通过观察神经网络和深度学习模型在训练过程中的性能,你可以学到很多东西。例如,如果你看到训练准确率随着训练轮数而变差,你就知道优化方面有问题。可能是学习率过高。在这篇文章中,你将发现如何在训练过程中回顾和可视化 PyTorch 模型随时间变化的性能。完成这篇文章后,你将了解:
- 在训练过程中收集哪些指标
- 如何绘制训练和验证数据集的指标图
- 如何解读图表来了解模型和训练进度
通过我的《用PyTorch进行深度学习》一书来启动你的项目。它提供了包含可用代码的自学教程。
让我们开始吧。

通过可视化指标了解训练期间的模型行为
图片作者: Alison Pang。部分权利保留。
概述
本章分为两部分:
- 从训练循环中收集指标
- 绘制训练历史
从训练循环中收集指标
在深度学习中,使用梯度下降算法训练模型意味着进行一次前向传播,使用模型和损失函数从输入中推断出损失指标,然后进行一次反向传播,从损失指标计算梯度,最后进行一次更新过程,将梯度应用于更新模型参数。虽然这些是你必须采取的基本步骤,但你可以在过程中做更多的事情来收集额外的信息。
正确训练的模型应该期望损失指标下降,因为损失是需要优化的目标。要使用的损失指标应取决于问题。
对于回归问题,模型预测值越接近实际值越好。因此,你想跟踪均方误差(MSE)、或有时是均方根误差(RMSE)、平均绝对误差(MAE)或平均绝对百分比误差(MAPE)。虽然不作为损失指标使用,但你可能也对模型产生的最大误差感兴趣。
对于分类问题,通常损失指标是交叉熵。但交叉熵的值不太直观。因此,你可能还想跟踪预测的准确率、真阳性率、精确率、召回率、F1 分数等。
从训练循环中收集这些指标非常简单。让我们从一个使用 PyTorch 和加州住房数据集的深度学习基本回归示例开始。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler # 读取数据 data = fetch_california_housing() X, y = data.data, data.target # 用于模型评估的训练-测试拆分 X_train_raw, X_test_raw, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=True) # 标准化数据 scaler = StandardScaler() scaler.fit(X_train_raw) X_train = scaler.transform(X_train_raw) X_test = scaler.transform(X_test_raw) # 转换为 2D PyTorch 张量 X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32).reshape(-1, 1) # 定义模型 model = nn.Sequential( nn.Linear(8, 24), nn.ReLU(), nn.Linear(24, 12), nn.ReLU(), nn.Linear(12, 6), nn.ReLU(), nn.Linear(6, 1) ) # 损失函数和优化器 loss_fn = nn.MSELoss() # 均方误差 optimizer = optim.Adam(model.parameters(), lr=0.001) n_epochs = 100 # 运行的轮数 batch_size = 32 # 每个批次的大小 batch_start = torch.arange(0, len(X_train), batch_size) for epoch in range(n_epochs): for start in batch_start: # 获取一个批次 X_batch = X_train[start:start+batch_size] y_batch = y_train[start:start+batch_size] # 前向传播 y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) # 反向传播 optimizer.zero_grad() loss.backward() # 更新权重 optimizer.step() |
这个实现很基础,但在过程中,你会在每一步都得到一个 `loss` 张量,它为优化器提供了改进模型的线索。要了解训练的进度,当然,你可以在每一步打印出这个损失指标。但你也可以保存这个值,以便稍后可视化。这样做时,请注意,你不希望保存一个张量,而只是它的值。这是因为这里的 PyTorch 张量会记住它是如何与它的值关联的,以便可以进行自动微分。这些额外的数据会占用内存,但你不需要它们。
因此,你可以将训练循环修改为以下形式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
mse_history = [] for epoch in range(n_epochs): for start in batch_start: # 获取一个批次 X_batch = X_train[start:start+batch_size] y_batch = y_train[start:start+batch_size] # 前向传播 y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) mse_history.append(float(loss)) # 反向传播 optimizer.zero_grad() loss.backward() # 更新权重 optimizer.step() |
在训练模型时,你应该用一个与训练集分开的测试集来评估它。通常,这会在每个 epoch 中进行一次,在完成该 epoch 中的所有训练步骤之后。测试结果也可以保存供以后可视化。事实上,如果你愿意,可以从测试集中获得多个指标。因此,你可以按如下方式添加到训练循环中:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
mae_fn = nn.L1Loss() # 创建一个计算 MAE 的函数 train_mse_history = [] test_mse_history = [] test_mae_history = [] for epoch in range(n_epochs): model.train() for start in batch_start: # 获取一个批次 X_batch = X_train[start:start+batch_size] y_batch = y_train[start:start+batch_size] # 前向传播 y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) train_mse_history.append(float(loss)) # 反向传播 optimizer.zero_grad() loss.backward() # 更新权重 optimizer.step() # 在测试集上验证模型 model.eval() with torch.no_grad(): y_pred = model(X_test) mse = loss_fn(y_pred, y_test) mae = mae_fn(y_pred, y_test) test_mse_history.append(float(mse)) test_mae_history.append(float(mae)) |
你可以定义自己的函数来计算指标,或者使用 PyTorch 库中已实现的函数。在评估时切换模型到评估模式是一个好习惯。同样,在 `no_grad()` 上下文中运行评估也是一个好习惯,这样你就可以明确地告诉 PyTorch 你无意对张量进行自动微分。
然而,上面的代码存在一个问题:训练集的 MSE 是在每个训练步骤中基于一个批次计算的,而测试集的指标是每个 epoch 计算一次,并且基于整个测试集。它们不能直接比较。事实上,如果你查看训练步骤的 MSE,你会发现它 **非常不稳定**。更好的方法是将同一个 epoch 的 MSE 汇总成一个数字(例如,它们的平均值),这样你就可以与测试集的数据进行比较。
进行此更改后,完整的代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler # 读取数据 data = fetch_california_housing() X, y = data.data, data.target # 用于模型评估的训练-测试拆分 X_train_raw, X_test_raw, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=True) # 标准化数据 scaler = StandardScaler() scaler.fit(X_train_raw) X_train = scaler.transform(X_train_raw) X_test = scaler.transform(X_test_raw) # 转换为 2D PyTorch 张量 X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32).reshape(-1, 1) # 定义模型 model = nn.Sequential( nn.Linear(8, 24), nn.ReLU(), nn.Linear(24, 12), nn.ReLU(), nn.Linear(12, 6), nn.ReLU(), nn.Linear(6, 1) ) # 损失函数、指标和优化器 loss_fn = nn.MSELoss() # 均方误差 mae_fn = nn.L1Loss() # 平均绝对误差 optimizer = optim.Adam(model.parameters(), lr=0.001) n_epochs = 100 # 运行的轮数 batch_size = 32 # 每个批次的大小 batch_start = torch.arange(0, len(X_train), batch_size) train_mse_history = [] test_mse_history = [] test_mae_history = [] for epoch in range(n_epochs): model.train() epoch_mse = [] for start in batch_start: # 获取一个批次 X_batch = X_train[start:start+batch_size] y_batch = y_train[start:start+batch_size] # 前向传播 y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) epoch_mse.append(float(loss)) # 反向传播 optimizer.zero_grad() loss.backward() # 更新权重 optimizer.step() mean_mse = sum(epoch_mse) / len(epoch_mse) train_mse_history.append(mean_mse) # 在测试集上验证模型 model.eval() with torch.no_grad(): y_pred = model(X_test) mse = loss_fn(y_pred, y_test) mae = mae_fn(y_pred, y_test) test_mse_history.append(float(mse)) test_mae_history.append(float(mae)) |
想开始使用PyTorch进行深度学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
绘制训练历史
在上面的代码中,你将指标收集到一个 Python 列表中,每个 epoch 一个。因此,使用 matplotlib 将它们绘制成折线图非常简单。下面是一个例子:
|
1 2 3 4 5 6 7 8 9 |
import matplotlib.pyplot as plt import numpy as np plt.plot(np.sqrt(train_mse_history), label="训练 RMSE") plt.plot(np.sqrt(test_mse_history), label="测试 RMSE") plt.plot(test_mae_history, label="测试 MAE") plt.xlabel("epochs") plt.legend() plt.show() |
例如,它绘制了如下内容: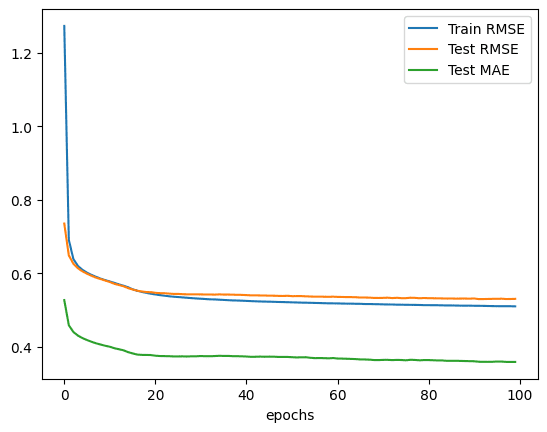
像这样的图表可以提供关于模型训练的有用信息,例如:
- 收敛速度(斜率)
- 模型是否可能已经收敛(线条的平稳段)
- 模型是否可能过度拟合了训练数据(验证线的拐点)
在上面的回归示例中,MAE 和 MSE 指标都应该随着模型的改进而下降。然而,在分类示例中,准确率指标应该随着更多的训练而增加,而交叉熵损失应该下降。这就是你期望从图中看到的结果。
这些曲线最终应该趋于平缓,这意味着你无法基于当前数据集、模型设计和算法进一步改进模型。你希望这种情况尽快发生,这样你的模型就能 **更快地收敛**,从而使你的训练更有效率。你也希望指标在较高的准确率或较低的损失区域趋于平缓,这样你的模型在预测方面就更有效。
在图中要注意的另一个属性是训练和验证指标之间的差异。在上图中,你看到训练集的 RMSE 在开始时高于测试集的 RMSE,但很快,曲线交叉,最终测试集的 RMSE 更高。这是符合预期的,因为最终模型会更好地拟合训练集,但测试集可以预测模型在未来未见过的数据上的表现。
你需要小心地解释微观尺度的曲线或指标。在上图中,你看到在 epoch 0 时,训练集的 RMSE 与测试集相比非常大。它们之间的差异可能没有那么显著,但由于你是通过在第一个 epoch 的每个步骤计算 MSE 来收集训练集 RMSE 的,你的模型在前几个步骤中可能表现不佳,但在该 epoch 的最后几个步骤中表现更好。跨所有步骤取平均值可能不是一个公平的比较,因为测试集的 MSE 是基于最后一个步骤之后模型的。
如果看到训练集的指标远好于测试集,则你的模型 **过拟合** 了。这可能意味着你应该在较早的 epoch 停止训练,或者你的模型设计需要一些正则化,例如 dropout 层。
在上图中,虽然你为回归问题收集了均方误差(MSE),但你绘制的是均方根误差(RMSE),这样你就可以与平均绝对误差(MAE)进行比较。你可能也应该收集训练集的 MAE。两条 MAE 曲线应该与 RMSE 曲线表现相似。
把所有东西放在一起,下面是完整的代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
import matplotlib.pyplot as plt import numpy as np import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler # 读取数据 data = fetch_california_housing() X, y = data.data, data.target # 用于模型评估的训练-测试拆分 X_train_raw, X_test_raw, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=True) # 标准化数据 scaler = StandardScaler() scaler.fit(X_train_raw) X_train = scaler.transform(X_train_raw) X_test = scaler.transform(X_test_raw) # 转换为 2D PyTorch 张量 X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32).reshape(-1, 1) # 定义模型 model = nn.Sequential( nn.Linear(8, 24), nn.ReLU(), nn.Linear(24, 12), nn.ReLU(), nn.Linear(12, 6), nn.ReLU(), nn.Linear(6, 1) ) # 损失函数、指标和优化器 loss_fn = nn.MSELoss() # 均方误差 mae_fn = nn.L1Loss() # 平均绝对误差 optimizer = optim.Adam(model.parameters(), lr=0.001) n_epochs = 100 # 运行的轮数 batch_size = 32 # 每个批次的大小 batch_start = torch.arange(0, len(X_train), batch_size) train_mse_history = [] test_mse_history = [] test_mae_history = [] for epoch in range(n_epochs): model.train() epoch_mse = [] for start in batch_start: # 获取一个批次 X_batch = X_train[start:start+batch_size] y_batch = y_train[start:start+batch_size] # 前向传播 y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) epoch_mse.append(float(loss)) # 反向传播 optimizer.zero_grad() loss.backward() # 更新权重 optimizer.step() mean_mse = sum(epoch_mse) / len(epoch_mse) train_mse_history.append(mean_mse) # 在测试集上验证模型 model.eval() with torch.no_grad(): y_pred = model(X_test) mse = loss_fn(y_pred, y_test) mae = mae_fn(y_pred, y_test) test_mse_history.append(float(mse)) test_mae_history.append(float(mae)) plt.plot(np.sqrt(train_mse_history), label="训练 RMSE") plt.plot(np.sqrt(test_mse_history), label="测试 RMSE") plt.plot(test_mae_history, label="测试 MAE") plt.xlabel("epochs") plt.legend() plt.show() |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
总结
在本章中,你发现了在训练深度学习模型时收集和审查指标的重要性。你学到了:
- 在模型训练期间应该关注哪些指标
- 如何在 PyTorch 训练循环中计算和收集指标
- 如何可视化训练循环中的指标
- 如何解读指标以推断训练过程的细节
开始使用PyTorch进行深度学习!

学习如何构建深度学习模型
...使用新发布的PyTorch 2.0库
在我的新电子书中探索如何实现
使用 PyTorch进行深度学习
它提供了包含数百个可用代码的自学教程,让你从新手变成专家。它将使你掌握:
张量操作、训练、评估、超参数优化等等...






暂无评论。