据集是前 33%,那么测试集上的误差会减小,而训练集上的误差会增加。以这种方式呈现结果(也许评估度量应该相对于当前时间窗口的值范围?)有点令人困惑。
无论如何,谢谢!
嗨,Jason,
很棒的教程!
您使用 shuffle 的默认值 True 来拟合模型,如下所示。
model.fit(trainX, trainY, epochs=200, batch_size=2, verbose=2)
我记得您在其他教程中指出,在训练时间序列时,不应该对其进行随机打乱。您有什么评论吗?
此致
是的,对于时间序列来说,数据的随机打乱是个坏主意!
def create_dataset(dataset, look_back=1)
我输入此代码时遇到一些错误
文件“”,第 1 行
def create_dataset(dataset, look_back=1)
^
SyntaxError: 解析时遇到意外的 EOF
您能帮我理解我哪里出错了。谢谢
确保您保留了代码的缩进。
另外,将代码保存到文件并在命令行中运行,更多详情请参见此处。
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
嗨,Jason,
很棒的教程!
但是,如何确定学习率?以及上面代码中的学习率是多少?
试错法,或者使用像 Adam 这样的方法自动调整。
你好。我有一个关于本章的问题。
我的理解如下。
在“训练”期间,权重是通过所有数据的 67% 计算出来的。
之后,我们使用所有数据的 33% 来进行预测。
问题
在“测试”期间,我们是否使用权重 y(t) 来预测 y_hat(t+1),而权重是使用 67% 的数据计算出来的?
我想知道在“测试”期间,使用什么数据来预测 y_hat(t+1)。
如果真实观测值可用,您可以使用它们作为输入;或者您可以使用预测值作为输入(例如,递归地)。
嗨 Jason,如何让它预测,比如 t + 60?
这被称为多步预测。
https://machinelearning.org.cn/multi-step-time-series-forecasting/
我有很多例子,也许可以从这里开始
https://machinelearning.org.cn/multi-step-time-series-forecasting-long-short-term-memory-networks-python/
你好杰森
一如既往,教程很棒! 谢谢。
我有 3 个问题
1) 如果我们有多步预测(例如用于回归分析),我们需要输出单元(神经元)的数量与输出步数相同,对吗? 类似于分类问题,我们需要使用与类别数量相同的输出神经元?
2) 我修改了神经网络模型,在单步输入的情况下(即 look_back == 1),使用更宽的模型(更多的单元或神经元)和更深的(更多的层,类似于您在多步输入或窗口中做的那样)……令人惊讶的是,我得到了“更糟糕的 MSE 和 RMSE 分数或指标!”
如何解释这一点?是由于模型过拟合吗?它是否类似于您在使用窗口(考虑到更多的回溯步长或滞后步长)时得到的结果,而您在您的案例中只得到了类似的分数?
我对这种 ANN 模型行为违背常识感到非常惊讶!如果存在,您有什么解释吗?
3) 对我来说,与经典图像分析和特征数据模型相比,时间序列分析的核心之一,除了引入 RNN 的其他技术(如 LSTM)之外,就是准备数据系列帧的工作,以及您使用函数定义创建输入 X 和输出 Y(或标签)的构建,该函数名为:def create_dataset(dataset, look_back):您同意吗?
提前感谢您的时间、努力和考虑!
致敬
JG
您有多种多步预测选项,例如单步模型的递归使用、向量输出或 seq2seq。我对每种方法都有教程。
也许模型过拟合了,需要进行分析。
是的,对问题进行框架化是影响最大的地方。
嗨 Jason,非常感谢您。我的问题可能非常愚蠢,但我想知道您是否能帮我回答一下。
我使用数据透视表来清理数据集并创建一个可用于时间序列分析的数据集(从更大的数据集中)。
我的日期列被视为索引,所以我只有一列。
Completed_dt
2005-01-31 5.0
2005-02-28 3.0
2005-03-31 5.0
2005-04-30 2.0
2005-05-31 6.0
2005-06-30 5.0
2005-07-31 6.0
2005-08-31 4.0
2005-09-30 6.0
2005-10-31 4.0
当我使用您的代码时
train_size = int(len(B1) * 0.67)
test_size = len(B1) – train_size
train, test = B1[0:train_size,:], B1[train_size:len(B1),:]
print(len(train), len(test))
我收到此错误:IndexError: too many indices for array
我知道原因是您有两列(日期列可能不是您数据中的索引),而我只有一列。
我尝试重置索引以修复错误,但执行后又出现了其他错误。
所以您知道应该在这行代码中进行什么更改以解决此错误吗?
train, test = B1[0:train_size,:], B1[train_size:len(B1),:]
谢谢你
也许试试先删除日期时间列?
嗨 Jason
我需要解决以下问题,下面是链接(Python 或任何语言)
https://stats.stackexchange.com/questions/309189/use-machine-learning-to-predict-a-next-day-of-visit-for-customer/309246
嗨 Jason,我有一个问题。此方法是否可用于非连续输入?例如,我正在研究老年人的活动每日步数。我发现他们的步行模式显示出每周变化的周期性。那么,我能否使用仅 t-7 和 t-14 的特征(也是两个输入,只是不连续)来预测 t+1?
当然,您可以根据需要构建任何输入,尝试这样的想法以提高性能是一个很好的主意。
嗨,Jason,
感谢您如此清晰的实现!
我刚开始一个项目,该项目旨在根据历史数据预测能源生产,而这些技术可能非常有帮助!
我看到了您发布的其他帖子(尤其是涉及多个输入的帖子),它们可能更好,但我想一步一步来。
我的问题如下:
我不确定是否理解了数据的形状(数据集、输入、输出):它是 (n_value,) 吗?
因为在 create_dataset 方法中,数据集似乎不仅仅是一个数组?
“a = dataset[i:(i+look_back), 0] ”
输入是否应该是这样的形状:(1, n_value)?
好问题,我建议从这些更现代的教程开始。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
你好,又是我。
我用电源生产的历史数据作为输入运行了网络,因此对于训练,train_X = array_of_int 和 train_Y = shifted_array_of_int。
当我尝试将预测作为输入(预测 t+2, ..., t+n)时,我最终得到了一条几乎是直线的结果……
您有解释吗?
谢谢
内容很棒。
谢谢。
我尝试使用您的代码处理我的数据集,它与您的数据集相似,但在训练后,程序出现以下错误:
print(‘Train Score: %.2f MSE (%.2f RMSE)’ % (trainScore, math.sqrt(trainScore)))
TypeError: must be real number, not list
您对如何解决此问题有什么想法吗?
谢谢
也许试试调试?
例如,打印出导致问题的行的原始元素,并理解为什么它们不符合预期?
嗨,我尝试将一封电子邮件发送到账户 jason@MachineLearningMastery.com,但没有收到回复,所以我在这里重复我的问题。
我想购买您网站上由您撰写的电子书“Python 深度学习”,但我想知道购买后是否能收到收据。
我是一名大学生,资金有限,所以如果能收到收据就更好了,因为我需要以某种方式报销费用。
非常感谢。
是的,我已经回复了您的邮件。
是的,购买后我可以提供税务收据,更多详情请参见此处。
https://machinelearning.org.cn/faq/single-faq/can-i-get-an-invoice-for-my-purchase
你好,Jason。
我还有另一个问题,我尝试计算平均绝对百分比误差 (MAPE),它非常大,我想知道为什么,您有什么建议吗?
也许先对数据进行缩放?
也许试试其他模型或模型配置?
为什么我们不将密集层替换为 LSTM 层?
您可以,请看这个。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
非常棒的文章!!
谢谢。
如何实现多输入时间序列预测与深度学习中的 LSTM 和 GRU
我提供了许多示例,您可以从这里开始。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
尊敬的Jason博士,
如果我们看函数
,目标是得到一个 AR(1) 模型,其中 1 是滞后 = lookback。
换句话说,如果您使用 statsmodels 包中的 AR(p) 模型,您可以指定滞后而无需诉诸 create_dataset 函数。
谢谢你,
悉尼的Anthony
换句话说,如果您想要一个 AR(1) 模型,您会告诉您的 statsmodels。
如果我们使用滞后为 1 的自回归模型,即 AR(1),并使用时间序列。
是的。
您好,先生,我正在自学机器学习,感谢您这样的导师提供的有益教程。请原谅我的问题可能很愚蠢,但我很想问:是什么指导了您选择的数字?例如,您实现了 3 的 look back,为了确定测试集的大小,您将数据集长度乘以了 0.67,并且 Dense 连接最初有 12 个节点,如果我没记错的话,就像我说的,我是新手。我的问题是,这些数字是标准的还是基于直觉的?如果它们是基于直觉的,我是否也可以基于任何其他数字,或者最好应该如何指导我的直觉来决定这些数字?
我的问题可能听起来很天真,但这是因为我需要充分的澄清。我实际上打算对电子健康记录运行时间序列,并且我想将它们指定为类别,例如成人/儿童每月/每周/每年,男性/女性每月/每周/每年,死亡/存活每月/每周/每年。请问这个时间序列模型是否可以实现?非常感谢您的回复,我期待着您的回复,谢谢!
配置主要是任意的——仅用于演示。
你好 Jason,
我在重塑原始数据集时遇到问题。我在 Pycharm 中运行了代码。它返回了此警告。您能帮我弄清楚原因吗?
谢谢!
a = history[i:(i + look_back), 0]
IndexError: 数组索引过多
这个可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好 Jason。我刚看了你关于使用 LSTM 的多输入帖子。但是您能否告诉我如何在此帖子中提到的这个非常神经网络中使用多输入?这将非常有帮助。谢谢。
是的,您可以在此处找到许多关于此主题的教程。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
你好 Jason,
非常感谢您关于时间序列深度学习的所有教程。
我已尝试对数据集应用缩放,例如最小-最大归一化和Z分数归一化。
我想问如何对此MLP使用反向缩放以获得实际预测,因为我只能找到此教程,该教程将反向缩放应用于预测。
https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/
如果您使用MinMaxScaler,则可以调用transform()进行缩放,并调用inverse_transform()进行反向缩放。
https://machinelearning.org.cn/standardscaler-and-minmaxscaler-transforms-in-python/
# 为训练生成预测
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
#反向缩放
trainPredict = scaler.inverse_transform(trainPredict)
testPredict = scaler.inverse_transform(testPredict)
dataset = scaler.inverse_transform(dataset)
我已尝试在model.predict之后添加此内容,它对绘图有效。但对于MSE。我无法对trainScore和testScore做同样的事情。有什么建议吗?
也许这个教程会有帮助
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
Jason,您好,我想问您一些问题。为什么在训练数据的末尾和测试数据的开头之间存在滞后?
如果您指的是图表,那是因为我们需要从T=0到N的数据来预测T=N+1。因此,如果我们要在k处分割训练和测试数据,基于训练数据的最后一次预测是k-1,而测试数据中的第一次预测是k+N。
并且如何删除滞后但仍然获得良好的预测?因为当我将look_back = 0时,没有滞后,但我的预测变得非常糟糕。谢谢Jason!
时间序列预测通常精度较低(与其他非时间序列线性回归模型相比),这是可以预料的。但是,如果您的look_back太小,您基本上没有提供足够的信息来预测输出。这就是为什么您会觉得它很糟糕。
那么我们如何知道k是多少?也许更改脚本,如果解决方案改变了脚本,我们应该更改脚本的哪一部分?感谢您的帮助。
k是什么?
我很抱歉,此消息是为了回复您之前的答案,这是您的答案:“如果您指的是图表,那是因为我们需要从T=0到N的数据来预测T=N+1。因此,如果我们要在k处分割训练和测试数据,基于训练数据的最后一次预测是k-1,而测试数据中的第一次预测是k+N”。我们如何知道k是多少?
哦。抱歉,我的界面看不到。
对于那个“k”,它是任意的。您可以决定在哪里截断训练和测试数据。常见的选择可能是前80%或70%作为训练数据。
我已经尝试过了,结果是在预测之后没有k值。例如,我的k值为1,但在我使用了这个脚本后,在预测之后没有k值?如何使预测之后有k值。谢谢!
抱歉,我无法理解您的问题。
这是示例
预测前的训练数据
2.730232716
1.064525604
0.9559851884841919
0.5522800087928772
0.596206
0.6401318311691284
2.758859157562256
3.2396929264068604
1.6957186460494995
1.148859262
1.5998286008834839
预测后的训练数据
1.459058
2.596945
2.0854816
1.1776162
1.1178119
0.89212847
--
--
2.1010685
2.3628752
1.522204
为什么会有空值?我选择训练数据占数据集的0.625%,训练数据和测试数据之间的阈值是2.7和3.5,在我预测之后它就变为空了。
如果我预测时间t-2,那么在预测结果中会有2个时间/数据的缺失值,是这样吗?
是的,您说对了!
我们可以知道缺失值是Adrian吗?如果可以,如何找到那个值?感谢您的帮助!
将测试集开始时间提前两个样本。换句话说,您可以在训练集和测试集之间留出两个样本的重叠。
多步预测可以解决这个问题吗?
抱歉,我还是不明白。您能举个例子吗?谢谢!
简单来说:只需将整个数据序列输入预测,您将消除间隙。
是否通过将训练数据减少2个数据,并将测试数据增加2个数据来实现?
不要减少训练数据大小,而是增加测试数据大小。这样您就会有一些重叠。
我有一个问题,我已经尝试过使用比测试数据少的训练数据,但结果显示训练数据较少时模型的性能更好。您知道为什么会这样吗?
较少的训练数据可能意味着模型没有足够多的上下文来学习问题。使用某些算法(如神经网络)进行建模时,更多的训练数据通常更好。
我有一个关于缩放器值的问题,您没有使用MinMax缩放器吗?
我使用了,但之后在Rescale时遇到了问题。
这里的rescale是什么意思?
在create_dataset方法中
def create_dataset(dataset, look_back=1)
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1)
a = dataset[i:(i+look_back), 0]
dataX.append(a)
dataY.append(dataset[i + look_back, 0])
return np.array(dataX), np.array(dataY)
我认为应该是
def create_dataset(dataset, look_back=1)
dataX, dataY = [], []
for i in range(len(dataset)-look_back)
a = dataset[i:(i+look_back), 0]
dataX.append(a)
dataY.append(dataset[i + look_back, 0])
return np.array(dataX), np.array(dataY)
无需减去1
感谢您的反馈Udesh!
亲爱的杰森,您好,
我有一个关于“使用窗口方法的多层感知机”部分中look_back参数的问题。在您在此部分提供的整个代码列表中,“#将一个值数组转换为数据集矩阵”部分,您是否应该将look_back定义为3而不是look_back=1?
嗨Tara…感谢您的反馈!让我们知道您的模型在您注意到的修改后表现如何。