
理解 RAG III:融合检索和重排序
图片由 Editor | Midjourney & Canva 提供
请查看本系列的上一篇文章
在介绍了什么是 RAG、它在大型语言模型 (LLM) 中的重要性以及经典的 RAG 检索器-生成器系统是什么样的之后,本系列“理解 RAG”的第三篇文章将探讨构建 RAG 系统的一种升级方法:融合检索。
在深入探讨之前,我们有必要简要回顾一下在本系列第二部分中探索过的基本 RAG 方案。
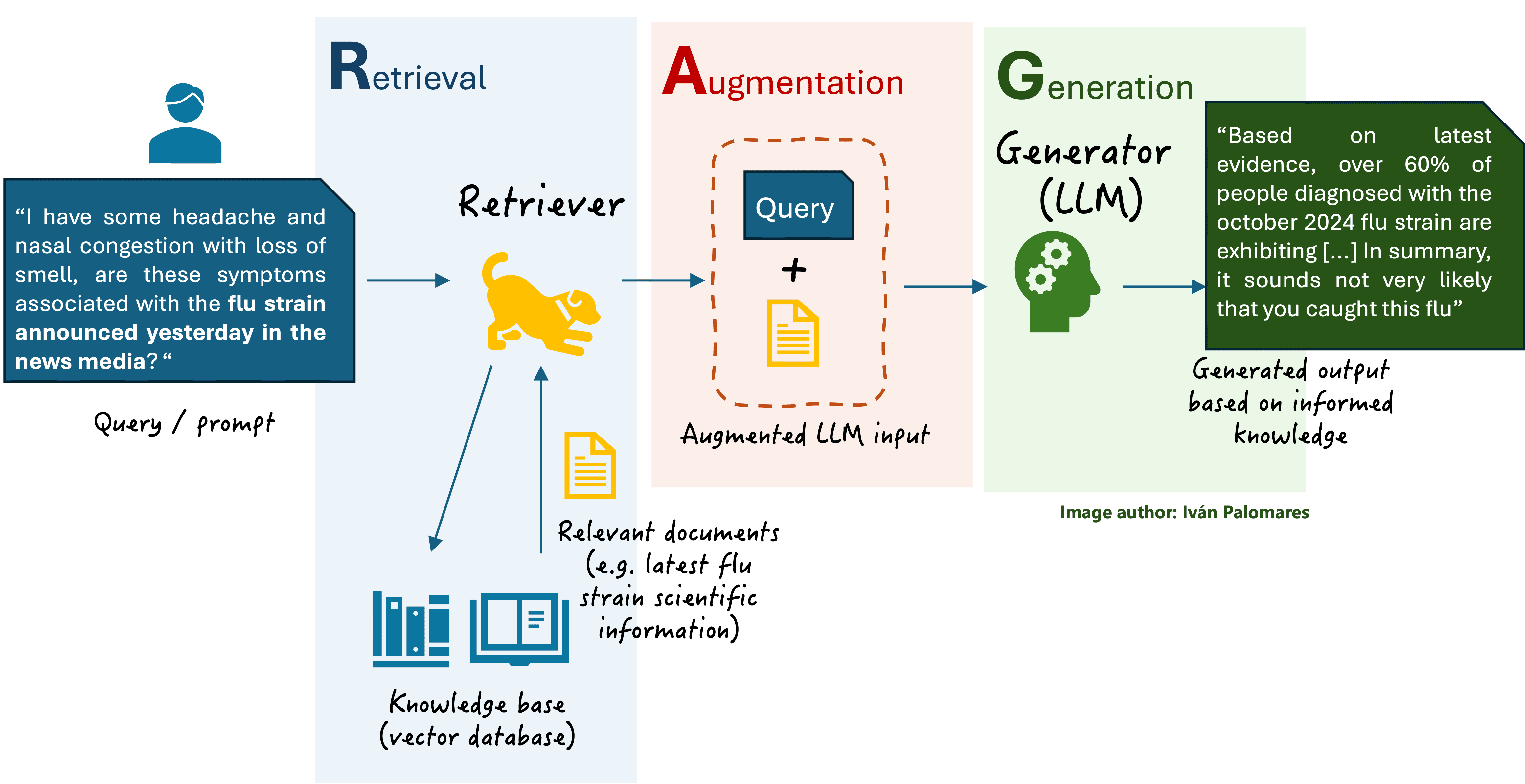
基本 RAG 方案
融合检索详解
融合检索方法涉及在 RAG 系统的检索阶段融合或聚合多个信息流。回想一下,在检索阶段,检索器——一个信息检索引擎——会获取 LLM 的原始用户查询,将其编码为向量数值表示,并使用它在一个庞大的知识库中搜索与查询高度匹配的文档。之后,通过添加从检索到的文档中获得的其他上下文信息来增强原始查询,最后将增强的输入发送给 LLM 生成响应。
通过在检索阶段应用融合方案,添加到原始查询上的上下文可以变得更加连贯和与上下文相关,从而进一步改善 LLM 生成的最终响应。融合检索利用了多个检索到的文档(搜索结果)的知识,并将其整合为更有意义和更准确的上下文。然而,我们已经熟悉的经典 RAG 方案也可以从知识库中检索多个文档,不一定只有一个。那么,这两种方法有什么区别呢?
经典 RAG 与融合检索的关键区别在于检索到的多个文档如何被处理和整合到最终响应中。在经典 RAG 中,检索到的文档中的内容被简单地连接起来,或者最多进行抽取式摘要,然后作为附加上下文输入到 LLM 以生成响应。没有应用高级的融合技术。与此同时,在融合检索中,使用更专门的机制来组合多个文档中的相关信息。这种融合过程可以在增强阶段(检索阶段)发生,甚至可以在生成阶段发生。
- 增强阶段的融合包括在将多个文档传递给生成器之前应用重排序、过滤或组合这些文档的技术。其中两个例子是重排序,即根据相关性对文档进行评分和排序,然后与用户提示一起输入到模型中;以及聚合,即将每个文档中最相关的信息片段合并为单个上下文。聚合通过经典的 TF-IDF(词频-逆文档频率)等信息检索方法、嵌入操作等来实现。
- 生成阶段的融合涉及 LLM(生成器)独立处理每个检索到的文档——包括用户提示——并在生成最终响应期间融合多个处理作业的信息。总的来说,RAG 中的增强阶段就成了生成阶段的一部分。此类别中的一个常见方法是 Fusion-in-Decoder (FiD),它允许 LLM 单独处理每个检索到的文档,然后在生成最终响应时结合它们的见解。FiD 方法在本文档中有详细描述。
重排序是将多个检索来源的信息有意义地结合起来的最简单但最有效的方法之一。下一节将简要解释它是如何工作的。
重排序的工作原理
在重排序过程中,检索器最初获取的文档集会根据用户查询的相关性重新排序,从而更好地满足用户需求并提高整体输出质量。检索器会将获取的文档传递给一个称为排序器的算法组件,该组件会根据学习到的用户偏好等标准重新评估检索到的结果,并应用文档排序,以最大化呈现给该特定用户的结果的相关性。例如,使用加权平均或其他形式的评分来组合和优先排序排名靠前的文档,从而使排名靠前文档的内容比排名靠后文档的内容更有可能成为最终合并上下文的一部分。
下图说明了重排序机制。
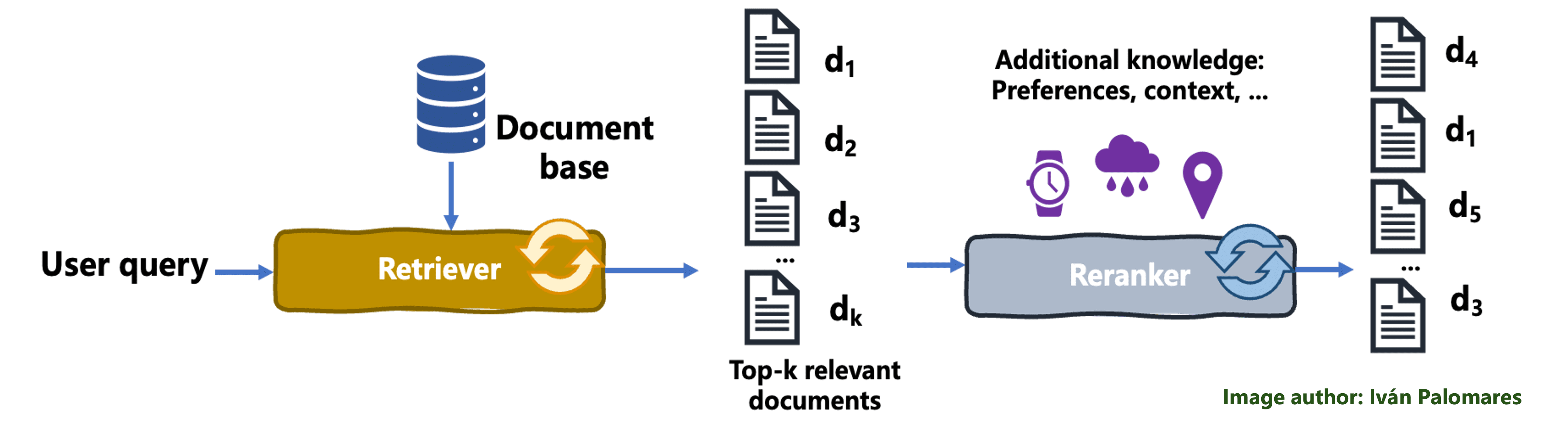
重排序过程
让我们举一个例子来更好地理解重排序,以亚洲东部旅游为例。假设一位旅行者向 RAG 系统查询“亚洲适合自然爱好者的热门目的地”。一个初步的检索系统可能会返回一份文档列表,包括一般的旅游指南、关于亚洲热门城市的文章以及国家公园的推荐。然而,一个重排序模型,可能使用额外的旅行者特定偏好和上下文数据(如喜欢的活动、以前喜欢的活动或以前去过的地方),可以重新排序这些文档,以优先考虑与该用户最相关的内容。它可能会重点介绍宁静的国家公园、鲜为人知的徒步小径和环保之旅,这些可能不是每个人都想得到的建议,从而为像我们目标用户这样的自然爱好者提供“直达要点”的结果。
总之,重排序会根据额外的用户相关性标准重新组织多个检索到的文档,以将内容提取过程集中在排名靠前的文档上,从而提高后续生成响应的相关性。






暂无评论。