机器学习是一个研究领域,它关注从示例中学习的算法。
分类是一项需要使用机器学习算法的任务,这些算法学习如何将类标签分配给问题域中的示例。一个易于理解的例子是将电子邮件分类为“垃圾邮件”或“非垃圾邮件”。
在机器学习中,您可能会遇到许多不同类型的分类任务以及可用于每种任务的专门建模方法。
在本教程中,您将了解机器学习中不同类型的分类预测建模。
完成本教程后,您将了解:
- 分类预测建模涉及将类标签分配给输入示例。
- 二元分类是指预测两个类中的一个,多类分类涉及预测两个以上类中的一个。
- 多标签分类涉及为每个示例预测一个或多个类,不平衡分类是指类之间示例分布不均的分类任务。
使用我的新书《使用Python进行机器学习精通》**启动您的项目**,包括*分步教程*和所有示例的*Python源代码*文件。
让我们开始吧。

机器学习中的分类类型
照片由Rachael拍摄,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 分类预测建模
- 二元分类
- 多类分类
- 多标签分类
- 不平衡分类
分类预测建模
在机器学习中,分类是指一种预测建模问题,其中为给定输入数据示例预测类标签。
分类问题的示例包括:
- 给定一个示例,判断它是否是垃圾邮件。
- 给定一个手写字符,将其分类为已知字符之一。
- 根据最近的用户行为,判断是否流失。
从建模的角度来看,分类需要一个包含大量输入和输出示例的训练数据集才能进行学习。
模型将使用训练数据集,并计算如何最好地将输入数据示例映射到特定的类标签。因此,训练数据集必须充分代表问题,并包含每个类标签的许多示例。
类标签通常是字符串值,例如“垃圾邮件”、“非垃圾邮件”,并且在提供给算法进行建模之前必须映射到数值。这通常被称为标签编码,其中为每个类标签分配一个唯一的整数,例如“垃圾邮件”= 0,“非垃圾邮件”= 1。
有许多不同类型的分类算法可用于解决分类预测建模问题。
关于如何将算法映射到问题类型没有好的理论;相反,通常建议从业者使用受控实验,并发现哪种算法和算法配置能为给定的分类任务带来最佳性能。
分类预测建模算法根据其结果进行评估。分类准确率是一种流行的指标,用于根据预测的类标签评估模型的性能。分类准确率并不完美,但对于许多分类任务来说是一个很好的起点。
除了类标签之外,某些任务可能需要预测每个示例的类成员概率。这提供了预测中额外的 U-性,应用程序或用户可以对其进行解释。评估预测概率的流行诊断工具是ROC曲线。
您可能会遇到大约四种主要类型的分类任务;它们是:
- 二元分类
- 多类分类
- 多标签分类
- 不平衡分类
让我们依次仔细看看每一个。
二元分类
二元分类是指那些具有两个类标签的分类任务。
示例包括
- 电子邮件垃圾邮件检测(垃圾邮件或非垃圾邮件)。
- 客户流失预测(流失或未流失)。
- 转化预测(购买或未购买)。
通常,二元分类任务涉及一个正常状态类和另一个异常状态类。
例如,“非垃圾邮件”是正常状态,“垃圾邮件”是异常状态。另一个例子是,在涉及医学测试的任务中,“未检测到癌症”是正常状态,“检测到癌症”是异常状态。
正常状态的类被分配类标签0,异常状态的类被分配类标签1。
通常使用预测每个示例的伯努利概率分布的模型来对二元分类任务进行建模。
伯努利分布是一种离散概率分布,涵盖了事件将具有二元结果(0或1)的情况。对于分类,这意味着模型预测示例属于类1(异常状态)的概率。
可用于二元分类的流行算法包括:
- 逻辑回归
- k-近邻
- 决策树
- 支持向量机
- 朴素贝叶斯
有些算法专门为二元分类设计,不原生支持两个以上的类;例如逻辑回归和支持向量机。
接下来,让我们仔细看看一个数据集,以培养对二元分类问题的直觉。
我们可以使用 make_blobs() 函数来生成一个合成的二元分类数据集。
下面的例子生成了一个包含1000个示例的数据集,这些示例属于两个类别中的一个,每个类别有两个输入特征。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 二元分类任务示例 from numpy import where from collections import Counter from sklearn.datasets import make_blobs from matplotlib import pyplot # 定义数据集 X, y = make_blobs(n_samples=1000, centers=2, random_state=1) # 总结数据集形状 print(X.shape, y.shape) # 按类标签汇总观测结果 counter = Counter(y) print(counter) # 汇总前几个示例 for i in range(10): print(X[i], y[i]) # 绘制数据集并按类标签着色 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先总结了创建的数据集,显示了1000个示例分为输入(X)和输出(y)元素。
然后总结了类标签的分布,显示实例属于类0或类1,并且每个类中有500个示例。
接下来,总结了数据集中的前10个示例,显示输入值是数值,目标值是表示类成员资格的整数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
(1000, 2) (1000,) 计数器({0: 500, 1: 500}) [-3.05837272 4.48825769] 0 [-8.60973869 -3.72714879] 1 [1.37129721 5.23107449] 0 [-9.33917563 -2.9544469 ] 1 [-11.57178593 -3.85275513] 1 [-11.42257341 -4.85679127] 1 [-10.44518578 -3.76476563] 1 [-10.44603561 -3.26065964] 1 [-0.61947075 3.48804983] 0 [-10.91115591 -4.5772537 ] 1 |
最后,为数据集中的输入变量创建了一个散点图,并根据它们的类值对点进行了着色。
我们可以看到两个截然不同的集群,我们可能会认为它们很容易区分。
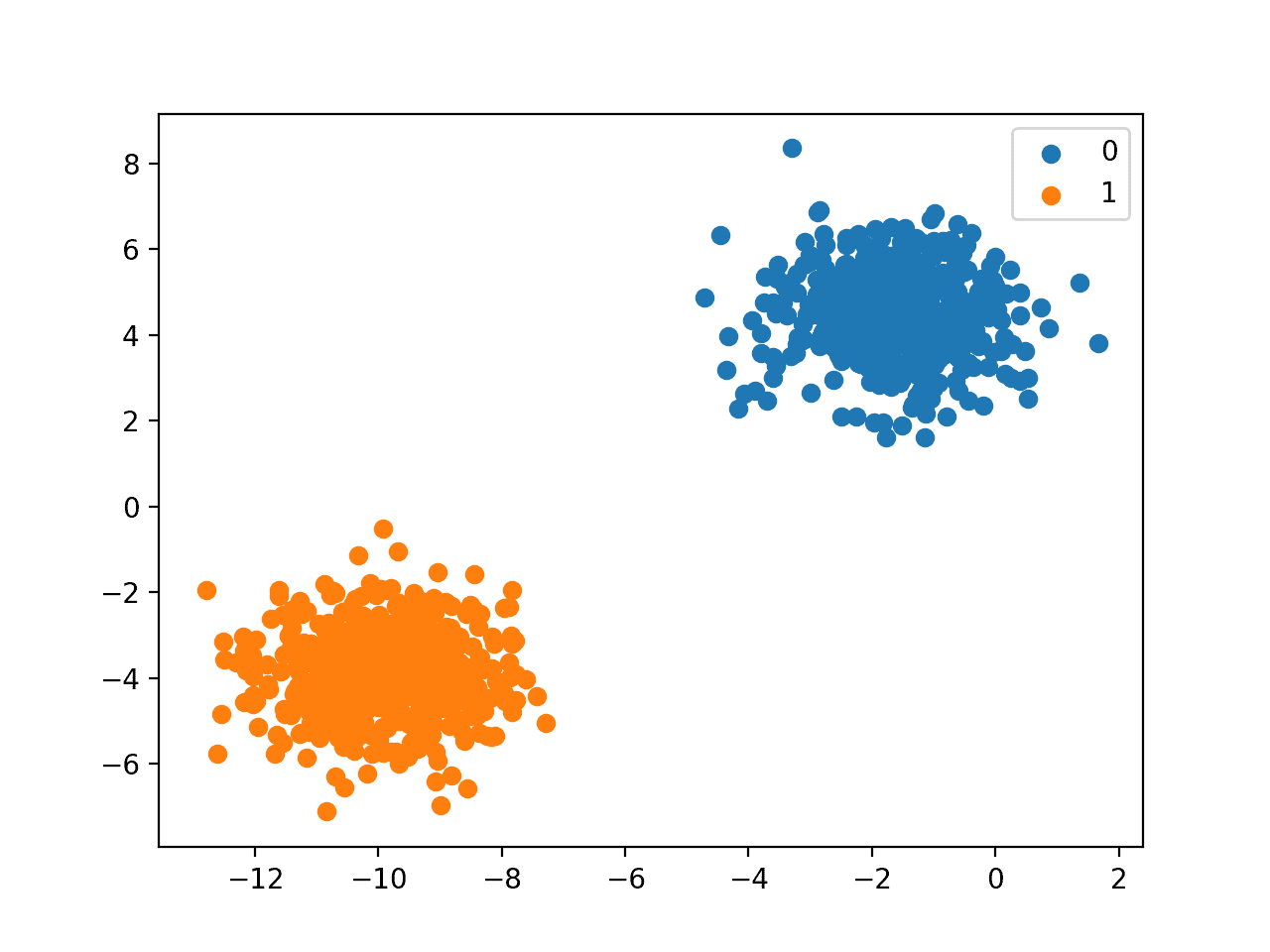
二元分类数据集的散点图
多类分类
多类分类是指那些具有两个以上类标签的分类任务。
示例包括
- 人脸分类。
- 植物物种分类。
- 光学字符识别。
与二元分类不同,多类分类没有正常和异常结果的概念。相反,示例被归类为属于已知类别范围中的一个。
在某些问题中,类标签的数量可能非常大。例如,模型可能在人脸识别系统中将一张照片分类为数千或数万张人脸中的一张。
涉及预测词序列的问题,例如文本翻译模型,也可以被视为一种特殊类型的多类分类。预测的词序列中的每个词都涉及多类分类,其中词汇表的大小定义了可能预测的类别数量,可能达到数万或数十万个词。
通常使用预测每个示例的多项式概率分布的模型来对多类分类任务进行建模。
多项式分布是一种离散概率分布,涵盖事件将具有分类结果的情况,例如 K 在 {1, 2, 3, ..., K} 中。对于分类,这意味着模型预测示例属于每个类标签的概率。
许多用于二元分类的算法都可以用于多类分类。
可用于多类分类的流行算法包括:
- k-近邻。
- 决策树。
- 朴素贝叶斯。
- 随机森林。
- 梯度提升。
为二元分类设计的算法可以适应多类问题。
这涉及到使用一种策略,即为每个类与所有其他类(称为一对多)或为每对类拟合一个模型(称为一对一)拟合多个二元分类模型。
- 一对多:为每个类别拟合一个二元分类模型,对抗所有其他类别。
- 一对一:为每对类别拟合一个二元分类模型。
可用于多类分类的二元分类算法包括:
- 逻辑回归。
- 支持向量机。
接下来,让我们更深入地了解一个数据集,以培养对多类分类问题的直觉。
我们可以使用 make_blobs() 函数来生成一个合成的多类分类数据集。
下面的例子生成了一个包含1000个示例的数据集,这些示例属于三个类别中的一个,每个类别有两个输入特征。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 多类分类任务示例 from numpy import where from collections import Counter from sklearn.datasets import make_blobs from matplotlib import pyplot # 定义数据集 X, y = make_blobs(n_samples=1000, centers=3, random_state=1) # 总结数据集形状 print(X.shape, y.shape) # 按类标签汇总观测结果 counter = Counter(y) print(counter) # 汇总前几个示例 for i in range(10): print(X[i], y[i]) # 绘制数据集并按类标签着色 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先总结了创建的数据集,显示了1000个示例分为输入(X)和输出(y)元素。
然后总结了类标签的分布,显示实例属于类0、类1或类2,并且每个类中大约有333个示例。
接下来,总结了数据集中的前10个示例,显示输入值是数值,目标值是表示类成员资格的整数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
(1000, 2) (1000,) 计数器({0: 334, 1: 333, 2: 333}) [-3.05837272 4.48825769] 0 [-8.60973869 -3.72714879] 1 [1.37129721 5.23107449] 0 [-9.33917563 -2.9544469 ] 1 [-8.63895561 -8.05263469] 2 [-8.48974309 -9.05667083] 2 [-7.51235546 -7.96464519] 2 [-7.51320529 -7.46053919] 2 [-0.61947075 3.48804983] 0 [-10.91115591 -4.5772537 ] 1 |
最后,为数据集中的输入变量创建了一个散点图,并根据它们的类值对点进行了着色。
我们可以看到三个截然不同的集群,我们可能会认为它们很容易区分。
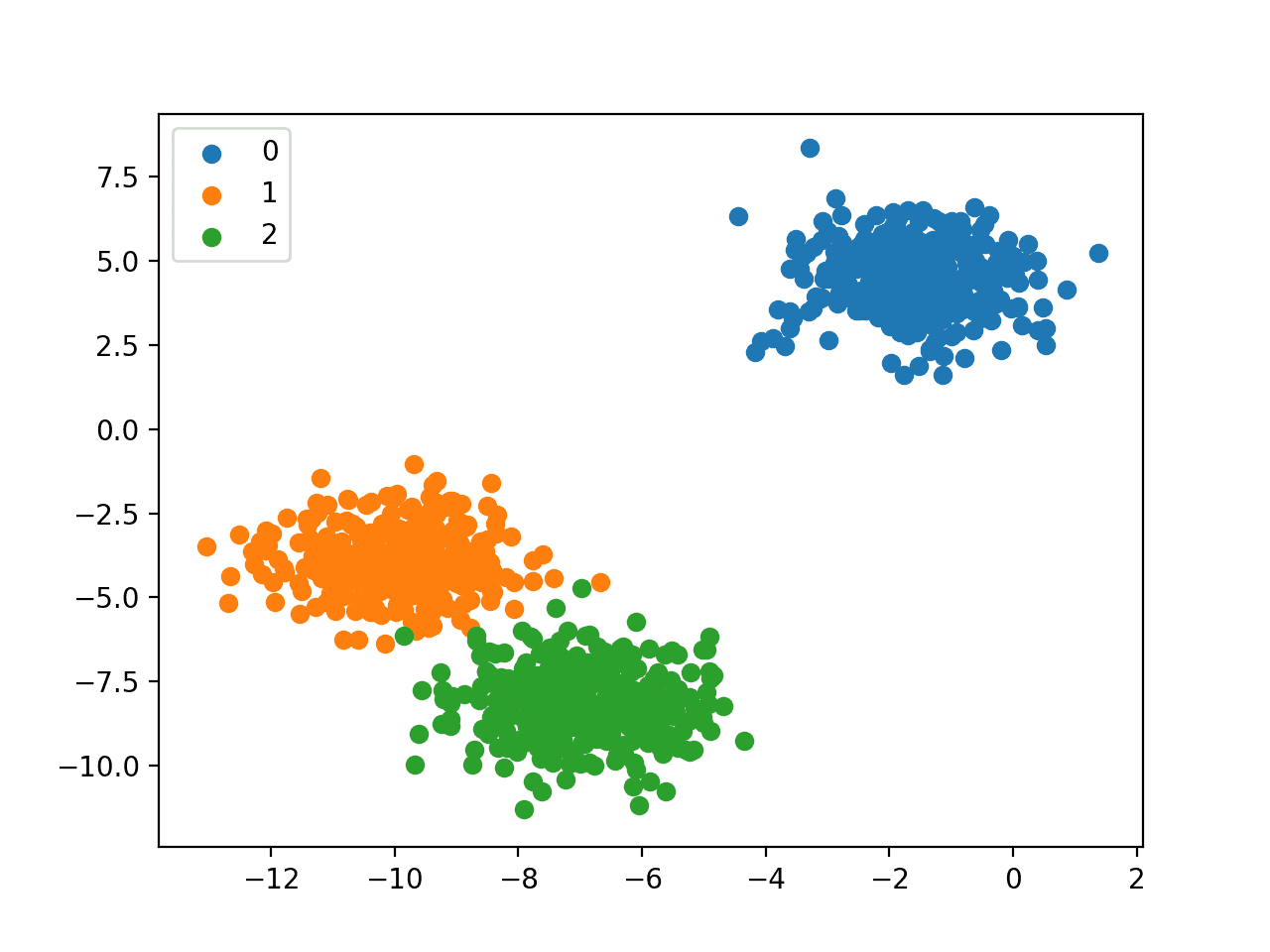
多类分类数据集的散点图
多标签分类
多标签分类是指那些具有两个或更多类标签的分类任务,其中每个示例可以预测一个或多个类标签。
考虑照片分类的例子,一张给定的照片中可能包含多个物体,模型可能会预测照片中存在多个已知物体,例如“自行车”、“苹果”、“人”等。
这与二元分类和多类分类不同,在二元分类和多类分类中,每个示例只预测一个类标签。
通常使用预测多个输出的模型来对多标签分类任务进行建模,每个输出都被预测为伯努利概率分布。这本质上是一个为每个示例进行多次二元分类预测的模型。
用于二元或多类分类的分类算法不能直接用于多标签分类。可以使用标准分类算法的专门版本,即所谓的算法的多标签版本,包括:
- 多标签决策树
- 多标签随机森林
- 多标签梯度提升
另一种方法是使用单独的分类算法来预测每个类别的标签。
接下来,让我们更深入地了解一个数据集,以培养对多标签分类问题的直觉。
我们可以使用 make_multilabel_classification() 函数来生成一个合成的多标签分类数据集。
下面的例子生成了一个包含1000个示例的数据集,每个示例有两个输入特征。有三个类别,每个类别可以取两个标签中的一个(0或1)。
|
1 2 3 4 5 6 7 8 9 |
# 多标签分类任务示例 from sklearn.datasets import make_multilabel_classification # 定义数据集 X, y = make_multilabel_classification(n_samples=1000, n_features=2, n_classes=3, n_labels=2, random_state=1) # 总结数据集形状 print(X.shape, y.shape) # 汇总前几个示例 for i in range(10): print(X[i], y[i]) |
运行示例首先总结了创建的数据集,显示了1000个示例分为输入(X)和输出(y)元素。
接下来,总结了数据集中的前10个示例,显示输入值是数值,目标值是表示类标签成员资格的整数。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
(1000, 2) (1000, 3) [18. 35.] [1 1 1] [22. 33.] [1 1 1] [26. 36.] [1 1 1] [24. 28.] [1 1 0] [23. 27.] [1 1 0] [15. 31.] [0 1 0] [20. 37.] [0 1 0] [18. 31.] [1 1 1] [29. 27.] [1 0 0] [29. 28.] [1 1 0] |
不平衡分类
不平衡分类是指每个类别中的示例数量分布不均的分类任务。
通常,不平衡分类任务是二元分类任务,其中训练数据集中的大多数示例属于正常类别,而少数示例属于异常类别。
示例包括
- 欺诈检测。
- 异常值检测。
- 医学诊断测试。
这些问题被建模为二元分类任务,尽管可能需要专门的技术。
可以使用专门的技术来改变训练数据集中样本的组成,通过对多数类进行欠采样或对少数类进行过采样。
示例包括
可以使用专门的建模算法,这些算法在训练数据集上拟合模型时,会更关注少数类别,例如成本敏感型机器学习算法。
示例包括
- 成本敏感型逻辑回归.
- 成本敏感型决策树。
- 成本敏感型支持向量机。
最后,可能需要替代的性能指标,因为报告分类准确率可能会产生误导。
示例包括
- 精确率。
- 召回率。
- F-度量。
接下来,让我们仔细看看一个数据集,以培养对不平衡分类问题的直觉。
我们可以使用 make_classification() 函数来生成一个合成的不平衡二元分类数据集。
下面的例子生成了一个包含1000个示例的数据集,这些示例属于两个类别中的一个,每个类别有两个输入特征。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 不平衡二元分类任务示例 from numpy import where from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_classes=2, n_clusters_per_class=1, weights=[0.99,0.01], random_state=1) # 总结数据集形状 print(X.shape, y.shape) # 按类标签汇总观测结果 counter = Counter(y) print(counter) # 汇总前几个示例 for i in range(10): print(X[i], y[i]) # 绘制数据集并按类标签着色 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先总结了创建的数据集,显示了1000个示例分为输入(X)和输出(y)元素。
然后总结了类标签的分布,显示出严重的类不平衡,大约980个示例属于类0,大约20个示例属于类1。
接下来,总结了数据集中的前10个示例,显示输入值是数值,目标值是表示类成员资格的整数。在这种情况下,我们可以看到大多数示例属于类0,正如我们所预期的那样。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
(1000, 2) (1000,) 计数器({0: 983, 1: 17}) [0.86924745 1.18613612] 0 [1.55110839 1.81032905] 0 [1.29361936 1.01094607] 0 [1.11988947 1.63251786] 0 [1.04235568 1.12152929] 0 [1.18114858 0.92397607] 0 [1.1365562 1.17652556] 0 [0.46291729 0.72924998] 0 [0.18315826 1.07141766] 0 [0.32411648 0.53515376] 0 |
最后,为数据集中的输入变量创建了一个散点图,并根据它们的类值对点进行了着色。
我们可以看到一个主要的属于类0的集群,以及一些散落在外的属于类1的示例。直觉告诉我们,具有这种不平衡类标签特性的数据集更具挑战性。
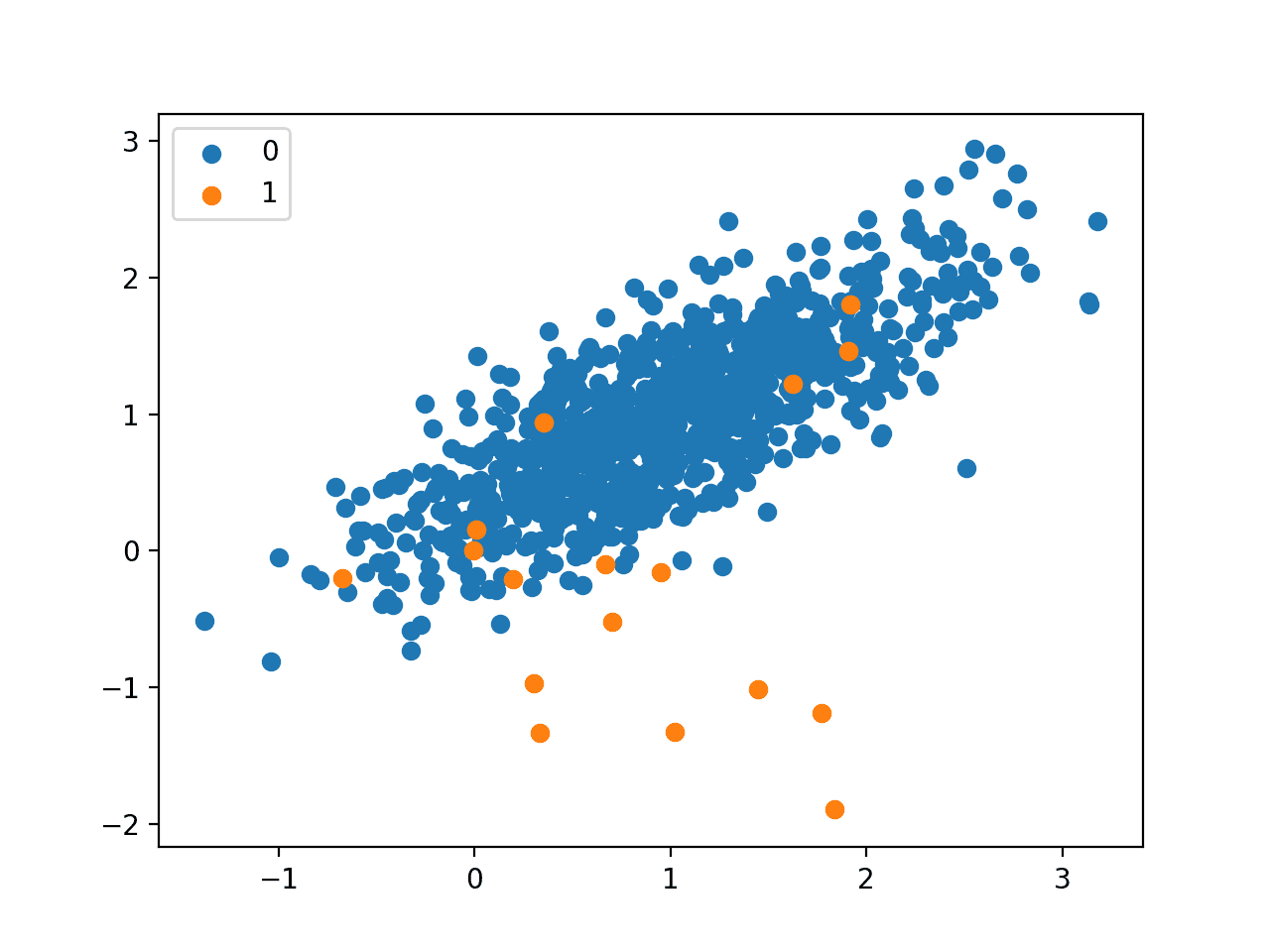
不平衡二元分类数据集的散点图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
总结
在本教程中,您了解了机器学习中不同类型的分类预测建模。
具体来说,你学到了:
- 分类预测建模涉及将类标签分配给输入示例。
- 二元分类是指预测两个类中的一个,多类分类涉及预测两个以上类中的一个。
- 多标签分类涉及为每个示例预测一个或多个类,不平衡分类是指类之间示例分布不均的分类任务。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。






您的内容太棒了,先生!!!
谢谢!
先生,
感谢您如此清晰易懂的解释。
此致
亲爱的杰森,愿上帝保佑您,有没有办法通过机器学习从多元变量回归中提取公式或方程?
我们可以使用模型来推断公式,而不是提取公式。
不需要机器学习,只需使用回归模型。
嗨,Jason,
为了跟进您对这个问题的回答,我有一个愚蠢的问题:应用于回归问题的机器学习和回归模型之间有什么区别?这个问题有时让我很困惑,您的回答将不胜感激!
没有。
需要数值预测的数据集是一个回归问题。
在回归数据集上拟合的算法是回归算法。
使用回归算法拟合的模型是回归模型。
这有帮助吗?
谢谢杰森,很有帮助!那我还有一个问题:线性混合模型呢?我知道它可以用于回归问题,它也可以用于机器学习吗?如果可以,我没有看到它在机器学习中有很多应用,也许我被蒙蔽了。
抱歉,我没有关于这个主题的教程。
抱歉杰森,我忘了告诉您,我指的是使用Python进行非线性回归,非常感谢您
当然可以。
谢谢!
对我来说非常有用的文章。
很高兴听到这个!
嗨,感谢您的精彩内容。最近我尝试了迁移学习方法,从一个包含约5000张图片和20个类别的数据集中学习服装风格。我的类别数据非常不平衡,例如,一个类别有1000张图片,而其他19个类别总共有约4000张图片。我尝试了加权类别,但当涉及到预测时,模型预测总是介于2个类别之间,从未得到其他类别。有没有比加权类别更好的方法?或者您对为什么会这样有何看法?
除了加权,您还可以尝试对数据进行重采样。但是,如果您的结果介于两个类别之间,那又有什么问题呢?如果您想查看所有20个类别的预测分数,我猜您需要在后处理部分做一些事情,将模型输出转换为您想要的样式。
谢谢您,先生,您的这份出色工作。
谢谢。很高兴你喜欢。
嗨 Jason
感谢您的教程。
根据您的教程,对于多类分类,
可用于多类分类的二元分类算法,包括一对多和一对一策略,有:
逻辑回归。
支持向量机。
1). 您是否有应用这两种策略的逻辑回归代码示例?
2). 在您的教程“Python机器学习项目第一步”中,您使用逻辑回归和SVC来预测鸢尾花数据,这是一个多类分类问题。为什么您没有应用一对多和一对一策略中的任何一个?
3). 您是否有关于多标签分类的教程或代码示例?
https://machinelearning.org.cn/machine-learning-in-python-step-by-step/
谢谢,
索菲亚
非常有用的机器学习文章,谢谢您,先生
谢谢。
结构非常好!谢谢。
谢谢!
嗨,Jason,
我有一个分类问题,即优化算法的结果。我的KNN分类算法在一个csv文件中提供了一份很好的文章列表,我想用它进行工作。那些被分类为“是”的表示相关,那些被分类为“否”的表示不相关。
我使用欧几里得距离并得到一个项目列表。最终结果会生成一个包含10个项目的列表(或我应用的任何k值)。基本上,我将距离视为一个排名。
问题
如何最好地投影一份相关项目列表以继续进行?——也就是说,如何潜在地循环第一个列表结果(例如当k=10时,8个“是”和2个“否”)?
我猜我不需要再次预处理文本,也不需要运行TD-IDF。我确实尝试简单地运行 k=998(对应于数据加载中的总条目列表),删除所有内容,然后删除所有带有“否”的文章。这会保持距离不受影响,但这是正确的做法吗?我想象中我必须再次训练数据,而且我不确定如何协调这个循环。任何帮助都将不胜感激。
谢谢,Jens
一个错字溜了进去……
我尝试简单地运行 k=998(对应于数据加载中的总条目列表),删除所有内容,然后删除所有带有“否”的文章。应该说
我尝试简单地运行 k=998(对应于数据加载中的总条目列表),然后删除所有带有“否”的文章。
抱歉,我没明白。或许可以尝试在Stack Overflow上提问,或者您可以将问题简化一下?
那单类别呢,杰森?我们可以把这个概念放在哪里?
异常检测(即根本不同),否则就是二元分类。
嗨,Jason,
感谢这篇很棒的文章!它帮了我很多。
问答或具体来说是跨度提取(Span Extraction)属于哪种分类?模型必须在一个段落中选择起始和结束索引的情况。这是多类别分类吗?你写道:“涉及预测词序列的问题,例如文本翻译模型,也可以被视为一种特殊的多类别分类。要预测的词序列中的每个词都涉及一个多类别分类,其中词汇表的大小定义了可能预测的类别数量,可能达到数万或数十万个词。” 这对于跨度提取问题也是一样的吗?
提前感谢您!
问答是序列生成——而不是分类。我不知道跨度提取是什么。
https://machinelearning.org.cn/sequence-prediction-problems-learning-lstm-recurrent-neural-networks/
谢谢您的快速回复!
跨度提取的定义是:“给定上下文 C,包含 n 个词元,即 C = {t1, t2, ..., tn},以及问题 Q,跨度提取任务要求从上下文 C 中提取连续子序列 A = {ti, ti+1, ..., ti+k} (1 <= i <= i + k <= n) 作为问题 Q 的正确答案,通过学习函数 F,使得 A = F(C,Q)。”
这是SQuAD任务。BiDAF、QANet 和其他模型为给定上下文中的每个词计算作为答案起始和结束的概率。它们使用交叉熵损失,这是用于分类的。这就是我感到困惑的原因。我不明白在这种情况下类别会是什么?起始和结束吗?
我不认为跨度提取是一个序列生成问题?没有词被预测/生成,而只是计算了起始和结束。我错了吗?
谢谢。
谢谢这篇好文章!它帮了我很多!
不客气。
嗨 Jason,
非常棒的帖子!您提到一些最初设计用于二元分类的算法也可以应用于多类别分类,例如逻辑回归和支持向量机。我对此有两个问题:
(1) 您能详细说明一下它们的“扩展”是什么意思吗?是指算法本身的修改,还是指相应软件包的源代码?作为用户,如果我们要将逻辑回归和支持向量机用于多类别分类,是否需要额外做些什么?
(2) 实际上我尝试了逻辑回归和支持向量机在多类别分类上的应用,但似乎只有支持向量机有效(我是在 R 中尝试的),而逻辑回归却报错说只能用于二元分类。这是真的吗,还是我做错了什么?
提前非常感谢!
谢谢。
我们通常可以使用 OVR 将二元分类适应为多类别分类,这里有一些例子
https://machinelearning.org.cn/one-vs-rest-and-one-vs-one-for-multi-class-classification/
谢谢你,Jason!
不客气。
嗨,Jason!!我刚开始学习机器学习,您的教程是最棒的!非常感谢您分享您的知识。
如果您能帮我解决这个问题,我将不胜感激。
我有一个包含水化学性质的数据集。我利用其中一些性质创建了一个新的列作为分类标签:“清洁水”和“不清洁水”。例如,我使用水中“钙”、“pH”和“电导率”的限值来分类水是否清洁。
我的问题是,我是否可以使用分类监督学习来预测我创建的这个输出变量(清洁水或不清洁水),同时使用我用来计算它的相同属性(“钙”、“pH”和“电导率”)作为输入变量。或者我是否可以使用我没有用来创建它的其他属性来预测标签。
我不知道是否可以对依赖于输入变量的标签使用监督分类学习?
我认为回归监督学习不能用于预测依赖于其他变量的变量(如果它是通过使用其他变量的方程创建的),这正确吗?
这听起来像分类问题。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-classification-and-regression
或许可以开发一个原型模型,并测试是否可以将该问题建模为分类问题。
Jason,
我给会计专业的学生教授数据分析基础知识。您的示例非常宝贵!很棒的工作。
谢谢理查德!
好东西,谢谢。
不客气!
尊敬的Jason博士,
感谢您的时间。
在“二元分类”标题下,有20行代码。
特别有趣的是第19行
是的,我看了文档在
https://matplotlib.net.cn/3.2.1/api/_as_gen/matplotlib.pyplot.scatter.html
它的第一行写着 scatterplot(x, y)
请问
为什么您要将 X 的一个特征与 X 的另一个特征绘图?也就是 X[row_ix,0] 与 X[row_ix,1] 相对,而不是 X 与 Y?
我知道这很明显,但“醍醐灌顶”的感觉还没有出现。
或者换句话说,为什么要绘制一个特征与另一个特征?
谢谢你,
悉尼的Anthony
散点图根据定义就是绘制一个变量与另一个变量。
在该示例中,我们针对每个类别绘制第0列与第1列。
尊敬的Jason博士,
谢谢您的回复,特别是散点图是一个变量与另一个变量的图,而不是 X 变量与 Y 变量的图。
我的问题是:给定一个变量与另一个变量的图,我想知道 X1(比如说)与 X2 的图和 X1 与 Y 的图之间精确的定义有什么不同。
换句话说,当绘制一个 X 变量与另一个 X 变量时,我们会得到什么信息?相关性?X1 和 X2 之间的距离有多远?
谢谢你,
悉尼的Anthony
散点图显示了两个变量之间的关系,例如它们的值如何变化时相互关联。
例如,如果它们都以相同的方向变化,例如正向,它有助于看到相关性。
尊敬的Jason博士,
另外一个问题,谢谢
在您的示例中,您绘制了 X 的一个特征与 X 的另一个特征的图。
如果您有两个以上特征,并且希望将一个特征与另一个特征绘制出来,该怎么做?例如,Iris 数据有四个特征。您是否必须绘制 4C2 = 6 个散点图?如果您有 10 个特征,那将是 10C2 = 45 个图?
谢谢你,
悉尼的安东尼,
您可以创建多个成对散点图,这里有一个示例:
https://machinelearning.org.cn/predictive-model-for-the-phoneme-imbalanced-classification-dataset/
尊敬的Jason博士,
首先谢谢您。并且感谢您指引我到 https://machinelearning.org.cn/predictive-model-for-the-phoneme-imbalanced-classification-dataset/ 的 scatter_matrix,
我查看了用于显示一个 X 变量与另一个 X 变量的成对散点图的多图的 scatter_matrix 过程。
多成对图包含了大量信息。
问题——关于解释多个成对关系,您有什么建议吗?
谢谢你。
悉尼的Anthony
我有很多关于这方面的内容,也许可以把这个作为第一步。
https://machinelearning.org.cn/machine-learning-in-python-step-by-step/
还有这个。
https://machinelearning.org.cn/how-to-use-correlation-to-understand-the-relationship-between-variables/
尊敬的Jason博士,
谢谢您,您最棒了。
我进一步研究了来自 pandas.plotting 的 scatter_matrix。
我尝试了绘制所有 X 的成对散点图。
在尝试了 X 的所有特征的成对比较后,scatter_matrix 有一个缺陷,那就是不像 pyplot 的 scatter,它不能像上面博客中那样按类别标签绘制。
这是 Iris 数据的 scatter matrix 代码。
结论
* scatter_matrix 允许所有变量的成对散点图。
* scatter matrix 需要一个数据框结构作为输入,而不是矩阵。
* 但是 scatter_matrix 不允许您根据 y 中定义的分类标签(即 setosa、virginicum 和 versicolor)来绘制变量。
待办事项——使用 pyplot 的子图来显示根据 y 的类别显示的所有成对 X 特征。
谢谢你,
悉尼的Anthony
是的,相信 Seaborn 版本允许按类别标签进行成对散点图。我有一篇关于这个的帖子已经写好并安排发布。
尊敬的Jason博士,
感谢您告知即将发布一篇关于按类别标签绘制成对散点图的帖子。我很期待。
重申一下,我想要带有基于类别标签的图例的散点图,如本页所示。我想将其扩展到所有按类别标签进行 X 的成对比较。
在 https://machinelearning.org.cn/predictive-model-for-the-phoneme-imbalanced-classification-dataset/ 有一个按类别标签的散点图矩阵,但表示类别标签的不同颜色没有在每个图中显示类别标签图例。
此外,我遇到的散点矩阵问题是,如果您有 4 个 X 变量,比如说变量 1、2、3、4,可能的配对是 (1,2)、(2,1)、(1,3)、(3,1)、(1,4)、(4,1)、(2,3)、(3,2)、(2,4)、(4,2) 和 (3,4) 以及 (4,3) = 12 个图。
但您不需要重复的图。您可以通过 (1,2)、(1,3)、(1,4)、(2,3)、(2,4) 和 (3,4) 得到最少的图,即 4C2 = 6。
https://seaborn.org.cn/generated/seaborn.scatterplot.html 底部的 seaborn 方法让我感到困惑,它的顶部有一个变量标签,底部有一个变量标签,左侧有一个变量标签,然后右侧有一个图例。
谢谢你,
悉尼的安东尼。
尊敬的Jason博士,
我找到了我想要的东西,接近于
https://seaborn.org.cn/examples/scatterplot_matrix.html。它绘制了 X 的成对散点图,并在图的最右侧带有图例。
结论
* X 的所有成对图都可以通过显示类别 y 的图例来实现。比 scatter_matrix 更容易使用,可能也比编写自己的算法来绘制所有 X 的成对图更容易。
* pairplot 函数需要一个 DataFrame 对象。DataFrame 的文件是一个 csv 文件,可以通过 seaborn 内置的 load('file')(其中 'file' 是文件名)或 panda 的 read_csv 从服务器下载。
* 如果您的数据是其他形式,例如矩阵,您可以将矩阵转换为 DataFrame 文件。
* 就我个人品味而言,seaborn 的图形比 pyplot 的图形更美观,尽管您需要 pyplot 的 show() 函数来显示图形。
* 再次就个人品味而言,我更喜欢由 (1,2)、(1,3)、(1,4)、(2,3)、(2,4) 和 (3,4) 组成的 4C2 个图,而不是 seaborn 或 panda 的 scatter_matrix,后者会绘制 2*4C2 个图,例如 (1,2)、(2,1)、(1,3)、(3,1)、(1,4)、(4,1)、(2,3)、(3,2)、(3,4) 和 (4,3)。
谢谢你,
悉尼的Anthony
干得不错。
很棒的文章!只是在“不平衡分类”标题下发现了一个拼写错误:应该是对少数类进行过采样(oversampling)。
谢谢!已修复。
非常感谢
理论解释得很好,先生。
谢谢!
先生,如果我有一个需要进行两次分类的数据集怎么办?
我的意思是,如果我有一个数据集,像这样:
自变量 – A,
因变量 – 1,另一个因变量 – 2,它又依赖于因变量 – 1
我该如何解决这个问题?
抱歉我的英语不好…
这听起来像一个多目标预测问题。
也许可以从为每个目标建模两个独立的预测问题开始。
我想再次对二元分类的结果进行分类。我应该使用什么方法?
您所说的对二元分类结果进行分类是什么意思?
如果您是指将模型的输出作为另一个模型的输入,就像堆叠集成一样,那么这可能会有所帮助。
https://machinelearning.org.cn/stacking-ensemble-machine-learning-with-python/
感谢您的文章。
不客气。
嗨,Jason,
我怎么才能找到您的书?
谢谢,
您可以在这里查看完整的 19 本书和图书套装目录
https://machinelearning.org.cn/products/
这确实是一篇非常有用的文章。感谢分享。您能否撰写一篇关于如何应用不同的数据过采样和欠采样技术,包括 SMOTE 到文本数据(例如情感分析数据集,二元分类)的文章?
谢谢!
我认为这些传统方法不适用于文本数据,也许您可以查阅文献寻找文本数据增强方法?
谢谢!
您能附上一个多标签问题可视化的例子吗?
例如带有饼图标记的散点图…
不,它可视化效果不好。
这里有一个例子可能会有所帮助:
https://machinelearning.org.cn/multi-label-classification-with-deep-learning/
尊敬的Jason博士,
我参考的是最后一张图,它是数据的散点图。
橙色点 = y 结果 = 1,蓝色点 = y 结果 == 0
我想预测当 X = 所有特征且 y == 1 时会发生什么。
我预期 yhat 主要是像这样的 1,就像蓝色点中橙色点 == y == 1。只得到 30% 的值预测为 1。
请问:我预期 yhat 主要是 1,就像橙色点 == y == 1 在蓝色点中。但只得到了 30% 的值预测为 1。
有什么方法可以提高模型的预测能力吗?
谢谢你,
悉尼的Anthony
或许您可以将其建模为一个不平衡分类项目。
https://machinelearning.org.cn/start-here/#imbalanced
尊敬的Jason博士,
再次感谢您。
感谢您在https://machinelearning.org.cn/start-here/#imbalanced上提供的摘要参考。
因此,我转到了https://machinelearning.org.cn/cost-sensitive-logistic-regression/上的成本敏感逻辑回归。
这是用于预测yhat的组合代码。
结果:根据我设置make_classification合成数据的方式,我设法使yhat/实际(y)的准确率在76%到100%之间。
结果二:即使在y == 0和y == 1的X之间存在相当大的重叠,我也设法获得了yhat/实际(y)的100%预测。
这是程序
这是打印输出
其他结果,
n_clusters_per_class = 1, flip_y = 0.05, AUC = 0.699, predicted/actual*100=100%
n_clusters_per_class = 1, flip_y = 0, AUC = 0.993, predicted/actual*100=100%
结论
* 这并非逻辑回归和处理不平衡数据的全部。
* 仅仅因为AUC=0.7但预测率=100%可能意味着yhat中存在假阳性结果。
* 使用模型时,
X, y = make_classification(n_samples=10000, n_features=2, n_informative=2, n_redundant=0, n_classes=2, n_clusters_per_class=1, weights=[0.99,0.01], random_state=1)
结果是AUC = 0.819和yhat/actual(y)*100=74%
结论中的结论:在y == 0和y == 1的X之间存在相当大的重叠时,可以通过成本敏感逻辑回归预测y = 0或y = 1。但这取决于每个组中数据的性质。
谢谢你,
悉尼的Anthony
干得好!
通常,准确度对于不平衡数据集来说是一个糟糕的指标
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
请注意,AUC不是一个比率或百分比。
尊敬的Jason博士,
除了逻辑回归,我还受https://machinelearning.org.cn/cost-sensitive-decision-trees-for-imbalanced-classification/的启发,做了一个决策树分类器和一个GridSearchCV。
它们使用的是原始数据集
代码
结果是
类权重为{‘class_weight’: {0: 1, 1: 1}}的决策树分类器产生了最高的AUC,为88%,而简单决策树分类器为80%。
与成本敏感逻辑回归的99.3%进行比较。
同样,这些结果是针对上述特定合成数据集的。
结论:仅仅因为成本敏感逻辑回归的AUC结果最高,并不意味着成本敏感逻辑回归是最好的模型。
这取决于数据。
谢谢你,
悉尼的Anthony
干得好!
尊敬的Jason博士,
我的最佳结果使用了SMOTE逻辑回归。
代码如下:
结果
使用SMOTE决策树分类器
使用SMOTE逻辑回归
在所有测试的模型中,SMOTE与逻辑回归产生了平均AUC为0.996。
预测时,X_things是y==1时的X,我们将此预测回管道模型以获得以下预测
结论,SMOTE逻辑回归表现最佳,AUC = 0.996,产生了100%的预测。
结论:这并非模型的万能钥匙。模型的准确性取决于数据。
结论:当数据存在显著重叠时,我们可以预测结果y = 0或y = 1。
谢谢你,
悉尼的Anthony
干得好!
亲爱的Jason博士您好,
感谢您的文章。
我有一个数据集,通过这篇文章我发现我的数据集包含多个类别(多类别分类)。
数据集无噪声且标签独立。
现在,我有一个问题
我如何才能找出哪种算法最适合对这个数据集进行分类?
好问题,这会有帮助
https://machinelearning.org.cn/faq/single-faq/what-algorithm-config-should-i-use
> # 加载库
import pandas as pd import numpy as np from pandas import read_csv from pandas.plotting import scatter_matrix from
> matplotlib import pyplot from sklearn.model_selection import
> train_test_split from sklearn.model_selection import cross_val_score
>
> dataset1 = pd.read_csv(“mirai_dataset.csv”)
> dataset2 = pd.read_csv(“mirai_labels.csv”)
>
> dataset = pd.concat([dataset1, dataset2], axis=1)
>
>
> import os import numpy as np from sklearn import metrics from
> scipy.stats import zscore
>
> def expand_categories(values)
> result = []
> s = values.value_counts()
> t = float(len(values))
> for v in s.index
> result.append(“{}:{}%”.format(v,round(100*(s[v]/t),2)))
> return “[{}]”.format(“,”.join(result))
> def analyze(dataset)
> print()
> cols = dataset2.values
> total = float(len(dataset))
>
> print(“{} rows”.format(int(total)))
> for col in cols
> uniques = dataset[col].unique()
> unique_count = len(uniques)
> if unique_count>100
> print(“** {}:{} ({}%)”.format(col,unique_count,int(((unique_count)/total)*100)))
> else
> print(“** {}:{}”.format(col,expand_categories(dataset[col])))
> expand_categories(dataset[col])
>
>
> **# 分析 KDD-99 analyze(dataset)**
>
>
> KeyError: “None of [Int64Index([0], dtype=’int64′)] are in the
> [columns]
大家好,
我正在尝试加载数据集,包括它们的标签CSV文件,并且正在尝试分析数据并使用分类模型进行训练。有没有人可以提供一些建议来可视化数据集并使用分类模型训练数据集。另外,这个数据集是用于Mirai攻击的,将用于入侵检测系统,所以数据以良性开始,然后到某个点是攻击。
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
https://archive.ics.uci.edu/ml/machine-learning-databases/00516/mirai/
这是我正在使用的数据集链接…提前谢谢
抱歉,我对那个数据集不熟悉,无法给出好的即兴建议。
您能处理这个用例吗……然后告诉我您将如何实现它……?
我需要根据客户之前的付款模式来预测哪些客户不会付款。
在此用例中,抽取100个客户的样本(请告诉我您需要什么数据)
也许这个过程会有所帮助
https://machinelearning.org.cn/start-here/#process
你好
请问我们可以从分类数据中推导出图表吗?
“从数据中提取图表”是什么意思?
感谢您的教程。我有一个形态学数据,包含20个测量变量(例如长度、体重、……整个生物体)。例如,物种1、物种2、物种3、物种4在同一属中被发现,我测量了20个变量。我的问题是如何根据它们的相似性进行分类?
您有物种的标签吗?如果有,只需尝试拟合一个分类模型,看看它如何。它可能工作良好,也可能不工作良好,您将需要尝试不同的模型(例如,SVM的不同核)。这篇帖子中有一个鸢尾花分类的例子,可能有助于您入门:https://machinelearning.org.cn/get-your-hands-dirty-with-scikit-learn-now/
我正要离开这个领域,然后您的网站出现了,一切都改变了……谢谢您……!
我很高兴您觉得它有用。谢谢您。
非常好的文章,谢谢。我有一个问题——我正在开发一个模型,它具有连续输出(目标事件的连续风险),随时间变化。然而,目标标签是0/1,表示事件是否在特定时间(例如1年)内发生。在验证时,我们发现在许多情况下,在1年时,模型的风险预测很高,但没有事件记录。所以看起来预测是错误的。然而,如果我们查看1年后的数据,我们发现在1年之后很快就发生了事件。因此,在1年时计算的AUROC具有误导性,因为事件被右截尾。有没有办法从目标标签更适合分类的数据中创建一个回归模型?
您认为您可以重新标记您的数据,以计算未来6个月内发生的事件数量,并使用此数量作为输出,而不是事件是否在同一天发生?
你好
对于多类分类,什么比例被认为是不平衡的?3:1:1是否被认为是不平衡的?另外,有没有关于多类不平衡数据集的文章?到目前为止我只找到了二元分类的。
谢谢
严格来说,任何不是1:1的都是不平衡的。但不同的算法可能会因为不平衡数据集而产生不同的影响。我的思考过程是考虑您的指标(例如,准确性?F1?MSE?)以及不平衡可能对指标造成的严重程度。
你好 Adrian,
感谢您提供出色的内容,我有一个关于多标签分类的问题,希望您能回答。
如果新数据来了,并且它不属于任何类(在训练期间定义的类),会发生什么?模型会如何反应?它会用其现有类对数据进行分类吗?
我希望,如果新数据不属于任何类,那么模型不应该对其进行分类。我如何在构建模型时实现这一点?
训练好的模型就是您设计它能做的事情。您必须考虑如何处理新类。选项是重新训练模型(您需要完整的数据集),或者通过集成来修改模型。
内容解释得非常好。
谢谢!
在分类中,最终目标是预测以前未见过的数据记录的类别标签,这些数据记录具有未知的类别标签。另一方面,大量的分类任务涉及处理一个已经有答案的训练集。为什么在此过程中利用已经给出答案的训练集很重要?
你好Rob……这种学习被称为“监督学习”。以下内容希望能澄清。
https://machinelearning.org.cn/supervised-and-unsupervised-machine-learning-algorithms/
可能不会打扰您,但如果他们要使用您的文章,您可以要求他们至少给您署名。
嗨,先生,我们可以将多项式朴素贝叶斯用于多类分类吗?如果可以,为什么我们应该这样做?以及如何做?
嗨 Sheetal……您可能会对以下资源感兴趣:
https://www.mygreatlearning.com/blog/multiclass-classification-explained/
我有一个问题,我想对移动货币客户进行分类,不仅基于交易价值,最好的方法是什么?一些特征包括就业状况、收入来源(二元)、地理区域。
谢谢你
你好 Russel……您可能希望考虑聚类算法。
https://machinelearning.org.cn/clustering-algorithms-with-python/
我如何就这个主题制作演示文稿?
机器学习(分类)
你好 Mafeng……请重新措辞和/或澄清您的问题,以便我们更好地帮助您。
詹姆斯,我真的很喜欢您的内容。我有一个快速问题:如果我进行多类分类,并且我将要使用的数据集包含超过2个特征,我该如何修改您发布的多类分类?我尝试了make_blobs()的3个特征,绘图结果似乎比2个特征make_blob()数据集的准确性低。
感谢您的反馈,Hyungtaek!以下资源可能会增加清晰度。
https://machinelearning.org.cn/multi-label-classification-with-deep-learning/
您好,感谢您的帖子。
我可以使用神经网络进行多分类吗,例如正常高血压、高血压前期和高血压?
你好 Denis……这很有可能。请描述您的源数据和模型目标,以便我们更好地协助您。
我有一个数据集,其中列是list1、list2、list3和final
list1、list2、list3包含一个带有置信度分数的项目列表(作为元组),final列表将根据list1、list2、list3给出最终项目名称。
最终值是list1、list2、list3中的一个值。
现在,使用哪种机器学习模型以及如何使用该模型对这个数据集进行训练,并预测新记录的最终值?
这将有list1、list2、list3的值。
示例
list1 list2 list3 final
1 [{“bike”:0.89},{“cycle:0.76}] [{“scooty”:0.90}] [{“2 Weeler”:0.80}] [Bike]
你好 Ashish……为了解决您的问题,我们需要训练一个模型,根据提供的列表(
list1、list2、list3)预测最终项目。鉴于您的数据结构,我们可以将其视为一个分类问题,其中特征是带有置信度分数的项目列表,目标是final值。以下是分步方法:
### 步骤1:数据预处理
我们需要将带有置信度分数的项目列表转换为适合机器学习模型的格式。一种方法是为列表中每个项目创建一个特征向量,表示置信度分数。
### 步骤2:特征提取
通过为每个列表创建一个固定大小的向量,从
list1、list2和list3中提取特征。这个向量可以通过汇总或平均所有列表中每个独特项目的置信度分数来构建。### 步骤3:模型训练
选择一个分类模型(例如,逻辑回归、随机森林、XGBoost)来根据提取的特征和
final列进行训练。### 步骤4:预测
使用训练好的模型预测新记录的最终值。
以下是使用 Python 和
scikit-learn库的示例:pythonimport pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.pipeline import make_pipeline
from sklearn.compose import ColumnTransformer
from sklearn.feature_extraction import DictVectorizer
# 示例数据
data = {
'list1': [[{'bike': 0.89}, {'cycle': 0.76}]],
'list2': [[{'scooty': 0.90}]],
'list3': [[{'2 Wheeler': 0.80}]],
'final': ['bike']
}
df = pd.DataFrame(data)
# 特征提取函数
def extract_features(df)
mlb = MultiLabelBinarizer()
def flatten_list(lst)
return {k: v for d in lst for k, v in d.items()}
list1_features = pd.DataFrame(df['list1'].apply(flatten_list).tolist()).fillna(0)
list2_features = pd.DataFrame(df['list2'].apply(flatten_list).tolist()).fillna(0)
list3_features = pd.DataFrame(df['list3'].apply(flatten_list).tolist()).fillna(0)
features = pd.concat([list1_features, list2_features, list3_features], axis=1).fillna(0)
return features
# 提取特征
X = extract_features(df)
y = df['final']
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估
from sklearn.metrics import accuracy_score
print('准确率:', accuracy_score(y_test, y_pred))
# 预测新记录的函数
def predict_final(list1, list2, list3, model)
new_df = pd.DataFrame({'list1': [list1], 'list2': [list2], 'list3': [list3]})
new_X = extract_features(new_df)
return model.predict(new_X)
# 示例预测
list1 = [{'bike': 0.89}, {'cycle': 0.76}]
list2 = [{'scooty': 0.90}]
list3 = [{'2 Wheeler': 0.80}]
prediction = predict_final(list1, list2, list3, model)
print('预测的最终值:', prediction)
### 解释
1. **数据准备:**
– 我们定义了一个函数
extract_features,将字典列表转换为扁平数据帧,其中每列代表一个项目,值代表置信度分数。2. **特征提取:**
–
extract_features函数处理list1、list2和list3列,并连接生成的数据帧。3. **模型训练:**
– 我们使用
RandomForestClassifier对提取的特征进行训练。4. **预测:**
–
predict_final函数允许您通过处理输入列表并使用训练好的模型来预测新记录的最终值。这种方法可以根据您的数据集和要求的具体情况进行调整和扩展。关键是确保特征提取过程有效地捕获输入列表中的相关信息。