在OpenCV中使用Haar级联分类器很简单。您只需提供XML文件中的训练模型即可创建分类器。然而,从头开始训练一个分类器并非那么简单。在本教程中,您将看到训练过程应该是什么样的。特别是,您将学习:
- 在OpenCV中训练Haar级联的工具是什么
- 如何准备训练数据
- 如何运行训练
通过我的书《OpenCV 机器学习》启动您的项目。它提供了带有可用代码的自学教程。
让我们开始吧。

在 OpenCV 中训练 Haar 级联目标检测器
图片由 Adrià Crehuet Cano 拍摄。保留部分权利。
概述
本文分为五个部分,它们是:
- OpenCV中训练级联分类器的问题
- 环境设置
- 级联分类器训练概述
- 准备训练数据
- 训练Haar级联分类器
OpenCV中训练级联分类器的问题
OpenCV已经存在多年,并且有许多版本。在撰写本文时,OpenCV 5正在开发中,推荐版本是OpenCV 4,准确地说是版本4.8.0。
OpenCV 3和OpenCV 4之间进行了大量的清理工作。最值得注意的是,大量代码被重写。这种变化是巨大的,许多函数都发生了变化。这包括训练Haar级联分类器的工具。
级联分类器不是像SVM那样可以轻松训练的简单模型。它是一个使用AdaBoost的集成模型。因此,训练涉及多个步骤。OpenCV 3有一个命令行工具来帮助进行此类训练,但该工具在OpenCV 4中已损坏。修复程序尚未提供。
因此,只能使用OpenCV 3训练Haar级联分类器。幸运的是,在训练完成后,您可以将其丢弃,并在将模型保存到XML文件后恢复到OpenCV 4。这正是您将在本文中完成的操作。
OpenCV 3和OpenCV 4不能在Python中同时存在。因此,建议为训练创建一个单独的环境。在Python中,您可以使用`venv`模块创建一个虚拟环境,它只是创建一组单独的已安装模块。替代方案是使用Anaconda或Pyenv,它们是相同理念下的不同架构。在上述所有选项中,您应该认为Anaconda环境最容易完成此任务。
想开始学习 OpenCV 机器学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
环境设置
如果您使用Anaconda,会更容易一些,您可以使用以下命令创建并使用一个名为“cvtrain”的新环境:
|
1 2 |
conda create -n cvtrain python 'opencv>=3,<4' conda activate cvtrain |
如果您发现 `opencv_traincascade` 命令可用,则说明您已准备就绪。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
$ opencv_traincascade 用法: opencv_traincascade -data <级联_目录名> -vec <向量_文件名> -bg <背景_文件名> [-numPos <正样本数量 = 2000>] [-numNeg <负样本数量 = 1000>] [-numStages <阶段数量 = 20>] [-precalcValBufSize <预计算值缓冲区大小_MB = 1024>] [-precalcIdxBufSize <预计算索引缓冲区大小_MB = 1024>] [-baseFormatSave] [-numThreads <最大线程数 = 16>] [-acceptanceRatioBreakValue <值> = -1>] --级联参数-- [-stageType <BOOST(默认)>] [-featureType <{HAAR(默认), LBP, HOG}>] [-w <样本宽度 = 24>] [-h <样本高度 = 24>] --boost参数-- [-bt <{DAB, RAB, LB, GAB(默认)}>] [-minHitRate <最小命中率> = 0.995>] [-maxFalseAlarmRate <最大误报率 = 0.5>] [-weightTrimRate <权重修剪率 = 0.95>] [-maxDepth <弱树最大深度 = 1>] [-maxWeakCount <弱树最大数量 = 100>] --haar特征参数-- [-mode <BASIC(默认) | CORE | ALL --lbp特征参数-- --HOG特征参数-- |
如果您使用的是`pyenv`或`venv`,则需要更多步骤。首先,创建环境并安装OpenCV(您应该注意到与Anaconda生态系统不同的包名)
|
1 2 3 4 |
# 创建环境并安装opencv 3 pyenv virtualenv 3.11 cvtrain pyenv activate cvtrain pip install 'opencv-python>=3,<4' |
这允许您使用OpenCV运行Python程序,但您没有用于训练的命令行工具。要获取这些工具,您需要按照以下步骤从源代码编译它们:
- 下载OpenCV源代码并切换到3.4分支
12345# 下载OpenCV源代码并切换到3.4分支git clone https://github.com/opencv/opencvcd opencvgit checkout 3.4cd ..
- 创建与存储库目录分离的构建目录
12mkdir buildcd build - 使用 `cmake` 工具准备构建目录,并指向 OpenCV 存储库
1cmake ../opencv
- 运行 `make` 进行编译(您可能需要先在系统中安装开发人员库)
12makels bin
- 您需要的工具将在 `bin/` 目录中,如上述最后一个命令所示
所需的命令行工具是`opencv_traincascade`和`opencv_createsamples`。本文的其余部分假设您已具备这些工具。
级联分类器训练概述
您将使用OpenCV工具训练一个**级联分类器**。该分类器是一个使用AdaBoost的集成模型。简单来说,会创建多个较小的模型,每个模型在分类方面都很弱。结合起来,它就成为一个具有良好精确度和召回率的强大分类器。
每个**弱分类器**都是一个二元分类器。为了训练它们,您需要一些正样本和负样本。负样本很容易:您向OpenCV提供一些随机图片,并让OpenCV选择一个矩形区域(如果这些图片中没有目标对象,则更好)。然而,正样本是以图像和对象完美地位于其中的边界框的形式提供的。
一旦提供了这些数据集,OpenCV将从中提取Haar特征,并使用它们来训练许多分类器。Haar特征是通过将正样本或负样本划分为矩形区域而获得的。划分方式涉及一些随机性。因此,OpenCV需要时间来找到最佳方法来为这项分类任务推导Haar特征。
在OpenCV中,您只需以OpenCV可读取的图像文件格式(例如JPEG或PNG)提供训练数据。对于负样本,只需一个包含文件名的纯文本文件。对于正样本,需要一个“信息文件”,这是一个纯文本文件,其中包含文件名、图片中对象的数量以及相应的边界框的详细信息。
用于训练的正样本数据应采用二进制格式。OpenCV提供了一个工具`opencv_createsamples`,用于从“信息文件”生成二进制格式。然后,这些正样本与负样本一起提供给另一个工具`opencv_traincascade`,以运行训练并以XML文件格式生成模型输出。这就是您可以加载到OpenCV Haar级联分类器中的XML文件。
准备训练数据
让我们考虑创建一个**猫脸**检测器。为了训练这样的检测器,您首先需要数据集。一种可能性是Oxford-IIIT宠物数据集,位于此位置:
这是一个800MB的数据集,按照计算机视觉数据集的标准来说是一个小型数据集。图像以Pascal VOC格式进行标注。简而言之,每张图像都有一个相应的XML文件,如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
<?xml version="1.0"?> <annotation> <folder>OXIIIT</folder> <filename>Abyssinian_100.jpg</filename> <source> <database>OXFORD-IIIT Pet Dataset</database> <annotation>OXIIIT</annotation> <image>flickr</image> </source> <size> <width>394</width> <height>500</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>cat</name> <pose>Frontal</pose> <truncated>0</truncated> <occluded>0</occluded> <bndbox> <xmin>151</xmin> <ymin>71</ymin> <xmax>335</xmax> <ymax>267</ymax> </bndbox> <difficult>0</difficult> </object> </annotation> |
XML文件告诉您它引用的是哪个图像文件(上面示例中的`Abyssinian_100.jpg`),以及它包含什么对象,边界框位于`<bndbox></bndbox>`标签之间。
要从XML文件提取边界框,您可以使用以下函数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import xml.etree.ElementTree as ET def read_voc_xml(xmlfile: str) -> dict: root = ET.parse(xmlfile).getroot() boxes = {"filename": root.find("filename").text, "objects": []} for box in root.iter('object'): bb = box.find('bndbox') obj = { "name": box.find('name').text, "xmin": int(bb.find("xmin").text), "ymin": int(bb.find("ymin").text), "xmax": int(bb.find("xmax").text), "ymax": int(bb.find("ymax").text), } boxes["objects"].append(obj) return boxes |
上述函数返回的字典示例如下:
|
1 2 |
{'filename': 'yorkshire_terrier_160.jpg', 'objects': [{'name': 'dog', 'xmax': 290, 'xmin': 97, 'ymax': 245, 'ymin': 18}]} |
有了这些,就可以轻松创建用于训练的数据集:在Oxford-IIT宠物数据集中,照片要么是猫,要么是狗。您可以将所有狗的照片作为负样本。然后,所有猫的照片将作为正样本,并设置适当的边界框。
OpenCV期望的正样本“信息文件”是一个纯文本文件,每行格式如下:
|
1 |
文件名 N x0 y0 w0 h0 x1 y1 w1 h1 ... |
文件名后面的数字是该图像上边界框的数量。每个边界框都是一个正样本。后面跟着的是边界框。每个框由其左上角的像素坐标以及框的宽度和高度指定。为了获得Haar级联分类器的最佳结果,边界框应与模型期望的纵横比相同。
假设您下载的宠物数据集位于`dataset/`目录中,您应该看到文件组织如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
数据集 |-- annotations | |-- README | |-- list.txt | |-- test.txt | |-- trainval.txt | |-- trimaps | | |-- Abyssinian_1.png | | |-- Abyssinian_10.png | | ... | | |-- yorkshire_terrier_98.png | | `-- yorkshire_terrier_99.png | `-- xmls | |-- Abyssinian_1.xml | |-- Abyssinian_10.xml | ... | |-- yorkshire_terrier_189.xml | `-- yorkshire_terrier_190.xml `-- images |-- Abyssinian_1.jpg |-- Abyssinian_10.jpg ... |-- yorkshire_terrier_98.jpg `-- yorkshire_terrier_99.jpg |
有了这个,使用以下程序创建正样本的“信息文件”和负样本文件列表就很容易了:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
import pathlib import xml.etree.ElementTree as ET import numpy as np def read_voc_xml(xmlfile: str) -> dict: """读取Pascal VOC XML并返回(文件名,对象名称,边界框) 其中边界框是一个 (xmin, ymin, xmax, ymax) 向量。像素 坐标是从1开始的。 """ root = ET.parse(xmlfile).getroot() boxes = {"filename": root.find("filename").text, "objects": [] } for box in root.iter('object'): bb = box.find('bndbox') obj = { "name": box.find('name').text, "xmin": int(bb.find("xmin").text), "ymin": int(bb.find("ymin").text), "xmax": int(bb.find("xmax").text), "ymax": int(bb.find("ymax").text), } boxes["objects"].append(obj) return boxes # 读取 Pascal VOC 并写入数据 base_path = pathlib.Path("dataset") img_src = base_path / "images" ann_src = base_path / "annotations" / "xmls" negative = [] positive = [] for xmlfile in ann_src.glob("*.xml"): # 加载 xml ann = read_voc_xml(str(xmlfile)) if ann['objects'][0]['name'] == 'dog': # 负样本 (狗) negative.append(str(img_src / ann['filename'])) else: # 正样本(猫) bbox = [] for obj in ann['objects']: x = obj['xmin'] y = obj['ymin'] w = obj['xmax'] - obj['xmin'] h = obj['ymax'] - obj['ymin'] bbox.append(f"{x} {y} {w} {h}") line = f"{str(img_src/ann['filename'])} {len(bbox)} {' '.join(bbox)}" positive.append(line) # 将输出写入 `negative.dat` 和 `positive.dat` with open("negative.dat", "w") as fp: fp.write("\n".join(negative)) with open("positive.dat", "w") as fp: fp.write("\n".join(positive)) |
该程序扫描数据集中所有 XML 文件,然后提取每个文件中的边界框(如果是猫的照片)。列表 negative 将保存狗照片的路径。列表 positive 将保存猫照片的路径以及上述格式的边界框,每行作为一个字符串。循环结束后,这两个列表将作为文件 negative.dat 和 positive.dat 写入磁盘。
negative.dat 的内容很简单。positive.dat 的内容如下:
|
1 2 3 4 5 |
dataset/images/Siamese_102.jpg 1 154 92 194 176 dataset/images/Bengal_152.jpg 1 84 8 187 201 dataset/images/Abyssinian_195.jpg 1 8 6 109 115 dataset/images/Russian_Blue_135.jpg 1 228 90 103 117 dataset/images/Persian_122.jpg 1 60 16 230 228 |
在运行训练之前,需要将 positive.dat 转换为二进制格式。这可以通过以下命令行完成:
|
1 |
opencv_createsamples -info positive.dat -vec positive.vec -w 30 -h 30 |
此命令应在与 positive.dat 相同的目录中运行,以便能找到数据集图像。此命令的输出将是 positive.vec,也称为“vec 文件”。在执行此操作时,需要使用 -w 和 -h 参数指定窗口的宽度和高度。这是为了在写入 vec 文件之前,将边界框裁剪的图像调整为这个像素大小。这还应与运行训练时指定的窗口大小匹配。
训练Haar级联分类器
训练分类器需要时间。它分多个阶段完成。每个阶段都会写入中间文件,一旦所有阶段完成,您将获得保存为 XML 文件的训练模型。OpenCV 期望所有这些生成的文件都存储在一个目录中。
运行训练过程确实很简单。我们考虑创建一个新目录 cat_detect 来存储生成的文件。创建目录后,您可以使用命令行工具 opencv_traincascade 运行训练
|
1 2 3 4 |
# 首先需要创建数据目录 mkdir cat_detect # 然后运行训练 opencv_traincascade -data cat_detect -vec positive.vec -bg negative.dat -numPos 900 -numNeg 2000 -numStages 10 -w 30 -h 30 |
请注意,positive.vec 用作正样本,negative.dat 用作负样本。另请注意,-w 和 -h 参数与您之前在 opencv_createsamples 命令中使用的相同。其他命令行参数解释如下:
-data:存储训练好的分类器的位置。此目录应已存在-vec:正样本的 vec 文件-bg:负样本列表,也称为“背景”图像-numPos:每个阶段训练中使用的正样本数量-numNeg:每个阶段训练中使用的负样本数量-numStages:要训练的级联阶段数量-w和-h:对象的像素大小。这必须与使用opencv_createsamples工具创建训练样本时使用的相同-minHitRate:每个阶段的最小所需真阳性率。在满足此条件之前,阶段训练不会终止。-maxFalseAlarmRate:每个阶段的最大所需假阳性率。在满足此条件之前,阶段训练不会终止。-maxDepth:弱树的最大深度-maxWeakCount:每个阶段弱树的最大数量
并非所有这些参数都是必需的。但您应该尝试不同的组合,看看是否能训练出更好的检测器。
在训练过程中,您将看到以下屏幕:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
$ opencv_traincascade -data cat_detect -vec positive.vec -bg negative.dat -numPos 900 -numNeg 2000 -numStages 10 -w 30 -h 30 参数 cascadeDirName: cat_detect vecFileName: positive.vec bgFileName: negative.dat numPos: 900 numNeg: 2000 numStages: 10 precalcValBufSize[Mb] : 1024 precalcIdxBufSize[Mb] : 1024 acceptanceRatioBreakValue : -1 stageType: BOOST featureType: HAAR sampleWidth: 30 sampleHeight: 30 boostType: GAB minHitRate: 0.995 maxFalseAlarmRate: 0.5 weightTrimRate: 0.95 maxDepth: 1 maxWeakCount: 100 mode: BASIC 给定窗口大小 [30,30] 的唯一特征数量:394725 ===== 训练第 0 阶段 ===== POS 计数:已消耗 900 : 900 NEG 计数:接受率 2000 : 1 预计算时间:3 +----+---------+---------+ | N | HR | FA | +----+---------+---------+ | 1| 1| 1| +----+---------+---------+ | 2| 1| 1| +----+---------+---------+ | 3| 1| 1| +----+---------+---------+ | 4| 1| 0.8925| +----+---------+---------+ | 5| 0.998889| 0.7785| ... | 19| 0.995556| 0.503| +----+---------+---------+ | 20| 0.995556| 0.492| +----+---------+---------+ END> ... 训练至今已耗时 0 天 2 小时 55 分 44 秒。 ===== 训练第 9 阶段 ===== POS 计数:已消耗 900 : 948 NEG 计数:接受率 2000 : 0.00723552 预计算时间:4 +----+---------+---------+ | N | HR | FA | +----+---------+---------+ | 1| 1| 1| +----+---------+---------+ | 2| 1| 1| +----+---------+---------+ | 3| 1| 1| +----+---------+---------+ | 4| 1| 1| +----+---------+---------+ | 5| 0.997778| 0.9895| ... | 50| 0.995556| 0.5795| +----+---------+---------+ | 51| 0.995556| 0.4895| +----+---------+---------+ END> 训练至今已耗时 0 天 3 小时 25 分 12 秒。 |
您应该注意到,$N$ 个阶段的训练运行编号为 0 到 $N-1$。某些阶段可能需要更长的训练时间。开始时,会显示训练参数以明确正在进行的操作。然后,在每个阶段,都会逐行打印一个表格。该表格显示三列:特征编号 N、命中率 HR(真阳性率)和误报率 FA(假阳性率)。
在第 0 阶段之前,您应该看到打印的 minHitRate 为 0.995,maxFalseAlarmRate 为 0.5。因此,每个阶段将找到许多 Haar 特征,直到分类器能够将命中率保持在 0.995 以上,同时误报率低于 0.5。理想情况下,您希望命中率为 1,误报率为 0。由于 Haar 级联是一种集成,如果您在多数情况下是正确的,则会得到正确的预测。近似地,您可以考虑一个 $n$ 阶段的分类器,其命中率为 $p$,误报率为 $q$,则总命中率为 $p^n$,总误报率为 $q^n$。在上述设置中,$n=10$,$p>0.995$,$q<0.5$。因此,总误报率将低于 0.1%,总命中率将高于 95%。
此训练命令在现代计算机上需要超过 3 小时才能完成。输出文件将命名为 cascade.xml,位于输出目录下。您可以使用以下示例代码检查结果:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import cv2 image = 'dataset/images/Abyssinian_88.jpg' model = 'cat_detect/cascade.xml' classifier = cv2.CascadeClassifier(model) img = cv2.imread(image) # 将图像转换为灰度图 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 执行对象检测 objects = classifier.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30)) # 在检测到的对象周围绘制矩形 for (x, y, w, h) in objects: cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2) # 显示结果 cv2.imshow('Object Detection', img) cv2.waitKey(0) cv2.destroyAllWindows() |
结果将取决于您的模型训练得如何,也取决于您传递给 detectMultiScale() 的参数。有关如何设置这些参数,请参阅之前的文章。
上述代码在一个数据集图像中运行检测器。您可能会看到如下结果:
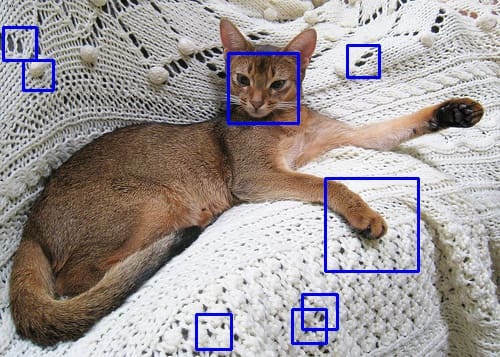
使用训练好的 Haar 级联对象检测器的示例输出
您会看到一些误报,但猫的脸已经被检测到。有多种方法可以提高质量。例如,您上面使用的数据集没有使用方形边界框,而您在训练和检测时使用了方形形状。调整数据集可能会有所改善。同样,您在训练命令行上使用的其他参数也会影响结果。但是,您应该知道 Haar 级联检测器速度非常快,但使用的阶段越多,它就会越慢。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
书籍
- 使用 Python 精通 OpenCV 4, 2019.
网站
总结
在这篇文章中,您学习了如何在 OpenCV 中训练 Haar 级联对象检测器。特别是,您学习了
- 如何为 Haar 级联训练准备数据
- 如何在命令行中运行训练过程
- 如何使用 OpenCV 3.x 训练检测器并在 OpenCV 4.x 中使用训练好的模型
开始使用 OpenCV 进行机器学习!

学习如何在图像处理项目中使用机器学习技术
...以高级方式使用 OpenCV,超越像素处理
在我的新电子书中探索如何实现
OpenCV 机器学习
它提供带有所有可用 Python 代码的自学教程,让您从新手成长为专家。它为您提供了
逻辑回归、随机森林、支持向量机、k 均值聚类、神经网络等等……所有这些都使用 OpenCV 中的机器学习模块






当我运行 opencv_traincascade 时,出现“command not found”(命令未找到)错误
嗨 Pedro...
opencv_traincascade命令用于在 OpenCV 中训练级联分类器(通常用于人脸或对象检测),但如果您遇到“command not found”错误,很可能意味着该命令不在您的系统 PATH 中,或者 OpenCV 未正确安装。以下是故障排除步骤:
1. **检查 OpenCV 安装**
– 确保 OpenCV 已安装了包含
opencv_traincascade的额外模块。– 如果 OpenCV 是从源代码编译的,请验证安装路径是否包含可执行文件。
2. **定位可执行文件**
– 您可以使用
find或locate来查找opencv_traincascadebash
find / -name "opencv_traincascade" 2>/dev/null
– 如果找到可执行文件,请记下其位置。
3. **添加到 PATH**
– 如果可执行文件位于标准目录之外(例如
/usr/local/bin),您可以将其添加到您的 PATH 中bash
export PATH=$PATH:/path/to/opencv/bin
– 将
/path/to/opencv/bin替换为opencv_traincascade所在的目录。将此行添加到您的.bashrc或.zshrc文件中,以使其永久生效。4. **使用 Contrib 模块重新构建 OpenCV**
– 如果您没有找到该命令,可能是因为 OpenCV 未使用 contrib 模块构建。您可以按如下方式安装包含这些模块的 OpenCV
bash
git clone https://github.com/opencv/opencv.git
git clone https://github.com/opencv/opencv_contrib.git
mkdir -p build && cd build
cmake -D OPENCV_EXTRA_MODULES_PATH=../opencv_contrib/modules ../opencv
make -j4
sudo make install
– 这将确保包含
opencv_traincascade。完成这些步骤后,请再次尝试运行
opencv_traincascade。如果问题仍然存在,请告诉我,我可以帮助您进一步排除故障。