使用神经网络模型进行时间序列预测的一个好处是,当新数据可用时,可以更新权重。
在本教程中,您将学习如何使用新数据更新长短期记忆 (LSTM) 循环神经网络以进行时间序列预测。
完成本教程后,您将了解:
- 如何使用新数据更新 LSTM 神经网络。
- 如何开发测试工具以评估不同的更新方案。
- 如何解释使用新数据更新 LSTM 网络的结果。
通过我的新书《时间序列预测深度学习》来启动您的项目,其中包括逐步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2017 年 4 月更新:添加了缺失的 update_model() 函数。
- 2019 年 4 月更新:更新了数据集链接。

如何在训练期间更新 LSTM 网络以进行时间序列预测
摄影:Esteban Alvarez,保留部分权利。
教程概述
本教程分为 9 部分。它们是:
- 洗发水销售数据集
- 实验测试框架
- 实验:无更新
- 实验:2 个更新 epoch
- 实验:5 个更新 epoch
- 实验:10 个更新 epoch
- 实验:20 个更新 epoch
- 实验:50 个更新 epoch
- 结果比较
环境
本教程假定您已安装 Python SciPy 环境。您可以使用 Python 2 或 3。
本教程假定您已安装 Keras v2.0 或更高版本,并使用 TensorFlow 或 Theano 后端。
本教程还假定您已安装 scikit-learn、Pandas、NumPy 和 Matplotlib。
如果您需要帮助设置 Python 环境,请参阅此帖子
洗发水销售数据集
此数据集描述了 3 年期间洗发水月销量。
单位是销售计数,共有 36 个观测值。原始数据集归功于 Makridakis、Wheelwright 和 Hyndman (1998)。
以下示例加载并创建加载数据集的图表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 加载并绘制数据集 from pandas import read_csv from pandas import datetime from matplotlib import pyplot # 加载数据集 def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # 总结前几行 print(series.head()) # 线图 series.plot() pyplot.show() |
运行该示例将数据集作为 Pandas Series 加载并打印前 5 行。
|
1 2 3 4 5 6 7 |
月份 1901-01-01 266.0 1901-02-01 145.9 1901-03-01 183.1 1901-04-01 119.3 1901-05-01 180.3 名称:销售额,数据类型:float64 |
然后创建该系列的线图,显示出明显的上升趋势。
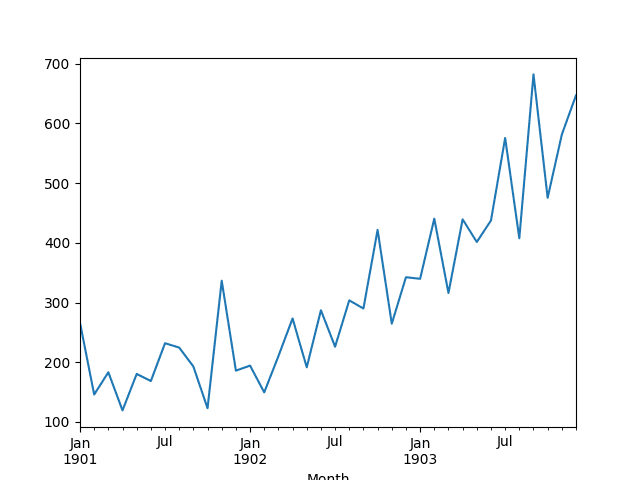
洗发水销售数据集的折线图
接下来,我们将看看实验中使用的LSTM配置和测试框架。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
实验测试框架
本节将介绍本教程中使用的测试框架。
数据分割
我们将把洗发水销售数据集分为两部分:训练集和测试集。
前两年的数据将用于训练数据集,剩下的一年数据将用于测试集。
模型将使用训练数据集进行开发,并对测试数据集进行预测。
测试数据集上的持久性预测(朴素预测)实现了 136.761 月度洗发水销售额的误差。这为测试集上的性能提供了可接受的下限。
模型评估
将使用滚动预测方案,也称为向前验证模型。
测试数据集的每个时间步都将逐一进行。模型将用于对时间步进行预测,然后将从测试集中获取实际预期值,并将其提供给模型以用于下一个时间步的预测。
这模拟了现实世界场景,其中每个月都会有新的洗发水销售观察值,并用于预测下个月。
这将通过训练和测试数据集的结构进行模拟。
测试数据集上的所有预测都将被收集,并计算误差分数以总结模型的技能。将使用均方根误差 (RMSE),因为它会惩罚大误差,并导致分数与预测数据单位相同,即月度洗发水销售额。
数据准备
在我们使用 LSTM 模型拟合数据集之前,我们必须转换数据。
在拟合模型和进行预测之前,对数据集执行以下三种数据转换。
- 转换时间序列数据使其平稳。具体来说,进行 lag=1 的差分以消除数据中不断增长的趋势。
- 将时间序列转换为监督学习问题。具体来说,将数据组织成输入和输出模式,其中使用上一个时间步的观测值作为输入来预测当前时间步的观测值。
- 转换观测值以具有特定比例。具体来说,将数据重新缩放到-1到1之间的值,以满足LSTM模型的默认双曲正切激活函数。
这些转换在预测上进行反转,以在计算误差分数之前将其恢复到原始比例。
LSTM 模型
我们将使用一个具有 1 个神经元的 LSTM 模型,训练 500 个 epoch。
批处理大小需要为 1,因为我们将使用步进验证并对最后 12 个月的数据中的每个数据进行一步预测。
批量大小为1意味着模型将使用在线训练(而不是批量训练或小批量训练)进行拟合。因此,预计模型拟合会存在一些方差。
理想情况下,会使用更多的训练epoch(例如1000或1500),但为了保持运行时间合理,这里截断到500。
模型将使用高效的ADAM优化算法和均方误差损失函数进行拟合。
实验运行
每个实验场景将运行10次。
这是因为 LSTM 网络的随机初始条件可能导致每次给定配置的训练性能都非常不同。
让我们开始实验。
实验:无更新
在第一个实验中,我们将评估一个一次性训练并重复用于预测每个时间步的 LSTM。
我们将其称为“无更新模型”或“固定模型”,因为一旦模型首次在训练数据上拟合,就不会进行任何更新。这提供了一个性能基线,我们期望对模型进行适度更新的实验能够超越这个基线。
完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 |
from pandas import DataFrame from pandas import Series 从 pandas 导入 concat from pandas import read_csv from pandas import datetime from sklearn.metrics import mean_squared_error 从 sklearn.预处理 导入 MinMaxScaler from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 LSTM from math import sqrt import matplotlib import numpy from numpy import concatenate # 用于加载数据集的日期时间解析函数 def parser(x): return datetime.strptime('190'+x, '%Y-%m') # 将序列构造成监督学习问题 def timeseries_to_supervised(data, lag=1): df = DataFrame(data) columns = [df.shift(i) for i in range(1, lag+1)] columns.append(df) df = concat(columns, axis=1) df = df.drop(0) return df # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return Series(diff) # 反转差分值 def inverse_difference(history, yhat, interval=1): return yhat + history[-interval] # 将训练和测试数据缩放到 [-1, 1] def scale(train, test): # 拟合缩放器 scaler = MinMaxScaler(feature_range=(-1, 1)) scaler = scaler.fit(train) # 转换训练集 train = train.reshape(train.shape[0], train.shape[1]) train_scaled = scaler.transform(train) # 转换测试集 test = test.reshape(test.shape[0], test.shape[1]) test_scaled = scaler.transform(test) return scaler, train_scaled, test_scaled # 预测值的逆缩放 def invert_scale(scaler, X, yhat): new_row = [x for x in X] + [yhat] array = numpy.array(new_row) array = array.reshape(1, len(array)) inverted = scaler.inverse_transform(array) return inverted[0, -1] # 训练一个 LSTM 网络 def fit_lstm(train, batch_size, nb_epoch, neurons): X, y = train[:, 0:-1], train[:, -1] X = X.reshape(X.shape[0], 1, X.shape[1]) model = Sequential() model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True)) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') for i in range(nb_epoch): model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False) model.reset_states() return model # 进行一步预测 def forecast_lstm(model, batch_size, X): X = X.reshape(1, 1, len(X)) yhat = model.predict(X, batch_size=batch_size) return yhat[0,0] # 运行重复实验 def experiment(repeats, series): # 将数据转换为平稳 raw_values = series.values diff_values = difference(raw_values, 1) # 将数据转换为监督学习 supervised = timeseries_to_supervised(diff_values, 1) supervised_values = supervised.values # 将数据分割成训练集和测试集 train, test = supervised_values[0:-12], supervised_values[-12:] # 转换数据尺度 scaler, train_scaled, test_scaled = scale(train, test) # 运行实验 error_scores = list() for r in range(repeats): # 拟合基础模型 lstm_model = fit_lstm(train_scaled, 1, 500, 1) # 预测测试数据集 predictions = list() for i in range(len(test_scaled)): # 预测 X, y = test_scaled[i, 0:-1], test_scaled[i, -1] yhat = forecast_lstm(lstm_model, 1, X) # 反转缩放 yhat = invert_scale(scaler, X, yhat) # 反转差分 yhat = inverse_difference(raw_values, yhat, len(test_scaled)+1-i) # 存储预测 predictions.append(yhat) # 报告性能 rmse = sqrt(mean_squared_error(raw_values[-12:], predictions)) print('%d) Test RMSE: %.3f' % (r+1, rmse)) error_scores.append(rmse) return error_scores # 执行实验 def run(): # 加载数据集 series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # 实验 repeats = 10 results = DataFrame() # 运行实验 results['results'] = experiment(repeats, series) # 总结结果 print(results.describe()) # 保存结果 results.to_csv('experiment_fixed.csv', index=False) # 入口点 run() |
运行示例会存储使用步进验证计算的测试数据集上的 RMSE 分数。这些分数存储在名为 experiment_fixed.csv 的文件中,以供后续分析。分数的摘要已打印,如下所示。
注意:鉴于算法或评估过程的随机性质,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
结果表明平均性能优于持久性模型,测试 RMSE 为 109.565465,而持久性模型的月度洗发水销售额为 136.761。
|
1 2 3 4 5 6 7 8 9 |
results 计数 10.000000 均值 109.565465 标准差 14.329646 最小值 95.357198 25% 99.870983 50% 104.864387 75% 113.553952 最大值 138.261929 |
接下来,我们将开始研究在步进验证期间对模型进行更新的配置。
实验:2 个更新 epoch
在此实验中,我们对所有训练数据拟合模型,然后在步进验证期间每次预测后更新模型。
然后,用于在测试数据集中引出预测的每个测试模式都将添加到训练数据集中,并更新模型。
在这种情况下,模型在进行下一次预测之前额外训练了 2 个 epoch。
使用与第一个实验相同的代码清单。代码清单的更改如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
# 更新 LSTM 模型 def update_model(model, train, batch_size, updates): X, y = train[:, 0:-1], train[:, -1] X = X.reshape(X.shape[0], 1, X.shape[1]) for i in range(updates): model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False) model.reset_states() # 运行重复实验 def experiment(repeats, series, updates): # 将数据转换为平稳 raw_values = series.values diff_values = difference(raw_values, 1) # 将数据转换为监督学习 supervised = timeseries_to_supervised(diff_values, 1) supervised_values = supervised.values # 将数据分割成训练集和测试集 train, test = supervised_values[0:-12], supervised_values[-12:] # 转换数据尺度 scaler, train_scaled, test_scaled = scale(train, test) # 运行实验 error_scores = list() for r in range(repeats): # 拟合基础模型 lstm_model = fit_lstm(train_scaled, 1, 500, 1) # 预测测试数据集 train_copy = numpy.copy(train_scaled) predictions = list() for i in range(len(test_scaled)): # 更新模型 if i > 0: update_model(lstm_model, train_copy, 1, updates) # 预测 X, y = test_scaled[i, 0:-1], test_scaled[i, -1] yhat = forecast_lstm(lstm_model, 1, X) # 反转缩放 yhat = invert_scale(scaler, X, yhat) # 反转差分 yhat = inverse_difference(raw_values, yhat, len(test_scaled)+1-i) # 存储预测 predictions.append(yhat) # 添加到训练集 train_copy = concatenate((train_copy, test_scaled[i,:].reshape(1, -1))) # 报告性能 rmse = sqrt(mean_squared_error(raw_values[-12:], predictions)) print('%d) Test RMSE: %.3f' % (r+1, rmse)) error_scores.append(rmse) return error_scores # 执行实验 def run(): # 加载数据集 series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # 实验 repeats = 10 results = DataFrame() # 运行实验 updates = 2 results['results'] = experiment(repeats, series, updates) # 总结结果 print(results.describe()) # 保存结果 results.to_csv('experiment_update_2.csv', index=False) # 入口点 run() |
注意:鉴于算法或评估过程的随机性质,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行实验会将最终测试的 RMSE 分数保存在“experiment_update_2.csv”中,并打印结果的摘要统计数据,如下所示。
|
1 2 3 4 5 6 7 8 9 |
results 计数 10.000000 平均值 99.566270 标准差 10.511337 最小值 87.771671 25% 93.925243 50% 97.903038 75% 101.213058 最大值 124.748746 |
实验:5 个更新 epoch
此实验重复上述更新实验,并在将每个测试模式添加到训练数据集后,对模型进行额外的 5 个 epoch 的训练。
注意:鉴于算法或评估过程的随机性质,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行实验会将最终测试的 RMSE 分数保存在“experiment_update_5.csv”中,并打印结果的摘要统计数据,如下所示。
|
1 2 3 4 5 6 7 8 9 |
results 计数 10.000000 平均值 101.094469 标准差 9.422711 最小值 91.642706 25% 94.593701 50% 98.954743 75% 104.998420 最大值 123.651985 |
实验:10 个更新 epoch
此实验重复上述更新实验,并在将每个测试模式添加到训练数据集后,对模型进行额外的 10 个 epoch 的训练。
注意:鉴于算法或评估过程的随机性质,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行实验会将最终测试的 RMSE 分数保存在“experiment_update_10.csv”中,并打印结果的摘要统计数据,如下所示。
|
1 2 3 4 5 6 7 8 9 |
results 计数 10.000000 平均值 108.806418 标准差 21.707665 最小值 92.161703 25% 94.872009 50% 99.652295 75% 112.607260 最大值 159.921749 |
实验:20 个更新 epoch
此实验重复上述更新实验,并在将每个测试模式添加到训练数据集后,对模型进行额外的 20 个 epoch 的训练。
注意:鉴于算法或评估过程的随机性质,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行实验会将最终测试的 RMSE 分数保存在“experiment_update_20.csv”中,并打印结果的摘要统计数据,如下所示。
|
1 2 3 4 5 6 7 8 9 |
results 计数 10.000000 平均值 112.070895 标准差 16.631902 最小值 96.822760 25% 101.790705 50% 103.380896 75% 119.479211 最大值 140.828410 |
实验:50 个更新 epoch
此实验重复上述更新实验,并在将每个测试模式添加到训练数据集后,对模型进行额外的 50 个 epoch 的训练。
注意:鉴于算法或评估过程的随机性质,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行实验会将最终测试的 RMSE 分数保存在“experiment_update_50.csv”中,并打印结果的摘要统计数据,如下所示。
|
1 2 3 4 5 6 7 8 9 |
results 计数 10.000000 平均值 110.721971 标准差 22.788192 最小值 93.362982 25% 96.833140 50% 98.411940 75% 123.793652 最大值 161.463289 |
结果比较
在本节中,我们将比较之前实验中保存的结果。
我们加载每个保存的结果,用描述性统计数据总结结果,并使用箱线图比较结果。
完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from pandas import DataFrame from pandas import read_csv from matplotlib import pyplot # 加载结果到数据框 filenames = ['experiment_fixed.csv', 'experiment_update_2.csv', 'experiment_update_5.csv', 'experiment_update_10.csv', 'experiment_update_20.csv', 'experiment_update_50.csv'] results = DataFrame() for name in filenames: results[name[11:-4]] = read_csv(name, header=0) # 总结所有结果 print(results.describe()) # 箱线图 results.boxplot() pyplot.show() |
运行示例首先计算并打印每个实验结果的描述性统计数据。
注意:鉴于算法或评估过程的随机性质,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
如果我们查看平均性能,我们可以看到固定模型提供了一个良好的性能基线,但我们看到适度数量的更新周期(20 和 50)平均产生更差的测试集 RMSE。
我们看到少量更新周期会带来更好的整体测试集性能,特别是 2 个周期,然后是 5 个周期。这令人鼓舞。
|
1 2 3 4 5 6 7 8 9 |
固定 更新_2 更新_5 更新_10 更新_20 更新_50 计数 10.000000 10.000000 10.000000 10.000000 10.000000 10.000000 平均值 109.565465 99.566270 101.094469 108.806418 112.070895 110.721971 标准差 14.329646 10.511337 9.422711 21.707665 16.631902 22.788192 最小值 95.357198 87.771671 91.642706 92.161703 96.822760 93.362982 25% 99.870983 93.925243 94.593701 94.872009 101.790705 96.833140 50% 104.864387 97.903038 98.954743 99.652295 103.380896 98.411940 75% 113.553952 101.213058 104.998420 112.607260 119.479211 123.793652 最大值 138.261929 124.748746 123.651985 159.921749 140.828410 161.463289 |
还创建了一个箱线图,比较了每个实验的测试 RMSE 结果分布。
该图突出显示了每个实验的中位数(绿线)以及数据的中间 50%(框)。该图与平均性能讲述了相同的故事,表明少量训练周期(2 或 5 个周期)会产生最佳的整体测试 RMSE。
该图显示,随着更新次数增加到 20 个周期,测试 RMSE 会上升,然后对于 50 个周期又会下降。这可能意味着大量进一步训练改进了模型(11 * 50 个周期),或者只是少量重复(10 次)导致的一个假象。
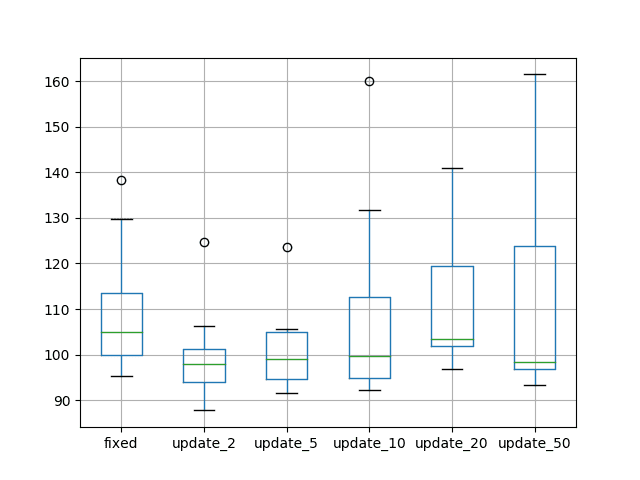
比较更新周期数的箱线图
重要的是要指出,这些结果是针对模型配置和此数据集的特定结果。
除了这个特定示例之外,很难概括这些结果,尽管这些实验确实为在您自己的预测建模问题上执行类似实验提供了一个框架。
扩展
本节列出了本节中实验的扩展思路。
- 统计显著性检验。我们可以计算成对的统计显著性检验,例如学生 t 检验,以查看结果总体中均值之间的差异是否具有统计显著性。
- 更多重复。我们可以将重复次数从 10 次增加到 30 次、100 次或更多,以使结果更具鲁棒性。
- 更多迭代次数。基础 LSTM 模型只进行了 500 个迭代的在线训练,据信增加训练迭代次数将产生更准确的基线模型。迭代次数减少是为了缩短实验运行时间。
- 与更多迭代次数进行比较。更新模型的实验结果应直接与使用相同总迭代次数的固定模型的实验进行比较,以查看将额外测试模式添加到训练数据集是否会产生任何明显差异。例如,每个测试模式的 2 次更新迭代可以与训练了 500 + (12-1) * 2) 或 522 次迭代的固定模型进行比较;5 次更新模型的实验可以与训练了 500 + (12-1) * 5) 或 555 次迭代的固定模型进行比较,依此类推。
- 全新模型。添加一个实验,在将每个测试模式添加到训练数据集后,拟合一个新模型。曾尝试过这样做,但由于运行时间过长,导致在本教程定稿之前未能收集到结果。预计这将为更新模型和固定模型提供一个有趣的比较点。
您是否探索过这些扩展?
请在评论中报告您的结果;我很想听听您的发现。
总结
在本教程中,您学习了如何在 Python 中进行时间序列预测时,在新数据可用时更新 LSTM 网络。
具体来说,你学到了:
- 如何设计一套系统的实验来探索更新 LSTM 模型的效果。
- 如何在有新数据可用时更新 LSTM 模型。
- 对 LSTM 模型的更新可以产生更有效的预测模型,但您的预测问题需要仔细校准。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。






嗨,Jason,
您的教程和实验都切中要害,解释得很好。感谢分享,请继续保持好工作。
谢谢 Rohit。
有点离题。LSTM 是否比通常的时间序列方法或机器学习方法表现更好?
哎呀。这取决于,就像任何算法一样。
参阅“天下没有免费的午餐”定理
https://en.wikipedia.org/wiki/No_free_lunch_in_search_and_optimization
真正的问题是,在什么情况下我们应该使用 LSTM 而不是 ARIMA 等经典方法。
我希望在我的新书中回答这个问题。通常,如果您想轻松处理多变量输入、多步输出和数据中的非线性关系。
嗨,Jason,
好文章。我正在研究 LSTM。我想为每个变量添加两层,并赋予不同的权重。这可能吗?
您能给我一些建议吗?
抱歉,我不确定您所说的“为每个变量添加两层并赋予不同权重”是什么意思。
您能详细说明一下吗?
抱歉,我没把话说清楚。
目前,我有两个输入,我知道其中一个输入比另一个更重要。我想在训练模型时给予它重要性。我的意思是,我尝试给这两个输入中的每一个赋予不同的权重,以使我的预测更精确。
这可能吗?
感谢您的时间。
通常不会。我们更倾向于让算法学习输入的重要性。
感谢您的建议。明白了。
嗨。非常有趣的主题。谢谢。
“更新 2、20、50 epoch”是什么意思?
更改训练迭代次数。
非常棒的帖子,谢谢 Jason
我很高兴您觉得它有用。
嘿,Jason,这真是一篇有趣的文章。
顺便说一下,在实验 2 的第 24 行中,您使用了一个从未定义过的 update_model。
祝好,
克里斯蒂安
哎呀,抱歉。我已经添加了缺失的函数。谢谢。
嗨,Jason,
我注意到 update_model 函数没有定义,您介意将其添加到列表中吗?
谢谢,我已经添加了该函数。
这确实是一篇很好的文章。但是,您是如何在这里使用 LSTM 生成前向预测的呢?
你具体指的是什么?
完成您的模型并调用 model.predict()。
衷心感谢这篇优秀的帖子!
很高兴您觉得它有用,Sam,谢谢。
每次 .fit 如何考虑学习率?我的理解是,每次“更新”时它都会重新开始,这使得在线学习在这种情况下变得困难——这是正确的吗?
(不是说任何事情是正确或不正确的,只是想理解)
在这种情况下,我们使用 Adam,其中每个“参数”(权重)都有自己的学习率。请看这里
https://keras.org.cn/optimizers/#adam
并且它保留了每个权重来自上一次“更新”的衰减/速率吗?
嗨 Jason,非常有趣!谢谢!
是否可以执行在线训练,同时保持上次拟合的最后状态(学习率、动量等)?我相信这可能会带来不同的结果。
大卫
不客气!
您可以保留最后的状态。不确定 SGD 的状态。可能不值得。也许可以尝试一下,看看是否有帮助。
非常感谢 Jason。这些 LSTM 文章太棒了!
我有一个关于更新的问题。如果更新时,不使用整个训练集 + 最后一个 test_scaled[i, 0:-1], test_scaled[i, -1],而只使用训练集中的一小部分和该切片,会有什么区别吗?例如,只使用最后 1/3 的训练样本 + 测试样本。您怎么看?
可能会有。尝试一下,然后报告您的结果。
试图理解您的批量大小为 1 的含义,即“批量大小为 1 是必需的,因为我们将使用步进式验证并进行一步预测……模型将使用在线训练(而不是批量训练或小批量训练)进行拟合。”
首先,我们进行了两次拟合:一次初始拟合,然后是一次更新拟合。似乎初始拟合的批量大小可以更大?
但其次,即使对于那个更新拟合,我们也不是只拟合一个观测值,而是重新拟合整个训练集 + 1 个额外观测值。
我的数据集有 17,000 个观测值,这使得训练时间相当长。只是在寻找加快速度的方法。
你好 Kim。
当使用有状态 LSTM 时,我们必须在 Keras 中对拟合和预测使用相同的批量大小。这很糟糕。这里要求进行一步(一个批量)预测限制了训练。
不过我有一个变通方法,请看这里
https://machinelearning.org.cn/use-different-batch-sizes-training-predicting-python-keras/
或者只是不要让 LSTM 有状态。
Jason,感谢您持续提供相关内容。我将在您引用的博客上发布一个我学到的额外提示。
如果能帮到你,我很乐意,Kim。
嗨,Jason,
精彩的帖子。
然而,当我尝试对 2 个 epoch 进行更新时,它似乎陷入了无限循环。它没有完成。也许更新函数有问题?您怎么看?
或许减少数据量,看看是否会有所不同——这可能是机器速度或 RAM 的问题?
嗨,Jason,
感谢这篇精彩的帖子。
我是循环神经网络的新手,对实验 0 中的单元状态更新有一个幼稚的问题
您说在实验 0 中,模型在训练集上训练后将不会更新。对我来说,这意味着在训练 LSTM (前 24 个月)后学习到的模型参数在预测接下来的 12 个月时都不会改变。但是,我想知道 LSTM 的单元状态是否也会固定,还是允许随着我们遇到测试集中的数据点而不断更新?也就是说,在预测第 30 个月时,LSTM 的单元状态会根据其在第 25-29 个月收到的输入进行更新吗?还是会固定为在训练 LSTM (前 24 个月)后获得的状态?
我的直觉告诉我,随着我们收到测试集中的数据点,它应该不断更新。然而,我在代码中没有明确看到这种情况发生,除非它在 LSTM 模型内部发生?
当我们遍历数据时,单元状态会更新,但单元状态也会在每个批次结束时重置,或者当我们对模型调用 reset_states() 时明确重置。
如何用新数据集重新训练我的模型,并将结果附加到之前的结果中?
上面的帖子有帮助吗?
嗨,Jason,
在模型更新时,为什么要重置单元状态?根据我的理解和直觉,它应该保持先前的单元状态,以提高时间序列建模的效率。
通常,样本结束或批次结束是清除状态的好时机,因为它通常与下一个样本或状态无关。
如果相关,则不要重置状态。
实验并查看哪种方法最适合您的数据。
嗨,Jason,
在您的陈述中
将观测值转换为特定尺度。具体来说,将数据重新缩放至 -1 和 1 之间,以符合 LSTM 模型的默认双曲正切激活函数。
总是这样吗?如果选择使用 Relu 作为激活函数,是否最佳实践是始终将序列范围保持在 0< ?
谢谢!
不,现在我建议将数据缩放到 0-1 用于 LSTM。
我也不建议更改 LSTM 单元内的传输函数。
嗨,Jason,
在您早期(2017 年)关于 LSTM 的一些文章中,您使用 MinMaxScaler 在 -1 和 1 之间进行缩放,并且在第一行 .fit 中没有给出任何激活,从而允许默认的 Tanh 激活
然而,在另一组较新(2018 年初至今)的文章中,您在 .fit 命令的第一行中给出了 activation=relu,并且没有缩放数据。
根据您上面的评论,您是否建议在拟合 LSTM 模型时同时使用 MinMaxScaler (0,1) 和 RELU?
是的,数据缩放给读者带来的困惑比我希望的要多。
ReLU 使模型对数据尺度的敏感性降低。
我仍然建议进行数据缩放,带或不带,更多内容请点击此处
https://machinelearning.org.cn/how-to-improve-neural-network-stability-and-modeling-performance-with-data-scaling/
嗨,Jason,
多次更新的原因是什么?
“在这种情况下,模型在进行下一次预测之前会额外拟合 2 个训练周期。”
这对我来说没有意义。不应该只有一个训练周期用于“下一个时间步”吗?
谢谢!
神经网络中的学习是一个迭代过程,旨在减少误差。除了通过测试,我们无法知道正确的迭代次数。
有道理,谢谢!但我想说的是,迭代次数不应该与初始模型相同吗?为了保持一致性?
你的 fit_lstm() 中的更新实际上是 nb_epochs。
如果我们将训练好的权重作为起点,则不需要。已经学到了一些东西,我们正在对其进行改进。
话虽如此,请始终将更新的模型与新模型进行比较测试。
感谢您持续的回复。我学到了很多。
如果您不介意,再问一个问题。
我说“当模型是有状态的时,它在处理测试数据以进行预测时,会学习测试数据集的序列依赖和模式”,这种说法错了吗?
有状态和无状态模型都会这样做。
区别在于有状态模型允许您控制何时重置内部状态。
所以,从这个意义上说,不需要通过重新拟合来更新模型,因为它在每个测试步骤中都会学习新的模式。对吗?
不,更新指的是更新模型权重。
将内部状态视为模型在进行预测时可以使用的变量。
你好,Jason。
有没有可能我们不是用所有先前的数据点重新训练整个 LSTM 网络,而是只将模型拟合到新的数据点上,因为对于上述方法来说,重新训练需要很长时间,使得任何实时工作都极其缓慢。即使在相当强大的系统上,处理大约 1000 个值的数据集也需要数小时。
当然,尝试多种方法,看看哪种最适合您的特定数据和项目要求。
但是在这里,整个 LSTM 又重新训练了一遍。但是有没有办法只将现有权重和模型拟合到新的数据点上,因为这可能比再次处理所有数据点更快。
我们每次只更新现有权重。
好的,很高兴听到这个消息。
再次感谢 Jason。
🙂
嗨,Jason,
非常感谢您提供此页面的链接。
在现实世界中,我们无法对新数据进行差分、监督转换、缩放,就像示例中的测试集一样。这是否意味着我们必须保留原始数据并将其与新数据合并,然后每次都重复差分、监督转换和缩放过程?
如果这样,它将消耗大量的系统资源。如果有一种更好的方法可以在不重新训练所有内容的情况下使用新数据更新模型。
您不需要重建整个模型,您可以只在新的/最近的数据上重新拟合。
感谢您的回复,Jason。
继续以洗发水销售为例。收到最新月份的数据后,是否可以直接用于拟合模型?它是一个单一值。因此,差分和缩放是不可行的。
model.fit(X, y, nb_epoch=1, batch_size=batch_size, verbose=0, shuffle=False)
这是否也意味着在离线训练之后,model.reset_states() 不应该在整个在线训练过程中执行?
为什么?先前的观测值是进行差分所必需的,并且可以从训练数据中估计出最小值/最大值。
重置状态可能会或可能不会影响模型。对于给定问题,测试预热内部状态是否重要是值得的。
嗨 Jason — 如果我错了请纠正我(如果之前回答过,也请原谅),但你是在每个批次(大小为1)之后都重置状态吗?这难道不意味着我们或多或少地失去了 LSTM 单元的有效性吗?如果我们在只看到一个步骤后就重置状态,那么我们无法学习时间 t-1 之前的任何动态……
感谢您的文章!
是的,大部分情况下,我们会失去 BPTT,但 LSTM 仍然在样本之间具有记忆。
你好 Jason,首先感谢您与我们分享您的知识。
我已经得到了训练好的模型,并想用新数据(data_original+data_new)重新训练它。问题是,如果我加载模型并想继续训练,它似乎会从头开始。即使我使用与训练原始模型时完全相同的设置和数据,也会发生这种情况。您能给我一个提示,我做错了什么吗?
def update_model(model, train, batch_size, updates)
X, y = train[:, :-n_seq], train[:, -n_seq:]
X = X.reshape(X.shape[0], n_lag, n_features)
for i in range(updates)
model.fit(X, y, nb_epoch=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
model = load_model(“multivariete_model.h5”)
update_model(model, train, 1, updates)
您必须将权重保存到文件中,然后稍后可以重新加载它们并继续训练。
我们可以在 LSTM 模型中应用网格搜索方法进行超参数优化吗?
是的,请看这篇文章
https://machinelearning.org.cn/tune-lstm-hyperparameters-keras-time-series-forecasting/
嗨,Jason,我有一些关于 LSTM 网络用于时间序列预测的在线学习的问题。
考虑到 LSTM 网络训练的时间成本,我们希望在处理下一个时间点数据时重新训练之前的模型。
所以,我们需要进行两次拟合:一次初始拟合,然后是一次更新拟合。
对于初始拟合,我们为无状态 LSTM 网络选择一个较大的批次大小。对于更新拟合,我们选择 batch-size=1,以便在初始拟合的基础上重新训练模型。
这个想法有什么问题吗?
我建议进行测试,并根据模型性能来判断这个想法是否可行。
我也非常想请教您。我是机器学习领域的新手。只更新模型用于新数据(在线学习)。有没有办法编写程序实现呢?
是的,使用新数据调用 model.fit()。
嗨,Jason,
我不确定为什么在执行实验时会一直收到以下错误:无更新。
127 results = DataFrame()
128 # 运行实验
–> 129 results[‘results’] = experiment(repeats, series)
130 # 总结结果
131 print(results.describe())
AttributeError: ‘NoneType’ object has no attribute ‘values’。
这段代码与 https://machinelearning.org.cn/multi-step-time-series-forecasting-long-short-term-memory-networks-python/ 中的代码相同,当我尝试完全按照该帖子操作时,它完美运行。
我为更新 LSTM 实验重新启动了内核很多次,但仍然没有帮助……
提前感谢!
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Jason,
顺便说一下:您写道“统计显著性检验。我们可以计算成对统计显著性检验,例如学生 t 检验,以查看结果总体均值之间的差异是否具有统计显著性。”
我想,人们可能会通过执行 Anova 来检验均值差异的显著性吧?
祝好
不,Student's t 检验更合适,如果使用相同数据,则使用配对版本。
更高级的方法在这里
https://machinelearning.org.cn/statistical-significance-tests-for-comparing-machine-learning-algorithms/
嗨,Jason,
我觉得这与本主题无关,抱歉!
但无论如何,我想知道你有没有解释增量序列学习的帖子?
谢谢!
你指的是更新模型吗?
https://machinelearning.org.cn/update-lstm-networks-training-time-series-forecasting/
你好 jason,
是否可以使用群智能算法(例如 ACO 和 PSO)训练 LSTM?
也许可以,但我预计它不如 SGD 高效。
嗨,Jason,
如果我没有大型训练数据集,如何让 LSTM 模型工作?此外,如果时间序列数据正在更新,比如说——我正在跟踪的数据每月更新一次,我每月得到一个新数据点,为了预测它前面一步,我需要再次用新数据点训练模型吗?
也许可以从线性模型开始,只有当它优于线性模型时才采用 LSTM。
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
你好 Jason,
我们如何预测未来值?
好问题,我在这里回答
https://machinelearning.org.cn/make-predictions-long-short-term-memory-models-keras/
嗨,Jason,
“例如,可以将每个测试模式的 2 个更新迭代与训练了 500 + (12-1) * 2) 或 522 个迭代的固定模型进行比较;将更新模型 5 与训练了 500 + (12-1) * 5) 或 555 个迭代的固定模型进行比较,以此类推。”
在上面的例子中,12 是什么?
假设我有 10 天的数据。每天有 375 行。
对于第一个模型,我运行 100 个 epochs,随后的 9 个模型拟合选择 2 个 epochs。那么对于模型 2,总 epochs 数将是
100 + (375-1)*2?
嗨,Jason,
这是一项伟大的工作!我从您的文章中学到了很多。非常感谢。
不过,我很好奇您是否尝试过使用预测值而不是可用测试数据来预测测试数据?
换句话说,在“实验:2个更新周期/预测测试数据集”部分的第35行,您使用测试数据来预测下一个时间步。这对于初始化预测来说没问题,但我的问题是为什么您不使用从上一个预测步骤生成的预测值来更新模型并对下一个时间步进行预测?我认为这更实际。
这篇文章也许能帮助你进行预测
https://machinelearning.org.cn/make-predictions-long-short-term-memory-models-keras/
我认为这篇文章与我所问的有所不同。
我的问题尤其关注“实验:2个更新周期/预测测试数据集”部分的第35行,您在那里使用可用的测试数据来更新模型并进行新的预测。
我的问题是,为什么您不使用预测值来更新模型(重新训练它),然后将预测测试与实际测试数据进行比较?(假设您没有测试数据,然后进行预测,再与可用的测试数据进行比较)
我之所以问这个问题,是因为我想知道是否有办法预测未来 10 或 20 个时间步,这正是大多数投资者在做出重大决定之前希望看到的!
您认为处理这种情况的最佳方法是什么?
再次声明,我问题的目的是学习,而不是批评您的工作!
期待您的反馈
谢谢你
也许是因为我正在演示如何更新模型,这是这篇文章的重点。那是几年前的事了。
我确信你经常被问到这个问题,但我必须知道。你和 Marquees Brownlee 有关系吗?
第一次被问到 🙂
据我所知,我们没有直接关系。
而且他比我有名多了
https://zh.wikipedia.org/wiki/Marques_Brownlee
嗨,Jason,
感谢您的精彩教程。我是 RNNs 的新手,我有一个(可能很愚蠢的)问题。
如果目标是以增量方式训练 LSTM,为什么我们需要训练数据?我们不能从完全冷启动开始,一次增量训练一个观测值,使用下一个时间步的预测进行评估(我认为这被称为预先评估)吗?
我不确定我是否理解,也许你可以详细说明一下?
一般来说,我们正在学习从输入到输出的映射,就像所有机器学习算法一样,只是在这种情况下,输入是一个序列。
在从历史观测中学习此映射之前,我们无法做出准确的预测。
我的意思是纯粹以在线、强化学习类型的方式评估和训练模型。训练数据将一次揭示一个数据点。下一个数据点将用作预测的真实值,然后馈入算法进行增量更新。因此,您基本上从无数据开始,并且没有训练-测试分割。您认为 RNN 可以这样训练吗?
可以做到,这被称为在线学习,但在深度学习中并不常见,深度学习需要相反——在使用前需要大量数据和训练。
关于从头开始在线学习的几点看法
——如果你没有历史数据,你什么时候才能相信预测?你如何知道何时取得成功?
——为了调整你的模型,你需要交替地用不同的参数重新训练。这在没有数据的情况下是无法完成的,所以你真的必须等到未来某个时候,当你积累了足够的数据来用不同的设置重新运行测试,并对结果进行统计分析以找到最佳调整的模型。所以从头开始的在线学习真的不存在!
您需要一个保留测试集来评估模型的技能。
评估模型超参数也是如此。
一旦模型经过评估/配置,就可以使用所有可用数据进行拟合并用于进行预测。
在将其转换为监督学习问题后对序列进行缩放是不合适的,因为每列将以不同的方式处理,这将是不正确的。
但是为什么您在此帖子的代码中将数据转换为监督学习问题后进行缩放呢?
我同意。
如果我再次撰写这篇文章,我就不会那样做了。
嗨,Jason,
我有一些简单的问题;
我正在使用 LSTM 预测负载预测或 1 天(提前 24 个值)。
在尝试仅预测 1 个值并将其添加到历史记录中,然后以相同方式预测接下来的 23 个值(结果不佳)之后,我现在想使用 dense(24),一次预测 24 个点。
(例如,输入 24×10,输出一次 24 个输出)。
我尝试用这种方法分割我的输入和输出数据;例如,前 10 天,输出为 1 天。
结果是一条中间线的形状(不遵循真实数据),不理想..(也许需要更多 epochs.. 但现在我有一个新想法
是否可以将输入分割,使得下一个样本不是 t+1,而是 t+24(第二天)??或者我在这里做错了什么?
这意味着我想尝试:t-24,t-48,t-72,……这样模型才能精确地看到 1 天的变化。
我是否违反了规则?
第二个问题
另一个案例
对于我的交叉验证,我这样做了
使用我创建的一个函数来执行增量学习,遵循以下循环
(从第 1 天到第 19 天训练 -> 预测第 20 天 -> 使用第 20 天真实预测数据重新拟合模型进行下一次训练 -> 预测第 21 天 -> 使用第 21 天真实数据训练 -> 预测第 22 天 -> 使用第 22 天真实数据训练 -> 预测第 23 天等等……)
模型在重新拟合一次后,不知何故忘记了之前所学的一切,并给出了与上次训练日几乎相同的输出。
(预测的第 21 天与训练的第 20 天相同)
(预测的第 22 天与训练的第 21 天相同)
(预测的第 23 天与训练的第 22 天相同)
…
重新拟合 LSTM 模型会使其忘记之前所学到的一切吗?
如果是这样,我如何为我的交叉验证进行增量学习?
感谢您的网站!
是的,如果您想预测 24 天,您必须为每个样本准备具有 24 个观测值的输出序列。这被称为多步预测,您可以在本教程中看到一个示例。
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
您不能使用交叉验证,您必须使用前向验证。
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
不,权重是从训练中“学习”的。
是的,多步预测需要 24 个值,但我指的是样本之间的时间偏移,它也可以是 24 个时间步的偏移吗(通常在 LSTM 中是 1 个时间步的偏移(t-4,t-3,t-2,t-1 ……))??
那么可以是(……,t-72,t-48,t-24)吗?
当然可以。
我的意思是,滑动窗口可以一次沿着时间序列滑动/移动 24 个时间步(而不是一次一个时间步)吗?
我尝试了,结果比每次滑动一个时间步更好更快!
干得好!
当然可以。
你好,我正在尝试教一个LSTM网络一个非常基本的替换规则,比如说替换
a =>x
b =>y
c => w
我正在使用这个字符级架构 https://github.com/tensorflow/tfjs-examples/tree/master/translation 它使用了一个LSTM,但不幸的是,即使我的损失函数非常小,即小于1e-6,我的预测结果仍然非常差。对于这个玩具实验,输出长度应该总是与输入长度相同,例如
abc => xyw
但LSTM有时会给出额外的字符,这是LSTM的特性吗?
或许可以联系代码的作者?
你好,先生,我已根据 https://www.kaggle.com/eray1yildiz/using-lstms-with-attention-for-emotion-recognition/comments 中的代码进行了实现。我已经训练了模型,现在正在进行预测部分。在这个实现中,作者使用了一个示例文本来预测情感,但我希望使用一个包含评论数据帧的数据集,并让系统预测每条评论的结果,并在数据帧中创建一个新列,以便将预测结果输入到每条评论的相应行中。您能帮我如何实现吗?拜托了,先生。
如果可能的话,您可以给我发邮件,以便我向您展示我的数据帧是什么样的以及我希望得到什么输出。
非常感谢。如果您能帮助我,我将不胜感激。谢谢您,先生。
抱歉,我不熟悉该代码。或许直接联系作者?
你好,
我正在尝试执行上面提到的“实验:无更新”代码。但是,在“results[‘results’] = experiment(repeats, series)”这一行出现了错误“ValueError: setting an array element with a sequence.”。
请帮我解决这个问题。
提前感谢
听到这个消息很抱歉,这可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
很好,不言自明。我想问,如果你想用前六个月的数据训练模型,然后用12-18个月的数据“更新-训练”模型,你会如何创建你的神经网络?这甚至可能吗?
我建议您测试一系列不同的模型和不同的数据准备方法,以发现哪种方法最适合您的预测问题。
这个框架将会有帮助
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
你好 jason,
帖子写得很好,我的训练时间即使对于少量数据也要一个多小时。您能提供一些建议吗?
尝试一个更小的模型?
尝试更少的数据?
尝试一台更快的机器?
你好,
谢谢您的回复。您在初始拟合中提到了批量大小为1,这会增加训练时间。我需要进行一步预测,我可以增加初始拟合的批量大小吗?
您可以根据自己的问题随意调整模型。
你好,首先我要感谢你的教程。
不过我有一个问题。我想使用LSTM对未标记的时间序列数据进行异常检测。你推荐什么方法?目前我正在尝试使用与其他模型(ARIMA和平滑)类似的方法——创建数据的滚动预测(使用本教程中建议的方法),计算实际值与预测值之间的差异。计算差异的移动平均值,并将所有差异大于相应移动平均值加上标准差的某个倍数标记为异常。这是一种好的方法吗?
提前感谢您的回复。
不客气!
我建议比较一系列不同的方法,以发现哪种方法最适合您的特定数据集。
你好 Jason,
csv文件的结果,有你想要的格式
结果
10.0
580.9731295227152
267.5408824335027
354.80478706439015
415.93196337203307
439.2223326231947
768.2236324265916
1104.5202715691487
对我来说,它就是那样,当我执行比较代码时,会发生一些错误。
很遗憾您遇到了麻烦,也许这会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我已经检查过那个链接了,一开始一切都和你的代码一样。
你能告诉我如何保存包含结果的csv数据吗?
保存的文件包含列标题和结果,例如一个正常的CSV文件。
错误是
ValueError: DataFrame 的真值是模糊的。请使用 a.empty、a.bool()、a.item()、a.any() 或 a.all()。
ValueError: 无法设置没有定义索引且无法转换为 Series 的帧
此代码不起作用,并发生我在上一篇帖子中评论过的错误。
对于文件名中的名称
results[name[11:-4]] = read_csv(f’results/{name}’, header=0)
我改为这样,它就起作用了。
对于文件名中的名称
data = read_csv(f’results/{name}’, header=0)
var = list(data.results)
results[name[11:-4]] = var
感谢分享。我很惊讶。
也许API变了?
也许您使用的是不同版本的 Python 或库?
你好 jason,
我得到了这个错误
– TypeError: fit() 收到意外的关键字参数 'nb_epoch'
现在只有 epoch 了。nb_epoch 已被弃用。我修改后就能用了!
谢谢
安德烈
谢谢,已修正。
嗨,Jason,
对于模型未固定且正在更新的部分,我有两个问题。
1. RMSE 在每一次尝试后都应该下降,但事实并非如此,而是随机波动的。
2. 当我们更新 50 次而不是 2 次时,为什么结果会恶化?最好它们不应该提高。
也许模型/训练方案不适合数据集。
嗨,Jason,
update_model() 函数应该返回模型,对吧?否则,模型一旦离开函数,其更新就会丢失。
我们正在通过引用传递对象,这是编程中一个非常古老的概念。
嗨 Jason
首先,非常感谢您的这篇文章和这个网站,我从您这里学到了很多!
我有一个关于如何将此步进验证方法与您在此处描述的多输出LSTM模型相结合的问题:https://machinelearning.org.cn/multi-step-time-series-forecasting-long-short-term-memory-networks-python/
如果我错了请纠正我,但如果我尝试预测多步输出(比如7天),并且在测试集中每个数据点预测之后,我用该数据点更新模型,我不是在泄露数据吗?当我更新模型时,我知道第1天的实际目标值,但第2到第6天的目标值对我来说是未知的,但我仍然会用第2到第6天的实际目标值更新模型。我是否误解了什么?我应该如何处理这个问题?
由于输出长度必须始终相同,我能想到的唯一解决方案是获取7天的预测,将第一个值替换为实际值,然后对其进行训练。然而,这似乎是一个糟糕的主意,因为我将对第2到第6天几乎肯定不正确的数据进行训练。
不客气!
只要你不使用未来来预测过去,你就没事。如果你愿意,你可以将关于未来的预测作为输入来预测后续时间步——例如递归预测模型。
这是一个使用步进验证的LSTM多步预测示例
https://machinelearning.org.cn/how-to-develop-lstm-models-for-multi-step-time-series-forecasting-of-household-power-consumption/
博客上还有许多其他示例,请使用搜索框。
希望这能有所帮助。
非常感谢!那篇文章非常有帮助。
我接着实现了那篇文章中的模型,除了最后一个(至少目前是这样)。我已经玩了几天了,有几个问题。
1) 我正在处理类似天气的数据,这些数据主要是前两周独立变量之间非线性相互作用的函数,并且数据也应该与一年前的相同数据有些相似。由于非线性,我没有使用ARIMA等模型。我是否应该考虑将任何参数传递给LSTM的层,以解释数据与一年前相似的情况?我已经有了年份周期+交叉项的虚拟变量。我查阅了Keras LSTM的文档,但没有发现任何明显的东西。
2) 我不确定我是否理解为什么模型没有泄露。一旦我开始使用XGBRegressor进行特征选择+FNN实现步进验证+更新模型策略时,结果变得如此之好,以至于我确定我正在泄露数据,这就是我转向LSTM的原因。一旦我在LSTM设置中实现了步进验证+更新模型,结果真的非常好。
我感到困惑的是,如果我想用这个模型进行实时预测,我实际上无法使用最新的目标变量序列来更新我的模型。例如,如果我试图预测未来30天,在现实生活中,我唯一能够用来更新模型的准确数据是30天前的数据点。我实现了滞后版本和最新版本,自然地,后者给出了更好的结果,这让我想要理解为什么模型没有泄露数据。这个问题是否有更深层次的直觉,或者基本上可以归结为,正如您所说,“只要您不使用未来来预测过去,您就没事”?
3) 我的另一个问题是关于尝试预测目标变量差异序列(如您在我提到的那篇文章中描述的)而不是目标变量序列的结果。我遇到了一些不寻常的问题
3a) 如果我将当前日期的目标变量 t_c 添加到 d_{c+1}、d_{c+2} 等每个差异中,即我的预测是 t_c + d_{c+1}、t_c + d_{c+2} 等,我会得到比我对差异进行滚动求和时更好的结果,即我的预测是 t_c + d_{c+1}、t_c + d_{c+1} + d_{c+2} 等。这似乎意味着模型正在学习预测相对于 t_c 的变化,而不是 t_{c + k} 和 t_{c + k + 1}(k > 0)之间的差异。我已通过手动检查验证了这一点,这似乎确实正在发生。我已确保我正在查看连续几天之间的差异,而不是 t_c 和 t_{c + k}(k > 1)之间的差异。我不知道该如何解释这一点。
3b) 在大多数参数组合下,预测的差异要么全部为正,要么全部为负,并且在预测期(30天)内通常变化不大。在大多数混合情况下,差异无论如何都接近于零。这似乎表明模型不愿意“冒险”。我曾尝试更改学习率来解决这个问题,但想不出其他办法。
3c) 当我对差异进行步进验证+更新时,结果变得更差,与我直接预测变量而不进行差分的情况恰恰相反。
3d) 缩放对差分模型似乎有不良影响,无论是 feature_range=(0, 1) 还是 feature_range=(-1, 1)。天数之间的差异几乎总是在 -1 和 1 之间。
对于所有这些模型,训练超过大约三个时期似乎会导致严重的过拟合,除了步进验证+更新模型策略的情况,其中 +/- 15 似乎是最佳的。
抱歉问题很长。我很乐意阅读您认为相关的任何材料,我知道我问了很多问题。
评论可真长啊!!!
或许可以尝试实验,找出需要哪些输入才能最好地模拟您的问题。
如果您仍然担心,或许可以仔细检查您的管道是否存在泄漏。甚至可以用笔和纸进行检查。
当然,使用任何最适合您的模型+数据的表示。
是的,对此我很抱歉,我正在解决我试图解决的这个问题的一些问题。对于任何偶然发现此评论并想知道我如何解决它的人
1) 这是我能找到的与问题最接近的解决方案:https://github.com/Arturus/kaggle-web-traffic/blob/master/how_it_works.md#working-with-long-timeseries
那里提到的解决方案使用了一种注意力机制。出于我的目的,我选择了一个更简单的版本,最终只是对前一年的相同时间片进行了重新训练。尽管我觉得那里描述的概念很有趣,并且希望将来尝试一下。
2) 我误解了 Jason 对我问题的第一个回答——我以为这意味着我所描述的没有泄露数据,这就是我感到困惑的原因。如果我理解正确的话,我描述的模型实际上泄露了数据。假设你想预测接下来一周的数据,对于某个时间段的每一天,比如一个月。今天是第一天,你预测第2到第8天。下一个要进行的预测是,有了第一天的数据,今天是第二天,你预测第3到第9天。在第一天进行第一次预测之后,当你预测第2到第8天时,你不能再根据第2到第8天的正确数据进行训练。你必须至少等到第8天,尝试预测第9到第15天,才能用第一天的数据更新你的模型,当时你正在尝试预测第2到第8天。
3) 差分通常用于使非平稳数据平稳。我的数据并非如此,尽管我不确定这是否解决了所有我提到的问题。
你的进步真棒,感谢分享你的见解!!
嗨,Jason,我可以问一下这个样本中神经元数量设置为1的原因是什么吗?我知道批量大小为1是为了新数据可以立即重新拟合模型,但我可以将神经元更改为10/20/50,还是在LSTM的步进验证中神经元为1是必须的?
没有什么好理由。
那么,我可以将神经元更改为大于1,并且有不止1层LSTM,对吗?
您可以更改层中的节点/单元数量,也可以更改层数——它们是不同的概念。
嗨,Jason Brownlee,
你分享的知识非常棒。这是每个人都应该效仿的榜样,因为这是前进的唯一途径。我将把它应用到我正在尝试解决的问题上。谢谢
谢谢!
你好,Adrian Tam,你的文章对我很有帮助。
作为一个新手,我不明白为什么函数 update_Model() 不需要将模型作为返回值?模型会继承更新的内容吗?希望你能详细解释一下。非常感谢!
因为模型是在函数外部创建的对象,而在函数中,我们只是修改它。在其他编程语言中,我们称之为“按引用传递”。
我如何将预测结果绘制成图表?
嗨,Sapna……您可能会发现以下资源对结果可视化很有帮助
https://machinelearning.org.cn/data-visualization-in-python-with-matplotlib-seaborn-and-bokeh/
我如何将预测结果绘制成图表?如果我想取测试集的接下来的五个值来预测第六个值,我该怎么做?
你好,
谢谢,詹姆斯。
我还有一个关于更新过程的问题。在测试时,我们是取测试数据中当前时间步的实际值来预测下一个时间步,还是取预测值并将它们添加到列表中以预测未来的时间步?
我们如何从测试集中获取实际值并基于它们进行预测?
嗨,Sapna……预测值被添加到“历史”中,用于进行进一步的预测。以下资源中可以找到更多详细信息
https://machinelearning.org.cn/introduction-to-time-series-forecasting-with-python/
感谢您的回复。我有一个包含循环和容量值的电池数据集。我希望当我在100个循环上训练它时,在测试过程中,它应该取第101个循环的实际容量值,然后预测第102个循环的容量。那么,我如何向模型提供实际值而不是预测值来进行未来预测呢?
我想在模型对测试集的3个月数据进行预测后更新模型,这样我就不需要在每个月的预测后更新,而是希望模型在一段时间后更新,以节省模型重新训练的次数。
嗨,詹妮弗……您的模型进展如何?如果您有任何关于教程的问题,请告诉我们。您可能还希望考虑混合CNN-LSTM模型。
https://machinelearning.org.cn/cnn-long-short-term-memory-networks/