集成学习是一种通用的机器学习元方法,旨在通过结合多个模型的预测来获得更好的预测性能。
尽管您可以为预测建模问题开发数量看似无限的集成模型,但有三种方法在集成学习领域占据主导地位。它们的重要性如此之高,以至于与其说是算法本身,不如说它们各自都是一个研究领域,并衍生出许多更专业的T方法。
集成学习方法的三种主要类别是Bagging、Stacking和Boosting,详细了解每种方法并在您的预测建模项目中考虑它们都非常重要。
但在此之前,您需要先对这些方法及其背后的关键思想有一个温和的介绍,然后再深入到数学和代码层面。
在本教程中,您将了解机器学习的三种标准集成学习技术。
完成本教程后,您将了解:
- Bagging涉及对同一数据集的不同样本拟合许多决策树,并对预测结果取平均值。
- Stacking涉及对相同数据拟合许多不同类型的模型,并使用另一个模型来学习如何最佳地组合预测结果。
- Boosting涉及按顺序添加集成成员,这些成员纠正了先前模型所做的预测,并输出预测结果的加权平均值。
通过我的新书《使用 Python 的集成学习算法》启动您的项目,其中包括分步教程和所有示例的Python 源代码文件。
让我们开始吧。

集成学习算法简明介绍
图片来源:Rajiv Bhuttan,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 标准集成学习策略
- Bagging 集成学习
- Stacking 集成学习
- Boosting 集成学习
标准集成学习策略
集成学习指的是结合两个或更多模型预测的算法。
尽管实现这一目标的方式几乎是无限的,但在实践中最常讨论和使用的集成学习技术大概有三类。它们的流行很大程度上归因于它们易于实现以及在各种预测建模问题上的成功。
在过去几年中,开发了大量基于集成的分类器。然而,其中许多都是少数几个经过广泛测试和广泛报道其能力的成熟算法的变体。
— 第 11 页,《集成机器学习》,2012 年。
鉴于它们的广泛使用,我们可以将它们称为“标准”集成学习策略;它们是:
- Bagging。
- Stacking。
- Boosting。
尽管每个方法都有一个算法描述,但更重要的是,每种方法的成功都催生了无数的扩展和相关技术。因此,将每种方法描述为一类技术或集成学习的标准方法更为有用。
与其深入探讨每种方法的具体细节,不如一步步地总结和对比每种方法。同样重要的是要记住,尽管对这些方法的讨论和使用普遍存在,但这三种方法本身并不能定义集成学习的全部范围。
接下来,我们来仔细看看 Bagging。
Bagging 集成学习
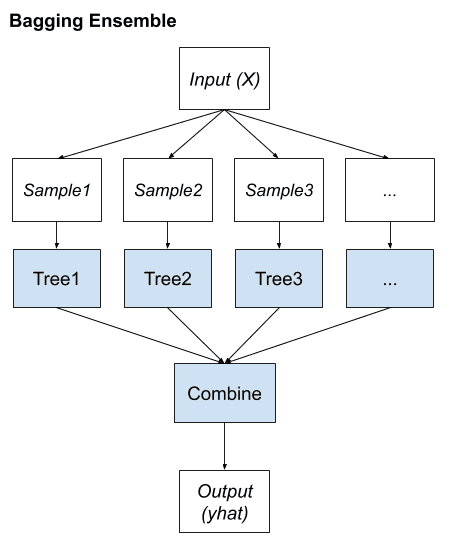
自助聚合,简称 Bagging,是一种集成学习方法,旨在通过改变训练数据来获得多样化的集成成员。
Bagging 的名称来源于 Bootstrap AGGregatING 的缩写。顾名思义,Bagging 的两个关键组成部分是自助法(bootstrap)和聚合(aggregation)。
— 第 48 页,《集成方法》,2012 年。
这通常涉及使用单个机器学习算法(几乎总是未剪枝的决策树),并在同一训练数据集的不同样本上训练每个模型。然后,通过简单的统计方法(如投票或平均)组合集成成员做出的预测。
集成模型的多样性由每个分类器训练所基于的自助复制品中的变化以及使用相对较弱的分类器来确保,该分类器的决策边界会随着训练数据中相对较小的扰动而显着变化。
— 第 11 页,《集成机器学习》,2012 年。
该方法的关键在于为训练集成成员准备数据集每个样本的方式。每个模型都获得其自己的独特数据集样本。
示例(行)是从数据集中随机抽取的,但会进行有放回抽样。
Bagging 采用自助分布来生成不同的基础学习器。换句话说,它应用自助采样来获取用于训练基础学习器的数据子集。
— 第 48 页,《集成方法》,2012 年。
“有放回”意味着如果一行数据被选中,它会被放回训练数据集,以便在同一个训练数据集中有再次被选中的可能性。这意味着一行数据在给定的训练数据集中可能被选中零次、一次或多次。
这被称为自助样本。这是一种在统计学中常用的小数据集技术,用于估计数据样本的统计值。通过准备多个不同的自助样本并估计统计量并计算估计值的平均值,可以获得比直接从数据集估计更好的所需量的总体估计值。
以同样的方式,可以准备多个不同的训练数据集,用于估计预测模型并进行预测。对模型预测求平均值通常会比直接在训练数据集上拟合的单一模型产生更好的预测。
我们可以将 Bagging 的关键要素总结如下:
- 训练数据集的自助样本。
- 对每个样本拟合未剪枝的决策树。
- 对预测结果进行简单投票或平均。
总之,Bagging 的贡献在于它改变了用于拟合每个集成成员的训练数据,这反过来又产生了熟练但不同的模型。
Bagging 集成
它是一种通用的方法,易于扩展。例如,可以引入更多对训练数据集的更改,可以替换在训练数据上拟合的算法,并且可以修改用于组合预测的机制。
许多流行的集成算法都基于这种方法,包括:
- Bagged 决策树(经典 Bagging)
- 随机森林
- 额外树
接下来,我们来仔细看看 Stackin。
想开始学习集成学习吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Stacking 集成学习
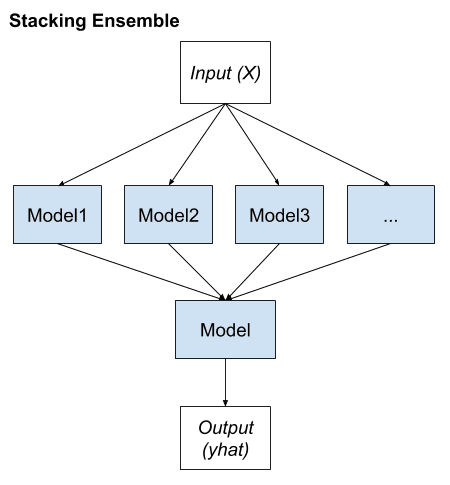
堆叠泛化,简称 Stacking,是一种集成方法,旨在通过改变拟合训练数据的模型类型并使用一个模型来组合预测,从而获得多样化的成员组。
堆叠是一种通用过程,其中训练一个学习器来组合各个学习器。在这里,各个学习器被称为第一级学习器,而组合器被称为第二级学习器,或元学习器。
— 第 83 页,《集成方法》,2012 年。
堆叠有其自身的术语,其中集成成员被称为0级模型,而用于组合预测的模型被称为1级模型。
两级模型层次结构是最常见的方法,尽管可以使用更多层模型。例如,我们可能不是只有一个1级模型,而是有3个或5个1级模型和一个2级模型,它组合1级模型的预测以进行预测。
堆叠可能是最流行的元学习技术。通过使用元学习器,该方法试图推断哪些分类器是可靠的,哪些不是。
— 第 82 页,《使用集成方法进行模式分类》,2010 年。
任何机器学习模型都可以用于聚合预测,尽管通常使用线性模型,例如用于回归的线性回归和用于二元分类的逻辑回归。这鼓励了模型的复杂性驻留在较低级别的集成成员模型中,而简单模型则学习如何利用各种预测。
通过使用可训练的组合器,可以确定哪些分类器可能在特征空间的哪些部分成功,并相应地组合它们。
— 第 15 页,《集成机器学习》,2012 年。
我们可以将 Stacking 的关键要素总结如下:
- 未更改的训练数据集。
- 每个集成成员使用不同的机器学习算法。
- 机器学习模型学习如何最佳地组合预测。
多样性来源于用作集成成员的不同机器学习模型。
因此,最好使用一组以非常不同方式学习或构建的模型,以确保它们做出不同的假设,从而具有较低相关性的预测误差。
堆叠集成
许多流行的集成算法都基于这种方法,包括:
- 堆叠模型(经典堆叠)
- 混合
- 超级集成
接下来,我们来仔细看看 Boosting。
Boosting 集成学习
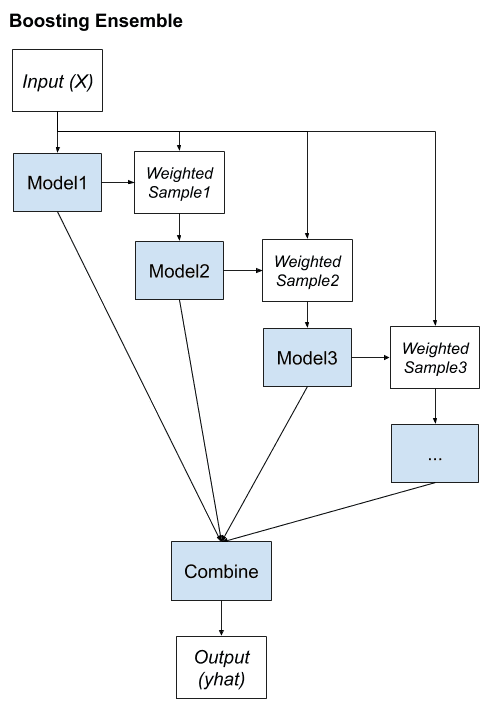
提升(Boosting)是一种集成方法,旨在通过改变训练数据来关注那些先前拟合模型在训练数据集上预测错误的示例。
在提升中,[...] 后续每个分类器的训练数据集越来越侧重于被先前生成的分类器错误分类的实例。
— 第 13 页,《集成机器学习》,2012 年。
提升集成的关键特性是纠正预测错误的想法。模型被顺序拟合并添加到集成中,以便第二个模型尝试纠正第一个模型的预测,第三个模型纠正第二个模型的预测,依此类推。
这通常涉及使用非常简单的决策树,它们只做出一个或几个决策,在 Boosting 中被称为弱学习器。弱学习器的预测通过简单的投票或平均进行组合,尽管它们的贡献权重与它们的性能或能力成比例。目标是从许多专门构建的“弱学习器”中开发一个所谓的“强学习器”。
……一种迭代方法,用于从弱分类器集合中生成一个强分类器,其中每个弱分类器都只能勉强优于随机猜测,但这个强分类器能够实现任意低的训练误差。
— 第 13 页,《集成机器学习》,2012 年。
通常,训练数据集保持不变,而是修改学习算法,根据先前添加的集成成员是否正确或错误地预测了特定示例(数据行),来更多或更少地关注这些示例。例如,可以对数据行进行加权,以指示学习算法在学习模型时必须给予的关注程度。
我们可以将 Boosting 的关键要素总结如下:
- 偏向于那些难以预测的训练数据示例。
- 迭代地添加集成成员以纠正先前模型的预测。
- 使用模型的加权平均值组合预测。
将许多弱学习器组合成强学习器的想法最初是理论上提出的,并且许多算法被提出但收效甚微。直到自适应提升(AdaBoost)算法的开发,提升才被证明是一种有效的集成方法。
术语“Boosting”指的是一系列能够将弱学习器转化为强学习器的算法。
— 第 23 页,《集成方法》,2012 年。
自 AdaBoost 以来,已经开发了许多提升方法,其中一些,如随机梯度提升,可能是对表格(结构化)数据进行分类和回归最有效的方法之一。
Boosting 集成
总结一下,许多流行的集成算法都基于这种方法,包括:
- AdaBoost(经典 Boosting)
- 梯度提升机
- 随机梯度提升(XGBoost 及类似算法)
至此,我们对标准集成学习技术的介绍就结束了。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用集成方法进行模式分类, 2010.
- 集成方法, 2012.
- 集成机器学习, 2012.
- 数据挖掘中的集成方法, 2010.
文章
总结
在本教程中,您学习了机器学习的三种标准集成学习技术。
具体来说,你学到了:
- Bagging涉及对同一数据集的不同样本拟合许多决策树,并对预测结果取平均值。
- Stacking涉及对相同数据拟合许多不同类型的模型,并使用另一个模型来学习如何最佳地组合预测结果。
- Boosting涉及按顺序添加集成成员,这些成员纠正了先前模型所做的预测,并输出预测结果的加权平均值。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌握现代集成学习!

在几分钟内改进您的预测
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 实现集成学习算法
它提供**自学教程**,并附有关于以下内容的**完整工作代码**:
堆叠、投票、提升、装袋、混合、超级学习器等等……






先生,您能用 R 语言展示相同的代码吗?
也许这会有帮助。
https://machinelearning.org.cn/machine-learning-ensembles-with-r/
您好,感谢您对每种方法的解释。这非常有帮助。我对Boosting集成学习中的加权样本有点困惑。根据特征的重要性赋予权重会不会给系统引入噪声?这就像改变训练数据。
谢谢。
是的,但我们更关心的是当样本不平衡时,稀有情况下的准确性,而不是噪声。
一如既往的精彩解释……所有方法都谈到了弱集成成员。那么,弱算法和强算法的集成学习如何呢?例如,对于图像分类问题,一个决策树(弱)模型从图像的元数据中学习,一个CNN(强)模型从图像数据集本身中学习。你认为这两者可以协同工作以获得更好的结果吗?你认为这应该如何实现?
谢谢
我想你可以试试。至于实现,我相信可以使用现有的集成库,或者你可以自己编写集成函数。
bagging 和 boosting 中哪种方法最好?
Bagging 更好还是 Boosting 更好,请从考试角度告诉我?哪种技术更好?
您好 Najum-ul-Saher……感谢您提出问题!虽然我无法回答您的考试问题,但我最能帮助您解决有关我们材料和代码列表的具体问题。
非常感谢这篇教程。
所有内容对我都有帮助。
再次感谢。
非常欢迎您 Julius!我们感谢您的支持和反馈!
你好,
这些集成方法中哪一个采用多数投票?
您好 gndkup……您可能会对以下内容感兴趣
https://machinelearning.org.cn/voting-ensembles-with-python/#:~:text=A%20voting%20ensemble%20(or%20a,model%20used%20in%20the%20ensemble.
请问如何在 R 中使用集成学习。需要代码,谢谢。
您好 Arowona……我们的内容主要专注于 Python。但是,以下资源可用于 R:
https://machinelearning.org.cn/machine-learning-with-r/
您好,感谢您的解释。
模型平均和分类器投票属于哪一类?
我有点困惑,因为它们在其他网站上被提及为集成策略/方法,但总是超出您解释的三类。
谢谢
您好 Noor……非常欢迎您!我们认为它们是集成学习算法。
以下是关于这个主题的一个很好的起点
https://machinelearning.org.cn/voting-ensembles-with-python/
加权集成和加权平均集成不是一回事对吗?我有点困惑。我做了一个集成模型,结合了3个不同的CNN模型,每个模型都乘以我通过网格搜索权重优化的权重。然后我把整个东西加起来(模型1*w1+模型2*w2…),做成了最终的集成模型,没有做任何平均,这是个愚蠢的主意吗?哈哈,我希望一些模型对其他模型的贡献不同。