XGBoost 是梯度提升集成算法的强大而有效的实现。
配置 XGBoost 模型的超参数可能具有挑战性,这通常会导致使用耗时且计算成本高昂的大型网格搜索实验。
配置 XGBoost 模型的一种替代方法是评估模型在训练期间的每个算法迭代中的性能,并将结果绘制为学习曲线。这些学习曲线图提供了一个诊断工具,可以对其进行解释并提出对模型超参数的具体更改建议,从而可能提高预测性能。
在本教程中,您将了解如何在 Python 中为 XGBoost 模型绘制和解释学习曲线。
完成本教程后,您将了解:
- 学习曲线为理解 XGBoost 等监督学习模型的训练动态提供了一个有用的诊断工具。
- 如何配置 XGBoost 以在每次迭代时评估数据集并将结果绘制为学习曲线。
- 如何解释和使用学习曲线图来改进 XGBoost 模型性能。
让我们开始吧。

使用学习曲线调整 XGBoost 性能
照片由 Bernard Spragg. NZ 提供,部分权利保留。
教程概述
本教程分为四个部分;它们是
- 极端梯度提升
- 学习曲线
- 绘制 XGBoost 学习曲线
- 使用学习曲线调整 XGBoost 模型
极端梯度提升
梯度提升是指一类集成机器学习算法,可用于分类或回归预测建模问题。
集成模型由决策树模型构建。树被一个接一个地添加到集成中,并进行拟合以纠正先前模型所做的预测错误。这是一种被称为“提升”的集成机器学习模型。
模型使用任何可微分的损失函数和梯度下降优化算法进行拟合。这赋予了该技术“梯度提升”的名称,因为在拟合模型时,损失梯度会像神经网络一样被最小化。
有关梯度提升的更多信息,请参阅本教程。
Extreme Gradient Boosting,简称 XGBoost,是梯度提升算法的一个高效开源实现。因此,XGBoost 是一个算法、一个开源项目和一个 Python 库。
它最初由 Tianqi Chen 开发,并在其 2016 年的论文“XGBoost: A Scalable Tree Boosting System”中由 Chen 和 Carlos Guestrin 进行了描述。
它旨在兼具计算效率(例如,执行速度快)和高效性,可能比其他开源实现更有效。
使用 XGBoost 的两个主要原因是执行速度和模型性能。
XGBoost 在分类和回归预测建模问题上主导结构化或表格数据集。证据表明,它是 Kaggle 竞争数据科学平台比赛获胜者的首选算法。
在 2015 年 Kaggle 博客上发布的 29 个挑战获胜解决方案中,有 17 个解决方案使用了 XGBoost。 […] 该系统在 KDDCup 2015 中也取得了成功,前 10 名的每个获胜团队都使用了 XGBoost。
— XGBoost: A Scalable Tree Boosting System, 2016。
有关 XGBoost 以及如何安装和使用 XGBoost Python API 的更多信息,请参阅教程
现在我们已经熟悉了 XGBoost 的概念及其重要性,让我们更深入地了解学习曲线。
学习曲线
通常,学习曲线是一张图,它以 x 轴上的时间和经验,以及 y 轴上的学习或改进。
学习曲线在机器学习中广泛用于学习(随着时间推移优化其内部参数)的算法,例如深度学习神经网络。
用于评估学习的指标可以是最大化的,这意味着更好的分数(更大的数字)表示更多的学习。一个例子是分类准确率。
更常见的是使用最小化的分数,例如损失或误差,其中更好的分数(较小的数字)表示更多的学习,而值为 0.0 表示训练数据集已完美学习,没有犯任何错误。
在机器学习模型训练期间,可以评估训练算法每一步的模型当前状态。它可以根据训练数据集进行评估,以了解模型“学习”得有多好。它也可以根据未包含在训练数据集中的保留验证数据集进行评估。在验证数据集上的评估可以了解模型“泛化”得有多好。
通常会在训练和验证数据集上为机器学习模型创建双学习曲线。
学习曲线的形状和动态可用于诊断机器学习模型的行为,进而可能建议对模型配置进行的更改类型,以改进学习和/或性能。
您在学习曲线中很可能观察到三种常见的动态;它们是:
- 欠拟合。
- 过拟合。
- 拟合良好。
最常见的是,学习曲线用于诊断模型的过拟合行为,可以通过调整模型的超参数来解决。
过拟合是指模型过于完美地学习了训练数据集,包括训练数据集中的统计噪声或随机波动。
过拟合的问题在于,模型对训练数据的专业化程度越高,它对新数据的泛化能力就越差,从而导致泛化误差增加。这种泛化误差的增加可以通过模型在验证数据集上的性能来衡量。
有关学习曲线的更多信息,请参阅教程
现在我们已经熟悉了学习曲线,让我们看看如何为 XGBoost 模型绘制学习曲线。
绘制 XGBoost 学习曲线
在本节中,我们将绘制 XGBoost 模型的学习曲线。
首先,我们需要一个数据集作为拟合和评估模型的基础。
在本教程中,我们将使用一个合成的二元(两类)分类数据集。
我们可以使用 make_classification() scikit-learn 函数来创建合成分类数据集。在这种情况下,我们将使用 50 个输入特征(列)并生成 10,000 个样本(行)。伪随机数生成器的种子被固定,以确保每次生成样本时都使用相同的基本“问题”。
下面的示例生成了合成分类数据集并总结了生成数据的形状。
|
1 2 3 4 5 6 |
# 测试分类数据集 from sklearn.datasets import make_classification # 定义数据集 X, y = make_classification(n_samples=10000, n_features=50, n_informative=50, n_redundant=0, random_state=1) # 汇总数据集 print(X.shape, y.shape) |
运行示例会生成数据并报告输入和输出组件的大小,确认预期的形状。
|
1 |
(10000, 50) (10000,) |
接下来,我们可以根据此数据集拟合 XGBoost 模型并绘制学习曲线。
首先,我们必须将数据集分为两部分:一部分用于训练模型(训练集),另一部分不用于训练模型,而是保留下来用于在训练算法的每个步骤中评估模型(测试集或验证集)。
|
1 2 3 |
... # 将数据拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.50, random_state=1) |
然后,我们可以定义一个具有默认超参数的 XGBoost 分类模型。
|
1 2 3 |
... # 定义模型 model = XGBClassifier() |
接下来,可以在数据集上拟合模型。
在这种情况下,我们必须向训练算法指定,我们希望它在每次迭代时(例如,在将新树添加到集成后)评估训练集和测试集上的模型性能。
为此,我们必须指定要评估的数据集和要评估的指标。
数据集必须指定为元组列表,其中每个元组包含一个数据集的输入和输出列,列表中的每个元素是不同的数据集,例如训练集和测试集。
|
1 2 3 |
... # 定义要在每次迭代时评估的数据集 evalset = [(X_train, y_train), (X_test,y_test)] |
我们可以评估许多指标,尽管由于这是一个分类任务,我们将评估模型在对数损失(交叉熵)上的表现,这是一个最小化分数(值越低越好)。
这可以通过在调用 fit() 时指定“eval_metric”参数并为我们提供的要评估的指标提供名称“logloss”来实现。我们也可以通过“eval_set”参数指定要评估的数据集。fit() 函数按惯例将训练数据集作为前两个参数。
|
1 2 3 |
... # 拟合模型 model.fit(X_train, y_train, eval_metric='logloss', eval_set=evalset) |
模型拟合后,我们可以将其性能评估为在测试数据集上的分类准确率。
|
1 2 3 4 5 |
... # 评估性能 yhat = model.predict(X_test) score = accuracy_score(y_test, yhat) print('Accuracy: %.3f' % score) |
然后,我们可以通过调用 evals_result() 函数来检索为每个数据集计算的指标。
|
1 2 3 |
... # 检索性能指标 results = model.evals_result() |
这将返回一个字典,首先按数据集(“validation_0”和“validation_1”)组织,然后按指标(“logloss”)组织。
我们可以创建每个数据集指标的折线图。
|
1 2 3 4 5 6 7 8 |
... # 绘制学习曲线 pyplot.plot(results['validation_0']['logloss'], label='train') pyplot.plot(results['validation_1']['logloss'], label='test') # 显示图例 pyplot.legend() # 显示绘图 pyplot.show() |
就是这样。
将所有这些内容结合起来,在合成分类任务上拟合 XGBoost 模型并绘制学习曲线的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 绘制 xgboost 模型的学习曲线 from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from xgboost import XGBClassifier from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=10000, n_features=50, n_informative=50, n_redundant=0, random_state=1) # 将数据拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.50, random_state=1) # 定义模型 model = XGBClassifier() # 定义要在每次迭代时评估的数据集 evalset = [(X_train, y_train), (X_test,y_test)] # 拟合模型 model.fit(X_train, y_train, eval_metric='logloss', eval_set=evalset) # 评估性能 yhat = model.predict(X_test) score = accuracy_score(y_test, yhat) print('Accuracy: %.3f' % score) # 检索性能指标 results = model.evals_result() # 绘制学习曲线 pyplot.plot(results['validation_0']['logloss'], label='train') pyplot.plot(results['validation_1']['logloss'], label='test') # 显示图例 pyplot.legend() # 显示绘图 pyplot.show() |
运行示例会拟合 XGBoost 模型,检索计算出的指标,并绘制模型性能的学习曲线。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。考虑运行几次示例并比较平均结果。
首先,报告了模型性能,显示模型在保留测试集上实现了约 94.5% 的分类准确率。
|
1 |
准确率:0.945 |
该图显示了训练集和测试集 XGBoost 模型的学习曲线,其中 x 轴是算法的迭代次数(或添加到集成中的树的数量),y 轴是模型的对数损失。每条线显示给定数据集的每次迭代的对数损失。
从学习曲线中,我们可以看到模型在训练数据集上的性能(蓝线)比模型在测试数据集上的性能(橙线)更好或损失更低,这通常是我们所期望的。
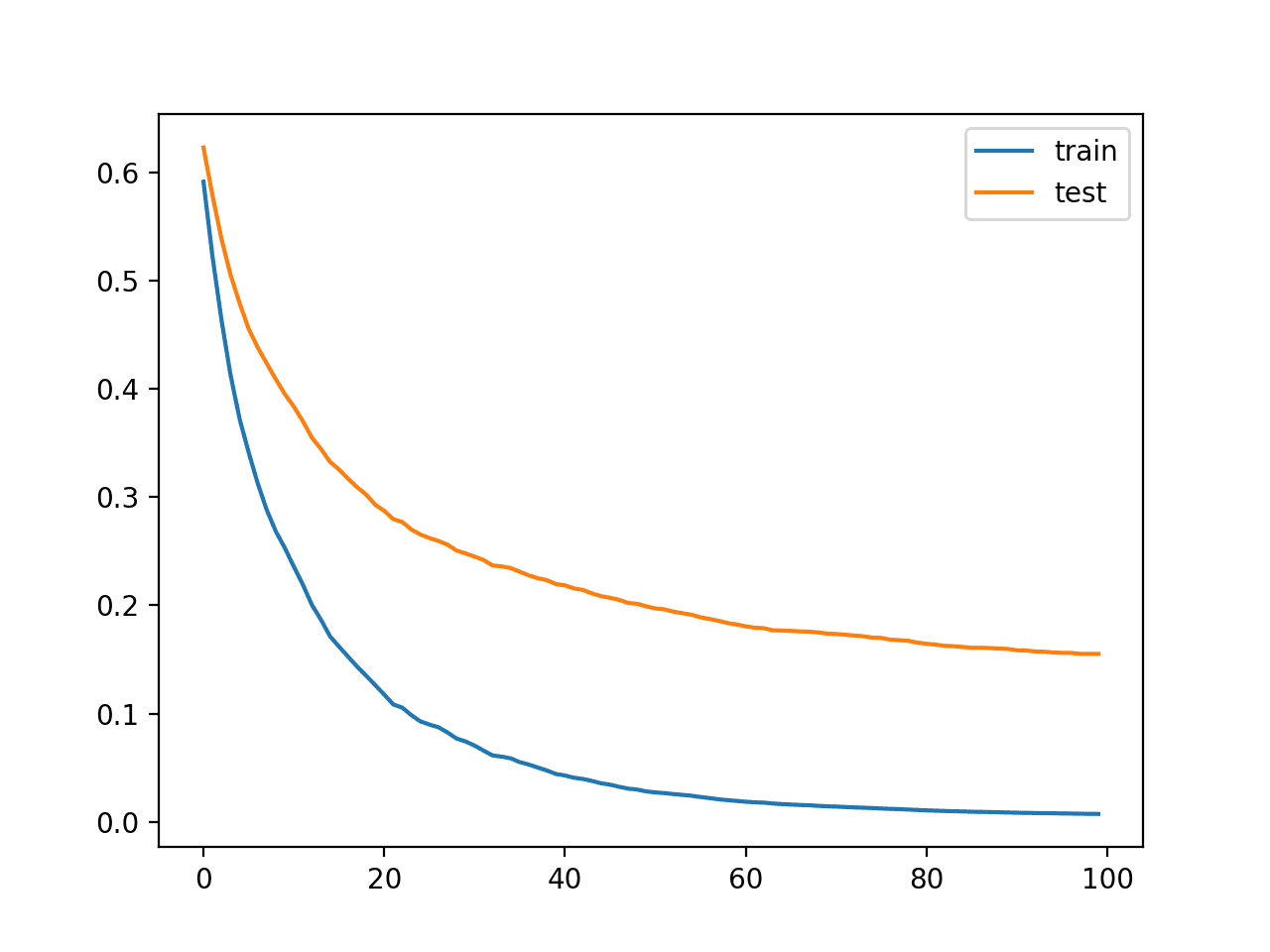
合成分类数据集上 XGBoost 模型学习曲线
既然我们知道如何为 XGBoost 模型绘制学习曲线,让我们看看如何使用这些曲线来提高模型性能。
使用学习曲线调整 XGBoost 模型
我们可以将学习曲线用作诊断工具。
这些曲线可以被解释并作为提出可能导致更好性能的模型配置具体更改的依据。
上一节中的模型和结果可以作为基线和起点。
观察图表,我们可以看到两条曲线都在向下倾斜,这表明更多的迭代(添加更多树)可能会进一步降低损失。
让我们试试看。
我们可以通过“n_estimators”超参数增加算法的迭代次数,该参数默认为 100。让我们将其增加到 500。
|
1 2 3 |
... # 定义模型 model = XGBClassifier(n_estimators=500) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 绘制 xgboost 模型的学习曲线 from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from xgboost import XGBClassifier from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=10000, n_features=50, n_informative=50, n_redundant=0, random_state=1) # 将数据拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.50, random_state=1) # 定义模型 model = XGBClassifier(n_estimators=500) # 定义要在每次迭代时评估的数据集 evalset = [(X_train, y_train), (X_test,y_test)] # 拟合模型 model.fit(X_train, y_train, eval_metric='logloss', eval_set=evalset) # 评估性能 yhat = model.predict(X_test) score = accuracy_score(y_test, yhat) print('Accuracy: %.3f' % score) # 检索性能指标 results = model.evals_result() # 绘制学习曲线 pyplot.plot(results['validation_0']['logloss'], label='train') pyplot.plot(results['validation_1']['logloss'], label='test') # 显示图例 pyplot.legend() # 显示绘图 pyplot.show() |
运行示例将拟合和评估模型,并绘制模型性能的学习曲线。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。考虑运行几次示例并比较平均结果。
我们可以看到,更多的迭代使准确率从约 94.5% 提高到约 95.8%。
|
1 |
准确率:0.958 |
从学习曲线中,我们可以看到额外的迭代确实导致曲线继续下降,然后在大约 150 次迭代后趋于平稳,并且在之后保持相对平坦。
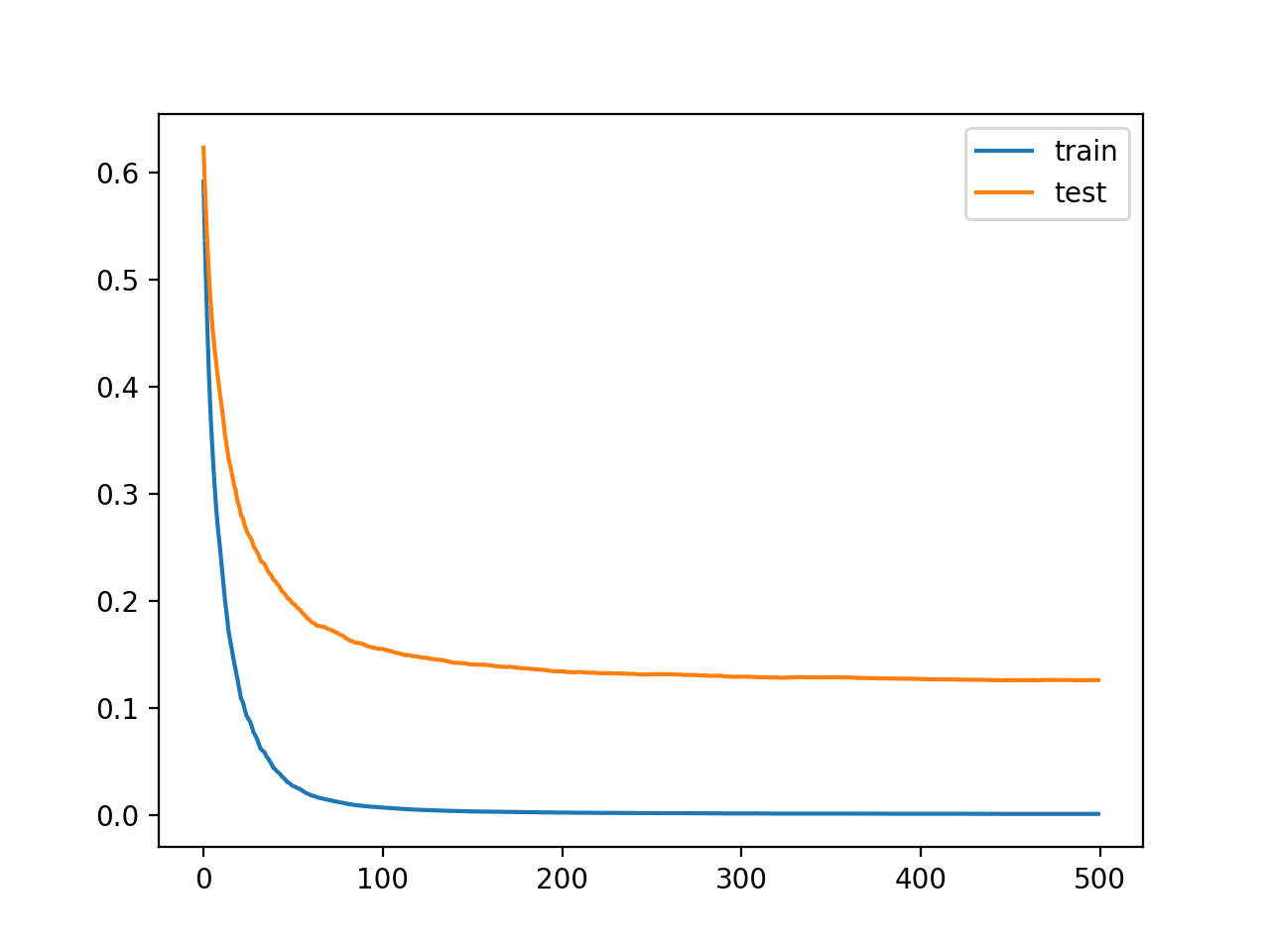
具有更多迭代次数的 XGBoost 模型学习曲线
长而平坦的曲线可能表明算法学习速度过快,我们可以通过减慢速度来获益。
这可以通过学习率来实现,它限制了添加到集成中的每棵树的贡献。这可以通过“eta”超参数控制,默认为 0.3。我们可以尝试一个较小的值,例如 0.05。
|
1 2 3 |
... # 定义模型 model = XGBClassifier(n_estimators=500, eta=0.05) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 绘制 xgboost 模型的学习曲线 from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from xgboost import XGBClassifier from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=10000, n_features=50, n_informative=50, n_redundant=0, random_state=1) # 将数据拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.50, random_state=1) # 定义模型 model = XGBClassifier(n_estimators=500, eta=0.05) # 定义要在每次迭代时评估的数据集 evalset = [(X_train, y_train), (X_test,y_test)] # 拟合模型 model.fit(X_train, y_train, eval_metric='logloss', eval_set=evalset) # 评估性能 yhat = model.predict(X_test) score = accuracy_score(y_test, yhat) print('Accuracy: %.3f' % score) # 检索性能指标 results = model.evals_result() # 绘制学习曲线 pyplot.plot(results['validation_0']['logloss'], label='train') pyplot.plot(results['validation_1']['logloss'], label='test') # 显示图例 pyplot.legend() # 显示绘图 pyplot.show() |
运行示例将拟合和评估模型,并绘制模型性能的学习曲线。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。考虑运行几次示例并比较平均结果。
我们可以看到,较小的学习率导致准确率下降,从约 95.8% 降至约 95.1%。
|
1 |
准确率:0.951 |
从学习曲线中,我们可以看到学习确实大大减慢了。曲线表明我们可以继续增加迭代次数,并可能获得更好的性能,因为曲线将有更多机会继续下降。
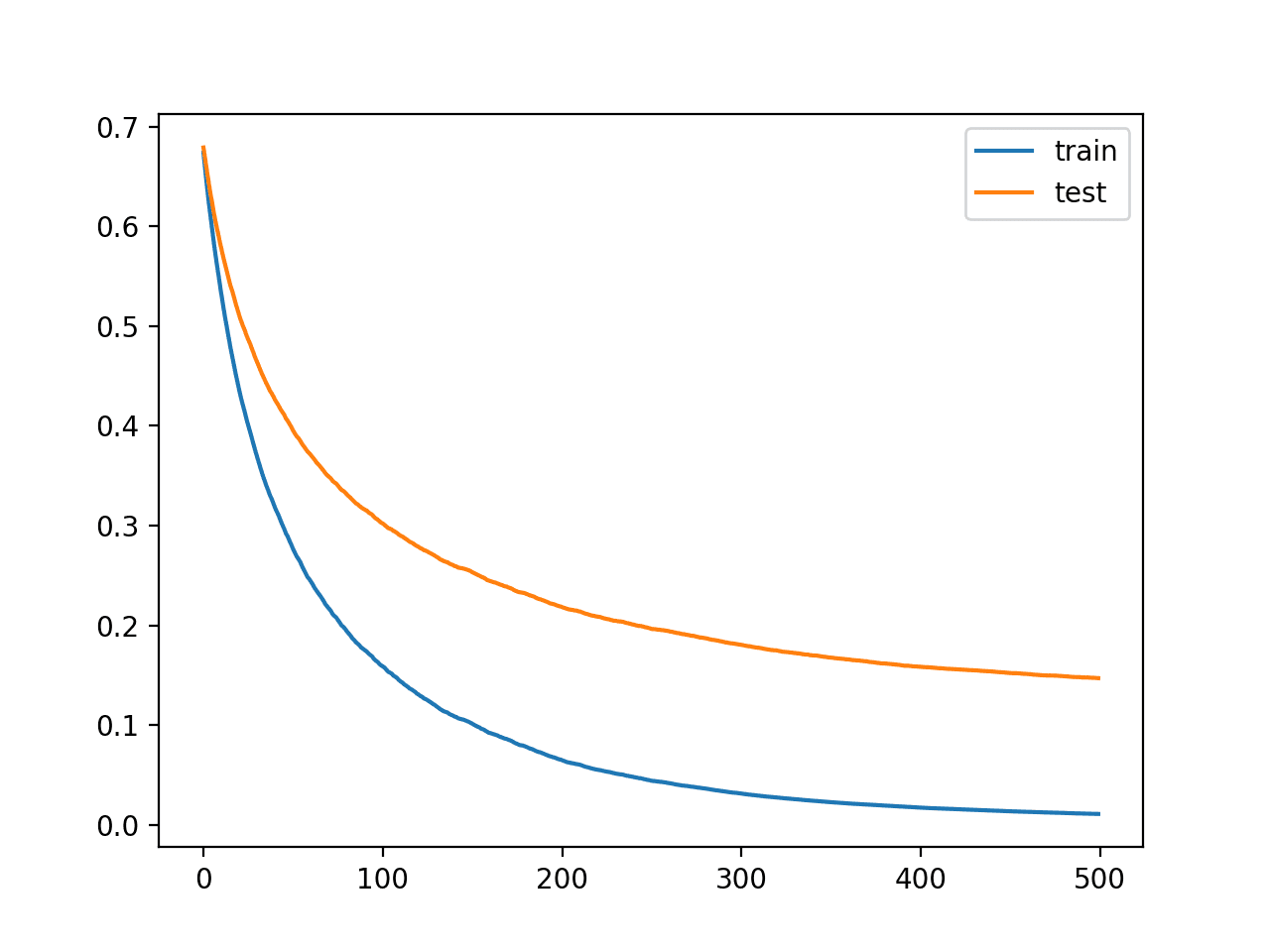
具有较小学习率的 XGBoost 模型学习曲线
让我们尝试将迭代次数从 500 增加到 2,000。
|
1 2 3 |
... # 定义模型 model = XGBClassifier(n_estimators=2000, eta=0.05) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 绘制 xgboost 模型的学习曲线 from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from xgboost import XGBClassifier from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=10000, n_features=50, n_informative=50, n_redundant=0, random_state=1) # 将数据拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.50, random_state=1) # 定义模型 model = XGBClassifier(n_estimators=2000, eta=0.05) # 定义要在每次迭代时评估的数据集 evalset = [(X_train, y_train), (X_test,y_test)] # 拟合模型 model.fit(X_train, y_train, eval_metric='logloss', eval_set=evalset) # 评估性能 yhat = model.predict(X_test) score = accuracy_score(y_test, yhat) print('Accuracy: %.3f' % score) # 检索性能指标 results = model.evals_result() # 绘制学习曲线 pyplot.plot(results['validation_0']['logloss'], label='train') pyplot.plot(results['validation_1']['logloss'], label='test') # 显示图例 pyplot.legend() # 显示绘图 pyplot.show() |
运行示例将拟合和评估模型,并绘制模型性能的学习曲线。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。考虑运行几次示例并比较平均结果。
我们可以看到,更多的迭代为算法提供了更多的改进空间,准确率达到了 96.1%,是迄今为止最好的。
|
1 |
准确率:0.961 |
学习曲线再次显示算法的收敛稳定,下降迅速然后趋于平稳。
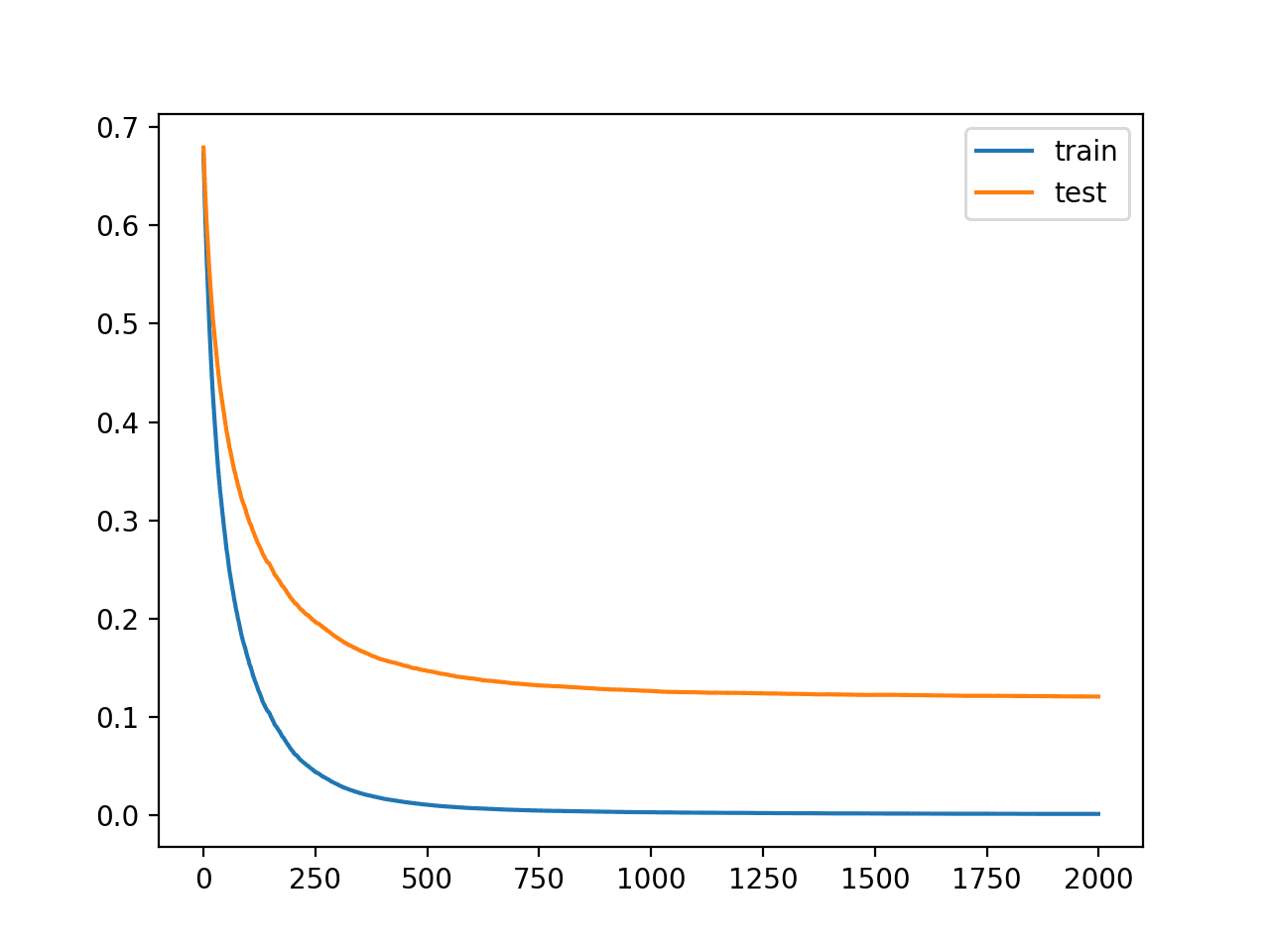
具有较小学习率和多次迭代的 XGBoost 模型学习曲线
我们可以重复减小学习率和增加迭代次数的过程,以查看是否有可能进一步改进。
减慢学习速度的另一种方法是通过“subsample”和“colsample_bytree”超参数分别将用于构建集成中每棵树的样本数和特征数减半,从而添加正则化。
在这种情况下,我们将尝试将样本数和特征数分别减半,通过“subsample”和“colsample_bytree”超参数。
|
1 2 3 |
... # 定义模型 model = XGBClassifier(n_estimators=2000, eta=0.05, subsample=0.5, colsample_bytree=0.5) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 绘制 xgboost 模型的学习曲线 from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from xgboost import XGBClassifier from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=10000, n_features=50, n_informative=50, n_redundant=0, random_state=1) # 将数据拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.50, random_state=1) # 定义模型 model = XGBClassifier(n_estimators=2000, eta=0.05, subsample=0.5, colsample_bytree=0.5) # 定义要在每次迭代时评估的数据集 evalset = [(X_train, y_train), (X_test,y_test)] # 拟合模型 model.fit(X_train, y_train, eval_metric='logloss', eval_set=evalset) # 评估性能 yhat = model.predict(X_test) score = accuracy_score(y_test, yhat) print('Accuracy: %.3f' % score) # 检索性能指标 results = model.evals_result() # 绘制学习曲线 pyplot.plot(results['validation_0']['logloss'], label='train') pyplot.plot(results['validation_1']['logloss'], label='test') # 显示图例 pyplot.legend() # 显示绘图 pyplot.show() |
运行示例将拟合和评估模型,并绘制模型性能的学习曲线。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。考虑运行几次示例并比较平均结果。
我们可以看到,添加正则化使准确率从约 96.1% 提高到约 96.6%。
|
1 |
准确率:0.966 |
曲线表明正则化减慢了学习,并且可能增加迭代次数可能会带来进一步的改进。
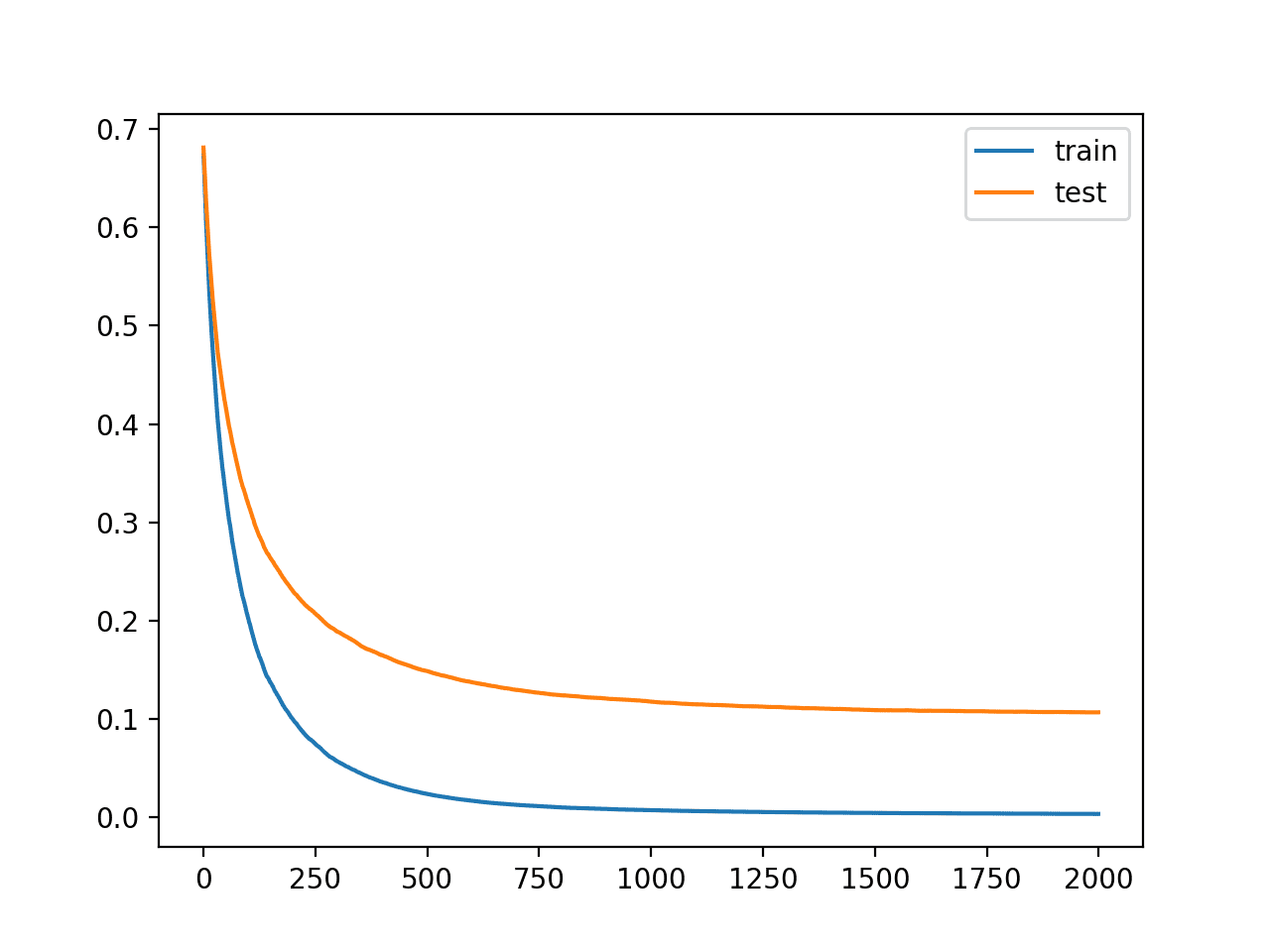
带正则化的 XGBoost 模型学习曲线
这个过程可以继续,我很想看看你们能想出什么。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
论文
- XGBoost:一个可扩展的树形增强系统, 2016.
API
总结
在本教程中,您了解了如何在 Python 中为 XGBoost 模型绘制和解释学习曲线。
具体来说,你学到了:
- 学习曲线为理解 XGBoost 等监督学习模型的训练动态提供了一个有用的诊断工具。
- 如何配置 XGBoost 以在每次迭代时评估数据集并将结果绘制为学习曲线。
- 如何解释和使用学习曲线图来改进 XGBoost 模型性能。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
发现赢得竞赛的算法!

在几分钟内开发您自己的 XGBoost 模型
...只需几行 Python 代码
在我的新电子书中探索如何实现
使用 Python 实现 XGBoost
它涵盖了自学教程,例如:
算法基础、缩放、超参数等等……
将 XGBoost 的强大功能带入您自己的项目
跳过学术理论。只看结果。






你好,
首先,我是一个忠实的粉丝。
一个观察——你能给图表添加 x 轴标签、y 轴标签和标题吗?我知道它们很直观,但我认为每个公开的图表都应该有这些:)
除此之外,这是一篇不错的文章!
好建议,谢谢!
嗨,
精彩的文章。您在 XGboost 实例函数中使用 eval_set 参数……它只适用于 XGboost 模型吗?还是也适用于其他 sklearn 模型?在文档中找不到,所以问一下。
谢谢。
什么是“eval_set”?
它是你在拟合模型时传递的参数(第 16 行)
model.fit(X_train, y_train, eval_metric=’logloss’, eval_set=evalset)
eval_set 在此页面上进行了描述
https://docs.xgboost.com.cn/en/latest/python/python_api.html
嗨 Jason
首先,我想说我已经关注您的材料一段时间了
我认为它们非常有价值且富有启发性。
关于学习曲线,您将如何处理具有如下学习曲线的模型:https://raw.githubusercontent.com/mljar/mljar-examples/master/Random_Data/AutoML_1k/5_Default_Xgboost/learning_curves.png?
感谢您提供的内容!
这将帮助您解释您的结果
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
你好,Jason!
我喜欢这个教程,它非常信息丰富。感谢发布。
关于流程的快速问题:如何在本教程中修改以使用 sklearn 管道?我在传递 eval_metric 和 eval_set 时遇到了问题。
您是否有关于学习曲线、XGBoost 和 sklearn 管道主题的教程?
致以最诚挚的问候,Bernardo
嗨 Bernardo……以下内容可能对您感兴趣
https://nabeelvalley.co.za/docs/data-science-with-python/xgboost-and-pipelines/
你好,我想知道如何修改这个来评估 Xgboost 回归
嗨 Pirunthan……您可能会发现以下内容很有趣
https://machinelearning.org.cn/xgboost-for-regression/
如果您想停止接收如下的评估消息:
[0] validation_0-logloss:0.53399
[0] validation_0-logloss:0.53152
[0] validation_0-logloss:0.63346
[0] validation_0-logloss:0.54667
[0] validation_0-logloss:0.53152
[0] validation_0-logloss:0.63372
[0] validation_0-logloss:0.53399
[1] validation_0-logloss:0.44288
[0] validation_0-logloss:0.63795
[1] validation_0-logloss:0.58414
[1] validation_0-logloss:0.44288
使用
xgb_model.fit(X, y, eval_metric=‘mlogloss’, eval_set=evalset, verbose=False)
https://discuss.xgboost.ai/t/cant-turn-off-the-validation-messages-during-training/2445/4