神经网络的架构由数百个神经元组成,每个神经元接收多个输入以执行多元线性回归运算进行预测。在之前的教程中,我们构建了一个仅使用前向函数进行预测的单输出多元线性回归模型。
在本教程中,我们将为我们的单输出多元线性回归模型添加优化器,并执行反向传播以降低模型的损失。具体来说,我们将演示:
- 如何在 PyTorch 中构建单输出多元线性回归模型。
- 如何使用 PyTorch 内置包来创建复杂的模型。
- 如何在 PyTorch 中使用小批量梯度下降训练单输出多元线性回归模型。
通过我的《用PyTorch进行深度学习》一书来启动你的项目。它提供了包含可用代码的自学教程。
让我们开始吧。

在 PyTorch 中训练单输出多元线性回归模型。
图片来源:Bruno Nascimento。部分权利保留。
概述
本教程分为三个部分;它们是
- 准备预测数据
- 使用
Linear类进行多元线性回归 - 可视化结果
构建数据集类
与之前的教程一样,我们将创建一个示例数据集来进行实验。我们的数据类包括一个数据集构造函数,一个用于获取数据样本的 __getitem__() 方法,以及一个用于获取创建的数据长度的 __len__() 函数。它看起来是这样的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import torch from torch.utils.data import Dataset # 创建数据集类 class Data(Dataset): # 构造函数 def __init__(self): self.x = torch.zeros(40, 2) self.x[:, 0] = torch.arange(-2, 2, 0.1) self.x[:, 1] = torch.arange(-2, 2, 0.1) self.w = torch.tensor([[1.0], [1.0]]) self.b = 1 self.func = torch.mm(self.x, self.w) + self.b self.y = self.func + 0.2 * torch.randn((self.x.shape[0],1)) self.len = self.x.shape[0] # Getter def __getitem__(self, index): return self.x[index], self.y[index] # 获取数据长度 def __len__(self): return self.len |
这样,我们就可以轻松创建数据集对象了。
|
1 2 |
# 创建数据集对象 data_set = Data() |
想开始使用PyTorch进行深度学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
构建模型类
现在我们有了数据集,让我们来构建一个自定义的多元线性回归模型类。正如我们在上一教程中讨论的,我们定义一个类并使其成为 nn.Module 的子类。因此,该类继承了后者所有的宏和属性。
|
1 2 3 4 5 6 7 8 9 10 11 |
... # 创建自定义多元线性回归模型 class MultipleLinearRegression(torch.nn.Module): # 构造函数 def __init__(self, input_dim, output_dim): super().__init__() self.linear = torch.nn.Linear(input_dim, output_dim) # 预测 def forward(self, x): y_pred = self.linear(x) return y_pred |
我们将创建一个输入大小为 2、输出大小为 1 的模型对象。此外,我们可以使用 parameters() 方法打印出所有模型参数。
|
1 2 3 4 |
... # 创建模型对象 MLR_model = MultipleLinearRegression(2,1) print("The parameters: ", list(MLR_model.parameters())) |
输出看起来是这样的。
|
1 2 3 |
参数: [Parameter 包含 tensor([[ 0.2236, -0.0123]], requires_grad=True), Parameter 包含 tensor([0.5534], requires_grad=True)] |
为了训练我们的多元线性回归模型,我们还需要定义优化器和损失函数。我们将为模型采用随机梯度下降优化器和均方误差损失。我们将学习率保持在 0.1。
|
1 2 3 4 |
# 定义模型优化器 optimizer = torch.optim.SGD(MLR_model.parameters(), lr=0.1) # 定义损失函数 criterion = torch.nn.MSELoss() |
使用小批量梯度下降训练模型
在开始训练过程之前,让我们将数据加载到 DataLoader 中,并为训练定义批量大小。
|
1 2 3 4 |
from torch.utils.data import DataLoader # 创建数据加载器 train_loader = DataLoader(dataset=data_set, batch_size=2) |
我们将开始训练,让过程进行 20 个 epoch,使用与我们之前的教程相同的 for 循环。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 训练模型 Loss = [] epochs = 20 for epoch in range(epochs): for x,y in train_loader: y_pred = MLR_model(x) loss = criterion(y_pred, y) Loss.append(loss.item()) optimizer.zero_grad() loss.backward() optimizer.step() print(f"epoch = {epoch}, loss = {loss}") print("Done training!") |
在上面的训练循环中,每个 epoch 都会报告损失。您应该会看到类似以下的输出
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
epoch = 0, loss = 0.06849382817745209 epoch = 1, loss = 0.07729718089103699 epoch = 2, loss = 0.0755983218550682 epoch = 3, loss = 0.07591515779495239 epoch = 4, loss = 0.07585576921701431 epoch = 5, loss = 0.07586675882339478 epoch = 6, loss = 0.07586495578289032 epoch = 7, loss = 0.07586520910263062 epoch = 8, loss = 0.07586534321308136 epoch = 9, loss = 0.07586508244276047 epoch = 10, loss = 0.07586508244276047 epoch = 11, loss = 0.07586508244276047 epoch = 12, loss = 0.07586508244276047 epoch = 13, loss = 0.07586508244276047 epoch = 14, loss = 0.07586508244276047 epoch = 15, loss = 0.07586508244276047 epoch = 16, loss = 0.07586508244276047 epoch = 17, loss = 0.07586508244276047 epoch = 18, loss = 0.07586508244276047 epoch = 19, loss = 0.07586508244276047 Done training! |
这个训练循环是 PyTorch 中的典型用法。您将来会在项目中经常重复使用它。
绘制图表
最后,让我们绘制图表来可视化损失在训练过程中如何下降并收敛到某个点。
|
1 2 3 4 5 6 7 8 |
... import matplotlib.pyplot as plt # 绘制 epoch 和 loss 的图表 plt.plot(Loss) plt.xlabel("Iterations ") plt.ylabel("total loss ") plt.show() |
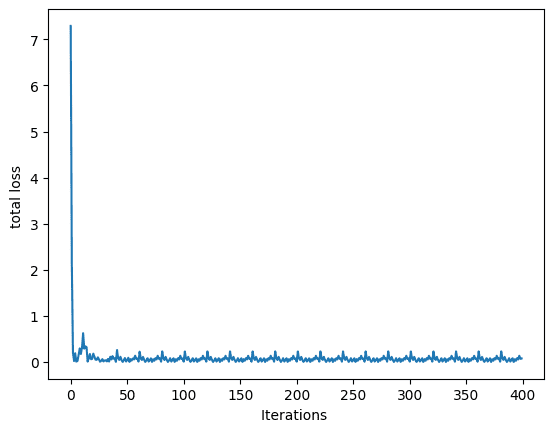
训练过程中的损失
将所有内容放在一起,完整的代码如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
# 导入库和包 import numpy as np import torch import matplotlib.pyplot as plt from torch.utils.data import Dataset, DataLoader torch.manual_seed(42) # 创建数据集类 class Data(Dataset): # 构造函数 def __init__(self): self.x = torch.zeros(40, 2) self.x[:, 0] = torch.arange(-2, 2, 0.1) self.x[:, 1] = torch.arange(-2, 2, 0.1) self.w = torch.tensor([[1.0], [1.0]]) self.b = 1 self.func = torch.mm(self.x, self.w) + self.b self.y = self.func + 0.2 * torch.randn((self.x.shape[0],1)) self.len = self.x.shape[0] # Getter def __getitem__(self, index): return self.x[index], self.y[index] # 获取数据长度 def __len__(self): return self.len # 创建数据集对象 data_set = Data() # 创建自定义多元线性回归模型 class MultipleLinearRegression(torch.nn.Module): # 构造函数 def __init__(self, input_dim, output_dim): super().__init__() self.linear = torch.nn.Linear(input_dim, output_dim) # 预测 def forward(self, x): y_pred = self.linear(x) return y_pred # 创建模型对象 MLR_model = MultipleLinearRegression(2,1) # 定义模型优化器 optimizer = torch.optim.SGD(MLR_model.parameters(), lr=0.1) # 定义损失函数 criterion = torch.nn.MSELoss() # 创建数据加载器 train_loader = DataLoader(dataset=data_set, batch_size=2) # 训练模型 Loss = [] epochs = 20 for epoch in range(epochs): for x,y in train_loader: y_pred = MLR_model(x) loss = criterion(y_pred, y) Loss.append(loss.item()) optimizer.zero_grad() loss.backward() optimizer.step() print(f"epoch = {epoch}, loss = {loss}") print("Done training!") # 绘制 epoch 和 loss 的图表 plt.plot(Loss) plt.xlabel("Iterations ") plt.ylabel("total loss ") plt.show() |
总结
在本教程中,您学习了如何在 PyTorch 中构建单输出多元线性回归模型。具体来说,您学习了
- 如何在 PyTorch 中构建单输出多元线性回归模型。
- 如何使用 PyTorch 内置包来创建复杂的模型。
- 如何在 PyTorch 中使用小批量梯度下降训练单输出多元线性回归模型。
开始使用PyTorch进行深度学习!

学习如何构建深度学习模型
...使用新发布的PyTorch 2.0库
在我的新电子书中探索如何实现
使用 PyTorch进行深度学习
它提供了包含数百个可用代码的自学教程,让你从新手变成专家。它将使你掌握:
张量操作、训练、评估、超参数优化等等...






暂无评论。