Keras中的长短期记忆(LSTM)网络支持多个输入特征。
这引出了一个问题:对于单变量时间序列,滞后观测值是否可以用作LSTM的特征,以及这是否能提高预测性能。
在本教程中,我们将探讨在Python中在LSTM模型中使用滞后观测值作为特征。
完成本教程后,您将了解:
- 如何开发一个测试框架来系统地评估LSTM特征在时间序列预测中的作用。
- 使用不同数量的滞后观测值作为LSTM模型的输入特征的影响。
- 使用不同数量的滞后观测值和匹配的神经元数量对LSTM模型的影响。
通过我的新书《深度学习时间序列预测》启动您的项目,书中包含分步教程以及所有示例的Python源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。

如何在LSTM网络中使用特征进行时间序列预测
照片由Tom Hodgkinson拍摄,部分权利保留。
教程概述
本教程分为4个部分。它们是:
- 洗发水销售数据集
- 实验测试框架
- 时间步长实验
- 时间步长和神经元实验
环境
本教程假定您已安装 Python SciPy 环境。您可以使用 Python 2 或 3。
本教程假定您已安装 Keras v2.0 或更高版本,并使用 TensorFlow 或 Theano 后端。
本教程还假定您已安装 scikit-learn、Pandas、NumPy 和 Matplotlib。
如果您需要帮助设置 Python 环境,请参阅此帖子
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
洗发水销售数据集
此数据集描述了 3 年期间洗发水月销量。
单位是销售计数,共有 36 个观测值。原始数据集归功于 Makridakis、Wheelwright 和 Hyndman (1998)。
以下示例加载并创建加载数据集的图表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 加载并绘制数据集 from pandas import read_csv from pandas import datetime from matplotlib import pyplot # 加载数据集 def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # 总结前几行 print(series.head()) # 线图 series.plot() pyplot.show() |
运行该示例将数据集作为 Pandas Series 加载并打印前 5 行。
|
1 2 3 4 5 6 7 |
月份 1901-01-01 266.0 1901-02-01 145.9 1901-03-01 183.1 1901-04-01 119.3 1901-05-01 180.3 名称:销售额,数据类型:float64 |
然后创建该系列的线图,显示出明显的上升趋势。
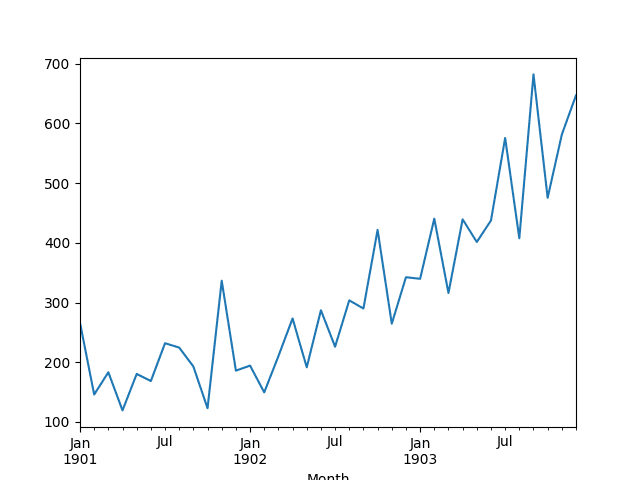
洗发水销售数据集的折线图
接下来,我们将看看实验中使用的LSTM配置和测试框架。
实验测试框架
本节将介绍本教程中使用的测试框架。
数据分割
我们将把洗发水销售数据集分为两部分:训练集和测试集。
前两年的数据将用于训练数据集,剩下的一年数据将用于测试集。
模型将使用训练数据集进行开发,并对测试数据集进行预测。
在测试数据集上的持久性预测(朴素预测)实现了136.761个月洗发水销量的误差。这为测试集上的性能提供了一个可接受的较低界限。
模型评估
将使用滚动预测方案,也称为向前验证模型。
测试数据集的每个时间步都将逐一进行。模型将用于预测时间步的值,然后从测试集中获取实际期望值,并将其提供给模型以预测下一个时间步。
这模拟了现实世界场景,其中每个月都会有新的洗发水销售观察值,并用于预测下个月。
这将通过训练和测试数据集的结构进行模拟。
将收集测试数据集上的所有预测,并计算误差得分来总结模型的技能。均方根误差(RMSE)将被使用,因为它会惩罚较大的误差,并且其得分与预测数据单位相同,即月度洗发水销量。
数据准备
在我们使用 LSTM 模型拟合数据集之前,我们必须转换数据。
在拟合模型和进行预测之前,对数据集执行以下三种数据转换。
- 转换时间序列数据使其平稳。具体来说,进行 lag=1 的差分以消除数据中不断增长的趋势。
- 将时间序列转换为监督学习问题。具体来说,将数据组织成输入和输出模式,其中前一个时间步的观测值用作预测当前时间步观测值的输入。
- 转换观测值以具有特定比例。具体来说,将数据重新缩放到-1到1之间的值,以满足LSTM模型的默认双曲正切激活函数。
在计算误差分数之前,这些转换将被应用于预测中,以将它们恢复到其原始尺度。
LSTM 模型
我们将使用一个基本的有状态LSTM模型,包含1个神经元,训练500个epoch。
由于我们将使用向前滚动验证,并且对最后12个月的测试数据进行单步预测,因此需要批量大小为1。
批量大小为1意味着模型将使用在线训练(而不是批量训练或小批量训练)进行拟合。因此,预计模型拟合会存在一些方差。
理想情况下,会使用更多的训练epoch(例如1000或1500),但为了保持运行时间合理,这里截断到500。
模型将使用高效的ADAM优化算法和均方误差损失函数进行拟合。
实验运行
每个实验场景将运行10次。
这样做的原因是,LSTM网络的随机初始条件每次训练给定配置时都可能导致非常不同的结果。
让我们开始实验。
特征实验
我们将进行5个实验;每个实验将使用从1到5的不同数量的滞后观测值作为特征。
使用1个输入特征的表示形式是使用有状态LSTM时的默认表示形式。使用2到5个特征是人为设定的。希望的是,来自滞后观测值的额外上下文可以改善预测模型的性能。
在训练模型之前,单变量时间序列被转换为监督学习问题。特征的数量指定了用于预测下一个观测值(y)的输入变量(X)的数量。因此,对于表示中使用的每个特征,必须从数据集开头删除相应数量的行。这是因为对于数据集中的前几个值,没有先前的观测值可以作为特征。
下面提供了测试1个输入特征的完整代码列表。
run()函数中的features参数在5个实验中从1到5不等。此外,实验结束时将结果保存到文件中,并且对于每个不同的实验运行,此文件名也必须更改,例如experiment_features_1.csv、experiment_features_2.csv等。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 |
from pandas import DataFrame from pandas import Series 从 pandas 导入 concat from pandas import read_csv from pandas import datetime from sklearn.metrics import mean_squared_error 从 sklearn.预处理 导入 MinMaxScaler from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 LSTM from math import sqrt import matplotlib import numpy from numpy import concatenate # 用于加载数据集的日期时间解析函数 def parser(x): return datetime.strptime('190'+x, '%Y-%m') # 将序列构造成监督学习问题 def timeseries_to_supervised(data, lag=1): df = DataFrame(data) columns = [df.shift(i) for i in range(1, lag+1)] columns.append(df) df = concat(columns, axis=1) return df # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return Series(diff) # 反转差分值 def inverse_difference(history, yhat, interval=1): return yhat + history[-interval] # 将训练和测试数据缩放到 [-1, 1] def scale(train, test): # 拟合缩放器 scaler = MinMaxScaler(feature_range=(-1, 1)) scaler = scaler.fit(train) # 转换训练集 train = train.reshape(train.shape[0], train.shape[1]) train_scaled = scaler.transform(train) # 转换测试集 test = test.reshape(test.shape[0], test.shape[1]) test_scaled = scaler.transform(test) return scaler, train_scaled, test_scaled # 预测值的逆缩放 def invert_scale(scaler, X, yhat): new_row = [x for x in X] + [yhat] array = numpy.array(new_row) array = array.reshape(1, len(array)) inverted = scaler.inverse_transform(array) return inverted[0, -1] # 训练一个 LSTM 网络 def fit_lstm(train, batch_size, nb_epoch, neurons): X, y = train[:, 0:-1], train[:, -1] X = X.reshape(X.shape[0], 1, X.shape[1]) model = Sequential() model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True)) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') for i in range(nb_epoch): model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False) model.reset_states() return model # 进行一步预测 def forecast_lstm(model, batch_size, X): X = X.reshape(1, 1, len(X)) yhat = model.predict(X, batch_size=batch_size) return yhat[0,0] # 运行重复实验 def experiment(repeats, series, features): # 将数据转换为平稳 raw_values = series.values diff_values = difference(raw_values, 1) # 将数据转换为监督学习 supervised = timeseries_to_supervised(diff_values, features) supervised_values = supervised.values[features:,:] # 将数据分割成训练集和测试集 train, test = supervised_values[0:-12, :], supervised_values[-12:, :] # 转换数据尺度 scaler, train_scaled, test_scaled = scale(train, test) # 运行实验 error_scores = list() for r in range(repeats): # 拟合基础模型 lstm_model = fit_lstm(train_scaled, 1, 500, 1) # 预测测试数据集 predictions = list() for i in range(len(test_scaled)): # 预测 X, y = test_scaled[i, 0:-1], test_scaled[i, -1] yhat = forecast_lstm(lstm_model, 1, X) # 反转缩放 yhat = invert_scale(scaler, X, yhat) # 反转差分 yhat = inverse_difference(raw_values, yhat, len(test_scaled)+1-i) # 存储预测 predictions.append(yhat) # 报告性能 rmse = sqrt(mean_squared_error(raw_values[-12:], predictions)) print('%d) Test RMSE: %.3f' % (r+1, rmse)) error_scores.append(rmse) return error_scores # 执行实验 def run(): # 加载数据集 series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # 实验 repeats = 10 results = DataFrame() # 运行实验 features = 1 results['results'] = experiment(repeats, series, features) # 总结结果 print(results.describe()) # 保存结果 results.to_csv('experiment_features_1.csv', index=False) # 入口点 run() |
为5个不同的特征数运行5个不同的实验。
如果您有足够的内存和CPU资源,可以并行运行它们。这些实验不需要GPU资源,运行应在几分钟到几十分钟内完成。
运行实验后,您应该有5个包含结果的文件,如下所示:
- experiment_features_1.csv
- experiment_features_2.csv
- experiment_features_3.csv
- experiment_features_4.csv
- experiment_features_5.csv
我们可以编写一些代码来加载和总结这些结果。
具体来说,审查每次运行的描述性统计信息以及使用箱须图比较每次运行的结果是有用的。
总结结果的代码如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from pandas import DataFrame from pandas import read_csv from matplotlib import pyplot # 加载结果到数据框 filenames = ['experiment_features_1.csv', 'experiment_features_2.csv', 'experiment_features_3.csv','experiment_features_4.csv','experiment_features_5.csv'] results = DataFrame() for name in filenames: results[name[11:-4]] = read_csv(name, header=0) # 总结所有结果 print(results.describe()) # 箱线图 results.boxplot() pyplot.show() |
运行代码后,首先会打印每个结果集的描述性统计信息。
注意:由于算法或评估程序的随机性质,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
从平均性能来看,默认使用单个特征就获得了最佳性能。这在查看中位数测试RMSE(第50百分位数)时也得到了体现。
|
1 2 3 4 5 6 7 8 9 |
features_1 features_2 features_3 features_4 features_5 count 10.000000 10.000000 10.000000 10.000000 10.000000 mean 104.588249 126.597800 118.268251 107.694178 116.414887 std 10.205840 18.639757 14.359983 8.683271 18.806281 min 89.046814 93.857991 103.900339 93.702085 98.245871 25% 97.850827 120.296634 107.664087 102.992045 105.660897 50% 103.713285 133.582095 116.123790 106.116922 112.950460 75% 111.441655 134.362198 121.794533 111.498255 117.926664 max 122.341580 149.807155 152.412861 123.006088 164.598542 |
同时还会创建一个比较结果分布的箱须图。
该图显示的结果与描述性统计信息相同。测试RMSE在2个特征时似乎跳升,并且随着特征数量的增加而呈上升趋势。
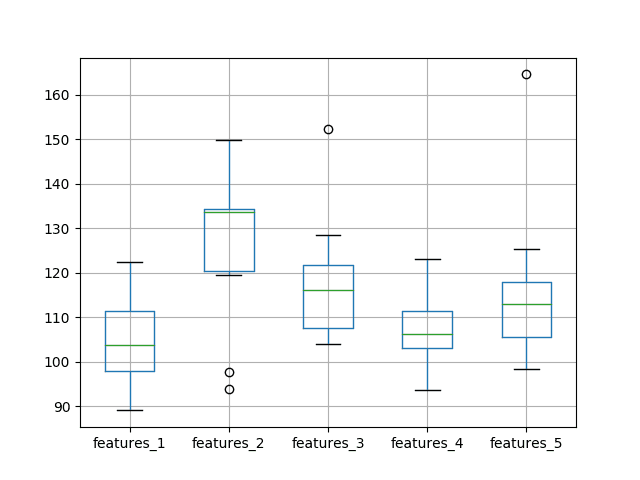
测试RMSE与输入特征数量的箱须图
特征增加导致误差减少的预期并未实现,至少在所使用的数据集和LSTM配置下是这样。
这就引出了网络容量是否是限制因素的问题。我们将在下一节中探讨这一点。
特征和神经元实验
LSTM 网络中的神经元数量(也称为单元)决定了其学习能力。
在前期的实验中,使用单个神经元可能限制了网络的学习能力,使其无法有效地利用滞后观测值作为特征。
我们可以重复之前的实验,并随着特征数量的增加而增加 LSTM 中的神经元数量,看看这是否能提高性能。
这可以通过修改实验函数中的一行来实现:
|
1 |
lstm_model = fit_lstm(train_scaled, 1, 500, 1, features) |
推广到
|
1 |
lstm_model = fit_lstm(train_scaled, 1, 500, features, features) |
此外,我们可以通过在文件名中添加“_neurons”后缀来将结果与第一个实验的结果分开,例如,修改:
|
1 |
results.to_csv('experiment_features_1.csv', index=False) |
推广到
|
1 |
results.to_csv('experiment_features_1_neurons.csv', index=False) |
使用这些更改重复相同的 5 个实验。
运行这些实验后,您应该有 5 个结果文件。
- experiment_features_1_neurons.csv
- experiment_features_2_neurons.csv
- experiment_features_3_neurons.csv
- experiment_features_4_neurons.csv
- experiment_features_5_neurons.csv
与之前的实验一样,我们可以加载结果、计算描述性统计数据并创建箱线图。完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from pandas import DataFrame from pandas import read_csv from matplotlib import pyplot # 加载结果到数据框 filenames = ['experiment_features_1_neurons.csv', 'experiment_features_2_neurons.csv', 'experiment_features_3_neurons.csv','experiment_features_4_neurons.csv','experiment_features_5_neurons.csv'] results = DataFrame() for name in filenames: results[name[11:-12]] = read_csv(name, header=0) # 总结所有结果 print(results.describe()) # 箱线图 results.boxplot() pyplot.show() |
运行代码后,首先会打印出 5 个实验的描述性统计数据。
注意:由于算法或评估程序的随机性质,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
结果与第一个单神经元 LSTM 实验集不同。当神经元数量和特征数量设置为一时,平均测试 RMSE 最低,然后随着神经元和特征数量的增加,误差也随之增加。
|
1 2 3 4 5 6 7 8 9 |
features_1 features_2 features_3 features_4 features_5 count 10.000000 10.000000 10.000000 10.000000 10.000000 均值 106.219189 138.411111 127.687128 154.281694 175.951500 标准差 16.100488 29.700981 21.411766 30.526294 44.839217 最小值 91.073598 92.641030 103.503546 94.063639 117.017109 25% 97.263723 125.748973 108.972440 134.805621 142.146601 50% 99.036766 133.639168 128.627349 162.295657 182.406707 75% 110.625302 146.896608 134.012859 176.969980 197.913894 最大值 146.638148 206.760081 170.899267 188.911768 250.685187 |
创建箱线图以比较分布。
随着神经元数量和输入特征数量的增加,分布范围和中位数性能的趋势几乎显示出测试 RMSE 的线性增加。
线性趋势可能表明网络容量的增加没有得到足够的训练时间来拟合数据。可能还需要增加训练轮数。
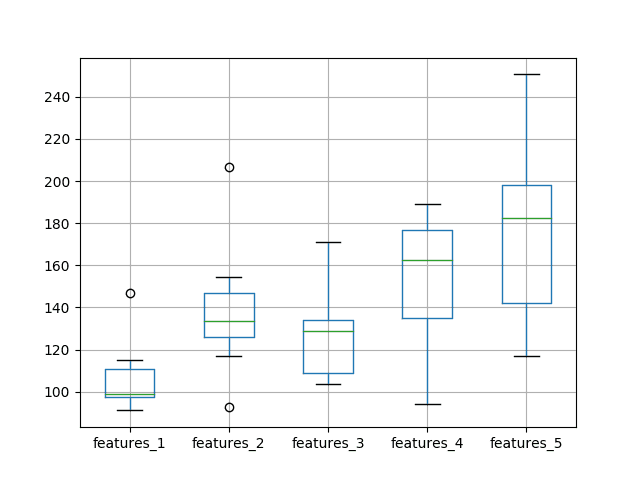
测试 RMSE 与神经元数量和输入特征数量的箱线图
特征和神经元实验:更多轮数
在本节中,我们重复上述实验,以增加神经元数量和特征数量,但将训练轮数从 500 增加到 1000。
这可以通过修改实验函数中的一行来实现:
|
1 |
lstm_model = fit_lstm(train_scaled, 1, 500, features, features) |
推广到
|
1 |
lstm_model = fit_lstm(train_scaled, 1, 1000, features, features) |
此外,我们可以通过在文件名中添加“1000”后缀来将结果与上一实验的结果分开,例如,修改:
|
1 |
results.to_csv('experiment_features_1_neurons.csv', index=False) |
推广到
|
1 |
results.to_csv('experiment_features_1_neurons1000.csv', index=False) |
使用这些更改重复相同的 5 个实验。
运行这些实验后,您应该有 5 个结果文件。
- experiment_features_1_neurons1000.csv
- experiment_features_2_neurons1000.csv
- experiment_features_3_neurons1000.csv
- experiment_features_4_neurons1000.csv
- experiment_features_5_neurons1000.csv
与之前的实验一样,我们可以加载结果、计算描述性统计数据并创建箱线图。完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from pandas import DataFrame from pandas import read_csv from matplotlib import pyplot # 加载结果到数据框 filenames = ['experiment_features_1_neurons1000.csv', 'experiment_features_2_neurons1000.csv', 'experiment_features_3_neurons1000.csv','experiment_features_4_neurons1000.csv','experiment_features_5_neurons1000.csv'] results = DataFrame() for name in filenames: results[name[11:-16]] = read_csv(name, header=0) # 总结所有结果 print(results.describe()) # 箱线图 results.boxplot() pyplot.show() |
运行代码后,首先会打印出 5 个实验的描述性统计数据。
注意:由于算法或评估程序的随机性质,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
结果显示与之前训练轮数减半的实验非常相似。平均而言,具有 1 个输入特征和 1 个神经元的模型优于其他配置。
|
1 2 3 4 5 6 7 8 9 |
features_1 features_2 features_3 features_4 features_5 count 10.000000 10.000000 10.000000 10.000000 10.000000 均值 109.262674 158.295172 120.340623 149.741882 201.992209 标准差 13.850525 32.288109 45.219564 53.121113 82.986691 最小值 95.927393 111.936394 83.983325 111.017837 78.040385 25% 98.754253 130.875314 95.198556 122.287208 148.840499 50% 103.990988 167.915523 110.256517 129.552084 188.498836 75% 116.055435 180.679252 122.158321 154.283676 234.519359 最大值 133.270446 204.260072 242.186747 288.907803 335.595974 |
还创建了箱线图来比较分布。在该图中,我们看到了与描述性统计中清晰可见的相同趋势。
至少在此问题和选定的 LSTM 配置上,我们没有看到增加输入特征数量有任何明显的好处。
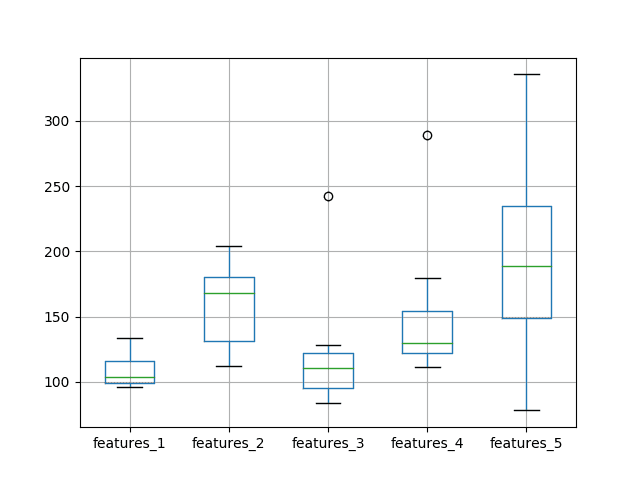
测试 RMSE 与神经元数量、输入特征数量和 1000 轮数的箱线图
扩展
本节列出了一些您可能考虑探索的进一步研究领域。
- 诊断运行图。回顾给定实验的多次运行的训练和测试 RMSE 图可能很有帮助。这可能有助于区分是否发生了过拟合或欠拟合,进而找出解决这些问题的方法。
- 增加重复次数。使用 10 次重复会产生相对较小的测试 RMSE 结果总体。将重复次数增加到 30 或 100(甚至更高)可能会产生更稳定的结果。
您是否探索过这些扩展?
在下面的评论中分享您的发现;我很想听听您的发现。
总结
在本教程中,您了解了如何在 LSTM 网络中使用滞后观测值作为输入特征。
具体来说,你学到了:
- 如何为使用 LSTM 进行输入表示的实验开发健壮的测试工具。
- 如何使用滞后观测值作为输入特征,通过 LSTM 进行时间序列预测。
- 如何通过增加输入特征来提高网络的学习能力。
您发现,“使用滞后观测值作为输入特征可以提高模型技能”的预期并未降低所选问题和 LSTM 配置的测试 RMSE。
你有什么问题吗?
请在下方评论中提问,我将尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。






使用多个特征时,状态式模型是否与具有时间步长的无状态模型相同?您可以在状态式模型中使用具有多个特征的时间步长吗?
这真的取决于您如何构建数据。
批次中所有数据的无状态模式,或者批次中样本内的所有时间步长,与状态式模式相同。
希望这能让事情更清楚。另请参阅此文章
https://machinelearning.org.cn/stateful-stateless-lstm-time-series-forecasting-python/
你好,Jason Brownlee 博士。我混淆了 Keras LSTM 输入中的 time_steps 和 features 的区别。你能举例说明吗?
很好的问题。
时间步长是网络将从中学习的过去观测值(例如,通过时间反向传播)。我将在博客上发表几篇关于 BPTT 的文章。
特征是在给定时间步长下进行的测量(例如,压力和温度)。
这有帮助吗?
感谢 Jason Brownlee 博士的回复。
那么,我们可以将时间步长和特征视为 LSTM 的两种输入吗?
对于多维输入,输入层只有一个神经元,它真的有效吗?LSTM 的输入层神经元数量是否需要与输入维度(时间步长维度 + 特征维度)相同,就像传统的 BP 神经网络一样?
不,输入层中的内存单元数量不必与输入特征或时间步长的数量匹配。
查看代码,您似乎将数据塑造成输入(X 变量)的方式如下:
X = X.reshape(X.shape[0], 1, X.shape[1])
但是,如果您将一个多月销售额作为输入,难道不应该增加时间步长数量,并将特征数量保持为 1(仅分析销售额,不分析其他特征)吗?
我在哪里错了?
好问题,这将有助于理解 LSTM 输入数据的形状。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
与 AR、MA 和 ARIMA 等传统方法相比,LSTM 在时间序列预测中的优势是什么?
很好的问题。
LSTM 的优势在于(我有一个关于此的计划帖子)它们可以学习时间依赖性。您只需输入序列,无需指定所需窗口/滞后(例如,ACF/PACF 分析的结果)。
除了 LSTM 不需要指定所需窗口/滞后之外,LSTM 的预测精度是否优于 ARIMA,或者 LSTM 是否因其特殊的模型结构和深度层而优于其他传统方法?
这可能取决于具体问题(例如,没有免费午餐)。
谢谢 Jason,又一篇结构清晰的博文。我正在从这一系列关于使用序列模型进行时间序列预测的文章中学习很多。我有两个问题:
1) 增加网络层数(加深)会对网络产生什么影响?更具体地说,您如何决定何时增加神经元数量以及何时加深网络(增加层数)?
2) 这可能是一个广泛的问题,但对于时间序列预测,您认为“多大”的数据才算“足够好”?如果一个问题的时间序列数据较少,是否可以从另一个 LSTM 进行迁移学习?
期待您的回复!
更多的层意味着更多的分层表示能力,但训练速度更慢,并且可能更容易过拟合。在您的项目上尝试不同的配置。
只要您能获得的数据。
您可能可以进行迁移学习,我还没有读到关于 LSTM 时间序列迁移学习的任何内容。
嗨,Jason,
感谢您出色的帖子。
我是深度学习和 LSTM 的新手。我有一个非常简单的问题。我取了 50 个时间步长的需求样本,并尝试使用该样本预测未来 10 个时间步长的需求值来训练模型。
但不幸的是,我最接近的是将需求样本划分为 67% 的训练集和 33% 的测试集,我的预测只能预测这 33%。有人能帮助我解决这个问题吗?
我借用了您的代码并将其放在 GitHub 上,并解释了这个问题。
先谢谢您了。
https://github.com/ukeshchawal/hello-world/blob/master/trial.ipynb
请参阅此帖子,了解评估时间序列预测方法的方法。
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
嗨,Jason,
非常感谢您提供的这些非常有帮助的文章!
我有一个关于滚动预测方法的问题。为什么您不在每个时间步长之后重新拟合 LSTM 模型?
我之所以认为您不仅会使用新时间步长中最新的 x 数据进行预测,还会重新训练模型以包含直到该点为止的所有观测值,是因为权重的权重/参数本身存在不稳定性,这值得一个“向前滚动”的模型,而不仅仅是提供最新的 x 数据。
这将产生计算时间成本。
我是否正确地考虑了这个问题?重新拟合大量模型,简单地因为 1. 我们希望参数/权重没有那么不稳定,以至于会产生实质性差异,以及 2. 时间成本?
谢谢!
您可以这样做,我建议您测试一下,看看它是否能提高技能。
这里有一个例子
https://machinelearning.org.cn/update-lstm-networks-training-time-series-forecasting/
嗨 Jason,我通常不评论这些,但我绝对喜欢您的代码结构!毫无疑问,我将来会使用这种函数式方法——调试似乎会痛苦得多。
我是一个新手,刚构建了我的第一个用于股票预测的 LSTM 模型作为练习,并在这里找到了解决问题的方法。我正在使用多个特征,包括开盘价、最高价、最低价和交易量来预测收盘价。我发现,无论我如何调整超参数,我的预测总是“滞后”于实际值,类似于正弦波相位不同。这是您在 LSTM 时间序列预测中见过的问题吗?也许与单元的记忆有关?
谢谢 Ayush!
是的,LSTM 在这种类型的问题上表现不佳。我建议使用 MLP。
嗨 Jason,我想知道您为什么推荐 MLP 而不是 LSTM?
通常 LSTM 在时间序列预测方面表现不佳。我发现 MLP 和 CNN 通常表现更好。
嗨,Jason,
非常有用的文章,谢谢!我有一个关于 fit_lstm 函数中输入数量的问题。在代码的主体中,此函数接受 4 个输入值,但在“Experiments with Features and Neurons More Epochs”部分,fit_lstm 函数的输入数量(从 4 变为 5)有所改变。能否提供有关此更改的一些详细信息?
我不记得了。您能指出您指的是哪个具体的代码更改吗?
嗨,Jason,
感谢您提供的精彩文章。我试图找出是否有可能在 LSTM 模型中找到特征重要性(哪些特征最重要?),但我无法从 Keras 的 LSTM 模型中找到。这可能吗?
抱歉,我没有见过 LSTM 的特征重要性度量。或许可以尝试在 scholar.google.com 上搜索?
嗨 Jason,我们不能像您在“回归数据特征选择”一文中所述的那样,将相关性特征选择和互信息特征选择等方法用于 LSTM 吗?
或许可以尝试一下。
你好,Jason。
我是时间序列 LSTM 的新手,我有一个具体问题,但找不到好的资料。
我有许多轴承温度的实例。(大约 500 个轴承)。目标是找到轴承出现问题时的趋势。那么,我可以用许多实例来训练我的 LSTM 吗?
每个轴承之间的温度变量几乎相同,但是当轴承出现问题时,温度会呈现出某种趋势。
您知道什么好的文章吗?
这听起来像一个好项目。
通常我建议通过这个过程来解决您的问题。
https://machinelearning.org.cn/start-here/#process
也许关于时间序列预测的这些资料会有帮助。
https://machinelearning.org.cn/start-here/#timeseries
你好 Jason。我运行了一个类似的实验
– 我有两年的每日支出数据,我对其进行了对数转换。
– 我还使用滚动向前验证,但预测多个天。
– 我运行 2 个场景
1. 一个简单的场景:我只使用我正在预测的变量(金额)的 200 个滞后值作为输入;
2. 一个更复杂的场景:我在输入中添加了 1 个数值特征和 6 个分类特征,例如节假日(1/0)、周末(1/0)、年份、月份、日期等。我将每个原始分类特征转换为 n-1 个虚拟变量,最后向网络输入总共 47 个特征,长度为 200(滞后数量)。
– 我的训练集包含 300 个样本(行),而验证集包含 60 个样本;
在复杂的场景中,输入量很大,训练速度很慢。因此,我很难尝试不同的参数(轮数、层数、输入节点)并得出最优模型。我想知道您会立即建议我进行哪些实验/更改。例如,增加更多的输入节点(目前设置为 1000),增加更多的层,减少滞后数量从而增加样本数量。我主要被特征数量与样本数量的比率所困扰,并且增加额外的特征对于如此少的样本是否是多余的?
这是一个棘手的问题。
我尝试用小样本来调整模型,然后再扩大规模。试试这个。
当我认真思考某个预测问题时,这里的各种建议似乎能提供最大的帮助。
我这里也有很多建议,希望能给您一些灵感。
https://machinelearning.org.cn/improve-deep-learning-performance/
您好!希望您一切安好!我非常欣赏您的文章!
我看了您关于滚动向前交叉验证的文章:https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
我想我明白了。
1. 将训练集大小增加 1,然后与下一个进行比较。
您提到需要固定最小观测值,在上面的链接中您固定为 500 作为第一个训练集大小。那么训练集的大小将是 500、501、502、503、……len(data)-1。
那么,据我理解,在滚动(增加训练集大小)时,或者每次滚动时,我们是更新模型?还是只记录误差?
但是,我没有看到您在这里使用任何滚动向前 CV 和最小观测值的部分……或者,是我错过了什么?
您固定“最小观测值”并在此更新模型的部分在哪里?
非常感谢!
在许多神经网络的情况下,我不会每次滚动向前都更新模型,因为计算成本太高。
嗨 Jason。我想知道将滞后值作为额外特征(如本教程中所用)与使用时间步长添加滞后值有什么区别。
基本上,对于每个样本,都有 #lags 时间步长,其中包含 1 个特征:滞后的 y 值(在 x、x-1、x-2 等处)。
我很确定我见过使用第二种方法的例子,但我找不到任何关于此的解释/比较。
希望你能回答这个!
关键是 BPTT 在时间步长上运行。
这是从序列中学习与学习静态输入/输出映射之间的区别。
这篇文章可能会有帮助
https://machinelearning.org.cn/gentle-introduction-backpropagation-time/
嗨 Jason,当滞后作为额外的特征时,是否也可以使用滞后时间步长是正确的,比如说每个样本是 L x F,其中 L 是每个 F 个输入特征中的滞后时间步长 (t, t-1, …, t-L)?除一个特征外,其余特征都是单变量输入序列的滞后版本。
嗨,Jason,
鉴于数据集中,数据集具有很高的时间变化和季节性。
比如说,每隔 3、6、7、8、9 个月,会持续一周出现非常高的值,
其他月份的值较低(峰值)。
我能够捕捉到低峰值,但无法捕捉到高峰值。
具体来说,我正在尝试为河流流量建模。当降雨量高时,河流流量就高……其他时候它们都保持较低的水平……我不确定如何捕捉高峰信号。
也许你可以将观测值分为高/低流量,然后为这些情况开发单独的模型?
感谢分享。我想知道您是否有关于无监督方法——自编码器处理类似格式数据的教程?
不客气。
是的,请看这个
https://machinelearning.org.cn/lstm-autoencoders/
我正在处理网格工作负载存档数据集,在预测进来的作业等待时间时,如何考虑输入变量来预测输出变量?我确实有请求时间、平均 CPU 使用率和一些属性,LSTM 能训练输入变量来给出输出变量吗?
是的,也许从这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
布朗利博士,您好!
感谢您又一篇详细的博文,您的博文非常有帮助。
关于增加单变量数据预测的输入时间步长对于 LSTM 的理论有效性,我有一个问题,所有的历史时间步长不都是通过 LSTM 的结构自动向前传递吗?
背景知识
我正在比较几种用于小时用水量预测的方法,与洗发水数据不同,小时用水量数据更长,并且数据本身具有很强的周期性。
当输入时间步长等于或大于数据周期(24 小时)时,神经网络和随机预测都表现良好,我最初也这样认为 LSTM,但根据我的有限理解,历史特征会自动传递到所有块中,从而减少了重复特征的需要;然而,我的工作发现,将输入时间步长增加到 24 可以极大地提高预测精度,这与神经网络和随机预测类似。
我从您 2016 年的一篇博文(使用 Keras 的 LSTM 循环神经网络进行时间序列预测)开始学习 LSTM,我已经修改了它的结构以支持多输入和多输出,我现在正在根据这篇博文的代码重新确认我之前的结果。
不客气。
理论不会有帮助——我建议设计受控实验,以发现最适合您特定数据集和模型的方法。
布朗利博士,您好!
感谢您的博文,我感到困惑,不理解您的第二个图,以及如何识别增加特征时误差(在测试 RMSE 中)不会减少。
我们可以看到 RMSE 没有降低,因为随着特征数量的增加,分布和中位数会升高。
嗨 Jason,我是 LSTM 的新手,我一直在阅读您的另一篇博文
Python 时间序列预测的特征选择
https://machinelearning.org.cn/feature-selection-time-series-forecasting-python/
您提到“通常我们不会选择滞后观测值作为 LSTM 的时间步长,而是提供所有时间步长,让 LSTM 学习使用哪些来做出好的预测。”以及“它对于线性模型和开发静态机器学习模型(非 LSTM)很有用。”
所以在我完全理解这篇博文之前,我将非常感谢您的评论,以帮助我理解这 2 篇博文“如何使用滞后观测值作为 LSTM 时间序列预测的输入特征”。谢谢!
好问题,这很有帮助。
https://machinelearning.org.cn/time-series-forecasting-supervised-learning/
嗨 Jason,很棒的作品。我只是想知道一件事。在一篇文章中,您将监督学习的输出用作时间步长,而在本文中,您将该输出用作特征,这两者之间的确切区别是什么?这让我感觉时间步长和特征是可以互换的。