集成算法是一类强大的机器学习算法,它结合了多个模型的预测结果。
使用Weka进行应用机器学习的一个好处是,它提供了如此多的不同集成机器学习算法。
在这篇文章中,您将学习如何在Weka中使用集成机器学习算法。
阅读本文后,您将了解
- 关于5种顶级集成机器学习算法。
- 如何在Weka中使用顶级集成算法。
- 关于Weka中集成算法的关键配置参数。
通过我的新书《Weka机器学习精通》来启动您的项目,其中包含分步教程和所有示例的清晰屏幕截图。
让我们开始吧。

如何在 Weka 中使用集成机器学习算法
照片由LEONARDO DASILVA拍摄,保留部分权利。
集成算法概述
我们将对Weka中的5种顶级集成机器学习算法进行一次巡览。
我们将简要介绍每种算法的工作原理,突出关键算法参数,并在Weka Explorer界面中演示该算法。
我们将回顾的5种算法是
- Bagging
- 随机森林
- AdaBoost
- 投票
- 堆叠
这些是您可以在您的项目上尝试的5种算法,以提高性能。
将使用一个标准的机器学习分类问题来演示每种算法。
具体来说,是电离层二分类问题。这是一个很好的数据集来演示分类算法,因为输入变量是数值型的,并且都具有相同的尺度,该问题只有两个需要区分的类。
每个实例描述了来自大气的雷达回波的特性,任务是预测电离层中是否存在结构。有34个数值输入变量,通常具有相同的尺度。您可以在UCI机器学习仓库上了解更多关于此数据集的信息。顶级结果的准确率在98%左右。
启动Weka Explorer
- 打开Weka GUI选择器。
- 点击“Explorer”按钮打开Weka Explorer。
- 从data/ionosphere.arff文件中加载电离层数据集
- 点击“Classify”打开分类选项卡。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
Bootstrap Aggregation (Bagging)
Bootstrap Aggregation,简称Bagging,是一种可用于分类或回归的集成算法。
Bootstrap是一种统计估计技术,其中统计量(如均值)从数据的多个随机样本(有放回)中估计。当数据量有限并且您对统计量的更稳健的估计感兴趣时,这是一种有用的技术。
这种采样原理可以与机器学习模型一起使用。从您的训练数据中抽取多个有放回的随机样本,并用于训练多个不同的机器学习模型。然后使用每个模型进行预测,并将结果平均以提供更稳健的预测。
这是一种最适用于低偏差、高方差的模型的技术,意味着它们进行的预测高度依赖于它们从中训练的特定数据。用于Bagging的最常用的、符合高方差要求的算法是决策树。
选择 bagging 算法
- 点击“Choose”按钮,然后在“meta”组下选择“Bagging”。
- 点击算法名称以查看算法配置。
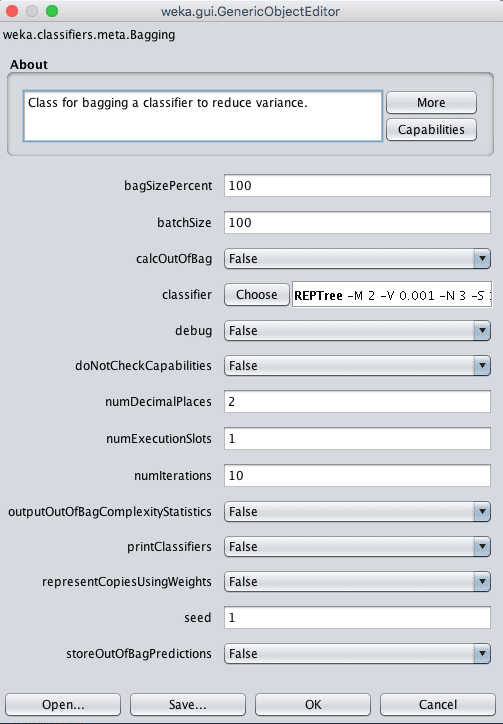
Weka Bagging 算法的配置
Bagging中的一个关键配置参数是被 bagging 的模型的类型。默认是REPTree,它是Weka对标准决策树的实现,也称为分类回归树(CART)。这在classifier参数中指定。
每个随机样本的大小由bagSizePercent指定,它的大小是相对于原始训练数据集的百分比。默认是100%,它将创建一个与训练数据集大小相同的新随机样本,但组成不同。
这是因为随机样本是有放回抽取的,这意味着每次从训练数据集中随机抽取一个实例并将其添加到样本中时,它也会被放回训练数据集中(替换),这意味着它可以被再次选中并添加到样本中一次或多次。
最后,bag的数量(以及分类器的数量)可以在numIterations参数中指定。默认值为10,尽管通常使用数百或数千的值。继续增加numIterations的值,直到模型性能不再提高,或者您耗尽内存。
- 点击“OK”关闭算法配置。
- 点击“Start”按钮在电离层数据集上运行算法。
您可以看到,在默认配置下,bagging的准确率达到了91%。
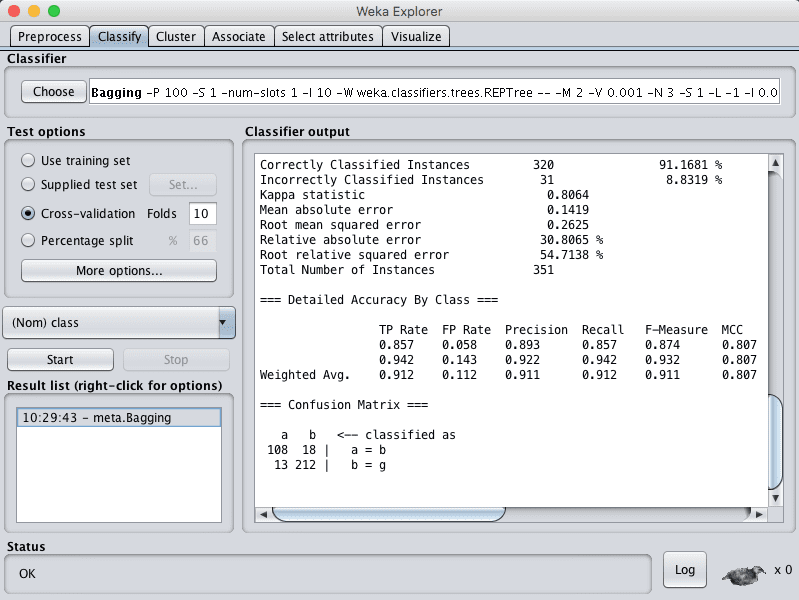
Weka Bagging 算法的分类结果
随机森林
Random Forest是bagging对于决策树的扩展,可用于分类或回归。
袋装决策树的一个缺点是,决策树是通过一种贪婪算法构建的,该算法在树构建过程的每一步都选择最佳分裂点。因此,生成的树看起来非常相似,这降低了所有bag的预测方差,进而损害了预测的稳健性。
Random Forest是袋装决策树的改进,它在树创建过程中会干扰贪婪分裂算法,使得分裂点只能从输入属性的随机子集中选择。这个简单的改变可以对减少bag树之间的相似性以及进而减少预测结果产生很大的影响。
选择随机森林算法
- 点击“Choose”按钮,然后在“trees”组下选择“RandomForest”。
- 点击算法名称以查看算法配置。
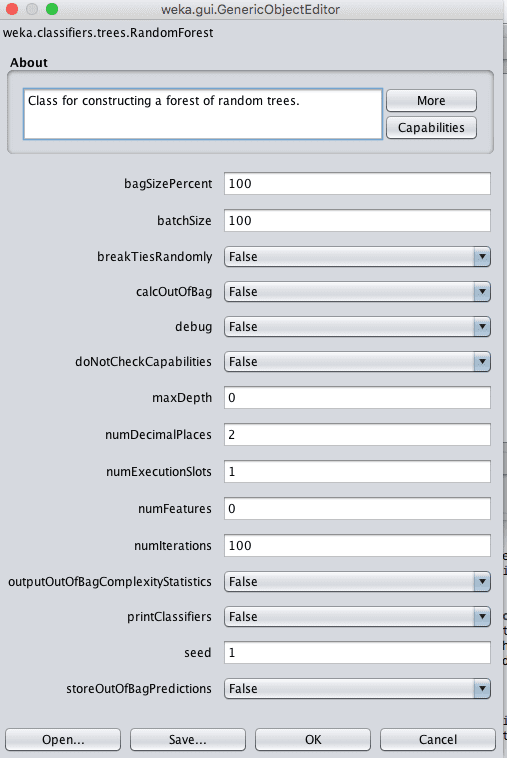
Weka 随机森林算法的配置
除了上面为bagging列出的参数外,随机森林的一个关键参数是每个分裂点要考虑的属性数量。在Weka中,这可以通过numFeatures属性控制,该属性默认设置为0,它会根据经验法则自动选择值。
- 点击“OK”关闭算法配置。
- 点击“Start”按钮在电离层数据集上运行算法。
您可以看到,在默认配置下,随机森林的准确率达到了92%。
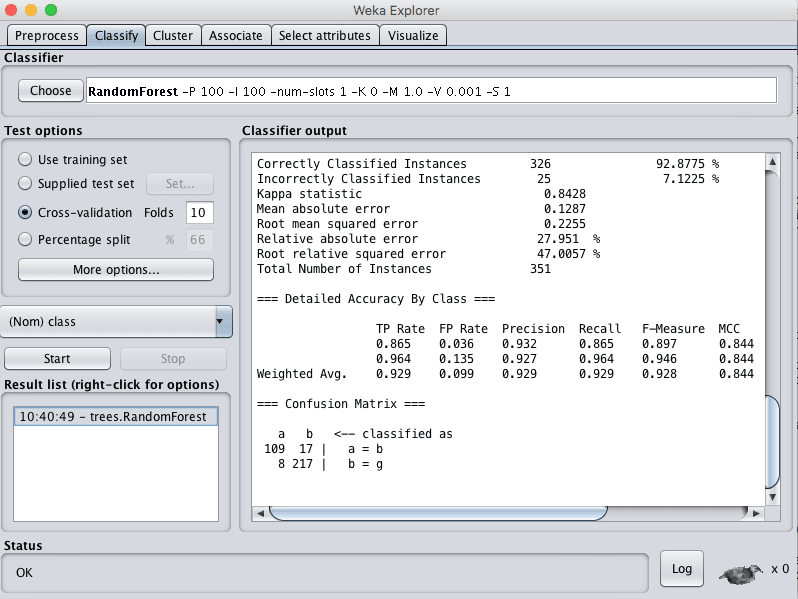
Weka 随机森林算法的分类结果
AdaBoost
AdaBoost是一种用于分类问题的集成机器学习算法。
它属于一类称为Boosting的集成方法,该方法按系列添加新的机器学习模型,后续模型试图修复先前模型所犯的预测错误。AdaBoost是此类模型首次成功的实现。
Adaboost设计用于使用短决策树模型,每个模型只有一个决策点。这些短树通常被称为决策桩。
第一个模型按照正常方式构建。训练数据集中的每个实例都有权重,并且根据模型的总体准确性以及实例是否被正确分类来更新权重。然后训练并添加后续模型,直到达到最小准确性或无法进一步改进。每个模型都根据其技能进行加权,这些权重在组合所有模型在新数据上的预测时使用。
选择 AdaBoost 算法
- 点击“Choose”按钮,然后在“meta”组下选择“AdaBoostM1”。
- 点击算法名称以查看算法配置。
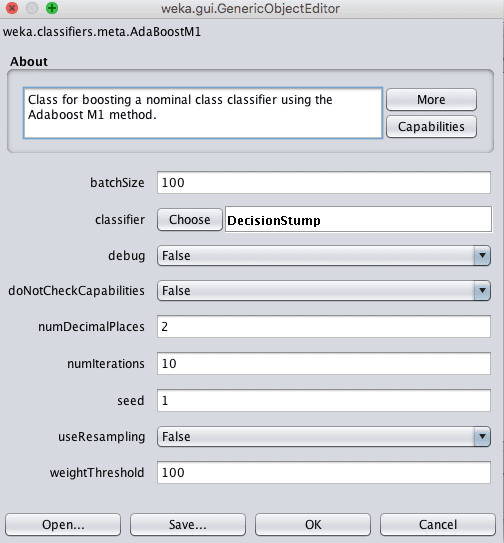
Weka AdaBoost 算法的配置
AdaBoost模型中的弱学习器可以通过classifier参数指定。
默认是决策桩算法,但也可以使用其他算法。除了弱学习器之外,一个关键参数是创建并按系列添加的模型数量。这可以在numIterations参数中指定,默认为10。
- 点击“OK”关闭算法配置。
- 点击“Start”按钮在电离层数据集上运行算法。
您可以看到,在默认配置下,AdaBoost的准确率达到了90%。
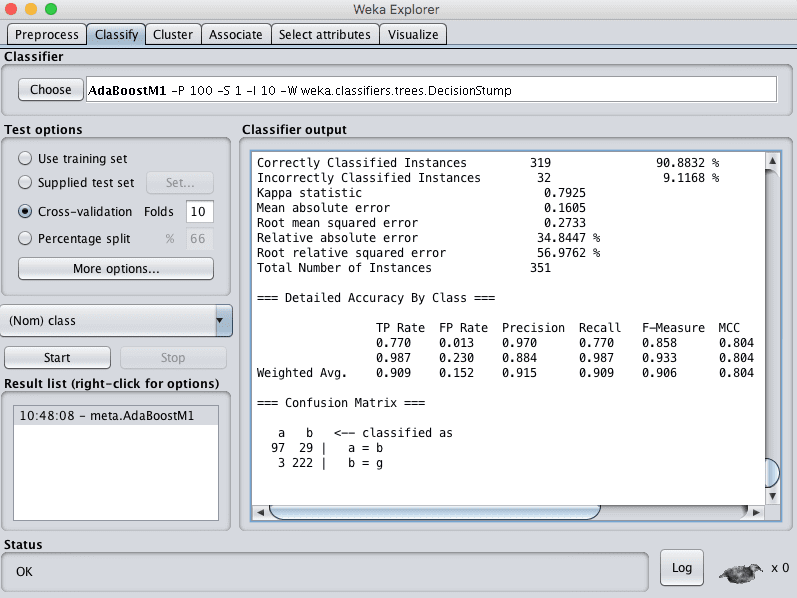
Weka AdaBoost 算法的分类结果
投票
投票可能是最简单的集成算法,并且通常非常有效。它可以用于分类或回归问题。
投票的工作方式是创建两个或多个子模型。每个子模型都会做出预测,这些预测会以某种方式组合,例如取预测的平均值或众数,允许每个子模型就结果应该是什么进行投票。
选择 Vote 算法
- 点击“Choose”按钮,然后在“meta”组下选择“Vote”。
- 点击算法名称以查看算法配置。
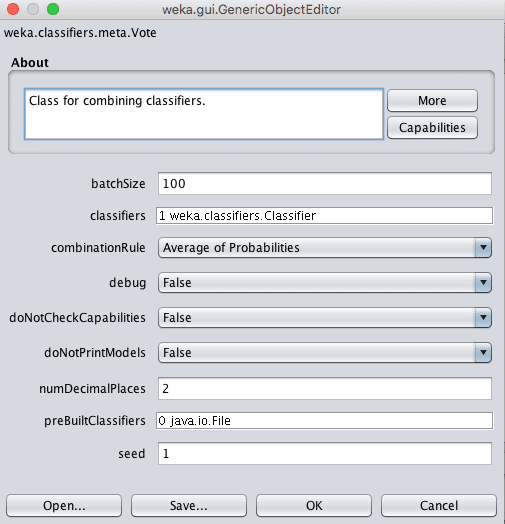
Weka Vote 集成算法的配置
Vote集成的一个关键参数是子模型的选择。
在Weka中,可以通过classifier参数指定模型。点击此参数可以添加多个分类器。
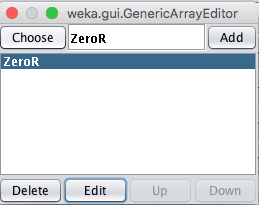
Weka Vote 集成算法的选择
选择一个分类器后点击“Edit”按钮,可以配置该分类器的详细信息。选择子模型的一个目标是选择能够做出非常不同的预测(不相关的预测)的模型。因此,选择非常不同的模型类型是一个好的经验法则,例如树、基于实例的方法、函数等。
另一个为投票配置的关键参数是如何组合子模型的预测。这由combinationRule参数控制,该参数默认设置为取概率的平均值。
- 点击“OK”关闭算法配置。
- 点击“Start”按钮在电离层数据集上运行算法。
您可以看到,在默认配置下,Vote的准确率达到了64%。
显然,该技术取得了不佳的结果,因为只选择了ZeroR子模型。尝试选择5到10个不同的子模型集合。
堆叠泛化(Stacking)
Stacked Generalization 或 Stacking,简称Stacking,是Voting集成的简单扩展,可用于分类和回归问题。
除了选择多个子模型外,Stacking还可以让您指定另一个模型来学习如何最好地组合子模型的预测。因为使用元模型来最好地组合子模型的预测,所以这种技术有时被称为Blending,即混合预测。
选择 Stacking 算法
- 点击“Choose”按钮,然后在“meta”组下选择“Stacking”。
- 点击算法名称以查看算法配置。
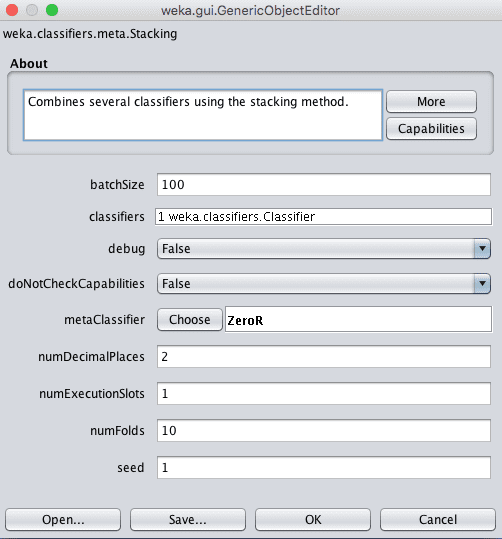
Weka Stacking 集成算法的配置
与Vote分类器一样,您可以在classifiers参数中指定子模型。
将用于学习如何最好地组合子模型预测的模型可以在metaClassifier参数中指定,该参数默认设置为ZeroR(多数投票或平均值)。对于回归和分类问题,通常使用线性算法,如线性回归或逻辑回归。这是为了实现一个输出,该输出是子模型预测的简单线性组合。
- 点击“OK”关闭算法配置。
- 点击“Start”按钮在电离层数据集上运行算法。
您可以看到,在默认配置下,Stacking的准确率达到了64%。
同样,与投票一样,Stacking由于只选择了ZeroR子模型而取得了不佳的结果。尝试选择5到10个不同的子模型集合和一个用于组合预测的良好模型。
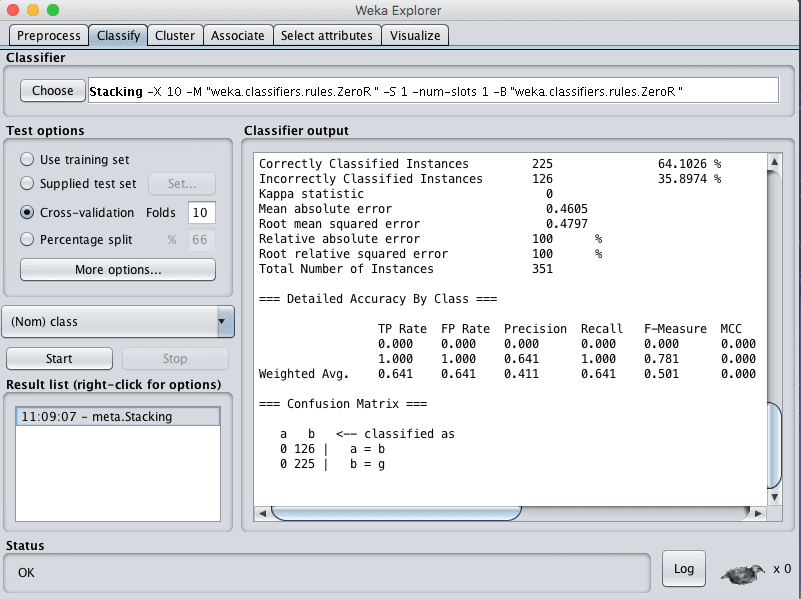
Weka Stacking 集成算法的分类结果
总结
在这篇文章中,您了解了如何在Weka中使用集成机器学习算法。
具体来说,你学到了
- 关于您可以在您的项目上使用的5种集成机器学习算法。
- 如何在Weka中使用集成机器学习算法。
- 关于Weka集成机器学习算法的关键配置参数。
您对Weka中的集成机器学习算法或本文有任何疑问吗?请在评论中提问,我会尽力回答。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






嗨,Jason,
我注意到,当我使用stacking组合一系列分类器时,当元学习器和基础学习器互换时,所用分类器的ROC存在显著差异。例如,当我使用Naïve Bayes作为基础学习器和J48作为元学习器时,记录的ROC为0.805;但当我使用J48作为基础学习器和Naive Bayes作为元学习器时,记录的ROC为0.926。对于使用的一些其他算法,也观察到了类似的模式。您能否详细解释一下这种现象最可能的原因?
谢谢
有趣的发现,Seun,我一时不知道。
好的Jason。谢谢
嗨,Jason,
我是Weka的新手,并尝试使用随机森林训练回归模型。我有以下三个问题:
1)交叉验证
我正在使用10折交叉验证,但我不知道数据是否在分成10折之前被洗牌。具体来说,为什么对于相同的算法,性能统计数据总是相同的?
此外,交叉验证训练的最终模型是什么?我看性能统计数据是由10个模型平均得出的,但最终模型是如何得出的?
2)随机森林
我正在使用默认参数和10折交叉验证,问题与1)相同,为什么性能总是相同的?我认为随机森林会随机选择实例作为训练集,并且还会为每棵树选择一个随机的输入属性子集。但每次我对我的数据集执行随机森林时,训练性能总是相同的。
谢谢。
你好Lebron,
k折交叉验证确实会将数据分成k个随机组,在k-1组上拟合模型,在留出组上进行评估,然后对所有组重复此过程。Weka使用相同的随机种子,因此每次运行时,您都会得到相同的组。
这就是为什么您每次都得到相同结果的原因。
在此处了解更多关于Weka中的交叉验证的信息
https://machinelearning.org.cn/estimate-performance-machine-learning-algorithms-weka/
感谢提供的信息
你好,这里一切都很好,当然每个人都在分享数据,这很好,继续写。
太棒了!
你好Jason先生
我使用了算法组合来预测缺陷数量
我想使用加权平均法来组合算法。Weka中实现了加权平均法吗?如何实现?
请指导我
您可以直接取预测的平均值,也可以使用新模型来学习如何最好地组合预测。
嗨,Jason;
我使用了随机森林,想知道为什么在某些测试数据上会出现误分类。有没有什么特定方法可以知道?
鉴于数据中的噪声以及模型与输入输出之间真实(但未知)映射的失配,总会有预测错误。
我们使用技能得分来了解模型在对新数据进行预测时平均表现如何。
bag大小会对准确率有什么影响?
好问题,较大的模型可能更具表现力,但会达到边际效用递减点。这 realmente取决于具体问题。
非常有用的教程…如果我使用vote并想选择两个分类器,我该如何选择最佳的分类器组合列表,以实现最佳的准确率和性能?
以及我如何真正提高模型的准确率,如果我使用随机森林为例?
好问题。通常,您希望选择预测不相关的模型(不相关的预测错误)。
这可能很难分析,所以也许可以使用实验来测试许多不同的组合。
如何可视化使用元分类器AdaBoost实现的决策树?是否有可以从输出绘制树的包?
据我所知没有。
如何查看随机森林的袋外错误率?
好问题,也许Weka不支持开箱即用。我不确定。
嗨,Jason,
感谢在数据挖掘领域的持续支持。我一直在尝试创建集成异常值检测模型,但未能成功创建一个优于Random Forest的模型。我甚至尝试在集成中包含RF以及其他算法,但似乎没有一个能超越RF。我甚至尝试微调参数,但都无济于事。
一些集成包括
(i)RF+KNN
(ii)KNN + Adaboost,以RF作为弱分类器
(iii)RF + realbost,以KNN作为弱分类器
我尝试了不同的组合,包括使用Vote。
您是否创建过优于RF的集成异常值检测器?
请为我推荐一些可以尝试的算法来进行集成
此致,
Dalton
我没有。
这篇帖子可能会给您更多探索的想法
https://machinelearning.org.cn/machine-learning-performance-improvement-cheat-sheet/
嗨,Jason,
感谢您的努力
我使用Weka实现了adaboostm1
结果如下:
AdaBoostM1:无法进行Boosting,仅使用了一个分类器!
这说明了什么?
我需要进行Boosting,该怎么做或如何解释?
更改算法的配置以使用多个分类器。
我们可以使用WEKA进行集成特征选择吗?
什么是集成特征选择?
尊敬的博士们,我使用了weka 6.8.2,并尝试使用随机森林生成树,设置迭代次数为50,然后它生成了具有不同树大小的树的数量。我该如何确定最佳树大小来生成规则呢?请尽快帮助我!
我建议测试一套不同的配置,看看哪种最适合您的问题。
好的,在使用随机森林(RF)之前,我使用Auto-Weka应用程序进行了测试,所以RF是该数据集的最佳分类器,但是,当使用RF生成树时,它显示了2、3、…等。那么,哪棵树是最好的,是中间的那棵,最后的那棵还是第一棵?我该如何为我的论文选择最好的树?或者您对此类树生成挑战有什么建议?
抱歉,我不明白。也许您可以提供更多背景信息?
你好Jason先生,我是一名博士生,我的研究领域是教育数据挖掘,我想对许多分类器进行比较研究,包括决策树。我从未用过weka软件,我想使用J48和CART。J48已经存在于weka提供的分类器之外,但我没有注意到CART的存在。您能否告诉我如何在weka软件中使用CART算法?
是的,我认为它叫做REPTree。
你好!Jason,希望你一切安好!我是一名MS计算机科学专业的学生,我的研究工作是使用优化的混合方法提高心脏病预测的准确性。请简要介绍一下如何使用混合方法以及从哪里获取数据集。
混合方法可能意味着组合现有算法。
您可以在这里搜索数据集
https://machinelearning.org.cn/faq/single-faq/where-can-i-get-a-dataset-on-___
你好
我有两个问题。
1-我想在weka中为分类器添加新算法,例如遗传算法。
我该怎么做?
2- 我的数据集是关于用水量的,我使用 Weka 预测一个月内的用水量。我使用了线性回归、RandomTree 和 RandomForest。我想提高准确率。
哪个算法适合我的目标?
抱歉,我没有关于在 Weka 中编写新算法的教程。
我在这里有一些提高准确率的建议
https://machinelearning.org.cn/machine-learning-performance-improvement-cheat-sheet/
你好,这里一切都很顺利,当然
每个人都在分享信息,这确实很好,继续写作。
谢谢。
我正在尝试比较三种用于预测数据的方法,与 RET 和 M5P 相比,Random Forest 具有最高的系数。结果框除了摘要外从未显示任何其他信息。我可以在哪里查看用于预测的 Random Forest 模型?
您可以保存模型,您的意思是这个吗?
方法如下
https://machinelearning.org.cn/save-machine-learning-model-make-predictions-weka/
先生您好。非常感谢您对集成算法的解释。我想问一下,如果我们通过堆叠将两种算法组合起来,例如,多层感知器和 IBk,我们如何计算最终技术的时序复杂度?
暂时不确定。
先生您好。我做了三个测试,有 62 个属性,对于第一个测试,我有 90% 的识别率,对于第二个测试,我有 92%,对于第三个测试,我有 88%。我想采用投票方法,以利用这三个测试的结果,最终只得到一个结果。要知道这三个测试的不同基础大小各不相同。
听起来不错,也许可以试试?
先生您好,我使用 weka 进行随机森林回归。但我不知道如何在 weka 中实现,您能帮助我在 weka 中实现随机森林回归吗?