机器学习算法经过参数化,以便它们能够最好地适应给定问题。一个难题是,为给定问题配置算法本身可能就是一个项目。
就像为问题选择“最佳”算法一样,您无法事先知道哪些算法参数最适合某个问题。最好的办法是进行受控实验的实证研究。
Caret R 包旨在使查找算法的最优参数变得非常容易。它提供了一种用于搜索参数的网格搜索方法,并结合了各种评估给定模型性能的方法。
在这篇文章中,您将发现 5 个秘诀,您可以使用它们来调整机器学习算法,以使用 Caret R 包找到问题的最佳参数。
通过我的新书《R 语言机器学习精通》启动您的项目,其中包括逐步教程和所有示例的R 源代码文件。
让我们开始吧。
模型调优
Caret R 包提供了一个网格搜索,它可以或您可以指定要在问题上尝试的参数。它将试验所有组合并找到给出最佳结果的组合。
这篇文章中的示例将演示如何使用 Caret R 包来调整机器学习算法。
所有示例都将使用学习向量量化 (LVQ),因为它很简单。它类似于 k 近邻,只是样本数据库更小且根据训练数据进行调整。它有两个参数需要调整:模型中实例(码本)的数量,称为大小,以及在进行预测时要检查的实例数量,称为k。
每个示例还将使用 R 自带的鸢尾花数据集。这个分类数据集提供了 150 个鸢尾花三个物种的观测值,以及它们的萼片和花瓣尺寸(以厘米为单位)。
每个示例还假设我们对分类准确率作为我们正在优化的指标感兴趣,尽管这可以更改。此外,每个示例都使用重复的 n 折交叉验证(10 折和 3 次重复)来估计给定模型(大小和 k 参数组合)的性能。如果需要,这也可以更改。
需要更多关于R机器学习的帮助吗?
参加我为期14天的免费电子邮件课程,了解如何在您的项目中使用R(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
网格搜索:自动网格
在 Caret R 包中有两种调整算法的方法,第一种是允许系统自动进行。这可以通过设置 tuneLength 来指示每个算法参数要尝试的不同值的数量。
这只支持整数和分类算法参数,它对要尝试的值做出了粗略的猜测,但它可以让您非常快速地启动和运行。
以下秘诀演示了 LVQ 的大小和 k 属性的自动网格搜索,每个属性有 5 个值 (tuneLength=5)(总共 25 个模型)。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 确保结果可重复 set.seed(7) # 加载库 library(caret) # 加载数据集 data(iris) # 准备训练方案 control <- trainControl(method="repeatedcv", number=10, repeats=3) # 训练模型 model <- train(Species~., data=iris, method="lvq", trControl=control, tuneLength=5) # 总结模型 print(model) |
用于模型的最终值为 size = 10 和 k = 1。
网格搜索:手动网格
搜索算法参数的第二种方法是手动指定调整网格。在网格中,每个算法参数都可以指定为可能值的向量。这些向量组合起来定义了所有可能的尝试组合。
下面的秘诀演示了手动调整网格的搜索,其中 size 参数有 4 个值,k 参数有 5 个值(20 种组合)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 确保结果可重复 set.seed(7) # 加载库 library(caret) # 加载数据集 data(iris) # 准备训练方案 control <- trainControl(method="repeatedcv", number=10, repeats=3) # 设计参数调整网格 grid <- expand.grid(size=c(5,10,20,50), k=c(1,2,3,4,5)) # 训练模型 model <- train(Species~., data=iris, method="lvq", trControl=control, tuneGrid=grid) # 总结模型 print(model) |
用于模型的最终值为 size = 50 和 k = 5。
数据预处理
数据集可以作为参数调整的一部分进行预处理。在用于评估每个模型的样本中进行此操作很重要,以确保结果考虑到测试中的所有变异性。如果在调整过程之前对数据集进行归一化或标准化,它将获得额外的知识(偏差),并且无法对看不见的数据给出准确的性能估计。
鸢尾花数据集中的属性都使用相同的单位,并且通常具有相同的比例,因此归一化和标准化并不是真正必要的。尽管如此,下面的示例演示了在用 preProcess="scale" 归一化数据集的同时,调整 LVQ 的 size 和 k 参数。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 确保结果可重复 set.seed(7) # 加载库 library(caret) # 加载数据集 data(iris) # 准备训练方案 control <- trainControl(method="repeatedcv", number=10, repeats=3) # 训练模型 model <- train(Species~., data=iris, method="lvq", preProcess="scale", trControl=control, tuneLength=5) # 总结模型 print(model) |
用于模型的最终值为 size = 8 和 k = 6。
并行处理
caret 包支持并行处理,以减少给定实验的计算时间。只要配置正确,它就会自动支持。在此示例中,我们加载 doMC 包并将核心数设置为 4,从而在调整模型时为 caret 提供 4 个工作线程。这用于每个参数组合的交叉验证重复循环。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 确保结果可重复 set.seed(7) # 配置多核 library(doMC) registerDoMC(cores=4) # 加载库 library(caret) # 加载数据集 data(iris) # 准备训练方案 control <- trainControl(method="repeatedcv", number=10, repeats=3) # 训练模型 model <- train(Species~., data=iris, method="lvq", trControl=control, tuneLength=5) # 总结模型 print(model) |
结果与第一个示例相同,只是完成得更快。
性能可视化
绘制不同算法参数组合的性能图可能很有用,以寻找趋势和模型的敏感性。Caret 支持直接绘制模型图,这将比较不同算法组合的准确性。
在下面的秘诀中,定义了一个更大的手动算法参数网格并绘制了结果图。该图显示了 x 轴上的 size 和 y 轴上的模型准确性。绘制了两条线,每条线代表一个 k 值。该图显示了性能随 size 增加的总体趋势,以及 k 值越大可能越好。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 确保结果可重复 set.seed(7) # 加载库 library(caret) # 加载数据集 data(iris) # 准备训练方案 control <- trainControl(method="repeatedcv", number=10, repeats=3) # 设计参数调整网格 grid <- expand.grid(size=c(5,10,15,20,25,30,35,40,45,50), k=c(3,5)) # 训练模型 model <- train(Species~., data=iris, method="lvq", trControl=control, tuneGrid=grid) # 总结模型 print(model) # 绘制参数对准确性的影响 plot(model) |
用于模型的最终值为 size = 35 和 k = 5。
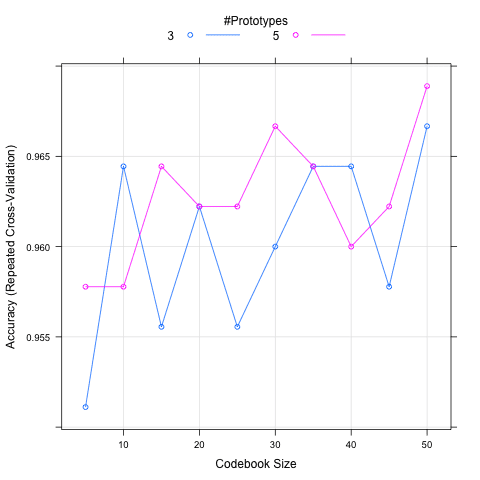
使用 Caret R 包进行网格搜索
显示 LVQ 的 size 和 k 与模型准确性
总结
在这篇文章中,您发现了 Caret R 包通过网格搜索来调整算法参数的支持。
您已经看到了使用 Caret R 包调整 LVQ 算法的 size 和 k 参数的 5 个秘诀。
这篇文章中的每个秘诀都是独立的,您可以将其复制并粘贴到您自己的项目中并适应您的问题。
在R中发现更快的机器学习!

在几分钟内开发您自己的模型
...只需几行R代码
在我的新电子书中探索如何实现
精通 R 语言机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到您自己的项目中
跳过学术理论。只看结果。




感谢这篇精彩的文章!您能提供一个在 Windows 中使用 Caret 包进行并行处理的示例吗,因为 doMC 包仅适用于 Unix?
doParallel
谢谢,Jason。对可用内容及其使用方法的精彩总结。
这适用于回归问题吗?
是的,可以。
如果我的响应变量不是分类变量,那么方法会是什么?这里你使用了学习向量量化方法。model <- train(Species~., data=iris, method="lvq", trControl=control, tuneLength=5)??
这个网站上其他教程中广泛使用的 Python 堆栈是否也有专门的多核设置?
我不能使用 CUDA。
是的,我相信大多数 sklearn 函数都有 n_jobs 参数。
码本大小或 size 参数指的是什么?
码本指的是模型的学习能力。
我刚开始学习模型。您的文章写得很好。谢谢 🙂
谢谢,很高兴对您有帮助。
非常感谢!非常有帮助
很高兴听到这个消息。
感谢这篇好文章!找到写得如此好的机器学习文章非常有帮助。
我有一个相关问题:您知道是否有可能在多分类问题中为不同的分类器提供不同的调整参数吗,例如,使用 Caret 中的 train 函数为使用 SVMRadial 的不同 SVM 提供不同的 C 值?
是的,您可以直接向模型提供参数。
嗨,Jason,
谢谢您的快速回复。那么,如何在同一个 train 函数中为不同的分类器指定不同的成本值呢?我还没有找到这个功能的示例。
提前感谢并致以最诚挚的问候。
您可以在评估模型时在 tuneGrid 参数中指定算法参数。它不必是网格,它可以是一组参数。
先生,好帖子!
您如何指示 CARET 使用敏感度而不是准确性来选择最佳模型?
您可以指定“metric”参数,更多详细信息请参见此处
https://machinelearning.org.cn/machine-learning-evaluation-metrics-in-r/
您能澄清一下 train() 函数在指定网格时内部发生了什么吗?我很好奇这行代码的输出模型。
a) 从这行代码输出的模型是交叉验证框架中验证集中错误最低的最佳模型吗?也就是说,如果使用 5 折交叉验证运行网格搜索,那么输出模型将是 5 个可能模型中的一个吗?
b) 评估所有验证拆分并对它们的错误指标进行平均,确定网格中表现最佳的 C,然后将此 C 用于所有训练数据并输出生成的模型吗?也就是说,使用上面的示例,对于网格中的 C=1 和 C=10,将对 5 个 ROC AUC 结果进行平均,如果 C=10 获胜,则将使用 C=10 在所有训练数据上重新运行模型而不使用 CV,并且该模型是输出?
我正在运行嵌套交叉验证并在内部交叉验证中调整超参数——有一个模型输出,我正在将其传输到我的测试集,但我还没有找到关于这个模型到底是什么的明确答案。
我手头不确定,也许可以发布到 R 用户组?
嗨,我把问题发布在 caret 的 GitHub 页面上,但似乎最好的参数会重新拟合到整个训练集,然后输出该模型(然后可以在测试集中用于预测)
“我们建议使用重采样来评估每个不同的参数值组合,以获得对每个候选模型性能的良好估计。一旦计算出结果,就选择“最佳”调整参数组合,并使用该值将最终模型拟合到整个训练集。”来自 https://bookdown.org/max/FES/model-optimization-and-tuning.html
此处:https://github.com/topepo/caret/issues/995
太棒了!
我喜欢阅读纸质书籍进行深入学习
谢谢。
先生,我需要您的帮助。
1) 这篇文章您能也用 python 发布吗?
2) 如何在 python 中执行网格搜索:自动网格?
3) 因为我只在 python 中找到了网格搜索:手动网格,而且我认为 python 中没有网格搜索:自动网格的概念,如果有任何替代方案或相同的功能,请告诉我。
是的,请看这篇文章
https://machinelearning.org.cn/how-to-tune-algorithm-parameters-with-scikit-learn/
先生,您说得完全正确,但我想从 statsmodels 运行 logit 模型并通过 RandomizedSearchCV 获取摘要。
import statsmodels.formula.api as smf
cv = RepeatedStratifiedKFold(n_splits=5,n_repeats=2,
random_state=True)
param_grid = {‘alpha’: sp_rand()}
# 创建并拟合 logit 模型,测试随机 alpha 值
logit_model=smf.logit(“Target~ ” + all_columns,train)
rsearch = RandomizedSearchCV(estimator=logit_model1, param_distributions=param_grid,cv=cv, n_iter=100) #param_distributions=param_grid
l1=rsearch.fit()
错误:fit() 缺少 1 个必需的位置参数:‘X’
但这里不需要 X,因为我们已经在上面拟合了一个公式。
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code