在本教程中,您将学习k-近邻算法,包括其工作原理以及如何在Python中从零开始实现它(不使用库)。
一种简单而强大的预测方法是使用与新数据最相似的历史示例。这就是k-近邻算法背后的原理。
完成本教程后,您将了解
- 如何一步步编写k-近邻算法。
- 如何在一个真实数据集上评估k-近邻算法。
- 如何使用k-近邻算法对新数据进行预测。
通过我的新书《从零开始的机器学习算法》启动您的项目,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2014年9月更新:本教程的原始版本。
- 2019年10月更新:从头开始完全重写。
用 Python 从零开始开发 K-近邻算法
图片来自维基百科,保留部分权利。
教程概述
本节将简要介绍我们将在本教程中实现的k-近邻算法以及我们将应用它的鲍鱼数据集。
k-近邻
k-近邻算法,简称KNN,是一种非常简单的技术。
它存储整个训练数据集。当需要预测时,它会从训练数据集中找到与新记录最相似的k个记录。然后,根据这些邻居进行汇总预测。
记录之间的相似性可以用多种方式衡量。可以使用特定于问题或数据的方法。通常,对于表格数据,一个很好的起点是欧几里得距离。
一旦找到邻居,可以通过返回最常见的输出或取平均值来进行汇总预测。因此,KNN可以用于分类或回归问题。
除了保存整个训练数据集之外,没有所谓的模型。由于在需要预测之前不进行任何工作,KNN通常被称为惰性学习方法。
鸢尾花物种数据集
在本教程中,我们将使用鸢尾花数据集。
鸢尾花数据集涉及根据鸢尾花的测量值预测花卉物种。
这是一个多类别分类问题。每个类别的观测数量是平衡的。有150个观测值,其中有4个输入变量和1个输出变量。变量名称如下:
- 花萼长度(厘米)。
- 花萼宽度(厘米)。
- 花瓣长度(厘米)。
- 花瓣宽度(厘米)。
- 类别
下面是前 5 行的样本。
|
1 2 3 4 5 6 |
5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa ... |
该问题的基线性能约为33%。
下载数据集并将其保存到当前工作目录中,文件名为“iris.csv”。
k-近邻算法(3个简单步骤)
首先,我们将在本节中开发算法的每个部分,然后我们将在下一节中将所有元素整合到一个应用于真实数据集的工作实现中。
本k-近邻教程分为3个部分
- 步骤1:计算欧几里得距离。
- 步骤2:获取最近邻居。
- 步骤3:进行预测。
这些步骤将教您实现和应用k-近邻算法来解决分类和回归预测建模问题的基础知识。
注意:本教程假定您正在使用Python 3。如果您需要安装Python的帮助,请参阅本教程:
我相信本教程中的代码也适用于Python 2.7,无需任何更改。
步骤1:计算欧几里得距离
第一步是计算数据集中两行之间的距离。
数据行大部分由数字组成,计算两行或数字向量之间距离的一种简单方法是绘制一条直线。这在2D或3D中是合理的,并且可以很好地扩展到更高维度。
我们可以使用欧几里得距离度量来计算两个向量之间的直线距离。它被计算为两个向量之间平方差之和的平方根。
- 欧几里得距离 = sqrt(sum i to N (x1_i – x2_i)^2)
其中x1是第一行数据,x2是第二行数据,i是在所有列上求和时特定列的索引。
对于欧几里得距离,值越小,两条记录越相似。值为0表示两条记录之间没有差异。
下面是一个名为euclidean_distance()的函数,它在Python中实现了这一点。
|
1 2 3 4 5 6 |
# 计算两个向量之间的欧几里得距离 def euclidean_distance(row1, row2): distance = 0.0 for i in range(len(row1)-1): distance += (row1[i] - row2[i])**2 return sqrt(distance) |
您可以看到,该函数假定每行的最后一列是输出值,并将其从距离计算中忽略。
我们可以用一个小的虚构分类数据集来测试这个距离函数。在构建KNN算法所需的元素时,我们将多次使用这个数据集。
|
1 2 3 4 5 6 7 8 9 10 11 |
X1 X2 Y 2.7810836 2.550537003 0 1.465489372 2.362125076 0 3.396561688 4.400293529 0 1.38807019 1.850220317 0 3.06407232 3.005305973 0 7.627531214 2.759262235 1 5.332441248 2.088626775 1 6.922596716 1.77106367 1 8.675418651 -0.242068655 1 7.673756466 3.508563011 1 |
下面是数据集的散点图,使用不同的颜色表示每个点的不同类别。
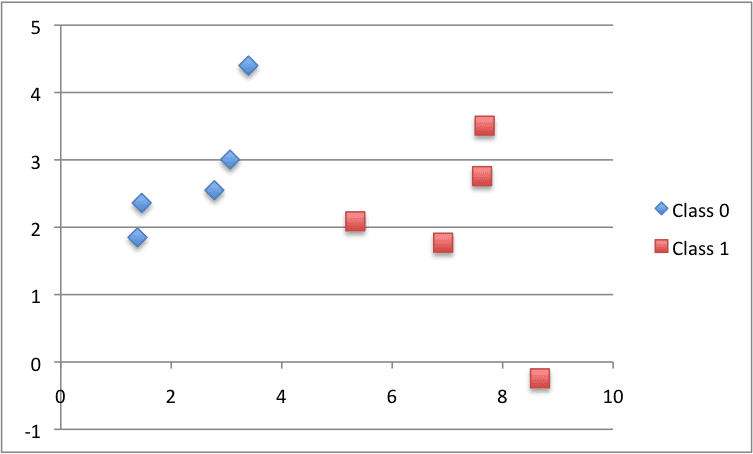
用于测试KNN算法的小虚构数据集的散点图
将这些放在一起,我们可以编写一个小的示例来测试我们的距离函数,通过打印第一行与所有其他行之间的距离。我们期望第一行与其自身的距离为0,这是一个很好的观察点。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 计算欧几里得距离的示例 from math import sqrt # 计算两个向量之间的欧几里得距离 def euclidean_distance(row1, row2): distance = 0.0 for i in range(len(row1)-1): distance += (row1[i] - row2[i])**2 return sqrt(distance) # 测试距离函数 dataset = [[2.7810836,2.550537003,0], [1.465489372,2.362125076,0], [3.396561688,4.400293529,0], [1.38807019,1.850220317,0], [3.06407232,3.005305973,0], [7.627531214,2.759262235,1], [5.332441248,2.088626775,1], [6.922596716,1.77106367,1], [8.675418651,-0.242068655,1], [7.673756466,3.508563011,1]] row0 = dataset[0] for row in dataset: distance = euclidean_distance(row0, row) print(distance) |
运行此示例将打印第一行与数据集中所有其他行(包括其自身)之间的距离。
|
1 2 3 4 5 6 7 8 9 10 |
0.0 1.3290173915275787 1.9494646655653247 1.5591439385540549 0.5356280721938492 4.850940186986411 2.592833759950511 4.214227042632867 6.522409988228337 4.985585382449795 |
现在是时候使用距离计算来定位数据集中的邻居了。
步骤2:获取最近邻居
数据集中新数据点的邻居是k个最近的实例,由我们的距离度量定义。
要找到数据集中新数据点的邻居,我们必须首先计算数据集中每个记录与新数据点之间的距离。我们可以使用我们上面准备的距离函数来完成此操作。
一旦计算出距离,我们必须根据它们与新数据的距离对训练数据集中的所有记录进行排序。然后,我们可以选择前k个作为最相似的邻居返回。
我们可以通过将数据集中每个记录的距离作为元组进行跟踪,按距离(降序)对元组列表进行排序,然后检索邻居来实现此目的。
下面是一个名为get_neighbors()的函数,它实现了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 定位最相似的邻居 def get_neighbors(train, test_row, num_neighbors): distances = list() for train_row in train: dist = euclidean_distance(test_row, train_row) distances.append((train_row, dist)) distances.sort(key=lambda tup: tup[1]) neighbors = list() for i in range(num_neighbors): neighbors.append(distances[i][0]) return neighbors |
您可以看到,上一步开发的euclidean_distance()函数用于计算每个train_row和新的test_row之间的距离。
train_row和距离元组的列表被排序,其中使用自定义键来确保元组中的第二个项目(tup[1])用于排序操作。
最后,返回一个包含与test_row最相似的num_neighbors个邻居的列表。
我们可以用上一节准备的小虚构数据集来测试这个函数。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# 获取实例邻居的示例 from math import sqrt # 计算两个向量之间的欧几里得距离 def euclidean_distance(row1, row2): distance = 0.0 for i in range(len(row1)-1): distance += (row1[i] - row2[i])**2 return sqrt(distance) # 定位最相似的邻居 def get_neighbors(train, test_row, num_neighbors): distances = list() for train_row in train: dist = euclidean_distance(test_row, train_row) distances.append((train_row, dist)) distances.sort(key=lambda tup: tup[1]) neighbors = list() for i in range(num_neighbors): neighbors.append(distances[i][0]) return neighbors # 测试距离函数 dataset = [[2.7810836,2.550537003,0], [1.465489372,2.362125076,0], [3.396561688,4.400293529,0], [1.38807019,1.850220317,0], [3.06407232,3.005305973,0], [7.627531214,2.759262235,1], [5.332441248,2.088626775,1], [6.922596716,1.77106367,1], [8.675418651,-0.242068655,1], [7.673756466,3.508563011,1]] neighbors = get_neighbors(dataset, dataset[0], 3) for neighbor in neighbors: print(neighbor) |
运行此示例将按相似度顺序打印数据集中与第一条记录最相似的3条记录。
正如预期的那样,第一条记录与自身最相似,并排在列表的首位。
|
1 2 3 |
[2.7810836, 2.550537003, 0] [3.06407232, 3.005305973, 0] [1.465489372, 2.362125076, 0] |
现在我们知道如何从数据集中获取邻居,我们可以使用它们进行预测。
步骤3:进行预测
从训练数据集中收集到的最相似邻居可以用于进行预测。
对于分类问题,我们可以返回邻居中最具代表性的类别。
我们可以通过对邻居的输出值列表执行`max()`函数来实现这一点。给定邻居中观察到的类别值列表,`max()`函数接收一组唯一的类别值,并对每个类别值在类别值列表中的计数进行调用。
下面是名为predict_classification()的函数,它实现了这一点。
|
1 2 3 4 5 6 |
# 使用邻居进行分类预测 def predict_classification(train, test_row, num_neighbors): neighbors = get_neighbors(train, test_row, num_neighbors) output_values = [row[-1] for row in neighbors] prediction = max(set(output_values), key=output_values.count) return prediction |
我们可以在上面虚构的数据集上测试这个函数。
下面是一个完整的例子。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# 预测示例 from math import sqrt # 计算两个向量之间的欧几里得距离 def euclidean_distance(row1, row2): distance = 0.0 for i in range(len(row1)-1): distance += (row1[i] - row2[i])**2 return sqrt(distance) # 定位最相似的邻居 def get_neighbors(train, test_row, num_neighbors): distances = list() for train_row in train: dist = euclidean_distance(test_row, train_row) distances.append((train_row, dist)) distances.sort(key=lambda tup: tup[1]) neighbors = list() for i in range(num_neighbors): neighbors.append(distances[i][0]) return neighbors # 使用邻居进行分类预测 def predict_classification(train, test_row, num_neighbors): neighbors = get_neighbors(train, test_row, num_neighbors) output_values = [row[-1] for row in neighbors] prediction = max(set(output_values), key=output_values.count) return prediction # 测试距离函数 dataset = [[2.7810836,2.550537003,0], [1.465489372,2.362125076,0], [3.396561688,4.400293529,0], [1.38807019,1.850220317,0], [3.06407232,3.005305973,0], [7.627531214,2.759262235,1], [5.332441248,2.088626775,1], [6.922596716,1.77106367,1], [8.675418651,-0.242068655,1], [7.673756466,3.508563011,1]] prediction = predict_classification(dataset, dataset[0], 3) print('Expected %d, Got %d.' % (dataset[0][-1], prediction)) |
运行此示例将打印预期的分类0以及从数据集中3个最相似的邻居预测的实际分类。
|
1 |
预期为0,实际为0。 |
我们可以想象如何改变`predict_classification()`函数来计算结果值的平均值。
现在我们已经拥有了使用KNN进行预测的所有部分。让我们将其应用于真实数据集。
鸢尾花物种案例研究
本节将KNN算法应用于鸢尾花数据集。
第一步是加载数据集并将加载的数据转换为数字,以便我们可以用于平均值和标准差计算。为此,我们将使用辅助函数load_csv()来加载文件,str_column_to_float()来将字符串数字转换为浮点数,以及str_column_to_int()来将类列转换为整数值。
我们将使用5折交叉验证来评估算法。这意味着每折将有150/5=30条记录。我们将使用辅助函数evaluate_algorithm()通过交叉验证评估算法,并使用accuracy_metric()计算预测的准确性。
开发了一个名为k_nearest_neighbors()的新函数,用于管理KNN算法的应用,首先从训练数据集中学习统计数据,然后使用它们对测试数据集进行预测。
如果您需要下面使用的数据加载函数的更多帮助,请参阅本教程
如果您需要更多关于使用交叉验证评估模型的方式的帮助,请参阅本教程
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 |
# 鸢尾花数据集上的k-近邻算法 from random import seed from random import randrange from csv import reader from math import sqrt # 加载 CSV 文件 def load_csv(filename): dataset = list() with open(filename, 'r') as file: csv_reader = reader(file) for row in csv_reader: if not row: continue dataset.append(row) return dataset # 将字符串列转换为浮点数 def str_column_to_float(dataset, column): for row in dataset: row[column] = float(row[column].strip()) # 将字符串列转换为整数 def str_column_to_int(dataset, column): class_values = [row[column] for row in dataset] unique = set(class_values) lookup = dict() for i, value in enumerate(unique): lookup[value] = i for row in dataset: row[column] = lookup[row[column]] return lookup # 查找每列的最小值和最大值 def dataset_minmax(dataset): minmax = list() for i in range(len(dataset[0])): col_values = [row[i] for row in dataset] value_min = min(col_values) value_max = max(col_values) minmax.append([value_min, value_max]) return minmax # 将数据集列重新缩放到 0-1 范围 def normalize_dataset(dataset, minmax): for row in dataset: for i in range(len(row)): row[i] = (row[i] - minmax[i][0]) / (minmax[i][1] - minmax[i][0]) # 将数据集分成 k 折 def cross_validation_split(dataset, n_folds): dataset_split = list() dataset_copy = list(dataset) fold_size = int(len(dataset) / n_folds) for _ in range(n_folds): fold = list() while len(fold) < fold_size: index = randrange(len(dataset_copy)) fold.append(dataset_copy.pop(index)) dataset_split.append(fold) return dataset_split # 计算准确率百分比 def accuracy_metric(actual, predicted): correct = 0 for i in range(len(actual)): if actual[i] == predicted[i]: correct += 1 return correct / float(len(actual)) * 100.0 # 使用交叉验证分割评估算法 def evaluate_algorithm(dataset, algorithm, n_folds, *args): folds = cross_validation_split(dataset, n_folds) scores = list() for fold in folds: train_set = list(folds) train_set.remove(fold) train_set = sum(train_set, []) test_set = list() for row in fold: row_copy = list(row) test_set.append(row_copy) row_copy[-1] = None predicted = algorithm(train_set, test_set, *args) actual = [row[-1] for row in fold] accuracy = accuracy_metric(actual, predicted) scores.append(accuracy) 返回 分数 # 计算两个向量之间的欧几里德距离 def euclidean_distance(row1, row2): distance = 0.0 for i in range(len(row1)-1): distance += (row1[i] - row2[i])**2 return sqrt(distance) # 定位最相似的邻居 def get_neighbors(train, test_row, num_neighbors): distances = list() for train_row in train: dist = euclidean_distance(test_row, train_row) distances.append((train_row, dist)) distances.sort(key=lambda tup: tup[1]) neighbors = list() for i in range(num_neighbors): neighbors.append(distances[i][0]) return neighbors # 使用近邻进行预测 def predict_classification(train, test_row, num_neighbors): neighbors = get_neighbors(train, test_row, num_neighbors) output_values = [row[-1] for row in neighbors] prediction = max(set(output_values), key=output_values.count) return prediction # kNN 算法 def k_nearest_neighbors(train, test, num_neighbors): predictions = list() for row in test: output = predict_classification(train, row, num_neighbors) predictions.append(output) return(predictions) # 在鸢尾花数据集上测试 kNN seed(1) filename = 'iris.csv' dataset = load_csv(filename) for i in range(len(dataset[0])-1): str_column_to_float(dataset, i) # 将类别列转换为整数 str_column_to_int(dataset, len(dataset[0])-1) # 评估算法 n_folds = 5 num_neighbors = 5 scores = evaluate_algorithm(dataset, k_nearest_neighbors, n_folds, num_neighbors) print('Scores: %s' % scores) print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores)))) |
运行示例将打印每个交叉验证折叠的平均分类准确率分数以及平均准确率分数。
我们可以看到,约 96.6% 的平均准确率显着优于 33% 的基线准确率。
|
1 2 |
分数:[96.66666666666667, 96.66666666666667, 100.0, 90.0, 100.0] 平均准确率:96.667% |
我们可以使用训练数据集来对新的观测值(数据行)进行预测。
这涉及到调用 `predict_classification()` 函数,并传入一个代表我们新观测值的行来预测类别标签。
|
1 2 3 |
... # 预测标签 label = predict_classification(dataset, row, num_neighbors) |
我们也可能想知道预测的类别标签(字符串)。
我们可以更新 `str_column_to_int()` 函数以打印字符串类别名称到整数的映射,这样我们就可以解释模型所做的预测。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 将字符串列转换为整数 def str_column_to_int(dataset, column): class_values = [row[column] for row in dataset] unique = set(class_values) lookup = dict() for i, value in enumerate(unique): lookup[value] = i print('[%s] => %d' % (value, i)) for row in dataset: row[column] = lookup[row[column]] return lookup |
下面列出了将这些内容结合起来的完整示例,展示了如何使用整个数据集的 KNN 并对新的观测值进行单个预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
# 使用鸢尾花数据集的 k-近邻进行预测 from csv import reader from math import sqrt # 加载 CSV 文件 def load_csv(filename): dataset = list() with open(filename, 'r') as file: csv_reader = reader(file) for row in csv_reader: if not row: continue dataset.append(row) return dataset # 将字符串列转换为浮点数 def str_column_to_float(dataset, column): for row in dataset: row[column] = float(row[column].strip()) # 将字符串列转换为整数 def str_column_to_int(dataset, column): class_values = [row[column] for row in dataset] unique = set(class_values) lookup = dict() for i, value in enumerate(unique): lookup[value] = i print('[%s] => %d' % (value, i)) for row in dataset: row[column] = lookup[row[column]] return lookup # 查找每列的最小值和最大值 def dataset_minmax(dataset): minmax = list() for i in range(len(dataset[0])): col_values = [row[i] for row in dataset] value_min = min(col_values) value_max = max(col_values) minmax.append([value_min, value_max]) return minmax # 将数据集列重新缩放到 0-1 范围 def normalize_dataset(dataset, minmax): for row in dataset: for i in range(len(row)): row[i] = (row[i] - minmax[i][0]) / (minmax[i][1] - minmax[i][0]) # 计算两个向量之间的欧几里德距离 def euclidean_distance(row1, row2): distance = 0.0 for i in range(len(row1)-1): distance += (row1[i] - row2[i])**2 return sqrt(distance) # 定位最相似的邻居 def get_neighbors(train, test_row, num_neighbors): distances = list() for train_row in train: dist = euclidean_distance(test_row, train_row) distances.append((train_row, dist)) distances.sort(key=lambda tup: tup[1]) neighbors = list() for i in range(num_neighbors): neighbors.append(distances[i][0]) return neighbors # 使用近邻进行预测 def predict_classification(train, test_row, num_neighbors): neighbors = get_neighbors(train, test_row, num_neighbors) output_values = [row[-1] for row in neighbors] prediction = max(set(output_values), key=output_values.count) return prediction # 使用 KNN 对鸢尾花数据集进行预测 filename = 'iris.csv' dataset = load_csv(filename) for i in range(len(dataset[0])-1): str_column_to_float(dataset, i) # 将类别列转换为整数 str_column_to_int(dataset, len(dataset[0])-1) # 定义模型参数 num_neighbors = 5 # 定义一个新的记录 row = [5.7,2.9,4.2,1.3] # 预测标签 label = predict_classification(dataset, row, num_neighbors) print('数据=%s, 预测: %s' % (row, label)) |
运行数据首先总结了类别标签到整数的映射,然后根据整个数据集拟合模型。
然后定义一个新的观测值(在本例中,我从数据集中取了一行),并计算预测标签。
在本例中,我们的观测值被预测为属于类别 1,我们知道它是“Iris-setosa”。
|
1 2 3 4 |
[鸢尾-维吉尼亚] => 0 [鸢尾-山鸢尾] => 1 [鸢尾-变色鸢尾] => 2 数据=[4.5, 2.3, 1.3, 0.3], 预测: 1 |
教程扩展
本节列出了您可能希望考虑调查的教程扩展。
- 调整 KNN。尝试越来越大的 `k` 值,看看是否可以提高算法在鸢尾花数据集上的性能。
- 回归。修改示例并将其应用于回归预测建模问题(例如,预测数值)。
- 更多距离度量。实现其他可用于查找相似历史数据的距离度量,例如汉明距离、曼哈顿距离和闵可夫斯基距离。
- 数据准备。距离度量受到输入数据尺度的强烈影响。尝试标准化和其他数据准备方法以改善结果。
- 更多问题。一如既往,在更多不同的分类和回归问题上尝试该技术。
进一步阅读
- 第 3.5 节 线性回归与 K-近邻的比较,第 104 页,《统计学习导论》,2014 年。
- 第 18.8 节 非参数模型,第 737 页,《人工智能:现代方法》,2010 年。
- 第 13.5 节 K-近邻,第 350 页,《应用预测建模》,2013 年
- 第 4.7 节,基于实例的学习,第 128 页,《数据挖掘:实用机器学习工具和技术》,第 2 版,2005 年。
总结
在本教程中,您学习了如何从头开始用 Python 实现 k-近邻算法。
具体来说,你学到了:
- 如何一步步编写k-近邻算法。
- 如何在一个真实数据集上评估k-近邻算法。
- 如何使用k-近邻算法对新数据进行预测。
下一步
采取行动!
- 遵循教程并从头开始实现 KNN。
- 将示例改编到另一个数据集。
- 遵循扩展并改进实现。
留下评论并分享您的经验。
了解如何从零开始编写算法!

没有库,只有 Python 代码。
...附带真实世界数据集的逐步教程
在我的新电子书中探索如何实现
从零开始实现机器学习算法
它涵盖了 18 个教程,包含 12 种顶级算法的所有代码,例如
线性回归、k-近邻、随机梯度下降等等……
最后,揭开
机器学习算法的神秘面纱
跳过学术理论。只看结果。






{kind=link}
杰森 –
我非常赞赏您的分步方法。您的解释使这份材料能够被广泛的受众理解。
继续保持出色的贡献。
谢谢 Damian!
如何使用 knn 填充缺失值???
训练一个模型来预测包含缺失数据的列,但不包括缺失数据。
然后使用训练好的模型来预测缺失值。
我是机器学习的新手。您能告诉我如何根据上述用户定义的 KNN 训练模型并使用训练好的模型进行进一步预测吗?
是否可以将 Jaccard 算法与 KNN 集成?
谢谢。
我推荐使用 scikit-learn,您可以从这里开始
https://machinelearning.org.cn/start-here/#python
这些预定义函数(实际后端代码)的定义在哪里可以找到??
GaussianNB()
LinearSVC(random_state=0)
KNeighborsClassifier(n_neighbors=3)
请帮忙!!
是的,你可以在 sklearn 的 github 项目中找到所有代码
https://github.com/scikit-learn/scikit-learn
Python 3 的一些更改
1.
print ‘训练集: ‘ + repr(len(trainingSet))
print ‘测试集: ‘ + repr(len(testSet))
print 需要与括号一起使用
print (“训练集:” + repr(len(trainingSet)))
print (“测试集:”+ repr(len(testSet)))
2. iteritems() 更改为 items()
sortedVotes = sorted(classVotes.iteritems(), key=operator.itemgetter(1), reverse=True)
应该是
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
感谢分享。
你能提供我使用球树算法的最近邻伪代码吗?
感谢您的建议,也许将来会考虑。
1. 我收到了错误消息“TypeError: unsupported operand type(s) for -: ‘str’ and ‘str'”
更改
distance += pow(((instance1[x]) – (instance2[x])), 2)
推广到
distance += pow((float(instance1[x]) – float(instance2[x])), 2)
谢谢。是的,这个例子假设是 Python 2.7。
标识符错误中的无效字符,我无法添加任何代码行。它给出了标签使用不一致的错误,但我没有。
我有一些可能对您有帮助的想法
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
感谢您分享这些信息,先生……
一篇非常有趣且清晰的文章。我还没有尝试过,但会在周末进行。
谢谢。
谢谢皮特,让我知道你的进展。
嘿,杰森,我读了多本书和教程,但你的解释最终让我明白了我在做什么。
期待你的更多教程。
谢谢艾伦!
嘿,杰森!
感谢这篇精彩的文章!
清晰直观的解释。我终于理解了 kNN 的背景。
附:
文章中存在一些代码错误。
1) 在 getResponse 中,应该是 “return sortedVote[0]” 而不是 sortedVotes[0][0]
2) 在 getAccuracy 中,应该是 “testSet[x][-1] IN predictions[x]” 而不是 IS。
谢谢瓦迪姆!
我认为代码是正确的,但也许我误解了你的评论。
如果你将 getResponse 更改为返回 sortedVote[0],你将得到类别和计数。我们不需要这个,我们只需要类别。
在 getAccuracy 中,我对类字符串之间的相等性(is)感兴趣,而不是集合操作(in)。
这有道理吗?
你好,
首先感谢您的信息丰富的教程。
我希望使用 KNN 实现回归。我有一个包含 4 个属性和第 5 个属性的数据集,我想预测它。
我只需创建一个函数来计算 neighbours[x][-1] 的平均值,还是应该以其他方式实现它?
提前感谢。
是的,这是一个很好的开始。
非常感谢这个例子!
不客气,马里奥。
感谢您关于 kNN 实现的帖子。
关于归一化的任何提示将不胜感激?
如果特征集包含名称、年龄、出生日期、ID 等字段怎么办?哪些算法可以很好地归一化这些特征?
嘿 PVA,好问题。
归一化只是将数值属性重新缩放为 0-1 之间。如果您愿意,scikit-learn 等工具可以为您完成,这里有一个方法:https://machinelearning.org.cn/rescaling-data-for-machine-learning-in-python-with-scikit-learn/
您可以使用编辑距离等方法计算字符串之间的距离,在这里了解更多:http://en.wikipedia.org/wiki/Edit_distance
出生日期 – 那么两个日期之间的距离可以是天、小时,或者您领域中任何有意义的单位。
如果您的数据库中没有“记录创建时间”,ID 可能只是作为“何时将条目添加到数据库”的某种间接标记。
希望这有帮助。
感谢这篇精彩的教程。
请问,有没有办法将模型保存为pkl文件或其他格式?
pkl 是一种 pickle 格式(通常),您可以使用 Python 的 pickle 模块进行保存和加载。请参考 Python 文档获取一些示例。它是 Python 原生的,但可能不兼容不同的机器/版本。因此,我们避免将其用于机器学习模型,因为担心它无助于与他人共享您的模型。例如,在 Tensorflow 中,使用 HDF5 格式代替。
万分感谢!
我在机器学习之旅中有很多起点,但很少有如此清晰的。
谢谢!
很高兴听到这个消息,兰德里!
你好,
当我运行代码时,它显示
ValueError: 无法将字符串转换为浮点数:'sepallength'
我应该怎么做才能运行程序。
请尽快帮助我……
提前致谢……
你好 kumaran,
我相信示例代码仍然运行良好。如果我将教程中的代码复制粘贴到一个名为 knn.py 的新文件中,并将 iris.data 下载到同一个目录中,那么使用 Python 2.7 运行示例对我来说是正常的。
您是否以某种方式修改了示例?
这是因为你的代码的第一行可能包含每个列的信息,
转换
for x in range(len(dataset)-1)
推广到
for x in range(1,len(dataset)-1)
它会跳过第一行,从第二行开始读取数据
使用
for x in range(1,len(dataset))
如果你也跳过了最后一行
嗨,Jabson,
感谢您的回复……
我正在使用 Anaconda IDE 3.4。
是的,它对鸢尾花数据集运行良好,如果我尝试放入其他数据集,它会显示值错误,因为这些数据集包含字符串和整数……
例如森林火灾数据集。
X Y 月 日 FFMC DMC DC ISI temp RH 风 雨 面积
7 5 mar fri 86.2 26.2 94.3 5.1 8.2 51 6.7 0 0
7 4 oct tue 90.6 35.4 669.1 6.7 18 33 0.9 0 0
7 4 oct sat 90.6 43.7 686.9 6.7 14.6 33 1.3 0 0
8 6 mar fri 91.7 33.3 77.5 9 8.3 97 4 0.2 0
8 6 mar sun 89.3 51.3 102.2 9.6 11.4 99 1.8 0 0
是否也可以用您的代码对这些数据集进行分类?
如果有一些其他分类器代码示例,请提供给我……
你好 KUMARAN
你得到你评论中提到的问题的解决方案了吗?我也面临同样的问题。请帮助我或提供解决方案,如果你有的话……
一篇关于 knn 的出色文章。它使概念如此清晰。
谢谢 sanksh!
我喜欢它解释的方式,简单明了。干得好。
谢谢!
杰森,很棒的文章!!简洁明了。
杰森,好文章。我是机器学习新手软件工程师。您循序渐进的方法让学习变得轻松有趣。虽然 Python 对我来说是新的,但它变得非常容易,因为我可以运行小段代码,而不是一次性尝试理解整个程序。
感谢您的辛勤工作。继续努力。
谢谢拉朱。
这对我来说太棒了。我找不到更好的了
我也遇到了Kumaran的同样问题。检查后,我认为“无法将字符串转换为浮点数”的问题是第一行是“sepal_length”等。Python无法转换它,因为它完全是字符串。所以只需删除它或稍微修改一下代码。
你好,
非常感谢这篇详细的文章。对扩展思路有什么线索吗?
谢谢,
RK
嗨——我想知道我们如何在不随机打乱的情况下将数据输入系统,因为我正在尝试对数据的最后一行进行预测?
我们是否删除
if random.random() < split
并替换为类似
if len(trainingSet)/len(dataset) < split
# 如果 < 0.67 则添加到训练集,否则添加到测试集
我问的原因是我知道我想要预测什么数据,而这样一来,由于随机选择过程,它似乎可以使用我想要在训练集中预测的数据。
我也有和你一样的困境,我进行了反复试验,现在我似乎无法正确地省略代码以创建预测。
我不是软件工程师,也没有计算机科学背景。我对数据科学和机器学习也很陌生,我刚刚开始学习Python和R,但体验很棒!
非常感谢你,Jason!
这篇文章非常精彩。作为一名对机器学习感兴趣的计算物理学研究生,这篇文章的水平恰到好处,让我可以快速浏览,亲自动手,并从中获得乐趣。
非常感谢您提供这篇文章。我很期待看到您网站上的其余内容。
谢谢你的文章!
我希望自己编写 KNN Python 程序,这真的很有帮助!
非常感谢您的分享。
不过您没有提到的一点是您是如何选择 k=3 的。
为了了解准确率对 k 的敏感程度,我编写了一个“筛选”函数,该函数在训练集上通过使用留一交叉验证准确率作为排名来迭代 k。
您还有其他建议吗?
这真的很有帮助。谢谢你!
杰森,这是一个非常有用的教程。谢谢你。
请问您能告诉我如何修改您的代码,使其适用于包含字符串(即文本)而非数值的数据集吗?
我非常渴望在文本数据上尝试这个算法,但似乎在网上找不到一篇不错的文章。
非常感谢您的帮助。
Mark
不错的教程!在解释 KNN 方面非常有帮助——Python 比数学运算更容易理解。不过有一点——Python 的 range 函数的用法是,不包含最后一个元素。
在 loadDataset() 中,您有
for x in range(len(dataset)-1):这应该直接是
for x in range(len(dataset)):否则,数据的最后一行将被省略!
这会超出索引范围..
非常感谢。
很棒
非常感谢
太棒了!我尝试了许多书籍和文章来开始学习机器学习。您的文章是第一篇清晰的!非常感谢您!请继续教我们!)
谢谢 Gleb!
嗨,Jason,
感谢这个精彩的介绍!我有两个与我的这项研究相关的问题。
首先是,这个代码中是如何实现优化的?
其次是,如上所述,这个算法的归纳强度如何,这对于一台会思考的机器来说会是一种有用的归纳吗?
非常感谢!
你好,Jason;
这是一个很棒的教程,对我帮助很大,感谢您的巨大努力,但我有一个问题,如果我想将数据随机分成100个训练集和50个测试集,并且我想在单独的文件中生成它们的值而不是打印总数怎么办?因为我需要在hugin中测试它们
非常感谢!
嗨,Jason,
这是一个非常棒的教程。您的文章非常清晰,但我有一个问题。
当我运行代码时,我看到了正确的分类。
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
…
然而,准确率是0%。我运行了准确率测试,但代码没有问题。
我如何修复准确率?我在哪里犯了错误?
感谢回复和您的帮助。
嗨,我通过这样做解决了这个问题
最初,在第 5 步中,在 getAccuracy 函数中,您有
…
for x in range(len(testSet))
if testSet[x][-1] is predictions[x]
correct += 1
…
这里的关键在于 IF 语句
if testSet[x][-1] is predictions[x]
将“IS”更改为“==”,这样 getAccuracy 现在就变成了
…
for x in range(len(testSet))
if testSet[x][-1] == predictions[x]
correct += 1
…
这解决了问题,并且运行正常!!
我认为设置 K 值对预测的准确性起着重要作用。如何确定“K”的最佳值。请提供一些最佳实践建议?
亲爱的,如何使用 Excel 表格中的数据进行多类别分类:数字图像(非手写)及其对应的 Excel 列中的图像标签?
您的本教程完全基于数值数据,只是给我提供了关于图像的想法。
非常清晰的解释和分步操作使得这很容易理解。我不确定getResponse函数中sortedVotes列表为什么被反转,我认为getResponse应该返回字典classVotes中最常见的键。如果您反转列表,这不是返回字典中最不常见的键吗?
我不知道如何为 3 个类别获取 k 近邻,例如 [1,1,2,2,0] 的平票。对于两个类别,使用 k=奇数时,我们可以找到两个类别的最大票数,但如果我们选择三个类别,就会出现平票。
提前感谢
你好
感谢你为此付出的巨大努力,伙计
我有一些基本问题
1: 我打开了“iris.data”文件,它只是一个 HTML 窗口。如何下载?
2: 如果我使用 HTML 页面的复制粘贴技术。粘贴到哪里?
您可以使用浏览器中的“文件”->“另存为”来保存文件,或者复制文本并将其粘贴到新文件中,然后将其保存为教程中预期的“iris.data”文件。
希望这能有所帮助。
Jason。
这是一个非常简单但全面的解释。感谢您的努力。
您能建议我如何绘制 3 个类别的散点图吗?如果您能上传代码,那就太好了。提前感谢!
如果我们想使用 KNN 将文本分类,该怎么办?
例如,给定的一段文本定义了 {政治、体育、技术}
我正在从事一个分类 RSS 提要的项目
如何在不使用 csv 库的情况下下载文件?
很好的解释,Jason。真的很感谢你的工作。
谢谢 Avinash。
嗨!非常全面的教程,我喜欢它!
如果某些特征比其他特征对确定正确类别更重要,您会怎么做?
谢谢 Agnes。
通常在构建模型之前进行特征选择是个好主意
https://machinelearning.org.cn/an-introduction-to-feature-selection/
你好,
我收到此错误消息。
训练集:78
测试集:21
—————————————————————————
TypeError Traceback (most recent call last)
in ()
72 print(‘Accuracy: ‘ + repr(accuracy) + ‘%’)
73
—> 74 main()
在 main() 中
65 k = 3
66 for x in range(len(testSet))
—> 67 neighbors = getNeighbors(trainingSet, testSet[x], k)
68 result = getResponse(neighbors)
69 predictions.append(result)
在 getNeighbors(trainingSet, testInstance, k) 中
27 length = len(testInstance)-1
28 for x in range(len(trainingSet))
—> 29 dist = euclideanDistance(testInstance, trainingSet[x], length)
30 distances.append((trainingSet[x], dist))
31 distances.sort(key=operator.itemgetter(1))
在 euclideanDistance(instance1, instance2, length) 中
20 distance = 0
21 for x in range(length)
—> 22 distance += pow(float(instance1[x] – instance2[x]), 2)
23 return math.sqrt(distance)
24
TypeError: unsupported operand type(s) for -: ‘str’ and ‘str’
你能帮忙吗?
谢谢你
不清楚,可能是从帖子复制粘贴错误?
谢谢你的回答,
就好像我不能在这里进行减法一样,这是错误消息
TypeError: unsupported operand type(s) for -: ‘str’ and ‘str’
我直接从教程复制/粘贴了代码
我很高兴能向你表达我的感激之情。我一直在寻找好的书籍来解释机器学习 (KNN),但我遇到的那些书都不像这个出色而令人惊叹的逐步解释那样清晰和简单。你确实是一位杰出的老师
谢谢。
嗨,Jason,我真的很想进入机器学习领域。我想为我目前就读的计算机工程专业的最后一年做一个大项目。人们总是说这对于一个本科生来说太遥不可及了,这让我很沮丧。我想证明他们是错的。我没有太多时间(从今天起 6 个月)。我真的想做一些有用的东西。您能给我发送一些链接,帮助我确定一个机器学习项目吗?请……非常感谢
import numpy as np
from sklearn import preprocessing, cross_validation, neighbors
import pandas as pd
df= np.genfromtxt(‘/home/reverse/Desktop/acs.txt’, delimiter=’,’)
X= np.array(df[:,1])
y= np.array(df[:,0])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,y,test_size=0.2)
clf = neighbors.KNeighborsClassifier()
clf.fit(X_train, y_train)
ValueError: Found arrays with inconsistent numbers of samples: [ 1 483]
然后我尝试使用此代码重新塑形:df.reshape((483,1))
我再次收到此错误“ValueError: total size of new array must be unchanged”
提前感谢……。
嗨,Jason,
很棒的教程,非常容易理解。谢谢!
不过有一个问题。你写道
“此外,我们希望控制哪些字段包含在距离计算中。具体来说,我们只想包含前 4 个属性。一种方法是将欧几里德距离限制为固定长度,忽略最终维度。”
您能更详细地解释一下这里的意思吗?为什么当我们想包含所有 4 个属性时,最终维度被忽略了?
非常感谢,
卡罗琳
这段话的要旨是,我们只想计算输入变量的距离,而不包括输出变量。
原因是当我们有新数据时,我们不会有输出变量,只有输入变量。我们的工作将是找到与新数据最相似的 k 个实例,并发现要预测的输出变量。
在特定情况下,鸢尾花数据集有 4 个输入变量,第 5 个是类别。我们只想使用前 4 个变量计算距离。
我希望这能让事情更清楚。
嗨,杰森!你展示的步骤很棒。你有没有关于 Matlab 中相同内容的文章?
谢谢你。
谢谢 Pranav,
抱歉,目前我没有 Matlab 示例。
我见过最好的算法教程!非常感谢!
谢谢萨拉,很高兴听到这个消息。
详细的解释,我能够很好地理解算法/代码!尝试使用我自己的数据集(.csv 文件)实现相同的操作。
loadDataset(‘knn_test.csv’, split, trainingSet, testSet)
能够执行并获取小型数据集(csv 文件中包含 4-5 行和列)的输出。
当我尝试使用相同代码处理一个包含 24 列(输入)和 12,000 行(样本)的更大数据集时,我收到以下错误
TypeError: unsupported operand type(s) for -: ‘str’ and ‘str’
错误消息中指出了以下行
distance += pow((instance1[x] – instance2[x]), 2)
dist = euclideanDistance(testInstance, trainingSet[x], length)
neighbors = getNeighbors(trainingSet, testSet[x], k)
main()
任何帮助或建议都将不胜感激。提前感谢。
谢谢 Nivedita。
也许加载的数据需要从字符串转换为数值?
谢谢 Jason 的回复。数据集中没有字符串/非数值。这是一个包含 24 列(输入)和 12,083 行(样本)的 csv 文件。
还有其他建议吗?
感谢帮助。
理解了,Nivedita,但请确认加载的数据在内存中存储为数值。将您的数组打印到屏幕上,和/或在每列的特定值上使用 type(value)。
在 Golang 中实现了这一点。
请查看:https://github.com/vedhavyas/machine-learning/tree/master/knn
任何反馈都非常感谢。
还计划在 Golang 中实现尽可能多的算法
干得好 Vedhavyas。
感谢您的巨大努力和实现,但我认为您需要在欧几里得距离计算之前添加归一化步骤。
很好的建议,谢谢 Baris。
在这种情况下,所有输入变量都具有相同的尺度。但是,我同意,当输入变量的尺度不同时——甚至通常在它们不不同时——归一化都是一个重要的步骤。
很棒的文章!如果您在代码中添加一些注释;预览数据及其结构;以及一个关于归一化的步骤,即使这个数据集不需要,它会更加完善。
很好的建议,谢谢 Sisay。
你好,我有一些这样的错误
回溯(最近一次调用)
文件“C:/Users/FFA/PycharmProjects/Knn/first.py”,第 80 行,在
main()
文件“C:/Users/FFA/PycharmProjects/Knn/first.py”,第 65 行,在 main
loadDataset(‘iris.data’, split, trainingSet, testSet)
文件“C:/Users/FFA/PycharmProjects/Knn/first.py”,第 10 行,在 loadDataset
dataset = list(lines)
_csv.Error:迭代器应返回字符串,而不是字节(您是否以文本模式打开文件?)
怎么了?如何解决错误?
更改此行
至此
看看有没有什么不同。
我也有同样的问题,我修改了上一行,但仍然没有用!!
我如何使用 matplotlib 绘制结果数据集分类器,谢谢
好问题,抱歉我手头没有示例。
我建议使用一个简单的二维数据集并使用散点图。
你好,
iris.data 网站链接无法访问。您能否将其重新上传到其他网站?谢谢
抱歉,托管数据集的 UCI 机器学习库目前似乎已关闭。
这里有一个包含所有数据集的网站备份
http://mlr.cs.umass.edu/ml/
我读过的最好的文章之一!一切都解释得如此完美……非常感谢!!!
加布里埃拉,很高兴听到这个消息。
很棒的教程,在 Python3 中运行良好,不得不将 getResponse 方法中的 iteritems 更改为 .items()
第 63 和 64 行
print (“Train set: ” + repr(len(trainingSet)))
print (“Test set: ” + repr(len(testSet)))
总的来说很棒的教程,谢谢你 🙂
谢谢 Abdallah。
你好,
首先,感谢这个信息量很大的教程。
其次,与您约 98% 的准确率相比,我在每个 k 值下都获得了约 65% 的准确率。您能告诉我这是否正常,如果不是,我可能犯了哪些常见错误?
谢谢 🙂
听到这个消息我很难过。
也许是不同版本的 Python(3 而不是 2.7?),或者复制粘贴错误?
嗨,Jason,这篇文章太棒了,它让我对 KNN 有了清晰的认识,而且非常易读。只想感谢你的出色工作。太棒了!!
我很高兴你觉得它有用!
你好,
感谢你的文章.. ?
我有些问题想问你..
编码的准确性是否表示两组分类的准确性?如果我想查看真阳性分类的准确性怎么办?如何编码?
先谢谢了
是的 Meaz,准确性是针对整个问题或两组的。
你可以将其更改为报告一个或另一个组的准确性,但我手头没有现成的代码片段给你。
超棒的文章!
在阅读了大量文章,其中在第二段我就迷失了方向之后,这篇文章就像是在向一个刚接触代数的人解释勾股定理!
请继续这样做,Jason
很高兴听到,Neeraj。
这是一个很棒的教程,请继续努力。我正在尝试使用 KNN 为我的 DBSCAN 算法生成 epsilon。我的数据集是时间序列。它只有一个特征,被分解成不同的时间窗口。我想知道是否有链接可以像这样清楚地解释此类问题。你认为 KNN 可以预测 epsilon 吗,因为我的每一行都有一个唯一的 ID,而不是 iris 数据集中的 setosa 等。
我不知道 Afees,我建议你试试看。
嗨 Jason
我正在 R 中开发类似的解决方案,但在 KNN 训练过程中遇到了问题
你看到了什么问题,Ahmad?
非常感谢,它确实帮助我理解了 KNN 的概念。
但是当我运行这段代码时,我得到了一个错误,我无法解决。你能帮我一下吗
import csv
import random
def loadDataset(filename, split, trainingSet=[] , testSet=[])
with open(filename, ‘rb’) as csvfile
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset))
for y in range(4)
dataset[x][y] = float(dataset[x][y])
if random.random() < split
trainingSet.append(dataset[x])
else
testSet.append(dataset[x])
trainingSet=[]
testSet=[]
loadDataset('iris.data', 0.66, trainingSet, testSet)
print 'Train: ' + repr(len(trainingSet))
print 'Test: ' + repr(len(testSet))
IndexError Traceback (最近一次调用)
in ()
15 trainingSet=[]
16 testSet=[]
—> 17 loadDataset(‘/home/emre/SWE546_DataMining/iris’, 0.66, trainingSet, testSet)
18 print ‘Train: ‘ + repr(len(trainingSet))
19 print ‘Test: ‘ + repr(len(testSet))
in loadDataset(filename, split, trainingSet, testSet)
7 for x in range(len(dataset))
8 for y in range(4)
—-> 9 dataset[x][y] = float(dataset[x][y])
10 if random.random() < split
11 trainingSet.append(dataset[x])
IndexError: 列表索引超出范围
解决了,谢谢
很高兴听到这个消息。
你是怎么解决的?
你好 jason,
我在 return math.sqrt(distance) 和 main() 中未定义的变量中都遇到了语法错误
听到这个消息很抱歉,具体是什么错误?
我应该如何从用户那里获取 testSet 作为输入,然后将我的预测打印为输出?
太棒了!我无法形容这对我理解算法有多大帮助,这样我就可以编写自己的 C# 版本了。非常感谢!
很高兴听到!
你好,
我遇到了一个问题,我需要在图像中检测和识别一个对象(在我的案例中是一个徽标)。我的图像是某种扫描文档,主要包含文本、签名和徽标。我感兴趣的是定位徽标并识别它是哪个徽标。
我的问题似乎比大多数对象识别问题更容易,因为徽标总是以相同的角度出现,只有比例和位置会变化。任何关于如何进行的帮助都将受到欢迎,因为我现在已经束手无策了。
谢谢
听起来不错,Mark。
我期望 CNN 在这个问题上表现良好,一些计算机视觉方法可能会进一步提供帮助。
嗨 Jason,我已按照你的教程操作,现在我正在尝试将其更改为运行我自己的文件而不是 iris 数据集。我一直收到错误
lines = csv.reader(csvfile)
NameError: name 'csv' is not defined
我所做的只是将第 62-64 行从
loadDataset(‘iris.data’, split, trainingSet, testSet)
print ‘训练集: ‘ + repr(len(trainingSet))
print ‘测试集: ‘ + repr(len(testSet))
到
loadDataset('fvectors.csv', split, trainingSet, testSet)
print( 'Train set: ' + repr(len(trainingSet)))
print( 'Test set: ' + repr(len(testSet)))
我也尝试过使用 fvectors 而不是 fvectors.csv,但也没有成功。你知道哪里出了问题吗?
看起来你的 python 环境可能没有正确安装。
考虑尝试这个教程
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
嗨 Jason,我漏了一个 import,一个愚蠢的错误。但现在我收到这个错误
_csv.Error:迭代器应返回字符串,而不是字节(您是否以文本模式打开文件?)
有什么想法吗?
我通过更改解决了这个问题
with open(‘fvectors.csv’, ‘rb’) as csvfile
推广到
with open(‘fvectors.csv’, ‘rt’) as csvfile
但现在我收到这个错误。
dataset[x][y] = float(dataset[x][y])
ValueError: 无法将字符串转换为浮点数
它似乎不喜欢我的数据头或标签,但标签对于代码的预测与实际部分来说不是必不可少的吗?
不错。
仔细检查你是否使用了正确的数据文件。
你好,Thomas,我也有同样的问题。我将“rb”改成了“rt”。我得到了错误“dataset[x][y] = float(dataset[x][y])
ValueError: could not convert string to float: 'sepal_length',显然这是由 header 引起的,你是怎么解决的?
考虑以 ASCII 格式打开文件 open(filename, 'rt')。这在 Python 3 中可能效果更好。
嗨 Jason
非常感谢如此精彩的 KNN 教程。
当我运行这段代码时,我发现了一个错误
distance += pow((instance1[x] – instance2[x]), 2)
TypeError: unsupported operand type(s) for -: ‘str’ and ‘str’
你能帮我解决这个错误吗?
谢谢
distance += pow((float(instance1[x]) – float(instance2[x])), 2)
你好,我有一些带有经纬度的邮政编码点(Tzip)。但这些点可能/可能不会落在真实的邮政编码多边形(truezip)内。我想做 k 最近邻居来查看 Tzip 点的 k 个邻居中哪个邮政编码占多数。我的意思是,如果 Tzip 77339 的 3 个邻居说 77339、77339、77152.. 那么多数投票将把类别确定为 77339。我希望 Tzip 和 truezip 作为名义变量。我可以用你的代码来做这个吗?我刚开始学习 python...提前感谢。
tweetzip, lat, long, truezip
77339, 73730.689, -990323 77339
77339, 73730.699, -990341 77339
77339, 73735.6, -990351 77152
也许吧,你可能需要根据你的例子进行调整。
考虑使用 sklearn 中的 KNN,所需的代码会少很多
https://machinelearning.org.cn/spot-check-classification-machine-learning-algorithms-python-scikit-learn/
感谢您的回复。我尝试按照您的建议使用 sklearn。但是对于行“kfold=model_selection.KFold(n_splits=10,random_state=seed)”,它显示了错误“seed is not defined”。
而且我认为(不确定我是否正确)它还将所有变量都视为数字变量……但我希望使用 2 个数字变量(lat/long)计算最近邻距离,并沿每一行获得结果。
我该怎么办?
def getNeighbors(trainingSet, testInstance, k)
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet))
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k)
neighbors.append(distances[x][0])
return neighbors
在这个函数中,要么“length = len(testInstance)-1”中的-1不应该存在,要么
testInstance = [5, 5, 5] 应该在其最后一个索引处包含一个字符项?
我说的对吗?
是的,我相信是这样。
谢谢
请问有没有人有与人类行为相关的数据集,请分享给我
考虑搜索 kaggle 和 uci 机器学习仓库。
你好,你能告诉我 getResponce 中你到底在逐行做什么吗?因为我在 Java 中做这个,但不知道到底该怎么做。
谢谢
你好,
我正在尝试在 Anaconda Python —–Spyder 中运行您的代码。
我遇到了错误
(1) AttributeError: 'dict' object has no attribute 'iteritems'
(2) filename = 'iris.data.csv'
with open(filename, ‘rb’) as csvfile
最初在加载和打开数据文件时,它显示了一个错误,例如
错误:迭代器应该返回字符串,而不是字节(您是否以文本模式打开文件?)
当我将 rb 改为 rt 时,它工作了……我不知道以后是否会产生问题……
请尽快回复
谢谢
第一个错误可能是因为示例是为 Python 2.7 开发的,而你正在使用 Python 3。我希望将来能为 Python 3 更新示例。
是的,在 Python 3 中,将其更改为 'rt' 以文本文件形式打开。
嗨,对于 python 3
只需替换此行 (47)
sortedVotes = sorted(classVotes.iteritems(), key=operator.itemgetter(1), reverse=True)
使用此行
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
它在 def getResponse(neighbors) 函数中
谢谢 Ivan。
我在这篇文章中没有找到任何关于性能的内容。是不是性能真的很差?
假设我们有一个包含 100,000 个条目的训练集,以及一个包含 1000 个条目的测试集。那么欧几里得距离应该计算 10^8 次吗?有什么解决方法吗?
是的,你可以使用更有效的距离度量(例如,去掉平方根)或使用高效的数据结构来跟踪距离(例如,kd-树/球体)
太棒了!!谢谢你 🙂
如果你正在使用 Python 3,
使用
1.#代替 rb
with open(filename, ‘r’) as csvfile
2. #代替 iteritems。
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
谢谢 Vipin!
你好 Jason,
好文章。我对 KNN 的底层原理理解了很多。但有一点。在 scikit learn 中,我们分两步使用 KNN 从训练到预测。
步骤 1:拟合分类器
步骤 2:预测
在拟合部分,我们没有传入测试数据。只传入了训练数据,因此我们可以看到它在哪里训练,在哪里测试。相对于您关于朴素贝叶斯实现的其他博客文章,计算均值和标准差的部分可以认为是拟合/训练部分,而使用高斯正态分布的部分可以认为是测试/预测部分。
然而,在这个实现中我看不出这种区别。您能告诉我哪一部分应该被认为是训练,哪一部分是测试吗?我问这个问题的原因是因为与 scikit-learn 的流程相关联总是很重要的,这样我们可以更好地理解。
很好的问题。
knn 没有训练,因为没有模型。数据集就是模型。
谢谢回复…scikit learn 的情况也一样吗?那么在 Scikit Learn 中拟合 KNN 模型时到底发生了什么?
是的,是一样的。
我没什么期望。也许将数据集存储在用于搜索的有效结构中(例如 kdtree)。
谢谢…这看起来很有趣…顺便说一下…我真的很喜欢你的方法…除了你的电子书,你认为我还需要哪些材料(视频/书籍)才能在深度学习和 NLP 方面取得优异成绩?我想转行成为一名 NLP 工程师。
多练习解决问题,培养真实可用的技能。
您认为我在哪里可以找到最能培养真实可用技能的问题?Kaggle??还是其他地方?
请看这篇文章
https://machinelearning.org.cn/get-started-with-kaggle/
好文章。你为什么不规范化数据?
好问题。因为 iris 数据集中的所有特征都具有相同的单位。
嗨 Jason,
在您的电子书“machine_learning_mastery_with_python”第 11 章(Spot-Check Classification Algorithms)中,您通过使用 scikit learn KNeighborsClassifier 类解释了 KNN。我想知道您在这里详细解释的那个与 KNeighborsClassifier 类之间的区别。对于机器学习从业者来说,这可能是一个非常基本的问题,因为我刚接触机器学习,并且正在尝试理解不同方法的目的。
谢谢
Golam Sarwar
这里的教程旨在帮助理解 kNN 方法的工作原理。
在实际应用中,我强烈建议您使用 sklearn 等库中的实现。
主要原因是避免错误和提高性能。在此了解更多信息
https://machinelearning.org.cn/dont-implement-machine-learning-algorithms/
谢谢…..
很好的解释和很棒的教程,我希望你能有其他关于其他分类算法的博客文章,就像这个一样
谢谢……Jason
谢谢。
我当然有,使用博客搜索功能。
嗨,Jason,
解释得很好!!
你能否也向我们展示相同的(KNN)算法在 Java 中的实现?
感谢您的建议,也许将来会考虑。
谢谢 Jason
不客气。
嗨,Jason,
每次尝试都会得到不同的准确性、FP、TP、FN、TN 吗?我使用的是相同的数据。
是的,请参阅此帖子以了解为什么在机器学习中会出现这种情况
https://machinelearning.org.cn/randomness-in-machine-learning/
谢谢 Jason。您可以在帖子中添加以下解释,使其更清晰
我发现不同的准确度是由 loadDataset 函数中的以下行引起的
if random.random() randomized.csv
你好,
我正在使用该函数而不是 getAccuracy。它给出了 TP、TN、FP、FN。
def getPerformance(testSet, predictions)
tp = 0
tn = 0
fp = 0
fn = 0
for x in range(len(testSet))
if testSet[x][-1] == predictions[x]
if predictions[x] == “yes”
tp += 1
else
tn += 1
else
if predictions[x] == “yes”
fp += 1
else
fn += 1
performance = [ ((tp/float(len(testSet))) * 100.0), ((tn/float(len(testSet))) * 100.0), ((fp/float(len(testSet))) * 100.0), ((fn/float(len(testSet))) * 100.0) ]
return performance
嗨 Barrys,
以下代码行检查的是什么 --> if predictions[x] == 'yes'
似乎它总是假的……
if predictions[x] == “yes”
tp += 1
else
tn += 1
这是我在任何博客文章中见过的关于任何主题的最佳教程。它非常容易理解。代码正确且没有过时。我喜欢所有内容的结构方式。它有点遵循 TDD 方法,逐步构建生产代码,并在此过程中测试每个步骤。为您的出色工作点赞!这确实很有帮助。
谢谢!
我在读取数据集时遇到问题,你能告诉我问题出在哪里吗?
import pandas as pd
import numpy as np from sklearn import preprocessing, neighbors from sklearn.model_selection import train_test_split import pandas as pd
df = np.read_txt(‘C:\Users\sms\Downloads\NSLKDD-Dataset-master\NSLKDD-Dataset-master\KDDTrain22Percent.arff’) df.replace(‘?’ , -99999, inplace=True) df.drop([‘class’], 1, inplace=True)
x = np.array(df.drop([‘class’],1)) y = np.array(df[‘class’])
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2)
clf = neighbors.KNieghborsClassifier() clf.fit(x_train, y_train)
accuracy = clf.score(x_test, y_test) print(accuracy)
问题是什么?
请上传使用元启发式萤火虫算法进行特征选择的 Python 代码
感谢您的建议。
很好,我为您添加了一些 pre 标签。
当我实现您的代码时,预测准确率似乎非常令人失望?我哪里出错了?
> 预测值='Iris-versicolor',实际值='Iris-setosa'
准确率:35.294117647058826%
# python 3 实现
import random
import csv
split = 0.66
with open(‘iris-data.txt’) as csvfile
lines = csv.reader(csvfile)
dataset = list(lines)
random.shuffle(dataset)
print(len(dataset))
div = int(split * len(dataset))
train = dataset[:div] # 分割 150 * .66 = 99
print(“这是训练数据的数量 ” + str(len(train)))
test = dataset[div:] # 测试数据 = 150-99 = 51
print(“这是测试数据的数量 ” + str(len(test)))
import math
# 两个数字数组之间平方差之和的平方根
def euclideanDistance(instance1, instance2, length)
distance = 0
for x in range(length)
# print(instance1[x])
distance += pow((float(instance1[x]) – float(instance2[x])), 2)
return math.sqrt(distance)
import operator
# distances = []
def getNeighbors(trainingSet, testInstance, k)
distances = []
length = len(testInstance) – 1
for x in range(len(trainingSet))
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k)
neighbors.append(distances[x][0])
return neighbors
classVotes = {}
def getResponse(neighbors)
# classVotes = {}
for x in range(len(neighbors))
response = neighbors[x][-1]
if response in classVotes
classVotes[response] += 1
else
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0]
def getAccuracy(testSet, predictions)
correct = 0
for x in range(len(testSet))
# print(predictions[x])
if testSet[x][-1] == predictions[x]
correct += 1
return (correct / float(len(testSet))) * 100.0
predictions = []
k = 3
for x in range(len(test))
# print(len(test[x]))
neighbors = getNeighbors(train, test[x], k)
# print(“N”,neighbors)
result = getResponse(neighbors)
# print(“R”,result)
predictions.append(result)
# print(predictions)
print(‘> predicted=’ + repr(result) + ‘, actual=’ + repr(test[x][-1]))
accuracy = getAccuracy(test, predictions)
print(‘Accuracy: ‘ + repr(accuracy) + ‘%’)
如何返回一个无偏差的随机响应,即无响应?
我正在使用这段代码将随机图像分类为字母。我有一个字母数据集供它使用。
例如,我有一个不是字母的随机图像,但是当我使用这段代码进行分类时,我得到了一个字母作为响应。如何判断这张图像不是字母?根据我的数据集。我应该修改代码以检查“sortedVotes[0][1]”中得到的结果吗?
谢谢你。
也许您也可以在训练数据集中包含“非字母”?
但是如果我没有这种类型的数据怎么办?
谢谢你。
您可能需要发明或设计它才能获得您想要的结果。
你好,我想要用 Java 语言实现这个,你能帮我一下吗?
你可以把它移植到 Java。
你好,我如何绘制标记数据的输出?
您想要哪种类型的图表?
请用 python 实现旋转森林(带 LDA 和 PCA)。
感谢您的建议。
精彩的解释,本来还在想从哪里开始机器学习,但这个教程消除了我的疑惑,我现在感觉自信满满,可以把这个算法应用到任何问题上,谢谢你
很高兴听到这个消息。
嗨 Jason,我似乎遇到了下面的错误。你能告诉我需要更改什么吗?我是 Python 新手
import csv
import random
def loadDataset(filename, split, trainingSet=[] , testSet=[])
with open(filename, ‘rt’) as csvfile
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)-1)
for y in range(4)
dataset[x][y] = float(dataset[x][y])
if random.random() < split
trainingSet.append(dataset[x])
else
testSet.append(dataset[x])
trainingSet=[]
testSet=[]
loadDataset('iris.data',0.66, trainingSet, testSet)
print ('Train: ' + repr(len(trainingSet)))
print ('Test: ' + repr(len(testSet)))
回溯(最近一次调用)
File "”, line 17, in
loadDataset(‘iris.data’,0.66, trainingSet, testSet)
File “”, line 9, in loadDataset
dataset[x][y] = float(dataset[x][y])
ValueError: could not convert string to float: ‘5.1,3.5,1.4,0.2,Iris-setosa’
@ yuvaraj 我刚刚试用了你的代码(带有正确的缩进),它在给定的数据集上完美地运行。
for x in range(len(dataset)-1)
for y in range(4)
dataset[x][y] = float(dataset[x][y])
这些行旨在将 dataset[x][0]、dataset[x][1]、dataset[x][2]、dataset[x][3] 从字符串类型转换为浮点类型,以便它们可以用于计算欧几里德距离。您不能将“Iris-setosa”转换为浮点类型。
嗨,Jason,
我正在我的数据集上运行您上面的代码,它有 40,000 行,10 个特征和 1 个二元类。
与您的 6 个模型代码相比,运行它需要更多时间(我实际上还没有让它完成,5-10 分钟后……)。
https://machinelearning.org.cn/machine-learning-in-python-step-by-step/
这段最新的代码在相同的数据集上运行得快得多,在 Macbook pro 上只需几秒钟。
这正常吗?或者我做错了什么……
我今天让它运行了大约一个小时,准确率是 0.96。为什么其他代码快那么多?它没有在所有数据上运行吗?
这可能是硬件或环境问题?
不确定。但是您确认此页面上的代码在所有数据上运行,而不仅仅是子集,特别是 KNN 代码?
https://machinelearning.org.cn/machine-learning-in-python-step-by-step/
它运行得很快。
非常感谢您的所有工作,我学到了很多。
您可以尝试在较少的数据上运行代码。
你好,布朗利博士
也许与其使用
is,不如使用==运算符,因为is询问的是标识,而不是相等性。我在尝试您的教程时自己也遇到了这个错误。顺便说一句,干得好。谢谢!谢谢。
非常感谢 Jason。这是关于 KNN 的最佳教程之一!!
有一点……在 GetResponse 函数中,.iteritems() 命令在 Python3 中不再存在……而是 .items()
再次感谢
谢谢您的留言。
我使用 KNN 训练了我的数据,邻居数量为 3,我计算了预测数据的距离。我得到了较小和较大的距离值。
如何计算 KNN 的可接受距离,如何计算 KNN 中距离的最大限制。
请建议任何计算 KNN 中距离最大限制的程序
也许可以使用测试数据集来估计这些值。
我得到了非常大的距离值,但它被预测为最近邻,这就是我希望找到 KNN 中最大可接受距离的原因。
有没有可用的程序来计算 KNN 中最大可接受距离?
可能有一些,但我并不清楚。或许可以在谷歌学术上查阅相关论文。
KNN 中的距离,请告诉我哪些因素会影响距离值。
观测值的值。
如何绘制这些数据以返回类似于开头图像的图像?
好问题,抱歉目前我没有示例。
我喜欢,因为我找到了我正在寻找的东西。
你结束了我四天漫长的寻找!上帝保佑
你这个人。祝你有个美好的一天。再见
谢谢,很高兴对您有帮助。
你好,Jason,我非常想购买你的书《Code Algorithms From Scratch in Python》,但我有一个问题,书中的代码都更新到 Python 3 了吗?即使在你的帖子中,很多代码仍然是 Python 2 的,我学过 Python 3,现在正在学习机器学习,完全是新手,我想专注于机器学习,而不是调试 Python 2 代码到 Python 3。我发现当代码因为 Python 2 和 Python 3 的差异而报错时,非常令人沮丧和恼火,你能不能也请更新你的帖子到 Python 3?谢谢
目前还没有,所有代码都是 Python 2.7。
嗨。我能知道你的 csv 文件是什么样的吗?
它在这里
https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
感谢 Jason 的另一个精彩教程。我想知道的是,你将如何绘制训练数据集的前 3 个属性与测试样本集的三维图像,并带有标签,以便更直观地了解结果。谢谢
Voronoi 镶嵌图在 2D 可视化 KNN 中很受欢迎
https://zh.wikipedia.org/wiki/Voronoi_%E5%9B%BE
我们可以用 LVQ 来做吗?
我们能否将此应用于具有两个以上类别的数据集?
当然可以。
这是我针对同一算法的实现,它更面向对象……对于熟悉 Java 或类似 Java 语言的人来说,可能更容易阅读:https://github.com/koraytugay/notebook/blob/master/programming_challenges/src/python/iris_flower_knn/App.py
干得好!
您好,目前为止教程很棒。我是 Python 新手,在 getNeighbours 函数中遇到了以下错误
文件“”,第 8 行
distances.sort(key=operator.itemgetter(1))
^
SyntaxError: invalid syntax
我使用的是 Python 3,但尝试了几种替代方法,仍然无法使其工作。有人能帮忙吗?
本教程假定使用 Python 2.7。
代码必须更新为 Python 3。
谢谢您,杰森先生,
我真的衷心感谢您提供了如此简单易懂的算法实现,并解释了每个函数的适当含义和需求
再次感谢您
我还参加了您的机器学习14天课程,这也真的对我帮助很大……
希望像这样向您学习更多……
谢谢你
很高兴听到这个消息。
我有一些问题
如果我想创建一个没有实际训练集的算法,这个算法是否归类为基于实例的算法?
此外,KNN 是解决此类问题的首选算法吗?
例如,我们可以考虑 IRIS 数据集,但想象您每天都会添加新数据。
非常感谢您抽出时间。
您必须有标记数据才能准备监督学习模型。
那么,如果我有一个像下面这样的数据框数据集,我们能有这样的情况吗?
年龄 . 收入 . 储蓄 . 房屋贷款 职业 . 信用风险 . 类别 (0-2)
23 . 25000 . 3600 . 否 私营部门 1
33 . 37000 . 12000 . 是 IT 1
37 . 34500 . 15000 . 是 IT 1
45 . 54000 . 60000 . 是 . 学术 0
26 . 26000 . 4000 . 是 . 私营部门 2
这里的标签是信用风险。假设每天都有这样的“新鲜”数据到来,KNN 是对数据进行分类的好方法吗?或者我们也可以应用其他算法?
我唯一担心的是准确性和过拟合问题,因为您将没有任何测试数据。此外,KNN 是一种非常简单的算法,最后,假设数据来自同一来源,可以安全地假设它们不会有任何偏差吗?
我建议使用像 sklearn 这样的框架来研究您的数据集。
你可以从这里开始
https://machinelearning.org.cn/start-here/#python
它实际上在 Iris 数据集中给出什么输出?我是说计算了哪个准确度?
抱歉,我没听懂您的问题。也许您可以提供更多上下文或重新措辞您的问题?
我可以使用此算法预测多个参数吗?在鸢尾花数据集中,它计算的是花的类型和准确性。如果我再添加一个参数,例如颜色,那么花的类型和颜色可以同时预测并计算准确性吗?
神经网络可以,sklearn 模型通常不能预测多个变量。
非常感谢。您的解释方式切中要害且概念化。
谢谢。
谢谢。您的解释方式切中要害且概念化。
要点*
嗨,杰森,博客很棒。喜欢你所有的帖子。非常感谢。然而,我有一个关于 sklearn 最近邻的问题。我非常困惑“indices”到底是什么意思。
这来自 sklearn 网站。“对于在两组数据之间查找最近邻的简单任务,可以使用 sklearn.neighbors 中的无监督算法。”
>>> from sklearn.neighbors import NearestNeighbors
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> nbrs = NearestNeighbors(n_neighbors=2, algorithm='ball_tree').fit(X)
>>> distances, indices = nbrs.kneighbors(X)
>>> indices
array([[0, 1],
[1, 0],
[2, 1],
[3, 4],
[4, 3],
[5, 4]]...)
>>> distances
array([[ 0. , 1. ],
[ 0. , 1. ],
[ 0. , 1.41421356],
[ 0. , 1. ],
[ 0. , 1. ],
[ 0. , 1.41421356]])
我在 iris 数据集上实现了这个,这就是我得到的。再次,如何解释下面的 1,2 和 3?非常感谢。
# 实例化学习模型 (k = 3)
knn = KNeighborsClassifier(n_neighbors=3)
# 拟合模型
knn.fit(X_train, y_train)
# 预测响应
pred = knn.predict(X_test)
distances, indices = knn.kneighbors(X)
print(indices[1:3])... Q1
[[84 82 35]
[58 18 50]]
print(distances[1:3])..Q2
[[0. 0.17320508 0.17320508]
[0. 0.14142136 0.24494897]]
print(y_train[indices][10:12])...Q3
[[0. 0. 0.]
[0. 0. 0.]]
可能是保存的训练数据中的索引。
我很高兴学习您的材料,但不幸的是,这些代码在 Python 3.7 中不起作用。
例如,此页面上的第一个代码片段。
是的,代码是很久以前为 Py2.7 编写的。
嗨,杰森,我是机器学习新手,您的文章真的简单易懂,我有一个非常基本的问题(很傻的问题),
哪个是正在被预测的未知对象
一旦我们拟合模型,我们就可以使用模型对新数据进行预测。
在这个例子中,模型测量一朵花并预测鸢尾花的种类。
杰森,为什么我在下载的《从零开始用 Python 实现机器学习算法》中找不到你的在线示例?
我只看到使用鲍鱼示例实现的 KNN。我的这本电子书是不是过时了?
我在书中提供了一个更完整的 knn 示例(更好的设计和对 py2 和 py3 的支持)。
嗨,Jason,
非常感谢您的解释。
我运行了代码,准确率显示为 0.0%
也许可以尝试 sklearn 提供的 knn?
这是我第一次接触机器学习。这是一篇描述详尽的文章,让我成为了机器学习的粉丝。我按照您的文章做了,并得到了结果。感谢您的这篇文章。
如果您能告诉我接下来要学习的文章,那将是很大的帮助,因为这是我学习机器学习的第一天。
谢谢,这里有一些类似的教程
https://machinelearning.org.cn/start-here/#code_algorithms
你好,
请修改代码,使用 numpy 和 pandas 为 python 3 用户从 URL 加载 CSV 文件。
谢谢
感谢您的建议。
我如何估计预测类别的条件概率
我建议使用 sklearn 的实现并调用 predict_proba()
https://scikit-learn.cn/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
嗨
很棒的教程!
但我对“if response in classVotes”这行代码感到困惑
你能解释一下吗?
当然,具体是哪一部分?
嗨,杰森,您能粗略估计一下创建一个好的机器学习项目需要多长时间吗?
这取决于项目和所涉及的开发人员。
可能是一个小时,也可能是一年。
这个过程将大大加快速度
https://machinelearning.org.cn/start-here/#process
嗨,谢谢您的帖子。有一个问题是:您认为我们应该将 predictions=[] 放在 for 循环中吗? predictions 列表应该在每次循环后清除
这个出了错
回溯(最近一次调用)
文件“C:\Users\micro\AppData\Local\Programs\Python\Python36-32\distnce1.py”,第 10 行,在
for x in range(len(dataset)-1)
NameError: 名称“dataset”未定义
您可能跳过了教程中的某些代码行。
我收到了以下错误
迭代器应返回字符串,而不是字节(您是否以文本模式打开文件?)
我已将数据保存为记事本中的“irisdataset.txt”
请帮助
文件以二进制模式打开,也许可以尝试将其更改为文本模式?
谢谢杰森。我把它改成了文本模式,现在可以工作了。但对于任何 k 值,我都得到了 100% 的准确率
也许您复制代码时有打字错误?
你好 Jason……
你能帮帮我吗!
我需要这段代码,但它根本不起作用 :((((
我使用的是 python 3.7 和自闭症数据集,数据有缺失值
我该怎么办
请问有人能帮帮我吗!!!
谢谢。
我的书中有适用于 Python 3 的更新版本
https://machinelearning.org.cn/machine-learning-algorithms-from-scratch/
如何修复这个错误?Jason 先生
import csv
import random
import math
import operator
def loadDataset(Part1_Train, split, trainingSet=[] , testSet=[])
with open('Part1_Train.csv', 'r') as csvfile
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)-1)
for y in range(4)
dataset[x][y] = float(dataset[x][y])
if random.random() predicted=' + repr(result) + ', actual=' + repr(testSet[x][-1]))
accuracy = getAccuracy(testSet, predictions)
print(‘Accuracy: ‘ + repr(accuracy) + ‘%’)
main()
—————————————————————————
ValueError 回溯 (最近一次调用)
in ()
72 print(‘Accuracy: ‘ + repr(accuracy) + ‘%’)
73
—> 74 main()
在 main() 中
58 testSet=[]
59 split = 0.67
—> 60 loadDataset('Part1_Train.csv', split, trainingSet, testSet)
61 print ('Train set: ' + repr(len(trainingSet)))
62 print ('Test set: ' + repr(len(testSet)))
in loadDataset(Part1_Train, split, trainingSet, testSet)
10 for x in range(len(dataset)-1)
11 for y in range(4)
—> 12 dataset[x][y] = float(dataset[x][y])
13 if random.random() < split
14 trainingSet.append(dataset[x])
ValueError: could not convert string to float: '5.1,3.5,1.4,0.2,A'
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
# -*- coding: utf-8 -*-
"""
创建于2019年4月28日星期日00:14:28
@作者:Feroz
"""
import csv
import random
import math
import operator
from matplotlib import pyplot
def loadDataset(filename, split, trainingSet=[] , testSet=[])
with open(filename, ‘r’) as csvfile
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)-1)
for y in range(4)
dataset[x][y] = float(dataset[x][y])
if random.random() predicted=' + repr(result) + ', actual=' + repr(testSet[x][-1]))
accuracy = getAccuracy(testSet, predictions)
print('准确率:' + str(accuracy) + '%')
main()
这是输出
运行文件('C:/Users/Feroz/Desktop/Project/untitled0.py', wdir='C:/Users/Feroz/Desktop/Project')
训练集:103
测试集:47
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-setosa', actual='Iris-setosa'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> predicted='Iris-versicolor', actual='Iris-versicolor'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> predicted='Iris-versicolor', actual='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
> 预测值='Iris-virginica',实际值='Iris-virginica'
准确率:0.0%
感谢您创建如此好的教程。我运行了您的代码,它运行得非常好,但为什么它给出 0.0% 的准确率,我没有明白这一点。谢谢
干得不错。
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
杰森,干得好。
我是 Python 新手。
运行第一段代码后
import csv
with open('iris.data', 'rb') as csvfile
lines = csv.reader(csvfile)
for row in lines
print ', '.join(row)
我收到一个错误消息
文件 "C:\Users\AKINSOWONOMOYELE\Anaconda3\lib\site-packages\spyder_kernels\customize\spydercustomize.py",第 110 行,位于 execfile 中
exec(compile(f.read(), filename, 'exec'), namespace)
文件 "C:/Users/AKINSOWONOMOYELE/.spyder-py3/temp.py",第 5 行
print ', '.join(row)
^
SyntaxError: invalid syntax
我该如何处理这个问题?
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好 Jason,
随机返回值如何将数据集分成训练集和测试集?
我不明白这个逻辑,你能帮帮我吗?
它返回一个介于 0 和 1 之间的数字,我们检查它是否低于我们的比率,以决定将其添加到哪个列表中。
回溯(最近一次调用)
文件“C:/Users/DELL/Desktop/project/python/pro2.py”,第 70 行,在
neighbors = getNeighbors(train, test[x], k)
文件“C:/Users/DELL/Desktop/project/python/pro2.py”,第 34 行,在 getNeighbors
dist = euclideanDistance(testInstance, trainingSet[x], length)
文件“C:/Users/DELL/Desktop/project/python/pro2.py”,第 23 行,在 euclideanDistance
distance += pow((float(instance1[x]) – float(instance2[x])), 2)
IndexError: 列表索引超出范围
这是什么错误
即列表索引超出范围。
你好,杰森。
我已读完文章和所有 250+ 条评论。但在我的分析中应用 KNN 时仍有疑问。该怎么办???请提供建议。谢谢
此致
桑迪潘·萨卡尔
此示例仅用于学习目的,不用于项目。
对于实际问题,我建议使用 sklearn
https://machinelearning.org.cn/spot-check-classification-machine-learning-algorithms-python-scikit-learn/
我们如何通过提供新的数据集进行预测,例如
萼片长度 萼片宽度 花瓣长度 花瓣宽度 类别
5.1 3.5 1.4 0.2 ?
让我们的模型进行预测
我建议使用 scikit-learn 实现,此示例仅用于学习。
请看这篇文章
https://machinelearning.org.cn/make-predictions-scikit-learn/
您好,我正在学习阶段,我手头有一个项目,我每分钟从一个 IoT 设备上的网络服务器获取许多传感器数据。我最初进行网络抓取,然后将数据以 CSV 格式存储。现在所有数据,包括时间日期戳,都采用字符串格式。
我的问题是,我想将 Knn 应用于预测下一个数据集是否包含任何异常,那么我的预处理方法应该是什么。因为最后,我必须检查实时数据中是否存在任何异常。
谢谢
如果是来自 IoT 的数据,它可能是一个时间序列。也许您可以将其建模为时间序列分类(异常或非异常)。
这里的教程可能会给您一些想法
https://machinelearning.org.cn/start-here/#deep_learning_time_series
请问如何将我的查询输入到我的knn分类算法中,不知道怎么编码
也许您可以使用此处的 scikit-learn 实现
https://scikit-learn.cn/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
嘿……我使用了这段代码:我必须为 Pima 印第安人数据集执行此操作
import random
import csv
split = 0.66
with open('C:\\Users\\HP\\Desktop\\diabetes.csv') as csvfile
lines = csv.reader(csvfile)
dataset = list(lines)
random.shuffle(dataset)
div = int(split * len(dataset))
train = dataset [:div]
test = dataset [div:]
import math
# 两个数字数组之间平方差之和的平方根
def euclideanDistance(instance1, instance2, length)
distance = 0
for x in range(length)
#print(instance1[x])
distance += pow((float(instance1[x]) – float(instance2[x])), 2)
return math.sqrt(distance)
import operator
#distances = []
def getNeighbors(trainingSet, testInstance, k)
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet))
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k)
neighbors.append(distances[x][0])
return neighbors
classVotes = {}
def getResponse(neighbors)
#classVotes = {}
for x in range(len(neighbors))
response = neighbors[x][-1]
if response in classVotes
classVotes[response] += 1
else
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0]
def getAccuracy(testSet, predictions)
correct = 0
for x in range(len(testSet))
#print(predictions[x])
if testSet[x][-1] == predictions[x]
correct += 1
return (correct/float(len(testSet))) * 100.0
predictions=[]
k = 3
for x in range(len(test))
#print(len(test[x]))
neighbors = getNeighbors(train, test[x], k)
#print("N",neighbors)
result = getResponse(neighbors)
#print("R",result)
predictions.append(result)
#print(predictions)
print(‘> predicted=’ + repr(result) + ‘, actual=’ + repr(test[x][-1]))
accuracy = getAccuracy(test, predictions)
print(‘Accuracy: ‘ + repr(accuracy) + ‘%’)
错误
文件“C:/Users/HP/.spyder-py3/ir.py”,第 23 行,位于 euclideanDistance
distance += pow((float(instance1[x]) – float(instance2[x])), 2)
ValueError: 无法将字符串转换为浮点数:“Pregnancies”
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
您是否使用统计方法或贝叶斯理论来加速参数匹配时的收敛?您是否将其应用于制药行业?
我两者都用,具体取决于项目。
网格搜索也能让你走得很远!
嗨
根据这篇博文的代码,当您计算K近邻时,您将节点本身视为其中一个节点,对吗?
不,通常我们会在未用于训练模型的数据上评估模型。
在这里,我们使用交叉验证,它将数据多次分成训练集和测试集,测试集中的示例不在训练集中。
嗨,Jason,
您能否也写一篇关于其他基于实例的降维技术,如IB2和IB3(用Python实现)的博客?
感谢您的建议!
您是指像凝聚NN和编辑NN吗?是的,我已经写好并计划了一篇关于这些主题的教程。
嗨,Jason,
感谢分享。您有凝聚NN和编辑NN算法的链接吗?很想看看您是如何实现这些算法的。
您可以使用博客搜索框。
这可能是一个很好的起点
https://machinelearning.org.cn/undersampling-algorithms-for-imbalanced-classification/
你好,Jason
我认为在“cross_validation_split”函数中有些地方需要修复。
考虑“len(dataset) / n_folds”的划分。在除法余数很大的情况下,
结果可能会遗漏一些数据。
例如,给定以下代码
则输出为
当处理非常大的数据集时,这也可能是关键问题。
无论如何,谢谢您,
Ori
谢谢分享,Ori!
我如何使用KNN方法判断一个评论或评论是否是激励性/有偏见的?您能告诉我吗?
提前感谢。
也许您可以将问题建模为文本分类。
https://machinelearning.org.cn/best-practices-document-classification-deep-learning/
您好!非常棒的文章,非常感谢!您的网站帮助很大!
我有一个与您的帖子相关的问题
我目前正在进行多参数体素分类。换句话说,我有几张对齐和配准的参数图像,并希望根据每个参数图像中的体素值形成体素簇。
我专注于医学图像。进行分析是为了表征和预测患者对治疗的反应。
我每个患者同时有多种类型的图像(CT扫描图像、分子图像、MRI等)。
为了查看是否能发现显著趋势,我首先想简单地使用多维k均值、基于层次的方法和/或PCA对体素进行聚类。
我知道在应用无监督聚类之前预处理数据非常重要。根据我所读到的,在对数据进行归一化(0到1之间)或标准化(均值为0,标准差为1)之间进行选择似乎没有硬性规定。这似乎取决于数据和上下文。
由于我的图像尺度差异很大,您认为我应该对每个参数图像中的体素值进行归一化还是标准化?
非常感谢您的帮助。
谢谢!
不客气。
也许可以尝试每种方法,并与原始数据进行比较,然后选择能产生最有效模型的方法。
谢谢!所以根据您的说法,也没有“硬性规定”。这有点证实了我所读到的……
这就是我要尝试的,但在无监督学习中,由于我们没有真实值,很难判断哪个结果是最好的……
无论如何,非常感谢您的帮助!
难以知道*哪个
(抱歉我是法国人)
布朗利博士,您好。
我如何在需求可追溯性中使用基于KNN的推荐系统来跟踪需求。
需求可追溯性是指能够从项目开始到结束跟踪需求的能力。
它是需求管理的一部分。
我需要Python代码来实现这个功能
也许可以先定义您的问题
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
然后可以按照这个过程系统地解决它
https://machinelearning.org.cn/start-here/#process
您的代码行“dist = euclidean_distance(test_row, train_row)”是错误的。
您应该调换参数的顺序。
请查看 euclidean_distance 实现中的 for_loop 以了解原因
代码是正确的,两个类在列表末尾都有一个额外的元素用于类。
但对于独立预测,您是对的,其中不会出现此类元素。
Jason Brownlee 博士,您好,
我正在为客户做一个概念验证(PoC)。让我解释一下需求。
我得到了一张带有以下列的 Excel 表格:
Server_SNo,
Owner,
Hosting Dept,
Bus owner,
Applications hosted,
Functionality,
comments
除了 Server_SNo,其他列可能包含数据,也可能不包含数据。
有些记录除了 Server_SNo(第一列)之外没有数据。
一个业务负责人可以拥有多台服务器。
因此,在 4000 条记录中,约 50% 的数据包含服务器与所有者的直接映射。剩下的 50% 的数据包含其他列的组合(Owner、Hosting Dept、Bus owner、Applications hosted、Functionality 和 comments)。
我的问题是,我需要为那 50% 的数据(包含其他列的组合)找到给定 Server_Sno 的所有者。
这是一个 NLP 问题吗?我使用 Python 和 NLTK 进行 NLP 的方向正确吗?
任何见解都将不胜感激。
“所有者”的数量可能固定。这可能是一个分类任务,带有一些文本输入。词袋模型将作为编码每个变量的第一步。
你好
我试图将代码转换为Java
我做到了,但我得到了不同的结果
/*
* 要更改此许可证头,请在项目属性中选择许可证头。
* 要更改此模板文件,请选择“工具”|“模板”
* 并在编辑器中打开模板。
*/
包iris;
导入java.io.BufferedReader;
导入java.io.File;
导入java.io.FileReader;
导入java.io.IOException;
导入java.util.ArrayList;
导入java.util.Arrays;
导入java.util.List;
导入knntradition.KNNTradition;
导入静态knntradition.KNNTradition.Max;
导入静态knntradition.KNNTradition.Sort2DList;
导入静态knntradition.KNNTradition.euclidean_distance;
导入静态knntradition.KNNTradition.get_neighbors;
/**
*
* @author Mustapha M. Baua
*/
公共类iris {
公共KNNTradition knn = new KNNTradition();
公共静态void main(String[] args)
{
/* # 在鸢尾花数据集上测试kNN
seed(1)
文件名 = ‘iris.csv’
dataset = load_csv(filename)
对于 range(len(dataset[0])-1) 中的 i
str_column_to_float(dataset, i)
*/
List<List> DataSetList = LoadDataSet();
System.out.println(“DataSetList 中的行数 “+ DataSetList.size());
System.out.println(“”);
/*# 将类列转换为整数
str_column_to_int(dataset, len(dataset[0])-1)
*/
List<List> lookup = lookup(DataSetList, DataSetList.get(0).size()-1);
DataSetList = str_column_to_int(DataSetList, DataSetList.get(0).size()-1);
//System.out.println(“lookup “+lookup);
DataSetList = normalize_dataset(DataSetList, dataset_minmax(DataSetList));
//System.out.println(DataSetList.get(0));
//System.out.println(DataSetList.get(51));
//System.out.println(DataSetList.get(101));
/*
# 评估算法
n_folds = 5
num_neighbors = 5
scores = evaluate_algorithm(dataset, k_nearest_neighbors, n_folds, num_neighbors)
print(‘Scores: %s’ % scores)
print(‘平均准确率:%.3f%%’ % (sum(scores)/float(len(scores)))) */
int n_folds = 5;
int num_neighbors = 5;
// public static List<List<List>> k_nearest_neighbors(List<List> train, List<List> test,int num_neighbors)
List kNearestNeighbors = k_nearest_neighbors(DataSetList, DataSetList, num_neighbors);
List scores = evaluate_algorithm(DataSetList, kNearestNeighbors,n_folds, num_neighbors);
System.out.println(“分数为 “);
System.out.println(“分数大小为 “+scores.size()+” “+scores);
System.out.println(“平均准确率: “+ sum(scores)/scores.size());
}
公共静态double sum(List list)
{
double sum = 0;
for(int k = 0 ; k<list.size();k++)
{
sum += Double.valueOf(list.get(k));
}
返回 sum;
}
公共静态List LoadDataSet()
{
List<List> DataSetList = new ArrayList();
try{
File file = new File(“E:\\iris.txt”);
FileReader Reader = new FileReader(file);
BufferedReader lineReader = new BufferedReader(Reader);
String lineText;
System.out.println(“尝试从文件中读取: “+file.getCanonicalPath());
while ((lineText = lineReader.readLine()) != null)
{
String[] Elements = lineText.split(“,”);
//System.out.println(lineText);
List singleList = new ArrayList() ;
singleList.addAll(Arrays.asList(Elements));
DataSetList.add(singleList);
}
System.out.println(“文件读取结束”);
}catch (IOException e)
{
System.out.println(e.getMessage());
}
返回 DataSetList;
}
/* # 将字符串列转换为整数
def str_column_to_int(dataset, column)
class_values = [row[column] for row in dataset]
unique = set(class_values)
lookup = dict()
for i, value in enumerate(unique)
lookup[value] = i
for row in dataset
row[column] = lookup[row[column]]
返回 lookup */
公共静态List<List> str_column_to_int(List<List> ds, int column)
{
List class_values =new ArrayList();
List unique = new ArrayList();
List<List> lookup = lookup(ds,column);
for(int i = 0;i<ds.size();i++)
class_values.add(ds.get(i).get(column));
for(int i = 0;i<ds.size();i++)
{
String Count = ChFreq(unique, String.valueOf(class_values.get(i)));
if (Count!=null && "0".equals(Count))
unique.add(class_values.get(i));
}
for(int k = 0;k<ds.size();k++)
{
List TempRow = ds.get(k);
for(int h = 0 ;h < lookup.size();h++)
{
if(lookup.get(h).get(1).equals(ds.get(k).get(column)))
{
TempRow.set(column,lookup.get(h).get(0));
ds.set(k, TempRow);
}
}
}
返回 ds;
}
公共静态List<List> lookup(List<List> ds, int column)
{
List<List> lookup =new ArrayList();
List class_values =new ArrayList();
List unique = new ArrayList();
for(int i = 0;i<ds.size();i++)
class_values.add(ds.get(i).get(column));
for(int i = 0;i<ds.size();i++)
{
String Count = ChFreq(unique, String.valueOf(class_values.get(i)));
if (Count!=null && "0".equals(Count))
unique.add(class_values.get(i));
}
for(int k = 0;k<unique.size();k++)
{
List TwoItems = new ArrayList();
TwoItems.add(String.valueOf(k));
TwoItems.add(unique.get(k));
lookup.add(TwoItems);
}
返回 lookup;
}
/* # kNN 算法
def k_nearest_neighbors(train, test, num_neighbors)
predictions = list()
for row in test
output = predict_classification(train, row, num_neighbors)
predictions.append(output)
返回(predictions) */
公共静态List k_nearest_neighbors(List<List> train, List<List> test,int num_neighbors)
{
List predictions = new ArrayList();
for(int k = 0 ; k<test.size();k++)
{
predictions.add(predict_classification(train, test.get(k), num_neighbors));
}
返回 predictions;
}
/* # 使用邻居进行预测
def predict_classification(train, test_row, num_neighbors)
neighbors = get_neighbors(train, test_row, num_neighbors)
output_values = [row[-1] for row in neighbors]
prediction = max(set(output_values), key=output_values.count)
返回 prediction */
公共静态String predict_classification(List<List> train, List test_row, long num_neighbors)
{
//System.out.println(“predict_classification train set “);
//System.out.println(“train size “+train.size()+” “+train);
List<List> neighbors = get_neighbors(train, test_row, num_neighbors);
List OutputValues = new ArrayList();
String prediction= null;
//System.out.println(neighbors);
//output_values = [row[-1] for row in neighbors]
if(neighbors!=null)
{
for(int i=0;i<neighbors.size();i++)
OutputValues.add(neighbors.get(i).get(neighbors.get(i).size()-2));
//System.out.println("outputvalues "+OutputValues);
prediction = Max(OutputValues);
}
返回 prediction;
}
// 定位最相似的邻居
公共静态List<List> get_neighbors(List<List> train, List test_row,long num_neighbors)
{
List<List> Distances = new ArrayList();
List<List> neighbors = new ArrayList();
double dist;
for(int i=0;i<train.size();i++)
{
List singleList = new ArrayList();
for(int k =0;k<train.get(i).size();k++)
singleList.add(train.get(i).get(k));
dist = euclidean_distance(test_row, train.get(i));
singleList.add(String.valueOf(dist));
Distances.add(singleList);
}
Distances = Sort2DList(Distances);
for(int i=0;i<num_neighbors;i++)
neighbors.add(Distances.get(i));
//System.out.println("neighbors are "+neighbors.size()+" "+ neighbors);
返回 neighbors;
}
公共静态List<List> Sort2DList(List<List> list)
{
List maxRow = new ArrayList();
for (int i=0;i<list.size()-1;i++)
{
for(int j=i+1;jDouble.parseDouble(list.get(j).get(list.get(j).size()-1)))
{
maxRow = list.get(i);
list.set(i, list.get(j));
list.set(j, maxRow);
}
}
}
返回 list;
}
/* # 使用交叉验证拆分评估算法
def evaluate_algorithm(dataset, algorithm, n_folds, *args)
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algorithm(train_set, test_set, *args)
actual = [row[-1] for row in fold]
accuracy = accuracy_metric(actual, predicted)
scores.append(accuracy)
返回 scores */
公共静态List evaluate_algorithm(List<List> dataset,List neighbors, int n_folds, int num_neighbors)
{
List<List<List>> folds = cross_validation_split(dataset,n_folds);
List scores = new ArrayList();
for(int i = 0;i <n_folds;i++)
{
List<List<List>> train_set=new ArrayList(folds);
List<List> test_set = folds.get(i);
List<List<List>> train_set_copy = new ArrayList(train_set);
train_set_copy.remove(test_set);
//train_set = sum(train_set, [])
//System.out.println(” i = “+ i +” “+ folds.size());
List predicted = new ArrayList();
//if(!(train_set.get(i).equals(test_set)))
//{
for(int j = 0 ;j<train_set_copy.size();j++)
{
predicted = k_nearest_neighbors(train_set_copy.get(j), test_set, num_neighbors);
}
//}
//System.out.println("predicted size is "+predicted.size()+" "+predicted);
List<List> fold = folds.get(i);
List actual = new ArrayList();
for(int j = 0; j < fold.size();j++)
{
actual.add(fold.get(j).get(fold.get(j).size()-1));
}
//System.out.println("actual size "+actual.size()+" "+actual);
double accuracy = accuracy_metric(actual,predicted);
scores.add(String.valueOf(accuracy));
}
返回 scores;
}
/* # 将数据集分成k折
def cross_validation_split(dataset, n_folds)
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for _ in range(n_folds)
fold = list()
while len(fold) < fold_size
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
返回 dataset_split */
公共静态List<List<List>> cross_validation_split(List<List> dataset, int n_folds)
{
List<List<List>> dataset_split = new ArrayList();
List<List> dataset_copy = dataset;
int fold_size = dataset.size()/n_folds;
for(int k = 0; k< n_folds; k++)
{
List<List> fold = new ArrayList();
while(fold.size()< fold_size)
{
int index = (int) (Math.random()*dataset_copy.size()-1)+0;
fold.add(dataset_copy.get(index));
}
dataset_split.add(fold);
}
返回 dataset_split;
}
/* # 将字符串列转换为浮点数
def str_column_to_float(dataset, column)
for row in dataset
row[column] = float(row[column].strip())
*/
公共静态String ChFreq(List list, String word)
{
int counter = 0;
if(list!=null)
{
for(int i =0 ;i <list.size();i++)
{
if(list.get(i) == null ? word == null : list.get(i).equals(word))
counter++;
}
}else
{
返回 null;
}
返回 String.valueOf(counter);
}
/* # 查找每列的最小值和最大值
def dataset_minmax(dataset)
minmax = list()
for i in range(len(dataset[0]))
col_values = [row[i] for row in dataset]
value_min = min(col_values)
value_max = max(col_values)
minmax.append([value_min, value_max])
返回 minmax */
公共静态List<List> dataset_minmax(List<List> dataset)
{
List<List> minmax = new ArrayList();
for(int k = 0 ;k < dataset.get(0).size();k ++)
{
List col = GetColumn(dataset,k);
List tempminmax = new ArrayList();
tempminmax.add(Min(col));
tempminmax.add(Max(col));
minmax.add(tempminmax);
}
返回 minmax;
}
公共静态List GetColumn(List<List> ds, int col)
{
List column =new ArrayList();
for(int i = 0;i<ds.size();i++)
column.add((ds.get(i).get(col)));
返回 column;
}
公共静态String Max(List list)
{
String max = list.get(0);
for(int i=0;i<list.size();i++)
if(Double.valueOf(max)<Double.valueOf(list.get(i)))
max = list.get(i);
返回 max;
}
公共静态String Min(List list)
{
String min = list.get(0);
for(int i=0;iDouble.valueOf(list.get(i)))
min = list.get(i);
返回 min;
}
/* # 将数据集列重新缩放到 0-1 范围
def normalize_dataset(dataset, minmax)
for row in dataset
for i in range(len(row))
row[i] = (row[i] – minmax[i][0]) / (minmax[i][1] – minmax[i][0]) */
公共静态List<List> normalize_dataset(List<List> dataset, List<List> minmax)
{
for(int i = 0; i< dataset.size();i++)
{
List row = dataset.get(i);
for(int j = 0; j<row.size();j++)
{
row.set(j,String.valueOf( (Double.parseDouble(row.get(j)) – Double.parseDouble(minmax.get(j).get(0))) / (Double.parseDouble(minmax.get(j).get(1)) – Double.parseDouble(minmax.get(j).get(0)))));
}
dataset.set(i, row);
}
//System.out.println("normalized dataset "+ dataset);
返回 dataset;
}
/* # 计算准确率百分比
def accuracy_metric(actual, predicted)
correct = 0
for i in range(len(actual))
if actual[i] == predicted[i]
correct += 1
返回 correct / float(len(actual)) * 100.0 */
公共静态double accuracy_metric(List actual, List predicted)
{
int correct =0;
for(int k = 0;k < actual.size();k++)
{
//for(int h = 0 ;h< predicted.size();h++)
//{
if( actual.get(k).equals(predicted.get(k)))
{
correct +=1;
}
//}
}
//System.out.println("correct "+ correct);
返回 correct / (actual.size() * 100.0);
}
}
干得好!
您好 ..
但我得到了不同的结果……这没关系吗……因为我想改进算法
是的,不同语言之间结果不同是意料之中的。
谢谢……我通过将结果乘以10000来处理这个问题
但这个步骤是什么意思?
train_set = sum(train_set, []) ??
好问题。看起来它什么也没做。
现在我解决了结果问题,我得到了完全正确的结果
这是int和double之间的数据类型问题
当我改进算法后,我会把它发给你
谢谢
干得好!
先生,您好,
感谢分享。我在哪里可以获得以下Java包?
导入knntradition.KNNTradition;
导入静态knntradition.KNNTradition.Max;
导入静态knntradition.KNNTradition.Sort2DList;
导入静态knntradition.KNNTradition.euclidean_distance;
导入静态knntradition.KNNTradition.get_neighbors;
我复制了你的源代码
但我收到了错误:“name ‘k_nearest_neighbors’ is not defined”
请帮助 🙁
听起来你跳过了一些代码,尝试复制粘贴教程末尾的示例。
仍然一样,错误位置在evaluate_algorithm中无法读取k_nearest_neighbors
你好,Jason。
我希望找到数据集中给定行的最近邻居。它通过输出数据集本身运行良好,但是我希望它在处理鸢尾花数据集时打印出标签,例如:iris-setosa、Iris-virginica或Iris-versicolor。就像推荐系统找出相似性一样。我该如何实现?
作为数据准备的一部分,每个类都被分配了一个称为整数编码的整数。请记住这种类到整数的映射。然后当你收集k个最近邻居时——计算整数值的众数并将其映射回字符串类名。
你好 Jason 我改进了算法,并且我也注意到了这个方法,我发现由于使用了Random方法,许多记录重复了,所以我将代码更改为以下内容
public List<List<List>> cross_validation_split(List<List> dataset, int n_folds)
{
List<List<List>> dataset_split = new ArrayList();
List<List> dataset_copy = dataset;
int fold_size = dataset.size()/n_folds;
int index = 0;
for(int k = 0; k< n_folds; k++)
{
List<List> fold = new ArrayList();
while(fold.size()< fold_size)
{
// 删除的行 int index = (int) (Math.random()*dataset_copy.size()-1)+0;
fold.add(dataset_copy.get(index));
index++;
}
//System.out.println("fold # "+ k+ " "+fold);
dataset_split.add(fold);
}
返回 dataset_split;
}
抱歉,我没有能力调试你的 Java 代码。
尊敬的 Jason Brownlee!
代码片段没有安排好,即最后一个完整的组合代码缺少一些重要的代码片段,而第一个比最后一个有。
最后完整的代码示例包含了所需的一切。
Jason 讲得很好,引发了很多讨论!
我脑海中有2个可能在KNN中实现的新扩展
1) KNN 的权重取决于与预测点的距离(例如,距离的倒数)。
2) NN 搜索算法的改进/加速/并行化(可能对大数据集有帮助)。
此致!
谢谢。
很棒的扩展想法!
嗨,Jason,
首先,我要感谢您出色的工作和解释,您帮助我们理解了这个新的IT主题。
现在我想问您一件事:我复制粘贴了第二段代码,程序输出了预测值,运行后得到了这个输出
[Iris-versicolor] => 0
[Iris-virginica] => 1
[Iris-setosa] => 2
数据=[4.5, 2.3, 1.3, 0.3],预测:2
这与您的不同
[鸢尾-维吉尼亚] => 0
[鸢尾-山鸢尾] => 1
[鸢尾-变色鸢尾] => 2
数据=[4.5, 2.3, 1.3, 0.3], 预测: 1
请您解释一下为什么在我的运行中 setosa 被分类为 2,而在您的运行中被分类为 1,其他分类也不同
非常感谢,
zoiks
是的,考虑到算法的随机性,你可以预期结果会有差异。
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
谢谢您的回答 🙂
不客气。
Jason,您的又一篇好文章,它真的帮助我从零开始构建算法来学习机器学习。
非常感谢。
谢谢。
我需要为我的课程解决一个简单的 KNN 代码。您可以发送您的电子邮件给我吗,这样我就可以把文件发给您?我今天必须提交 🙁
我没有能力审查您的代码/数据
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
亲爱的 Jason,
我需要计算每一行及其25个邻居之间的距离,并将它们作为列存储在我的项目中。我该怎么做?我尝试了以下代码,但它不起作用。
distances =list()
for i in range(600)
row0 = dataset[i]
for row in dataset
dist = euclidean_distance(row0, row)
distances.append((row, dist))
distances.sort(key=lambda tup: tup[1])
提前感谢
也许这会有帮助。
https://machinelearning.org.cn/distance-measures-for-machine-learning/
为什么我不能将字符串列转换为浮点数?
ValueError: 无法将字符串转换为浮点数:'Id'
我面临着
同样的代码复制粘贴
如果字符串包含浮点数,你可以转换。
如果字符串包含字符,你需要对它们进行编码,例如序数编码、独热编码用于标签,或词袋用于自由文本。
嗨,Jason,
您的教程总是那么有帮助。我这里有一个问题。当我们实现 cross_validation_split 时,randrange() 用于生成一个随机值来定位数据集的行。这个随机值会重复吗?如果是,一些行会在某些折叠中出现多次,而有些行从未被使用过吗?
为每个折叠选择的索引被移除,以确保它们不能被重新选择,请参阅对 pop() 的调用。
是的,非常感谢!
不客气。
嗨,Jason,
抱歉,还有一个问题。
我可以问一下这个步骤的目的是什么?
‘rain_set = sum(train_set, []) ‘
非常感谢。
您好,教程很棒,您解释概念非常清楚。请问我正在尝试解决的问题是血液分类,用户希望搜索特定血型,系统自动检测并显示结果,同时建议用户可以从其他血型中获取血液……请问这是否可以用KNN实现?
谢谢。
这可能是可行的,也许可以开发一个原型来探索这个想法。
嗨,Jason,
非常感谢您编写此内容,它帮助我从头开始实现了一个,并将我的目标(类)和数据分成了两个单独的列表。
我正在尝试使用您的代码实现嵌套交叉验证,但我似乎无法弄清楚如何操作。您能否就如何通过扩展您的 evaluate_algorithm 函数来提供一些见解和代码?另外,evaluate_algorithm 函数中第 78 行的目的是什么,它做了什么?
我是机器学习新手。
不客气。
也许这会给你一些想法
https://machinelearning.org.cn/nested-cross-validation-for-machine-learning-with-python/
再次感谢 Jason。
嗨,Jason,
非常感谢您。我运行了这部分代码
def evaluate_algorithm(X, algorithm, K, k)
folds = CrossValidationSplit(X, K)
traindata=folds
scores = list()
for fold in folds
traindata.remove(fold)
traindata = sum(traindata, [])
testdata = list()
for row in fold
r = list(row)
testdata.append(r)
r[-1] = None
predicted = algorithm(traindata, testdata, k)
actual = [row[-1] for row in fold]
accuracy = accuracy_metric(actual, predicted)
scores.append(accuracy)
return scores, traindata, testdata, actual
然后出现错误,请问能帮我一下吗?
ValueError:包含多个元素的数组的真值不明确。请使用 a.any() 或 a.all()
这些技巧会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
大家好,
我正在阅读 K-NN 的伪代码。第一步涉及计算欧几里得距离。
1
2
3
4
5
6
7
X1 X2 Y
2.7810836 2.550537003 0
1.465489372 2.362125076 0
3.396561688 4.400293529 0
1.38807019 1.850220317 0
3.06407232 3.005305973 0
7.627531214 2.759262235 1
在上述数据中,我们给出了 X1 和 X2。在计算欧几里得距离时,它们计算的是 X1 和 X2 之间的欧几里得距离,但我认为 X1 和 X2 是一个点的两个特征。为什么我们要计算 X1 和 X2 之间的距离,它们是两个特征而不是两个点。上面显示的图也传达了同样的信息。
请您澄清一下
是的,相同的思想可以扩展到任意数量的特征。
你好 Jason,
我正在查看您的代码,您能否解释一下为什么在您的欧几里得距离代码中使用了 range(len(row1)-1) 而不是 range(len(row1))。
您上面提供的测试集上的欧几里得距离的最终值是不同的
因为您没有包含列表中的最后一列。
我仍在学习机器学习,需要了解为什么在您的实现中计算距离时省略了包含整数值的列?
# 测试距离函数
数据集 = [[2.7810836,2.550537003,0],
[1.465489372,2.362125076,0],
[3.396561688,4.400293529,0],
[1.38807019,1.850220317,0],
[3.06407232,3.005305973,0],
[7.627531214,2.759262235,1],
[5.332441248,2.088626775,1],
[6.922596716,1.77106367,1],
[8.675418651,-0.242068655,1],
[7.673756466,3.508563011,1]]
我是在尝试创建您的欧几里得距离函数的向量化实现时遇到这个问题的,如下所示
我的向量化实现
def euclediandist(vec1,vec2)
"""
计算两个向量/点之间的欧几里得距离。
参数
———-
vec1 : array_like
第一个向量/点的数据点值
vec2 : array_like
第二个向量/点的数据点值
返回值
——-
dist : float
两个向量之间的欧几里得距离。
指令
————
计算两个向量/点之间的欧几里得距离
"""
dist=0.0
print(“向量差:”,vec2-vec1)
print(“差的平方:”,np.square(vec2-vec1))
print(“差的平方和:”,np.sum(np.square(vec2-vec1)))
print(“差的平方和的平方根:”,np.sqrt(np.sum(np.square(vec2-vec1))))
print(‘—————————————————————————‘)
dist = np.sqrt(np.sum(np.square(vec2-vec1)))
return dist
________________________________________________________________________
函数调用
# 在 numpy 中保留精度
np.set_printoptions(precision=17)
dataset_np = np.asarray(dataset)
for i in dataset_np
euclediandist(dataset_np[0],i)
_________________________________________________________________________
输出
向量差:[0. 0. 0.]
差的平方:[0. 0. 0.]
差的平方和:0.0
差的平方和的平方根:0.0
—————————————————————————
向量差:[-1.3155942280000001 -0.1884119270000002 0. ]
差的平方:[1.7307881727469163 0.0354990542358534 0. ]
差的平方和:1.7662872269827696
差的平方和的平方根:1.3290173915275787
—————————————————————————
向量差:[0.6154780879999997 1.8497565259999997 0. ]
差的平方:[0.37881327680813537 3.4215992054795876 0. ]
差的平方和:3.800412482287723
差的平方和的平方根:1.9494646655653247
—————————————————————————
向量差:[-1.39301341 -0.7003166860000001 0. ]
差的平方:[1.9404863604398281 0.4904434606900227 0. ]
差的平方和:2.4309298211298507
差的平方和的平方根:1.5591439385540549
—————————————————————————
向量差:[0.2829887200000001 0.45476896999999994 0. ]
差的平方:[0.08008261564723845 0.20681481607486085 0. ]
差的平方和:0.2868974317220993
差的平方和的平方根:0.5356280721938492
—————————————————————————
向量差:[4.846447614000001 0.20872523199999993 1. ]
差的平方:[23.488054475246297 0.04356622247345379 1. ]
差的平方和:24.531620697719752
差的平方和的平方根:4.952940611164215
—————————————————————————
向量差:[ 2.551357648 -0.46191022800000026 1. ]
差的平方:[6.509425848008093 0.21336105873101222 1. ]
差的平方和:7.722786906739105
差的平方和的平方根:2.7789902674782985
—————————————————————————
向量差:[ 4.1415131160000005 -0.7794733330000001 1. ]
差的平方:[17.152130890000034 0.607578676858129 1. ]
差的平方和:18.759709566858163
差的平方和的平方根:4.3312480380207
—————————————————————————
向量差:[ 5.894335050999999 -2.7926056580000003 1. ]
差的平方:[34.74318569344716 7.798646361093614 1. ]
差的平方和:43.54183205454078
差的平方和的平方根:6.59862349695304
—————————————————————————
向量差:[4.892672866 0.958026008 1. ]
差的平方:[23.938247773692652 0.9178138320044161 1. ]
差的平方和:25.856061605697068
差的平方和的平方根:5.084885603993178
—————————————————————————
您将最后一列作为下面测试数据中的响应变量了吗?
数据集 = [[2.7810836,2.550537003,0],
[1.465489372,2.362125076,0],
[3.396561688,4.400293529,0],
[1.38807019,1.850220317,0],
[3.06407232,3.005305973,0],
[7.627531214,2.759262235,1],
[5.332441248,2.088626775,1],
[6.922596716,1.77106367,1],
[8.675418651,-0.242068655,1],
[7.673756466,3.508563011,1]]
我们排除了向量/行中的最后一个值,因为它是一个类标签。
感谢您的快速回复!
你能帮我用余弦相似度做KNN吗?
抱歉,我没有例子。
也许可以从上面的示例开始,并实现您的余弦距离度量而不是欧几里得距离。
非常感谢,Jason!我的研究生论文刚刚引用了你。
谢谢 Ted!
嗨,Jason,
很棒的文章!写得太好了——这对每个人都是一篇非常有帮助的文章。我希望读到你更多的文章!感谢分享这些宝贵的信息!
谢谢!
这确实是一个有趣的话题,我有点同意你在这里提到的内容!
谢谢!
我对 Python 相当陌生,这真的帮助我理解了!!但我不知道如何绘图……我想展示:k 的数量 vs 准确度
抱歉,我没有关于绘图基础知识的教程。
也许可以查阅 matplotlib API。
我对此一无所知。这是一个令人惊叹的网站,比任何普通网站都好。我必须表示感谢。出色的工作!你们都写了一个不可思议的博客,并且有一些非凡的内容。继续做出惊人的成就。
谢谢。
我是Python新手,这篇文章对我很有帮助。感谢分享这些内容,期待更多有趣的帖子。
谢谢。很高兴您喜欢。
你好
我有问题?
我能可视化分类后的列表数据集的 Voronoi 图吗?
我想为带有 knn 分类器的向量(列表)数据集制作 Voronoi 图
这可能吗?
这里还没有例子,但是你可以查看 SciPy 中一个方便的函数来帮助你绘制图表:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.spatial.voronoi_plot_2d.html
我浏览了您的大部分帖子。这篇帖子可能是我为我的研究获得最有用的信息的地方
感谢您的反馈,Nclex!
非常棒且有趣的帖子。我一直在寻找这类信息,很喜欢阅读这篇。
感谢您的反馈!
嘿,我有一个错误,提示“无法将字符串转换为浮点数:'sepallength'”。
有什么想法为什么它不起作用以及修复它的提示吗?
嗨,尤素福……以下内容可能对你有帮助
https://itsmycode.com/python-valueerror-could-not-convert-string-to-float/
你能向我们展示如何编写曼哈顿距离的函数吗?
嗨,伍海宇……以下内容可能对你有用
https://machinelearning.org.cn/distance-measures-for-machine-learning/
那很多。我已经读过了。
这篇关于从零开始学习 Python 的文章真的很有帮助!您在这个主题上确实有很多很棒的内容!感谢您提供宝贵的信息……
Shein,反馈太棒了!
感谢您的帖子。过去几周我一直在考虑写一篇非常相似的帖子,我可能会把它写得简短精悍,然后链接到这篇,如果这没问题的话。谢谢。
感谢您的反馈 satta!
哇哦,感谢你的教程,哥们,我真的很喜欢。愿上帝保佑你的知识
感谢 hokiwin 的美言和支持!我们非常感激!
您好,Jason 博士
非常感谢您所做的一切努力,我尝试在 Iris 数据集上重新实现整个实验,但是遇到了
错误“list index out of range”(列表索引超出范围)
for i in range(len(actual))
—> 67 if actual[i] == predicted[i]
68 correct += 1
69 return correct / float(len(actual)) * 100.0
IndexError: 列表索引超出范围
我尝试这样修复错误
for i in range(min(len(actual),len(predicted)))
if actual[i] == predicted[i]
correct += 1
return correct / float(len(actual)) * 100.0
我得到
分数: [3.3333333333333335]
平均准确率: 3.333%
我没有得到和您一样的 96% 的结果。如果您能帮助我发现问题,您的帮助和努力将不胜感激。
Alaa
博士生
你好 Alaa…你是复制代码还是手动输入的?另外,你有没有在 Google Colab 和你本地的 Python 环境中尝试过你的代码?
James 博士您好,我发了两条回复,但它们没有出现在网站上。我已经输入了代码并在 Google Colab 上应用了,但是遇到了同样的问题。任何其他的建议或意见都将不胜感激。
ALAA
非常棒的文章。感谢分享。
感谢您的反馈!我们非常感激!