重采样方法旨在改变用于不平衡分类任务的训练数据集的构成。
在不平衡分类的重采样方法中,大部分注意力都集中在对少数类进行过采样上。尽管如此,已经开发出了一系列用于对多数类进行欠采样的方法,这些方法可以与有效的过采样方法结合使用。
尽管存在许多不同类型的欠采样技术,但大多数可以归为选择要保留在转换后的数据集中的样本、选择要删除的样本以及结合了这两种方法类型的混合方法。
在本教程中,您将了解不平衡分类的欠采样方法。
完成本教程后,您将了解:
- 如何使用 Near-Miss 和 Condensed Nearest Neighbor Rule 方法从多数类中选择要保留的样本。
- 如何使用 Tomek Links 和 Edited Nearest Neighbors Rule 方法从多数类中选择要删除的样本。
- 如何使用 One-Sided Selection 和 Neighborhood Cleaning Rule,这些方法结合了选择要从多数类保留和删除的样本的方法。
立即开始您的项目,阅读我的新书 《Python 不平衡分类》,其中包含分步教程以及所有示例的Python源代码文件。
让我们开始吧。
- 2021 年 1 月更新:更新了 API 文档链接。

如何使用欠采样算法进行不平衡分类
照片由 nuogein 提供,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 不平衡分类的欠采样
- Imbalanced-Learn 库
- 选择样本保留的方法
- Near Miss 欠采样
- Condensed Nearest Neighbor Rule 欠采样
- 选择样本删除的方法
- Tomek Links 欠采样
- Edited Nearest Neighbors Rule 欠采样
- 保留和删除方法组合
- One-Sided Selection 欠采样
- Neighborhood Cleaning Rule 欠采样
不平衡分类的欠采样
欠采样是指一组旨在平衡具有倾斜类别分布的分类数据集的类别分布的技术。
不平衡的类别分布将具有少数几个样本的类别(少数类)和一个或多个具有许多样本的类别(多数类)。在二元(两类)分类问题中,其中类别 0 是多数类,类别 1 是少数类,这是最容易理解的。
欠采样技术通过从训练数据集中删除属于多数类的样本来更好地平衡类别分布,例如将倾斜度从 1:100 降低到 1:10、1:2,甚至 1:1 的类别分布。这与过采样不同,过采样涉及向少数类添加样本以试图降低类别分布的倾斜度。
…欠采样,即通过消除多数类样本来减少数据,以实现各类样本数量的均衡……
— 第 82 页,《不平衡数据学习》,2018 年。
欠采样方法可以直接应用于训练数据集,然后该数据集可用于拟合机器学习模型。通常,欠采样方法与少数类的过采样技术结合使用,并且这种组合通常比在训练数据集上单独使用过采样或欠采样能获得更好的性能。
最简单的欠采样技术包括从多数类中随机选择样本并将其从训练数据集中删除。这被称为随机欠采样。虽然简单有效,但该技术的一个局限性在于,样本的删除不考虑它们在确定类别之间的决策边界方面可能有多么有用或重要。这意味着有用信息可能会被删除,或者很可能被删除。
随机欠采样的一个主要缺点是,该方法可能会丢弃可能对归纳过程很重要的潜在有用数据。数据的删除是一个关键的决定,因此许多欠采样方法都采用启发式方法来克服非启发式决策的局限性。
— 第 83 页,《不平衡数据学习》,2018 年。
这种方法的一个扩展是更谨慎地选择要删除的多数类样本。这通常涉及启发式方法或学习模型,这些模型试图识别要删除的冗余样本或不删除的有用样本。
有许多使用这些启发式方法的欠采样技术。在接下来的部分中,我们将回顾一些更常用的方法,并对它们在合成不平衡二元分类数据集上的操作形成直观认识。
我们可以使用 scikit-learn 库中的 make_classification() 函数定义一个合成二元分类数据集。例如,我们可以创建 10,000 个具有两个输入变量和 1:100 分布的样本,如下所示:
|
1 2 3 4 |
... # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) |
然后,我们可以使用 scikit-learn 库中的 scatter() Matplotlib 函数创建数据集的散点图,以了解每个类别中样本的空间关系及其不平衡情况。
|
1 2 3 4 5 6 7 |
... # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
总而言之,创建不平衡分类数据集并绘制样本的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 生成并绘制一个合成的不平衡分类数据集 from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行该示例首先会总结类别分布,显示大约 1:100 的类别分布,其中大约有 10,000 个样本为类别 0,100 个样本为类别 1。
|
1 |
Counter({0: 9900, 1: 100}) |
接下来,会创建一个散点图显示数据集中的所有样本。我们可以看到类别 0(蓝色)的大量样本和类别 1(橙色)的少量样本。我们还可以看到两个类别存在重叠,一些类别 1 的样本明显位于属于类别 0 的特征空间部分。
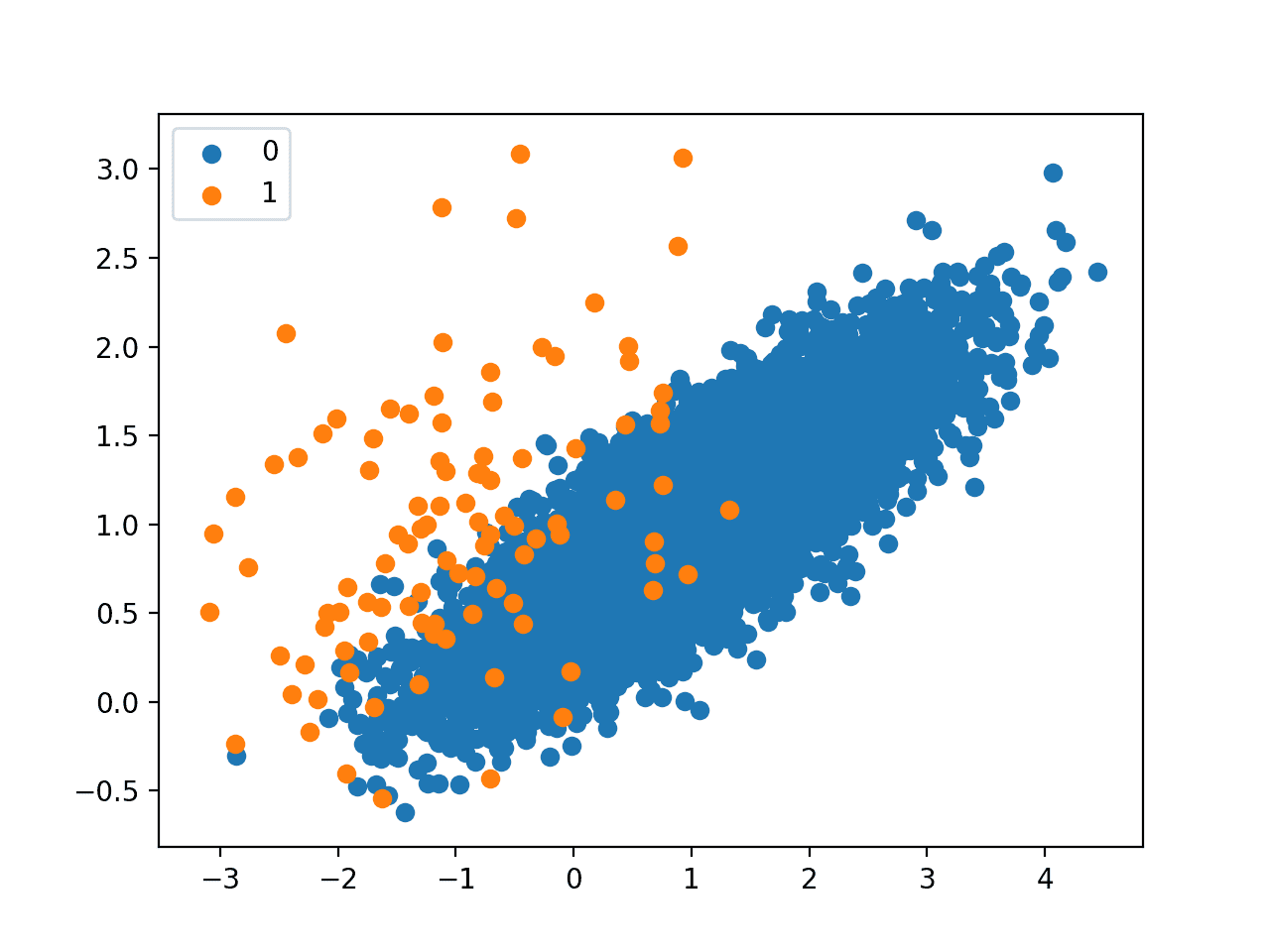
不平衡分类数据集的散点图
此图为理解不同欠采样技术对多数类影响的直观认识提供了起点。
接下来,我们可以开始回顾通过 imbalanced-learn Python 库提供的流行欠采样方法。
有许多不同的方法可供选择。我们将它们分为选择多数类样本保留哪部分的方法、选择样本删除的方法以及这两种方法的组合。
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Imbalanced-Learn 库
在这些示例中,我们将使用 imbalanced-learn Python 库提供的实现,该库可以通过 pip 安装,如下所示:
|
1 |
sudo pip install imbalanced-learn |
您可以通过打印已安装库的版本来确认安装成功。
|
1 2 3 |
# 检查版本号 import imblearn print(imblearn.__version__) |
运行示例将打印已安装库的版本号;例如
|
1 |
0.5.0 |
选择样本保留的方法
在本节中,我们将仔细研究两种从多数类中选择要保留的样本的方法:Near-Miss 系列方法和流行的 Condensed Nearest Neighbor Rule。
Near Miss 欠采样
Near Miss 是指一系列欠采样方法,它们根据多数类样本到少数类样本的距离来选择样本。
这些方法是由 Jianping Zhang 和 Inderjeet Mani 在其 2003 年的论文《KNN 方法在不平衡数据分布中的应用:信息提取案例研究》中提出的。
该技术有三个版本,分别命名为 NearMiss-1、NearMiss-2 和 NearMiss-3。
NearMiss-1 选择与少数类中最近的三个样本平均距离最小的多数类样本。NearMiss-2 选择与少数类中最远的三个样本平均距离最小的多数类样本。NearMiss-3 涉及为少数类中的每个样本选择一定数量的最近的多数类样本。
此处,距离在特征空间中使用欧几里得距离或类似距离确定。
- NearMiss-1:与三个最近的少数类样本的平均距离最小的多数类样本。
- NearMiss-2:与三个最远的少数类样本的平均距离最小的多数类样本。
- NearMiss-3:与每个少数类样本距离最近的多数类样本。
NearMiss-3 似乎是可取的,因为它只保留决策边界上的多数类样本。
我们可以使用 imbalanced-learn 类的 NearMiss 类来实现 Near Miss 方法。
使用的 Near-Miss 策略类型由“version”参数定义,该参数默认设置为 1(对于 NearMiss-1),但可以设置为 2 或 3 以用于其他两种方法。
|
1 2 3 |
... # 定义欠采样方法 undersample = NearMiss(version=1) |
默认情况下,该技术将欠采样多数类,使其样本数量与少数类相同,尽管可以通过将 `sampling_strategy` 参数设置为少数类的一个比例来更改。
首先,我们可以演示 NearMiss-1,它仅选择与三个少数类实例距离最近的多数类样本,由 `n_neighbors` 参数定义。
我们期望在重叠的少数类样本周围出现多数类样本的簇。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 使用 NearMiss-1 对不平衡数据集进行欠采样 from collections import Counter from sklearn.datasets import make_classification from imblearn.under_sampling import NearMiss from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 定义欠采样方法 undersample = NearMiss(version=1, n_neighbors=3) # 转换数据集 X, y = undersample.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行该示例将对多数类进行欠采样,并创建转换后数据集的散点图。
正如预期的那样,我们可以看到只有在重叠区域中离少数类样本最近的多数类样本才被保留。
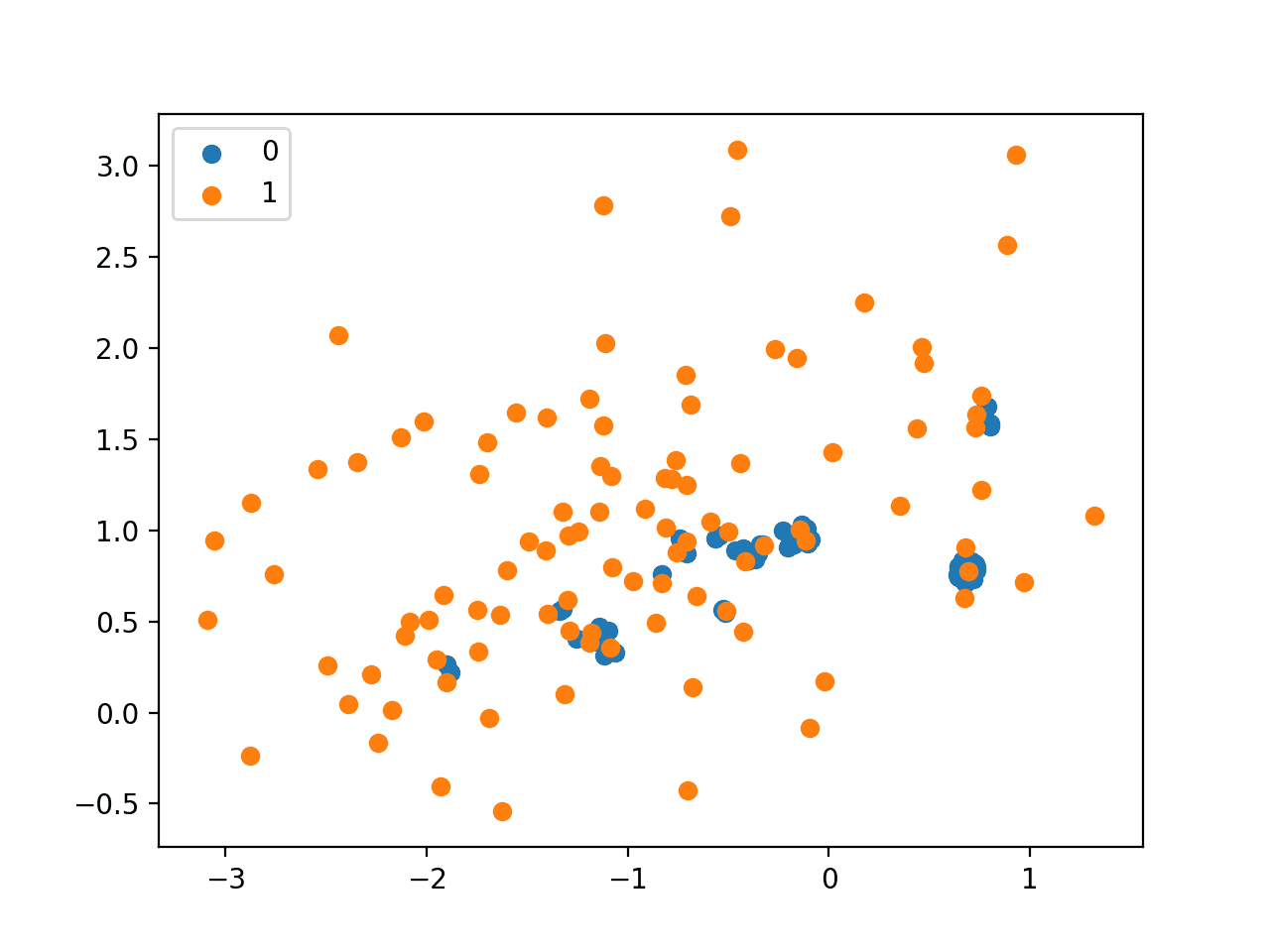
使用 NearMiss-1 欠采样的不平衡数据集的散点图
接下来,我们可以演示 NearMiss-2 策略,该策略与 NearMiss-1 相反。它选择离少数类最远样本最近的样本,由 `n_neighbors` 参数定义。
仅从描述来看,这不是一个直观的策略。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 使用 NearMiss-2 对不平衡数据集进行欠采样 from collections import Counter from sklearn.datasets import make_classification from imblearn.under_sampling import NearMiss from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 定义欠采样方法 undersample = NearMiss(version=2, n_neighbors=3) # 转换数据集 X, y = undersample.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行该示例,我们可以看到 NearMiss-2 选择的样本似乎位于两个类别重叠区域的质心。
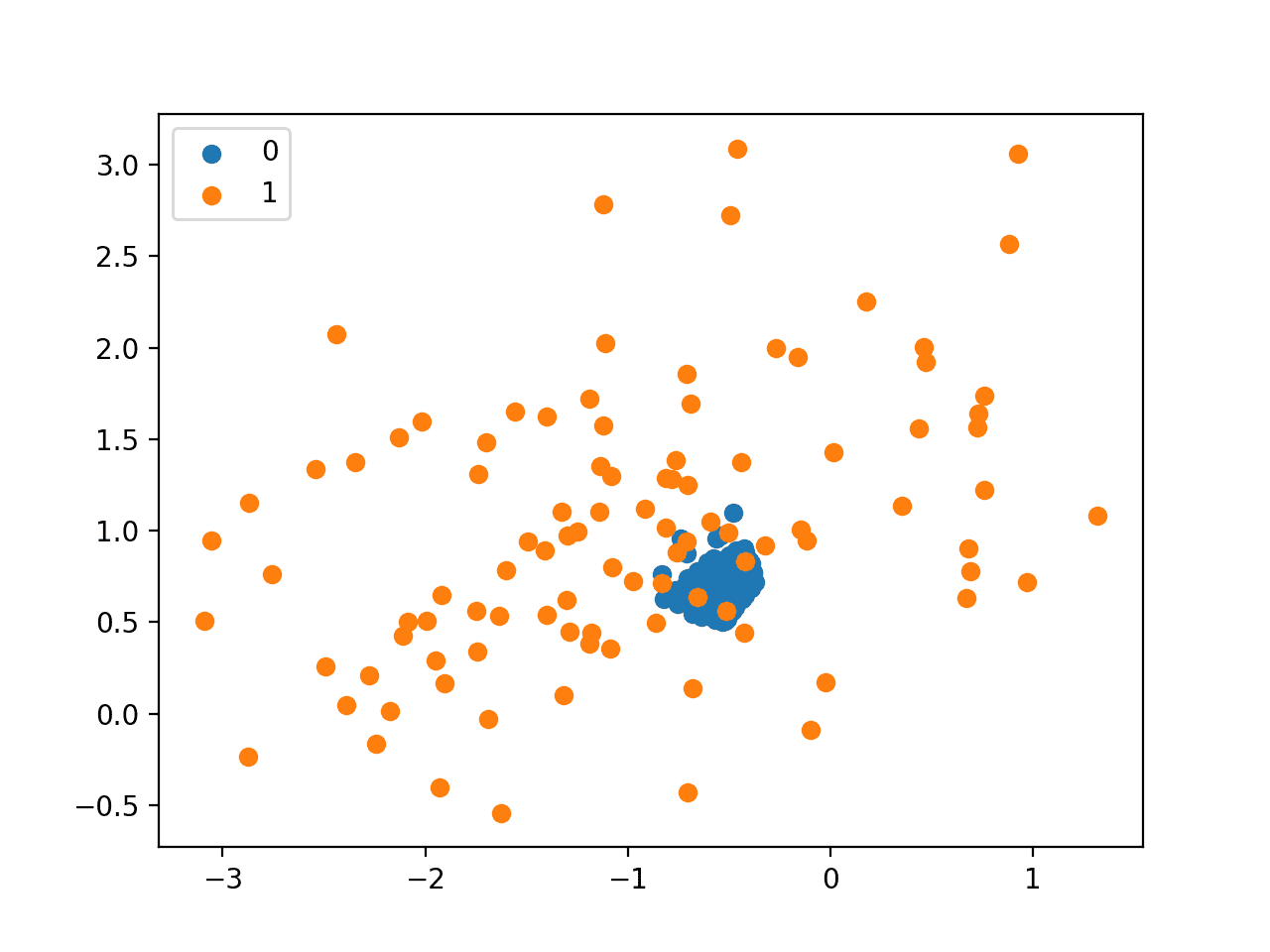
使用 NearMiss-2 欠采样的不平衡数据集的散点图
最后,我们可以尝试 NearMiss-3,它为每个少数类选择最近的多数类样本。
`n_neighbors_ver3` 参数确定为每个少数类样本选择的样本数量,尽管通过 `sampling_strategy` 设置的期望平衡比会对此进行过滤,以实现期望的平衡。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 使用 NearMiss-3 对不平衡数据集进行欠采样 from collections import Counter from sklearn.datasets import make_classification from imblearn.under_sampling import NearMiss from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 定义欠采样方法 undersample = NearMiss(version=3, n_neighbors_ver3=3) # 转换数据集 X, y = undersample.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
正如预期的那样,我们可以看到,重叠区域中的每个少数类样本都有最多三个来自多数类的邻居。
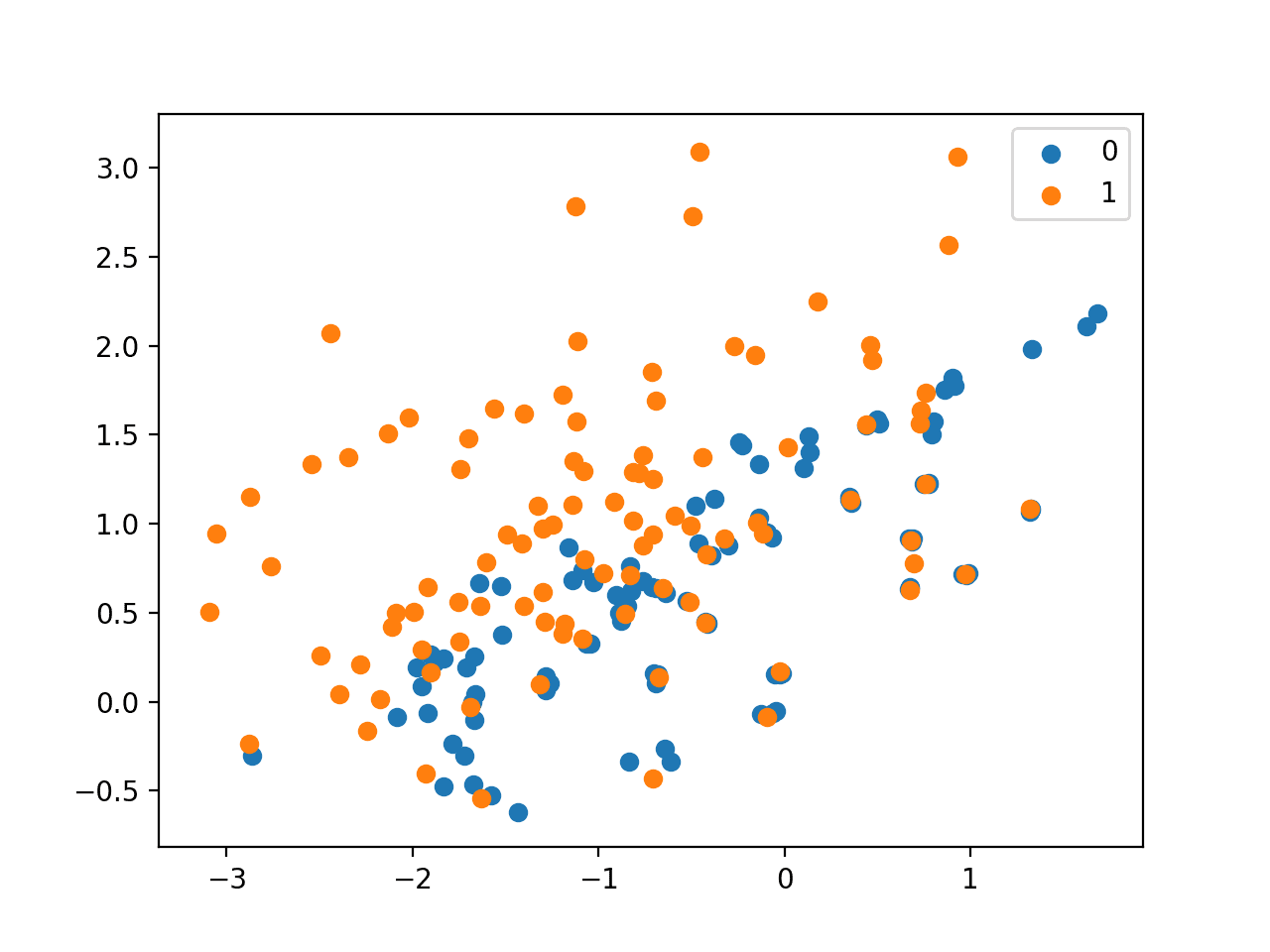
使用 NearMiss-3 欠采样的不平衡数据集的散点图
Condensed Nearest Neighbor Rule 欠采样
Condensed Nearest Neighbors,简称 CNN,是一种欠采样技术,它寻求样本集合的一个子集,该子集在使用 NN 规则时不会损失模型性能,这被称为最小一致集。
…样本集的一致子集概念。这是一个子集,当它被用作 NN 规则的存储参考集时,可以正确地对样本集中的所有剩余点进行分类。
— Condensed Nearest Neighbor Rule (Corresp.),1968 年。
通过枚举数据集中的样本,并将它们添加到“存储”中,仅当它们无法被存储的当前内容正确分类时,才实现这一点。这种方法由 Peter Hart 在 1968 年的论文《The Condensed Nearest Neighbor Rule》中提出,旨在通过 k-Nearest Neighbors (KNN) 算法来减少内存需求。
当用于不平衡分类时,存储由少数类中的所有样本组成,并且仅将不能正确分类的多数类样本增量添加到存储中。
我们可以使用 imbalanced-learn 库中的 CondensedNearestNeighbour 类来实现 Condensed Nearest Neighbor 欠采样。
在过程中,KNN 算法用于对点进行分类,以确定它们是否应添加到存储中。k 值通过 `n_neighbors` 参数设置,默认为 1。
|
1 2 3 |
... # 定义欠采样方法 undersample = CondensedNearestNeighbour(n_neighbors=1) |
这是一个相对缓慢的过程,因此建议使用小型数据集和较小的 k 值。
以下是演示 Condensed Nearest Neighbor Rule 欠采样的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 使用 Condensed Nearest Neighbor Rule 对不平衡数据集进行欠采样和绘图 from collections import Counter from sklearn.datasets import make_classification from imblearn.under_sampling import CondensedNearestNeighbour from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 定义欠采样方法 undersample = CondensedNearestNeighbour(n_neighbors=1) # 转换数据集 X, y = undersample.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行该示例,首先会报告原始数据集的倾斜分布,然后是转换后数据集的更平衡的分布。
我们可以看到,最终的分布大约是 1:2 的少数类与多数类样本比例。这表明尽管 `sampling_strategy` 参数试图平衡类别分布,但算法将继续将错误分类的样本添加到存储(转换后的数据集)中。这是一个可取的属性。
|
1 2 |
Counter({0: 9900, 1: 100}) Counter({0: 188, 1: 100}) |
创建了结果数据集的散点图。我们可以看到,算法的重点是少数类中位于两个类别决策边界上的样本,特别是位于少数类样本周围的多数类样本。
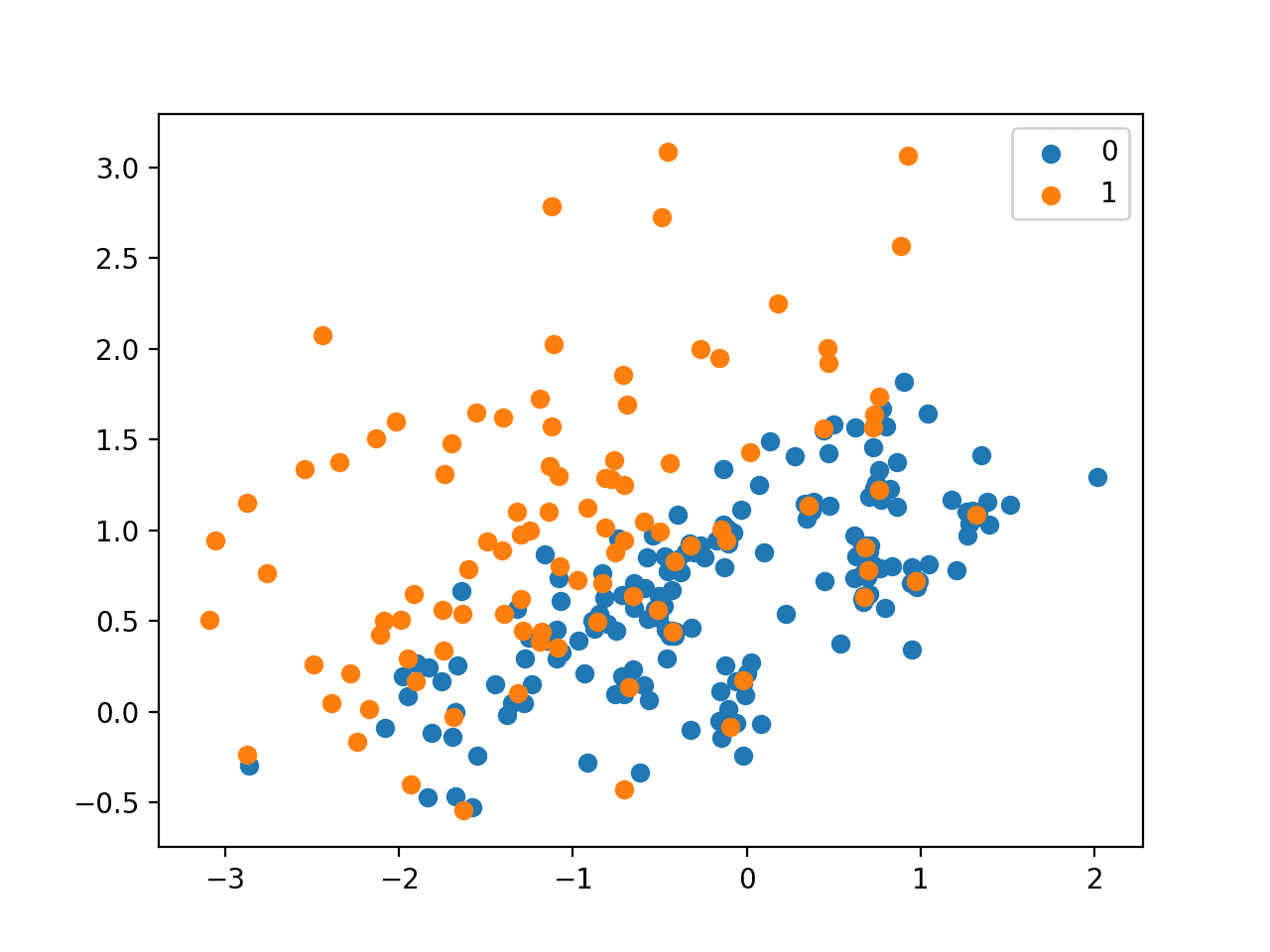
使用 Condensed Nearest Neighbor Rule 欠采样的不平衡数据集的散点图
选择样本删除的方法
在本节中,我们将仔细研究选择多数类样本删除的方法,包括流行的 Tomek Links 方法和 Edited Nearest Neighbors rule。
Tomek Links 欠采样
Condensed Nearest Neighbor Rule 的一个批评是样本是随机选择的,尤其是在开始时。
这会导致将冗余样本保留在存储中,并偶尔将位于分布内部而非类别边界上的样本保留在存储中。
… condensed nearest-neighbor (CNN) 方法随机选择样本。这会导致 a) 保留不必要的样本和 b) 偶尔保留内部样本而非边界样本。
— CNN 的两种修改,1976 年。
Ivan Tomek 在其 1976 年的论文《Two modifications of CNN》中提出了对 CNN 过程的两种修改。其中一种修改(方法 2)是一种规则,它找到成对的样本,每个样本来自一个类别;它们在特征空间中彼此的欧几里得距离最小。
这意味着在具有类别 0 和 1 的二元分类问题中,一对样本将包含一个来自每个类别的样本,并且它们是数据集中最近的邻居。
换句话说,如果实例 a 的最近邻是 b,实例 b 的最近邻是 a,并且实例 a 和 b 属于不同的类别,则实例 a 和 b 定义一个 Tomek Link。
— 第 46 页,《不平衡学习:基础、算法与应用》,2013 年。
这些跨类别对现在通常被称为“Tomek Links”,它们很有价值,因为它们定义了类别边界。
方法 2 具有另一个潜在的重要特性:它找到参与(分段线性)边界形成的边界点对。[…] 因此,这类方法可以利用这些对来逐步生成原始完全指定的边界的近似描述,这些描述越来越简单。
— CNN 的两种修改,1976 年。
用于查找 Tomek Links 的过程可以用来定位所有跨类最近邻。如果少数类中的样本保持不变,则该过程可用于查找最接近少数类的多数类样本,然后将其删除。这些将是模棱两可的样本。
从这个定义中,我们可以看到属于 Tomek Links 的实例要么是边界实例,要么是噪声实例。这是因为只有边界实例和噪声实例才会有来自对立类别的最近邻。
— 第 46 页,《不平衡学习:基础、算法与应用》,2013 年。
我们可以使用 imbalanced-learn 类的 TomekLinks 类来实现 Tomek Links 方法进行欠采样。
|
1 2 3 |
... # 定义欠采样方法 undersample = TomekLinks() |
以下是演示 Tomek Links 欠采样的完整示例。
由于该过程仅删除所谓的“Tomek Links”,因此我们不期望转换后的数据集是平衡的,只希望类别边界处更清晰。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 使用 Tomek Links 对不平衡数据集进行欠采样和绘图 from collections import Counter from sklearn.datasets import make_classification from imblearn.under_sampling import TomekLinks from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 定义欠采样方法 undersample = TomekLinks() # 转换数据集 X, y = undersample.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行该示例,首先会总结原始数据集的类别分布,然后是转换后数据集的类别分布。
我们可以看到只有 26 个多数类样本被删除。
|
1 2 |
Counter({0: 9900, 1: 100}) Counter({0: 9874, 1: 100}) |
转换后数据集的散点图并未明显显示对多数类的微小编辑。
同样,与 Tomek Links 一样,Edited Nearest Neighbor Rule 与其他欠采样方法结合使用时效果最佳。在实践中,Tomek Links 程序经常与其他方法结合使用,例如 Condensed Nearest Neighbor Rule。
选择结合 Tomek Links 和 CNN 是自然的,因为 Tomek Links 可以说消除了边界和噪声实例,而 CNN 消除了冗余实例。
— 第 46 页,《不平衡学习:基础、算法与应用》,2013 年。
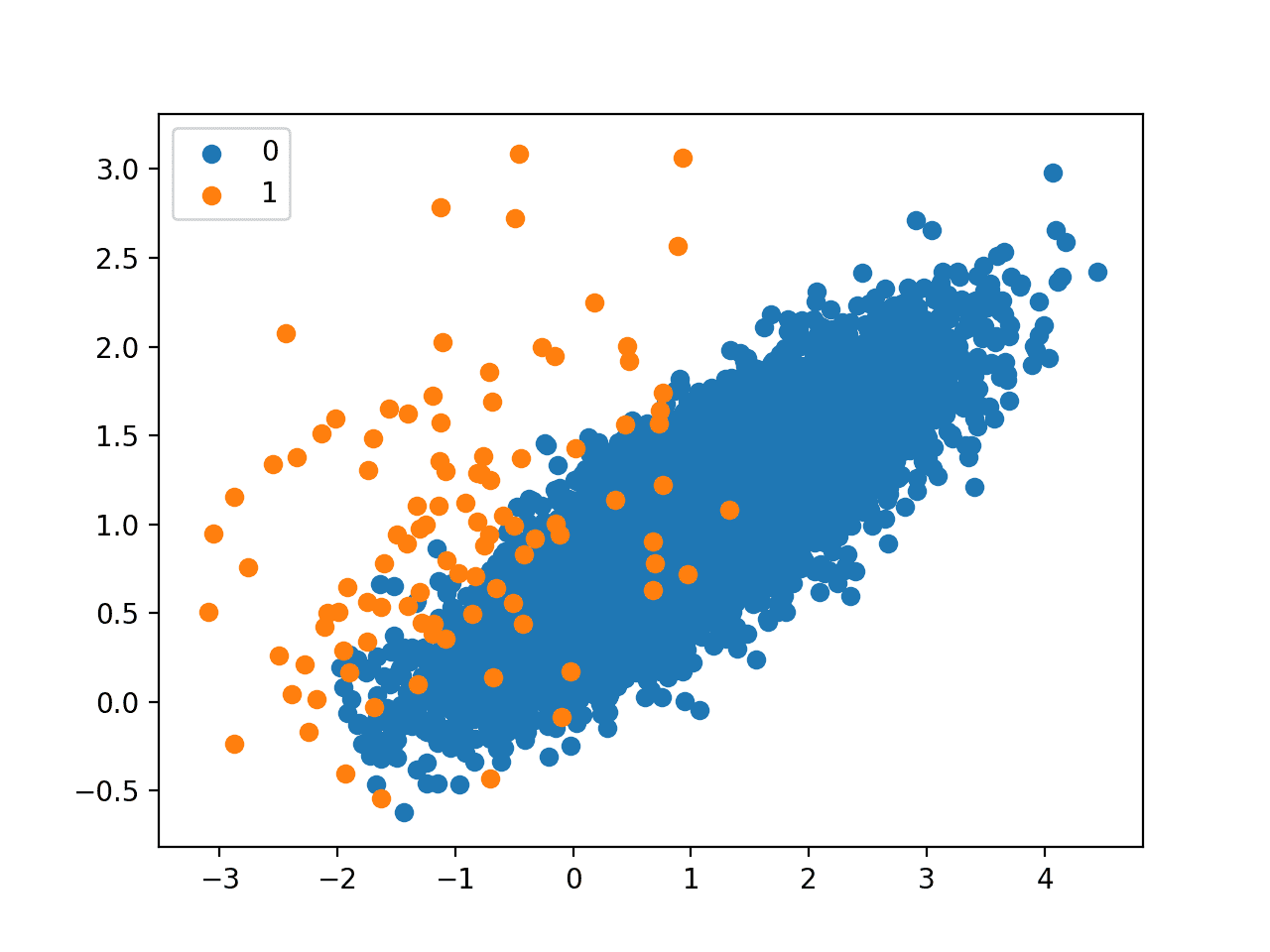
使用 Tomek Links 方法欠采样的不平衡数据集的散点图
Edited Nearest Neighbors Rule 欠采样
另一个用于查找数据集中的模糊和噪声样本的规则称为 Edited Nearest Neighbors,有时也简称为 ENN。
该规则涉及使用 *k=3* 个最近邻来定位数据集中被错误分类的样本,然后将这些样本删除,之后再应用 k=1 的分类规则。这种重采样和分类方法是由 Dennis Wilson 在其 1972 年的论文《Asymptotic Properties of Nearest Neighbor Rules Using Edited Data》中提出的。
使用三个最近邻规则修改预分类样本,然后使用单个最近邻规则进行决策,这是一个特别有吸引力的规则。
— 使用编辑数据时最近邻规则的渐近性质,1972 年。
当用作欠采样过程时,该规则可以应用于多数类中的每个样本,允许删除那些被错误分类为属于少数类的样本,而保留那些被正确分类的样本。
它也应用于少数类中的每个样本,其中那些被错误分类的样本会删除其来自多数类的最近邻。
…对于数据集中的每个实例 a,计算其三个最近邻。如果 a 是一个多数类实例,并且被其三个最近邻错误分类,则从数据集中删除 a。或者,如果 a 是一个少数类实例,并且被其三个最近邻错误分类,则删除 a 的邻居中的多数类实例。
— 第 46 页,《不平衡学习:基础、算法与应用》,2013 年。
可以使用 imbalanced-learn 类的 EditedNearestNeighbours 类来实现 Edited Nearest Neighbors 规则。
`n_neighbors` 参数控制编辑规则中使用的邻居数量,默认值为三,与论文中的情况相同。
|
1 2 3 |
... # 定义欠采样方法 undersample = EditedNearestNeighbours(n_neighbors=3) |
以下是演示 ENN 欠采样规则的完整示例。
与 Tomek Links 一样,该过程仅删除类别边界上的噪声和模糊点。因此,我们不期望转换后的数据集是平衡的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 使用 Edited Nearest Neighbor Rule 对不平衡数据集进行欠采样和绘图 from collections import Counter from sklearn.datasets import make_classification from imblearn.under_sampling import EditedNearestNeighbours from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 定义欠采样方法 undersample = EditedNearestNeighbours(n_neighbors=3) # 转换数据集 X, y = undersample.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行该示例,首先会总结原始数据集的类别分布,然后是转换后数据集的类别分布。
我们可以看到只有 94 个多数类样本被删除。
|
1 2 |
Counter({0: 9900, 1: 100}) Counter({0: 9806, 1: 100}) |
鉴于执行的欠采样量很少,从图中无法明显看出多数类样本的质量变化。
同样,与 Tomek Links 一样,Edited Nearest Neighbor Rule 与另一种欠采样方法结合使用时效果最佳。
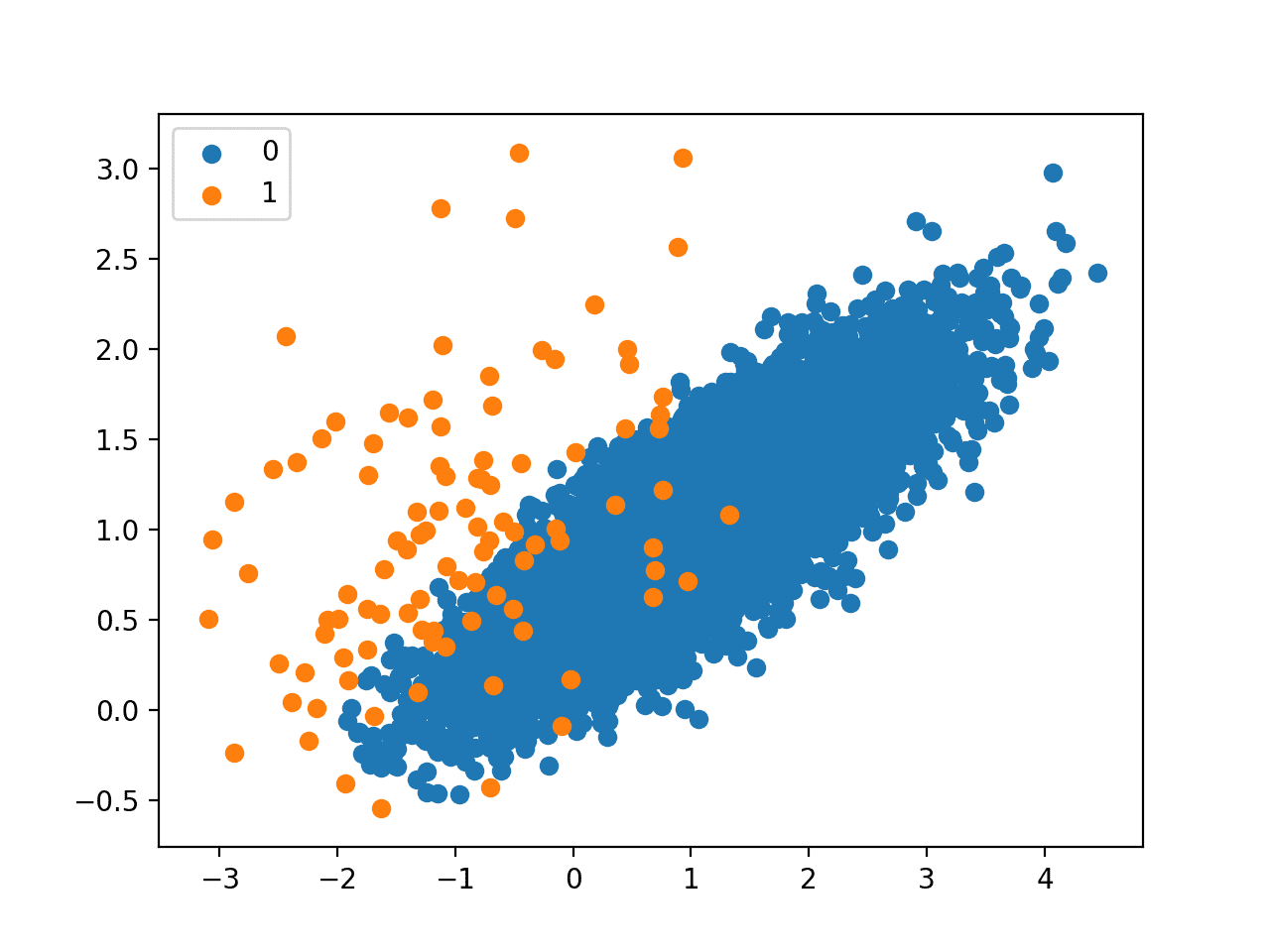
使用 Edited Nearest Neighbor Rule 欠采样的不平衡数据集的散点图
Tomek Links 的开发者 Ivan Tomek 在其 1976 年的论文《An Experiment with the Edited Nearest-Neighbor Rule》中探索了 Edited Nearest Neighbor Rule 的扩展。
在他的实验中,有一个重复的 ENN 方法,它调用 ENN 规则对数据集进行固定次数的迭代编辑,称为“无限编辑”。
…无限重复 Wilson 的编辑(实际上,编辑总是被停止,因为经过一定次数的重复后,设计集对进一步的消除变得免疫)
— 无限编辑最近邻规则的实验,1976 年。
他还描述了一种称为“all k-NN”的方法,该方法会删除被错误分类的所有数据集中的样本。
通过 imbalanced-learn 库也可以获得这两种额外的编辑过程,分别通过 RepeatedEditedNearestNeighbours 和 AllKNN 类。
保留和删除方法组合
在本节中,我们将仔细研究结合了我们已经讨论过的用于从多数类保留和删除样本的技术,例如 One-Sided Selection 和 Neighborhood Cleaning Rule。
One-Sided Selection 欠采样
One-Sided Selection,简称 OSS,是一种结合了 Tomek Links 和 Condensed Nearest Neighbor (CNN) Rule 的欠采样技术。
具体来说,Tomek Links 是类别边界上的模糊点,它们在多数类中被识别并删除。然后使用 CNN 方法从决策边界远处移除多数类中的冗余样本。
OSS 是一种欠采样方法,它通过应用 Tomek links 然后应用 US-CNN 来实现。Tomek links 用作欠采样方法,并删除噪声和边界多数类示例。[…] US-CNN 旨在删除远离决策边界的多数类示例。
— 第 84 页,《不平衡数据学习》,2018 年。
这种方法组合是由 Miroslav Kubat 和 Stan Matwin 在他们 1997 年的论文《解决不平衡训练集诅咒:单方面选择》中提出的。
CNN 过程分一步进行,首先将所有少数类样本添加到存储中,以及一些多数类样本(例如 1),然后使用 KNN(*k=1*)对所有剩余的多数类样本进行分类,并将那些被错误分类的样本添加到存储中。

One-Sided Selection 欠采样过程概述
摘自《解决不平衡训练集诅咒:单方面选择》。
我们可以通过 imbalanced-learn 库中的 OneSidedSelection 类来实现 OSS 欠采样策略。
种子样本的数量可以用 `n_seeds_S` 设置,默认为 1,KNN 的 k 值可以通过 `n_neighbors` 参数设置,默认为 1。
鉴于 CNN 过程是分块进行的,因此拥有更多的多数类种子样本以有效删除冗余样本更有用。在这种情况下,我们将使用 200。
|
1 2 3 |
... # 定义欠采样方法 undersample = OneSidedSelection(n_neighbors=1, n_seeds_S=200) |
以下是将在二元分类问题上应用 OSS 的完整示例。
我们可能会期望从多数类的内部(例如,远离类别边界)移除大量冗余样本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 对不平衡数据集进行欠采样并使用单面选择进行绘图 from collections import Counter from sklearn.datasets import make_classification from imblearn.under_sampling import OneSidedSelection from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 定义欠采样方法 undersample = OneSidedSelection(n_neighbors=1, n_seeds_S=200) # 转换数据集 X, y = undersample.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先报告原始数据集的类别分布,然后报告转换后的数据集的类别分布。
我们可以看到,大部分多数类别的样本已被移除,其中包括冗余样本(通过 CNN 移除)和模糊样本(通过 Tomek Links 移除)。此数据集的比例现在约为 1:10,而之前是 1:100。
|
1 2 |
Counter({0: 9900, 1: 100}) Counter({0: 940, 1: 100}) |
创建了转换后数据集的散点图,显示大多数剩余的多数类样本都位于类别边界附近,以及与少数类重叠的样本。
探索多数类别的更大种子样本以及单步 CNN 过程中使用的不同 k 值可能会很有趣。
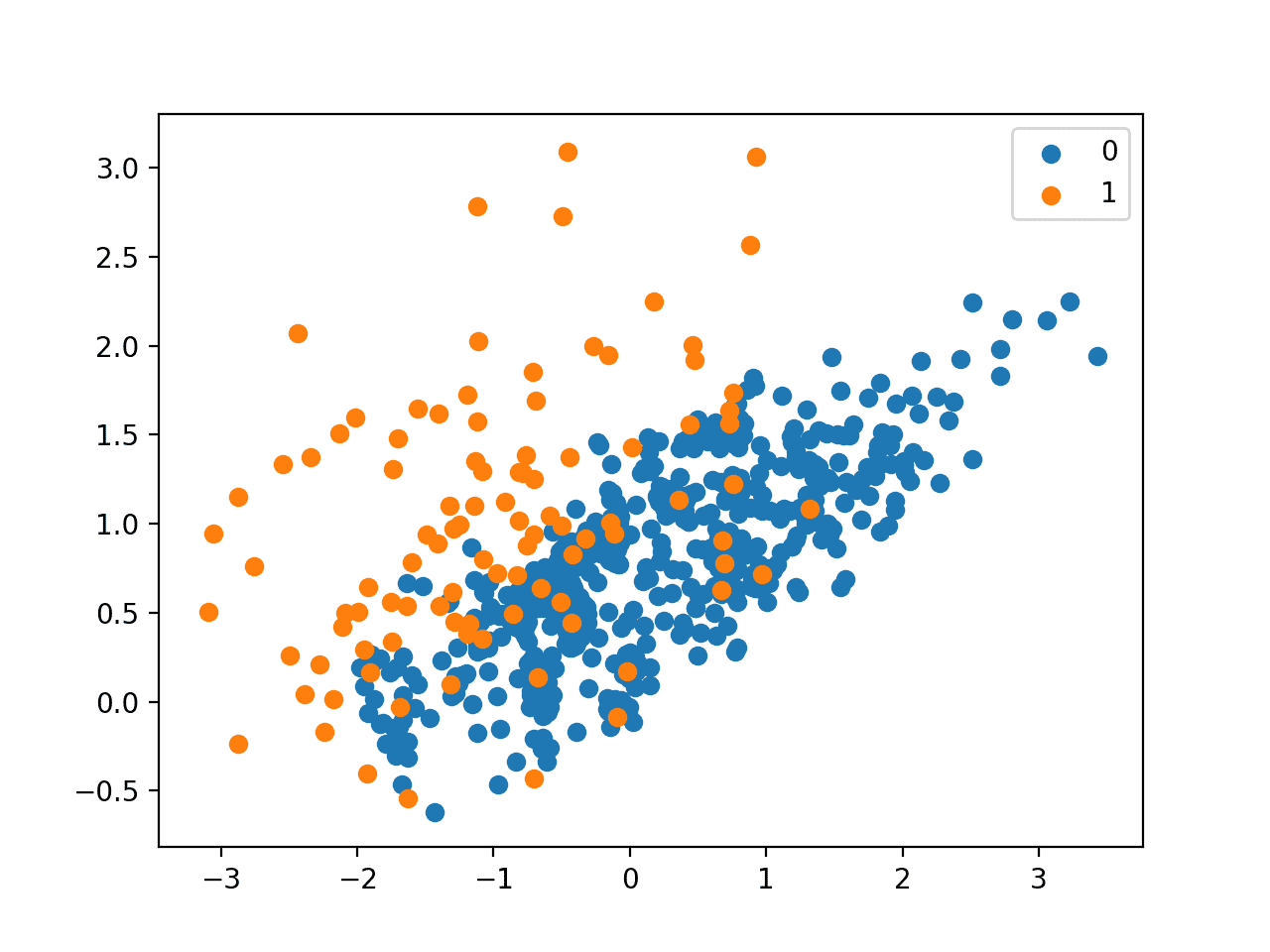
使用单面选择进行欠采样的不平衡数据集的散点图
Neighborhood Cleaning Rule 欠采样
邻域清理规则 (Neighborhood Cleaning Rule),简称 NCR,是一种欠采样技术,它结合了凝聚近邻规则 (Condensed Nearest Neighbor, CNN) 来移除冗余样本,以及编辑近邻规则 (Edited Nearest Neighbors, ENN) 来移除噪声或模糊样本。
与单面选择 (One-Sided Selection, OSS) 类似,CSS 方法以单步方式应用,然后根据 ENN 规则移除根据 KNN 分类器错误分类的样本。与 OSS 不同的是,CSS 移除了较少的冗余样本,而是更侧重于“清理”保留的样本。
这样做的原因是为了减少对改善类别分布平衡的关注,而将更多注意力放在保留的多数类别样本的质量(无歧义性)上。
……分类结果的质量不一定取决于类的大小。因此,除了类别分布之外,我们还应该考虑数据的其他特征,例如可能阻碍分类的噪声。
— Improving Identification of Difficult Small Classes by Balancing Class Distribution, 2001。
这种方法由 Jorma Laurikkala 在其 2001 年的论文“Improving Identification of Difficult Small Classes by Balancing Class Distribution”中提出。
该方法首先选择少数类别中的所有样本。然后,使用 ENN 规则识别并移除多数类别中的所有模糊样本。最后,使用单步 CNN 版本,其中移除根据存储被错误分类的多数类别中的样本,但前提是多数类别中的样本数量大于少数类别大小的一半。

邻域清理规则算法的摘要。
摘自 Improving Identification of Difficult Small Classes by Balancing Class Distribution。
可以使用 NeighbourhoodCleaningRule imbalanced-learn 类来实现此技术。在 ENN 和 CNN 步骤中使用的邻居数量可以通过 n_neighbors 参数指定,默认为三个。threshold_cleaning 控制是否将 CNN 应用于给定类别,这在存在多个大小相似的少数类别时可能很有用。这里设置为 0.5。
下面列出了将 NCR 应用于二分类问题的完整示例。
鉴于其对数据清理而非移除冗余样本的关注,我们预计多数类别样本数量的减少幅度会比较适中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 使用邻域清理规则对不平衡数据集进行欠采样并绘图 from collections import Counter from sklearn.datasets import make_classification from imblearn.under_sampling import NeighbourhoodCleaningRule from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 总结类别分布 counter = Counter(y) print(counter) # 定义欠采样方法 undersample = NeighbourhoodCleaningRule(n_neighbors=3, threshold_cleaning=0.5) # 转换数据集 X, y = undersample.fit_resample(X, y) # 总结新的类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先报告原始数据集的类别分布,然后报告转换后的数据集的类别分布。
我们可以看到,只移除了 114 个多数类别样本。
|
1 2 |
Counter({0: 9900, 1: 100}) Counter({0: 9786, 1: 100}) |
鉴于欠采样的数量有限且有针对性,通过创建的散点图看不出多数类别样本量变化带来的明显变化。
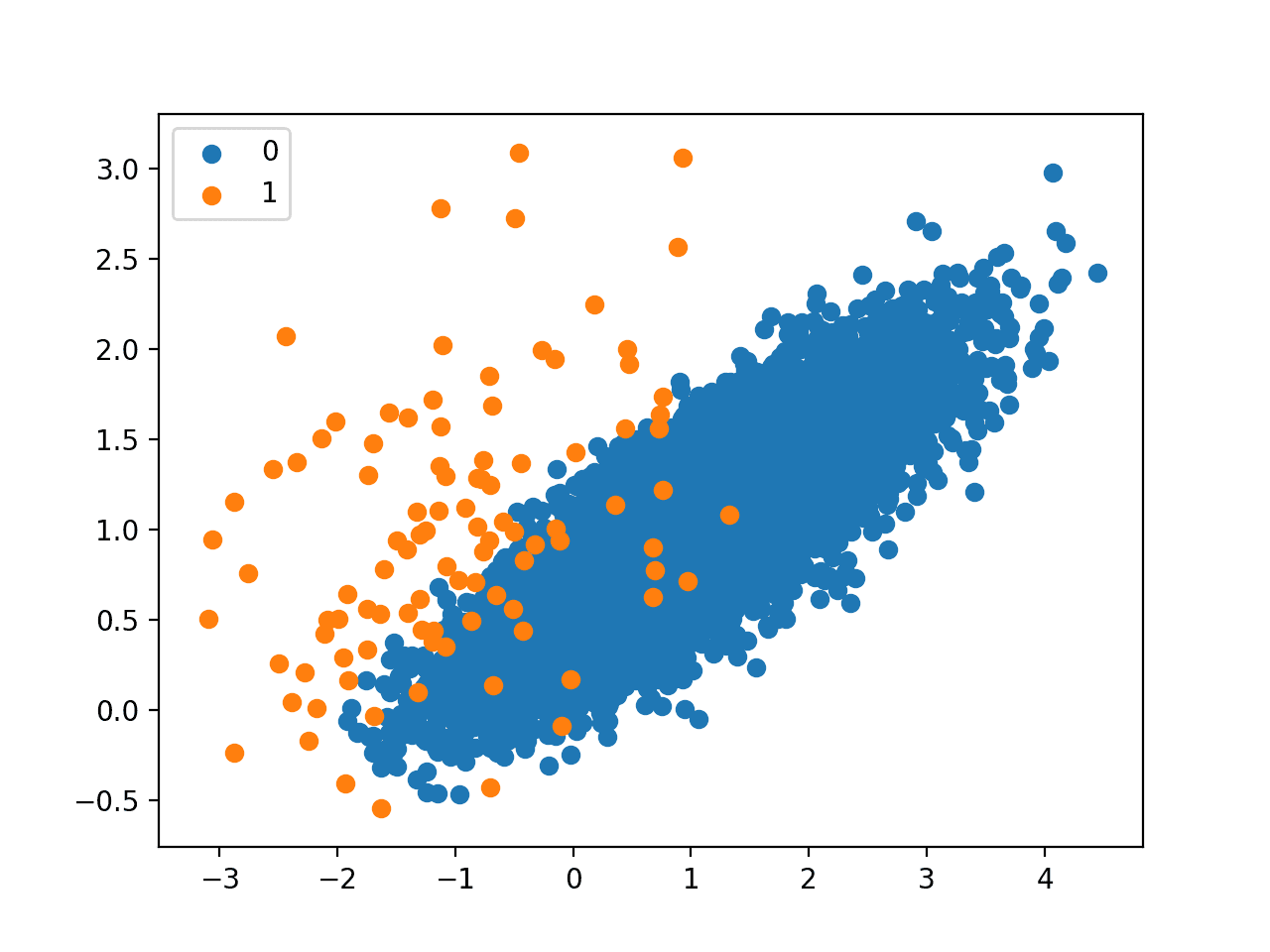
使用邻域清理规则进行欠采样的不平衡数据集的散点图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- KNN 方法处理不平衡数据分布:信息提取案例研究, 2003.
- 凝聚近邻规则(对应), 1968
- CNN 的两个修改, 1976.
- 处理不平衡训练集的诅咒:单面选择, 1997.
- 使用编辑数据的近邻规则的渐近性质, 1972.
- 编辑近邻规则的实验, 1976.
- 通过平衡类别分布改善困难小类别的识别, 2001.
书籍
- 从不平衡数据集中学习 (Learning from Imbalanced Data Sets), 2018.
- 不平衡学习:基础、算法与应用 (Imbalanced Learning: Foundations, Algorithms, and Applications), 2013.
API
- 欠采样,Imbalanced-Learn 用户指南.
- imblearn.under_sampling.NearMiss API
- imblearn.under_sampling.CondensedNearestNeighbour API
- imblearn.under_sampling.TomekLinks API
- imblearn.under_sampling.OneSidedSelection API
- imblearn.under_sampling.EditedNearestNeighbours API.
- imblearn.under_sampling.NeighbourhoodCleaningRule API
文章
总结
在本教程中,您了解了不平衡分类的欠采样方法。
具体来说,你学到了:
- 如何使用 Near-Miss 和 Condensed Nearest Neighbor Rule 方法从多数类中选择要保留的样本。
- 如何使用 Tomek Links 和 Edited Nearest Neighbors Rule 方法从多数类中选择要删除的样本。
- 如何使用 One-Sided Selection 和 Neighborhood Cleaning Rule,这些方法结合了选择要从多数类保留和删除的样本的方法。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...



")


感谢另一篇精彩的文章。
请告诉我……如何在印度购买您的书籍?
您可以从任何国家/地区直接从网站购买书籍。
https://machinelearning.org.cn/products/
你好 Jason,
当我使用 GridSearchCV 时,是否有任何经验法则可以帮助选择哪个超参数
来选择以获得模型更好的性能。
谢谢,
Marco
是的,也许是过去在相关问题上表现良好的超参数范围。
你好 Jason,
我在网上查了一下,我看到 RandomForestClassifier、XGBClassifier 和 GradientBoostingClassifier 最常见的超参数是
n_estimators(问题:它们是树的数量吗?)
max_depth(问题:是每棵树的深度吗?)
(由您决定)还有其他有价值的超参数值得关注吗?
我还看了 catboost。与 XGBClassifier 相比,性能大致相同。
如何提高它们的性能?这是超参数调整的问题吗?
谢谢
Marco
是的,两种情况都如此。
是的,还有更多,请看这里
https://machinelearning.org.cn/hyperparameters-for-classification-machine-learning-algorithms/
非常好的指南!非常感谢可重现的示例。
谢谢!
嗨 Jason,您的网站是一个极好的资源。您能否分享一些关于哪种欠采样方法最有效的直觉?我有一个略微不平衡的数据集,有超过 200 万条记录……
谢谢。
随机采样在计算上是有效的。其他方法,嗯,最好是进行基准测试,而不是试图估计它们的复杂性。
早上好!
在处理不平衡分类问题时,我曾想过一个想法:移除多数类别中的“重复”点(定义为距离小于某个小阈值的邻居)是否有意义?拥有如此几乎相同的实例对预测模型有什么价值吗?您对此类方法有经验吗?
此致!
重复点可能应该在数据清理过程中被移除。
https://machinelearning.org.cn/basic-data-cleaning-for-machine-learning/
如何将距离从欧氏距离更改为像 NearMiss 方法中的 Jaccard 这样的距离?
很好的问题!
我目前认为 imbalanced-learn 库不支持任意距离函数。您可能需要用自定义代码扩展该库。
你好 Jason,
我正在构建一个 LSTM 分类模型。数据具有不平衡的多类别,总共 9 个类别。多数类别有 59287 个实例,最少数类别有 2442 个实例。在这种情况下,为了处理不平衡类别问题,哪种方法是好的,是过采样、欠采样还是成本敏感方法?
也许可以尝试成本敏感学习。
你好 Jason,
感谢您的博客。非常有启发性。
根据您的评论,我阅读了这篇论文 [1],我想了解您是如何以及为何提出这个建议的。
此外,我想知道单面选择 (OSS) 和邻域清理规则 (NCL) 哪个更有效。对于这个问题,我认为这可能取决于数据集。实际的实验可以提供更多关于它们性能的信息。我想知道您的看法。
[1] 10.1109/IJCNN.2010.5596486
非常感谢
不客气。
也许可以在您的数据集上同时尝试两者,然后使用性能最好的那个。
你好,我刚刚发现了一个可能改变理解逻辑的排印错误。在上面解释 NearMiss-1 实现的文档中
“首先,我们可以演示 NearMiss-1,它只选择与三个多数类别实例距离最小的多数类别样本,由 n_neighbors 参数定义。”,不应该是三个少数类别实例而不是三个多数类别实例吗?
谢谢
谢谢,已修正。
你好,您的网站对我理清疑虑非常有帮助。不过,我还有一个疑问。我想使用 SMOTE 进行过采样。假设数据集中存在缺失数据。现在,如果我使用 SimpleImputer() 并将其通过管道传递,SimpleImputer 将尝试用均值替换 NaN 值(默认情况下)。SMOTE 使用 KNN 方法。
如果我在 train_test_split 之前用均值替换 NaN 值并训练模型,那么就会发生信息泄漏。在这种情况下我该怎么做?
谢谢。
是的,在训练集上进行训练和插补,然后应用于训练集和测试集。之后再将 SMOTE 应用于训练集。
如果您在带 CV 的管道中使用此方法,这将是自动完成的。
嗨 Jason,感谢您提供的精彩示例。
我正在努力更改散点图上点的颜色。您有什么建议如何更改它吗?
我尝试了 color 选项,但它会将所有点更改为一种颜色。
最好查看 matplotlib API 和示例。
你好 Jason,感谢您的文章,它非常有帮助。但我有一个问题。
我为我的数据集应用了 Near Miss 3 方法,该数据集有 24 列和 42350 行,其中一些列的数据存在严重的不平衡,而其他列则数据平衡。我的问题是,在我实现了 Near Miss 3 并固定了不平衡数据后,一些列只有 30 个剩余值,而其他列有 8012 个。当我想合并它们时,这会造成巨大的差距,产生大量的 Na 值。我通过 sklearn 的 SimpleImputer 用每列的均值、每列的最频繁值或每列的标准差替换了 Na 值。但这次,用 Na 替换的值会产生更多的不平衡数据。换句话说,当我试图平衡我的数据集时,我创建了另一个更不平衡的数据集。
我决定通过应用不那么敏感的 M.L. 算法,如基于树的算法,或通过 F1 Score 或 ROC AUC Score 来评估我的模型指标来解决这个问题。这是有效的,但我想平衡我的不平衡数据以应用其他算法。顺便说一下,我的问题是一个二分类问题。
有没有办法使用 Near Miss 3 或您在本文中提到的其他方法来平衡我的数据集,而不会产生更多不平衡的数据,或者继续使用基于树的模型或 F1 & ROC AUC Score?
也许您可以调整 Near Miss 的配置,例如进行实验并查看结果?
也许您可以尝试一种替代技术并比较结果?
我们谈论的是哪种配置?
在这种情况下,哪种替代技术可以与之相比,因为所有这些都会删除数据,而我的问题将保持不变。
您能具体一点吗?
也许可以尝试一套欠采样技术(例如本教程中的那些),并找出最适合您特定数据集和所选模型的方法。
Jason,您好,我再次尝试了本教程中的所有欠采样技术,但我的问题仍然存在。您可以在这里找到我的尝试和结果:https://github.com/talfik2/undersampling_problem
我还添加了我的数据集和我的代码,以便您可以更好地检查它。
听到这个消息我很难过。
我没有能力审查您的代码,希望您能理解。
Jason,您好!这篇文章真的很好而且信息丰富。Near-Miss 中最好的方法是什么?是第三个版本吗?
谢谢!
也许可以在您的数据集上评估每个版本并比较结果。
谢谢!
你好,Jason。
感谢这篇文章!非常感谢。
您通常会推荐哪种方法来克服不平衡分类问题?
特别是对于医学领域。
例如,我的数据集有 9,354 行类别 = 0,136 行类别 = 1
我尝试了对数据集进行混洗,分别创建了两个类别的独立数据框,对于类别 = 0 的数据框,我随机选择了 136 行。然后,将两个数据框连接起来。
我对主数据集(没有训练集和测试集之间的分割)执行了上述操作——这样可以吗?
然而,即使进行参数调整,平均结果如下:
准确率 = 0.5474,AUC = 0,召回率 = 0.1511,精确率 = 0.600,F1 = 0.2333
我使用了 pycaret 来完成以上操作,以快速获得结果。
您建议我尝试本文中提到的任何欠采样方法吗?
我还想知道我是否应该改用预训练模型?
请帮忙。非常非常感谢!
是的,尝试过采样/欠采样。我不确定这是否有效,因为每个问题都可能不同。
我担心如何比较处理不平衡数据集的各种方法的結果。
我尝试过随机欠采样/过采样、imblearn 欠采样/过采样以及许多其他方法,包括这里描述的一些技术。
我的问题是:我应该使用来自原始数据集的测试样本,还是来自修改后的平衡数据集的测试样本?几乎所有方法在用平衡数据集测试时都能取得好结果,但在原始测试样本上测试时,几乎没有方法能取得好的召回率或精确率指标,并且除了在原始数据集上测试模型之外,测试模型没有多大意义。
谢谢你