使用Weka平台的一大好处是支持大量的机器学习算法。
您在解决问题时尝试的算法越多,您对问题的了解就越多,并且越有可能发现一个或几个表现最佳的算法。
在这篇文章中,您将了解Weka支持的机器学习算法。
阅读本文后,您将了解
- Weka中支持的不同类型的机器学习算法和值得尝试的关键算法。
- 如何在Weka中配置算法以及如何保存和加载良好的算法配置。
- 如何了解更多关于Weka支持的机器学习算法。
通过我的新书《Weka机器学习精通》开启您的项目,其中包括所有示例的分步教程和清晰的屏幕截图。
让我们开始吧。

如何在 Weka 中使用机器学习算法
图片来源:Eugeniy Golovko,保留部分权利。
Weka机器学习算法
Weka拥有大量的机器学习算法。这非常棒,是使用Weka作为机器学习平台的一大优势。
缺点是,知道何时使用哪个算法可能会有点让人不知所措。此外,这些算法的名称可能对您来说不熟悉,即使您在其他语境中知道它们。
在本节中,我们将首先介绍Weka支持的一些知名算法。我们在这篇文章中学习的内容适用于整个Weka平台中使用的机器学习算法,但Explorer是了解更多算法的最佳场所,因为它们都集中在一个易于访问的地方。
- 打开Weka GUI选择器。
- 单击“Explorer”按钮打开Weka资源管理器。
- 打开一个数据集,例如Weka安装中data/diabetes.arff文件中的Pima Indians数据集。
- 点击“Classify”打开分类选项卡。
Explorer的“Classify”选项卡是您可以了解各种不同算法并探索预测建模的地方。
您可以通过单击“Choose”按钮选择一个机器学习算法。
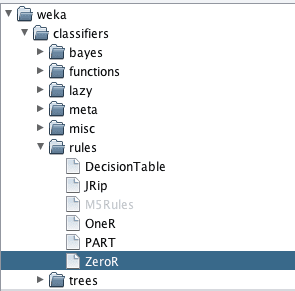
Weka选择机器学习算法
点击“Choose”按钮后,会弹出一个机器学习算法列表供您选择。它们被分为几个主要组别:
- bayes:以某种核心方式使用贝叶斯定理的算法,如朴素贝叶斯。
- function:估计函数的算法,如线性回归。
- lazy:使用惰性学习的算法,如k-近邻。
- meta:使用或组合多个算法的算法,如集成学习。
- misc:不完全符合其他组的实现,例如运行已保存的模型。
- rules:使用规则的算法,如One Rule。
- trees:使用决策树的算法,如随机森林。
该选项卡名为“Classify”,算法列在一个名为“Classifiers”的总组下。然而,Weka同时支持分类(预测类别)和回归(预测数值)预测建模问题。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
您正在处理的问题类型由您希望预测的变量定义。在“Classify”选项卡上,这在测试选项下方选择。默认情况下,Weka选择数据集中最后一个属性。如果该属性是名义的,那么Weka假定您正在处理分类问题。如果该属性是数值的,Weka假定您正在处理回归问题。

Weka选择要预测的输出属性
这很重要,因为您正在处理的问题类型决定了您可以使用的算法。例如,如果您正在处理分类问题,则不能使用线性回归等回归算法。另一方面,如果您正在处理回归问题,则不能使用逻辑回归等分类算法。
请注意,如果您对“回归”这个词感到困惑,没关系。它令人困惑。回归是统计学中的一个历史词。它曾经指为数值输出(进行回归)创建模型。现在它既指一些算法的名称,也指预测数值。
Weka将把您所选问题不支持的算法灰显。许多机器学习算法可以用于分类和回归。因此,无论您选择哪种问题,您都可以访问大量的算法。
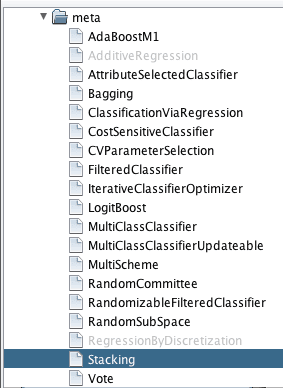
Weka算法不适用于某些问题类型
使用哪种算法
通常,在处理机器学习问题时,您无法事先知道哪种算法最适合您的问题。
如果您有足够的信息来知道哪种算法能达到最佳性能,您可能就不会做应用机器学习了。您会做其他事情,比如统计学。
因此,解决方案是在您的问题上尝试一系列算法,看看哪种效果最好。尝试少数强大的算法,然后加倍投入表现最佳的1到3种算法。它们将为您提供关于哪些一般类型的算法表现良好,或者哪些学习策略可能优于平均水平,能够更好地发现数据中的隐藏结构。
Weka中的一些机器学习算法具有非标准名称。您可能已经知道一些机器学习算法的名称,但对Weka中算法的名称感到困惑。
下面列出了10种您应该考虑在您的问题上尝试的顶级机器学习算法,包括它们的标准名称和Weka中使用的名称。
线性机器学习算法
线性算法假设预测属性是输入属性的线性组合。
- 线性回归:function.LinearRegression
- 逻辑回归:function.Logistic
非线性机器学习算法
非线性算法对输入属性和要预测的输出属性之间的关系没有强烈的假设。
- 朴素贝叶斯:bayes.NaiveBayes
- 决策树(特别是C4.5变种):trees.J48
- k-近邻(也称为KNN):lazy.IBk
- 支持向量机(也称为SVM):functions.SMO
- 神经网络:functions.MultilayerPerceptron
集成机器学习算法
集成方法结合来自多个模型的预测,以做出更稳健的预测。
- 随机森林:trees.RandomForest
- Bootstrap Aggregation(也称为Bagging):meta.Bagging
- 堆叠泛化(也称为Stacking或Blending):meta.Stacking
Weka拥有广泛的集成方法,也许是所有流行机器学习框架中可用的最大集合之一。
如果您正在寻找一个利用Weka的专业领域,除了易用性之外,该平台真正的力量来源,我会指出对集成技术的支持。
机器学习算法配置
一旦您选择了一个机器学习算法,就可以对其进行配置。
配置是可选的,但强烈建议。Weka巧妙地为每个机器学习算法选择了合理的默认值,这意味着您可以选择一个算法并立即开始使用它,而无需对其了解太多。
要从算法中获得最佳结果,您应该将其配置为最适合您的问题。
您如何为自己的问题配置算法?
同样,这也是一个悬而未决的问题,无法事先知道。虽然算法确实有一些启发式方法可以指导您,但它们并非万灵药。真正的答案是系统地测试给定算法在您问题上的一系列标准配置。
在Weka中,您可以通过点击所选机器学习算法的名称来配置它。这将弹出一个窗口,显示算法的所有配置详情。
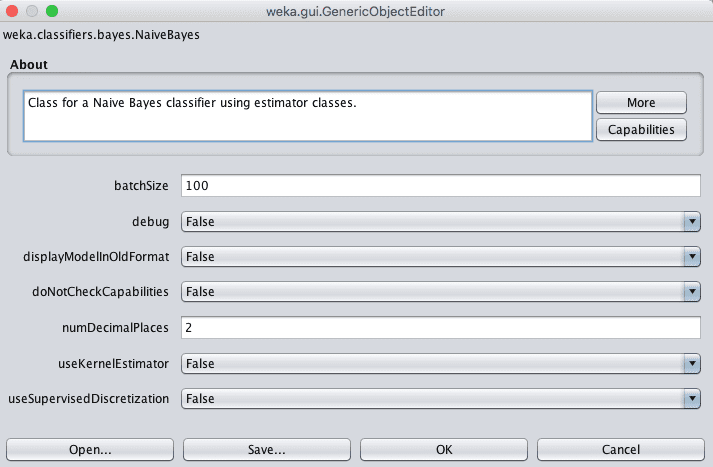
Weka配置机器学习算法
将鼠标悬停在每个选项上,会显示一个描述配置选项的工具提示,从而了解更多关于每个配置选项的含义。
有些选项提供了有限的值集供您选择,其他选项则接受整数或实数值。尝试通过实验和研究,为您的算法在您的问题上得出3到5个标准配置。
一个专业提示是,您可以将标准算法配置保存到文件中。点击算法配置底部的“保存”按钮。输入一个清楚标明算法名称和您正在保存的配置类型的文件名。您可以在Weka Explorer、Experimenter以及Weka的其他地方稍后加载算法配置。当您确定了一套希望在不同问题上重复使用的标准算法配置时,这尤其有价值。
您可以通过点击算法配置窗口上的“OK”按钮来采纳并使用该算法的配置。
获取更多算法信息
Weka提供了关于每个支持的机器学习算法的更多信息。
在算法配置窗口上,您会注意到两个按钮可以了解更多关于算法的信息。
更多信息
点击“更多”按钮将显示一个窗口,其中总结了算法的实现和所有算法配置属性。

Weka关于算法的更多信息
这对于更全面地了解算法的工作原理以及如何配置它非常有用。它还经常包含对算法实现所依据的书籍或论文的引用。这些是很好的资源,可以追踪和查阅,以便更好地了解如何从给定算法中获得最大收益。
作为初学者,查阅如何更好地配置算法并非易事,因为它可能会让人感到有些不知所措,但这是一个专业技巧,当您对应用机器学习有了更多经验后,它将帮助您更快地学习更多知识。
算法能力
点击“Capabilities”按钮,将为您提供算法能力的概览。
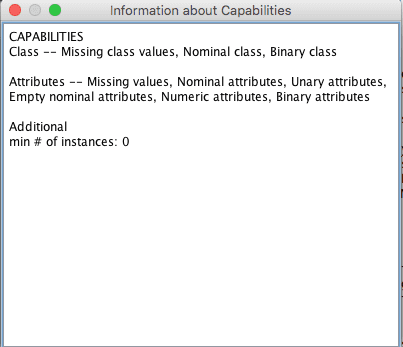
Weka算法能力
最重要的是,这对于了解算法如何处理缺失数据以及它可能对您的问题提出的任何其他重要期望很有用。
审查这些信息可以为您提供关于如何创建新的和不同的数据视图,以提高一个或多个算法性能的思路。
总结
在这篇文章中,您了解了Weka机器学习工作台中对机器学习算法的支持。
具体来说,你学到了:
- Weka为分类和回归问题提供了大量的机器学习算法可供选择。
- 您可以轻松配置每个机器学习算法,并保存和加载一组标准配置。
- 您可以深入了解给定算法的细节,甚至发现其来源,以便学习如何获得最佳性能。
您对Weka中的机器学习算法或此文章有任何疑问吗?请在评论中提问,我将尽力回答。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






谢谢你
不客气。
为什么Weka中的天气预测只使用J48、REP树、随机树等算法?
你可以使用任何你想要的算法。
嗨,Jason,
非常感谢您分享这些信息。
请问,我对人工智能很感兴趣。我拥有运筹学和IT背景,并且在计算应用领域工作了几年。
我希望能与您联系,寻求专业建议
一个好的入门点可能在这里
https://machinelearning.org.cn/start-here/#getstarted
先生,请问我可以开发或编写自己的算法在WEKA中实现,而不是使用WEKA软件自带的算法吗?另外,是否可以修改WEKA内置的算法?
是的,你可以在Weka中实现自己的算法并修改现有算法。
抱歉,我没有教程来演示如何做到这一点。
我们有什么方法可以了解算法是如何工作的,例如查找准确度。它们何时知道何时停止?所有算法都有深入的文档吗?
很好的问题!
通常,我们通过指定停止条件来结束训练,例如固定的迭代次数或训练或验证数据集上模型技能的改进变化。
嗨 Jason
Bayes.BayesNet会属于非线性机器学习算法吗?…类似于非线性算法朴素贝叶斯?
它是线性的。
嗨,Jason,
我正在进行Web服务安全项目(基于REST),我如何获取数据集以进行机器学习训练。
我不确定我是否理解,您是问如何通过REST使用Weka吗?我不知道。
为了网络服务安全,我正在使用机器学习构建入侵检测系统,为此我需要数据集。所以,我不知道从哪里获取!
不,抱歉,也许可以尝试一些谷歌搜索?
您可以从data.world、big ml或kaggle获取
如果概括地说Weka中哪些算法最能体现AI的各个流派概念,它是否主要取决于传入数据状态?是否有某些算法明显属于某个流派,例如,朴素贝叶斯显然被贝叶斯流派使用……?
提前感谢
是的,Weka的算法组织方式在这方面做得很好。
我安装了WEKA,但看不到任何数据集可供打开。无法继续。
我在这里展示了如何单独下载数据集
https://machinelearning.org.cn/download-install-weka-machine-learning-workbench/
我很难将三个服务器的CPU和内存利用率数据用于训练和预测。您能帮我一下如何操作吗?
谢谢
也许这个框架会有帮助
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
如何在weka中使用AAAlgo算法
什么是“AAAlgo”?
您好,先生,我想开发或修改基于神经网络的现有算法,先生,我可以在Java中编写代码并在Weka中运行它吗?如果可以,您能告诉我具体步骤吗?我还很困惑是选择Weka还是Python。请给我一些建议,先生。
抱歉,我没有关于这个主题的教程。
你好
感谢您分享的信息,这对我初步研究机器学习算法有很大帮助。我将在大学的一个项目中使用Weka,我将分析各种网络流量,从轻度到重度的正常使用,再到轻度到重度的恶意使用。分析所有数据集的差异,以推断出常见的趋势,试图勾勒出潜在的IDS可以从中学习的地方。
对我的研究有哪些算法是最佳推荐的?
感谢您的时间。
不客气。
是的,也许可以遵循这个过程
https://machinelearning.org.cn/start-here/#process
你好,
如何使用您的工具中的图形模型,例如CRF和HMM
我没有关于这些方法的教程,但我希望能将来写一些。
嗨,Jason,
我们可以加载自己的数据集还是只能使用Weka中已有的数据集?
此外,它是否具有数据清理功能?
感谢您的回复,并感谢您所有富有洞察力的文章。
问候
是的,您可以加载自己的数据集
https://machinelearning.org.cn/load-csv-machine-learning-data-weka/
是的,Weka提供用于数据清理的数据转换,也许可以从这里开始
https://machinelearning.org.cn/start-here/#weka
嗨 Jason,感谢您的出色工作。我能对结果部分进行更多解释吗?例如,如果我有一个低于节点的节点,算法会是什么样子。
Sigmoid 节点 1
输入权重
阈值 -6.9928483131703745
属性 温度 5.821816668231223
属性 pH 值 1.5059966471679669
属性 电导率 1.9145713932268624
属性 浊度 -4.70465564011304
属性 UV245 -0.7809926826308812
抱歉,这与帖子不太相关。您能详细说明一下吗?