梯度提升涉及决策树的顺序创建和添加,每个决策树都试图纠正之前学习器所犯的错误。
这就提出了一个问题,即在梯度提升模型中要配置多少棵树(弱学习器或估计器),以及每棵树应该有多大。
在这篇文章中,您将发现如何设计一个系统的实验来选择您的问题中使用的决策树的数量和大小。
阅读本文后,您将了解
- 如何评估向XGBoost模型添加更多决策树的效果。
- 如何评估在XGBoost模型中创建更大的决策树的效果。
- 如何研究问题中树的数量和深度之间的关系。
通过我的新书《XGBoost With Python》启动您的项目,其中包括所有示例的分步教程和 Python 源代码文件。
让我们开始吧。
- 2017 年 1 月更新:已更新以反映 scikit-learn API 0.18.1 版本中的更改。

如何在 Python 中使用 XGBoost 调整决策树的数量和大小
图片来源:USFWSmidwest,保留部分权利。
在 Python 中使用 XGBoost 需要帮助吗?
参加我的免费 7 天电子邮件课程,探索 xgboost(含示例代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
问题描述:Otto 数据集
在本教程中,我们将使用 Otto Group 产品分类挑战赛 数据集。
该数据集可从Kaggle免费获取(您需要注册Kaggle才能下载此数据集)。您可以从数据页面下载训练数据集train.csv.zip,并将解压后的train.csv文件放入您的工作目录中。
此数据集描述了超过 61,000 种产品在 10 个产品类别(例如时尚、电子产品等)中的 93 个模糊细节。输入属性是某种不同事件的计数。
目标是为新产品进行预测,预测结果是每个 10 个类别的概率数组,模型使用多类对数损失(也称为交叉熵)进行评估。
该竞赛于2015年5月完成,该数据集对XGBoost来说是一个很好的挑战,因为它具有非平凡的示例数量、问题的难度以及几乎不需要数据准备(除了将字符串类别变量编码为整数)。
调整XGBoost中决策树的数量
大多数梯度提升实现默认配置相对较少的树,例如数百或数千棵。
一般原因是,在大多数问题上,超出限制添加更多树并不能提高模型的性能。
原因在于提升树模型的构建方式,它是一个顺序过程,每棵新树都试图建模并纠正前面一系列树所犯的错误。很快,模型就会达到收益递减点。
我们可以很容易地在Otto数据集上演示这个收益递减点。
XGBoost模型中的树数量(或轮次)在XGBClassifier或XGBRegressor类的n_estimators参数中指定。XGBoost库中的默认值为100。
使用scikit-learn,我们可以对n_estimators模型参数执行网格搜索,评估从50到350的一系列值,步长为50(50、150、200、250、300、350)。
|
1 2 3 4 5 6 |
# 网格搜索 model = XGBClassifier() n_estimators = range(50, 400, 50) param_grid = dict(n_estimators=n_estimators) kfold = StratifiedKFold(n_splits scoring="neg_log_loss", n_jobs=-1, cv=kfold) result = grid_search.fit(X, label_encoded_y) |
我们可以在Otto数据集上执行此网格搜索,使用10折交叉验证,需要训练60个模型(6种配置 * 10折)。
完整的代码清单如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# Otto数据集上的XGBoost,调整n_estimators from pandas import read_csv from xgboost import XGBClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import LabelEncoder import matplotlib matplotlib.use('Agg') from matplotlib import pyplot # 加载数据 data = read_csv('train.csv') dataset = data.values # 将数据拆分为 X 和 y X = dataset[:,0:94] y = dataset[:,94] # 将字符串类值编码为整数 label_encoded_y = LabelEncoder().fit_transform(y) # 网格搜索 model = XGBClassifier() n_estimators = range(50, 400, 50) param_grid = dict(n_estimators=n_estimators) kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold) grid_result = grid_search.fit(X, label_encoded_y) # 总结结果 print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) # 绘图 pyplot.errorbar(n_estimators, means, yerr=stds) pyplot.title("XGBoost n_estimators vs Log Loss") pyplot.xlabel('n_estimators') pyplot.ylabel('Log Loss') pyplot.savefig('n_estimators.png') |
注意:鉴于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
运行此示例将打印以下结果。
|
1 2 3 4 5 6 7 8 |
最佳值:-0.001152,使用 {'n_estimators': 250} -0.010970 (0.001083) with: {'n_estimators': 50} -0.001239 (0.001730) with: {'n_estimators': 100} -0.001163 (0.001715) with: {'n_estimators': 150} -0.001153 (0.001702) with: {'n_estimators': 200} -0.001152 (0.001702) with: {'n_estimators': 250} -0.001152 (0.001704) with: {'n_estimators': 300} -0.001153 (0.001706) with: {'n_estimators': 350} |
我们可以看到交叉验证对数损失分数是负的。这是因为scikit-learn交叉验证框架将它们倒置了。原因是,在内部,该框架要求所有要优化的度量都必须最大化,而对数损失是一个最小化度量。通过将分数倒置,可以很容易地将其最大化。
最佳树的数量是n_estimators=250,导致对数损失为0.001152,但与n_estimators=200相比,差异并不显著。事实上,如果我们绘制结果,100到350之间的树数量相对差异不大。
下面是显示树的数量与平均(倒置)对数损失之间关系的折线图,标准差以误差条显示。
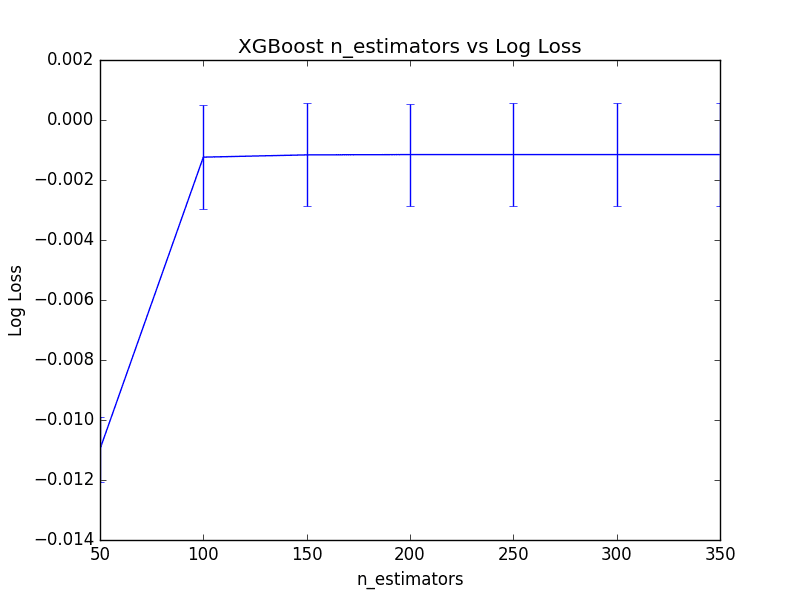
调整XGBoost中的树数量
调整XGBoost中决策树的大小
在梯度提升中,我们可以控制决策树的大小,也称为层数或深度。
浅层树的性能预计会很差,因为它们捕获的问题细节很少,通常被称为弱学习器。深层树通常捕获的问题细节过多,会过度拟合训练数据集,限制了对新数据做出良好预测的能力。
通常,提升算法配置为弱学习器,即层数较少的决策树,有时甚至简单到只有一个根节点,也称为决策桩而不是决策树。
最大深度可以在XGBoost的XGBClassifier和XGBRegressor包装类中通过max_depth参数指定。此参数接受一个整数值,默认值为3。
|
1 |
model = XGBClassifier(max_depth=3) |
我们可以使用scikit-learn中的网格搜索基础设施,在Otto数据集上调整XGBoost的这个超参数。下面我们评估max_depth在1到9之间的奇数值(1、3、5、7、9)。
每个5个配置都使用10折交叉验证进行评估,导致构建了50个模型。完整的代码清单如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# XGBoost在Otto数据集上,调整max_depth from pandas import read_csv from xgboost import XGBClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import LabelEncoder import matplotlib matplotlib.use('Agg') from matplotlib import pyplot # 加载数据 data = read_csv('train.csv') dataset = data.values # 将数据拆分为 X 和 y X = dataset[:,0:94] y = dataset[:,94] # 将字符串类值编码为整数 label_encoded_y = LabelEncoder().fit_transform(y) # 网格搜索 model = XGBClassifier() max_depth = range(1, 11, 2) print(max_depth) param_grid = dict(max_depth=max_depth) kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold, verbose=1) grid_result = grid_search.fit(X, label_encoded_y) # 总结结果 print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) # 绘图 pyplot.errorbar(max_depth, means, yerr=stds) pyplot.title("XGBoost max_depth vs Log Loss") pyplot.xlabel('max_depth') pyplot.ylabel('Log Loss') pyplot.savefig('max_depth.png') |
运行此示例将打印每个max_depth的对数损失。
注意:鉴于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
最佳配置是max_depth=5,导致对数损失为0.001236。
|
1 2 3 4 5 6 |
最佳值:-0.001236,使用 {'max_depth': 5} -0.026235 (0.000898) with: {'max_depth': 1} -0.001239 (0.001730) with: {'max_depth': 3} -0.001236 (0.001701) with: {'max_depth': 5} -0.001237 (0.001701) with: {'max_depth': 7} -0.001237 (0.001701) with: {'max_depth': 9} |
查看对数损失分数的图表,我们可以看到从max_depth=1到max_depth=3有显著跳跃,然后max_depth的其他值性能相当。
尽管在max_depth=5时观察到最佳分数,但值得注意的是,使用max_depth=3或max_depth=7几乎没有实际差异。
这表明在您可以使用网格搜索来找出问题的max_depth上的收益递减点。下面绘制了max_depth值与(倒置)对数损失的图表。
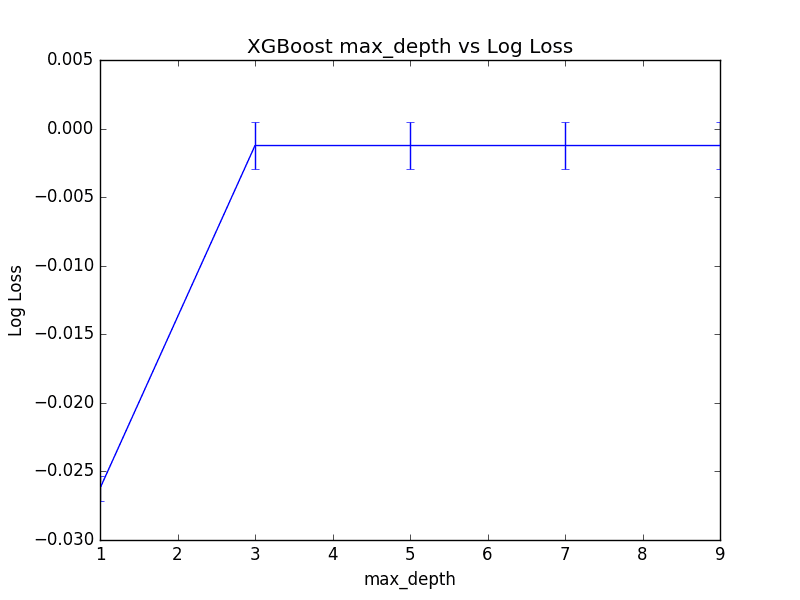
调整XGBoost中的最大树深度
调整XGBoost中树的数量和最大深度
模型中树的数量与每棵树的深度之间存在关系。
我们预计,更深的树将导致模型中所需的树更少,反之,更简单的树(如决策桩)需要更多的树才能达到相似的结果。
我们可以通过评估n_estimators和max_depth配置值的网格来调查这种关系。为了避免评估时间过长,我们将限制评估的总配置值数量。参数的选择旨在揭示关系而不是优化模型。
我们将创建一个包含4个不同n_estimators值(50、100、150、200)和4个不同max_depth值(2、4、6、8)的网格,每个组合将使用10折交叉验证进行评估。总共将训练和评估4*4*10或160个模型。
完整的代码清单如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# Otto数据集上的XGBoost,调整n_estimators和max_depth from pandas import read_csv from xgboost import XGBClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import LabelEncoder import matplotlib matplotlib.use('Agg') from matplotlib import pyplot import numpy # 加载数据 data = read_csv('train.csv') dataset = data.values # 将数据拆分为 X 和 y X = dataset[:,0:94] y = dataset[:,94] # 将字符串类值编码为整数 label_encoded_y = LabelEncoder().fit_transform(y) # 网格搜索 model = XGBClassifier() n_estimators = [50, 100, 150, 200] max_depth = [2, 4, 6, 8] print(max_depth) param_grid = dict(max_depth=max_depth, n_estimators=n_estimators) kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold, verbose=1) grid_result = grid_search.fit(X, label_encoded_y) # 总结结果 print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) # 绘制结果 scores = numpy.array(means).reshape(len(max_depth), len(n_estimators)) for i, value in enumerate(max_depth): pyplot.plot(n_estimators, scores[i], label='depth: ' + str(value)) pyplot.legend() pyplot.xlabel('n_estimators') pyplot.ylabel('Log Loss') pyplot.savefig('n_estimators_vs_max_depth.png') |
注意:鉴于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
运行代码会为每个参数对生成对数损失的列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
最佳值:-0.001141,使用 {'n_estimators': 200, 'max_depth': 4} -0.012127 (0.001130) with: {'n_estimators': 50, 'max_depth': 2} -0.001351 (0.001825) with: {'n_estimators': 100, 'max_depth': 2} -0.001278 (0.001812) with: {'n_estimators': 150, 'max_depth': 2} -0.001266 (0.001796) with: {'n_estimators': 200, 'max_depth': 2} -0.010545 (0.001083) with: {'n_estimators': 50, 'max_depth': 4} -0.001226 (0.001721) with: {'n_estimators': 100, 'max_depth': 4} -0.001150 (0.001704) with: {'n_estimators': 150, 'max_depth': 4} -0.001141 (0.001693) with: {'n_estimators': 200, 'max_depth': 4} -0.010341 (0.001059) with: {'n_estimators': 50, 'max_depth': 6} -0.001237 (0.001701) with: {'n_estimators': 100, 'max_depth': 6} -0.001163 (0.001688) with: {'n_estimators': 150, 'max_depth': 6} -0.001154 (0.001679) with: {'n_estimators': 200, 'max_depth': 6} -0.010342 (0.001059) with: {'n_estimators': 50, 'max_depth': 8} -0.001237 (0.001701) with: {'n_estimators': 100, 'max_depth': 8} -0.001161 (0.001688) with: {'n_estimators': 150, 'max_depth': 8} -0.001153 (0.001679) with: {'n_estimators': 200, 'max_depth': 8} |
我们可以看到,最佳结果是在n_estimators=200和max_depth=4下实现的,这与前两轮独立参数调整中找到的最佳值(n_estimators=250,max_depth=5)相似。
我们可以绘制给定n_estimators下每个max_depth系列之间的关系。
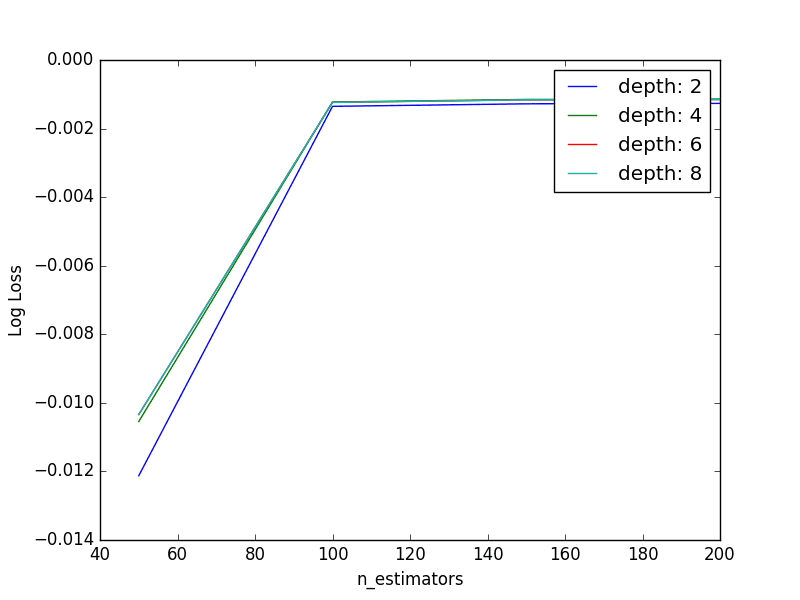
调整XGBoost中的树数量和最大树深度
这些线条重叠,使得难以看清它们之间的关系,但总体而言,我们看到了预期的交互作用。随着树深度的增加,所需的提升树数量减少。
此外,我们预计更深的个体树所提供的增加的复杂性会导致训练数据的过度拟合,这会因拥有更多的树而加剧,从而导致较低的交叉验证分数。我们在这里没有看到这种情况,因为我们的树没有那么深,也没有太多树。探索这种预期留作您可以自行探索的练习。
总结
在这篇文章中,您了解了如何在Python中使用XGBoost进行梯度提升时调整决策树的数量和深度。
具体来说,你学到了:
- 如何调整XGBoost模型中决策树的数量。
- 如何调整XGBoost模型中决策树的深度。
- 如何联合调整XGBoost模型中的树数量和树深度。
您对梯度提升模型中决策树的数量或大小或本文有任何疑问吗?请在评论中提出您的问题,我将尽力回答。
发现赢得竞赛的算法!

在几分钟内开发您自己的 XGBoost 模型
...只需几行 Python 代码
在我的新电子书中探索如何实现
使用 Python 实现 XGBoost
它涵盖了自学教程,例如:
算法基础、缩放、超参数等等……
将 XGBoost 的强大功能带入您自己的项目
跳过学术理论。只看结果。






我喜欢你的教学风格。
我完成了一门课程后会购买你的套餐。
先生,一个小小的拼写错误。(我仔细阅读了每一行)🙂
"This dataset is available fro free"(fro 应为 for)
再次感谢您提供的所有免费内容和简洁的解释。
谢谢Mike,已修复!
嘿,好文章。我有一个疑问。在“使用XGBoostClassifier(参数)运行”和“创建DMatrix,参数列表然后进行xgb.train()”之间有什么区别?
这两种方法会产生相同的结果吗?为什么有两种方法做同样的事情?
我一直使用第二种方法...其中没有n_estimators参数。您使用的是第一种方法。您能解释一下吗??
它们应该给出相同的结果,但我喜欢使用xgboost和sklearn的工具。
关于xgboost的网格搜索教程非常棒。
我想知道如何传递参数booster ='gbtree'或booster='dart'。
这是我的代码:
model = XGBClassifier(booster=’gbtree’,objective=’binary:logistic’)
n_estimators = [50, 100]
max_depth = [2, 3]
learning_rate=[0.05,0.15]
param_grid = dict(max_depth=max_depth, n_estimators=n_estimators, learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=7)
grid_search = GridSearchCV(model, param_grid, scoring=”roc_auc”, n_jobs=1, cv=kfold, verbose=1)
grid_result = grid_search.fit(norm_X_train, y_train)
print(“Best: %f using %s” % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_[‘mean_test_score’]
stds = grid_result.cv_results_[‘std_test_score’]
params = grid_result.cv_results_[‘params’]
TypeError: __init__() got an unexpected keyword argument ‘booster’
我想分别用dart和gbtree训练模型。我该怎么做?
在R中可以轻松完成。在python中显示上述错误。
如何从网格搜索中保存最佳模型?
一旦找到最佳参数集,您就可以使用这些参数训练一个新的最终模型。
嗨,Jason,
感谢分享这一切。我使用GridSearchCV应用了sklearn的XGBoostClassifier,但我发现未经调优的xgboost比调优后能带来更好的准确度和f1分数。
有什么想法这可能是为什么吗?有没有什么原因可能导致这种情况发生?
它可能是过度拟合训练数据。
嗨,Jason,
很棒的文章。
1. 在工业界,当数据科学家使用xgboost时,他们是否也只大致调整这些有限的因素——n_estimators、深度、分数、学习率等。
2. 如果是,那么这种调整不是通过模型上的单个网格/随机搜索进行的吗?
3. 还有其他高级的可以调整的东西吗?
谢谢
是的,我建议对超参数值进行网格搜索或随机搜索,以查看哪种方法最适合您的特定问题。
预测器数量和树深度之间有什么关系?如果树的深度小于预测器的数量,是否意味着我没有使用所有预测器进行决策?我应该将树深度保持等于预测器的数量吗?
这取决于您的数据。
如何为多指标评分设置refit参数并使best_*属性可用于该指标
据我所知,它将为单个指标选择最佳结果。
也许您可以编写自己的指标,将其他指标组合起来,并以一种在所有指标上都能得出帕累托最优结果的方式进行组合。
非常感谢,你帮了我很多
很高兴听到这个消息。
在装有Win10的Dell XPS笔记本电脑上,按原样运行sklearn的grid_search代码会因并行失败而输出错误。错误信息:
“ImportError: [joblib] 尝试在不支持分叉的系统上进行并行计算,但未保护您的导入。要在脚本中使用并行计算,您必须使用“if __name__ == '__main__'”来保护您的主循环。有关更多信息,请参阅joblib文档中的Parallel”
这是一个已知问题(https://github.com/scikit-learn-contrib/hdbscan/issues/22)。
为了解决这个问题,需要按照错误消息的建议,用标准语句“if __name__ == "__main__":”包装任何非函数代码或类。
捕捉得好,谢谢。抱歉,我不了解Windows。
精彩的文章
非常有帮助
谢谢。
您好,我阅读了您的许多文章,并从中受益匪浅。
作为一名学生,我没有太多的计算资源,我想知道当数据量呈指数级增长时,超参数是否仍然有效?这将浪费我大量的时间在原始数据上调整超参数。
好问题。很难知道。
也许……
嗨,Jason,好文章!
关于使用“提前停止”。
-我采取了以下策略,请告诉我是否最佳。
>将数据分为训练集、保留集和测试集。
>将训练集分为训练集和评估集。
>在训练集上执行超参数调整,并使用交叉验证获得最佳参数。
>使用“评估集”作为评估集,执行提前停止以检查最佳的“early_stopping_rounds”。
>现在,使用训练集中的所有数据进行训练,并使用保留集进行预测以检查性能,如果需要,返回调整。
>最后使用“测试集”进行预测。
请告诉我你的想法。
谢谢,
查克。
是的,尝试提前停止,看看它是否对您的特定配置/数据集有帮助。
嗨,Jason,
我稍微修改了您的代码以运行XGBRegressor,然而在运行CV以找到最佳树数量时,我得到了错误:
TypeError: get_params() 缺少1个必需的位置参数: 'self'
在
grid_result = grid)search.fit(X,y)这行上,这是因为它已更改为回归模型而不是分类模型吗?我该如何调试这个?听到这个消息我很难过。
您的sklearn和xgboost版本是否最新?
嗨,Jason,
请忽略 Callum 的上一条评论,我只是漏掉了一些括号,现在它已经可以工作了,但又遇到了另一个错误,我认为这是因为它是回归而不是分类。
不客气。
记住要计算回归的误差,而不是准确度。
嗨,Jason,
我正在用你的PDF书学习Xgboost。
我想问一下n_estimator的数量。
在我的Xgboost模型中,随着n_estimator数量的增加,验证RMSE持续下降。
一些与Xgboost相关的文档建议n_estimator的数量应小于500。
我如何确定n_estimator的数量?
我建议增加n_estimators直到误差趋于平稳。
谢谢您的回答。
我的提升模型是回归模型。
因此,我监测了模型训练中训练和验证RMSE的变化。
我尝试将n_estimators增加到10,000。
然而,验证RMSE持续下降。
在这种情况下,为了防止过拟合,我是否根据验证RMSE的降低程度来确定n_estimators?
还是应该按照你的建议继续增加n_estimators?
增加n_estimators不会导致过拟合。
我建议继续添加树,直到RMSE不再下降。
我非常感谢您的回复。
据我所知,对于一个理想的模型,训练和验证RMSE之间的差距应该很小。
我判断发生过拟合的原因是,随着n_estimators的增加,训练和验证RMSE之间的差异也增加了。
即使训练和验证RMSE之间的差距很大,我是否需要根据您的回复不断增加n_estimators?
抱歉问了这么基础的问题。
因为这是我第一次开发基于决策树的集成模型,所以我有很多问题。
再次感谢您的耐心解答。
如果您发现过拟合,也许可以对验证数据集使用提前停止。
感谢您的快速回复。
为了最大限度地减少过拟合的可能性,我希望将两个RMSE之间的差异(小于1%)作为添加树的指标。
这个标准合理吗?
使用数据做出决策,也许可以测试一下?
感谢分享!看起来很棒 🙂
只是好奇,你认为程序会以热启动的方式(例如,对于具有50棵树的GBM,只需在49棵树的模型上再添加一棵树)持续训练模型,还是每次都从头开始重新训练模型?抱歉,我是Python及其包的初学者,所以还没有从源代码中弄清楚这一点。
不客气。
模型每次都从头开始重新训练。从热启动开始训练会更好,这可能通过API实现,但我尚未研究。
如果您探索这种方法,请告诉我!
grid_search = GridSearchCV(model, param_grid, scoring=”precision”, n_jobs=-1, cv=kfold, verbose=1)
grid_result = grid_search.fit(X, label_encoded_y)
# 总结结果
print(“Best: %f using %s” % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_[‘mean_test_score’]
stds = grid_result.cv_results_[‘std_test_score’]
params = grid_result.cv_results_[‘params’]
for mean, stdev, param in zip(means, stds, params)
print(“%f (%f) with: %r” % (mean, stdev, param))
# 绘图
pyplot.errorbar(max_depth, means, yerr=stds)
pyplot.title(“XGBoost max_depth vs Log Loss”)
pyplot.xlabel(‘max_depth’)
pyplot.ylabel(‘Log Loss’)
pyplot.savefig(‘max_depth.png’)
我的问题是
如果GridSearchCV中的评分设置为“precision”,我还可以使用cv_results_[‘mean_test_score’]、cv_result_[‘std_test_score’]、cv_results_[‘params’]并将它们放入pyplot.errorbar()中绘制图表吗?还是我需要计算和使用其他指标。如果我需要使用其他指标来显示精度,它们是什么?非常感谢,祝您有个美好的一天!
我相信它会报告您选择的任何指标。
嗨,Jason,
在n_estimators和max_depth调整时,我得到RuntimeWarning: invalid value encountered in multiply loss = -(transformed_labels * np.log(y_pred)).sum(axis=1),请问如何修复?
谢谢
抱歉,我以前没见过这个错误,也许这些建议能帮到你。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Jason,
n_estimators是否不再需要调优,它不在列表https://docs.xgboost.com.cn/en/latest/parameter.html中。
谢谢
它仍然存在并控制集成中树的数量。
嗨,Jason,
非常感谢您的精彩帖子。我正在使用lightgbm,当增加n_estimator时,cv分数会变得更好。然而,在测试集中使用高n_estimator时,我得到了更差的分数。我只使用网格搜索调整n_estimator。n_estimator的区间是[200, 500, 1000, 2500, 5000],cv分数(f1分数)是[0.0889565, 0.18166364, 0.26475717, 0.38393814, 0.43235423]
但是200棵树模型在测试集中的f1分数比5000棵树模型高得多?
这怎么会发生呢?是否与数据泄露有关?您有什么想法吗?
非常感谢您的支持,
关注测试集的性能,并确保测试集充分代表训练数据集/更广泛的问题。
嗨,Jason,
我最好的参数是100棵树,分数为0.001604。我使用了与您在分析第一部分中应用网格搜索(仅使用n_estimators)完全相同的代码,但结果不符。
导致这些不同值的原因是什么?是因为K折验证中的随机抽样吗?
如果是,我如何控制抽样?我们使用Train_Test_Split中的种子概念,以便每次运行代码时都能获得一致的分割。
谢谢 🙂
好问题,请看这个
https://machinelearning.org.cn/different-results-each-time-in-machine-learning/
你好 Jason,
是否有办法实现相同的过程,为数据集不同特征组合选择max_depth和n_estimators的最佳值?
我知道我们可以通过使用已知函数获得特征重要性,但如果选择不同的组合,准确性可能会有所不同,我说错了吗?
依次尝试每个值,并使用最适合您数据集的值。
所以唯一的方法是创建不同特征组合的迭代,并为我的数据集找到最佳准确性。
感谢回复。
你好Jason。好文章。在查看图表时,注意到平均对数损失及其标准差有点奇怪。查看数据集后发现,您的训练使用了第一列(行ID)作为特征集。删除该列后,对数损失似乎合理。只是想分享这个观察。
感谢您的反馈,Madhu!正如您所指出的,特征选择通常是有益的,应该予以考虑。
嗨,Jason,
长期使用XGBoost时,我们如何(或使用哪些指标)监控数据漂移或持续性能,以了解何时需要重建或重新调整?我的模型使用XGBClassifier构建,评估指标为logloss,目标为binary:logistic。任何指导都会有帮助!
感谢您的时间,
Allie
您好 Allie,
随着底层数据分布因概念漂移或其他因素而变化,长时间监控 XGBoost 模型(或任何机器学习模型)对于保持其性能至关重要。对于用于二元分类的 XGBoost 模型,有几种策略和指标可用于检测数据漂移并评估持续性能。这种监控将帮助您确定何时需要重新调整或重建模型。以下是一个结构化方法:
### 1. 性能指标
随着时间的推移,在您定期更新的验证集或新的传入数据上跟踪性能指标。二元分类的关键指标包括:
– **准确率(Accuracy)**:虽然这是一个直接的指标,但它可能对类别不平衡不敏感。
– **精确率(Precision)、召回率(Recall)、F1 分数(F1-Score)**:这些对于不平衡数据集至关重要,并提供了模型在每个类别上表现如何的更详细视图。
– **对数损失(Log Loss)(交叉熵)**:由于您使用 `logloss` 作为评估指标,因此监控其随时间的趋势可以直接指示性能变化。对数损失的增加表明模型的概率估计准确性正在下降。
– **AUC-ROC**:接收者操作特征曲线下的面积对于评估跨不同分类阈值的性能很有价值,并且对类别不平衡不敏感。
### 2. 数据漂移检测
可以通过监控特征或目标变量分布随时间的变化来检测数据漂移。有几种方法:
– **统计测试**:定期应用统计测试(例如,连续特征的 KS 测试,分类特征的卡方测试)来检测历史训练数据和新传入数据之间特征分布的显著变化。
– **特征重要性监控**:跟踪 XGBoost 提供的特征重要性指标的变化。特征重要性的显著变化可能表明数据动态发生了变化。
– **基于模型的漂移检测**:训练一个简单的模型来区分旧数据和新数据。显著的性能(例如,准确率远高于随机猜测)可能表明数据漂移。
### 3. 概念漂移检测
概念漂移是指输入特征与目标变量之间关系的变化。监控需要更细致的方法:
– **监控目标分布**:对于二元分类,类别比例随时间的变化可能是一个简单而有效的指标。
– **残差分析**:分析您预测的残差随时间的变化。残差模式或分布的显著变化可能表明概念漂移。
– **基于窗口的分析**:使用滑动窗口方法比较模型在最新数据上的性能与历史数据上的性能。性能显著下降表明概念漂移。
### 4. 自动化监控工具
考虑使用或开发自动化监控工具,可以跟踪这些指标并在达到特定阈值时提醒您。这种方法可以包括:
– **仪表盘**:使用 Grafana、Kibana 或自定义仪表盘等工具实时可视化关键指标。
– **警报系统**:实施根据预定义规则(例如,对数损失显著增加或 AUC-ROC 下降)发送警报的系统。
### 5. 持续学习
– **在线学习**:对于需要频繁更新的模型,请考虑允许您的模型从新数据中逐步学习的技术。
– **定期再训练**:根据从监控中获得的见解,安排使用新数据定期再训练您的模型,以适应变化。
### 结论
有效监控 XGBoost 模型需要结合性能指标跟踪、数据和概念漂移检测以及实施持续评估和适应系统。通过建立强大的监控框架,您可以确保您的模型随着时间的推移保持有效,并能够适应底层数据的变化。