DistilBart 是一个典型的用于 NLP 任务的编码器-解码器模型。在本教程中,您将学习如何构建这样一个模型,以及如何检查其架构以便与其他模型进行比较。您还将学习如何使用预训练的 DistilBart 模型生成摘要,以及如何控制摘要的风格。
完成本教程后,您将了解:
- DistilBart 的编码器-解码器架构如何在内部处理文本
- 控制摘要风格和内容的方法
- 评估和改进摘要质量的技术
通过我的书籍《Hugging Face Transformers中的NLP》,快速启动您的项目。它提供了带有工作代码的自学教程。
让我们开始吧!

理解 DistilBart 模型和 ROUGE 指标
图片来自 Svetlana Gumerova。部分权利保留。
概述
本文分为两部分:
- 理解编码器-解码器架构
- 使用 ROUGE 评估摘要结果
理解编码器-解码器架构
DistilBart 是 BART 模型的一个“蒸馏”版本,BART 是一个强大的用于自然语言生成、翻译和理解的序列到序列模型。BART 模型使用完整的编码器和解码器 Transformer 架构。
您可以在论文 “Attention is all you need” 中找到 Transformer 模型的架构。总的来说,其结构如下:
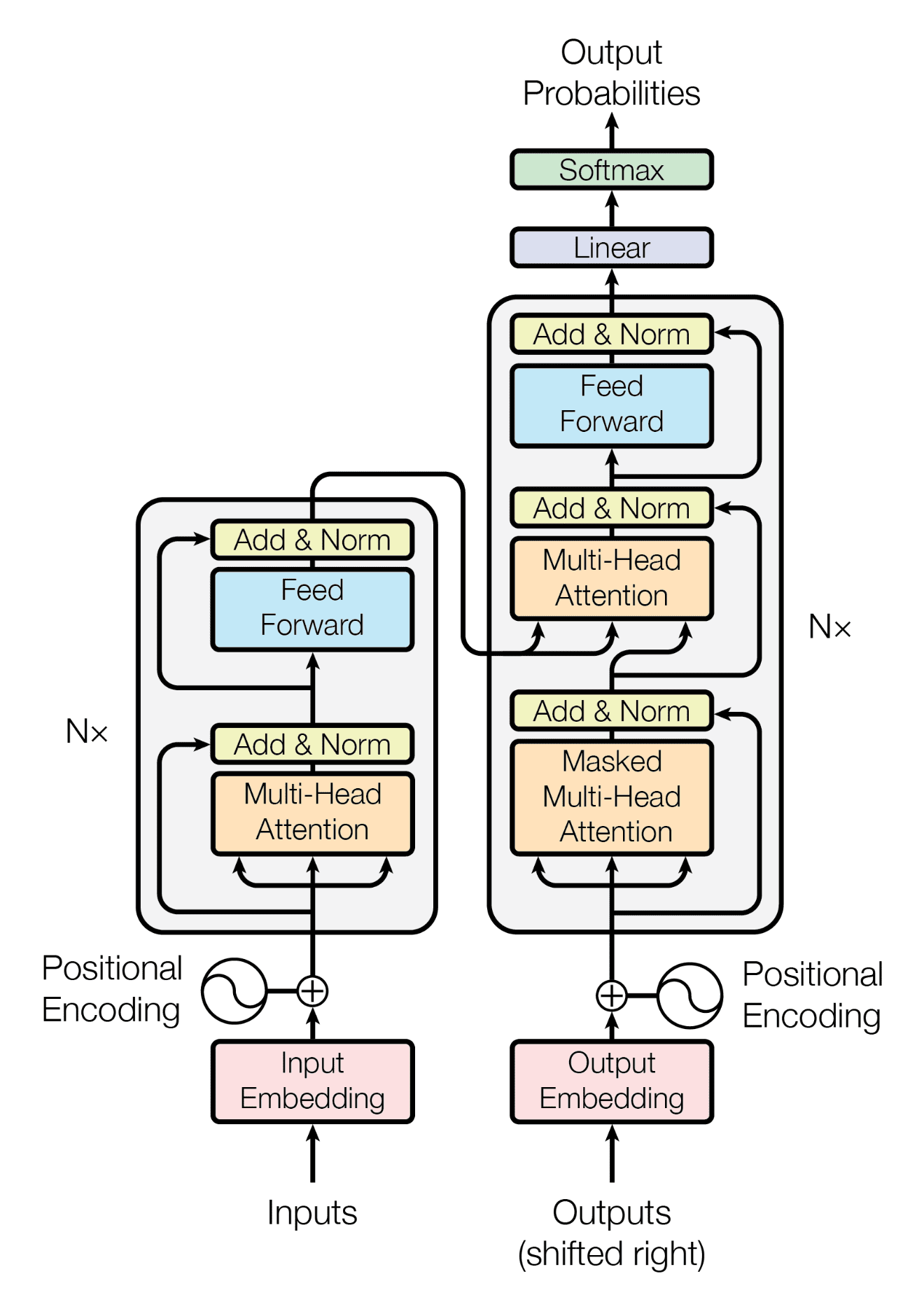
Transformer 架构
Transformer 架构的关键特征是它分为编码器和解码器。编码器接收输入序列并输出一系列隐藏状态。解码器接收隐藏状态并输出最终序列。它对于序列到序列任务(如摘要)非常有效,在这些任务中,在生成摘要之前需要完全解析输入以提取关键信息。
正如在 上一篇文章 中所解释的,您只需几行代码即可使用预训练的 DistilBart 模型构建一个摘要器。事实上,您可以通过查看模型配置来了解 DistilBart 架构中的一些设计参数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from transformers import AutoConfig, AutoModelForSeq2SeqLM def explore_model_architecture(): """检查 DistilBart 的配置和架构。""" model_name = "sshleifer/distilbart-cnn-12-6" # 加载模型配置 config = AutoConfig.from_pretrained(model_name) print("模型架构:") print(f"- 编码器层数: {config.encoder_layers}") print(f"- 解码器层数: {config.decoder_layers}") print(f"- 隐藏层大小: {config.hidden_size}") print(f"- 注意力头数: {config.encoder_attention_heads}") # 验证编码器-解码器结构 model = AutoModelForSeq2SeqLM.from_pretrained(model_name) print("\n模型组件:") print(f"- 编码器: {type(model.model.encoder).__name__}") print(f"- 解码器: {type(model.model.decoder).__name__}") return model, config # 示例用法 model, config = explore_model_architecture() |
上面的代码打印了模型中隐藏状态的大小、注意力头数以及编码器和解码器的层数。输出如下:
|
1 2 3 4 5 6 7 8 |
模型架构 - 编码器层数: 12 - 解码器层数: 6 - 隐藏层大小: 1024 - 注意力头数: 16 模型组件 - 编码器: BartEncoder - 解码器: BartDecoder |
这样创建的模型是 PyTorch 模型。如果您想了解更多信息,可以打印模型:
|
1 2 |
... print(model) |
这将显示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
artForConditionalGeneration( (model): BartModel( (shared): BartScaledWordEmbedding(50264, 1024, padding_idx=1) (encoder): BartEncoder( (embed_tokens): BartScaledWordEmbedding(50264, 1024, padding_idx=1) (embed_positions): BartLearnedPositionalEmbedding(1026, 1024) (layers): ModuleList( (0-11): 12 x BartEncoderLayer( (self_attn): BartSdpaAttention( (k_proj): Linear(in_features=1024, out_features=1024, bias=True) (v_proj): Linear(in_features=1024, out_features=1024, bias=True) (q_proj): Linear(in_features=1024, out_features=1024, bias=True) (out_proj): Linear(in_features=1024, out_features=1024, bias=True) ) (self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True) (activation_fn): GELUActivation() (fc1): Linear(in_features=1024, out_features=4096, bias=True) (fc2): Linear(in_features=4096, out_features=1024, bias=True) (final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True) ) ) (layernorm_embedding): LayerNorm((1024,), eps=1e-05, elementwise_affine=True) ) (decoder): BartDecoder( (embed_tokens): BartScaledWordEmbedding(50264, 1024, padding_idx=1) (embed_positions): BartLearnedPositionalEmbedding(1026, 1024) (layers): ModuleList( (0-5): 6 x BartDecoderLayer( (self_attn): BartSdpaAttention( (k_proj): Linear(in_features=1024, out_features=1024, bias=True) (v_proj): Linear(in_features=1024, out_features=1024, bias=True) (q_proj): Linear(in_features=1024, out_features=1024, bias=True) (out_proj): Linear(in_features=1024, out_features=1024, bias=True) ) (activation_fn): GELUActivation() (self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True) (encoder_attn): BartSdpaAttention( (k_proj): Linear(in_features=1024, out_features=1024, bias=True) (v_proj): Linear(in_features=1024, out_features=1024, bias=True) (q_proj): Linear(in_features=1024, out_features=1024, bias=True) (out_proj): Linear(in_features=1024, out_features=1024, bias=True) ) (encoder_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True) (fc1): Linear(in_features=1024, out_features=4096, bias=True) (fc2): Linear(in_features=4096, out_features=1024, bias=True) (final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True) ) ) (layernorm_embedding): LayerNorm((1024,), eps=1e-05, elementwise_affine=True) ) ) (lm_head): Linear(in_features=1024, out_features=50264, bias=False) ) |
这可能不易阅读。但如果您熟悉 Transformer 架构,您会注意到:
BartModel包含嵌入模型、编码器模型和解码器模型。相同的嵌入模型同时出现在编码器和解码器中。- 嵌入模型的大小表明词汇量包含 50264 个 token。嵌入模型的输出大小为 1024(“隐藏大小”),这是每个 token 的嵌入向量的长度。
- 编码器和解码器都使用 `BartLearnedPositionalEmbedding` 模型,这可能是一个用于每个模型输入序列的学习型位置编码。
- 编码器有 12 层,而解码器只有 6 层。请注意,DistilBart 是 BART 的“蒸馏”版本,因为 BART 有 12 层解码器,而 DistilBart 将其简化为 6 层。
- 在编码器的每一层中,有一个自注意力机制、两个层归一化、两个前馈层,并使用 GELU 作为激活函数。
- 在解码器的每一层中,有一个自注意力机制、一个来自编码器的交叉注意力机制、三个层归一化、两个前馈层,并使用 GELU 作为激活函数。
- 在编码器和解码器中,隐藏大小在各层之间保持不变,但前馈层中间部分的大小是隐藏大小的 4 倍。
大多数 Transformer 模型使用类似的架构,但存在一些差异。这些是模型的高级构建块,但您无法看到确切使用的算法,例如,按什么顺序调用构建块来处理输入序列。只有当您检查模型实现代码时,才能找到这些细节。
并非所有模型都同时拥有编码器和解码器。但是,这种设计对于序列到序列任务非常常见。来自编码器模型的输出被称为输入序列的“上下文表示”。它捕捉了输入文本的本质。解码器模型使用上下文表示来生成最终序列。
使用 ROUGE 评估摘要结果
既然您已经了解了如何使用预训练的 DistilBart 模型生成摘要,那么如何知道其输出的质量呢?
这确实是一个非常困难的问题。每个人对好的摘要都有自己的看法。然而,一些著名的指标用于评估语言模型的各种输出。评估摘要质量的一种流行指标是 ROUGE。
ROUGE 代表“Recall-Oriented Understudy for Gisting Evaluation”(面向召回的要点评估替补)。它是一组用于评估文本摘要和机器翻译质量的指标。在后台,会计算生成摘要的精度和召回率的 F1 分数,并与参考摘要进行比较。它易于理解且易于计算。作为一种基于召回的指标,它侧重于摘要回忆关键短语的能力。ROUGE 的弱点在于它需要参考摘要。因此,评估的有效性取决于参考的质量。
让我们回顾一下如何使用 DistilBart 生成摘要:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
import torch from transformers import AutoTokenizer, AutoModelForSeq2SeqLM class Summarizer: def __init__(self, model_name="sshleifer/distilbart-cnn-12-6"): """使用模型和分词器初始化摘要器。""" self.device = "cuda" if torch.cuda.is_available() else "cpu" self.tokenizer = AutoTokenizer.from_pretrained(model_name) self.model = AutoModelForSeq2SeqLM.from_pretrained(model_name) self.model.to(self.device) def summarize(self, text, context_weight=0.5, max_length=150, min_length=50, num_beams=4, length_penalty=2.0, repetition_penalty=1.0, do_sample=False, temperature=1.0, early_stopping=True): """生成具有上下文感知能力的摘要。""" inputs = self.tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=1024 ).to(self.device) # 使用输入 token 生成摘要 summary_ids = self.model.generate( inputs["input_ids"], attention_mask=inputs["attention_mask"], max_length=max_length, min_length=min_length, num_beams=num_beams, length_penalty=length_penalty, repetition_penalty=repetition_penalty, do_sample=do_sample, temperature=temperature, early_stopping=early_stopping, ) # 解码并返回摘要 summary = self.tokenizer.decode(summary_ids[0], skip_special_tokens=True) return summary # 让我们运行一个示例看看它是如何工作的 summarizer = Summarizer() text = """ 人工智能的发展已经彻底改变了许多行业。 机器学习算法现在为从推荐系统到 自动驾驶汽车的一切提供动力。特别是深度学习,在 图像识别和自然语言处理等任务中取得了显著的成功。 然而,这些进展也引发了关于人工智能对社会影响的重要伦理考量, 隐私和就业。 """ summary = summarizer.summarize(text) print(f"摘要:\n{summary}") |
`Summarizer` 类加载了预训练的 DistilBart 模型和分词器,然后使用该模型为输入文本生成摘要。为了生成摘要,将多个参数传递给 `generate()` 方法来控制摘要的生成方式。您可以调整这些参数,但默认值是一个不错的起点。
现在,让我们扩展 `Summarizer` 类,通过为 `generate()` 方法设置不同的参数来生成不同风格的摘要。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
.. class StyleControlledSummarizer(Summarizer): def summarize_with_style(self, text, style="concise"): """以不同风格生成摘要。 参数 text (str): 要摘要的输入文本 style (str): 摘要风格(“简洁”,“详细”,“技术”,“简单”) Returns str: 以指定风格生成的摘要 """ style_params = { "concise": { "max_length": 80, "min_length": 30, "length_penalty": 3.0, "num_beams": 4, "early_stopping": True }, "detailed": { "max_length": 200, "min_length": 100, "length_penalty": 1.0, "num_beams": 6, "early_stopping": False }, "technical": { "max_length": 150, "min_length": 50, "length_penalty": 2.0, "num_beams": 5, "repetition_penalty": 1.5 }, "simple": { "max_length": 100, "min_length": 30, "length_penalty": 2.0, "num_beams": 3, "do_sample": True, "temperature": 0.7 } } params = style_params[style] return self.summarize(text, **params) # 让我们运行一个示例看看它是如何工作的 style_summarizer = StyleControlledSummarizer() text = """ 量子计算利用量子力学原理执行 计算。与使用比特的经典计算机不同,量子计算机 使用量子比特或 qubit。这些 qubit 可以同时处于多种状态 通过叠加,这可能使量子计算机 能够以指数级速度解决某些问题,比经典计算机快得多。 然而,保持量子相干性并最大限度地减少错误仍然是 构建实用量子计算机的一个重大挑战。 """ styles = ["concise", "detailed", "technical", "simple"] for style in styles: summary = style_summarizer.summarize_with_style(text, style=style) print(f"\n{style.capitalize()} 摘要:") print(summary) |
`StyleControlledSummarizer` 类定义了四种摘要风格:“简洁”,“详细”,“技术”和“简单”。您可以看到 `generate()` 方法的参数对于每种风格都不同。特别是,“详细”风格使用了更长的摘要长度,“技术”风格使用了更高的重复惩罚,而“简单”风格则使用了较低的温度以获得更具创意的摘要。
这样好吗?让我们看看 ROUGE 指标怎么说。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
... from rouge_score import rouge_scorer class SummaryEvaluator: def __init__(self): """使用 ROUGE 指标进行初始化。""" self.scorer = rouge_scorer.RougeScorer( ['rouge1', 'rouge2', 'rougeL'], use_stemmer=True ) def evaluate_summary(self, reference, candidate): """计算摘要的 ROUGE 分数。 参数 reference (str): 参考摘要 candidate (str): 生成的摘要 Returns dict: 不同指标的 ROUGE 分数 """ scores = self.scorer.score(reference, candidate) print("摘要质量指标:") print(f"ROUGE-1: {scores['rouge1'].fmeasure:.3f}") print(f"ROUGE-2: {scores['rouge2'].fmeasure:.3f}") print(f"ROUGE-L: {scores['rougeL'].fmeasure:.3f}") return scores # 检查指标实现 summarizer = StyleControlledSummarizer() evaluator = SummaryEvaluator() reference = "量子计算使用量子比特进行更快的计算,但面临相干性挑战。" for style in ["简洁", "详细", "技术性", "简单"]: candidate = summarizer.summarize_with_style(text, style=style) scores = evaluator.evaluate_summary(reference, candidate) |
您可能会看到如下输出
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
简洁摘要 量子计算利用量子力学原理来执行某些 问题比经典计算机指数级更快。与经典计算机不同 使用比特,量子计算机使用量子比特或量子比特。 这些量子比特可以通过叠加同时存在于多个状态。 摘要质量指标 ROUGE-1: 0.235 ROUGE-2: 0.082 ROUGE-L: 0.157 详细摘要 量子计算利用量子力学原理执行量子计算。 与使用比特的经典计算机不同,量子计算机使用量子 量子比特或量子比特。这些量子比特可以通过 叠加同时存在于多个状态,这可能使量子计算机能够解决某些问题 比经典计算机指数级更快。然而,维持量子相干性 并尽量减少错误仍然是构建实用量子计算机的重大挑战。 根据英国剑桥大学的研究人员的说法。返回邮件 在线主页。返回您来自的页面。 摘要质量指标 ROUGE-1: 0.168 ROUGE-2: 0.043 ROUGE-L: 0.168 技术摘要 量子计算利用量子力学原理来执行某些 问题比经典计算机指数级更快。与经典计算机不同 使用比特,量子计算机使用量子比特或量子比特。 通过叠加同时存在于多个状态。然而,维持量子 相干性和最小化错误仍然是一个挑战。 摘要质量指标 ROUGE-1: 0.262 ROUGE-2: 0.068 ROUGE-L: 0.197 简单摘要 量子计算利用量子力学原理执行量子计算。 计算。与使用比特的经典计算机不同,量子计算机使用量子 量子比特或量子比特。这些量子比特可以通过 叠加。 摘要质量指标 ROUGE-1: 0.217 ROUGE-2: 0.091 ROUGE-L: 0.174 |
要运行此代码,您需要安装rouge_score包
|
1 |
pip install rouge_score |
上面使用了三个指标。ROUGE-1基于unigrams,即单个词。ROUGE-2基于bigrams,即两个词。ROUGE-L基于最长公共子序列。每个指标衡量摘要质量的不同方面。指标值越高越好。
正如您从上面看到的,更长的摘要并不总是更好。这完全取决于您用于评估ROUGE指标的“参考”。
总而言之,以下是完整的代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 |
import torch from rouge_score import rouge_scorer from transformers import AutoTokenizer, AutoModelForSeq2SeqLM class Summarizer: def __init__(self, model_name="sshleifer/distilbart-cnn-12-6"): """使用模型和分词器初始化摘要器。""" self.device = "cuda" if torch.cuda.is_available() else "cpu" self.tokenizer = AutoTokenizer.from_pretrained(model_name) self.model = AutoModelForSeq2SeqLM.from_pretrained(model_name) self.model.to(self.device) def summarize(self, text, context_weight=0.5, max_length=150, min_length=50, num_beams=4, length_penalty=2.0, repetition_penalty=1.0, do_sample=False, temperature=1.0, early_stopping=True): """生成具有上下文感知能力的摘要。""" inputs = self.tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=1024 ).to(self.device) # 使用输入 token 生成摘要 summary_ids = self.model.generate( inputs["input_ids"], attention_mask=inputs["attention_mask"], max_length=max_length, min_length=min_length, num_beams=num_beams, length_penalty=length_penalty, repetition_penalty=repetition_penalty, do_sample=do_sample, temperature=temperature, early_stopping=early_stopping, ) # 解码并返回摘要 summary = self.tokenizer.decode(summary_ids[0], skip_special_tokens=True) return summary class StyleControlledSummarizer(Summarizer): def summarize_with_style(self, text, style="concise"): """以不同风格生成摘要。 参数 text (str): 要摘要的输入文本 style (str): 摘要风格(“简洁”,“详细”,“技术”,“简单”) Returns str: 以指定风格生成的摘要 """ style_params = { "concise": { "max_length": 80, "min_length": 30, "length_penalty": 3.0, "num_beams": 4, "early_stopping": True }, "detailed": { "max_length": 200, "min_length": 100, "length_penalty": 1.0, "num_beams": 6, "early_stopping": False }, "technical": { "max_length": 150, "min_length": 50, "length_penalty": 2.0, "num_beams": 5, "repetition_penalty": 1.5 }, "simple": { "max_length": 100, "min_length": 30, "length_penalty": 2.0, "num_beams": 3, "do_sample": True, "temperature": 0.7 } } params = style_params[style] return self.summarize(text, **params) class SummaryEvaluator: def __init__(self): """使用 ROUGE 指标进行初始化。""" self.scorer = rouge_scorer.RougeScorer( ['rouge1', 'rouge2', 'rougeL'], use_stemmer=True ) def evaluate_summary(self, reference, candidate): """计算摘要的 ROUGE 分数。 参数 reference (str): 参考摘要 candidate (str): 生成的摘要 Returns dict: 不同指标的 ROUGE 分数 """ scores = self.scorer.score(reference, candidate) print("摘要质量指标:") print(f"ROUGE-1: {scores['rouge1'].fmeasure:.3f}") print(f"ROUGE-2: {scores['rouge2'].fmeasure:.3f}") print(f"ROUGE-L: {scores['rougeL'].fmeasure:.3f}") return scores # 检查指标实现 summarizer = StyleControlledSummarizer() evaluator = SummaryEvaluator() text = """ 量子计算利用量子力学原理执行 计算。与使用比特的经典计算机不同,量子计算机 使用量子比特或 qubit。这些 qubit 可以同时处于多种状态 通过叠加,这可能使量子计算机 能够以指数级速度解决某些问题,比经典计算机快得多。 然而,保持量子相干性并最大限度地减少错误仍然是 构建实用量子计算机的一个重大挑战。 """ reference = "量子计算使用量子比特进行更快的计算,但面临相干性挑战。" for style in ["简洁", "详细", "技术性", "简单"]: summary = summarizer.summarize_with_style(text, style=style) print(f"\n{style.capitalize()} 摘要:") print(summary) scores = evaluator.evaluate_summary(reference, summary) |
进一步阅读
以下是一些您可能会觉得有用的资源:
- DistilBart模型
- ROUGE指标
- Sam Shleifer, Alexander M. Rush (arXiv:2010.13002)的“预训练摘要蒸馏”
- Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer (arXiv:1910.13461)的“BART: 降噪序列到序列预训练用于自然语言生成、翻译和理解”
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin (arXiv:1706.03762)的“Attention is all you need”
- Chin-Yew Lin. 2004. “ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out”,第74-81页,西班牙巴塞罗那。计算语言学协会。
总结
在这个高级教程中,您学习了文本摘要的几个高级功能。特别是,您学习了
- DistilBart 的编码器-解码器架构如何处理文本
- 控制摘要风格的方法
- 评估摘要质量的方法
这些高级技术使您能够创建更复杂、更有效的文本摘要系统,以满足特定的需求和要求。
想在您的NLP项目中使用强大的语言模型吗?

在您自己的机器上运行最先进的模型
...只需几行Python代码在我的新电子书中探索如何实现
使用 Hugging Face Transformers 进行自然语言处理
它涵盖了在以下任务上的实践示例和实际用例:文本分类、摘要、翻译、问答等等...
最终将高级NLP带入
您自己的项目
没有理论。只有实用的工作代码。






暂无评论。