你可能听说过 Kaggle 数据科学竞赛,但你知道 Kaggle 还有许多其他功能可以帮助你进行下一个机器学习项目吗?对于那些正在寻找下一个机器学习项目数据集的人来说,Kaggle 允许你访问他人公开的数据集并分享你自己的数据集。对于那些希望构建和训练自己机器学习模型的人来说,Kaggle 还提供了一个浏览器内嵌的笔记本环境和一些免费的 GPU 时间。你还可以查看他人公开的笔记本!
除了网站,Kaggle 还提供了一个命令行界面(CLI),你可以在命令行中使用它来访问和下载数据集。
让我们深入探讨一下 Kaggle 有哪些可以提供的吧!
完成本教程后,您将学习到:
- 什么是 Kaggle?
- 如何将 Kaggle 用作机器学习流程的一部分
- 使用 Kaggle API 的命令行界面 (CLI)
通过我的新书《Python for Machine Learning》启动你的项目,书中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧!
在机器学习项目中使用Kaggle
照片来源:Stefan Widua。部分权利保留。
概述
本教程分为五个部分,它们是:
- 什么是 Kaggle?
- 设置 Kaggle 笔记本
- 在 Kaggle 笔记本中使用 GPU/TPU
- 在 Kaggle 笔记本中使用 Kaggle 数据集
- 使用 Kaggle 数据集和 Kaggle CLI 工具
什么是 Kaggle?
Kaggle 最出名的可能是它举办的数据科学竞赛,其中一些竞赛提供五位数的奖金池,并吸引了数百个团队参加。除了这些竞赛,Kaggle 还允许用户发布和搜索数据集,这些数据集可以用于他们的机器学习项目。要使用这些数据集,你可以使用浏览器内的 Kaggle 笔记本或 Kaggle 的公共 API 来下载数据集,然后用于你的机器学习项目。
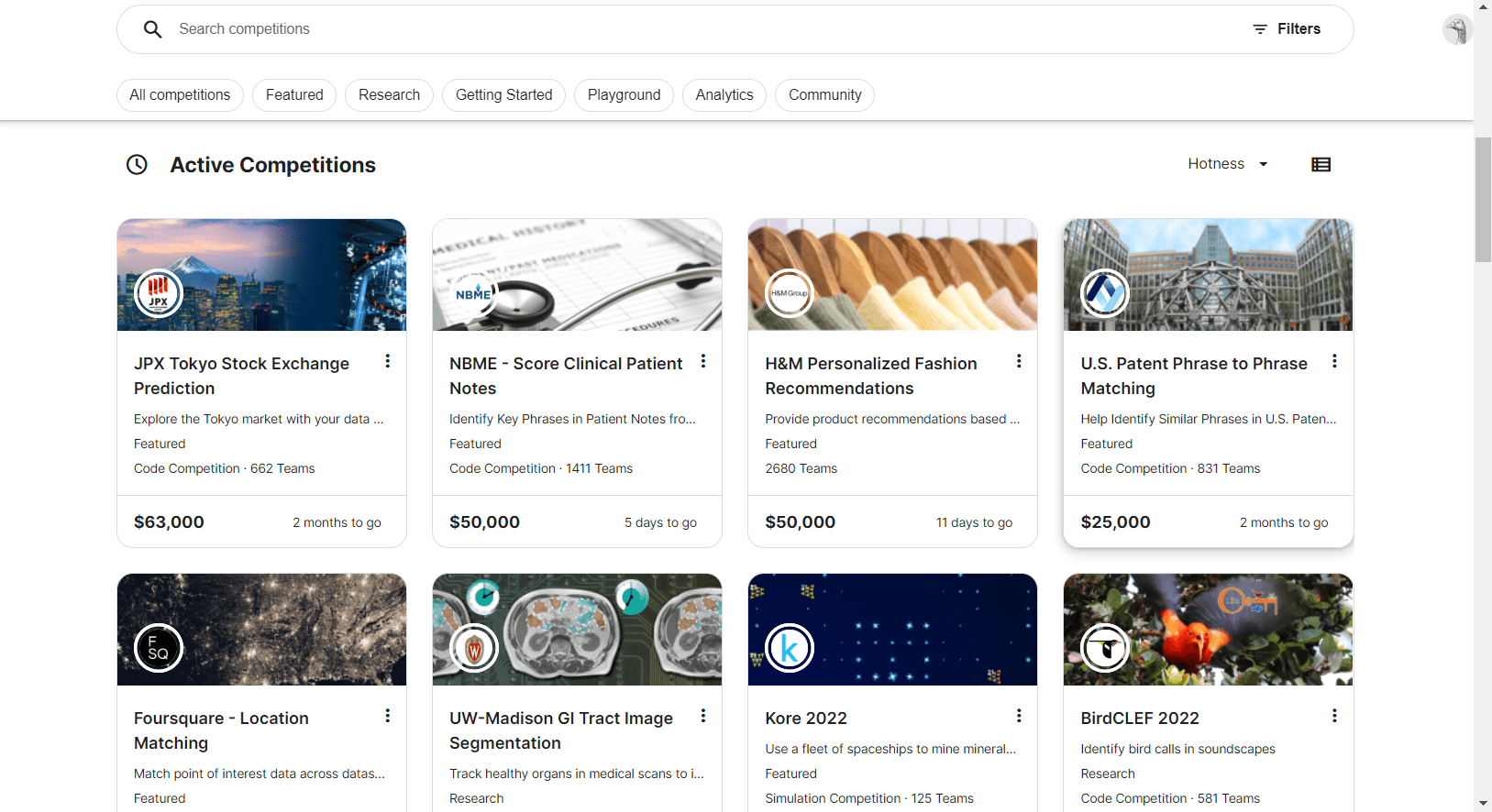
Kaggle 竞赛
此外,Kaggle 还提供了一些课程和讨论页面,供你进一步了解机器学习并与其他机器学习从业者交流!
在本文的其余部分,我们将重点介绍如何使用 Kaggle 的数据集和笔记本,以帮助我们在进行自己的机器学习项目或寻找新项目时。
设置 Kaggle 笔记本
要开始使用 Kaggle 笔记本,你需要创建一个 Kaggle 账户,可以使用现有的 Google 账户,或者使用你的电子邮件创建一个。
然后,转到“代码”页面。
Kaggle 主页左侧边栏,“代码”标签页
届时,你将能够看到你自己的笔记本以及他人公开的笔记本。要创建你自己的笔记本,请点击“新建笔记本”。
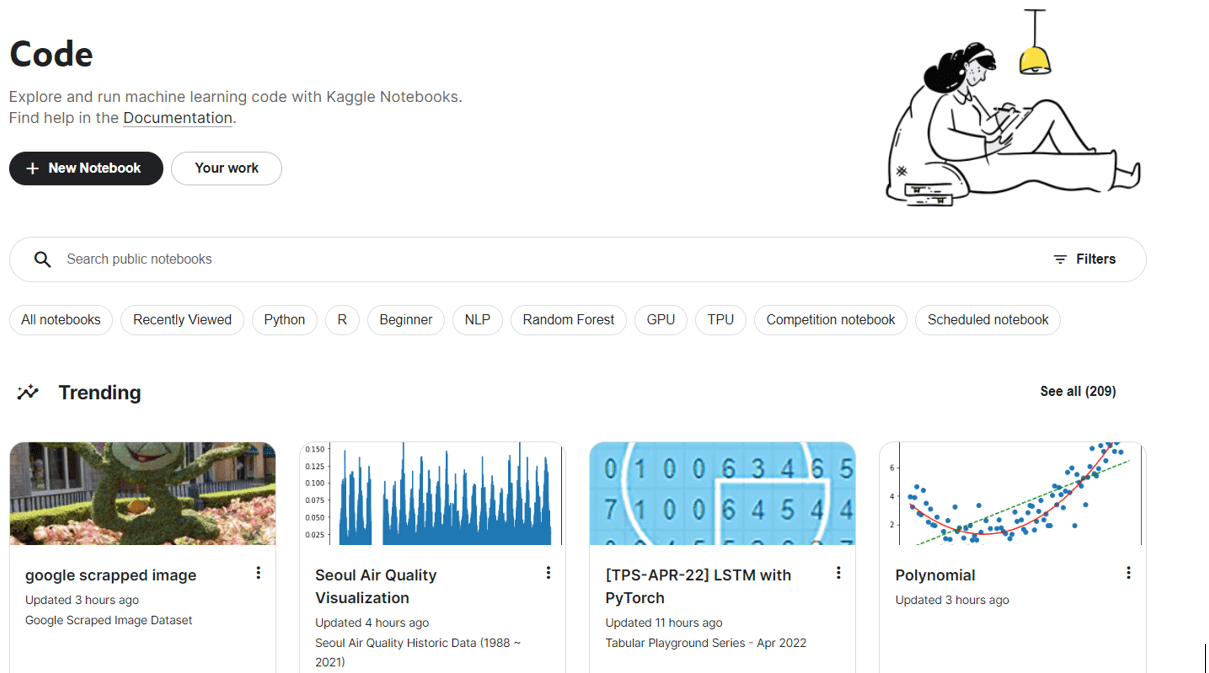
Kaggle 代码页面
这将创建你的新笔记本,它看起来像一个 Jupyter 笔记本,有许多相似的命令和快捷方式。
Kaggle 笔记本
你也可以通过“文件”->“编辑器类型”在笔记本编辑器和脚本编辑器之间切换。
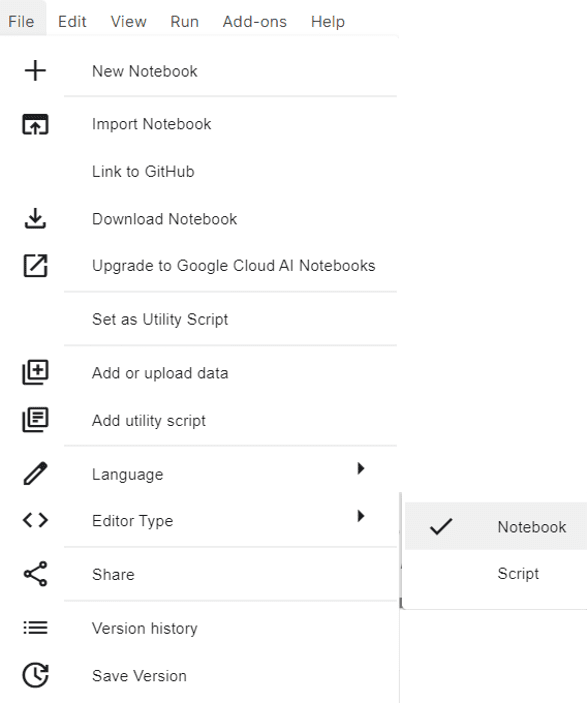
在 Kaggle 笔记本中更改编辑器类型
将编辑器类型更改为脚本会显示此内容
Kaggle 笔记本脚本编辑器类型
想开始学习机器学习 Python 吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
使用带 GPU/TPU 的 Kaggle
谁不爱为机器学习项目提供免费 GPU 时间呢?GPU 可以极大地加速机器学习模型的训练和推理,尤其是深度学习模型。
Kaggle 提供一些免费的 GPU 和 TPU 分配,你可以在你的项目中使用它们。在撰写本文时,在验证你的账户后,每周可提供 30 小时的 GPU 和 20 小时的 TPU。
要将加速器附加到你的笔记本,请转到“设置”▷“环境”▷“首选项”。
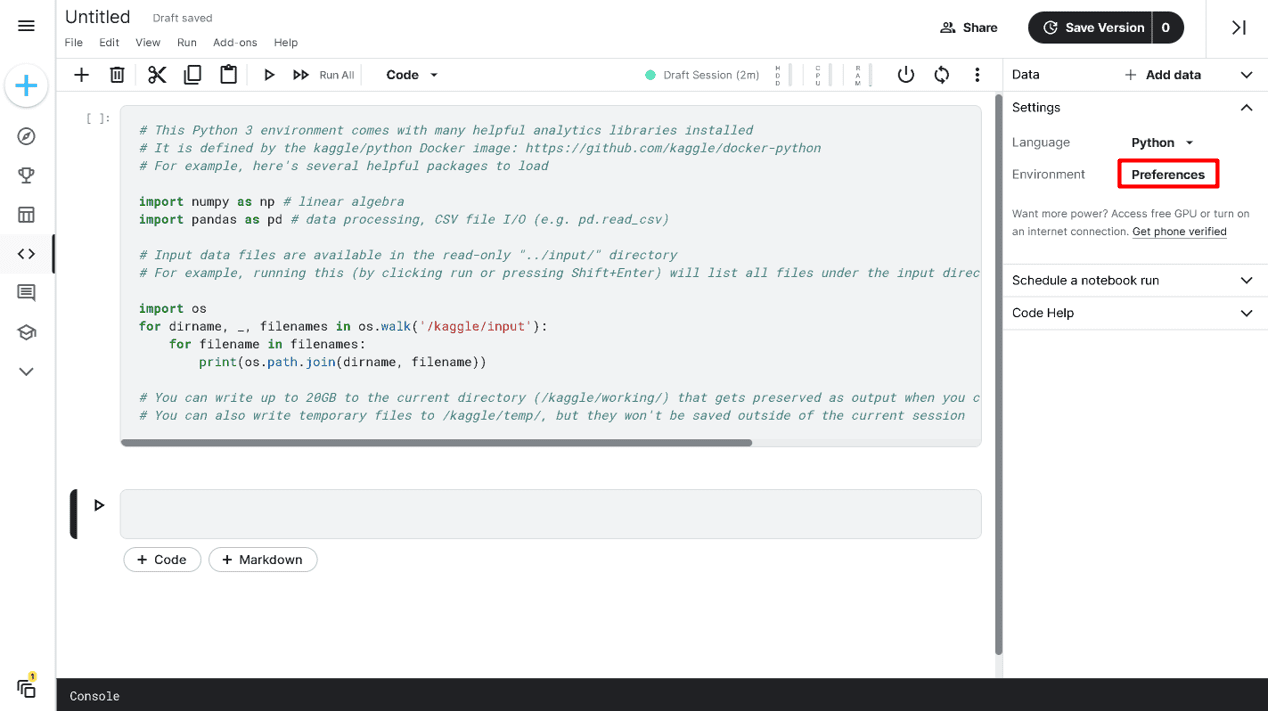
更改 Kaggle 笔记本环境首选项
系统会要求你通过电话号码验证你的账户。
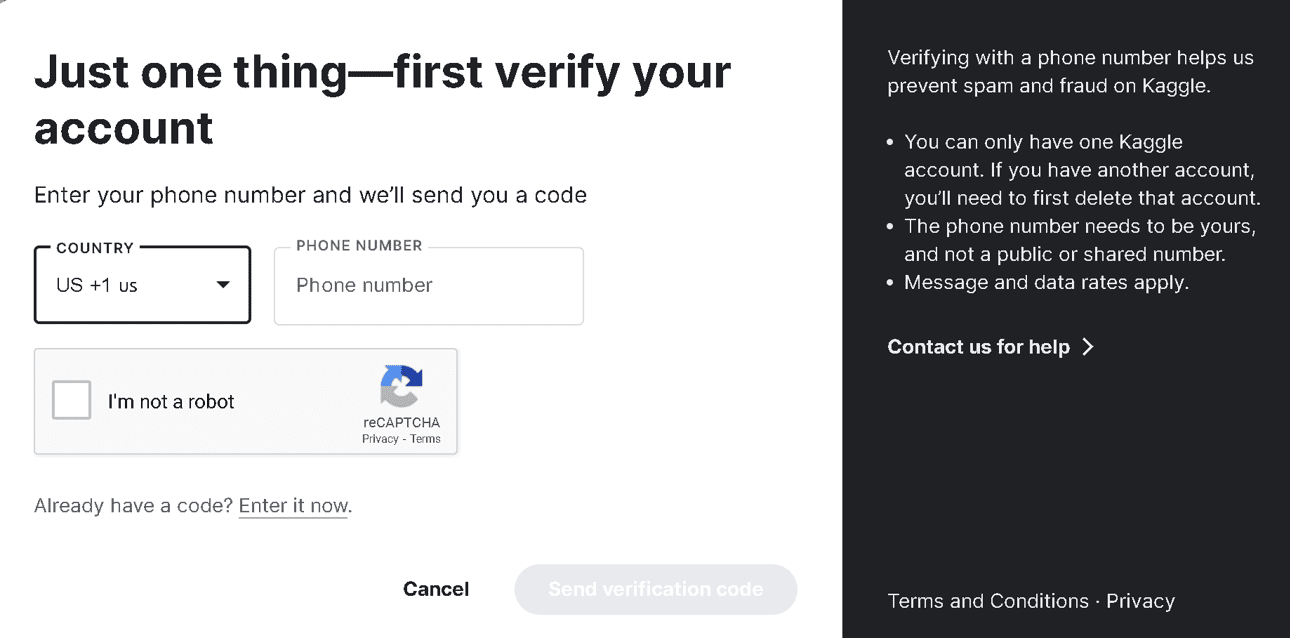
验证手机号码
然后会显示此页面,其中列出了你剩余的可用时间,并提到开启 GPU 会减少可用的 CPU 数量,所以这可能只在进行神经网络的训练/推理时才比较合适。

将 GPU 加速器添加到 Kaggle 笔记本
在 Kaggle 笔记本中使用 Kaggle 数据集
机器学习项目是数据饥渴的怪物,为我们当前的项目寻找数据集或寻找数据集来开始新项目总是一件费力的事情。幸运的是,Kaggle 拥有由用户和竞赛贡献的大量数据集。这些数据集对于寻找当前机器学习项目数据的人或寻找新项目创意的人来说,可能是一个宝库。
让我们探索一下如何将这些数据集添加到我们的 Kaggle 笔记本中。
首先,点击右侧边栏的“添加数据”。
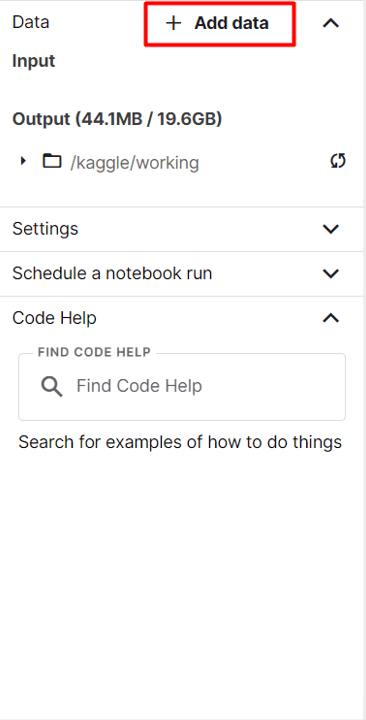
将数据集添加到 Kaggle 笔记本环境
此时应该会弹出一个窗口,其中显示了一些公开可用的数据集,并提供了一个选项,允许你上传自己的数据集供 Kaggle 笔记本使用。
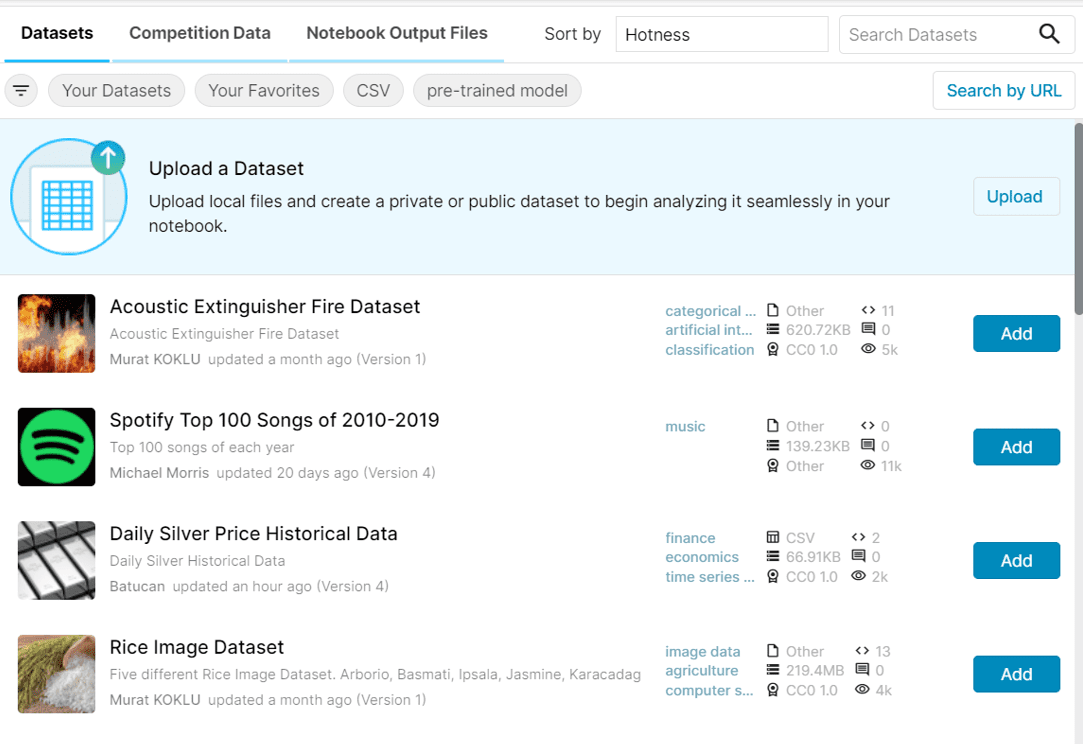
搜索 Kaggle 数据集
我将在本教程中使用经典的泰坦尼克号数据集作为示例,你可以在窗口右上角的搜索栏中输入你的搜索词找到它。
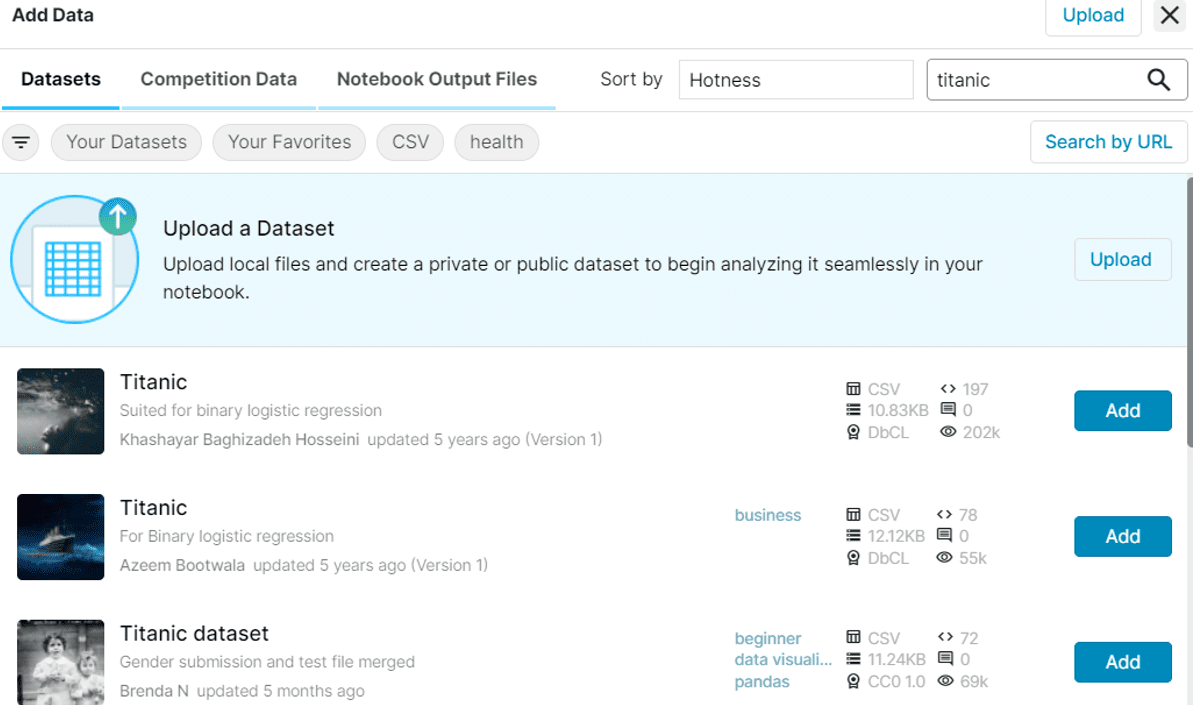
Kaggle 数据集按“泰坦尼克号”关键字筛选
之后,就可以在笔记本中使用该数据集了。要访问文件,请查看文件的路径,并在前面加上 ../input/{path}。例如,泰坦尼克号数据集的文件路径是
|
1 |
../input/titanic/train_and_test2.csv |
在笔记本中,我们可以使用以下方式读取数据:
|
1 2 3 |
import pandas pandas.read_csv("../input/titanic/train_and_test2.csv") |
这使我们能够从文件中获取数据
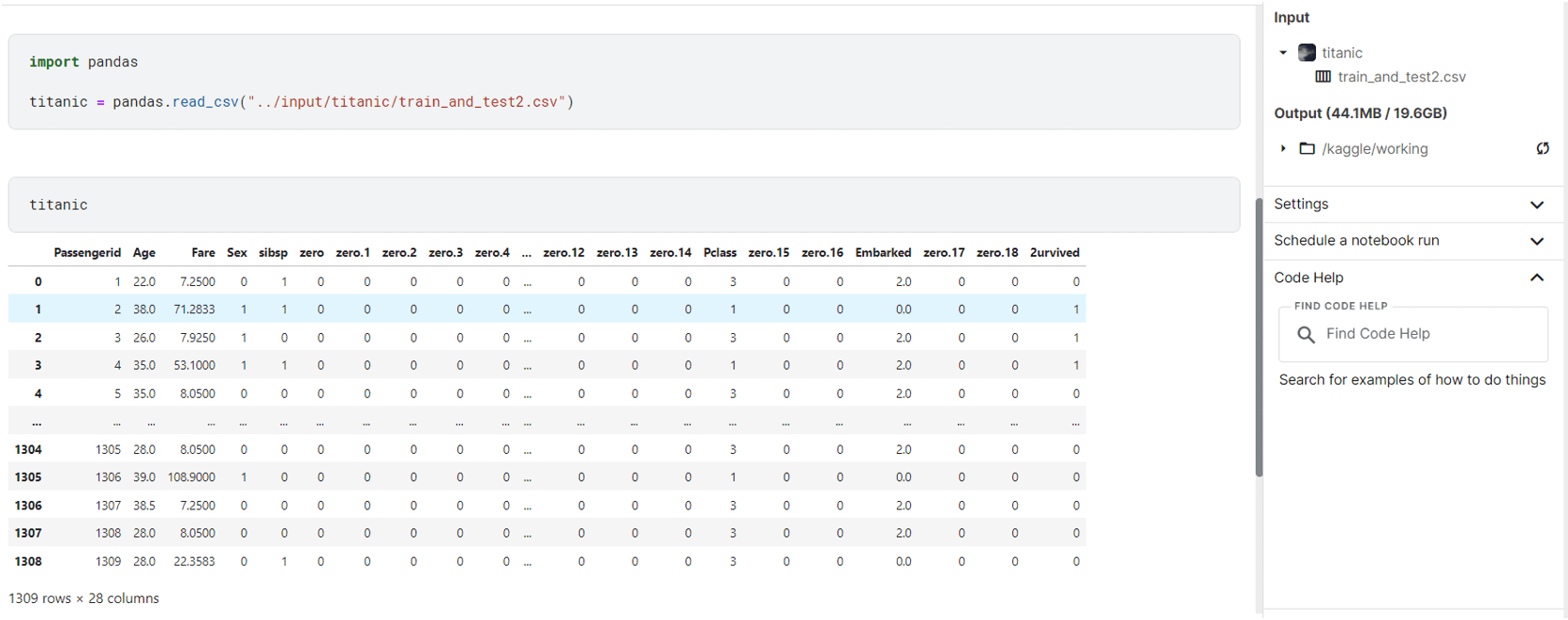
在 Kaggle 笔记本中使用泰坦尼克号数据集
使用 Kaggle 数据集和 Kaggle CLI 工具
Kaggle 还提供了一个公共 API 和一个 CLI 工具,我们可以使用它来下载数据集、与竞赛交互等等。我们将研究如何使用 CLI 工具设置和下载 Kaggle 数据集。
要开始,请使用以下命令安装 CLI 工具:
|
1 |
pip install kaggle |
对于 Mac/Linux 用户,你可能需要:
|
1 |
pip install --user kaggle |
然后,你需要创建一个 API 令牌进行身份验证。转到 Kaggle 网页,点击右上角的个人资料图标,然后转到“账户”。
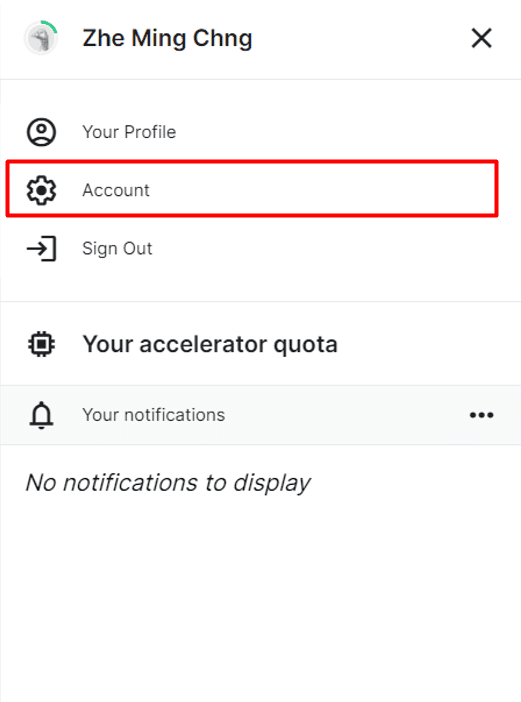
转到 Kaggle 账户设置
从那里,向下滚动到“创建新的 API 令牌”。
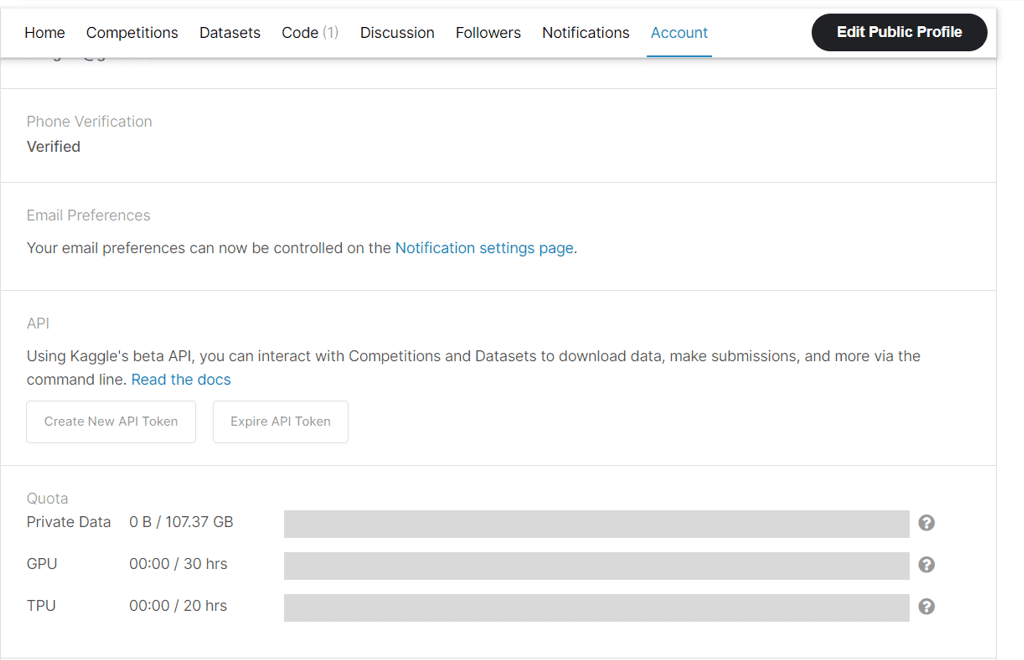
为 Kaggle 公共 API 生成新的 API 令牌
这将下载一个 kaggle.json 文件,你将使用它通过 Kaggle CLI 工具进行身份验证。你必须将其放置在正确的位置才能使其正常工作。对于 Linux/Mac/Unix 类操作系统,应将其放置在 ~/.kaggle/kaggle.json,对于 Windows 用户,应将其放置在 C:\Users\<Windows-username>\.kaggle\kaggle.json。如果将其放置在错误的位置并调用 kaggle 命令,将会出现错误:
|
1 |
OSError: Could not find kaggle.json. Make sure it’s location in … Or use the environment method |
现在,让我们开始下载那些数据集吧!
要使用搜索词(例如 titanic)搜索数据集,我们可以使用:
|
1 |
kaggle datasets list -s titanic |
搜索“titanic”,我们得到:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
$ kaggle datasets list -s titanic ref title size lastUpdated downloadCount voteCount usabilityRating ----------------------------------------------------------- --------------------------------------------- ----- ------------------- ------------- --------- --------------- datasets/heptapod/titanic Titanic 11KB 2017-05-16 08:14:22 37681 739 0.7058824 datasets/azeembootwala/titanic Titanic 12KB 2017-06-05 12:14:37 13104 145 0.8235294 datasets/brendan45774/test-file Titanic dataset 11KB 2021-12-02 16:11:42 19348 251 1.0 datasets/rahulsah06/titanic Titanic 34KB 2019-09-16 14:43:23 3619 43 0.6764706 datasets/prkukunoor/TitanicDataset Titanic 135KB 2017-01-03 22:01:13 4719 24 0.5882353 datasets/hesh97/titanicdataset-traincsv Titanic-Dataset (train.csv) 22KB 2018-02-02 04:51:06 54111 377 0.4117647 datasets/fossouodonald/titaniccsv Titanic csv 1KB 2016-11-07 09:44:58 8615 50 0.5882353 datasets/broaniki/titanic titanic 717KB 2018-01-30 04:08:45 8004 128 0.1764706 datasets/pavlofesenko/titanic-extended Titanic extended dataset (Kaggle + Wikipedia) 134KB 2019-03-06 09:53:24 8779 130 0.9411765 datasets/jamesleslie/titanic-cleaned-data Titanic: cleaned data 36KB 2018-11-21 11:50:18 4846 53 0.7647059 datasets/kittisaks/testtitanic test titanic 22KB 2017-03-13 15:13:12 1658 32 0.64705884 datasets/yasserh/titanic-dataset Titanic Dataset 22KB 2021-12-24 14:53:06 1011 25 1.0 datasets/abhinavralhan/titanic titanic 22KB 2017-07-30 11:07:55 628 11 0.8235294 datasets/cities/titanic123 Titanic Dataset Analysis 22KB 2017-02-07 23:15:54 1585 29 0.5294118 datasets/brendan45774/gender-submisson Titanic: all ones csv file 942B 2021-02-12 19:18:32 459 34 0.9411765 datasets/harunshimanto/titanic-solution-for-beginners-guide Titanic Solution for Beginner's Guide 34KB 2018-03-12 17:47:06 1444 21 0.7058824 datasets/ibrahimelsayed182/titanic-dataset Titanic dataset 6KB 2022-01-27 07:41:54 334 8 1.0 datasets/sureshbhusare/titanic-dataset-from-kaggle Titanic DataSet from Kaggle 33KB 2017-10-12 04:49:39 2688 27 0.4117647 datasets/shuofxz/titanic-machine-learning-from-disaster Titanic: Machine Learning from Disaster 33KB 2017-10-15 10:05:34 3867 55 0.29411766 datasets/vinicius150987/titanic3 The Complete Titanic Dataset 277KB 2020-01-04 18:24:11 1459 23 0.64705884 |
要下载列表中的第一个数据集,我们可以使用:
|
1 |
kaggle datasets download -d heptapod/titanic --unzip |
使用 Jupyter 笔记本读取文件,与 Kaggle 笔记本示例类似,结果如下:
在 Jupyter 笔记本中使用泰坦尼克号数据集
当然,有些数据集非常大,你可能不想将它们保存在自己的磁盘上。尽管如此,这仍然是 Kaggle 为你的机器学习项目提供的免费资源之一!
进一步阅读
本节提供了更多资源,如果你有兴趣深入了解该主题。
- Kaggle: https://www.kaggle.com
- Kaggle API 文档: https://www.kaggle.com/docs/api
总结
在本教程中,你了解了 Kaggle 是什么,如何使用 Kaggle 获取数据集,甚至在 Kaggle 笔记本中获取一些免费的 GPU/TPU 实例。你还看到了如何使用 Kaggle API 的 CLI 工具下载数据集供我们在本地环境中使用。
具体来说,你学习了:
- 什么是 Kaggle
- 如何在 Kaggle 笔记本以及它们的 GPU/TPU 加速器一起使用
- 如何在 Kaggle 笔记本中使用 Kaggle 数据集或使用 Kaggle 的 CLI 工具下载它们
掌握机器学习 Python!

更自信地用 Python 编写代码
...从学习实用的 Python 技巧开始
在我的新电子书中探索如何实现
用于机器学习的 Python
它提供自学教程和数百个可运行的代码,为您提供包括以下技能:
调试、性能分析、鸭子类型、装饰器、部署等等...






这非常棒,我认为比 Kaggle 网站本身提供的信息更好、更及时。
感谢分享这些信息。
不客气,Kasturi!