在比较两种不同的机器学习算法或比较同一算法的不同配置时,收集一组结果是一个好习惯。
重复进行每次实验运行30次或更多次,可以得到一组结果,从中可以计算出预期的平均性能,这是因为大多数机器学习算法都具有随机性。
如果两种算法或配置的预期平均性能不同,你怎么知道这种差异是否显著,以及显著到什么程度?
统计显著性检验是帮助解释机器学习实验结果的重要工具。此外,这些工具的发现可以帮助你更好地、更自信地展示你的实验结果,并为你的预测建模问题选择合适的算法和配置。
在本教程中,你将学习如何使用Python中的统计显著性检验来研究和解释机器学习实验结果。
完成本教程后,您将了解:
- 如何应用正态性检验来确认你的数据是否(或不是)正态分布。
- 如何应用参数统计显著性检验来处理正态分布的结果。
- 如何应用非参数统计显著性检验来处理更复杂的结果分布。
通过我新书《机器学习统计学》快速启动你的项目,书中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 更新于2018年5月:更新了与“拒绝”和“未能拒绝”H0相关的语言。

如何使用统计显著性检验来解释机器学习结果
照片由oatsy40拍摄,部分权利保留。
教程概述
本教程分为6个部分。它们是:
- 生成样本数据
- 描述性统计
- 正态性检验
- 比较高斯结果的均值
- 比较方差不同的高斯结果的均值
- 比较非高斯结果的均值
本教程假定您使用Python 2或3以及带有NumPy、Pandas和Matplotlib的SciPy环境。
需要机器学习统计学方面的帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
生成样本数据
情况是您获得了两种算法或同一算法的两种不同配置的实验结果。
每种算法都在测试数据集上进行了多次试验,并收集了技能得分。我们剩下两组技能得分。
我们可以通过生成两个具有略微不同均值的正态随机数总体来模拟这种情况。
以下代码生成了第一种算法的结果。总共1000个结果存储在一个名为*results1.csv*的文件中。结果是从均值为50、标准差为10的正态分布中抽取的。
|
1 2 3 4 5 6 7 8 9 10 11 |
from numpy.random import seed from numpy.random import normal from numpy import savetxt # 定义结果的底层分布 mean = 50 stev = 10 # 从理想分布生成样本 seed(1) results = normal(mean, stev, 1000) # 保存到ASCII文件 savetxt('results1.csv', results) |
下面是*results1.csv*中前5行数据的片段。
|
1 2 3 4 5 6 |
6.624345363663240960e+01 4.388243586349924641e+01 4.471828247736544171e+01 3.927031377843829318e+01 5.865407629324678851e+01 ... |
我们现在可以生成第二种算法的结果。我们将使用相同的方法,并从略有不同的高斯分布(均值为60,标准差相同)中抽取结果。结果将被写入*results2.csv*。
|
1 2 3 4 5 6 7 8 9 10 11 |
from numpy.random import seed from numpy.random import normal from numpy import savetxt # 定义结果的底层分布 mean = 60 stev = 10 # 从理想分布生成样本 seed(1) results = normal(mean, stev, 1000) # 保存到ASCII文件 savetxt('results2.csv', results) |
下面是*results2.csv*中前5行数据的样本。
|
1 2 3 4 5 6 |
7.624345363663240960e+01 5.388243586349924641e+01 5.471828247736544171e+01 4.927031377843829318e+01 6.865407629324678851e+01 ... |
接下来,我们将假设我们不知道任何一组结果的底层分布。
我选择每个实验1000个结果的总体是任意的。使用30或100个结果的总体来实现足够好的估计(例如,低标准误差)会更现实。
如果你的结果不是高斯分布,也不用担心;我们将看看这些方法在非高斯数据上如何失效以及用什么替代方法。
描述性统计
收集结果后的第一步是查看一些摘要统计数据,并了解更多关于数据分布的信息。
这包括查看摘要统计和数据图。
下面是查看两组结果摘要统计的完整代码列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from pandas import DataFrame from pandas import read_csv from matplotlib import pyplot # 加载结果文件 results = DataFrame() results['A'] = read_csv('results1.csv', header=None).values[:, 0] results['B'] = read_csv('results2.csv', header=None).values[:, 0] # 描述性统计 print(results.describe()) # 箱线图 results.boxplot() pyplot.show() # 直方图 results.hist() pyplot.show() |
示例加载了两组结果,并首先打印了摘要统计信息。为了简洁起见,*results1.csv*中的数据称为“A”,*results2.csv*中的数据称为“B”。
我们将假设这些数据代表测试集上的错误分数,并且最小化分数是目标。
我们可以看到,平均而言,A(50.388125)比B(60.388125)要好。我们还可以从其中位数(第50个百分位数)看到相同的情况。从标准差来看,我们还可以看到两个分布似乎具有相似(相同)的散布。
|
1 2 3 4 5 6 7 8 9 |
A B count 1000.000000 1000.000000 mean 50.388125 60.388125 std 9.814950 9.814950 min 19.462356 29.462356 25% 43.998396 53.998396 50% 50.412926 60.412926 75% 57.039989 67.039989 max 89.586027 99.586027 |
接下来,创建了一个比较两组结果的箱线图。箱体捕获了数据的前50%,异常值显示为点,绿线显示为中位数。我们可以看到,这两个分布的数据确实具有相似的散布,并且似乎围绕中位数对称。
A的结果看起来比B好。
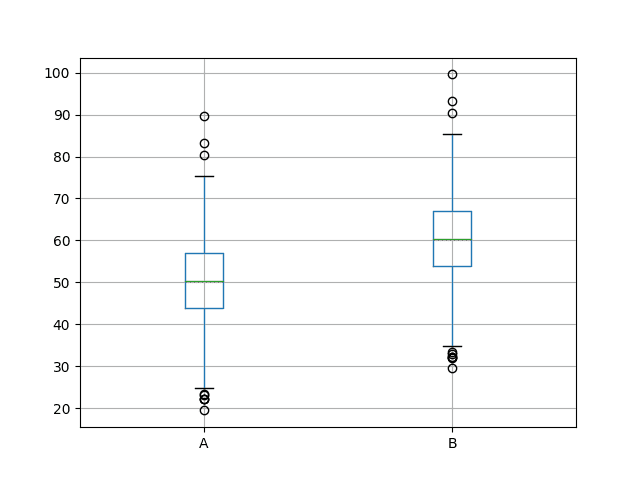
两组结果的箱线图
最后,绘制了两组结果的直方图。
这些图强烈表明两组结果都是从高斯分布中抽取的。
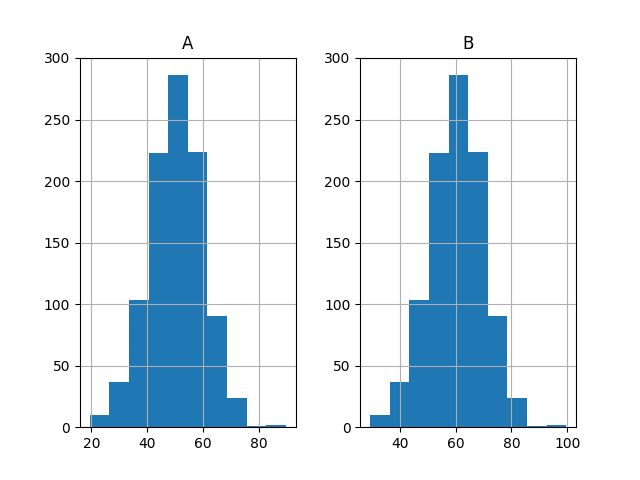
两组结果的直方图
正态性检验
从高斯分布中抽样的数据更容易处理,因为有许多专门为此情况设计的工具和技术。
我们可以使用统计检验来确认从两个分布中抽取的样本是高斯分布(也称为正态分布)。
在SciPy中,这是normaltest()函数。
根据文档,该测试描述为:
检验样本是否与正态分布不同。
该检验的零假设(H0),或默认期望是该统计量描述了一个正态分布。
如果p值大于0.05,我们将无法拒绝此假设。如果p值小于等于0.05,我们将拒绝此假设。在这种情况下,我们将有95%的信心认为该分布不是正态的。
以下代码加载*results1.csv*并确定数据是否可能为高斯分布。
|
1 2 3 4 5 6 7 8 9 10 |
from pandas import read_csv from scipy.stats import normaltest from matplotlib import pyplot result1 = read_csv('results1.csv', header=None) value, p = normaltest(result1.values[:,0]) print(value, p) if p >= 0.05: print('result1很可能是正态的') else: print('result1很可能不是正态的') |
运行示例后,首先打印计算出的统计量以及计算该统计量的p值,它是否来自高斯分布。
我们可以看到,*results1.csv*很可能是高斯分布。
|
1 2 |
2.99013078116 0.224233941463 result1很可能是正态的 |
我们可以对*results2.csv*的数据重复进行相同的测试。
完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 |
from pandas import read_csv from scipy.stats import normaltest from matplotlib import pyplot result2 = read_csv('results2.csv', header=None) value, p = normaltest(result2.values[:,0]) print(value, p) if p >= 0.05: print('result2很可能是正态的') else: print('result2很可能不是正态的') |
运行示例后,会得到相同的统计p值和结果。
两组结果都是高斯分布。
|
1 2 |
2.99013078116 0.224233941463 result2很可能是正态的 |
比较高斯结果的均值
两组结果都是高斯分布且具有相同的方差;这意味着我们可以使用Student t检验来查看两分布均值之间的差异是否具有统计学意义。
在SciPy中,我们可以使用ttest_ind()函数。
该检验描述为:
计算两个独立样本得分均值的T检验。
该检验的零假设(H0)或默认期望是两个样本来自同一总体。如果我们未能拒绝这个假设,这意味着均值之间没有显著差异。
如果我们得到的p值小于等于0.05,这意味着我们可以拒绝零假设,并且在95%的置信度下,均值存在显著差异。这意味着在100个相似的样本中,有95个样本的均值会存在显著差异,而有5个样本不会。
除了数据是高斯分布之外,此统计检验的一个重要假设是两个分布具有相同的方差。从上一步查看描述性统计信息中,我们知道情况确实如此。
完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from pandas import read_csv from scipy.stats import ttest_ind from matplotlib import pyplot # 加载results1 result1 = read_csv('results1.csv', header=None) values1 = result1.values[:,0] # 加载results2 result2 = read_csv('results2.csv', header=None) values2 =result2.values[:,0] # 计算显著性 value, pvalue = ttest_ind(values1, values2, equal_var=True) print(value, pvalue) if pvalue > 0.05: print('样本很可能来自相同的分布(未能拒绝H0)') else: print('样本很可能来自不同的分布(拒绝H0)') |
运行示例后,会打印出统计量和p值。我们可以看到p值远小于0.05。
事实上,它小到几乎可以肯定均值之间的差异具有统计学意义。
|
1 2 |
-22.7822655028 2.5159901708e-102 样本很可能来自不同的分布(拒绝H0) |
比较方差不同的高斯结果的均值
如果两组结果的均值相同,但方差不同,会怎样?
我们不能直接使用Student t检验。事实上,我们必须使用该检验的一个修改版本,称为Welch t检验。
在SciPy中,这是相同的ttest_ind()函数,但我们必须将“equal_var”参数设置为“False”,以表明方差不相等。
我们可以通过一个示例来演示这一点,在该示例中,我们生成了两组均值非常接近(50 vs 51)但标准差差异很大(1 vs 10)的结果。我们将生成100个样本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from numpy.random import seed from numpy.random import normal from scipy.stats import ttest_ind # 生成结果 seed(1) n = 100 values1 = normal(50, 1, n) values2 = normal(51, 10, n) # 计算显著性 value, pvalue = ttest_ind(values1, values2, equal_var=False) print(value, pvalue) if pvalue > 0.05: print('样本很可能来自相同的分布(未能拒绝H0)') else: print('样本很可能来自不同的分布(拒绝H0)') |
运行示例后,会打印出检验统计量和p值。
我们可以看到,有很好的证据(接近99%)表明样本来自不同的分布,即均值存在显著差异。
|
1 2 |
-2.62233137406 0.0100871483783 样本很可能来自不同的分布(拒绝H0) |
分布越接近,区分它们所需的样本就越大。
我们可以通过计算每个结果的不同子样本的统计检验,并将p值与样本大小绘制出来来证明这一点。
我们期望p值随着样本量的增加而减小。我们还可以画一条95%的线(0.05),并显示样本量大到足以表明这两个总体存在显著差异的点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from numpy.random import seed from numpy.random import normal from scipy.stats import ttest_ind from matplotlib import pyplot # 生成结果 seed(1) n = 100 values1 = normal(50, 1, n) values2 = normal(51, 10, n) # 计算不同结果子集的p值 pvalues = list() for i in range(1, n+1): value, p = ttest_ind(values1[0:i], values2[0:i], equal_var=False) pvalues.append(p) # 绘制p值与样本数量的关系图 pyplot.plot(pvalues) # 绘制95%的阈值线,低于此线则拒绝H0 pyplot.plot([0.05 for x in range(len(pvalues))], color='red') pyplot.show() |
运行示例后,会生成一个p值与样本大小的折线图。
我们可以看到,对于这两组结果,样本量必须约为90,我们才有95%的信心认为均值存在显著差异(蓝色线与红色线相交处)。
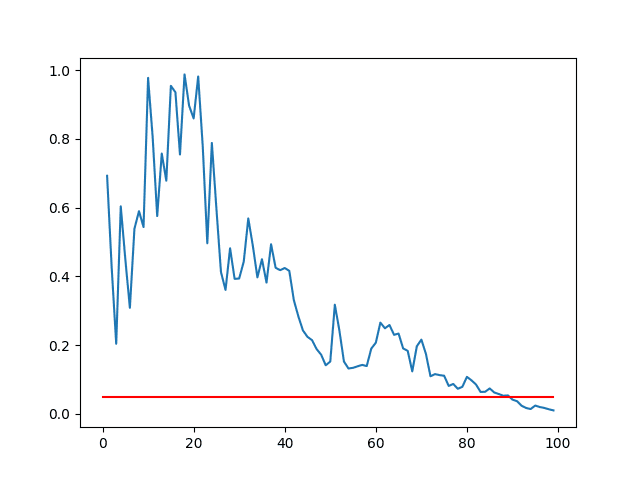
p值与样本大小的折线图
比较非高斯结果的均值
如果我们的数据不是高斯分布,我们就不能使用Student t检验或Welch t检验。
我们可以用于非高斯数据的另一种统计显著性检验称为Kolmogorov-Smirnov检验。
在SciPy中,这被称为ks_2samp()函数。
在文档中,该检验描述为:
这是用于检验两个独立样本是否来自同一连续分布的零假设的双边检验。
此检验可用于高斯数据,但其统计功效较低,可能需要大样本。
我们可以通过一个示例来演示对两组非高斯分布结果的统计显著性计算。我们可以生成两组具有重叠均匀分布(50至60和55至65)的结果。这些结果集将分别具有约55和60的不同均值。
以下代码生成了两组100个结果,并使用Kolmogorov-Smirnov检验来证明总体均值之间的差异具有统计学意义。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from numpy.random import seed from numpy.random import randint from scipy.stats import ks_2samp # 生成结果 seed(1) n = 100 values1 = randint(50, 60, n) values2 = randint(55, 65, n) # 计算显著性 value, pvalue = ks_2samp(values1, values2) print(value, pvalue) if pvalue > 0.05: print('样本很可能来自相同的分布(未能拒绝H0)') else: print('样本很可能来自不同的分布(拒绝H0)') |
运行示例后,会打印出统计量和p值。
p值非常小,表明总体之间存在差异几乎可以肯定是显著的。
|
1 2 |
0.47 2.16825856737e-10 样本很可能来自不同的分布(拒绝H0) |
进一步阅读
本节列出了一些文章和资源,供您深入研究应用机器学习的统计显著性检验。
总结
在本教程中,您了解了如何使用统计显著性检验来解释机器学习结果。
您可以使用这些检验来帮助您自信地选择一种机器学习算法而不是另一种,或者为同一种算法选择一组配置参数而不是另一组。
您学到了
- 如何使用正态性检验来检查您的实验结果是否为高斯分布。
- 如何使用统计检验来检查对于具有相同和不同方差的高斯数据,平均结果之间的差异是否具有统计学意义。
- 如何使用统计检验来检查对于非高斯数据,平均结果之间的差异是否具有统计学意义。
您对这篇文章或统计显著性检验有任何疑问吗?
在下面的评论中提出你的问题,我会尽力回答。




")


这太棒了。解释非常清晰和详细,并且包含完整的代码,非常感激。
一个问题——你知道R中对应的函数吗?特别是,在R中测试样本是否正态分布的最佳方法是什么?
再次感谢一篇好文章
谢谢 David。
是的,R可以做到。抱歉,我不知道函数。
你在看箱线图时说“A的结果看起来比B好”,你能解释一下A比B好在哪里吗?对我来说,这两个图是相同的,只是在均值的差异上有所偏移。
没错,均值不同,我们假设的是错误分数,所以均值越低结果越好。
感谢Jason博士的这篇信息丰富的帖子。我从您的许多帖子中学到了很多!
我有一些评论和问题如下。
1)我注意到在“比较高斯结果的均值”和“比较方差不同的高斯结果的均值”这两个部分的代码中,都有‘pvalue = ttest_ind(values1, values2, equal_var=False’。对于第一部分,难道不应该是‘equal_var=True’吗?
2)另外,在“比较非高斯结果的均值”部分,您使用的是双样本Kolmogorov-Smirnov检验,根据以下文档的第3页(http://www.mit.edu/~6.s085/notes/lecture5.pdf):“它对两个分布的任何差异都很敏感:两个具有相同均值但形状差异很大的分布将产生大的Dn值”(显著结果)。因此,得到一个显著的结果只能告诉我们它们具有不同的分布,但不能告诉我们哪个组更优,因为我们实际上并没有比较均值,正如章节标题所示。
而不是双样本Kolmogorov-Smirnov检验,难道不应该使用Mann-Whitney U检验(又称Wilcoxon秩和检验)吗?与双样本Kolmogorov-Smirnov检验类似,它用于比较两个组是否具有相同的分布。然而,第3页(http://www.mit.edu/~6.s085/notes/lecture5.pdf)指出:“与前面的Kolmogorov-Smirnov检验相比,此检验(如同其无配对的近亲Mann-Whitney U)只对中位数的改变敏感,而不对形状的改变敏感”。此外,在R中,您可以在Mann-Whitney U检验(R中的‘wilcox.test’)中添加‘conf.int=TRUE’参数,这将使我们能够从“配对差异中位数”的角度确定哪个组更优(https://stats.stackexchange.com/questions/215764/significant-two-sided-wilcoxon-rank-sum-test-which-group-has-higher-median)。双样本Kolmogorov-Smirnov检验(R中的‘ks.test()’)似乎没有类似的参数。
3)当我们“比较两种不同的机器学习算法或比较同一算法的不同配置”时。如果我们使用相同的30或100个重采样组来比较这两种算法或配置,难道不应该分别使用配对t检验(对于高斯结果)和Wilcoxon符号秩检验(对于非高斯结果)吗?实际上,我们将进行2次测量(每种算法一次,在相同的受试者(重采样)上)。根据(http://emerald.tufts.edu/~gdallal/paired.htm):“当两次测量都在同一受试者上进行时,受试者间的变异性将从比较中消除。治疗方法之间的差异与差异随受试者变化的程度进行比较。如果这种差异对于每个受试者大致相同,即使不同的受试者反应差异很大,也可以检测到小的治疗效果。”这还使我们能够使用较少的样本(在重采样上的算法运行)获得更强大的检验,从而节省计算时间。
你好,Andrew,
是的,equal_var参数那里有一个笔误。已修正。
是的,这是一个很好的建议。我非常喜欢报告中位数和使用Man-whitney U检验。
也许可以。
非常有信息,谢谢!
很高兴你觉得它有用,Viktor。
Jason你好!非常有用的文章。非常感谢。
我想问:如何确切地使用它来选择模型?我猜你使用了k折交叉验证,并且对每个模型使用了相同的折来进行比较,但通常你不会创建太多的折(5或10个,也许)。即使样本量很小,这些检验仍然有用吗?
再次感谢!
好问题,Roberto。
无论你的重采样方法如何(训练/测试或CV),请对你的模型进行多次(30次以上)评估。对另一个算法或配置重复此操作,然后比较这两组结果。
你好,Brownlee博士!
又一篇精彩且信息量十足的教程!
我使用Keras在MNIST上训练了一个LeNet。现在在推理时,对于10k张图像,我得到了98.7%的准确率。我在推理过程中对网络进行了一些更改,准确率下降到了96.5%。我应该如何进行显著性检验来证明所做的更改对网络有显著影响?
我正在考虑制作100组测试数据,每组100张图像,然后分别运行基线网络和修改后的网络。之后,我应该使用上面描述的技术来证明我的假设。
这是正确的方法吗?
谢谢
好问题。
一种方法是保持模型和训练/测试数据不变,然后重新训练n次,比如30次,得到30个准确率分数,然后再对另一个模型重复这个过程。之后,你可以比较这两组结果,看看均值是否有差异,以及这种差异是否显著。
您好,先生……很棒的文章!!!
我有一个关于使用统计检验来比较具有不同设置的同一模型的问题。
假设我使用10个特征训练了一个模型,在测试集上获得了58%的准确率。
现在,我使用相同的模型和相同的参数,但只使用9个特征进行测试,获得了53%的准确率。
1.我应该如何使用统计检验来证明准确率的差异在统计学上是显著的?
2.我如何在Python中应用单尾配对t检验来处理这种情况?
教程中的建议是一个很好的开始。
你到底遇到了什么问题?
正如您在上面的文章中所说的……我们需要重复实验30次或更多次才能获得准确率分数的总体。在我的情况下,这意味着我需要对带有10个特征的测试集重复预测30次,同样地,对带有9个特征的测试集重复30次。这样我就可以得到两组不同的分数,然后我可以在上面应用t检验。
这样对吗?
另外,我想知道在Python中用哪个函数来执行单尾配对检验?
我查阅了配对检验,得知`ttest_rel()`用于配对t检验。
也许吧,这确实取决于具体情况。
我在这里有一个使用t检验的例子。
https://machinelearning.org.cn/parametric-statistical-significance-tests-in-python/
我有一篇关于比较算法的显著性检验的文章在这里。
https://machinelearning.org.cn/statistical-significance-tests-for-comparing-machine-learning-algorithms/
这是一篇很棒的文章,谢谢——我学到了很多。
不过我还有几个问题。
如何将其应用于分类问题?是比较分类结果(1, 0, 1, 0)?还是在应用决策函数之前的结果(0.23, 0.89, 0.66)?
然后,如果是一个非二元分类问题呢?
再次感谢
对于分类,我们会查看准确率分数的总体——就像我们在上面的文章中所做的那样。
这有帮助吗?
哦,是的,当然!抱歉,我第一次阅读时误以为您是在比较分类器的输出而不是准确率分数。
谢谢您的澄清!
不客气。
嗨,Jason,
这个教程非常有帮助!
您能否推荐一些关于您使用的方法论和显著性检验技术的书籍或论文?
非常感谢!
是的,我正在写一本关于这个主题的书。应该很快就会出来了。
总的来说,修改后的配对学生t检验是评估交叉验证折叠准确率的首选方法(参见Weka的实现)。或者,5次重复的2折交叉验证和配对学生t检验具有较低的II类错误率。
请看这篇论文,这是一个很好的起点。
Thomas Dietterich,“Approximate Statistical Tests for Comparing Supervised Classification Learning Algorithms”,1998年。
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.37.3325&rep=rep1&type=pdf
非常感谢!
很有趣的是,我研究领域(交通运输研究)中有许多工作没有为机器学习实验提供统计显著性检验。
我曾一度认为它们不需要,直到您的文章说服了我。
我只是需要找到一些学术参考资料才能更确定我的决定,但无法找到。(也许是我使用了错误的关键词)
感谢您的文章和参考资料!祝您的书大获成功,我很高兴能在其出版后阅读。
谢谢,很高兴它帮助了Elton。
我希望很快能有更多关于统计假设检验主题的内容。
你好Jason,这个检验是针对结果的,那么在训练神经网络时,数据集必须服从正态分布吗??
如何检查数据集的分布??
不,对于像神经网络这样的非线性方法,不需要高斯分布。
你可以通过绘制变量的直方图来检查分布。
你好,我也在尝试找出两种分类树算法(在同一数据集上的bagging和随机森林结果)之间是否存在统计显著性。我将多次执行它们以获得每种算法的两个准确率结果列表,并且我想基于这些准确率结果进行t检验。即使我没有高斯分布,我也可以直接进行检验吗?如果不行,我该如何处理准确率数据?
请看这个教程
https://machinelearning.org.cn/statistical-significance-tests-for-comparing-machine-learning-algorithms/
你好,
我有一个标记的数据集,并希望应用不同的分类算法。我的目标是选择最佳的分类算法。数据集有很多特征。当我应用t检验时,应该选择哪个特征?
谢谢
这篇文章描述了如何使用假设检验来比较模型性能。
https://machinelearning.org.cn/statistical-significance-tests-for-comparing-machine-learning-algorithms/
嘿,如果p值 > 0.05,这意味着你未能拒绝原假设,但这并不意味着你可以接受原假设。结果将是模棱两可的。所以,你不能说“它很可能服从正态分布”。
我们从不接受,我们只拒绝或未能拒绝。
结果仍然是概率性的。
你好Jason。这篇文章在比较不同模型性能的项目中帮了我很多。但是,如果我想比较一个随机模型的性能和一个确定性模型的性能,我该怎么做?我是否需要对两个非高斯分布使用非参数检验?
也许可以使用bootstrap来估计确定性模型的性能,然后比较样本均值?
你好,Jason
感谢您提供的信息丰富的教程!
我有一个关于“p值与样本量的折线图”的问题。它明显有一个最大值,但我预期它应该是一个单调递减的指数函数。这个函数的形式有什么解释吗?
你好Elie……我不明白你的问题。你能详细说明一下吗?
嗨,Jason,
您是否有关于如何复制ML模型(重复执行ML模型)的代码?还是说,字面上就是将代码执行x次来编译结果集?