通常,您为机器学习准备的原始数据并不适合建模。
您需要对其进行准备或重塑,以满足不同机器学习算法的期望。
在本帖中,您将了解两种可用于转换机器学习数据以进行建模的技术。
阅读本文后,您将了解
- 如何将实值属性转换为称为离散化的离散分布。
- 如何将离散属性转换为多个实值,称为哑变量。
- 何时根据您的数据进行离散化或创建哑变量。
启动您的项目,阅读我的新书《Weka 机器学习精通》,其中包含分步教程和所有示例的清晰截图。
让我们开始吧。
- **2018 年 3 月更新**:添加了下载数据集的备用链接,因为原始链接似乎已被删除。
离散化数值属性
一些机器学习算法更喜欢,或者发现处理离散属性更容易。
例如,决策树算法可以在实值属性中选择分割点,但当分割点选择在实值属性的 bin 或预定义组之间时,它们会更清晰。
离散属性是描述类别的属性,称为名义属性。那些描述类别并且类别顺序有意义的属性称为有序属性。将实值属性转换为有序属性或 bin 的过程称为离散化。
您可以使用 Weka 中的 Discretize 过滤器来离散化您的实值属性。
下面的教程演示了如何使用 Discretize 过滤器。Pima 印第安人糖尿病发病数据集用于演示此过滤器,因为输入值是实值,将它们分组到 bin 中可能是有意义的。
你可以在此处了解更多关于此数据集的信息:
您还可以通过加载文件 diabetes.arff 来访问 Weka 安装目录下的 data/ 目录中的数据集。
1. 打开 Weka Explorer。
2. 加载 Pima 印第安人糖尿病发病数据集。
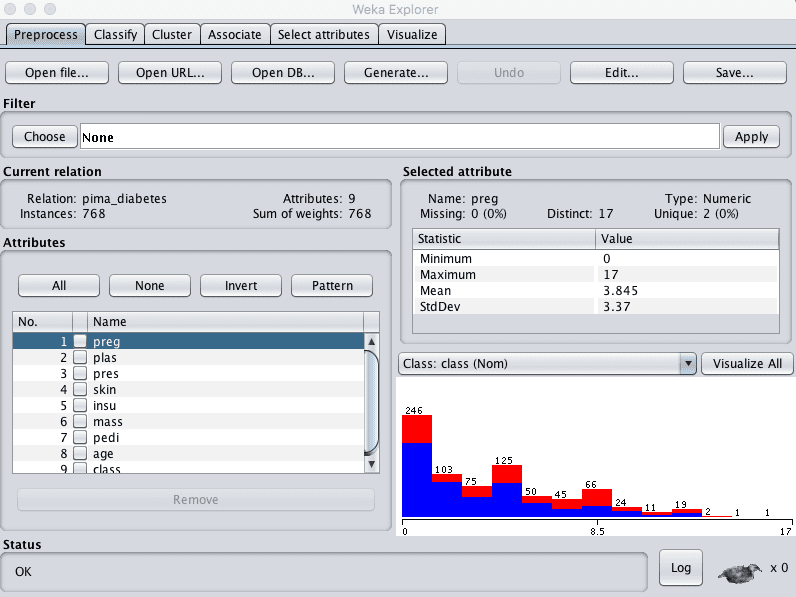
Weka Explorer 加载糖尿病数据集
3. 单击“Filter”的“Choose”按钮,然后选择 Discretize,它位于 unsupervised.attribute.Discretize 下。
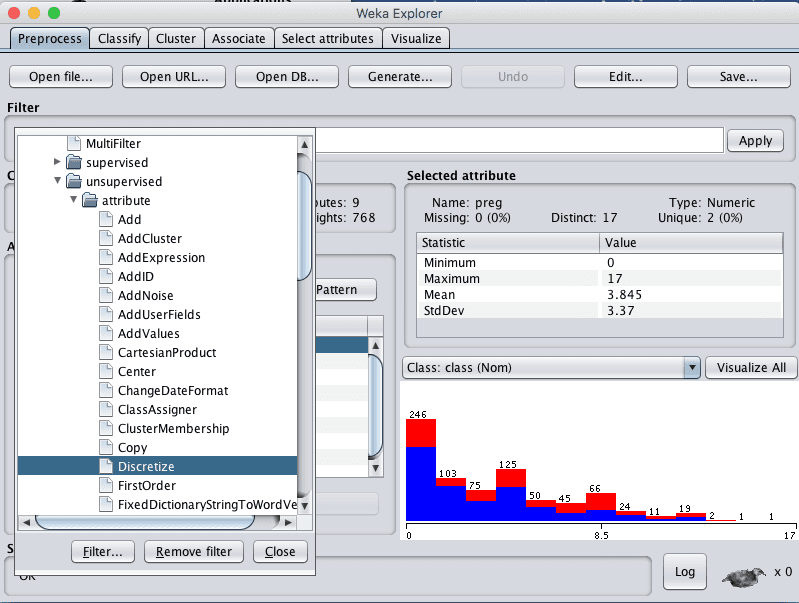
Weka 选择 Discretize 数据过滤器
4. 单击过滤器进行配置。您可以选择要离散化的属性索引,默认是离散化所有属性,在本例中也是如此。单击“OK”按钮。
5. 单击“Apply”按钮应用过滤器。
您可以单击每个属性,在“Selected attribute”窗口中查看详细信息,以确认过滤器已成功应用。
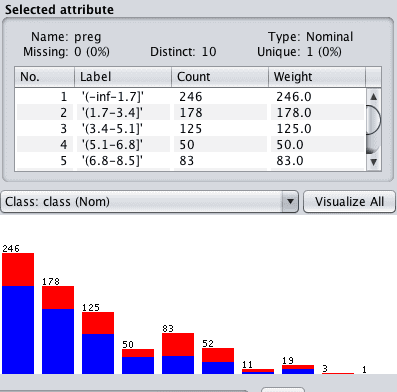
Weka 离散化属性
在处理决策树类算法时,离散化您的实值属性非常有用。当您认为给定属性的值中存在自然分组时,它可能更有用。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
将名义属性转换为哑变量
一些机器学习算法更喜欢使用实值输入,并且不支持名义或有序属性。
名义属性可以转换为实值。这是通过为每个类别创建一个新的二进制属性来完成的。对于具有该值类别的给定实例,将二进制属性设置为 1,并将其他类别的二进制属性设置为 0。此过程称为创建哑变量。
您可以使用 Weka 中的 NominalToBinary 过滤器从名义属性创建哑二进制变量。
下面的配方演示了如何使用 NominalToBinary 过滤器。Contact Lenses 数据集用于演示此过滤器,因为所有属性都是名义属性,并且为创建哑变量提供了充足的机会。
您可以从 UCI 机器学习存储库 下载 Contact Lenses 数据集。您还可以通过加载文件 contact-lenses.arff 来访问 Weka 安装目录下的 data/ 目录中的数据集。
1. 打开 Weka Explorer。
2. 加载 Contact Lenses 数据集。
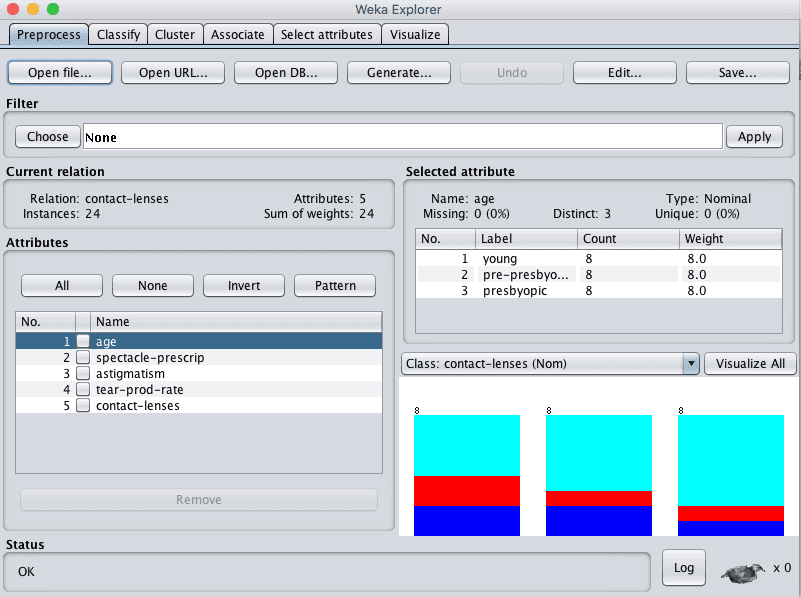
Weka Explorer 加载 Contact Lenses 数据集
3. 单击“Filter”的“Choose”按钮,然后选择 NominalToBinary,它位于 unsupervised.attribute.NominalToBinary 下。
Weka 选择 NominalToBinary 数据过滤器
4. 单击过滤器进行配置。您可以选择要转换为二进制值的属性索引,默认是转换所有属性。将其更改为仅第一个属性。单击“OK”按钮。
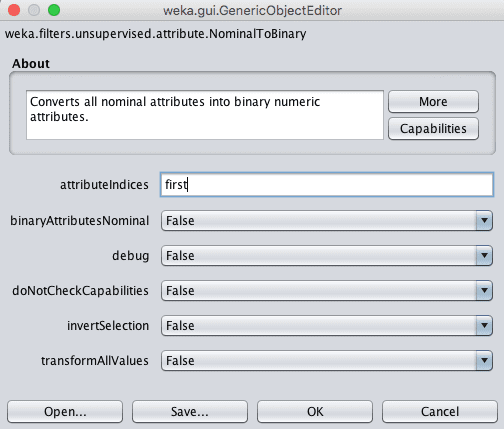
Weka NominalToBinary 数据过滤器配置
5. 单击“Apply”按钮应用过滤器。
查看属性列表将显示 age 属性已被删除,并被三个新的二进制属性替换:age=young、age=pre-presbyopic 和 age=presbyopic。
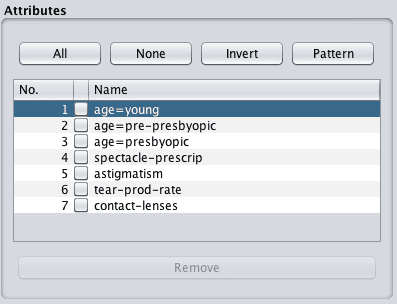
Weka 名义属性转换为哑变量
创建哑变量对于不支持名义输入变量的技术(如线性回归和逻辑回归)很有用。它也可能在 k-近邻和人工神经网络等技术中有用。
总结
在本帖中,您了解了如何转换机器学习数据以满足不同机器学习算法的期望。
具体来说,你学到了:
- 如何将实值输入属性转换为称为离散化的名义属性。
- 如何将分类输入变量转换为多个称为哑变量的二进制输入属性。
- 建模数据时何时使用离散化和哑变量。
您对数据转换或本帖有任何疑问吗?在评论中提问,我会尽力回答。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






离散化和 Numeric To Nominal 之间有什么区别?
在我看来它们听起来一样。
Discretize 会根据 bin 的数量 (n) 来离散化值。Weka 将简单地将值的范围分成 n 个子集,并将子集的值分配给实例。这是在您的属性是真正连续变量的情况下。
Numeric To Nominal 是将一些数值转换为名义变量,如果该属性有少量唯一值。例如,如果您有一个 ID 属性可以将数据集聚类成几个子集,那么将其转换为名义属性而不是将其视为数字可能更明智。这适用于不是真正连续但由于是数字而被 Weka 视为数值的属性。
非常有帮助!
你好。
我想为 arff 文件中的类属性赋予不同的数值。
值:3.4, 4.5, 3.3 等,我该如何输入?
我可以知道格式吗?
如果您想预测数值,这被称为回归而不是分类。
也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-classification-and-regression
有可能通过 Weka 对足球运动员进行排名吗?
我有一个包含数据的数据库,例如身高、体重、速度、力量、敏捷性、踢球偏好、声誉等。
您想知道使用哪种技术进行排名吗?
另一个问题……名义数字转换如何可能?
也许可以。
也许使用评分算法会更容易,例如
https://en.wikipedia.org/wiki/Elo_rating_system
如何将日期值离散化为按年份而不是等宽?
取决于您的数据。
您好,非常感谢您的教程。有没有办法将我的输出类别从数字转换为二进制名义?我的产品评论数据集评分范围是 1-10,我想使用 Weka 来区分正面(1-5)和负面(6-10),同时考虑评分的排名。谢谢!
是的,也许有一个数据过滤器可以执行此操作。抱歉,我没有实际的示例。
您好,感谢您的教程。我的数据集有 10 个类别,我想在 Weka 中构建多类别 MLP 模型。我想预测每个类别的概率作为网络的输出。为此,我将我的属性列转换为虚拟列,但在 Weka 中无法将其选为 train_y 数据。如何解决?
不确定,抱歉。
如何在 Weka 中将字符串属性转换为数字属性??
例如 -
如果有三种虹膜疾病类别 - Iris-setosa、Iris-versicolor、Iris-virginica
如果我们想将其转换为数字类型。
......在 python 中像 toarray() 一样编号
我相信 ARFF 格式会帮助您正确定义分类变量以在 Weka 中使用。
https://machinelearning.org.cn/load-csv-machine-learning-data-weka/
可以更改 Weka 代码以产生略有不同的结果吗?
当然可以。
谢谢,非常有帮助。
不客气。