看看所有非常大的卷积神经网络,如ResNets、VGGs等等,不禁让人思考:我们如何才能在保持相同精度水平,甚至在参数更少的情况下提高模型的泛化能力,同时使这些网络更小、参数更少。一种方法是深度可分离卷积,在TensorFlow和Pytorch中也被称为可分离卷积(不要与空间可分离卷积混淆,后者也称为可分离卷积)。深度可分离卷积由Sifre在“用于图像分类的刚体运动散射”中引入,并被流行的模型架构如MobileNet和Xception中的类似版本所采用。它将通常在普通卷积层中结合在一起的通道卷积和空间卷积分开。
在本教程中,我们将探讨什么是深度可分离卷积以及如何使用它们来加速我们的卷积神经网络图像模型。
完成本教程后,您将学习到:
- 什么是深度卷积、逐点卷积和深度可分离卷积
- 如何在Tensorflow中实现深度可分离卷积
- 在计算机视觉模型中使用它们
让我们开始吧!

在 Tensorflow 中使用深度可分离卷积
图片作者:Arisa Chattasa。保留部分权利。
概述
本教程分为3个部分
- 什么是深度可分离卷积
- 它们为什么有用
- 在计算机视觉模型中使用深度可分离卷积
什么是深度可分离卷积
在深入了解深度卷积和深度可分离卷积之前,快速回顾一下卷积可能会有所帮助。图像处理中的卷积是将一个核应用于一个体积的过程,我们通过像素的加权和进行计算,权重为核的值。如下图所示:
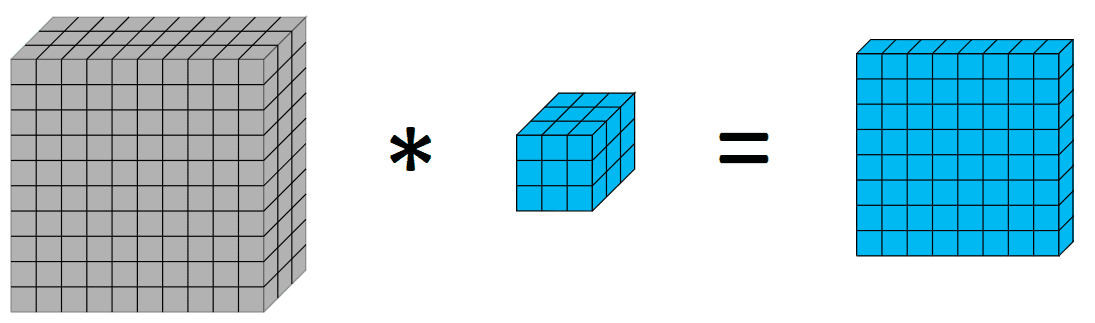
将一个3x3的核应用于10x10x3的输入,输出一个8x8x1的体积
现在,我们引入深度卷积。深度卷积基本上是沿着图像的单一空间维度进行卷积。从视觉上看,一个单一的深度卷积滤波器看起来会像这样:
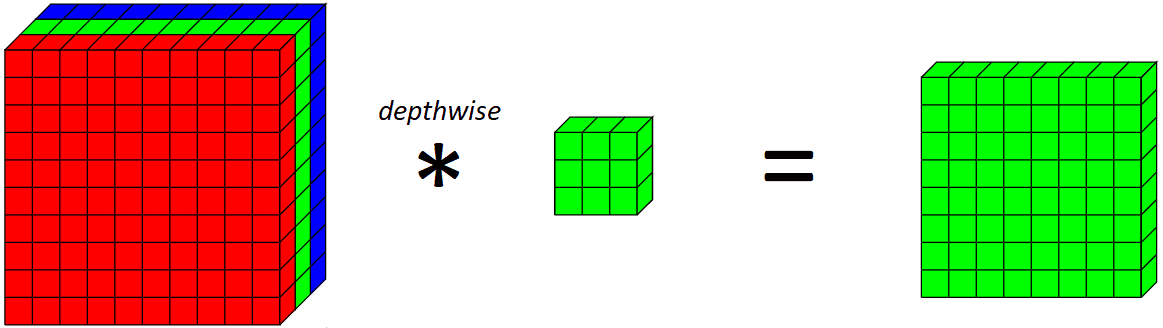
在这个例子中,对绿色通道应用一个深度为3x3的核
普通卷积层与深度卷积的关键区别在于,深度卷积只沿着图像的一个空间维度(即通道)进行卷积,而普通卷积在每个步骤中都跨所有空间维度/通道进行。
如果我们看看一个完整的深度层在所有RGB通道上的作用,
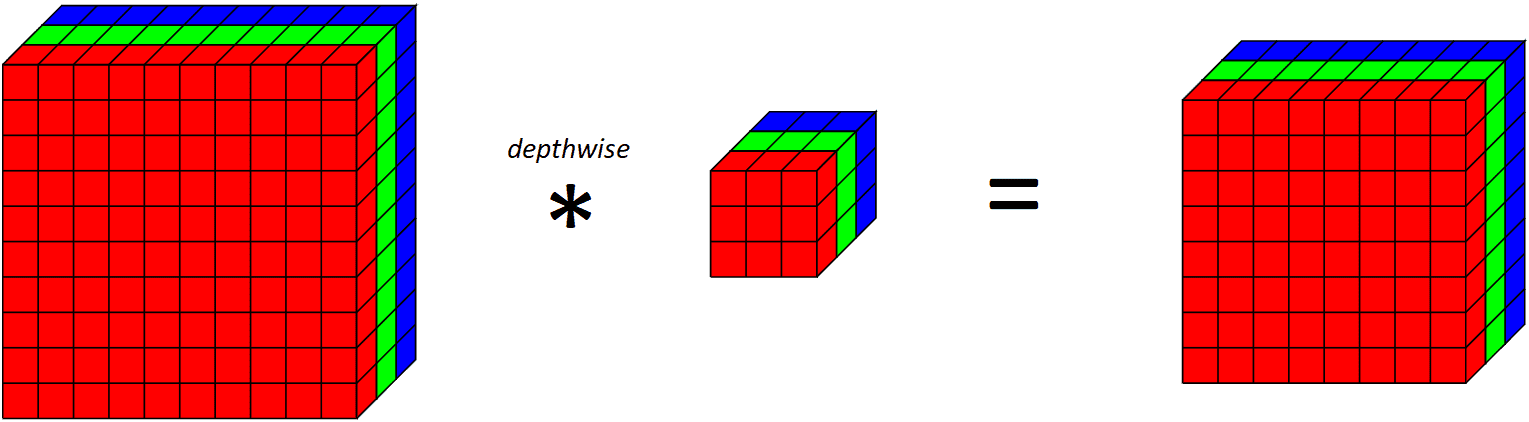
对10x10x3的输入体积应用深度卷积滤波器,输出8x8x3的体积
请注意,由于我们为每个输出通道应用一个卷积滤波器,所以输出通道的数量等于输入通道的数量。应用这个深度卷积层之后,我们再应用一个逐点卷积层。
简单来说,逐点卷积层是一个使用1x1核的常规卷积层(因此它查看所有通道上的一个点)。从视觉上看,它像这样:

对10x10x3的输入体积应用逐点卷积,输出10x10x1的体积
深度可分离卷积为何有用?
现在,您可能会想,使用深度可分离卷积进行两次操作有什么用?既然本文的标题是加速计算机视觉模型,那么进行两次操作而不是一次操作如何帮助加速呢?
为了回答这个问题,我们来看看模型中的参数数量(尽管进行两次卷积而不是一次会带来一些额外的开销)。假设我们想对RGB图像应用64个卷积滤波器,使输出有64个通道。普通卷积层中的参数数量(包括偏置项)是 $ 3 \times 3 \times 3 \times 64 + 64 = 1792 $。另一方面,使用深度可分离卷积层将只有 $ (3 \times 3 \times 1 \times 3 + 3) + (1 \times 1 \times 3 \times 64 + 64) = 30 + 256 = 286 $ 个参数,这是一个显著的减少,深度可分离卷积的参数数量不到普通卷积的6倍。
这有助于减少计算量和参数数量,从而分别减少训练/推理时间并有助于正则化我们的模型。
让我们看看实际效果。对于我们的输入,让我们使用CIFAR10图像数据集,包含32x32x3的图像。
|
1 2 3 4 5 |
import tensorflow.keras as keras from keras.datasets import mnist # 加载数据集 (trainX, trainY), (testX, testY) = keras.datasets.cifar10.load_data() |
然后,我们实现一个深度可分离卷积层。Tensorflow中有一个实现,但我们将在最后一个例子中讨论它。
|
1 2 3 4 5 6 7 8 9 |
class DepthwiseSeparableConv2D(keras.layers.Layer): def __init__(self, filters, kernel_size, padding, activation): super(DepthwiseSeparableConv2D, self).__init__() self.depthwise = DepthwiseConv2D(kernel_size = kernel_size, padding = padding, activation = activation) self.pointwise = Conv2D(filters = filters, kernel_size = (1,1), activation = activation) def call(self, input_tensor): x = self.depthwise(input_tensor) return self.pointwise(x) |
构建一个使用深度可分离卷积层的模型并查看参数数量,
|
1 2 3 4 |
visible = Input(shape=(32, 32, 3)) depthwise_separable = DepthwiseSeparableConv2D(filters=64, kernel_size=(3,3), padding="valid", activation="relu")(visible) depthwise_model = Model(inputs=visible, outputs=depthwise_separable) depthwise_model.summary() |
其输出为
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
_________________________________________________________________ 层 (类型) 输出形状 参数 # ================================================================= input_15 (InputLayer) [(None, 32, 32, 3)] 0 depthwise_separable_conv2d_ (None, 30, 30, 64) 286 11 (DepthwiseSeparableConv2 D) ================================================================= 总参数: 286 可训练参数: 286 不可训练参数: 0 _________________________________________________________________ |
我们可以将其与使用常规2D卷积层的类似模型进行比较,
|
1 |
normal = Conv2D(filters=64, kernel_size=(3,3), padding=”valid”, activation=”relu”)(visible) |
其输出为
|
1 2 3 4 5 6 7 8 9 10 11 12 |
_________________________________________________________________ 层 (类型) 输出形状 参数 # ================================================================= 输入 (InputLayer) [(None, 32, 32, 3)] 0 conv2d (Conv2D) (None, 30, 30, 64) 1792 ================================================================= 总参数: 1,792 可训练参数: 1,792 不可训练参数: 0 _________________________________________________________________ |
这与我们之前对参数数量的初步计算结果相符,并展示了通过使用深度可分离卷积可以实现的参数数量的减少。
更具体地说,让我们来看看普通卷积层和深度可分离卷积层中核的数量和大小。对于一个输入通道为 $c$、核空间分辨率为 $w \times h$、输出通道为 $n$ 的常规2D卷积层,我们需要 $(n, w, h, c)$ 个参数,即 $n$ 个滤波器,每个滤波器的核大小为 $(w, h, c)$。然而,对于一个具有相同输入通道数、核空间分辨率和输出通道数的类似深度可分离卷积,情况就不同了。首先是深度卷积,它包含 $c$ 个滤波器,每个滤波器的核大小为 $(w, h, 1)$,由于它作用于每个滤波器,因此输出 $c$ 个通道。这个深度卷积层有 $(c, w, h, 1)$ 个参数(加上一些偏置单元)。然后是逐点卷积,它接收来自深度层的 $c$ 个通道,并输出 $n$ 个通道,因此我们有 $n$ 个滤波器,每个滤波器的核大小为 $(1, 1, n)$。这个逐点卷积层有 $(n, 1, 1, n)$ 个参数(加上一些偏置单元)。
您现在可能会想,但它们为什么能起作用呢?
来自Chollet的Xception论文的一种思考方式是,深度可分离卷积假设我们可以分别映射跨通道和空间相关性。鉴于此,卷积层中将存在大量冗余权重,我们可以通过将卷积分解为深度和逐点分量的两个卷积来减少这些冗余权重。对于熟悉线性代数的人来说,一种思考方式是当我们矩阵中的列向量相互成倍数时,我们如何将矩阵分解为两个向量的外积。
在计算机视觉模型中使用深度可分离卷积
现在我们已经看到了通过使用深度可分离卷积而非普通卷积滤波器可以实现的参数减少,接下来我们看看如何在实践中使用Tensorflow的SeparableConv2D滤波器。
本例中,我们将使用上述示例中使用的CIFAR-10图像数据集,而模型将基于VGG块构建。深度可分离卷积的潜力在于更深层的模型,在这些模型中,正则化效果对模型更有益,并且参数的减少比LeNet-5等轻量级模型更明显。
使用普通卷积层构建VGG块模型,
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from keras.models import Model from keras.layers import Input, Conv2D, MaxPooling2D, Dense, Flatten, SeparableConv2D import tensorflow as tf # 创建vgg块的函数 def vgg_block(layer_in, n_filters, n_conv): # 添加卷积层 for _ in range(n_conv): layer_in = Conv2D(filters = n_filters, kernel_size = (3,3), padding='same', activation="relu")(layer_in) # 添加最大池化层 layer_in = MaxPooling2D((2,2), strides=(2,2))(layer_in) return layer_in visible = Input(shape=(32, 32, 3)) layer = vgg_block(visible, 64, 2) layer = vgg_block(layer, 128, 2) layer = vgg_block(layer, 256, 2) layer = Flatten()(layer) layer = Dense(units=10, activation="softmax")(layer) # 创建模型 model = Model(inputs=visible, outputs=layer) # 总结模型 model.summary() model.compile(optimizer="adam", loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics="acc") history = model.fit(x=trainX, y=trainY, batch_size=128, epochs=10, validation_data=(testX, testY)) |
然后我们看看这个包含普通卷积层的6层卷积神经网络的结果:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
_________________________________________________________________ 层 (类型) 输出形状 参数 # ================================================================= input_1 (InputLayer) [(None, 32, 32, 3)] 0 conv2d (Conv2D) (None, 32, 32, 64) 1792 conv2d_1 (Conv2D) (None, 32, 32, 64) 36928 max_pooling2d (MaxPooling2D (None, 16, 16, 64) 0 ) conv2d_2 (Conv2D) (None, 16, 16, 128) 73856 conv2d_3 (Conv2D) (None, 16, 16, 128) 147584 max_pooling2d_1 (MaxPooling (None, 8, 8, 128) 0 2D) conv2d_4 (Conv2D) (None, 8, 8, 256) 295168 conv2d_5 (Conv2D) (None, 8, 8, 256) 590080 max_pooling2d_2 (MaxPooling (None, 4, 4, 256) 0 2D) flatten (Flatten) (None, 4096) 0 dense (Dense) (None, 10) 40970 ================================================================= 总参数: 1,186,378 可训练参数: 1,186,378 不可训练参数: 0 _________________________________________________________________ Epoch 1/10 391/391 [==============================] - 11s 27ms/步 - 损失: 1.7468 - 准确率: 0.4496 - 验证损失: 1.3347 - 验证准确率: 0.5297 Epoch 2/10 391/391 [==============================] - 10s 26ms/步 - 损失: 1.0224 - 准确率: 0.6399 - 验证损失: 0.9457 - 验证准确率: 0.6717 Epoch 3/10 391/391 [==============================] - 10s 26ms/步 - 损失: 0.7846 - 准确率: 0.7282 - 验证损失: 0.8566 - 验证准确率: 0.7109 Epoch 4/10 391/391 [==============================] - 10s 26ms/步 - 损失: 0.6394 - 准确率: 0.7784 - 验证损失: 0.8289 - 验证准确率: 0.7235 Epoch 5/10 391/391 [==============================] - 10s 26ms/步 - 损失: 0.5385 - 准确率: 0.8118 - 验证损失: 0.7445 - 验证准确率: 0.7516 Epoch 6/10 391/391 [==============================] - 11s 27ms/步 - 损失: 0.4441 - 准确率: 0.8461 - 验证损失: 0.7927 - 验证准确率: 0.7501 Epoch 7/10 391/391 [==============================] - 11s 27ms/步 - 损失: 0.3786 - 准确率: 0.8672 - 验证损失: 0.8279 - 验证准确率: 0.7455 Epoch 8/10 391/391 [==============================] - 10s 26ms/步 - 损失: 0.3261 - 准确率: 0.8855 - 验证损失: 0.8886 - 验证准确率: 0.7560 Epoch 9/10 391/391 [==============================] - 10s 27ms/步 - 损失: 0.2747 - 准确率: 0.9044 - 验证损失: 1.0134 - 验证准确率: 0.7387 Epoch 10/10 391/391 [==============================] - 10s 26ms/步 - 损失: 0.2519 - 准确率: 0.9126 - 验证损失: 0.9571 - 验证准确率: 0.7484 |
让我们尝试相同的架构,但将普通卷积层替换为Keras的SeparableConv2D层
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 深度可分离VGG块 def vgg_depthwise_block(layer_in, n_filters, n_conv): # 添加卷积层 for _ in range(n_conv): layer_in = SeparableConv2D(filters = n_filters, kernel_size = (3,3), padding='same', activation='relu')(layer_in) # 添加最大池化层 layer_in = MaxPooling2D((2,2), strides=(2,2))(layer_in) return layer_in visible = Input(shape=(32, 32, 3)) layer = vgg_depthwise_block(visible, 64, 2) layer = vgg_depthwise_block(layer, 128, 2) layer = vgg_depthwise_block(layer, 256, 2) layer = Flatten()(layer) layer = Dense(units=10, activation="softmax")(layer) # 创建模型 model = Model(inputs=visible, outputs=layer) # 总结模型 model.summary() model.compile(optimizer="adam", loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics="acc") history_dsconv = model.fit(x=trainX, y=trainY, batch_size=128, epochs=10, validation_data=(testX, testY)) |
运行上述代码得到以下结果:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
_________________________________________________________________ 层 (类型) 输出形状 参数 # ================================================================= input_1 (InputLayer) [(None, 32, 32, 3)] 0 separable_conv2d (Separab (None, 32, 32, 64) 283 leConv2D) separable_conv2d_2 (Separab (None, 32, 32, 64) 4736 leConv2D) max_pooling2d (MaxPoolin (None, 16, 16, 64) 0 g2D) separable_conv2d_3 (Separab (None, 16, 16, 128) 8896 leConv2D) separable_conv2d_4 (Separab (None, 16, 16, 128) 17664 leConv2D) max_pooling2d_2 (MaxPoolin (None, 8, 8, 128) 0 g2D) separable_conv2d_5 (Separa (None, 8, 8, 256) 34176 bleConv2D) separable_conv2d_6 (Separa (None, 8, 8, 256) 68096 bleConv2D) max_pooling2d_3 (MaxPoolin (None, 4, 4, 256) 0 g2D) flatten (Flatten) (None, 4096) 0 dense (Dense) (None, 10) 40970 ================================================================= 总参数: 174,821 可训练参数: 174,821 不可训练参数: 0 _________________________________________________________________ Epoch 1/10 391/391 [==============================] - 10s 22ms/步 - 损失: 1.7578 - 准确率: 0.3534 - 验证损失: 1.4138 - 验证准确率: 0.4918 Epoch 2/10 391/391 [==============================] - 8s 21ms/步 - 损失: 1.2712 - 准确率: 0.5452 - 验证损失: 1.1618 - 验证准确率: 0.5861 Epoch 3/10 391/391 [==============================] - 8s 22ms/步 - 损失: 1.0560 - 准确率: 0.6286 - 验证损失: 0.9950 - 验证准确率: 0.6501 Epoch 4/10 391/391 [==============================] - 8s 21ms/步 - 损失: 0.9175 - 准确率: 0.6800 - 验证损失: 0.9327 - 验证准确率: 0.6721 Epoch 5/10 391/391 [==============================] - 9s 22ms/步 - 损失: 0.7939 - 准确率: 0.7227 - 验证损失: 0.8348 - 验证准确率: 0.7056 Epoch 6/10 391/391 [==============================] - 8s 22ms/步 - 损失: 0.7120 - 准确率: 0.7515 - 验证损失: 0.8228 - 验证准确率: 0.7153 Epoch 7/10 391/391 [==============================] - 8s 21ms/步 - 损失: 0.6346 - 准确率: 0.7772 - 验证损失: 0.7444 - 验证准确率: 0.7415 Epoch 8/10 391/391 [==============================] - 8s 21ms/步 - 损失: 0.5534 - 准确率: 0.8061 - 验证损失: 0.7417 - 验证准确率: 0.7537 Epoch 9/10 391/391 [==============================] - 8s 21ms/步 - 损失: 0.4865 - 准确率: 0.8301 - 验证损失: 0.7348 - 验证准确率: 0.7582 Epoch 10/10 391/391 [==============================] - 8s 21ms/步 - 损失: 0.4321 - 准确率: 0.8485 - 验证损失: 0.7968 - 验证准确率: 0.7458 |
请注意,深度可分离卷积版本中的参数数量明显较少(约20万 vs 约120万参数),同时每个epoch的训练时间也略短。深度可分离卷积在更深的模型中(可能面临过拟合问题)以及在具有更大核的层中更可能表现更好,因为参数和计算量的减少幅度更大,足以抵消执行两次卷积而非一次卷积所带来的额外计算成本。接下来,我们将绘制两个模型的训练和验证准确率,以查看模型训练性能的差异。
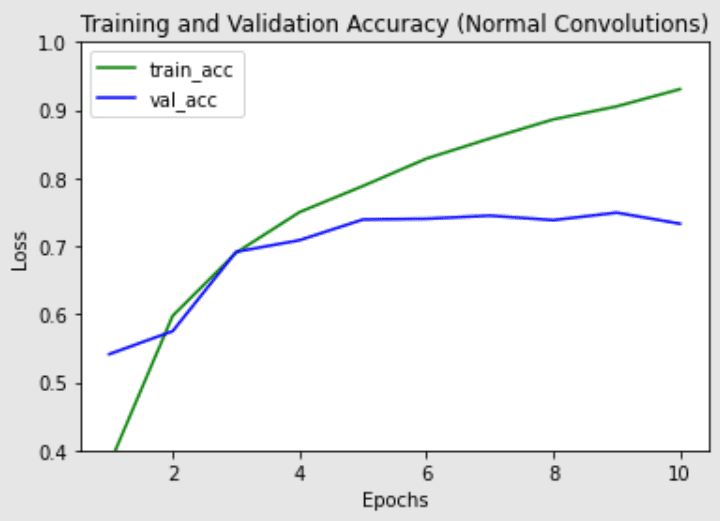
采用普通卷积层的网络的训练和验证准确率
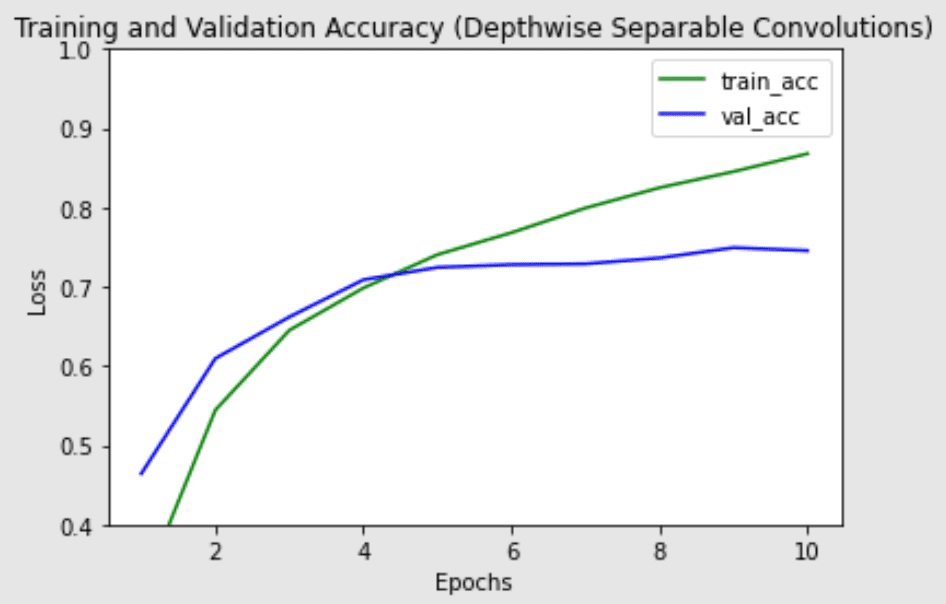
采用深度可分离卷积层的网络的训练和验证准确率
两个模型的最高验证准确率相似,但深度可分离卷积对训练集的过拟合似乎较少,这可能有助于它更好地泛化到新数据。
将深度可分离卷积版本的模型所有代码合并在一起,
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import tensorflow.keras as keras from keras.datasets import mnist # 加载数据集 (trainX, trainY), (testX, testY) = keras.datasets.cifar10.load_data() # 深度可分离VGG块 def vgg_depthwise_block(layer_in, n_filters, n_conv): # 添加卷积层 for _ in range(n_conv): layer_in = SeparableConv2D(filters = n_filters, kernel_size = (3,3), padding='same',activation='relu')(layer_in) # 添加最大池化层 layer_in = MaxPooling2D((2,2), strides=(2,2))(layer_in) return layer_in visible = Input(shape=(32, 32, 3)) layer = vgg_depthwise_block(visible, 64, 2) layer = vgg_depthwise_block(layer, 128, 2) layer = vgg_depthwise_block(layer, 256, 2) layer = Flatten()(layer) layer = Dense(units=10, activation="softmax")(layer) # 创建模型 model = Model(inputs=visible, outputs=layer) # 总结模型 model.summary() model.compile(optimizer="adam", loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics="acc") history_dsconv = model.fit(x=trainX, y=trainY, batch_size=128, epochs=10, validation_data=(testX, testY)) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 图像分类的刚体运动散射(深度可分离卷积)
- MobileNet
- Xception
API
- Tensorflow中的深度可分离卷积 (SeparableConv2D)
总结
在这篇文章中,您已经了解了什么是深度卷积、逐点卷积和深度可分离卷积。您还看到了如何使用深度可分离卷积,在显著减少参数数量的同时获得具有竞争力的结果。
具体来说,您学到了
- 什么是深度卷积、逐点卷积和深度可分离卷积
- 如何在Tensorflow中实现深度可分离卷积
- 在计算机视觉模型中使用它们
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。

")
")



非常有用的一篇文章!
在您的图中,Y轴可能应该是“准确率”而不是“损失”。
你好George…谢谢你的反馈!以下资源将提供更多关于学习曲线的细节
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
如果您能在这里添加最新博客选项,以便我们相应地筛选最近或最新的文章,那就太好了。
你好Deepak…“筛选最近或最新的文章”是什么意思?
你好,我觉得“这个逐点卷积层有(n,1,1,n)个参数(加上一些偏置单元)”这句话有错别字,总参数数量应该是(n,1,1,c),因为在逐点卷积中,操作是在相同空间维度(即w和h)的每个通道上进行的,每个通道只有一个权重值。
你好Ahmed…你说得完全正确!在逐点卷积中,层使用 \(1 \times 1\) 的核,这意味着它在空间维度(宽度和高度)上对每个通道应用单个权重。因此,参数的总数确实应该是 \((n, 1, 1, c)\),其中 \(c\) 是输入通道的数量,\(n\) 是输出通道的数量。这种设置允许对每个输入通道独立进行深度操作,这对于在深度可分离卷积中保持通道分离性至关重要。
感谢您的指正!