Weka 提供了大量的分类算法。
大量的可用机器学习算法是使用 Weka 平台解决机器学习问题的好处之一。
在这篇文章中,您将学习如何在 Weka 中使用 5 种顶级机器学习算法。
阅读本文后,您将了解
- 关于 5 种可用于分类问题的顶级机器学习算法。
- 如何在 Weka 中使用 5 种顶级分类算法。
- 5 种顶级分类算法的关键配置参数。
用我的新书《Weka 机器学习精通》启动您的项目,其中包括所有示例的分步教程和清晰的屏幕截图。
让我们开始吧。

如何在 Weka 中使用分类机器学习算法
照片由 Don Graham 提供,保留部分权利。
分类算法之旅概述
我们将对 Weka 中的 5 种顶级分类算法进行一次巡礼。
我们将简要描述每种算法的工作原理,突出显示关键算法参数,并在 Weka Explorer 界面中演示该算法。
我们将回顾的 5 种算法是:
- 逻辑回归
- 朴素贝叶斯
- 决策树
- k-最近邻
- 支持向量机
这 5 种算法可以作为起点,尝试解决您的分类问题。
将使用一个标准的机器学习分类问题来演示每种算法。具体来说,是电离层二元分类问题。这是一个很好的数据集来演示分类算法,因为输入变量是数值型的,并且都具有相同的尺度,而且问题只有两个类别需要区分。
每个实例描述了大气雷达回波的特性,任务是预测电离层中是否存在结构。有 34 个数值输入变量,大致具有相同的尺度。您可以在 UCI 机器学习存储库上了解有关此数据集的更多信息。最高结果的准确率约为 98%。
启动 Weka Explorer
- 打开Weka GUI选择器。
- 点击“Explorer”按钮打开 Weka Explorer。
- 从 data/ionosphere.arff 文件加载电离层数据集。
- 点击“Classify”打开分类选项卡。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
逻辑回归
逻辑回归是一种二元分类算法。
它假设输入变量是数值型的并服从高斯(钟形曲线)分布。最后一点并非必须为真,因为即使您的数据不是高斯分布,逻辑回归仍然可以取得良好的结果。对于电离层数据集,一些输入属性具有类似高斯分布,但许多不具备。
该算法为每个输入值学习一个系数,这些系数线性组合成一个回归函数,并通过一个逻辑(S 形)函数进行转换。逻辑回归是一种快速简单的技术,但在某些问题上可能非常有效。
逻辑回归仅支持二元分类问题,尽管 Weka 实现已进行调整以支持多类别分类问题。
选择逻辑回归算法
- 点击“选择”按钮,在“函数”组下选择“Logistic”。
- 点击算法名称以查看算法配置。
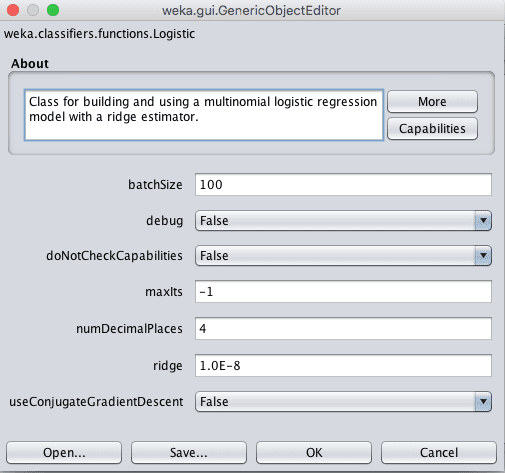
Weka 逻辑回归算法配置
该算法可以运行固定次数的迭代(maxIts),但默认情况下会一直运行,直到估计算法收敛为止。
该实现使用脊估计器,这是一种正则化。此方法旨在通过最小化模型学习到的系数来简化训练期间的模型。脊参数定义了对算法施加多大的压力来减小系数的大小。将其设置为 0 将关闭此正则化。
- 点击“确定”关闭算法配置。
- 点击“开始”按钮在电离层数据集上运行算法。
您可以看到,在默认配置下,逻辑回归达到了 88% 的准确率。
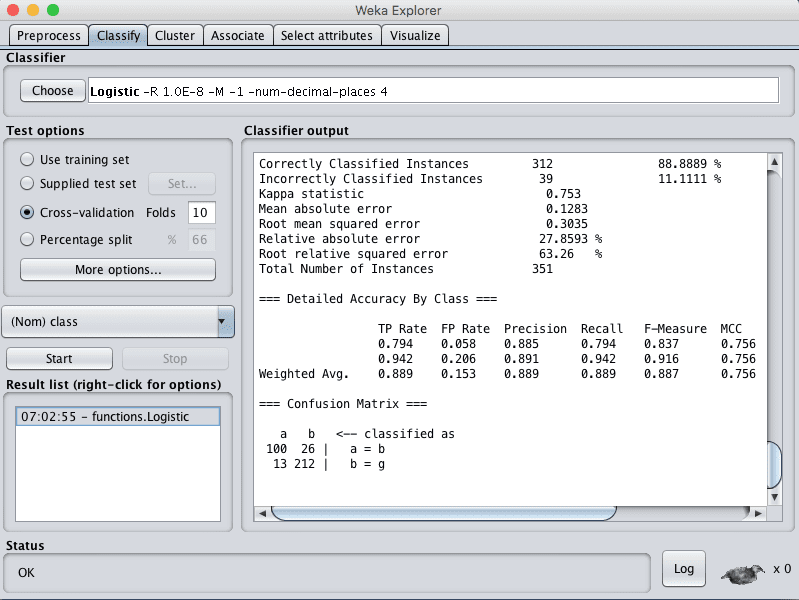
Weka 逻辑回归算法分类结果
朴素贝叶斯
朴素贝叶斯是一种分类算法。传统上,它假设输入值是标称的,尽管通过假设分布来支持数值输入。
朴素贝叶斯使用贝叶斯定理的简单实现(因此称为朴素),其中每个类别的先验概率从训练数据中计算得出,并假定彼此独立(技术上称为条件独立)。
这是一个不切实际的假设,因为我们期望变量之间相互作用并相互依赖,尽管这个假设使得概率计算快速而简单。即使在这个不切实际的假设下,朴素贝叶斯也已被证明是一种非常有效的分类算法。
朴素贝叶斯计算每个类别的后验概率,并预测概率最高的类别。因此,它支持二元分类和多类别分类问题。
选择朴素贝叶斯算法
- 点击“选择”按钮,在“贝叶斯”组下选择“NaiveBayes”。
- 点击算法名称以查看算法配置。
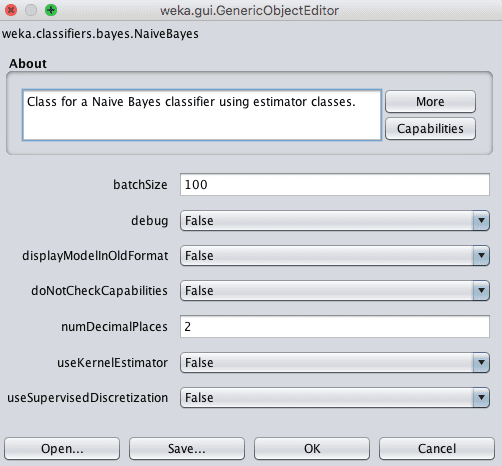
Weka 朴素贝叶斯算法配置
默认情况下,每个数值属性都假定为高斯分布。
您可以使用 `useKernelEstimator` 参数将算法更改为使用核估计器,这可能更好地匹配数据集中属性的实际分布。另外,您可以使用 `useSupervisedDiscretization` 参数将数值属性自动转换为标称属性。
- 点击“确定”关闭算法配置。
- 点击“开始”按钮在电离层数据集上运行算法。
您可以看到,在默认配置下,朴素贝叶斯达到了 82% 的准确率。
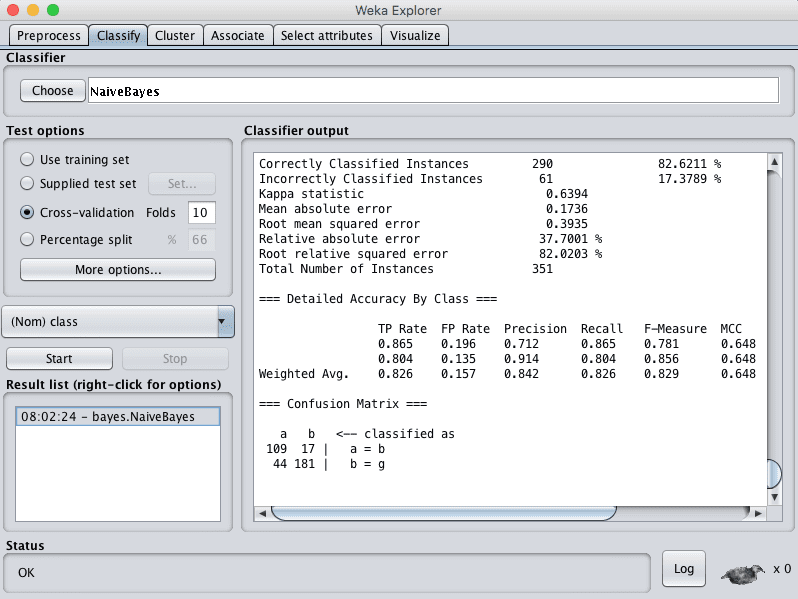
Weka 朴素贝叶斯算法分类结果
您还可以使用其他几种朴素贝叶斯算法。
决策树
决策树可以支持分类和回归问题。
决策树最近被称为分类与回归树 (CART)。它们通过创建一棵树来评估数据实例,从树的根部开始向下移动到叶子(根),直到可以做出预测。创建决策树的过程是通过贪婪地选择最佳分割点来做出预测,并重复该过程直到树达到固定深度。
树构建完成后,对其进行修剪,以提高模型对新数据的泛化能力。
选择决策树算法
- 点击“选择”按钮,在“树”组下选择“REPTree”。
- 点击算法名称以查看算法配置。
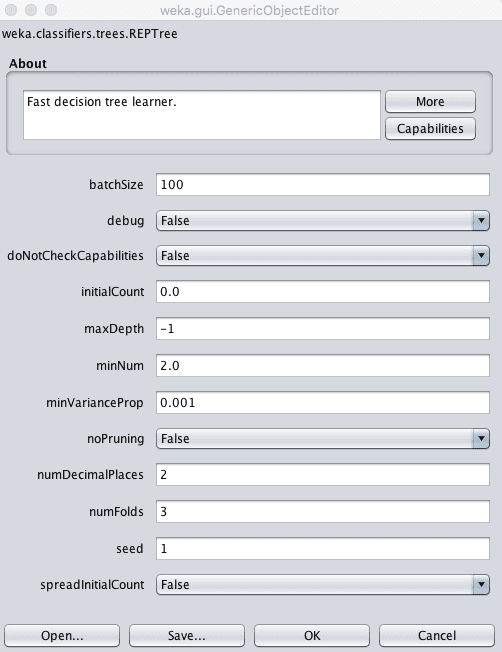
Weka 决策树算法配置
树的深度是自动定义的,但可以在 maxDepth 属性中指定深度。
您还可以选择通过将 `noPruning` 参数设置为 True 来关闭剪枝,尽管这可能会导致性能下降。
minNum 参数定义了在从训练数据构建树时,叶节点中树支持的最小实例数。
- 点击“确定”关闭算法配置。
- 点击“开始”按钮在电离层数据集上运行算法。
您可以看到,在默认配置下,决策树算法达到了 89% 的准确率。
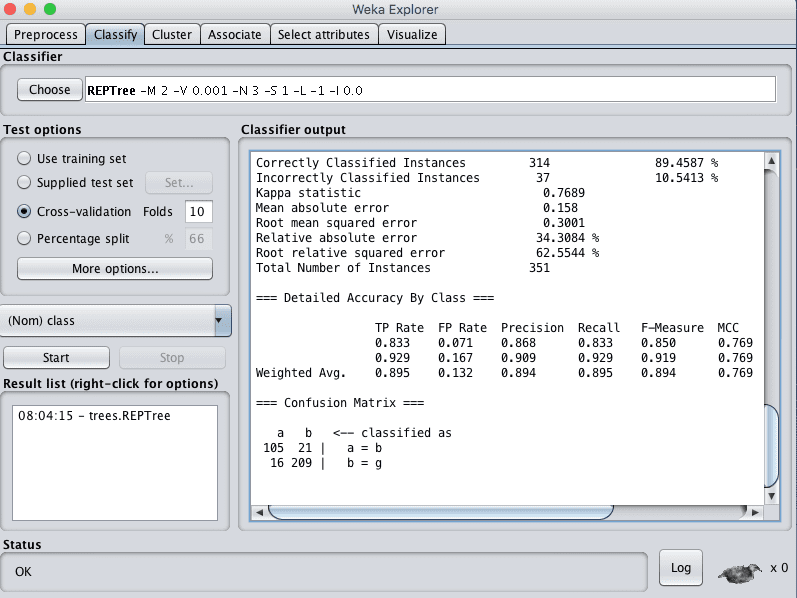
Weka 决策树算法分类结果
您可以使用另一种更高级的决策树算法,即 C4.5 算法,在 Weka 中称为 J48。
您可以通过右键点击“结果列表”并点击“可视化树”来查看在整个训练数据集上准备的决策树的可视化。

Weka 决策树可视化
k-最近邻
k-最近邻算法支持分类和回归。它也简称为 kNN。
它的工作原理是存储整个训练数据集,并在进行预测时查询它以找到 k 个最相似的训练模式。因此,除了原始训练数据集之外,没有模型,执行的唯一计算是在请求预测时查询训练数据集。
它是一个简单的算法,但除了数据实例之间的距离在做出预测时有意义之外,它对问题没有太多假设。因此,它通常能取得非常好的性能。
在对分类问题进行预测时,KNN 将采用训练数据集中 k 个最相似实例的众数(最常见的类别)。
选择 k-最近邻算法
- 点击“选择”按钮,在“惰性”组下选择“IBk”。
- 点击算法名称以查看算法配置。
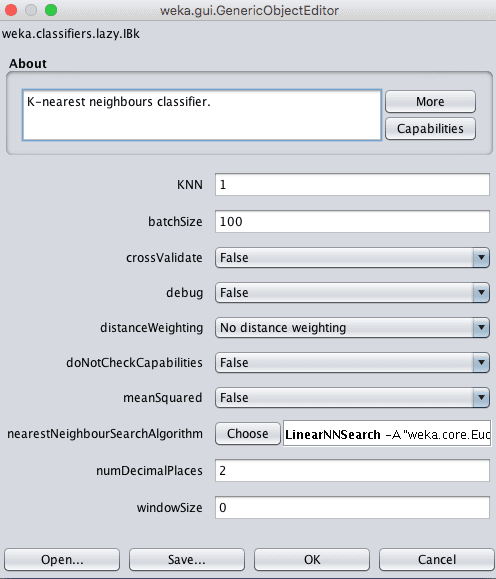
Weka k-最近邻算法配置
邻域的大小由 k 参数控制。
例如,如果 k 设置为 1,则使用与给定新模式(需要预测)最相似的单个训练实例进行预测。k 的常见值为 3、7、11 和 21,对于更大的数据集,k 值更大。Weka 可以通过在算法内部使用交叉验证并设置 `crossValidate` 参数为 True 来自动发现 k 的良好值。
另一个重要参数是使用的距离度量。这在 `nearestNeighbourSearchAlgorithm` 中配置,它控制训练数据的存储和搜索方式。
默认是 LinearNNSearch。点击此搜索算法的名称将提供另一个配置窗口,您可以在其中选择一个 `distanceFunction` 参数。默认情况下,使用欧几里得距离来计算实例之间的距离,这适用于尺度相同的数值数据。如果您的属性在度量或类型上不同,则曼哈顿距离是一个不错的选择。
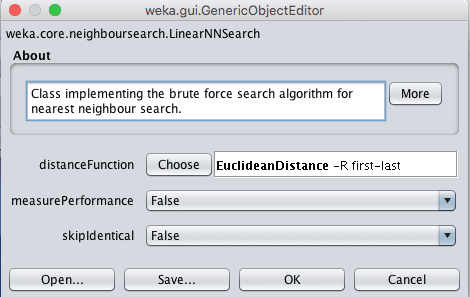
Weka k-最近邻算法中搜索算法的配置
最好在您的问题上尝试一系列不同的 k 值和距离度量,看看哪个效果最好。
- 点击“确定”关闭算法配置。
- 点击“开始”按钮在电离层数据集上运行算法。
您可以看到,在默认配置下,kNN 算法达到了 86% 的准确率。
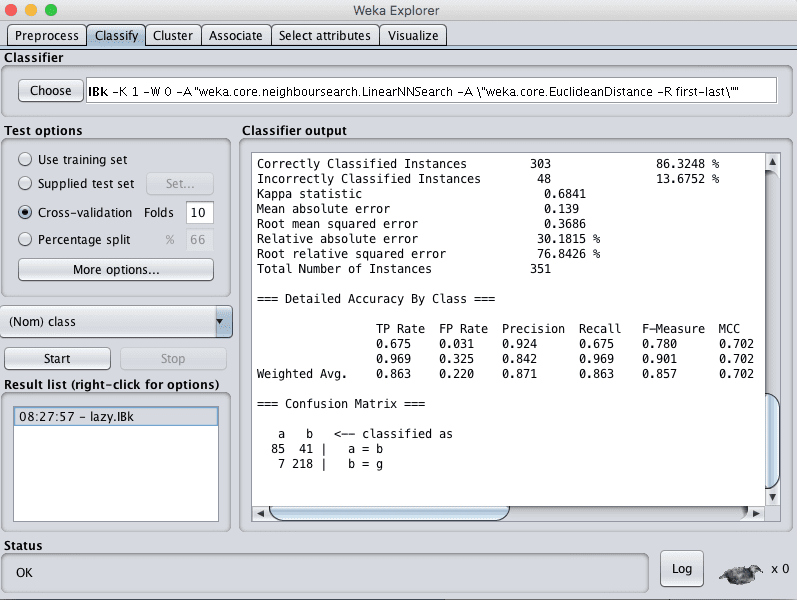
Weka k-最近邻分类结果
支持向量机
支持向量机是为二元分类问题而开发的,尽管该技术已进行扩展以支持多类别分类和回归问题。该算法通常简称为 SVM。
SVM 是为数值输入变量开发的,尽管它会自动将标称值转换为数值。输入数据在使用前也会进行归一化。
SVM 通过寻找一条最佳地将数据分成两组的线来工作。这是通过优化过程完成的,该过程只考虑训练数据集中最接近最佳分离类别的线的那些数据实例。这些实例被称为支持向量,因此得名该技术。
在几乎所有感兴趣的问题中,都无法画出一条线来整齐地分离这些类别,因此在线周围添加了一个边距以放松约束,允许一些实例被错误分类,但总体上能获得更好的结果。
最后,很少有数据集可以用直线分离。有时需要划出带有曲线甚至多边形区域的线。这通过 SVM 将数据投影到更高维空间以绘制线并进行预测来实现。可以使用不同的核来控制投影以及分离类别的灵活性。
选择 SVM 算法
- 点击“选择”按钮,在“函数”组下选择“SMO”。
- 点击算法名称以查看算法配置。
SMO 指的是 SVM 实现中使用的特定高效优化算法,它代表顺序最小优化。
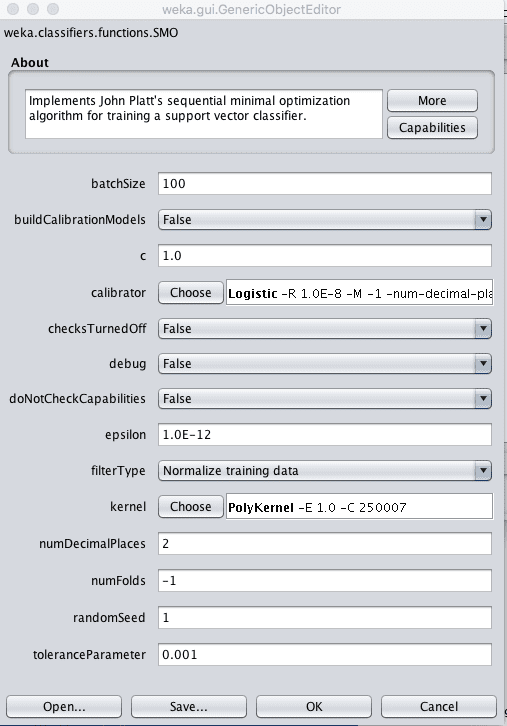
Weka 支持向量机算法配置
C 参数,在 Weka 中称为复杂性参数,控制绘制分离类别的线的灵活程度。值为 0 表示不允许违反边界,而默认值为 1。
SVM 中的一个关键参数是使用的核类型。最简单的核是线性核,它用直线或超平面分离数据。Weka 中的默认核是多项式核,它将使用曲线或波浪线分离类别,多项式越高,波浪越曲折(指数值)。
一个流行且强大的核是 RBF 核或径向基函数核,它能够学习闭合多边形和复杂形状来分离类别。
最好在您的问题上尝试一系列不同的核和 C(复杂性)值,看看哪个效果最好。
- 点击“确定”关闭算法配置。
- 点击“开始”按钮在电离层数据集上运行算法。
您可以看到,在默认配置下,SVM 算法达到了 88% 的准确率。
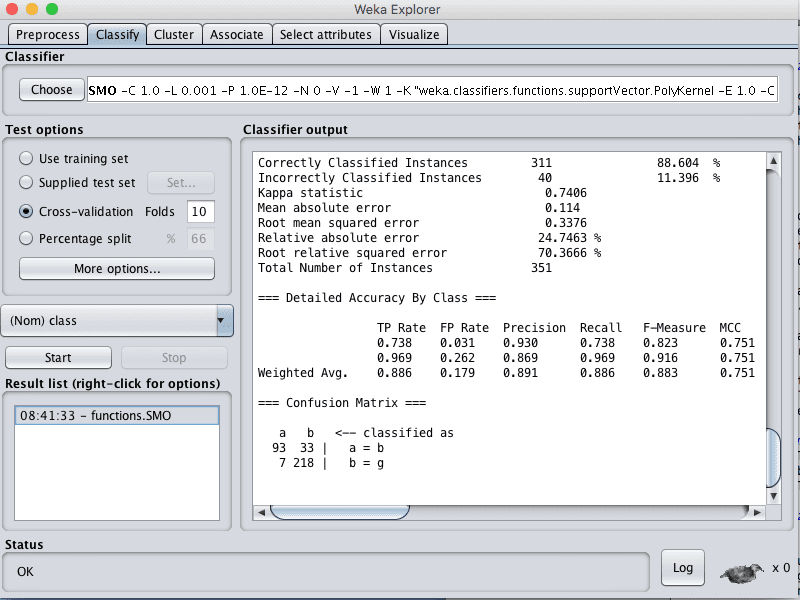
Weka 支持向量机算法分类结果
总结
在这篇文章中,您了解了如何在 Weka 中使用顶级分类机器学习算法。
具体来说,你学到了:
- 您可以尝试解决自己问题的 5 种顶级分类算法。
- 每种算法要调整的关键配置参数。
- 如何在 Weka 中使用每种算法。
您对 Weka 中的分类算法或本文有任何疑问吗?请在评论中提出您的问题,我将尽力回答。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






嗨,感谢您的博客。我只想知道,如果我应用所有这些算法并得到结果,我该如何比较它们以找出最适合我的数据集的算法?
谢谢!
好问题,马利克。
模型选择通常归结为两点:
1. 性能。什么指标能最好地捕捉您对模型的需求,找到在该指标上取得最佳分数的模型或模型集合。
2. 复杂性。我们希望模型在性能良好的同时尽可能简单。这对于可维护性、可解释性、可更新性等方面都有好处。
您希望对所有能想到的算法和数据表示进行比较,然后根据这两个标准选择“最佳”方案。至少作为起点。
这有帮助吗?
非常有帮助!!!
很高兴听到这个消息。
先生,在 weka 中安装 R 插件后。Explorer 选项卡无法工作,MLR 包反复更新。只有 ZeroR 在工作。
抱歉我不知道。或许可以尝试在 weka 用户组发帖?
嗨。 🙂
我想问一下,这个“0.02”是什么意思?它既不是中位数,也不是算术平均值。
谢谢 🙂
通常,决策树中使用特定的值作为分割点。
我可以问一下,这些“特定值”是根据什么选择的?
很好的问题。
您可以在此处了解有关 CART 工作原理的更多信息
https://machinelearning.org.cn/classification-and-regression-trees-for-machine-learning/
非常有帮助,谢谢……
安,很高兴您觉得它有用!
非常有帮助。我有一个问题,我们如何知道只选择这 5 种算法?为什么您在众多算法中只选择了这 5 种算法?
您可以选择任何您喜欢的算法。
非常有帮助。我有一个问题:我们如何在混合数据集(如 UCI 的信用审批数据集)上应用朴素贝叶斯和 SVM?因为它们都不能直接处理数值和标称数据集。
朴素贝叶斯和 SVM 都可以处理实值输入,您可以将数据转换为这种标准形式。
嗨 Jason
如何在 Weka 中添加新的分类器算法?
抱歉,我没有这方面的例子。
嗨。这非常有启发性。我有一个问题。就像我们在 J48 算法或任何基于树的算法中可视化树结构以可视化模型一样,我们如何可视化逻辑回归、k-最近邻等模型——基本上是非基于树的算法?我希望可视化训练集和测试集的模式。
一般来说,我们不这样做。相反,我们使用可视化代理,例如准确率或 RMSE 等技能分数。
非常感谢
嗨。如何在 Weka 中使用 SVM 中的自有算法?请帮帮我。提前感谢。
抱歉,我没有在 Weka 中实现自定义算法的示例。
您好!请帮我总结一下 Weka 中的逻辑回归,就像您对 SVM、朴素贝叶斯等算法所做的那样。
问题究竟是什么?
我有个问题。请问对于以下结果,哪个模型最好?我需要考虑哪些参数?
J48 66.0651%(正确分类) 0.4584(RMSE) 0.3217(kappa) 0.707(ROC) 0.12(耗时)
SMO 66.0967%(正确分类) 0.5823(RMSE) 0.3222(kappa) 0.661(ROC) 100.08(耗时)
模型选择不仅涉及技能,还涉及问题的更广泛考虑。
模型技能之间的差异可能显著,也可能不显著。可以使用统计显著性检验来帮助区分技能差异是否真实。
例如,我们通常更喜欢简单的模型而不是更复杂的模型。
利益相关者也可能偏爱具有特定形式的模型。
嗨,Jason,
感谢这篇有用的文章,我在混淆矩阵中有一个问题,那就是,如何在 weka 中获取算法是如何混淆并进行正确分类的,这意味着分类器可以预测这 500 个实例属于类别 A,而另外 50 个实例预测它们属于类别 B,尽管实际情况它们应该属于类别 A。
本教程展示了如何在新数据上进行预测。
https://machinelearning.org.cn/save-machine-learning-model-make-predictions-weka/
你好杰森。谢谢你。我有一个问题。我如何比较分类(例如 SVM 与 MLP)。我想用例如调整兰德指数来理解它们的协议。但是我不明白如何在各种分类过程中提取每个案例(实例)的分类。你能帮我吗?提前致谢。
这篇文章展示了如何在 Weka 中进行预测。
https://machinelearning.org.cn/save-machine-learning-model-make-predictions-weka/
你好杰森,你的博客真的很有用,而且解释主题的方式很容易理解,你能否也写一篇关于 AIC 和 BIC 的文章。
1. 哪些算法可以使用它?
2. 是跨不同算法还是相同算法的不同模型进行比较?
3. 应该考虑 AIC/BIC 还是 RMSE/准确性?
期待您的文章。
感谢您的建议!
你好,Jason!
我有一个关于如何在 SVM 中使用四种核函数的问题。我没有找到线性核和 Sigmoid 核的选项。如何配置不同核的设置?
在 SVM 的配置中,您可以选择核,然后点击该核来更改其配置。
请问,SVM 中的线性核在哪里?
更改“核”的配置并选择线性。
您好,您能推荐哪种分类器最适合有两个属性且具有实际数据(数值)的情况吗?
尝试一系列方法,看看哪种最适合您的特定数据集,这可能会有所帮助。
https://machinelearning.org.cn/faq/single-faq/what-algorithm-config-should-i-use
嘿,您好,
感谢您的基础教程。
我在一个数据集上进行了操作,发现 SVM 和决策技术的准确率和最佳分类器百分比相同,并且决策树和 SVM 的混淆矩阵也相同。在这种情况下,您如何选择最佳分类器?
好问题。我建议选择最简单/复杂性最低的方法。
也许决策树比 SVM 更不复杂。
我们如何使用 weka 对敏感数据进行分类?
什么是“敏感数据”?
尊敬的先生,工作顺利。我的问题是,我们如何判断这些是顶级算法?
其次,上面 5 个中哪个表现最好?
我建议您针对您的问题测试一系列算法,并发现哪些算法在您的特定数据集上表现最佳。
杰森 - 在 Weka 中,以图表形式展示单个算法随时间变化(例如学习曲线)的最佳方式是什么?
抱歉,我没有在 Weka 中使用学习曲线的示例。
谢谢您的教程。
对于决策树示例,您能解释一下叶节点上打印的值吗?
谢谢
很好的问题。
我不确定,或许可以查阅 Weka 用户手册。
https://machinelearning.org.cn/help-with-weka/
您好。感谢您的培训,它非常有启发性。我们如何将所有这些算法进行比较?我们需要放大哪一部分来比较答案?以及我如何保存结果?
您可以使用 Weka 实验器在您的数据集上比较多种算法,从这里开始
https://machinelearning.org.cn/start-here/#weka
实际上,我看到了你关于上传和保存的帖子,但是当我们保存它并重新加载时,形状和输入会改变,并且不显示百分比。
抱歉,我没跟上,您能详细说明一下吗?
我如何将算法的输出复制到 Weka 软件中,也就是说,我如何保存算法并在输出中找到每个算法的百分比?
抱歉,我没跟上,您能详细说明一下吗?
我如何存储算法的输出?我的意思是,分类器输出部分,我如何存储它显示的结果?
或许可以全选文本,复制到剪贴板,然后粘贴到文本编辑器中?
我在 weka 中使用了这 5 种算法并得到了结果。但在我的结果中,我想比较所有算法,看看哪种算法在我的所有结果中工作得更正确、更好。我该怎么做?
你可以使用实验器
https://machinelearning.org.cn/compare-performance-machine-learning-algorithms-weka/
Weka 工具如何使用?
这里有一些教程
https://machinelearning.org.cn/start-here/#weka
嘿亲爱的杰森,请比较所使用的五种算法的结果并得出结论。谢谢你。
感谢您的建议。
我的意思是,请帮助我完成这项工作,我想比较所使用的五种算法的结果并得出结论。我将不胜感激。
您可以按照本教程并根据您的需求进行调整。
https://machinelearning.org.cn/regression-machine-learning-tutorial-weka/
具体来说,我的意思是您从这个数据集中得出的结论。
嗨,杰森,很棒的帖子。很高兴您在 2020 年仍在回复。
一个问题,是否可以在 Weka 中集成两个不同的分类器,就像我们在其他编程语言(如 Python)中可以做的那样?
非常感谢!
谢谢!
是的,您可以使用投票或堆叠。
嗨,杰森,这是一个非常好的入门教程。您能告诉我哪种算法适合文本数据分类,其中大约有 70-90 个不同的类别吗?
期待您的回复。
谢谢
测试一系列算法,并找出哪些算法对您的特定数据集有效。
用于文本分类的 CNN 表现非常好。
亲爱的杰森,我喜欢你的解释……它很容易理解。
我使用 LR、KNN、J48、NB 和 SVM 在 weka 和 python 中按照您的教程运行了我自己的数据。但是我没有得到两个平台(weka vs python)的相同准确率结果。我能知道为什么吗?
LDA 算法在 weka 中无法运行吗?但在 python 中有。
还有一件事,为什么 python 在混淆矩阵中不能 100% 预测。但在 weka 中我可以看到 100% 的数据被预测了,尽管两者都使用了 10 折交叉验证。
我真的需要您的意见……
谢谢您。
我们可能会得到不同的结果,请看这里
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
谢谢你亲爱的杰森……我明白了……
不客气。
您能解释一下使用交叉验证和训练_测试数据有什么区别吗?哪个更好?
您可以在此处了解 K 折交叉验证。
https://machinelearning.org.cn/k-fold-cross-validation/
您可以在此处了解训练/测试集划分。
https://machinelearning.org.cn/train-test-split-for-evaluating-machine-learning-algorithms/
两者没有优劣之分,它们是不同的。您必须选择您认为对您的预测建模项目值得信赖的技术。
如果您不确定,请使用交叉验证。
非常感谢。这对我帮助很大。
不客气。
非常有用。谢谢!
不客气。
不错的教程!!!
测试数据和训练数据有什么区别?
训练数据用于拟合模型,测试数据用于评估拟合模型。
先生您好
关于分类的解释非常好。您能帮我找到任何关于 Python 中 FURIA 分类的资源吗……它在 Weka 中可以运行,但在 Python 中无法使用 weka.classifiers.rules.FURIA。
嗨,萨克提……以下是关于 Furia 分类的一个很棒的资源
https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.447.2303&rep=rep1&type=pdf
亲爱的 Jason,
感谢您的这篇文章。
您知道如何使用 WEKA 测试我的结构模型吗?
我的模型中有 7 个主要结构,每个结构至少有 7 个指标。我正在尝试使用这些结构预测感知到的使用意图。
嗨,阿肯……您可能会发现以下内容有帮助
https://machinelearning.org.cn/estimate-performance-machine-learning-algorithms-weka/
喜欢这些文章!
感谢 Jerry 的支持和反馈!