
理解 RAG 第四部分:RAGAs 与其他评估框架
图片由 Editor | Midjourney & Canva 提供
请务必查看本系列的上一篇文章
检索增强生成 (RAG) 在扩展和克服独立大型语言模型 (LLMs) 的许多局限性方面发挥了关键作用。通过集成检索器,RAG 提高了响应的相关性和事实准确性:只需实时利用向量文档库等外部知识源,并在将用户原始查询或提示传递给 LLM 进行输出生成过程之前,为其添加相关的上下文信息。
对于深入研究 RAG 领域的人来说,一个自然的问题随之而来:我们该如何评估这些并非简单的系统?
为此存在几种框架,例如 DeepEval,它提供了 14 种以上的评估指标来评估幻觉和忠实度等标准;MLflow LLM Evaluate,以其模块化和简洁性而闻名,可在自定义管道中进行评估;以及 RAGAs,它专注于定义 RAG 管道,提供忠实度和上下文相关性等指标来计算综合的 RAGAs 质量分数。
以下是这三个框架的摘要
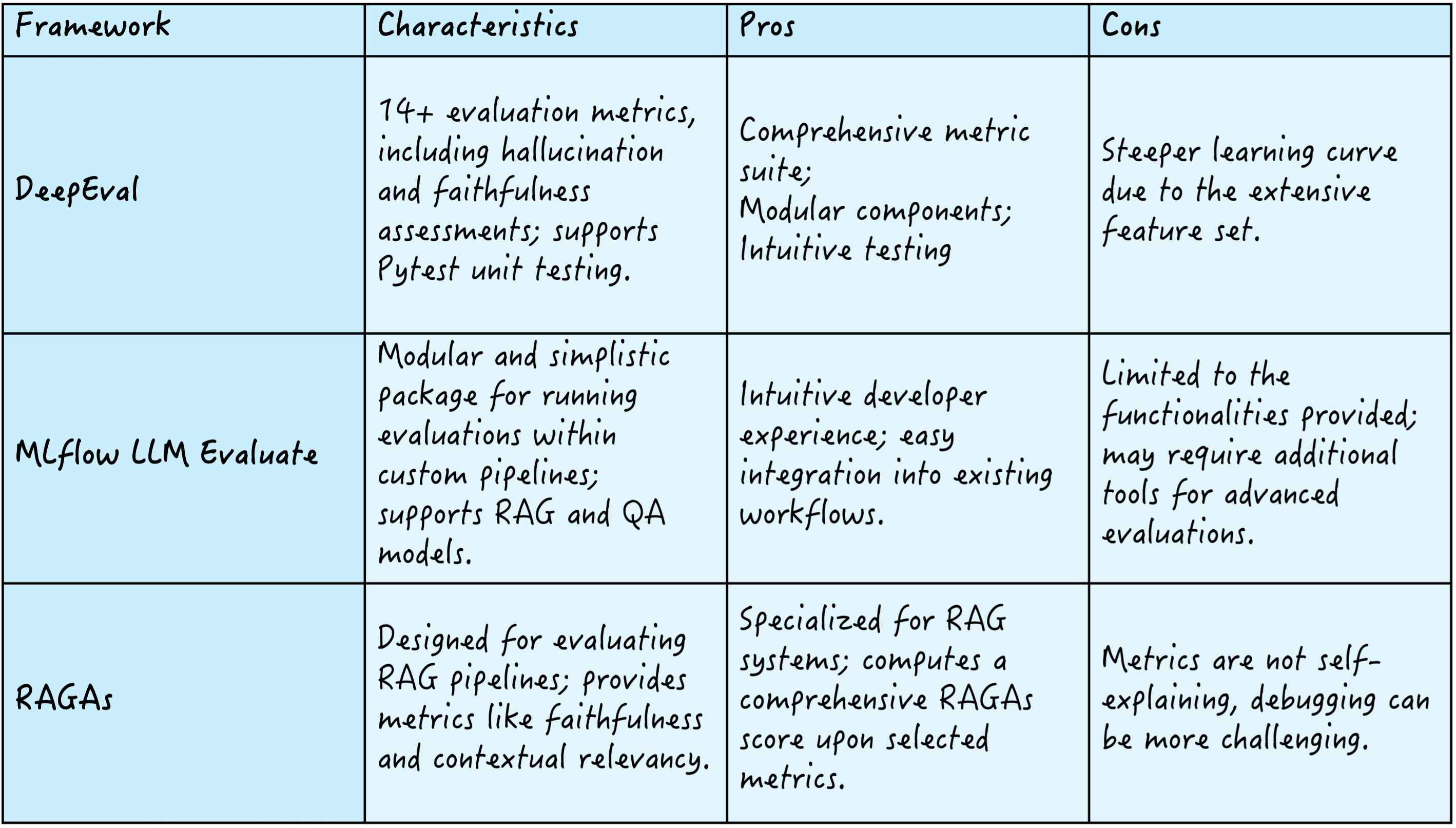
RAG 评估框架
让我们进一步审视后者:RAGAs。
理解 RAGAs
RAGAs(检索增强生成评估的缩写)被认为是评估 LLM 应用程序的最佳工具包之一。它成功地评估了 RAG 系统的组件——即最简单方法中的检索器和生成器——无论是单独评估还是作为单个管道联合评估。
RAGAs 的核心要素是其指标驱动开发 (MDD) 方法,该方法依赖数据来做出明智的系统决策。MDD 包含随着时间推移持续监控关键指标,从而清晰地了解应用程序的性能。除了允许开发人员评估其 LLM/RAG 应用程序并进行指标辅助实验外,MDD 方法还与应用程序的可重现性高度契合。
RAGAs 组件
- Prompt object(提示对象):一个组件,用于定义用于引发语言模型生成响应的提示的结构和内容。通过遵循一致且清晰的提示,可以促进准确的评估。
- Evaluation Sample(评估样本):一个单独的数据实例,它封装了用户查询、生成的响应以及参考响应或真实数据(类似于 ROUGE、BLEU 和 METEOR 等 LLM 指标)。它作为评估 RAG 系统性能的基本单位。
- Evaluation dataset(评估数据集):一组评估样本,用于根据各种指标更系统地评估 RAG 系统的整体性能。它旨在全面评估系统的有效性和可靠性。
RAGAs 指标
RAGAs 提供了通过定义检索器和生成器的特定指标来配置 RAG 系统指标的能力,并将它们融合到一个整体的 RAGAs 分数中,如下图所示。

RAGAs 分数 | 图片来源:RAGAs 文档
让我们来了解一下检索和生成方面的一些最常见的指标。
检索性能指标
- Contextual recall(上下文召回率):召回率衡量从知识库中检索到的相关文档在真实数据 top-k 结果中的比例,即,已检索到多少与回答提示最相关的文档?它通过将检索到的相关文档数量除以相关文档总数来计算。
- Contextual precision(上下文精确率):在检索到的文档中,有多少与提示相关,而不是噪声?这就是上下文精确率所回答的问题,它通过将检索到的相关文档数量除以检索到的文档总数来计算。
生成性能指标
- Faithfulness(忠实度):它评估生成的响应是否与检索到的证据一致,换句话说,就是响应的事实准确性。这通常通过比较响应和检索到的文档来完成。
- Contextual Relevancy(上下文相关性):此指标确定生成的响应与查询的相关程度。它通常基于人类判断或通过自动语义相似度评分(例如余弦相似度)来计算。
作为一个连接 RAG 系统检索和生成两方面的示例指标,我们有
- Context utilization(上下文利用率):它评估 RAG 系统在生成响应时有效利用检索到的上下文的程度。即使检索器检索到了优秀的上下文(高精确率和召回率),生成器性能不佳也可能导致未能有效利用它,因此提出了上下文利用率来捕捉这种细微差别。
在 RAGAs 框架中,单个指标被组合起来计算一个整体 RAGAs 分数,该分数全面量化了 RAG 系统的性能。计算该分数的流程包括选择相关指标并计算它们,将它们标准化到相同的范围(通常是 0-1),然后计算这些指标的加权平均值。权重的分配取决于每个用例的优先级,例如,对于需要强大事实准确性的系统,您可能希望优先考虑忠实度而不是召回率。
有关 RAGAs 指标及其通过 Python 示例计算的更多信息,请访问此处。
总结
本文介绍了 RAGAs,并对其进行了基本了解:RAGAs 是一个流行的评估框架,用于系统地衡量 RAG 系统在信息检索和文本生成方面的多方面性能。理解这个框架的关键要素是掌握其实际应用以利用高性能 RAG 应用程序的第一步。






暂无评论。