训练数据是机器学习算法用来学习的数据集,也称为训练集。验证数据是机器学习算法用来测试其准确性的数据集之一。验证算法的性能是指将其预测输出与验证数据中的已知真实值进行比较。
训练数据通常很大且复杂,而验证数据通常较小。训练样本越多,模型性能越好。例如,在垃圾邮件检测任务中,如果训练集中有 10 封垃圾邮件和 10 封非垃圾邮件,那么机器学习模型很难检测新邮件中的垃圾邮件,因为它没有关于垃圾邮件看起来是怎样的足够信息。但是,如果我们有 1000 万封垃圾邮件和 1000 万封非垃圾邮件,那么我们的模型就更容易检测新垃圾邮件,因为它看到了很多它看起来的例子。
在本教程中,您将学习 PyTorch 中的训练和验证数据。我们还将展示训练和验证数据对机器学习模型的重要性,特别是对神经网络的关注。具体来说,您将学习:
- PyTorch 中训练和验证数据的概念。
- 如何在 PyTorch 中将数据分割成训练集和验证集。
- 如何使用 PyTorch 中的内置函数构建简单的线性回归模型。
- 如何使用各种学习率来训练模型以获得所需的准确度。
- 如何调整超参数以获得数据的最佳模型。
通过我的《用PyTorch进行深度学习》一书来启动你的项目。它提供了包含可用代码的自学教程。
让我们开始吧。

使用 PyTorch 中的优化器。
图片由 Markus Krisetya 拍摄。保留部分权利。
概述
本教程分为三个部分;它们是
- 构建训练集和验证集的数据类
- 构建和训练模型
- 可视化结果
构建训练集和验证集的数据类
首先,让我们加载本教程所需的一些库。
|
1 2 3 4 |
import numpy as np import matplotlib.pyplot as plt import torch from torch.utils.data import Dataset, DataLoader |
我们将从构建自定义数据集类开始,以生成足够的合成数据。这将允许我们将数据分割成训练集和验证集。此外,我们还将添加一些步骤将异常值包含在数据中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 创建我们的数据集类 class Build_Data(Dataset): # 构造函数 def __init__(self, train = True): self.x = torch.arange(-3, 3, 0.1).view(-1, 1) self.func = -5 * self.x + 1 self.y = self.func + 0.4 * torch.randn(self.x.size()) self.len = self.x.shape[0] # 添加一些异常值 if train == True: self.y[10:12] = 0 self.y[30:35] = 25 else: pass # 获取数据 def __getitem__(self, index): return self.x[index], self.y[index] # 获取数据长度 def __len__(self): return self.len train_set = Build_Data() val_set = Build_Data(train=False) |
对于训练集,我们将 `train` 参数默认设置为 `True`。如果设置为 `False`,它将生成验证数据。我们已将训练集和验证集创建为单独的对象。
现在,让我们可视化我们的数据。您将在 x=-2 和 x=0 处看到异常值。
|
1 2 3 4 5 6 7 8 |
# 绘制和可视化数据点 plt.plot(train_set.x.numpy(), train_set.y.numpy(), 'b+', label='y') plt.plot(train_set.x.numpy(), train_set.func.numpy(), 'r', label='func') plt.xlabel('x') plt.ylabel('y') plt.legend() plt.grid('True', color='y') plt.show() |
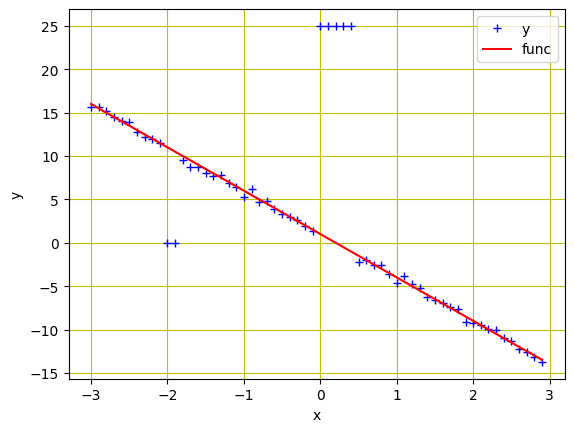
训练和验证数据集
生成上述图表的完整代码如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import numpy as np import matplotlib.pyplot as plt import torch from torch.utils.data import Dataset, DataLoader # 创建我们的数据集类 class Build_Data(Dataset): # 构造函数 def __init__(self, train = True): self.x = torch.arange(-3, 3, 0.1).view(-1, 1) self.func = -5 * self.x + 1 self.y = self.func + 0.4 * torch.randn(self.x.size()) self.len = self.x.shape[0] # 添加一些异常值 if train == True: self.y[10:12] = 0 self.y[30:35] = 25 else: pass # 获取数据 def __getitem__(self, index): return self.x[index], self.y[index] # 获取数据长度 def __len__(self): return self.len train_set = Build_Data() val_set = Build_Data(train=False) # 绘制和可视化数据点 plt.plot(train_set.x.numpy(), train_set.y.numpy(), 'b+', label='y') plt.plot(train_set.x.numpy(), train_set.func.numpy(), 'r', label='func') plt.xlabel('x') plt.ylabel('y') plt.legend() plt.grid('True', color='y') plt.show() |
构建和训练模型
PyTorch 的 `nn` 包为我们提供了许多有用的函数。我们将从 `nn` 包中导入线性回归模型和损失函数。此外,我们还将从 `torch.utils.data` 包中导入 `DataLoader`。
|
1 2 3 4 |
... model = torch.nn.Linear(1, 1) criterion = torch.nn.MSELoss() trainloader = DataLoader(dataset=train_set, batch_size=1) |
我们将创建一个包含各种学习率的列表,以一次性训练多个模型。这是深度学习从业者中的一种常见做法,他们会调整不同的超参数来获得最佳模型。我们将把训练和验证损失都存储在张量中,并创建一个名为 `Models` 的空列表来存储我们的模型。稍后,我们将绘制图表来评估我们的模型。
|
1 2 3 4 5 |
... learning_rates = [0.1, 0.01, 0.001, 0.0001] train_err = torch.zeros(len(learning_rates)) val_err = torch.zeros(len(learning_rates)) Models = [] |
为了训练模型,我们将使用各种学习率和随机梯度下降(SGD)优化器。训练和验证数据的结果将与模型一起保存在列表中。我们将所有模型训练 20 个 epoch。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
... epochs = 20 # 遍历各种学习率列表 for i, learning_rate in enumerate(learning_rates): model = torch.nn.Linear(1, 1) optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate) for epoch in range(epochs): for x, y in trainloader: y_hat = model(x) loss = criterion(y_hat, y) optimizer.zero_grad() loss.backward() optimizer.step() # 训练数据 Y_hat = model(train_set.x) train_loss = criterion(Y_hat, train_set.y) train_err[i] = train_loss.item() # 验证数据 Y_hat = model(val_set.x) val_loss = criterion(Y_hat, val_set.y) val_err[i] = val_loss.item() Models.append(model) |
上面的代码分别收集训练和验证的损失。这有助于我们了解我们的训练效果如何,例如,是否过拟合。如果我们发现验证集的损失与训练集的损失差异很大,那么它就过拟合了。在这种情况下,我们训练好的模型无法泛化到它未见过的数据,即验证集。
想开始使用PyTorch进行深度学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
可视化结果
在上面,我们使用了相同的模型(线性回归)并以固定的 epoch 数进行训练。唯一的变化是学习率。然后我们可以比较哪个学习率在最快收敛方面给我们带来了最好的模型。
让我们可视化每个学习率的训练和验证数据的损失图。通过查看图表,您可以观察到在学习率为 0.001 时损失最小,这意味着我们的模型在该学习率下对于此数据收敛得更快。
|
1 2 3 4 5 6 |
plt.semilogx(np.array(learning_rates), train_err.numpy(), label = '总训练损失') plt.semilogx(np.array(learning_rates), val_err.numpy(), label = '总验证损失') plt.ylabel('总损失') plt.xlabel('学习率') plt.legend() plt.show() |
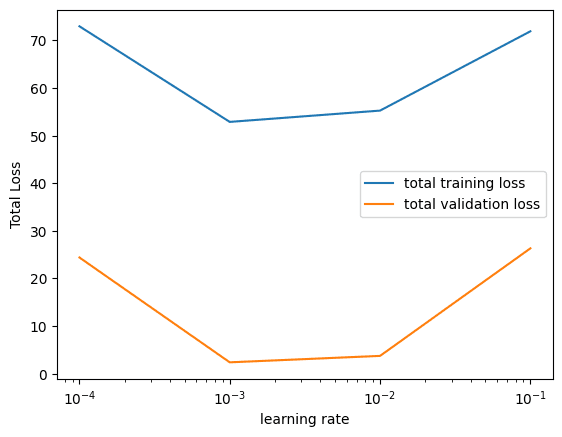
损失与学习率
我们还绘制每个模型在验证数据上的预测。一个完全收敛的模型应该能完美地拟合数据,而一个远未收敛的模型会产生偏离数据的预测。
|
1 2 3 4 5 6 7 8 9 |
# 绘制验证数据上的预测 for model, learning_rate in zip(Models, learning_rates): yhat = model(val_set.x) plt.plot(val_set.x.numpy(), yhat.detach().numpy(), label = '学习率:' + str(learning_rate)) plt.plot(val_set.x.numpy(), val_set.func.numpy(), 'or', label = '验证数据') plt.xlabel('x') plt.ylabel('y') plt.legend() plt.show() |
我们看到预测可视化如下: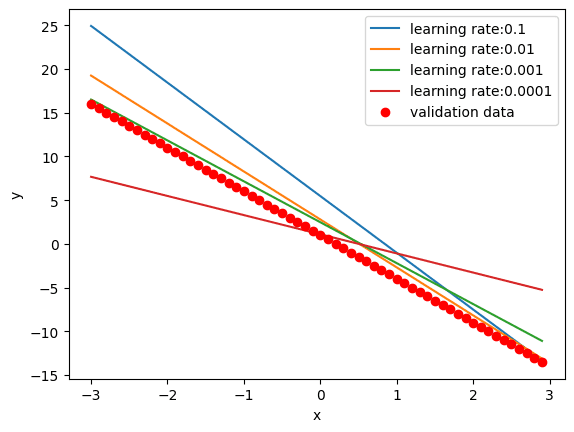
如您所见,绿线更接近验证数据点。它是具有最佳学习率(0.001)的线。
以下是从创建数据到可视化训练和验证损失的完整代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
import numpy as np import matplotlib.pyplot as plt import torch from torch.utils.data import Dataset, DataLoader # 创建我们的数据集类 class Build_Data(Dataset): # 构造函数 def __init__(self, train=True): self.x = torch.arange(-3, 3, 0.1).view(-1, 1) self.func = -5 * self.x + 1 self.y = self.func + 0.4 * torch.randn(self.x.size()) self.len = self.x.shape[0] # 添加一些异常值 if train == True: self.y[10:12] = 0 self.y[30:35] = 25 else: pass # 获取数据 def __getitem__(self, index): return self.x[index], self.y[index] # 获取数据长度 def __len__(self): return self.len train_set = Build_Data() val_set = Build_Data(train=False) criterion = torch.nn.MSELoss() trainloader = DataLoader(dataset=train_set, batch_size=1) learning_rates = [0.1, 0.01, 0.001, 0.0001] train_err = torch.zeros(len(learning_rates)) val_err = torch.zeros(len(learning_rates)) Models = [] epochs = 20 # 遍历各种学习率列表 for i, learning_rate in enumerate(learning_rates): model = torch.nn.Linear(1, 1) optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate) for epoch in range(epochs): for x, y in trainloader: y_hat = model(x) loss = criterion(y_hat, y) optimizer.zero_grad() loss.backward() optimizer.step() # 训练数据 Y_hat = model(train_set.x) train_loss = criterion(Y_hat, train_set.y) train_err[i] = train_loss.item() # 验证数据 Y_hat = model(val_set.x) val_loss = criterion(Y_hat, val_set.y) val_err[i] = val_loss.item() Models.append(model) plt.semilogx(np.array(learning_rates), train_err.numpy(), label = '总训练损失') plt.semilogx(np.array(learning_rates), val_err.numpy(), label = '总验证损失') plt.ylabel('总损失') plt.xlabel('学习率') plt.legend() plt.show() # 绘制验证数据上的预测 for model, learning_rate in zip(Models, learning_rates): yhat = model(val_set.x) plt.plot(val_set.x.numpy(), yhat.detach().numpy(), label = '学习率:' + str(learning_rate)) plt.plot(val_set.x.numpy(), val_set.func.numpy(), 'or', label = '验证数据') plt.xlabel('x') plt.ylabel('y') plt.legend() plt.show() |
总结
在本教程中,您学习了 PyTorch 中训练和验证数据的概念。具体来说,您学习了:
- PyTorch 中训练和验证数据的概念。
- 如何在 PyTorch 中将数据分割成训练集和验证集。
- 如何使用 PyTorch 中的内置函数构建简单的线性回归模型。
- 如何使用各种学习率来训练模型以获得所需的准确度。
- 如何调整超参数以获得数据的最佳模型。
开始使用PyTorch进行深度学习!

学习如何构建深度学习模型
...使用新发布的PyTorch 2.0库
在我的新电子书中探索如何实现
使用 PyTorch进行深度学习
它提供了包含数百个可用代码的自学教程,让你从新手变成专家。它将使你掌握:
张量操作、训练、评估、超参数优化等等...






关于训练和验证的精彩文章。但我缺失的信息如下:
我有一些带有参数的对象。我想将参数输入 AI(PyTorch),AI 会对对象做出决策。每个对象都有一个 id。我不想将 objectid 输入 AI,因为它可能会影响结果。AI 的输出是决策的数组/流,但没有 objectid。
有没有办法将 AI 的结果与相应的 objectid 一起获取?
(如果 AI 在管道中,具有多个写入器和结果读取器,那将非常方便)