时间序列数据集可能包含季节性成分。
这是随时间重复的周期,例如每月或每年。这种重复的周期可能会掩盖我们在进行预测时希望建模的信号,反过来又可能为我们的预测模型提供强大的信号。
在本教程中,您将了解如何使用 Python 识别和修正时间序列数据中的季节性。
完成本教程后,您将了解:
- 时间序列中季节性的定义以及它为机器学习预测提供的机会。
- 如何使用差分法创建每日温度数据的季节性调整时间序列。
- 如何直接对季节性成分进行建模并将其明确地从观测值中减去。
开始您的项目,阅读我的新书《Python 时间序列预测》,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。
- 2019年8月更新:更新了数据加载以使用新的API。

如何使用 Python 识别和去除时间序列数据中的季节性
图片由 naturalflow 提供,部分权利保留。
时间序列中的季节性
时间序列数据可能包含季节性变化。
季节性变化,或称季节性,是指随时间规律性重复的周期。
一年内重复的模式称为季节性变化,尽管该术语更广泛地应用于任何固定周期内的重复模式。
— 第 6 页,《R 语言时间序列入门》
时间序列中的周期结构可能包含季节性,也可能不包含。如果它在相同的频率下持续重复,则具有季节性,否则则不具有季节性,称为周期。
对机器学习的好处
理解时间序列中的季节性成分可以提高机器学习建模的性能。
这可以通过两种主要方式发生:
- 更清晰的信号:识别并去除时间序列中的季节性成分可以使输入变量和输出变量之间的关系更清晰。
- 更多信息:关于时间序列季节性成分的附加信息可以提供新信息以提高模型性能。
这两种方法都可能在项目中很有用。在数据清理和准备过程中,可能会对季节性进行建模并将其从时间序列中去除。
提取季节性信息并将其作为输入特征,直接或以摘要形式提供,可能发生在特征提取和特征工程活动中。
季节性类型
季节性有很多种;例如:
- 一天中的时间。
- 每日。
- 每周。
- 每月。
- 每年。
因此,确定您的时间序列问题中是否存在季节性成分是主观的。
确定是否存在季节性方面最简单的方法是绘制数据并进行审查,可能在不同的尺度上并添加趋势线。
去除季节性
一旦确定了季节性,就可以对其进行建模。
季节性模型可以从时间序列中移除。这个过程称为季节性调整,或去季节化。
季节性成分已被移除的时间序列称为季节性平稳。具有明显季节性成分的时间序列称为非平稳。
在时间序列分析领域,有许多复杂的方法可以研究和提取时间序列中的季节性。由于我们主要对预测建模和时间序列预测感兴趣,因此我们仅限于那些可以在历史数据上开发并在预测新数据时可用的方法。
在本教程中,我们将研究两种对具有强加性季节性成分的经典气象类问题(每日温度)进行季节性调整的方法。接下来,让我们看看本教程将使用的数据集。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
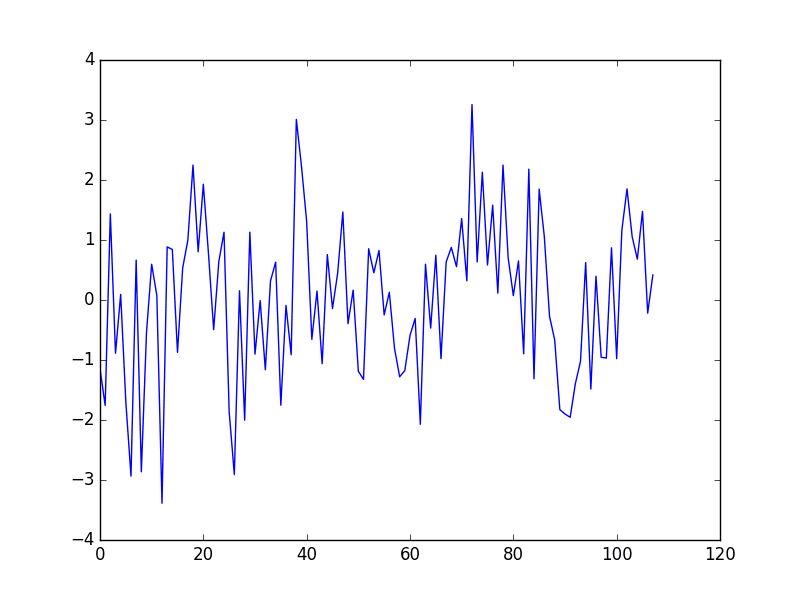
日最低气温数据集
此数据集描述了墨尔本市 10 年(1981-1990 年)的每日最低气温。
单位是摄氏度,共有3650个观测值。数据来源归功于澳大利亚气象局。
以下是数据的前 5 行样本,包括标题行。
|
1 2 3 4 5 6 |
"日期","温度" "1981-01-01",20.7 "1981-01-02",17.9 "1981-01-03",18.8 "1981-01-04",14.6 "1981-01-05",15.8 |
下面是对整个数据集的图示,您可以在此处下载数据集并了解更多关于它的信息。
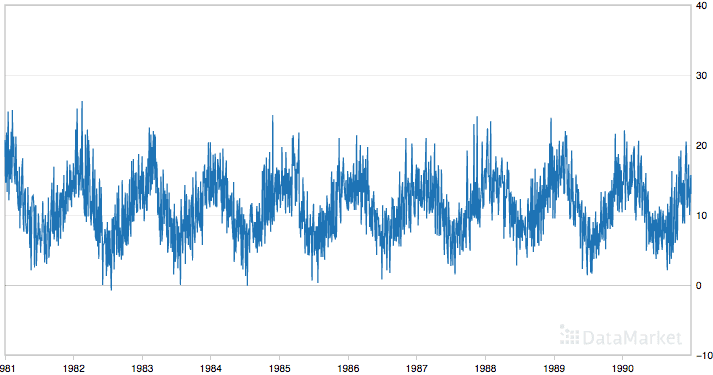
日最低气温
该数据集显示了强大的季节性成分,并且具有良好的、精细的细节可供处理。
加载每日最低温度数据集
下载每日最低温度数据集,并将其保存在当前工作目录中,文件名为“daily-minimum-temperatures.csv”。
下面的代码将加载并绘制数据集。
|
1 2 3 4 5 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0) series.plot() pyplot.show() |
运行示例将创建以下数据集的图。
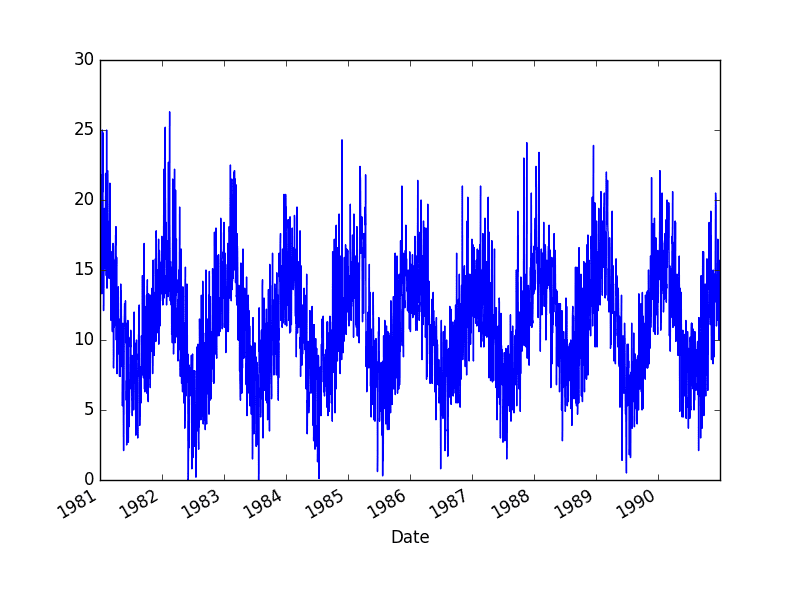
每日最低温度数据集
差分季节性调整
修正季节性成分的一种简单方法是使用差分。
如果存在一个以一周为周期的季节性成分,那么我们可以通过减去上一周的值来消除今天的观测值。
对于每日最低温度数据集,看起来我们每年都有一个季节性成分,从夏天到冬天都有波动。
我们可以从同一天去年的每日最低温度中减去该值来纠正季节性。这需要特殊处理闰年中的 2 月 29 日,并且意味着第一年的数据将无法用于建模。
下面是一个在 Python 中对每日数据使用差分法的示例。
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0) X = series.values diff = list() days_in_year = 365 for i in range(days_in_year, len(X)): value = X[i] - X[i - days_in_year] diff.append(value) pyplot.plot(diff) pyplot.show() |
运行此示例将创建一个新的季节性调整数据集并绘制结果。
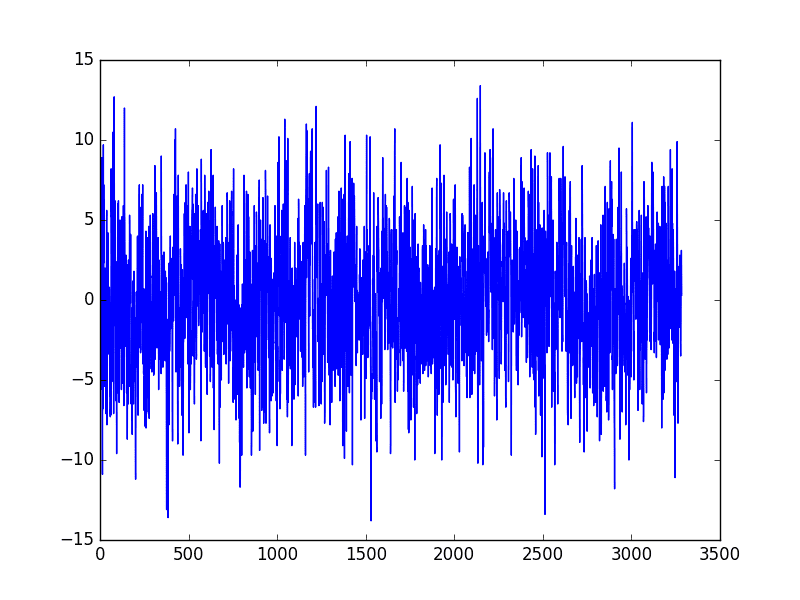
差分季节性调整的每日最低温度
我们的数据集中有两个闰年(1984 年和 1988 年)。它们没有得到明确处理;这意味着从 1984 年 3 月开始的观测值的偏移量是错误的,而在 1988 年 3 月之后,偏移量则错误了两次。
一种选择是更新代码示例以考虑闰日。
另一种选择是考虑到一年中任何给定时间段内的温度可能都是稳定的。也许是几周。我们可以通过考虑日历月份内的所有温度都是稳定的来简化此过程。
一个改进的模型可能是减去去年同一日历月份的平均温度,而不是同一天的温度。
我们可以先对数据集进行重采样,得到月平均最低温度。
|
1 2 3 4 5 6 7 8 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0) resample = series.resample('M') monthly_mean = resample.mean() print(monthly_mean.head(13)) monthly_mean.plot() pyplot.show() |
运行此示例将打印出前 13 个月的月平均最低温度。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
日期 1981-01-31 17.712903 1981-02-28 17.678571 1981-03-31 13.500000 1981-04-30 12.356667 1981-05-31 9.490323 1981-06-30 7.306667 1981-07-31 7.577419 1981-08-31 7.238710 1981-09-30 10.143333 1981-10-31 10.087097 1981-11-30 11.890000 1981-12-31 13.680645 1982-01-31 16.567742 |
它还绘制了月度数据,清楚地显示了数据集的季节性。
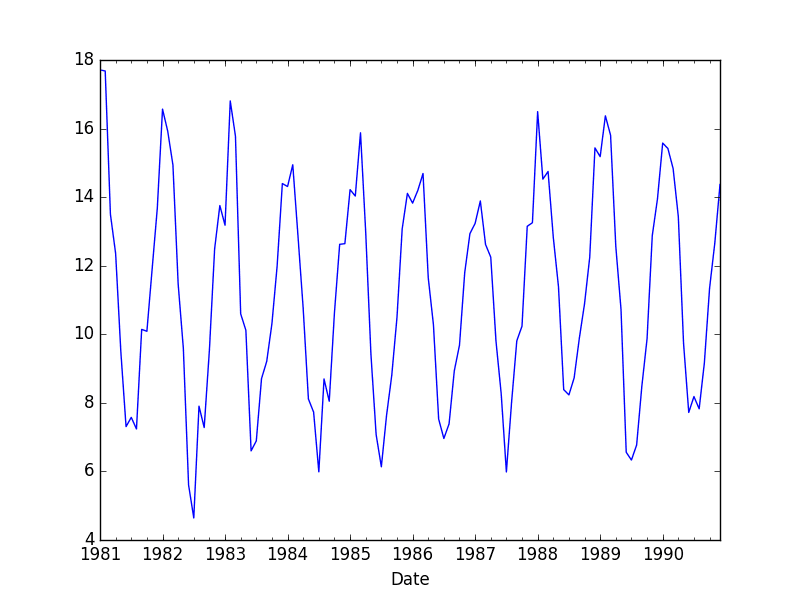
每月最低温度数据集
我们可以对月度数据测试相同的差分方法,并确认季节性调整后的数据集确实消除了年度周期。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0) resample = series.resample('M') monthly_mean = resample.mean() X = series.values diff = list() months_in_year = 12 for i in range(months_in_year, len(monthly_mean)): value = monthly_mean[i] - monthly_mean[i - months_in_year] diff.append(value) pyplot.plot(diff) pyplot.show() |
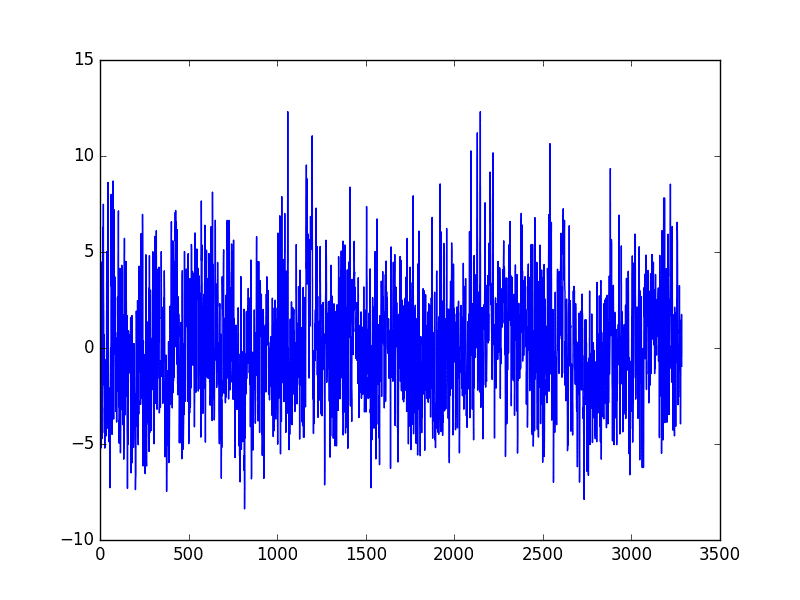
运行示例将创建一个新的季节性调整的月平均最低温度数据集,跳过第一年的数据以进行调整。然后绘制调整后的数据集。
季节性调整的每月最低温度数据集
接下来,我们可以使用去年同一月份的月平均最低温度来调整每日最低温度数据集。
同样,我们只跳过第一年的数据,但使用月度数据而不是每日数据进行校正可能是一种更稳定的方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0) X = series.values diff = list() days_in_year = 365 for i in range(days_in_year, len(X)): month_str = str(series.index[i].year-1)+'-'+str(series.index[i].month) month_mean_last_year = series[month_str].mean() value = X[i] - month_mean_last_year diff.append(value) pyplot.plot(diff) pyplot.show() |
再次运行示例将创建季节性调整后的数据集并绘制结果。
此示例对于上一年的每日波动和因闰年 2 月 29 日而产生的偏移错误是稳健的。
更稳定的季节性调整后的每月最低温度数据集
日历月份的边缘提供了一个硬边界,这对于温度数据可能没有意义。
更灵活的方法,例如采用去年同一日期前后一周的平均值,可能又是更好的方法。
此外,温度数据在多个尺度上很可能存在季节性,这些季节性可以通过直接或间接的方式进行校正,例如:
- 日级别。
- 多日级别,如一周或几周。
- 多周级别,如一个月。
- 多月级别,如一个季度或季节。
通过建模进行季节性调整
我们可以直接对季节性成分进行建模,然后将其从观测值中减去。
特定时间序列中的季节性成分很可能是一个具有固定周期和幅度的正弦波。这可以使用曲线拟合方法轻松近似。
可以构建一个数据集,将正弦波的时间索引作为输入(x 轴),并将观测值作为输出(y 轴)。
例如
|
1 2 3 4 5 6 |
时间索引,观测值 1,obs1 2,obs2 3,obs3 4,obs4 5,obs5 |
拟合完成后,模型就可以用来计算任何时间索引的季节性成分。
在温度数据的情况下,时间索引将是这一年的第几天。然后,我们可以估计任何历史观测值或未来任何新观测值的这一年第几天的季节性成分。
然后,该曲线可以作为新的输入用于使用监督学习算法进行建模,或者从观测值中减去以创建季节性调整后的序列。
让我们开始拟合每日最低温度数据集的曲线。NumPy 库提供了 polyfit() 函数,可用于将选定阶数的多项式拟合到数据集中。
首先,我们可以创建一个时间索引(在本例中为天)到观测值的数据集。我们可以采用一年的数据或所有年份的数据。理想情况下,我们会尝试这两种方法,看看哪种模型能获得更好的拟合。我们也可以使用以每个值为中心的移动平均来平滑观测值。这也可能导致模型获得更好的拟合。
准备好数据集后,我们可以通过调用 polyfit() 函数来创建拟合,将 x 轴值(整数年天数)、y 轴值(温度观测值)和多项式阶数传递进去。阶数控制项的数量,进而控制用于拟合数据的曲线的复杂性。
理想情况下,我们希望找到描述数据集季节性的最简单曲线。对于一致的正弦波状季节性,4 阶或 5 阶多项式就足够了。
在这种情况下,我通过反复试验选择了 4 阶。结果模型的形式为:
|
1 |
y = x^4*b1 + x^3*b2 + x^2*b3 + x^1*b4 + b5 |
其中 *y* 是拟合值,*x* 是时间索引(年第几天),*b1* 到 *b5* 是曲线拟合优化算法找到的系数。
拟合完成后,我们将有一组系数来表示我们的模型。然后,我们可以使用该模型来计算单个观测值、一年的观测值或整个数据集的曲线。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from pandas import read_csv from matplotlib import pyplot from numpy import polyfit series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0) # 拟合多项式:x^2*b1 + x*b2 + ... + bn X = [i%365 for i in range(0, len(series))] y = series.values degree = 4 coef = polyfit(X, y, degree) print('Coefficients: %s' % coef) # 创建曲线 curve = list() for i in range(len(X)): value = coef[-1] for d in range(degree): value += X[i]**(degree-d) * coef[d] curve.append(value) # 绘制原始数据上的曲线 pyplot.plot(series.values) pyplot.plot(curve, color='red', linewidth=3) pyplot.show() |
运行示例将创建数据集、拟合曲线、预测数据集中每一天的值,然后绘制结果季节性模型(红色)与原始数据集(蓝色)的对比图。
此模型的一个限制是它没有考虑闰日,这会产生小的偏移噪声,可以通过更新方法轻松纠正。
例如,在创建季节性模型时,我们可以直接从数据集中删除两个 2 月 29 日的观测值。
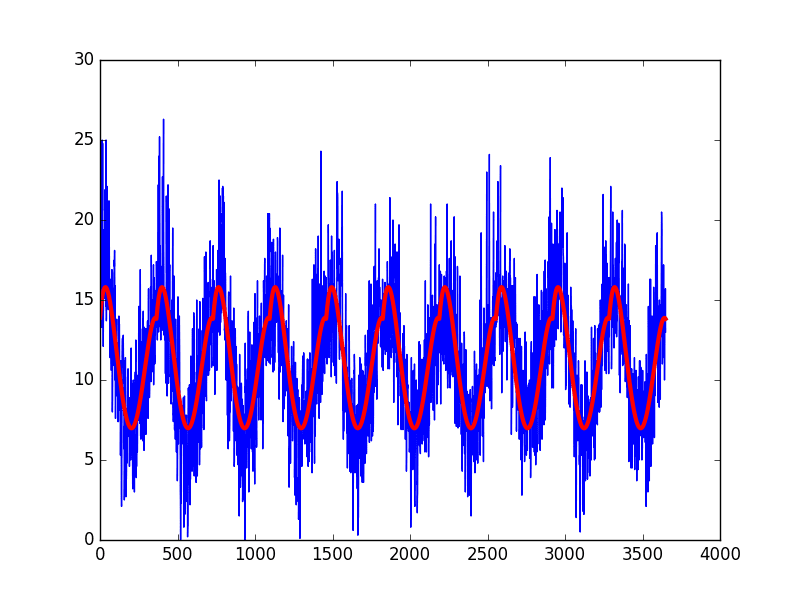
每日最低温度的曲线拟合季节性模型
该曲线似乎很好地拟合了数据集中季节性结构。
现在,我们可以使用此模型来创建该数据集的季节性调整版本。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from pandas import read_csv from matplotlib import pyplot from numpy import polyfit series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0) # 拟合多项式:x^2*b1 + x*b2 + ... + bn X = [i%365 for i in range(0, len(series))] y = series.values degree = 4 coef = polyfit(X, y, degree) print('Coefficients: %s' % coef) # 创建曲线 curve = list() for i in range(len(X)): value = coef[-1] for d in range(degree): value += X[i]**(degree-d) * coef[d] curve.append(value) # 创建季节性调整 values = series.values diff = list() for i in range(len(values)): value = values[i] - curve[i] diff.append(value) pyplot.plot(diff) pyplot.show() |
运行示例将季节性模型预测的值从原始观测值中减去。该
然后绘制季节性调整后的数据集。
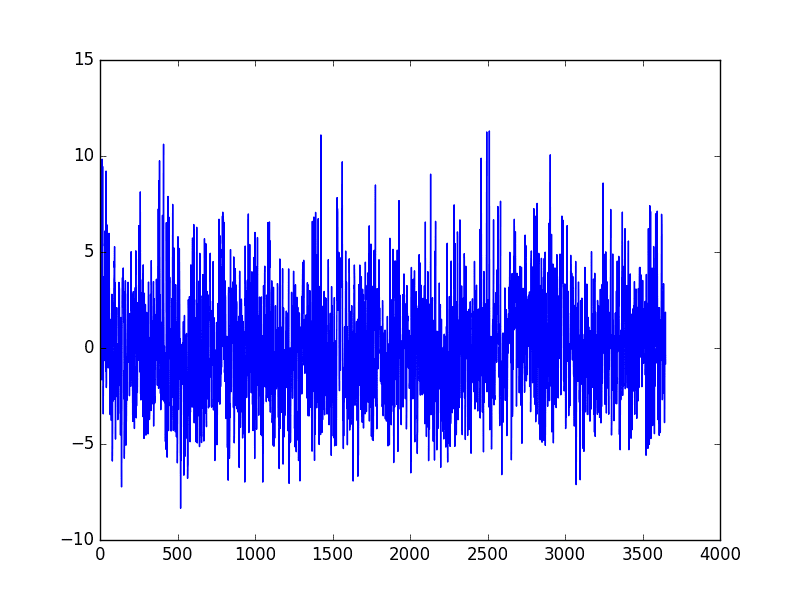
曲线拟合的每日最低温度季节性调整
总结
在本教程中,您学习了如何使用 Python 创建季节性调整的时间序列数据集。
具体来说,你学到了:
- 时间序列中季节性的重要性以及它提供的数据准备和特征工程机会。
- 如何使用差分法创建季节性调整的时间序列。
- 如何直接对季节性成分进行建模并将其从观测值中减去。
您对时间序列去季节化或本帖子有什么疑问吗?
在下面的评论中提出你的问题,我会尽力回答。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。






减去代表年度周期影响的正弦波后,我们得到每日温度与其平均值之间偏差的值,这是否正确?我只是想理解这个结果值意味着什么。喜欢您的帖子!
没错。
这些第一阶差分值可用于拟合模型。然后可以使用该模型进行预测,并将季节性成分加回到预测值中,以获得最终可用的值。
这有帮助吗?
当然!谢谢。我认为另一种可能的特征工程方法是使用经验模式分解算法来提取不同的信号成分以用于拟合模型,我会测试一下。
您能否更具体地说明如何将季节性成分加回去?我没看到如何在去季节化过程中保留这种季节性成分……或者我遗漏了什么……如果遗漏了,请指出在哪里。谢谢!
如果您通过减去一年前的数据来进行季节性调整,您可以通过再次添加减去的值来反转它。
顺便说一句,在 GitHub 上有一个有用的 EMD 库:https://github.com/jaidevd/pyhht
感谢您的链接,augmentale。
我见过人们使用分解并取误差/残差部分来去除趋势和季节性。如何选择使用哪种方法/技术来去除季节性/趋势?
你好 Amit,
分解对于时间序列分析很有用,但通常不能用于时间序列预测。至少据我所知。
我建议尝试一套方法,看看哪种效果最好——即产生预测最准确的模型。
如何对部分数据具有季节性效应,而部分数据没有季节性效应的时间序列进行去季节化?
单独准备每个序列。
嗨,Jason,
我需要预测每 12 小时的家庭电力需求,为期 3 天(6 个数据点)。我有大约 3 年的数据,间隔为 12 小时。表面上看,似乎可能存在多个季节性模式。如何识别复杂的季节性周期?在这种情况下哪种方法最好?
听起来很有趣。
试试拟合一些多项式?
你好,
我有一个具有多个季节性的数据。有没有办法识别所有季节性?我尝试了季节性分解,但我们需要为每月、每周或每年传递参数。我的情况是,我需要识别数据中出现的所有季节性。
提前感谢。
此致,
BMK
也许可以看一张图,然后使用季节性差分逐个去除。
嘿,你可以使用傅里叶变换来找到季节性频率。祝你好运!
好建议。
如果我想预测某个值,我看不出季节性调整的好处。我错过了这些信息。
季节性的模型很简单,所以我们对其进行建模并去除它。然后,我们想在其之上添加更多价值。
如果我有一个季节性时间序列及其一般趋势。它可以是 AR、MA、ARMA 或 ARIMA 吗?如果我能给您看数据,谢谢。
抱歉,我不明白你的问题。也许你可以重述一下?
如何检查数据中的半年季节性变化??
请简要说明。
谢谢
你具体指的是什么?
嗨 Jason。很棒的文章!非常容易跟上:)
我对 python 很陌生,所以请原谅我这个基本的问题。如何“保留”季节性调整后的值。例如写入 ascii 或其他技术,以便我可以在其他脚本中使用这些数据。非常感谢!
好问题,你可以将数据保存到 CSV 文件。
这篇文章提供了一些选项供你尝试
https://stackoverflow.com/questions/6081008/dump-a-numpy-array-into-a-csv-file
我们可以使用这种技术来比较不同长度的信号吗?例如,信号 A 记录 5 秒,信号 B 记录 1 分钟。如果我们想比较这两个信号,我可以使用你的想法来去除较长信号的季节性分量吗?
抱歉,我不确定我是否理解。也许你可以试试看。
很棒的文章。非常感谢 Jason。我也关注了你的 ARIMA 文章,并且想知道 ARIMA 是否可以处理所有问题(包括季节性),因此我们不必分离处理季节性并将 ARIMA 应用于季节性调整后的数据。因为从技术上讲,季节性是一种特殊的自相关形式,可以通过差分来处理。我这样想对吗?
移除趋势和季节性等系统性模式将提高模型的性能。
非常感谢 Jason 的这篇文章!我需要分析一个具有非常强的季节性的气候数据集中的极端值——这个方法是我完成这项任务所需要的!:)
像您这样花时间发布方法和示例的人,让我们这些需要使用我们不一定经过训练的技术从数据集中提取有价值信息的人的生活变得更加轻松(且不那么令人沮丧)!因此,您为我们创造了一个更美好的世界!
再次感谢
很高兴我能帮到 Ian!
我如何将其用于每周和每年的季节性?
您需要相应地修改它。
为什么周期通常在时间序列建模中被忽略?
季节性是一个周期,它不是被忽略的。我们可以去除它或使用 SARIMA 模型对其进行建模。
https://machinelearning.org.cn/how-to-grid-search-sarima-model-hyperparameters-for-time-series-forecasting-in-python/
同一数据序列中的多个季节性?
这是一个很棒的例子——非常感谢。
这些例子非常机械——因此适合广大受众。
只是想知道是否/为什么不考虑使用 pandas.groupby 和 .transform 方法?
谢谢 Edward。
你认为我应该如何在上述教程中使用这些方法?
你好 Jason,
这是一篇很棒的文章,谢谢。
我有一些疑问。
1) 在应用 SARIMAX(季节性 ARIMA)模型之前,是否已经有必要从时间序列数据中移除趋势和/或季节性?
2) 我如何统计上知道时间序列数据是否平稳?是使用 adf.test,如果 p 值 >0.05,我是否可以认为数据不平稳?
3) 最后一个问题;在使用 HoltsWinter 或指数平滑等其他模型时,是否有必要使数据平稳?
请指教。
移除趋势和季节性等结构会有帮助。问题会更简单,模型技能也会更高。但这不是必需的操作。
这篇文章包含有关测试平稳性的信息
https://machinelearning.org.cn/time-series-data-stationary-python/
同样,序列不一定必须平稳,但大多数方法都假设它,并且如果你满足假设,模型技能通常会更高。
你好,
在执行深度学习方法(如 MLP 或 LSTM)之前,我们需要去除季节性吗?
提前感谢。
任何能让模型更容易解决的问题都是个好主意。
你好,
我将第一个窗口中的代码直接复制到 Ubuntu 上运行的 Jupyter notebook 中,但遇到了 2 个错误。
1. 关于 from_csv 被弃用的使用。
2. 我还得到了一个索引错误。
—————————————————————————
IndexError Traceback (最近一次调用)
in ()
1 from pandas import Series
2 from matplotlib import pyplot
—-> 3 series = Series.from_csv(‘daily-minimum-temperatures.csv’, header=0)
4 series.plot()
5 pyplot.show()
~/anaconda3/lib/python3.6/site-packages/pandas/core/series.py in from_csv(cls, path, sep, parse_dates, header, index_col, encoding, infer_datetime_format)
2888 sep=sep, parse_dates=parse_dates,
2889 encoding=encoding,
-> 2890 infer_datetime_format=infer_datetime_format)
2891 result = df.iloc[:, 0]
2892 if header is None
.
.
.
.
IndexError: 列表索引超出范围
我很遗憾听到这个消息,请尝试以下步骤。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,我想知道你是否可以建议任何方法来预测季节性的开始日期。例如,夏季或冬季的开始日期。
谢谢你
这真的取决于“开始”对你的问题意味着什么。你必须定义开始,然后你就可以预测它。
你好,
如何使用 Minitab 在我的模型中定义每周季节性?它是定义为 S=4 吗?
提前感谢。
什么是“Minitab”?
嗨,Jason,
非常感谢这篇文章!
“对于具有季节性成分的时间序列,滞后可能期望是季节性的周期(宽度)。”
我的季节性是每年八月到二月。例如。
2016-08 12.84M
2016-09 21.43M
2016-10 24.74M
2016-11 21.46M
2016-12 20.21M
2017-01 16.75M
2017-02 13.46M
M = 百万
我应该考虑滞后 6 还是 7 吗?请建议。
此外,在差分数据集之上,我们需要进行趋势去除,然后将其输入 ARIMA 模型吗?
请确认。非常感谢。:)
抱歉,我无法为您分析数据的季节性。
嗨,Jason,
如果“季节性”成分不是固定的,即每个周期的长度都会改变,那该怎么办?例如太阳黑子数量,它不是正好 11 年,而是从一个周期到另一个周期会变化。如何去除周期性成分?
好问题,时间序列会变得复杂。
我相信季节性成分可以通过预期变化进行建模,也许可以查看指数平滑。
https://machinelearning.org.cn/how-to-grid-search-triple-exponential-smoothing-for-time-series-forecasting-in-python/
你好,
有什么方法可以对磁盘可用空间、CPU 使用率、网络和基础设施监控进行建模吗?请告知我资源。
当然,也许可以从这里开始。
https://machinelearning.org.cn/start-here/#process
感谢你的文章!
这是我见过的很棒的文章:)
我可以问你一个快速问题吗?
我对于确定性趋势/季节性和随机性趋势/季节性感到困惑。
我的问题是
先去除确定性趋势/季节性,然后进行乘法 SARIMAX 建模过程,这样可以吗?
我不确定数据是否同时具有确定性和随机性趋势/季节性。
谢谢。
谢谢。
你的方法听起来很合理。
你好 Jason,非常感谢你的文章。
我正在尝试将你的方法应用于另一种类型的问题,但我有一些我无法解决的疑问。
这种方法是否适用于“消费者消费”的季节性分析?也就是说,了解消费者一年的行为(按月)。如果适用,模型如何处理年度变化?例如,新店在分析年份开业(导致分析数据中的销售额激增)。是否更方便剔除这些新开店的影响?
提前感谢!
也许可以尝试一下,看看是否合适。
使用能更好地捕捉季节性的模型可能会更容易,例如 SARIMA 或 ETS。
好文!
两个问题——
为什么在应用 ARIMA 之前需要去除季节性,如果我们无论如何都要在 ARIMA 中提供“d”的值(p,d,q)?
为什么我们需要 SARIMA,如果我们已经有了 ARIMA,我们可以给“d”一个值来处理季节性?
谢谢。
好问题。
差分会使其平稳,显式去除季节性也会使其平稳。这是一个选择,可能更喜欢更多的控制。
对季节性进行建模可以提高模型性能。
感谢您的回复,Jason。
我偶然发现 OTexts 第 12.8 章中的一个例子。(希望你了解 otexts)
陈述如下:
cafe<-Arima(training, order=c(2,1,1), seasonal=c(0,1,2), lambda=0)
现在,这让我感到非常困惑。这里提供了 d =1 的值,这意味着季节性已被去除,序列现在是平稳的,但随后又提供了 D = 1 的季节性分量。
您能向我解释一下这里发生了什么吗?
我有一个工作面试,在这个问题上卡住了,这个问题与 ARIMA 中的季节性有关。
再次感谢您的时间。
这里的第一个 d 去除了趋势(趋势调整),第二个 D 去除了季节性(季节性调整)。
这有帮助吗?
是的,它确实可以。非常感谢,Jason。
嗨,Jason,
我需要对 LSTMs 进行季节性调整吗?似乎文学界对此没有共识。
这可能非常有帮助!例如,它使问题更容易建模。
代码中有一个错误,你基于月平均值分解了时间序列。“x = series.values”应该是“monthly_mean = monthly_mean.values”。如果我错了,请纠正我。
我认为不行。
看看第四个代码片段。代码行:X = series.values 的目的是什么?你在代码中没有使用 X。此外,当 monthly_mean = resample.mean() 时,无法通过 monthly_mean[i] 访问 monthly_mean;
from pandas import read_csv
from matplotlib import pyplot
series = read_csv(‘daily-minimum-temperatures.csv’, header=0, index_col=0)
resample = series.resample(‘M’)
monthly_mean = resample.mean()
X = series.values
diff = list()
months_in_year = 12
for i in range(months_in_year, len(monthly_mean))
value = monthly_mean[i] – monthly_mean[i – months_in_year]
diff.append(value)
pyplot.plot(diff)
pyplot.show()
是的,你可以忽略它。
你可以这样访问 monthly_mean
value = monthly_mean.iloc[i][‘Temp’] – monthly_mean.iloc[i – months_in_year][‘Temp’]
我需要从给定的时间序列中推断季节性。我的目的是找出给定的序列在哪个时间范围内达到了给定的阈值。
例如,给定一个月的 CPU 百分比系列,粒度为 1 小时。我需要得到这样的陈述:
每天的第 3 小时和第 7 小时达到阈值。
每周日,第 5 小时和第 8 小时达到阈值。
隔天,第 16 小时达到阈值。
或许可以试试看?
我正在使用 R 软件中的 Kendall 包进行每日和每月降雨数据的趋势分析。但是,每次尝试进行 MannKendall 分析时,我都会收到此错误。
> MannKendall(data)
错误在 Kendall(1:length(x), x) : length(x)<3
如果您可以,请帮助我解决此错误?
抱歉,我对该软件包不熟悉,也许可以发布到 Cross Validated?
你好,
我正在处理过去 30 年的甲烷排放数据。我想知道气候变化是否对我的甲烷数据中的季节性方差/宽度/幅度产生了影响。我该如何量化这一点?
也许可以研究因果模型?
也许可以研究时间序列数据的统计相关性?
我很确定在“每日最低温度曲线拟合季节性模型”的循环中存在一个错误。
我的绘图结果全错了。
将循环替换为 polyval(coef, X) 可以解决问题(注意 polyval 需要从 numpy 导入)。
你确定吗?你是否按原样复制了所有代码?从命令行运行?
更多信息在这里
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我花了一整天时间处理大量的 numpy 和奇怪的数组/列表转换,才找到这个解决方案!Jason,Brett 的解决方案让我今天的生活变得轻松!
本教程非常有帮助!
您能否指导我,季节性调整/去季节化时间序列数据有什么好处?
它移除了一个简单的结构,以便模型可以专注于学习更复杂的结构。
有没有办法在不绘制图表的情况下检测数据中的平稳性、季节性和噪声?请告知。
可能,我还没见过可靠的方法。
Jason,我正在尝试使用四年的每日数据进行预测,这些数据是关于杂货销售的。当我查看分解图时,我观察到趋势可以忽略不计,为了寻找季节性,我将数据转换为每周数据,并观察到了季节性模式。
1)我使用了每日数据进行预测,首先我检查了adf检验,结果看起来还可以,所以为了捕捉季节性,我使用了SARIMA模型进行预测,这是一种可以接受的方法吗?
2)我将使用随机森林和其他树模型以及LSTM进行预测,我应该在拟合模型之前去除季节性,然后将其恢复到我的预测中吗?或者简单地添加另一个特征,即窗口为7天的滚动平均值?
3)最后,在进行任何差分/去季节化之前,我应该将样本分成训练集和测试集,对吗?我可以对整个样本执行此类操作吗?
干得不错。
是的,SARIMA 是一个不错的开始。也可以尝试 ETS。
是的,尝试在原始数据上使用机器学习模型,然后尝试去除季节性并比较结果。
差分后可以分成训练/测试集,这很少会导致数据泄露。
嗨,Jason,
非常棒的演示,尤其是建模方法。
您是否尝试过使用 FFT 方法去除季节性?如果尝试过,请提供链接。
网上的例子不如您的作品清晰有力!
目前我还没有这方面的教程。
你好,Jason!
我只是复制了“建模”章节的代码,结果与文章中的结果完全不同。是什么原因造成的?
这本书可能比博客更新。
另外,请看这个:
https://machinelearning.org.cn/ufaqs/why-do-i-get-different-results-each-time-i-run-the-code/
我从这篇帖子中学到了很多,谢谢 Jason。
但是我有一个问题:如果我们的季节性数据通过差分进行了调整,我们只需要将减去的值加回去即可获得原始值。
如果我们用建模调整了季节性数据,我们该怎么做才能再次获得原始预测值?因为我们没有 t+1 的曲线值,只有预测值(yhat)。
您将从一个周期前的值添加到输入数据或训练数据中。
嗨,Jason,
感谢您的帖子。
我阅读了这篇文章,也阅读了题为(如何使用 Python 检查时间序列数据是否平稳)的文章。然后我应用了相同的数据集来使用“增强迪基-富勒检验”来检查平稳性。结果表明时间序列是平稳的。为什么会这样?因为我有一个类似的数据集,我的结果也表明时间序列是平稳的,但我知道从折线图上看它是具有季节性的。
谢谢你。
平稳的时间序列也可以是季节性的。例如,正弦波就是平稳的。
帖子写得很好,非常棒。我正在应用季节性差分,之前进行了一个简单的差分,您知道如何恢复它吗?我的数据是月度数据。非常感谢。
您是指如何反转差分?该操作称为累积和(cumsum() 函数)。
我可以用 cumsum() 来反转季节性差分吗?
cumsum() 是将序列中的相邻数字相加。如果您能以某种方式将季节性数据表示为一个序列(例如,对数据进行重采样),那么它应该可以工作。
你好 Adrian Tam
我有一个两年的天气时间序列数据集,我想使用相同的方法来去除季节性,但是第一年将被赋值为 Null 值,而我需要这些值,因为一年的数据不足以让我的模型进行预测,所以是否有其他方法可以保留第一年的值?
看看这个是否有帮助:https://machinelearning.org.cn/sarima-for-time-series-forecasting-in-python/
如何对新的测试数据点进行去季节化?例如,我有一个在去季节化数据上训练的时间序列模型,我如何使用它来预测新的未来测试数据点?
Hi Soumitra…对于时间序列预测应用,您将始终拥有数据直到您开始进行预测的点。因此,您将能够按照教程中的讨论去除季节性。
你好,Jason
我正在使用 LSTM 模型进行序列预测。我的一些输入序列同时具有线性趋势和季节性。
我想先去除线性趋势,然后去除季节性。
我的问题如下:应该在将数据集拆分为训练集和测试集之前这样做吗?如果答案是肯定的,我应该如何处理我想要进行预测的新数据?我的意思是,我应该从这些新数据中去除什么趋势和季节性?
提前非常感谢!
你好 Jason,
我是一名天文学家,我正在做一个项目。在该项目中,我有一些时间序列数据。为了检查时间序列的平稳性,我做了一些测试,如“增强迪基-富勒”和“KPSS”测试,发现我的时间序列是平稳的。现在我想检查时间序列中的季节性成分,这我无法通过目视检查来完成。为此,我需要依赖其他方法。为此,我生成了模型的各种可能的阶数组合(p,d,q)*(P,D,Q,S),其中(p,q,d 分别代表非季节性 AR、MA 模型和非季节性差分的阶数参数,P、Q、D、S 分别代表季节性 AR、MA 模型、季节性差分和季节性成分),并使用“SARIMAX”模型进行拟合,尝试确定最低的 AIC 值。正如我们所知,最低的 AIC 值代表了我们时间序列的最佳最优模型。当我这样做时,我发现最低 AIC 值对应的阶数参数例如是 (1,1,1)*(2,0,0,58)。非季节性成分中不应该有差分参数=1。为什么我会得到这样的结果?你能解释一下吗?
Hi Ajay…您可能希望研究适用于您应用的 LSTM 模型。
https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/