梯度提升决策树存在一个问题,即它们学习速度快,并且容易过拟合训练数据。
减慢梯度提升模型学习速度的一种有效方法是使用学习率,也称为收缩率(在XGBoost文档中为eta)。
在这篇文章中,你将了解学习率在梯度提升中的作用,以及如何使用Python中的XGBoost库在你的机器学习问题上调整学习率。
阅读本文后,您将了解
- 学习率对梯度提升模型的影响。
- 如何在你的机器学习问题上调整学习率。
- 如何调整你的问题上提升树的数量和学习率之间的权衡。
通过我的新书《XGBoost With Python》启动您的项目,其中包括所有示例的分步教程和 Python 源代码文件。
让我们开始吧。
- 2017 年 1 月更新:已更新以反映 scikit-learn API 0.18.1 版本中的更改。

在 Python 中使用 XGBoost 调整梯度提升的学习率
图片由Robert Hertel拍摄,保留部分权利。
在 Python 中使用 XGBoost 需要帮助吗?
参加我的免费 7 天电子邮件课程,探索 xgboost(含示例代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
使用学习率减慢梯度提升的学习速度
梯度提升涉及顺序地创建和向模型添加树。
创建新树以纠正现有树序列预测中的残差错误。
结果是模型可以快速拟合,然后过拟合训练数据集。
一种减慢梯度提升模型学习速度的技术是,在向模型添加新树时,对新树的修正应用一个权重因子。
这个权重被称为收缩因子或学习率,具体取决于文献或工具。
朴素梯度提升与带有收缩的梯度提升相同,其中收缩因子设置为1.0。将值设置为小于1.0的效果是,每棵添加到模型的树进行的修正更少。这反过来导致必须向模型添加更多的树。
通常使用0.1到0.3范围内的小值,以及小于0.1的值。
让我们研究学习率对标准机器学习数据集的影响。
问题描述:Otto 数据集
在本教程中,我们将使用 Otto Group 产品分类挑战赛 数据集。
此数据集可从Kaggle免费获取(你需要注册Kaggle才能下载此数据集)。你可以从数据页面下载训练数据集 train.csv.zip,并将解压后的 train.csv 文件放入你的工作目录。
此数据集描述了超过 61,000 种产品在 10 个产品类别(例如时尚、电子产品等)中的 93 个模糊细节。输入属性是某种不同事件的计数。
目标是为新产品提供10个类别的概率数组预测,模型使用多类别对数损失(也称为交叉熵)进行评估。
这项竞赛于2015年5月完成,由于大量的样本、问题的难度以及几乎不需要数据准备(除了将字符串类别变量编码为整数),这个数据集对XGBoost来说是一个很好的挑战。
在XGBoost中调整学习率
使用scikit-learn封装器创建XGBoost梯度提升模型时,可以通过设置 learning_rate 参数来控制添加到模型中的新树的权重。
我们可以使用scikit-learn中的网格搜索功能来评估使用不同学习率值训练梯度提升模型对对数损失的影响。
我们将把树的数量保持在默认的100不变,并在Otto数据集上评估一系列标准学习率值。
|
1 |
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3] |
将测试6种不同学习率,每种变体将使用10折交叉验证进行评估,这意味着总共有6×10或60个XGBoost模型需要训练和评估。
将打印每个学习率的对数损失,以及导致最佳性能的值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# XGBoost在Otto数据集上,调整learning_rate from pandas import read_csv from xgboost import XGBClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import LabelEncoder import matplotlib matplotlib.use('Agg') from matplotlib import pyplot # 加载数据 data = read_csv('train.csv') dataset = data.values # 将数据拆分为 X 和 y X = dataset[:,0:94] y = dataset[:,94] # 将字符串类值编码为整数 label_encoded_y = LabelEncoder().fit_transform(y) # 网格搜索 model = XGBClassifier() learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3] param_grid = dict(learning_rate=learning_rate) kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold) grid_result = grid_search.fit(X, label_encoded_y) # 总结结果 print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) # 绘图 pyplot.errorbar(learning_rate,means, yerr=stds) pyplot.title("XGBoost learning_rate vs Log Loss") pyplot.xlabel('learning_rate') pyplot.ylabel('Log Loss') pyplot.savefig('learning_rate.png') |
注意:由于算法或评估过程的随机性,或数值精度的差异,你的结果可能会有所不同。考虑运行几次示例并比较平均结果。
运行此示例将打印最佳结果以及每个评估学习率的对数损失。
|
1 2 3 4 5 6 7 |
最佳结果:-0.001156,使用{'learning_rate': 0.2} -2.155497 (0.000081) 伴随: {'learning_rate': 0.0001} -1.841069 (0.000716) 伴随: {'learning_rate': 0.001} -0.597299 (0.000822) 伴随: {'learning_rate': 0.01} -0.001239 (0.001730) 伴随: {'learning_rate': 0.1} -0.001156 (0.001684) 伴随: {'learning_rate': 0.2} -0.001158 (0.001666) 伴随: {'learning_rate': 0.3} |
有趣的是,我们看到最佳学习率是0.2。
这是一个较高的学习率,这表明默认的100棵树可能太少,需要增加。
我们还可以绘制学习率对(反向)对数损失分数的影响,尽管所选学习率值的对数10类分布意味着大多数都被压在图的左侧,接近零。
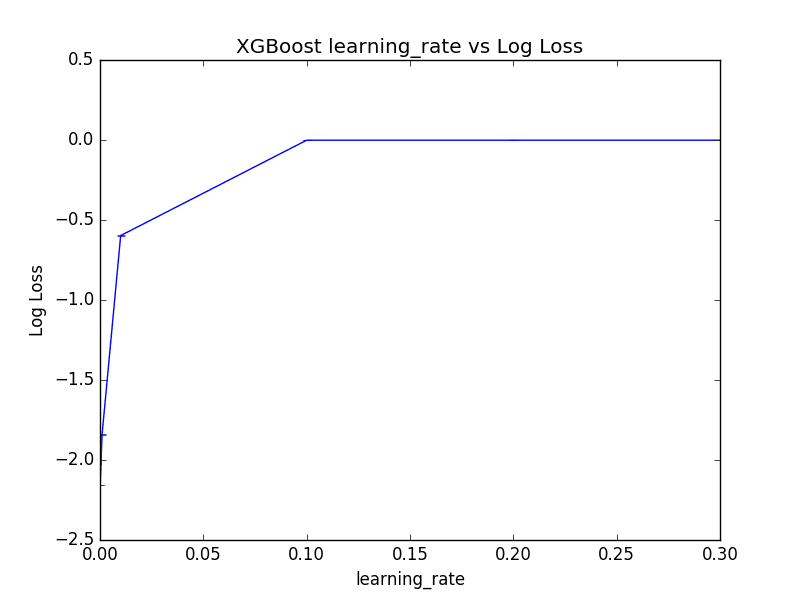
调整XGBoost中的学习率
接下来,我们将研究在改变学习率的同时改变树的数量。
在XGBoost中调整学习率和树的数量
较小的学习率通常需要向模型添加更多的树。
我们可以通过评估一组参数对来探索这种关系。决策树的数量将从100到500变化,学习率将以log10比例从0.0001到0.1变化。
|
1 2 |
n_estimators = [100, 200, 300, 400, 500] learning_rate = [0.0001, 0.001, 0.01, 0.1] |
有5种不同n_estimators和4种不同learning_rate。每个组合将使用10折交叉验证进行评估,因此总共需要训练和评估4x5x10或200个XGBoost模型。
预期是,对于给定的学习率,性能会随着树的数量增加而改善,然后趋于平稳。完整的代码清单如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# XGBoost在Otto数据集上,调整学习率和n_estimators from pandas import read_csv from xgboost import XGBClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import LabelEncoder import matplotlib matplotlib.use('Agg') from matplotlib import pyplot import numpy # 加载数据 data = read_csv('train.csv') dataset = data.values # 将数据拆分为 X 和 y X = dataset[:,0:94] y = dataset[:,94] # 将字符串类值编码为整数 label_encoded_y = LabelEncoder().fit_transform(y) # 网格搜索 model = XGBClassifier() n_estimators = [100, 200, 300, 400, 500] learning_rate = [0.0001, 0.001, 0.01, 0.1] param_grid = dict(learning_rate=learning_rate, n_estimators=n_estimators) kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold) grid_result = grid_search.fit(X, label_encoded_y) # 总结结果 print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) # 绘制结果 scores = numpy.array(means).reshape(len(learning_rate), len(n_estimators)) for i, value in enumerate(learning_rate): pyplot.plot(n_estimators, scores[i], label='learning_rate: ' + str(value)) pyplot.legend() pyplot.xlabel('n_estimators') pyplot.ylabel('Log Loss') pyplot.savefig('n_estimators_vs_learning_rate.png') |
注意:由于算法或评估过程的随机性,或数值精度的差异,你的结果可能会有所不同。考虑运行几次示例并比较平均结果。
运行该示例将打印最佳组合以及每个评估对的对数损失。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
最佳结果:-0.001152,使用{'n_estimators': 300, 'learning_rate': 0.1} -2.155497 (0.000081) 伴随: {'n_estimators': 100, 'learning_rate': 0.0001} -2.115540 (0.000159) 伴随: {'n_estimators': 200, 'learning_rate': 0.0001} -2.077211 (0.000233) 伴随: {'n_estimators': 300, 'learning_rate': 0.0001} -2.040386 (0.000304) 伴随: {'n_estimators': 400, 'learning_rate': 0.0001} -2.004955 (0.000373) 伴随: {'n_estimators': 500, 'learning_rate': 0.0001} -1.841069 (0.000716) 伴随: {'n_estimators': 100, 'learning_rate': 0.001} -1.572384 (0.000692) 伴随: {'n_estimators': 200, 'learning_rate': 0.001} -1.364543 (0.000699) 伴随: {'n_estimators': 300, 'learning_rate': 0.001} -1.196490 (0.000713) 伴随: {'n_estimators': 400, 'learning_rate': 0.001} -1.056687 (0.000728) 伴随: {'n_estimators': 500, 'learning_rate': 0.001} -0.597299 (0.000822) 伴随: {'n_estimators': 100, 'learning_rate': 0.01} -0.214311 (0.000929) 伴随: {'n_estimators': 200, 'learning_rate': 0.01} -0.080729 (0.000982) 伴随: {'n_estimators': 300, 'learning_rate': 0.01} -0.030533 (0.000949) 伴随: {'n_estimators': 400, 'learning_rate': 0.01} -0.011769 (0.001071) 伴随: {'n_estimators': 500, 'learning_rate': 0.01} -0.001239 (0.001730) 伴随: {'n_estimators': 100, 'learning_rate': 0.1} -0.001153 (0.001702) 伴随: {'n_estimators': 200, 'learning_rate': 0.1} -0.001152 (0.001704) 伴随: {'n_estimators': 300, 'learning_rate': 0.1} -0.001153 (0.001708) 伴随: {'n_estimators': 400, 'learning_rate': 0.1} -0.001153 (0.001708) 伴随: {'n_estimators': 500, 'learning_rate': 0.1} |
我们可以看到,观察到的最佳结果是学习率为0.1,有300棵树。
从原始数据和较小的负对数损失结果中很难看出趋势。下面是每个学习率作为系列图,显示对数损失性能随树的数量变化的情况。
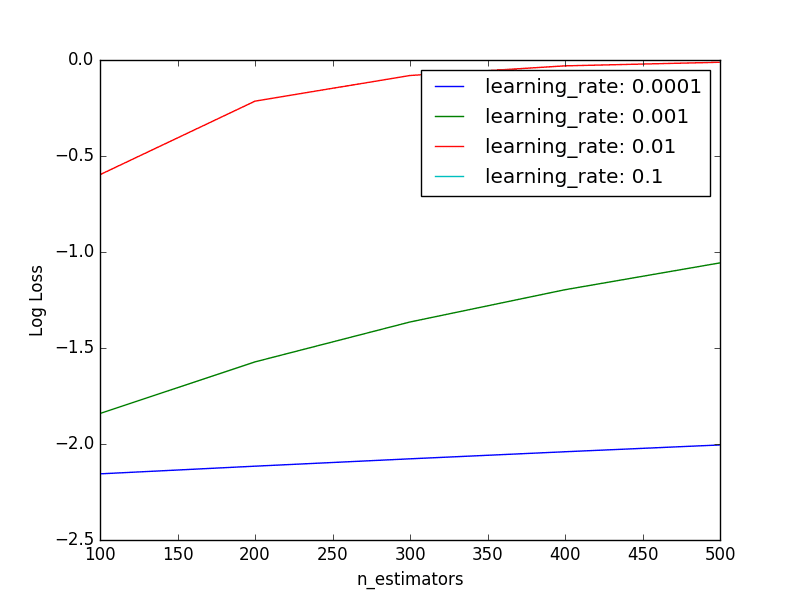
调整XGBoost中的学习率和树的数量
我们可以看到预期的普遍趋势是,性能(倒置的对数损失)随着树的数量增加而提高。
对于较小的学习率,性能通常较差,这表明可能需要更多的树。我们可能需要将树的数量增加到数千棵,这可能会带来相当高的计算成本。
由于图的y轴比例较大,learning_rate=0.1的结果被遮挡了。我们可以提取learning_rate=0.1的性能度量并直接绘制它们。
|
1 2 3 4 5 6 7 8 9 |
# 绘制learning_rate=0.1的性能 from matplotlib import pyplot n_estimators = [100, 200, 300, 400, 500] loss = [-0.001239, -0.001153, -0.001152, -0.001153, -0.001153] pyplot.plot(n_estimators, loss) pyplot.xlabel('n_estimators') pyplot.ylabel('Log Loss') pyplot.title('XGBoost learning_rate=0.1 n_estimators vs Log Loss') pyplot.show() |
运行此代码显示,随着树的数量增加,性能会提高,然后在大约400到500棵树的范围内趋于平稳。
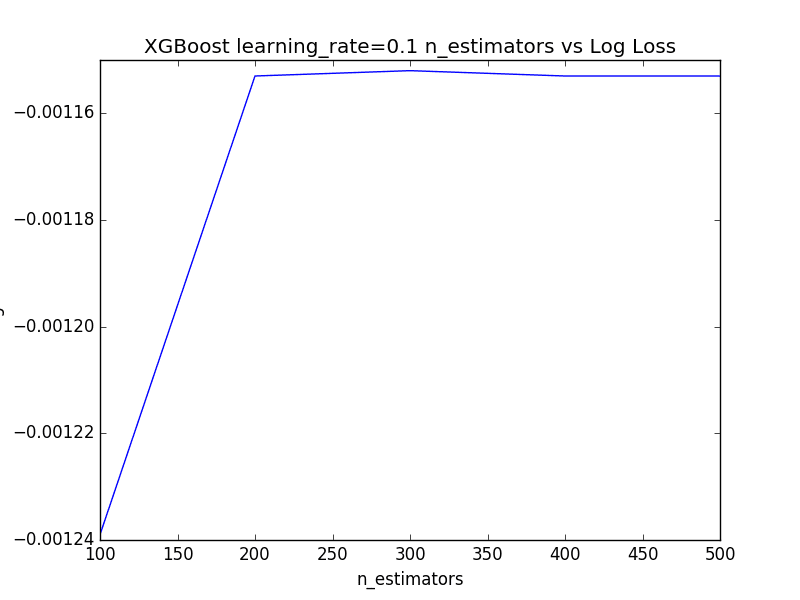
XGBoost中学习率为0.1且树数量变化的图
总结
在这篇文章中,你了解了在梯度提升模型中加权新树的影响,称为收缩或学习率。
具体来说,你学到了:
- 添加学习率旨在减缓模型对训练数据的适应速度。
- 如何评估你的机器学习问题上的学习率范围。
- 如何评估你的问题上同时改变树的数量和学习率的关系。
你对梯度提升中的收缩或这篇文章有任何疑问吗?请在评论中提出你的问题,我将尽力回答。
发现赢得竞赛的算法!

在几分钟内开发您自己的 XGBoost 模型
...只需几行 Python 代码
在我的新电子书中探索如何实现
使用 Python 实现 XGBoost
它涵盖了自学教程,例如:
算法基础、缩放、超参数等等……
将 XGBoost 的强大功能带入您自己的项目
跳过学术理论。只看结果。





 Ensemble in Python")
你好!“调整学习率”的第一部分需要多长时间才能运行?你在什么系统上运行的?谢谢。
我在大型AWS实例上运行了这些示例,例如
https://machinelearning.org.cn/train-xgboost-models-cloud-amazon-web-services/
抱歉,我不记得花了多长时间。我认为没有任何一个示例花费超过几个小时。
太棒了!谢谢提供信息!
“在XGBoost中调整学习率和树的数量”这部分对我来说运行时间更长(已经运行了6小时但仍在运行)。
哎呀,我想我可能在拥有32个核心的大型AWS实例上运行了它。
学习率的用途是什么?它代表什么?你能给我一个直观的解释吗?
学习率使提升过程或多或少保守,例如根据之前添加的树的结果进行或多或少的纠正或提升。
优秀且有用的文章。我将其应用于我的数据,它帮助我完美地选择了学习率和n_estimators,从而大大改善了结果。
谢谢,
谢谢,干得好!
CSV文件的第一列是ID,这个特征没用吗?
谢谢你
是的,通常是这样。
如何对调整后的xg_boost模型进行预测?您是否只是将学习率和树的数量作为参数传递给XGBClassifier?您能否也将该代码添加到文章中?
模型拟合后,您可以保存它并开始使用它进行预测。
这被称为创建最终模型,更多信息在此
https://machinelearning.org.cn/train-final-machine-learning-model/
嗨……能否展示一下二元分类问题的梯度提升树是如何构建的?我很好奇树是如何精确构建的……使用什么函数来确定分裂……以及每棵树的结果是如何相加来计算预测类别的。如果可能的话……请使用简单的例子……学习率为0.1……我熟悉单一CART树……但到目前为止,我仍然不理解梯度提升树。直到最近我才意识到,对于梯度提升树,树是使用回归树构建的……分类是使用概率值转换的。如果你能按要求展示一个例子,我将非常感激……谢谢
感谢您的建议。
嘿,你能告诉我为什么在GB中我们已经有了基学习器的超参数,甚至已经通过梯度最小化技术预先计算了γ m,为什么我们还要使用学习率或收缩参数呢?这个学习率如何增加更多的价值?
这是一个收缩因子,文章中已经解释过了。或许应该重读一下?
除了使用离散值作为学习率,还可以尝试使用上下限的方法。因此,类似于 learning_rate = scipy.stats.uniform(lower_bound, upper_bound) 的方法。
谢谢。
你好,我这里有个问题。
我读了一些论文,似乎我们需要在拟合基学习器之后找到最佳学习率(最小化我们的损失函数)。这是否意味着在Python库中,我们不需要找到最佳学习率,而只需将其简单地设置为一个常数?
没关系。我这里滥用了符号。
不客气。
调整参数后如何评估准确率、精确度和召回率
您可以使用scikit-learn库计算任何您想要的指标
https://scikit-learn.cn/stable/modules/classes.html#module-sklearn.metrics
网格搜索
执行网格搜索后,我得到了如下结果
GridSearchCV(cv=StratifiedKFold(n_splits=5, random_state=7, shuffle=True),
error_score=’raise-deprecating’,
estimator=XGBClassifier(base_score=0.5, booster=’gbtree’, colsample_bylevel=1,
colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,
max_depth=3, min_child_weight=1, missing=None, n_estimators=100,
n_jobs=1, nthread=None, objective=’binary:logistic’, random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1),
fit_params=None, iid=’warn’, n_jobs=-1,
param_grid={‘learning_rate’: [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]},
pre_dispatch=’2*n_jobs’, refit=True, return_train_score=’warn’,
scoring=’neg_log_loss’, verbose=0)
但是当我尝试执行“grid_result = grid_search.fit(X, label_encoded_y)”时,它会显示此错误,你能提供解决方案吗?
JoblibValueError 回溯 (最近一次调用在最后)
in ()
----> 1 grid_result = grid_search.fit(X, label_encoded_y)
/home/gopal/.local/lib/python2.7/site-packages/sklearn/model_selection/_search.pyc in fit(self, X, y, groups, **fit_params)
721 返回结果容器[0]
722
--> 723 self._run_search(evaluate_candidates)
724
725 结果 = 结果容器[0]
/home/gopal/.local/lib/python2.7/site-packages/sklearn/model_selection/_search.pyc in _run_search(self, evaluate_candidates)
1190 def _run_search(self, evaluate_candidates)
1191 """搜索param_grid中的所有候选者"""
--> 1192 evaluate_candidates(ParameterGrid(self.param_grid))
1193
1194
/home/gopal/.local/lib/python2.7/site-packages/sklearn/model_selection/_search.pyc in evaluate_candidates(candidate_params)
710 用于参数,(训练,测试)
711 在产品(candidate_params,
--> 712 cv.split(X, y, groups)))
713
714 all_candidate_params.extend(candidate_params)
/home/gopal/.local/lib/python2.7/site-packages/sklearn/externals/joblib/parallel.pyc in __call__(self, iterable)
932
933 with self._backend.retrieval_context()
--> 934 self.retrieve()
935 # 确保我们收到最后一条消息,告知我们已完成
936 elapsed_time = time.time() - self._start_time
/home/gopal/.local/lib/python2.7/site-packages/sklearn/externals/joblib/parallel.pyc in retrieve(self)
860 this_report = format_outer_frames(context=10,
861 stack_start=1)
--> 862 raise exception.unwrap(this_report)
863 else
864 raise
JoblibValueError: JoblibValueError
很抱歉听到这个消息,我在这里有一些建议。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨 Jason
对于网格搜索交叉验证,我得到了 RMSE=1066, MAE=749.49,但对于普通交叉验证,RMSE=1052, MAE=739.03。因此我很困惑,为什么在调整参数后,big mart数据集的RMSE值仍然高于普通交叉验证的RMSE值。请在这方面给我指导,并建议我如何根据RMSE和MAE值计算准确率。
这种差异可能是由于学习算法的随机性。
也许可以尝试重复交叉验证以获得更稳定的评估?
嗨 Jason
根据我的知识,对数损失不过是交叉熵,其范围是0到1,但这里你的图表每次都显示对数损失的负值,即对数损失与学习率的关系图以及其他图表。此外,我也得到了相同的对数损失负值,请澄清我为什么得到对数损失的负值?
是的,sklearn会反转损失分数,使所有分数最大化而不是最小化。
你也会在负均方误差中看到这种情况。
为什么会这样呢,先生,如果损失分数最大化,我认为模型就不会被视为好模型
你具体指的是什么?
我的意思是,如果sklearn中的对数损失分数最大化而不是最小化,我如何判断模型是好是坏。另外,对数损失的负值有什么意义。
如果使用准确率等指标评估模型,并与朴素模型进行比较,如果其表现更好,则该模型具有技能。
这会有帮助
https://machinelearning.org.cn/faq/single-faq/how-to-know-if-a-model-has-good-performance
学习率似乎有一个临界点,高于该点您会得到0到1之间的正常预测范围,但低于该点,您会从XGBoost获得有限的预测范围(例如,所有记录都在.49和.51之间)。您是否注意到这一点,能否解释发生了什么?较低的学习率和有限的预测范围会导致较低的精度和召回率,但在每种情况下,验证结果中前3个十分位数的捕获率都好得多。
真有意思。
不,我以前没见过这种情况。可能是模型未能收敛。
关于学习率背后的数学原理有什么见解吗?0.1的值是否像一个权重?
它控制模型更新量或给定树对预测的贡献。较小的值意味着贡献较少,很可能需要更多的树。
对于给定数据集,请使用试错法进行配置。
XGBoost的表现比神经网络好吗?
取决于具体的数据集。
对于表格数据,是的,通常是这样。
嗨,Jason,
在Kaggle竞赛笔记本中,人们将XGB参数调整到4位小数,例如
params = {'classify__estimator__colsample_bytree': 0.6522,
'classify__estimator__gamma': 3.6975,
'classify__estimator__learning_rate': 0.0503,
'classify__estimator__max_delta_step': 2.0706,
'classify__estimator__max_depth': 10,
'classify__estimator__min_child_weight': 31.5800,
'classify__estimator__n_estimators': 166,
'classify__estimator__subsample': 0.8639
}
我能知道这是怎么做到的吗?
我发现一些使用hyperopt库的方法,但是与hyperopt和gridsearch之间的调整结果相比,它的准确性并不高,gridsearch的准确性更高。
不明白为什么hyperopt的准确率较低
hyperopt只是另一种搜索可能超参数空间的方法,它不是“最佳”方法。鉴于“没有免费午餐定理”,没有“最佳”搜索方法。
https://machinelearning.org.cn/faq/single-faq/what-is-the-no-free-lunch-theorem
是的,如果您使用一个好的网格,这可能会发生。
抱歉,我不太明白这个问题,在我看来好像没问题。
你到底是什么意思,能详细说明一下吗?
谢谢Jason,明白了
嗨 Jason,
我的老师在我们的课堂示例中实际使用了这个示例和完全相同的设置。我现在正尝试将(完全相同的设置)应用于我自己的模型,但我遇到了错误,提示“
ValueError:估算器“的learning_rate参数无效”(我已在下面发布了完整的错误)。这是什么意思?当我第一次遇到错误时,我使用的是您上面列出的n_estimator和learning rate的数字。然后我尝试增加学习率,但我仍然得到相同的错误。
—————————————————————————
_RemoteTraceback 回溯 (最近一次调用在最后)
_RemoteTraceback
"""
回溯(最近一次调用)
文件 "C:\Users\cyrra\anaconda3\lib\site-packages\joblib\externals\loky\process_executor.py", 第 431 行, in _process_worker
r = call_item()
文件 "C:\Users\cyrra\anaconda3\lib\site-packages\joblib\externals\loky\process_executor.py", 第 285 行, in __call__
return self.fn(*self.args, **self.kwargs)
文件 "C:\Users\cyrra\anaconda3\lib\site-packages\joblib\_parallel_backends.py", 第 595 行, in __call__
return self.func(*args, **kwargs)
文件 "C:\Users\cyrra\anaconda3\lib\site-packages\joblib\parallel.py", 第 262 行, in __call__
return [func(*args, **kwargs)
文件 "C:\Users\cyrra\anaconda3\lib\site-packages\joblib\parallel.py", 第 262 行, in
return [func(*args, **kwargs)
文件 "C:\Users\cyrra\anaconda3\lib\site-packages\sklearn\utils\fixes.py", 第 222 行, in __call__
return self.function(*args, **kwargs)
文件 "C:\Users\cyrra\anaconda3\lib\site-packages\sklearn\model_selection\_validation.py", 第 581 行, in _fit_and_score
estimator = estimator.set_params(**cloned_parameters)
文件 "C:\Users\cyrra\anaconda3\lib\site-packages\sklearn\base.py", 第 230 行, in set_params
raise ValueError('Invalid parameter %s for estimator %s. '
ValueError: 估算器 GridSearchCV(cv=StratifiedKFold(n_splits=4, random_state=7, shuffle=True),
estimator=XGBClassifier(base_score=0.5, booster='gbtree',
colsample_bylevel=1, colsample_bynode=1,
colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain',
interaction_constraints='',
learning_rate=0.300000012,
max_delta_step=0, max_depth=6,
min_child_weight=1, missing=nan,
monotone_constraints='()',
n_estimators=100, n_jobs=8,
num_parallel_tree=1,
objective='multi:softprob', random_state=0,
reg_alpha=0, reg_lambda=1,
scale_pos_weight=None, subsample=1,
tree_method='exact', validate_parameters=1,
verbosity=None),
n_jobs=-1,
param_grid={'max_depth': [2, 4, 6, 8],
'n_estimators': [50, 100, 150, 200]},
scoring='neg_log_loss', verbose=1) 的参数 learning_rate 无效。请使用 `estimator.get_params().keys()` 检查可用参数列表。
"""
上述异常是以下异常的直接原因
ValueError 回溯 (最近一次调用)
in
----> 1 grid_result_m = grid_search_m.fit(X, ym)
~\anaconda3\lib\site-packages\sklearn\utils\validation.py in inner_f(*args, **kwargs)
61 extra_args = len(args) - len(all_args)
62 if extra_args 63 return f(*args, **kwargs)
64
65 # extra_args > 0
~\anaconda3\lib\site-packages\sklearn\model_selection\_search.py in fit(self, X, y, groups, **fit_params)
839 return results
840
----> 841 self._run_search(evaluate_candidates)
842
843 # multimetric is determined here because in the case of a callable
~\anaconda3\lib\site-packages\sklearn\model_selection\_search.py in _run_search(self, evaluate_candidates)
1286 def _run_search(self, evaluate_candidates)
1287 """搜索param_grid中的所有候选者"""
----> 1288 evaluate_candidates(ParameterGrid(self.param_grid))
1289
1290
~\anaconda3\lib\site-packages\sklearn\model_selection\_search.py in evaluate_candidates(candidate_params, cv, more_results)
793 n_splits, n_candidates, n_candidates * n_splits))
794
----> 795 out = parallel(delayed(_fit_and_score)(clone(base_estimator),
796 X, y,
797 train=train, test=test,
~\anaconda3\lib\site-packages\joblib\parallel.py in __call__(self, iterable)
1052
1053 with self._backend.retrieval_context()
----> 1054 self.retrieve()
1055 # Make sure that we get a last message telling us we are done
1056 elapsed_time = time.time() - self._start_time
~\anaconda3\lib\site-packages\joblib\parallel.py in retrieve(self)
931 try
932 if getattr(self._backend, 'supports_timeout', False)
----> 933 self._output.extend(job.get(timeout=self.timeout))
934 else
935 self._output.extend(job.get())
~\anaconda3\lib\site-packages\joblib\_parallel_backends.py in wrap_future_result(future, timeout)
540 AsyncResults.get from multiprocessing."""
541 try
----> 542 return future.result(timeout=timeout)
543 except CfTimeoutError as e
544 raise TimeoutError from e
~\anaconda3\lib\concurrent\futures\_base.py in result(self, timeout)
437 raise CancelledError()
438 elif self._state == FINISHED
----> 439 return self.__get_result()
440 else
441 raise TimeoutError()
~\anaconda3\lib\concurrent\futures\_base.py in __get_result(self)
386 def __get_result(self)
387 if self._exception
----> 388 raise self._exception
389 else
390 return self._result
ValueError: 估算器 GridSearchCV(cv=StratifiedKFold(n_splits=4, random_state=7, shuffle=True),
estimator=XGBClassifier(base_score=0.5, booster='gbtree',
colsample_bylevel=1, colsample_bynode=1,
colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain',
interaction_constraints='',
learning_rate=0.300000012,
max_delta_step=0, max_depth=6,
min_child_weight=1, missing=nan,
monotone_constraints='()',
n_estimators=100, n_jobs=8,
num_parallel_tree=1,
objective='multi:softprob', random_state=0,
reg_alpha=0, reg_lambda=1,
scale_pos_weight=None, subsample=1,
tree_method='exact', validate_parameters=1,
verbosity=None),
n_jobs=-1,
param_grid={'max_depth': [2, 4, 6, 8],
'n_estimators': [50, 100, 150, 200]},
scoring='neg_log_loss', verbose=1) 的参数 learning_rate 无效。请使用 `estimator.get_params().keys()` 检查可用参数列表。
很抱歉听到你遇到麻烦,也许这些提示会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我对我选择最佳学习率的方式感到困惑。在图中绘制了对数损失。我们希望最小化损失。由于对数是单调变换,这意味着我们也希望选择使对数损失最小化的学习率值,因此最佳学习率实际上是0.0001。这也支持了XGBoost在学习率尽可能小的情况下泛化能力更好的理论。
嗨,多姆……以下内容可能对你感兴趣
https://towardsdatascience.com/selecting-optimal-parameters-for-xgboost-model-training-c7cd9ed5e45e