Weka平台上有大量的回归算法。
Weka支持的机器学习算法数量庞大,是使用该平台的最大优势之一。
在这篇文章中,您将学习如何在Weka中使用顶级回归机器学习算法。
阅读本文后,您将了解
- 关于Weka支持的5种顶级回归算法。
- 如何在Weka中使用回归机器学习算法进行预测建模。
- 关于Weka中回归算法的关键配置选项。
通过我的新书《Weka机器学习精通》启动您的项目,包括所有示例的分步教程和清晰的截图。
让我们开始吧。

如何在 Weka 中使用回归机器学习算法
图片来自 solarisgirl,保留部分权利。
回归算法概述
我们将介绍Weka中的5种顶级回归算法。
我们将简要介绍每种算法的工作原理,突出关键算法参数,并在Weka Explorer界面中演示该算法。
我们将回顾的5种算法是
- 线性回归
- k-近邻
- 决策树
- 支持向量机
- 多层感知器
这些是您可以作为起点应用于回归问题的5种算法。
我们将使用一个标准的机器学习回归问题来演示每种算法。
具体来说,是波士顿房价数据集。每个实例描述了波士顿郊区的属性,任务是预测以千美元计的房价。有13个数值输入变量,具有不同的尺度,描述了郊区的属性。您可以在UCI机器学习存储库上了解更多关于此数据集的信息。
启动Weka Explorer
- 打开Weka GUI选择器。
- 点击“Explorer”按钮打开Weka Explorer。
- 从housing.arff文件中加载波士顿房价数据集。
- 点击“Classify”打开分类选项卡。
让我们从线性回归算法开始。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
线性回归
线性回归只支持回归类型问题。
它的工作原理是估计一条直线或超平面的系数,使其最适合训练数据。它是一种非常简单的回归算法,训练速度快,如果数据的输出变量是输入的线性组合,则可以获得很好的性能。
在转向更复杂的算法之前,最好先评估一下线性回归在您的特定问题上的表现,以防它表现良好。
选择线性回归算法
- 点击“Choose”按钮,在“functions”组下选择“LinearRegression”。
- 点击算法名称以查看算法配置。
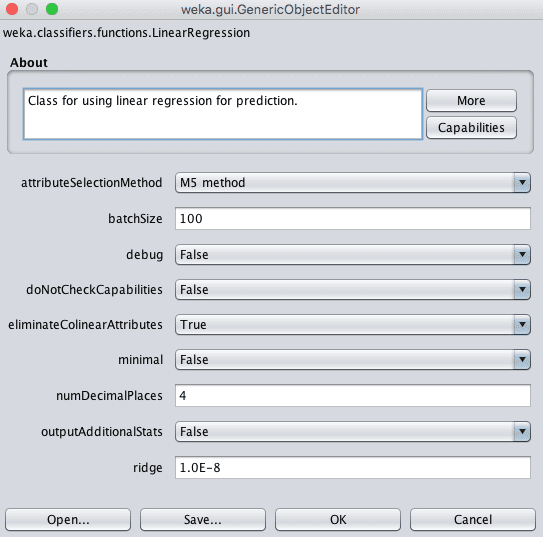
Weka线性回归配置
如果您的训练数据具有高度相关的输入属性,线性回归的性能可能会降低。Weka可以通过将eliminateColinearAttributes设置为True(默认值)来自动检测和删除高度相关的输入属性。
此外,与输出变量无关的属性也可能对性能产生负面影响。Weka可以通过设置attributeSelectionMethod来自动执行特征选择,仅选择那些相关属性。此功能默认启用,也可以禁用。
最后,Weka实现使用岭正则化技术来降低学习模型的复杂性。它通过最小化学习系数的绝对和的平方来实现这一点,这将防止任何特定系数变得过大(回归模型中复杂性的标志)。
- 点击“OK”关闭算法配置。
- 点击“Start”按钮,在波士顿房价数据集上运行算法。
您可以看到,在线性回归的默认配置下,RMSE达到了4.9。
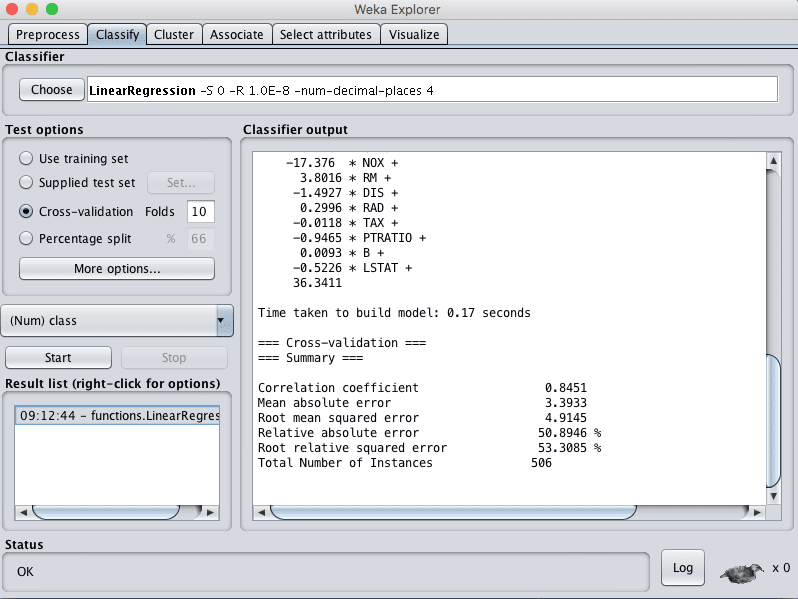
Weka线性回归结果
k-近邻
k-近邻算法支持分类和回归。它也简称为kNN。它的工作原理是存储整个训练数据集,并在进行预测时查询它以找到k个最相似的训练模式。
因此,除了原始训练数据集外,没有其他模型,并且在请求预测时,唯一执行的计算是查询训练数据集。
它是一种简单的算法,但除了数据实例之间的距离在做出预测时有意义之外,它对问题没有太多假设。因此,它通常能取得非常好的性能。
在对回归问题进行预测时,KNN将取训练数据集中k个最相似实例的平均值。选择KNN算法
- 点击“Choose”按钮,在“lazy”组下选择“IBk”。
- 点击算法名称以查看算法配置。
在Weka中,KNN被称为IBk,代表基于实例的k。
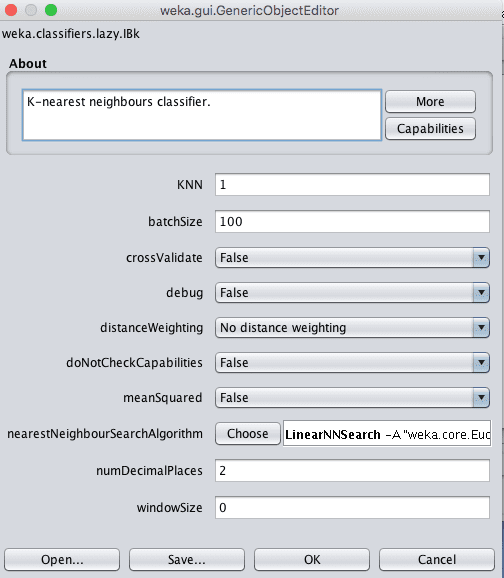
Weka k-近邻配置
邻域的大小由k参数控制。例如,如果设置为1,则预测是使用与给定新模式(请求预测)最相似的单个训练实例进行的。k的常见值是3、7、11和21,对于更大的数据集,值更大。Weka可以通过将crossValidate参数设置为True,在算法内部使用交叉验证自动发现一个好的k值。
另一个重要参数是使用的距离度量。这在nearestNeighbourSearchAlgorithm中配置,它控制训练数据的存储和搜索方式。默认是LinearNNSearch。点击此搜索算法的名称将提供另一个配置窗口,您可以在其中选择一个distanceFunction参数。默认情况下,使用欧几里得距离计算实例之间的距离,这对于具有相同尺度的数值数据来说是好的。如果您的属性在度量或类型上有所不同,则曼哈顿距离是一个不错的选择。
最好在您的问题上尝试一系列不同的k值和距离度量,看看哪种效果最好。
- 点击“OK”关闭算法配置。
- 点击“Start”按钮,在波士顿房价数据集上运行算法。
您可以看到,在KNN算法的默认配置下,RMSE达到了4.6。
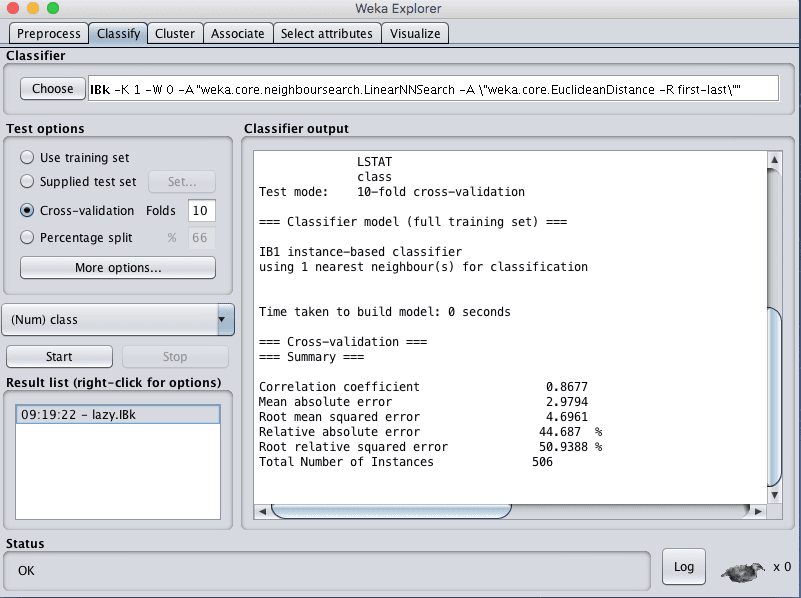
Weka k-近邻算法的回归结果
决策树
决策树可以支持分类和回归问题。
决策树最近被称为分类与回归树(CART)。它们通过创建一棵树来评估数据实例,从树的根部开始,向下移动到叶子(根部,因为树是倒着画的),直到可以做出预测。创建决策树的过程是通过贪婪地选择最佳分割点来做出预测,并重复此过程直到树达到固定深度。
树构建完成后,会进行修剪以提高模型对新数据的泛化能力。
选择决策树算法
- 点击“Choose”按钮,在“trees”组下选择“REPTree”。
- 点击算法名称以查看算法配置。
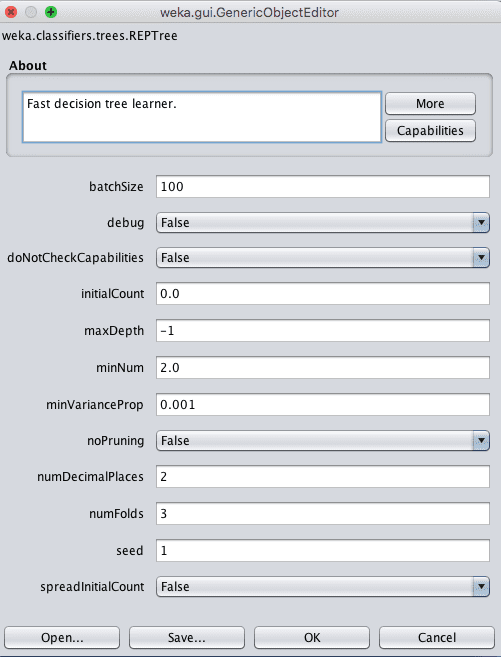
Weka决策树算法配置
树的深度是自动定义的,但可以在maxDepth属性中指定深度。
您还可以选择通过将noPruning参数设置为True来关闭修剪,尽管这可能会导致性能下降。
minNum参数定义了从训练数据构建树时叶节点中树支持的最小实例数。
- 点击“OK”关闭算法配置。
- 点击“Start”按钮,在波士顿房价数据集上运行算法。
您可以看到,在决策树算法的默认配置下,RMSE达到了4.8。
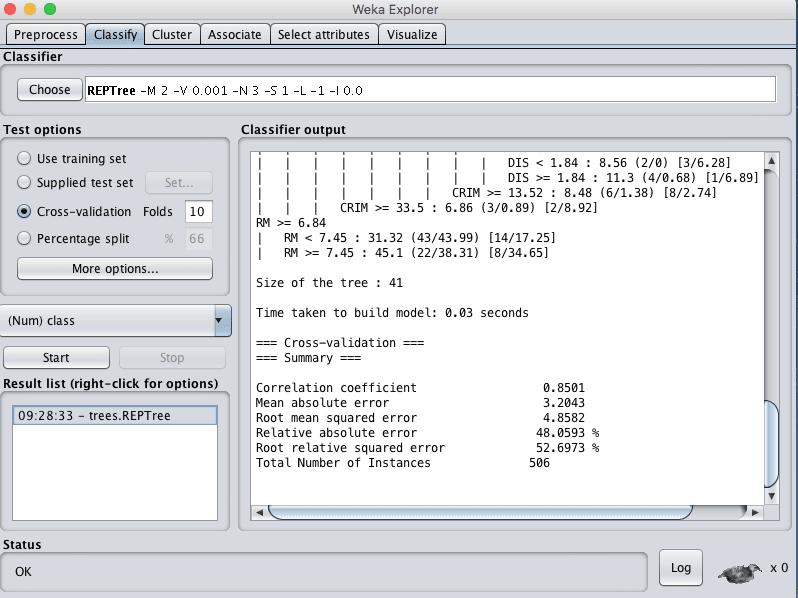
Weka决策树算法的回归结果
支持向量回归
支持向量机最初是为二分类问题开发的,但该技术已扩展以支持多类分类和回归问题。SVM在回归上的应用被称为支持向量回归,简称SVR。
SVM是为数值输入变量开发的,但会自动将标称值转换为数值。输入数据在使用前也会进行归一化。
与SVM寻找一条最佳地将训练数据分成不同类别的线不同,SVR通过寻找一条最佳拟合线来最小化成本函数的误差。这通过一个优化过程完成,该过程只考虑训练数据集中最接近具有最小成本的线的那些数据实例。这些实例被称为支持向量,因此得名该技术。
在几乎所有感兴趣的问题中,无法绘制一条线来最佳拟合数据,因此在直线上添加了一个边距以放松约束,允许容忍一些不良预测,但总体上获得更好的结果。
最后,很少有数据集能用直线拟合。有时需要绘制带曲线甚至多边形区域的线条。这通过将数据投影到更高维空间来绘制线条和进行预测来实现。可以使用不同的核函数来控制投影和灵活性。
选择SVR算法
- 点击“Choose”按钮,在“function”组下选择“SMOreg”。
- 点击算法名称以查看算法配置。
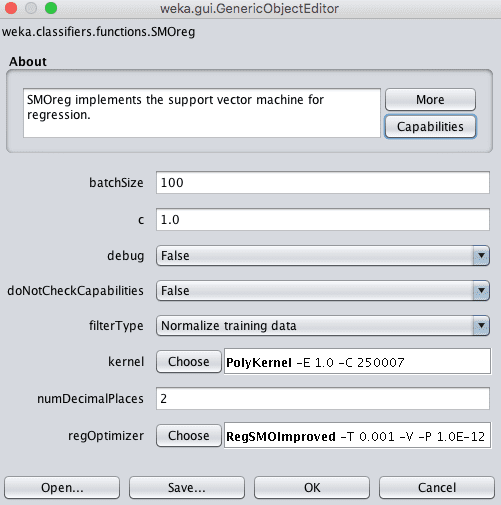
Weka支持向量回归算法配置
Weka中称为复杂性参数的C参数控制绘制拟合数据的线的灵活性。值为0表示不允许违反边距,而默认值为1。
SVM中的一个关键参数是使用的核类型。最简单的核是线性核,它用直线或超平面分离数据。Weka中的默认是多项式核,它将使用曲线或波浪线拟合数据,多项式阶数越高,曲线越波浪(指数值)。
多项式核的默认指数为1,这使其等效于线性核。一个流行且强大的核是RBF核或径向基函数核,它能够学习闭合多边形和复杂形状以拟合训练数据。
最好在您的问题上尝试一系列不同的核函数和C(复杂性)值,看看哪种效果最好。
- 点击“OK”关闭算法配置。
- 点击“Start”按钮,在波士顿房价数据集上运行算法。
您可以看到,在SVR算法的默认配置下,RMSE达到了5.1。
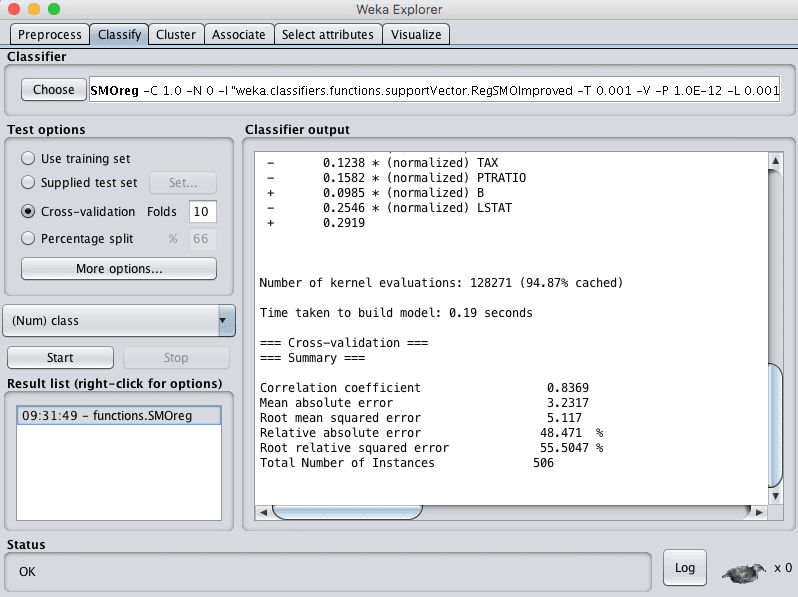
Weka支持向量回归算法的回归结果
多层感知器
多层感知器算法支持回归和分类问题。
它也称为人工神经网络或简称神经网络。
神经网络是一种复杂的预测建模算法,因为有如此多的配置参数,只能通过直觉和大量的试错才能有效地调整。
它是一种受大脑中生物神经网络模型启发的算法,其中称为神经元的小型处理单元组织成层,如果配置得当,能够近似任何函数。在分类中,我们感兴趣的是近似基础函数以最好地区分不同的类别。在回归问题中,我们感兴趣的是近似一个最适合实值输出的函数。
选择多层感知器算法
- 点击“Choose”按钮,在“function”组下选择“MultilayerPerceptron”。
- 点击算法名称以查看算法配置。
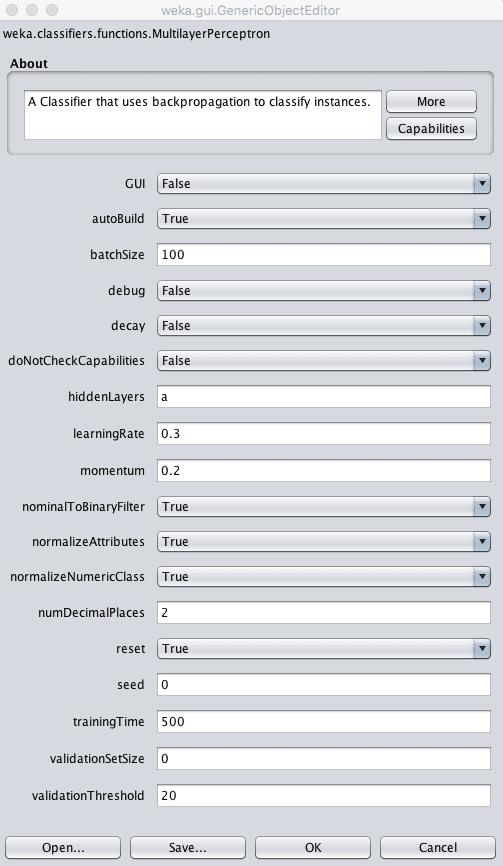
Weka多层感知器算法配置
您可以手动指定模型使用的神经网络结构,但不建议初学者这样做。
默认会自动设计网络并在您的数据集上进行训练。默认会创建一个单隐藏层网络。您可以在hiddenLayers参数中指定隐藏层的数量,默认设置为自动“a”。
您也可以使用图形用户界面(GUI)来设计网络结构。这可能很有趣,但建议您在简单的训练和测试数据集分割下使用GUI,否则您将被要求为交叉验证的10个折叠中的每一个设计网络。
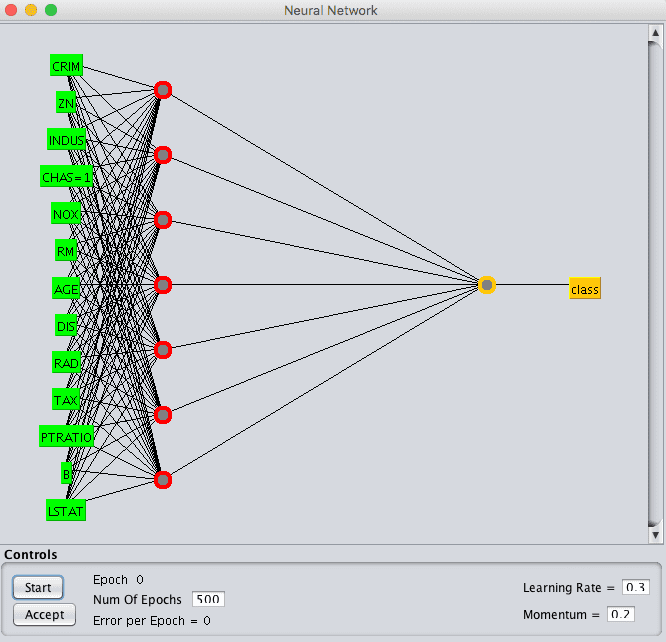
Weka多层感知器算法的GUI设计器
您可以通过设置学习率来配置学习过程,指定每个时期更新模型的程度。常见的值很小,例如0.3(默认值)到0.1之间。
学习过程可以通过动量(默认为0.2)进一步调整,即使不需要进行更改也能继续更新权重,以及衰减(将衰减设置为True),这将随着时间的推移降低学习率,以便在训练开始时进行更多学习,在结束时进行更少学习。
- 点击“OK”关闭算法配置。
- 点击“Start”按钮,在波士顿房价数据集上运行算法。
您可以看到,在多层感知器算法的默认配置下,RMSE达到了4.7。
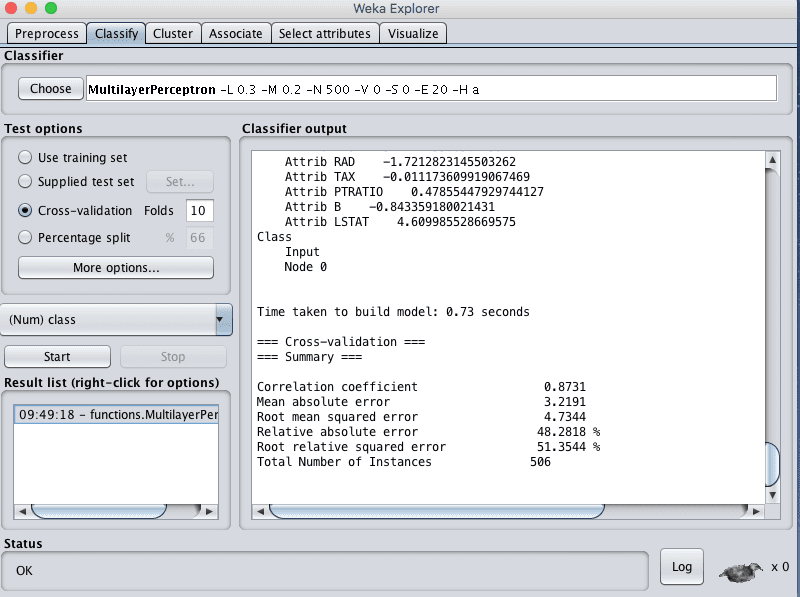
Weka多层感知器算法的回归结果
总结
在这篇文章中,您了解了Weka中的回归算法。
具体来说,你学到了
- 关于可用于预测建模的5种顶级回归算法。
- 如何在Weka中运行回归算法。
- 关于Weka中回归算法的关键配置选项。
您对Weka中的回归算法或本文有任何疑问吗?请在评论中提出您的问题,我将尽力回答。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






嗨,Jason,
非常感谢您在这个网页上的辛勤工作。我真的从您这里学到了很多关于WEKA的知识 😉
我有一个关于输出解释的问题。我们知道,“平均绝对误差”和“均方根误差”的值越低越好,这表明值越好。
然而,在我的情况下,“相对绝对误差”和“均方根相对误差”都大于100%!!!这可能吗?这两个值是否也像MAE/RMSE一样越低越好?
非常感谢
谢谢Allen。
通常,我建议您使用均方根误差(Root Mean Square Error),它是一个众所周知且广泛使用的指标。除非您的问题/领域/等要求,否则不要尝试其他度量。
谢谢您的回复,Jason。
我们能说“相对绝对误差”和“均方根相对误差”不是回归的重要指标吗?或者即使它们大于100%,我们也可以忽略它们吗?
嗨,Jason,
首先,我要感谢您提供这些在线教程。它们对我有很大帮助。
我关于这篇文章的问题是:您怎么能说这些是前5名算法呢?为什么不是其他的呢?您能给出说明/参考文献或其他什么吗?
非常感谢
这些只是我建议应用于一个问题以了解哪些可能有效、哪些可能无效的算法。
拥有多样化的算法类型有助于解决这个问题。
一般来说,我们无法知道哪种算法最适合我们的问题。如果能,我们可能就不需要机器学习了——我们只需解决问题。话虽如此,您对数据了解得越多,就越能想到某种算法类型或表示可能比其他算法更有效——但这只是一些启发式方法。
Jason,有没有办法为多层感知器设置正则化参数?这是一种相当常见的做法,用于确保网络不会过度拟合您的训练数据并能很好地泛化到新数据。我一直在Weka Javadoc的MultilayerPerceptron类的选项中寻找,但我找不到任何东西。有什么想法吗?感谢您撰写这篇文章!
嗨 Dan,
看起来这个实现没有正则化。
线性回归模型
构建模型所需时间:0.04秒
=== 测试集评估 ===
在提供的测试集上测试模型所需时间:0.02秒
=== 总结 ===
相关系数 0.7914
平均绝对误差 0.3449
均方根误差 0.4511
相对绝对误差 53.6479 %
均方根相对误差 61.1281 %
实例总数 84
忽略的未知类别实例 16
请问我该如何解释这些数据?
只需查看RMSE(均方根误差),它与您的输出变量具有相同的尺度。
我不理解您说的RMSE(均方根误差)与您的输出变量具有相同的尺度是什么意思。请问您能进一步解释吗?我是Weka的新手,我需要这个预测用于我的研究工作,谢谢。
您可以在这里了解更多关于RMSE的信息
https://en.wikipedia.org/wiki/Root-mean-square_deviation
谢谢你,伙计,加上数据后我得到了这些。很抱歉打扰你,根据线性回归输出,这个预测可靠吗?
测试模式:在训练数据上评估
=== 分类器模型(完整训练集) ===
线性回归模型
question22a =
0.2423 * qualification +
0.2505 * question5 +
-0.13 * question6 +
-0.1356 * question7 +
-0.1561 * question8a +
-0.0983 * question10a +
0.3403 * question14b +
0.3004 * question16a +
-0.4492 * question16b +
-0.1079 * question17a +
0.1564 * question18a +
-0.1771 * question19b +
-0.2994 * question20b +
0.6329 * question21a +
0.3278 * question22b +
0.5585
构建模型所需时间:0.01秒
=== 在训练集上评估 ===
=== 总结 ===
相关系数 0.8079
平均绝对误差 0.3358
均方根误差 0.4201
相对绝对误差 53.2933 %
均方根相对误差 58.9348 %
实例总数 88
忽略的未知类别实例 12
请查看RMSE(均方根误差),它与您预测的变量具有相同的单位。
一个熟练的RMSE是特定领域相关的,我无法为您回答这个问题。
我可以获得更多关于回归决策树的详细信息吗,例如模型构建、交叉验证和预测。
我非常感谢您的工作。我有一个问题。我使用数据集进行线性回归,得到了适当的结果,我也将其与Ms Excel在相同数据集上的回归结果进行了比较。结果是相同的。
现在我想应用多元回归。Weka支持多元回归吗?
因为我在Weka和Google上都搜索过,但不幸的是我没有看到任何适当的回复。
是的,weka支持多元回归,例如多个输入特征和一个输出特征。
你好 Jason,
我需要在C++项目中使用在WEKA中训练的模型。这可能吗?如果可能,您建议我如何做?
提前感谢,
丽塔
也许您可以从cpp调用Java API?
嗨 Jason,非常感谢您的精彩文章。
我的问题是,我在哪里可以看到这些方法的回归系数?
这些算法会为您找到系数。
非常感谢Jason教授..
不客气。
尊敬的Jason博士;
我如何将Weka中的回归结果导出为其他格式,例如TIFF,ASC-II,以便在地图中可视化。
非常感谢
Pham
这篇帖子展示了如何保存Weka模型
https://machinelearning.org.cn/save-machine-learning-model-make-predictions-weka/
如何开始使用weka进行第一次天气预报工作
这个过程将指导您
https://machinelearning.org.cn/start-here/#process
亲爱的,
我如何从分类模型中知道Spearman和Kendall(相关系数)的值?
回归模型中的相关系数度量是否等同于分类模型中的准确度?
我们无法计算这些类别预测的相关性度量。
它可能是回归问题预测的适当度量。
嗨,Jason博士
如果我想在WEKA中应用线性回归
并且我有一个数据集包含以下属性:(p1,p2,p3,c1,c2,c3…等)
我想选择一个变量,例如:p3作为p1和p2的输出结果
同样,c3是c1和c2的结果。
我可以这样做吗?如果可以,请告诉我怎么做。因为我做了很多假设,我想要两个变量的相关系数作为一个变量的输出。
我不确定Weka是否足够灵活以支持此功能,抱歉。
=== 分类器模型(完整训练集) ===
线性回归模型
消耗单位 =
0.735 * WIFI单位 +
0.9777 * 应用单位 +
0.9278 * GPS +
0.9922 * 通话单位 +
111.7584 * 电池寿命=2,3 +
360.8313 * 电池寿命=3 +
23.4648
构建模型所需时间:0.02秒
=== 交叉验证 ===
=== 总结 ===
相关系数 0.9989
平均绝对误差 77.0165
均方根误差 310.2879
相对绝对误差 1.7131 %
均方根相对误差 4.6261 %
实例总数 366
忽略的未知类别实例 1
为什么我的回归中MSE和RMSE很大?
一些想法
也许问题很具挑战性?
也许模型拟合不佳?
非常感谢Jason的精彩阐述。请问,您能告诉我所讨论的这些模型中哪一个最好,与所用数据集相关?我的意思是,就您提供的RMSE值而言,哪个结果更好?是更小还是更大?
嗨 Olayinka……以下资源可能对您有用
https://machinelearning.org.cn/compare-performance-machine-learning-algorithms-weka/
我可以在同一个分类器中应用更多的回归算法吗?
您可以为同一个回归问题应用多个回归算法。
你好 Jason,
谢谢您的文章,它们总是很有帮助 :)
回归模型的归一化绝对误差(NAE)如何?
我们如何解释它?我们如何使用它进行比较?以及使用RMSE和NAE对相同模型进行不同排名可能的原因是什么?
提前感谢您!
NAE是绝对误差除以如果预测平均值所产生的误差。
抱歉,我不了解它。
我没有听说过NAE,抱歉。
Jason教授您好,
我想问一下:我能否知道使用weka生成一些分类模型时CPU和/或RAM的使用情况?
此致,
Amneh。
抱歉,我不知道,这取决于数据集的大小吧。
除了RMSE,相关系数是否也适合比较结果?
它可能非常有用。
规则数量会影响模型性能吗?
我怀疑在某种程度上会,例如,规模非常大的时候。
Jason先生您好,
我是Weka的新手,正尝试使用多层感知器预测事件持续时间。
数据集中的分类属性已使用唯一整数编码。但它对所有测试实例只预测一个值,如下所示
构建模型所需时间:190.3秒
=== 测试分割上的预测 ===
实例编号,实际值,预测值,误差
1,6.57,6.087,-0.483
2,18.6,6.087,-12.513
3,6.45,6.087,-0.363
4,5.68,6.087,0.407
5,1.42,6.087,4.667
6,6.73,6.087,-0.643
7,7,6.087,-0.913
8,11.07,6.087,-4.983
9,5.9,6.087,0.187
10,65.18,6.087,-59.093
…
我哪里做错了?
每个输入都会有一个输出,并且它们按照样本的顺序排列。
但我检查了我所有的测试数据,它只预测了一个值,在我这里是6.087。这不正常,对吗?
是的,那不是一个好模型。也许可以尝试其他模型?
嗨,Jason。非常感谢您在这里的杰出工作。
我有一个问题。我想对一个包含多个实例的数据集进行插补
15个特征。
我决定使用15个多层感知器(每个特征一个)。为了训练每个多层感知器,我将要插补的特征设置为类别,使用数据集执行Java中的buildclassifier方法,并将得到的训练好的机器存储在一个哈希表中,以便以后插补任何未见的实例。
当这个实例到达时,我取出对应要插补特征的MLP并执行插补。为了避免错误的插补,我决定使用一种类似于MICE的技术,首先对整个实例进行基本过滤插补,然后使用每台机器插补原始缺失值。
通过在每个特征中设置类别来训练不同的机器,这种方法好吗?
非常感谢!
好问题,通常我们需要扮演科学家,测试一系列方法才能发现哪种方法对给定数据集效果好。
我在这里解释了更多
https://machinelearning.org.cn/faq/single-faq/what-algorithm-config-should-i-use
谢谢!!!
这正是我正在努力做的!
太棒了!
嗨 Jason
我得到了一个名义输出,例如:(>4,<4),用于输入葡萄糖值。
如何获得数值,例如(3.4,4.5),我应该在arff中更改什么?
是的,也许可以试试那个?
感谢您的实验,为什么我们使用默认设置,它能更改吗?如果能,何时可以应用。
默认值工作得很好。
是的,您可以更改设置并尝试改进模型性能。
这是一个很棒的Weka指南。非常感谢!
我正尝试从大约100个向量中预测接下来的一两个向量(4-7维)。您认为从哪个工具开始最好?
非常感谢!
我建议测试一系列方法,并使用受控实验来发现哪种方法效果最好。
谢谢,Jason。我的问题是想询问分析向量而不是标量。任何想法都将不胜感激。
我不确定weka是否支持多输出回归,抱歉。
Jason,
非常感谢您为此付出的所有努力。我一直在阅读您的教程和购买您的书籍,它们都是很棒的资源!
我有一个问题,因为Weka中关于多元线性回归的信息似乎不多。您会考虑做一个关于执行多元线性回归的教程吗?我最大的问题是Weka训练数据与我尝试整合的不同类别的格式。您推荐宽数据(将类别转换为独热编码)吗?还是高数据,我们将训练数据与第三列类别连接起来?
再次感谢您!
谢谢 Keith!
很好的建议,谢谢。
我认为Weka会为您执行基本的预处理,例如缩放和独热编码。不确定分类输入,也许您可以尝试一下看看?
我从哪里获得
Weka多层感知器算法的GUI设计器
此致
jose
另外,ANN如何进行预测?
干得好!
本教程将向您展示如何在Weka中使用模型进行预测
https://machinelearning.org.cn/save-machine-learning-model-make-predictions-weka/
嗨,Jason,
感谢您的解释,我非常欣赏您的工作。
我有一个关于使用Weka进行神经网络预测的问题,如果我想预测一个特定的类别。
如果我没理解错的话,我需要将其设置为输出。
然而,当我这样做时,即使使用不同的周期(增加或减少),RMSE的输出仍然相同。
您能解释一下为什么我得到了相同的结果或输出吗?
此致,
Sara。
谢谢。
听起来您正在回归问题上使用MLP。也许可以尝试将您的数据集更改为分类问题,以便能够预测类别标签。
谢谢Jason的回复,我还有另一个问题。
如果我正在使用MLP训练特定类别的回归数据,我需要在参数中设置ValidationSize,还是可以将其保留为0?
即使我训练了50%的数据,20%用于验证,30%用于测试。
ValidationSize 是什么?
这是MLP中的一个参数,它指的是数据中的验证集大小。
它可能用于早期停止。
一个更大的验证集是个好主意,尽管您必须确保在训练模型上使用/投入足够的数据。可能需要进行一些实验。
谢谢 Jason,
您能解释一下两个分类器(MP5和MLP)之间的区别吗?
用于数值预测?
M5P我认为是一个基于决策树的算法。
MLP(多层感知器)是一个神经网络。
M5P*
你好 Jason,
感谢您提供这些教程,您能为我阐明平均绝对误差和相对绝对误差之间的区别吗?
以及哪一个更值得考虑?
是的,这会有帮助
https://en.wikipedia.org/wiki/Approximation_error
使用最能体现您/利益相关者对模型重要性的指标。
你好,Jason
非常感谢您的文章和教程,它们真的很有帮助。
我正在使用Weka上的MLPRegressor,但网上几乎找不到它的信息。它与MLP有何不同,它是如何工作的?
如果您知道哪里可以找到更多信息,我将不胜感激。
谢谢
Bora
它是一个MLP(多层感知器——一个神经网络)。您可以为您的回归问题配置它。
非常感谢Jason的精彩阐述。请问,您能告诉我所讨论的这些模型中哪一个最好,与所用数据集相关?我的意思是,就RMSE值而言,哪个结果更好?是更小还是更大?
嗨 Olayinka……不客气!以下资源将提供清晰的解释
https://machinelearning.org.cn/compare-performance-machine-learning-algorithms-weka/
我创建了两个模型:一个使用m5、贪婪和无属性选择方法的线性回归模型,另一个是决策桩模型,用于数值预测。首先,我使用10折交叉验证在拟合数据上准备模型,然后将这些训练好的模型用于未见过的测试数据。我收到了所有统计指标,如相关系数、均方根误差(RMSE)、平均绝对误差等。我的问题是如何比较这些模型。以及如何预测哪个模型比另一个更好。我是Weka工具的新手。所以我也不知道如何解释Weka工具中显示为结果的这些参数。
嗨 Pahul……在Weka(一个用Java编写的流行机器学习软件套件)中比较模型涉及几个步骤。以下是如何做到的一般指南
1. **准备数据**:在开始之前,请确保您的数据是Weka可以读取的格式,通常是ARFF、CSV或通过JDBC连接的数据库。您的数据集应经过适当的预处理,包括处理缺失值、特征选择和必要的归一化。
2. **打开Weka Explorer**:启动Weka并打开Explorer界面。这是最常用的界面,用于在您的数据上试验不同的算法。
3. **加载数据集**:转到Explorer中的“Preprocess”选项卡。点击“Open file…”加载您的数据集。确保您的数据已正确加载并且属性已正确识别。
4. **配置并运行模型**
– 切换到“Classify”选项卡。在这里,您可以选择不同的算法来构建模型。
– 从列表中选择一个分类器。Weka包含各种算法,从决策树等简单算法到神经网络或支持向量机等更复杂的算法。
– 对于每个模型,您可以配置其参数。点击分类器名称打开其配置窗口。调整这些参数可以显著影响模型性能。
– 通过点击“Start”分别运行每个模型。您可以使用交叉验证或使用单独的测试集等不同方法评估模型。
5. **分析结果**
– 每个模型的性能都显示在输出窗口中。根据您的具体问题,请注意准确率、精确率、召回率、F-measure、ROC面积等指标。
– 为了进行更详细的分析,您可以查看混淆矩阵,它显示了每个类别的正确和不正确预测的数量。
6. **比较模型**
– 要比较模型,您需要查看它们的性能指标并确定哪些指标对您的问题最重要。例如,在某些情况下,准确率可能是关键,而在其他情况下,精确率和召回率更重要。
– 记录每个模型的性能并手动进行比较。
7. **统计检验(可选)**
– 为了进行更严格的比较,您可以使用统计检验。Weka在“Experimenter”界面中提供了此选项。
– 在Experimenter中,您可以设置一系列使用不同算法和数据集的实验,然后执行统计检验(如配对t检验),以查看它们的性能是否存在显著差异。
8. **结论**
– 根据您的比较和任务要求,决定哪个模型表现最好。
– 请记住,最好的模型并不总是准确率最高的模型。还要考虑可解释性、速度和复杂性等其他因素。
9. **文档和报告**
– 记录过程和结果以供将来参考或报告是一个好习惯。包括数据集、模型配置和性能指标的详细信息。
这是一个概述,具体步骤可能因您的数据和所比较模型的复杂性而异。Weka的用户友好界面使其相对容易执行这些任务,即使对于机器学习新手也是如此。