Stable Diffusion 在 LAION-5B 数据集上进行训练,这是一个包含数十亿通用图像-文本对的大规模数据集。然而,它在理解特定主题及其在各种上下文中的生成方面存在不足(通常模糊、晦涩或无意义)。为了解决这个问题,针对特定用例对模型进行微调变得至关重要。对于 Stable Diffusion,有两种重要的微调技术:
- 文本反转:此技术侧重于重新训练模型的文本嵌入,以将一个词作为主题注入。
- DreamBooth:与文本反转不同,DreamBooth 涉及对整个模型进行重新训练,专门针对主题进行定制,从而实现更好的个性化。
在本文中,您将探索以下概念:
- 微调挑战和 DreamBooth 中的推荐设置
- 使用 DreamBooth 进行 Stable Diffusion 微调 – 示例
- 有效使用 DreamBooth 中的提示技巧
通过我的书 《掌握 Stable Diffusion 数字艺术》 开启您的项目。 它提供带有工作代码的自学教程。
让我们开始吧

使用 DreamBooth 训练 Stable Diffusion
照片作者: Sasha Freemind。保留部分权利。
概述
本文共五部分,分别为:
- 什么是 DreamBooth?
- 微调挑战
- 使用 DreamBooth 进行微调的工作流程
- 使用您训练好的模型
- 有效使用 DreamBooth 的技巧
什么是 DreamBooth?
DreamBooth 是生成式 AI 的一项重大飞跃,特别是对于 Text2Img 模型。它是由一组 Google 研究人员推出的一项专门技术,用于微调预训练的大型 Text2Img 模型(如 Stable Diffusion),以适应特定主题、角色或对象。因此,您现在可以将自定义对象或概念注入模型,以实现更个性化和多样化的生成。以下是 Google 研究人员的说法:
这就像一个照相亭,但一旦主体被捕捉到,无论您的梦想带您到哪里,它都可以被合成出来。
DreamBooth 在各个领域提供了广泛的令人兴奋的用例,主要侧重于增强图像生成。这包括:
- 个性化:用户可以创建亲人、宠物或特定对象的图像,使其适用于礼品、社交媒体和个性化商品。
- 艺术和商业用途:艺术家和设计师可以利用他们的艺术作品训练模型,以生成多样的艺术图像和可视化。这对于商业用途也很有益,可以针对品牌和营销需求进行定制化图像生成。
- 研究和实验:DreamBooth 是研究人员的强大工具。它能够探索深度学习模型、特定领域的应用和受控实验。通过微调模型,研究人员可以突破生成式 AI 的界限,并对其潜力获得新的见解。
只需提供您主题的几张图像,在训练时提供其类别名称,并在推理时提供专门定制的提示,即可生成个性化输出。让我们深入了解 DreamBooth 的微调过程:
- 创建微调图像数据集
包含主题的几张(3-5 张)高质量且具有代表性的图像。模型将根据训练数据来熟悉该主题,因此需要精心设计。有关详细信息将在微调部分讨论。 - 绑定唯一的标识符和类别名称
主题必须与一个文本模型词汇表中不常用的稀有标记相关联。模型将通过此唯一标识符识别主题。为了保持主题的原始本质,您还需要在训练期间提供一个类别名称(模型已知的)。例如,您可以将一只个人宠物狗与标识符“[V]”和类别名称“dog”相关联,这样当提示“一只 [V] 狗坐着”时,模型在生成狗图像时将识别出宠物狗的标识符。
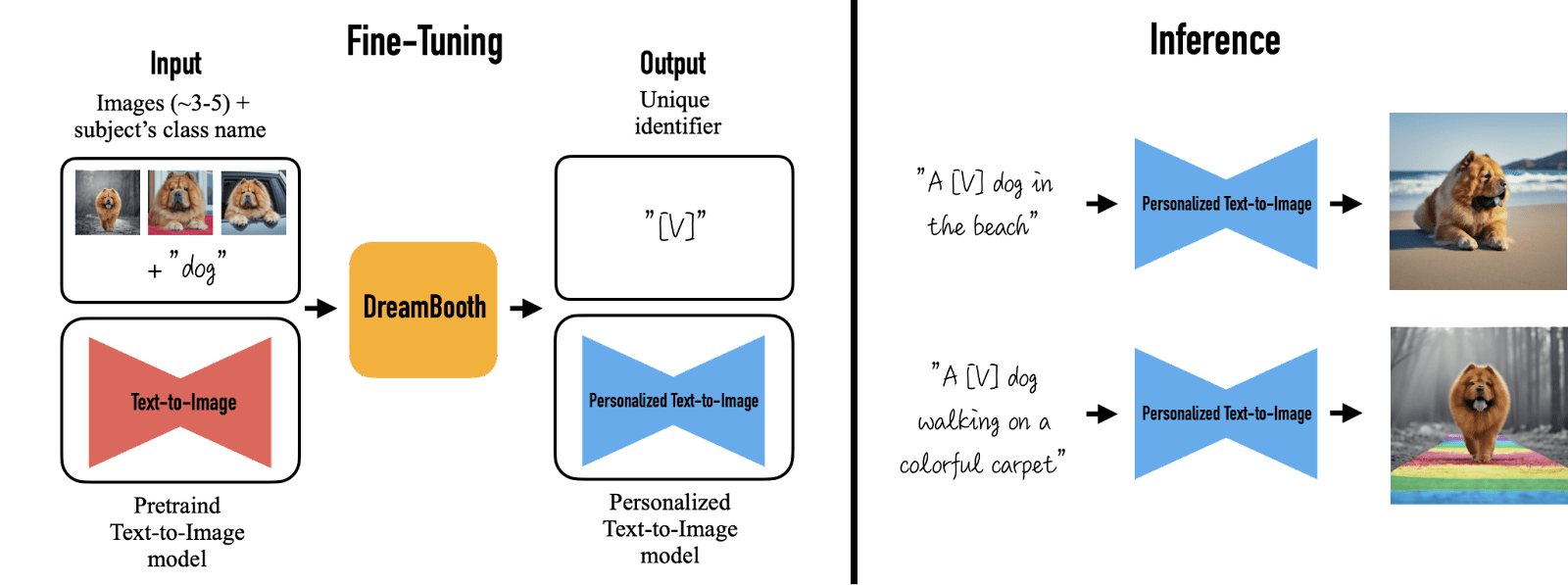
微调模型。图片来源:DreamBooth
上述第一个标准对于图像生成的明显原因很重要。第二个标准也很重要,因为您不是从头开始训练 Stable Diffusion,而是对现有模型进行微调以适应您的数据集。模型已经学会了狗是什么。学习您的标记是狗的一种变体,比取消学习一个词(即,将一个词的含义重新分配给完全不同的概念)或从头学习一个新词(例如,从一个从未见过任何动物的模型中学到狗是什么)更容易。
微调挑战
微调 Stable Diffusion 模型意味着从一个已知有效的现有模型开始训练。这种类型的训练存在一些挑战:
- 过拟合
当模型过于紧密地记住训练数据而忘记如何泛化时,就会发生过拟合。它仅在训练数据上表现良好,但在新数据上表现不佳。由于您只向 DreamBooth 提供少量图像,它很可能会很快过拟合。 - 语言漂移
语言漂移是微调语言模型的常见现象,并将其影响扩展到 Txt2Img 模型。在微调过程中,模型可能会丢失关于类别内主题的各种表示的重要信息。这种漂移会导致模型难以生成同一类别内的各种主题,从而影响输出的丰富性和多样性。
以下是一些 DreamBooth 设置,通过仔细调整这些设置,您可以使模型更具适应性,以生成多样化的输出,同时降低过拟合和语言漂移的风险。
- 优化学习率和训练步数
调整学习率、训练步数和批次大小对于克服过拟合至关重要。高学习率和许多训练步数会导致过拟合(影响多样性)。低学习率和较少的训练步数会导致模型欠拟合(未能捕捉到主题)。因此,建议从较低的学习率开始,并逐渐增加训练步数,直到生成结果满意。 - 先验保留损失
这是通过生成大约 200 到 300 个相同类别的样本以及主题的图像,然后将这些样本添加到我们的训练图像集中来完成的。这些附加图像是通过 Stable Diffusion 模型本身通过类别提示生成的。 - GPU 高效技术
诸如 8bit-Adam(支持量化)、fp16 混合精度训练(将梯度计算精度降低到 16 位浮点)和梯度累积(分步计算梯度而不是为整个批次计算)之类的技术可以帮助优化内存利用率并加快训练速度。
使用 DreamBooth 进行微调的工作流程
我们已准备好开始微调过程,并使用下面的基于 Diffuser 的 DreamBooth 训练脚本的简化版本。借助上述 GPU 高效技术,您可以在 Google Colab Notebook 中提供的 Tesla T4 GPU 上运行此脚本。
开始之前,您应该设置好环境。在 notebook 单元格中,您可以使用以下命令来运行 shell 命令:
|
1 2 3 4 5 6 7 |
!wget -q https://github.com/ShivamShrirao/diffusers/raw/main/examples/dreambooth/train_dreambooth.py !wget -q https://github.com/ShivamShrirao/diffusers/raw/main/scripts/convert_diffusers_to_original_stable_diffusion.py %pip install -qq git+https://github.com/ShivamShrirao/diffusers %pip install -q -U --pre triton %pip install -q accelerate transformers ftfy bitsandbytes natsort safetensors xformers |
上面下载的训练脚本名为 train_dreambooth.py。还下载了一个转换脚本来处理训练输出。一些包已安装在 Python 环境中。要验证它是否正常工作,您可以在新单元格中运行这些导入,以确保没有触发错误:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import json import os from google.colab import files import shutil from natsort import natsorted from glob import glob import torch from torch import autocast from diffusers import StableDiffusionPipeline, DDIMScheduler from IPython.display import display |
训练 Stable Diffusion 模型需要大量资源。最好利用一些在线资源来存储模型。该脚本假定您已注册 Hugging Face 帐户并获取了 API 令牌。请在标记为 HUGGINGFACE_TOKEN 的指定字段中提供您的访问令牌,以便脚本正常工作,即:
|
1 2 3 |
!mkdir -p ~/.huggingface HUGGINGFACE_TOKEN = "在此处放入您的令牌" !echo -n "{HUGGINGFACE_TOKEN}" > ~/.huggingface/token |
让我们指定我们的基础模型和模型保存的输出目录。启动脚本时,我们将传递这些变量。
|
1 2 3 4 5 |
MODEL_NAME = "runwayml/stable-diffusion-v1-5" OUTPUT_DIR = "/content/stable_diffusion_weights/zwx" # 创建输出目录 !mkdir -p $OUTPUT_DIR |
现在是最关键的部分,以获得令人满意的且一致的 DreamBooth 结果。使用代表您主题的高质量图像非常重要。请注意,模型将学习训练集中的伪影,例如低分辨率或运动模糊。创建数据集时应考虑以下几点:
- 数据集大小:由于这些模型会很快过拟合,因此最好包含 10 到 120 个主题样本。裁剪它们并将它们的大小调整为 512×512 像素。
- 图像多样性:选择您想要的精确内容的连贯样本,并尝试包含不同角度的图像。为了多样性,您可能还需要包含人物、风景或动物/物体的背景场景。此外,移除内部不需要的物体(例如,水印、被边缘裁剪的人物)。避免使用纯色或透明背景的图像。
在将图像上传到 Colab notebook 之前,让我们运行以下单元格:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# concepts_list 是概念/主题的列表,每个主题都表示为一个字典 concepts_list = [ { "instance_prompt": "photo of zwx dog", "class_prompt": "photo of a dog", "instance_data_dir": "/content/data/zwx", "class_data_dir": "/content/data/dog" }, ] # 根据每个概念的 instance_data_dir 创建一个目录 for c in concepts_list: os.makedirs(c["instance_data_dir"], exist_ok=True) # 将 concepts_list 转储到 JSON 文件 with open("concepts_list.json", "w") as f: json.dump(concepts_list, f, indent=4) |
运行此单元格后,上面映射到 instance_data_dir 的路径将创建一个目录。您准备好的图像应使用 Colab 笔记本侧边栏中的文件图标上传到上述目录。
instance_prompt 是一个示例。您应该根据您想要命名图像的方式来更新它。鼓励使用新的标记(如上面的“zwx”)作为唯一标识符。但 class_prompt 应仅使用易于理解的词语来突出图像。
在此示例中,我们正在对哈士奇犬进行 Stable Diffusion 微调,我们提供了 7 张实例图像。您可以尝试类似的操作。在此单元格之后,您的目录结构可能如下所示:
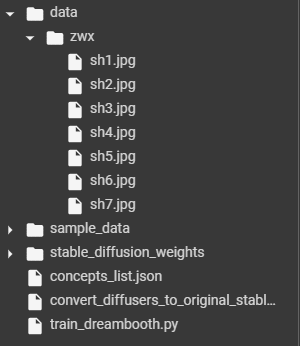
从 Colab Notebook 侧边栏看到的包含训练图像的目录
现在您已准备好开始训练。下表列出了基于计算需求的最佳标志。限制因素通常是 GPU 可用内存。
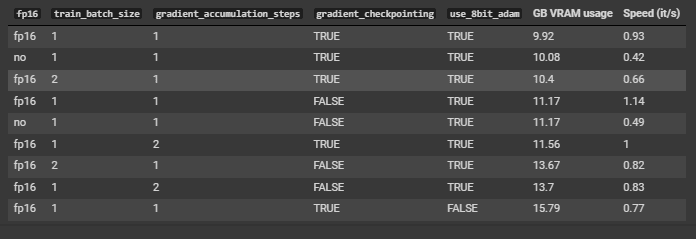
推荐的训练标志
训练是执行 diffusers 提供的训练脚本。以下是一些您可以考虑的参数:
--use_8bit_adam启用全精度和量化支持--train_text_encoder启用文本编码器微调--with_prior_preservation启用先验保留损失--prior_loss_weight控制先验保留的强度
在 Colab notebook 中创建并运行以下内容作为单元格即可完成训练:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
!python3 train_dreambooth.py \ --pretrained_model_name_or_path=$MODEL_NAME \ --pretrained_vae_name_or_path="stabilityai/sd-vae-ft-mse" \ --output_dir=$OUTPUT_DIR \ --revision="fp16" \ --with_prior_preservation --prior_loss_weight=1.0 \ --seed=1337 \ --resolution=512 \ --train_batch_size=1 \ --train_text_encoder \ --mixed_precision="fp16" \ --use_8bit_adam \ --gradient_accumulation_steps=1 \ --learning_rate=1e-6 \ --lr_scheduler="constant" \ --lr_warmup_steps=0 \ --num_class_images=50 \ --sample_batch_size=4 \ --max_train_steps=800 \ --save_interval=10000 \ --save_sample_prompt="photo of zwx dog" \ --concepts_list="concepts_list.json" |
请耐心等待此脚本完成。然后您可以运行以下命令将其转换为我们可以使用的格式:
|
1 2 3 4 5 6 7 8 9 |
WEIGHTS_DIR = natsorted(glob(OUTPUT_DIR + os.sep + "*"))[-1] ckpt_path = WEIGHTS_DIR + "/model.ckpt" half_arg = "" fp16 = True if fp16: half_arg = "--half" !python convert_diffusers_to_original_stable_diffusion.py --model_path $WEIGHTS_DIR --checkpoint_path $ckpt_path $half_arg print(f"[*] Converted ckpt saved at {ckpt_path}") |
上面的命令将在分配给 WEIGHTS_DIR 的目录(即最新的检查点目录)下创建 model.ckpt 文件。此输出文件将与 Automatic1111 的 Stable Diffusion Web UI 兼容。如果 fp16 被指定为 True,它将只占用一半的空间(即 2GB),这通常是推荐的。
使用您训练好的模型
创建的模型就像任何其他 Stable Diffusion 模型权重文件一样。您可以将其加载到 WebUI 中。您也可以像下面的单元格一样,使用 Python 代码加载它:
|
1 2 3 4 5 6 7 8 9 10 11 |
model_path = WEIGHTS_DIR pipe = StableDiffusionPipeline.from_pretrained(model_path, safety_checker=None, torch_dtype=torch.float16 ).to("cuda") pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config) pipe.enable_xformers_memory_efficient_attention() g_cuda = torch.Generator(device='cuda') seed = 52362 g_cuda.manual_seed(seed) |
让我们尝试四个样本
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
prompt = "photo of zwx dog in a bucket wearing 3d glasses" negative_prompt = "" num_samples = 4 guidance_scale = 7.5 num_inference_steps = 24 height = 512 width = 512 with autocast("cuda"), torch.inference_mode(): images = pipe( prompt, height=height, width=width, negative_prompt=negative_prompt, num_images_per_prompt=num_samples, num_inference_steps=num_inference_steps, guidance_scale=guidance_scale, generator=g_cuda ).images for img in images: display(img) # 释放运行时内存 exit() |
生成的图像看起来是这样的:




好了!
有效使用 DreamBooth 的技巧
如果您正在对模型进行人脸微调,那么先验保留至关重要。人脸需要更严格的训练,因为 DreamBooth 需要更多的训练步骤和更低的学习率来进行人脸微调。
像 DDIM(推荐)、PNDM 和 LMS Discrete 这样的调度器可以帮助减轻模型过拟合。当输出看起来有噪声或缺乏清晰度或细节时,您应该尝试使用调度器。
除了 U-Net 训练,训练文本编码器还可以显著提高输出质量(尤其是在人脸方面),但会消耗内存;至少需要一块 24GB 的 GPU。您也可以使用前面讨论过的 GPU 高效技术进行优化。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
- LAION-5B 数据集: https://laion.ai/blog/laion-5b/
- 通过视觉接地对抗语言漂移,作者:Lee 等人(2019)
- DreamBooth
- 来自 diffusers 的 DreamBooth 训练示例
总结
现在您已经了解了 DreamBooth,这是一个用于为个性化内容精炼 Stable Diffusion 模型的强大工具。但是,它也面临着由于图像数量少导致的过拟合和语言漂移等挑战。为了充分利用 DreamBooth,您还了解了一些优化方法。请记住,DreamBooth 的成功取决于仔细的数据集准备和精确的参数调整。有关更深入的见解,请参阅详细的 DreamBooth 训练指南。
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
本书提供 自学教程,包含所有 可运行的代码(Python),将您从新手指导为图像生成领域的专家。它教您如何设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数等等……所有这一切都是为了帮助您创作令人惊叹的数字艺术。






暂无评论。