
理解 RAG 第十部分:生产环境中的 RAG 管道
图片由 Editor | Midjourney & Canvas 提供
请务必查看本系列的上一篇文章
- 理解 RAG 第一部分:为什么需要它
- 理解RAG第二部分:经典RAG如何工作
- 理解 RAG 第三部分:融合检索与重排序
- 理解 RAG 第四部分:RAGAs 与其他评估框架
- 理解 RAG 第 V 部分:管理上下文长度
- 理解 RAG 第六部分:有效的检索优化
- 理解 RAG 第七部分:向量数据库与索引策略
- 理解 RAG 第八部分:减轻 RAG 中的幻觉
- 理解 RAG 第九部分:微调 LLMs 以用于 RAG
管道在部署软件方面起着核心作用,因为它们有助于在生产环境中自动化和协调多项任务,从而保证数据和流程的顺畅流动。在检索增强生成(RAG)应用程序等高级系统的背景下,生产中的管道的意义更加重大。它们对于在管理复杂工作流程的同时,保持合理的效率、可扩展性、组件之间的一致性和可靠性至关重要。
本篇“理解 RAG”系列文章将重点讨论生产环境中 RAG 管道的关键特性,区分三种类型的管道:索引管道、检索管道和生成管道。每种管道在整个 RAG 体系结构中都扮演着自己的角色,理解它们如何交互对于优化性能并确保系统产生及时、相关且事实正确的結果至关重要。
在下面对这三个 RAG 管道的描述中,我们将探索前面图示中显示的元素。
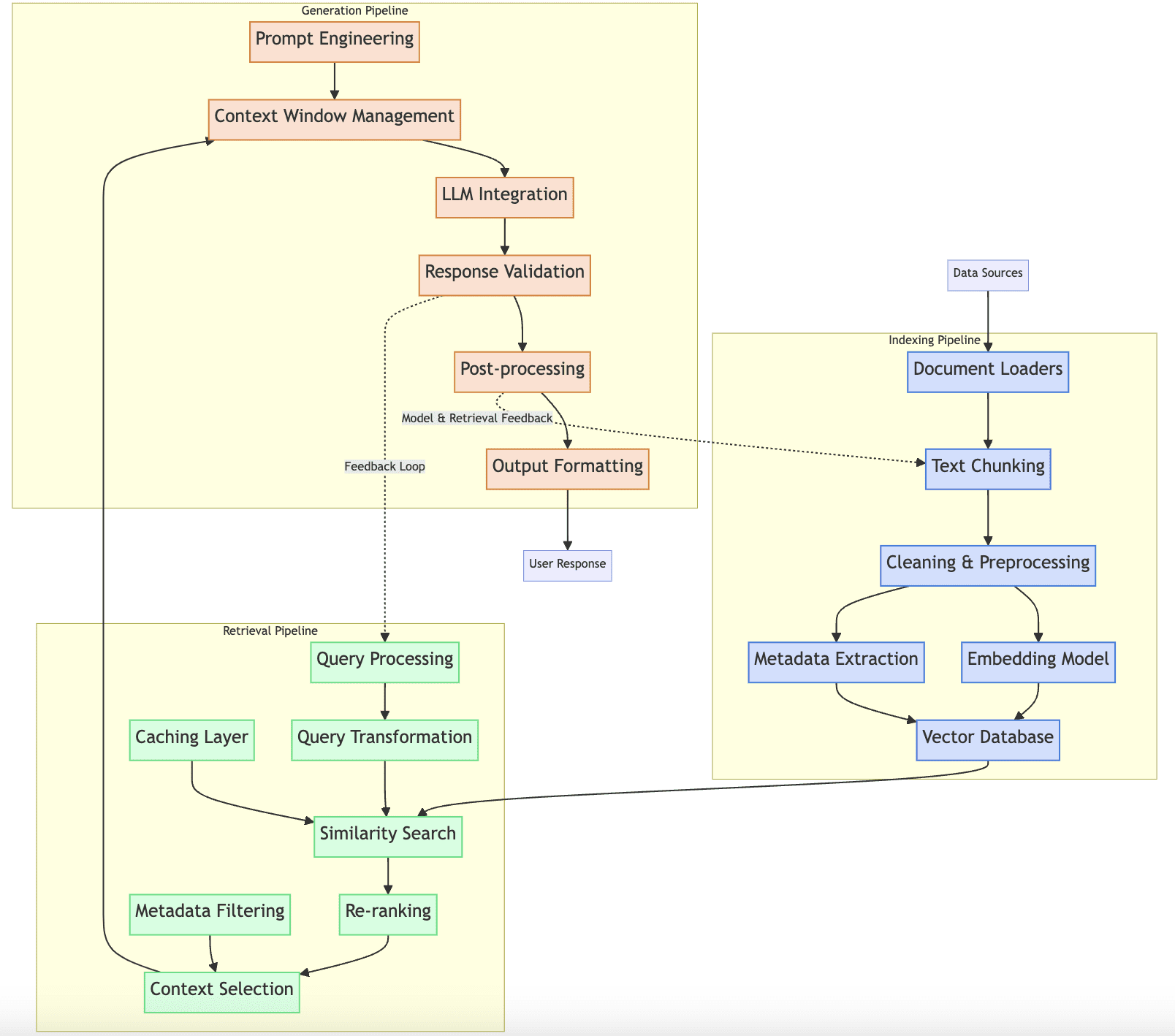
RAG 生产管道
索引管道
RAG 系统中索引管道的目的是收集、处理和存储文档到向量数据库中,以便高效检索。简单来说,索引管道负责 RAG 系统的文档数据库。
为此,它依赖于以下组件:
- 文档加载器,用于从 PDF、网页等不同格式的多种来源收集和加载文档。
- 文本分块策略,以确保长文档能够以可管理的部分集成到向量数据库中。这些策略包括重叠设置,以保持来自同一文档的块之间的语义关系。
- 数据预处理工作流程,应用清理、过滤和删除重复文档相关数据等步骤。
- 嵌入模型,将文本转换为数值向量表示或嵌入。
- 向量数据库,文档将在此存储以供将来检索。
- 文档元数据提取方法。
这些组件在前面图示的“索引管道”块中按顺序表示。索引管道如何与 RAG 系统中的其他管道交互?正如您可能猜到的,该管道在应用一些基于相似性的搜索后,会将处理和存储的文档提供给检索管道。管道中发生的流程必须以与检索策略一致且连贯的方式进行设计:例如,分块方法和设置通常会影响检索质量。索引管道的良好维护策略必须支持增量更新,以便随时提供最新数据。
检索管道
检索管道负责在每次用户提交查询时,从向量数据库中查找并提取最相关的上下文。它直接与 RAG 管道的其他两个管道——索引管道和生成管道——进行通信,其组件包括:
- 查询理解和预处理:在处理查询之前,可以使用一个更简单的、专注于语言理解任务的语言模型,如意图识别或命名实体识别 (NER),以便在预处理原始查询之前更好地理解它。
- 查询转换机制,如查询扩展、分解等。
- 相似性搜索算法是 RAG 系统检索器和此管道的关键部分。通过与向量数据库交互,并与索引管道进行协调,使用余弦距离或欧几里得距离等相似性度量来查找与处理后的查询最相关的存储文档。这里可以使用缓存层来高效管理频繁的查询。
- 如果我们实现重排序策略,重排序机制也成为此管道的一部分。
- 基于元数据的上下文过滤或选择,以从检索到的文档中选择最相关的信息。
通过整合混合搜索功能,例如语义搜索和基于关键字的搜索,可以进一步增强此管道。
在交互方面,检索管道从索引管道消费数据,并将构建的相关上下文发送到控制 RAG 系统语言模型的生成管道。它还可以向索引管道提供反馈以优化其操作。
生成管道
该管道的目标是利用语言模型和检索管道构建的检索上下文来创建连贯、准确的响应。其关键组件或阶段包括:
- 提示工程和模板化,用于将上下文作为语言模型的输入进行准备。
- 上下文窗口管理对于处理长上下文的情况是必要的,以确保相关信息包含在语言模型的限制内,如输入令牌长度。
- LLM 选择和配置对于实际的 RAG 应用至关重要,这些应用通常有多个针对特定任务(如摘要、翻译或情感分析)进行微调的模型。
- 响应验证程序,用于验证和后处理原始生成输出。
- 响应格式化和结构化,以便呈现给最终用户。
生成管道从检索管道接收相关上下文,并作为向用户提供响应的最后阶段。它可以包含基于与其他组件交互的反馈循环,以促进持续改进。
总结
本篇 RAG 系列文章讨论了 RAG 系统在部署到生产环境后通常集成的三个主要管道类型。为了获得最佳的 RAG 应用程序性能并确保成功,重要的是要独立监控、版本化和增强每个管道,同时确保它们协同工作。






暂无评论。