训练神经网络或大型深度学习模型是一项复杂的优化任务。
训练神经网络的经典算法称为随机梯度下降。众所周知,通过使用在训练过程中变化的学习率,可以提高某些问题的性能并加快训练速度。
在这篇文章中,您将了解如何使用Python中Keras深度学习库的神经网络模型实现各种学习率调度。
阅读本文后,你将了解:
- 如何配置和评估基于时间的学习率调度
- 如何配置和评估基于衰减的学习率调度
通过我的新书《Python深度学习》启动您的项目,书中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2016 年 6 月:首次发布
- 2017 年 3 月更新:更新至 Keras 2.0.2、TensorFlow 1.0.1 和 Theano 0.9.0
- 2019 年 9 月更新:更新至 Keras 2.2.5 API
- 2022 年 7 月更新:更新至 TensorFlow 2.x API

使用Keras的Python深度学习模型学习率调度
照片作者:Columbia GSAPP,部分权利保留。
模型训练的学习率调度
调整随机梯度下降优化过程的学习率可以提高性能并减少训练时间。
有时,这被称为学习率退火或自适应学习率。这里,这种方法被称为学习率调度,其中默认调度使用恒定的学习率来更新网络权重,以用于每个训练周期。
在训练过程中调整学习率最简单、也许最常用的方法是随着时间推移降低学习率。这些方法的好处是在训练过程的早期,当学习率值较大时进行大步更新,然后降低学习率,以便在训练过程的后期对权重进行较小的更新。
这样可以在早期快速学习到好的权重,并在后期进行微调。
以下是两个流行且易于使用的学习率调度:
- 根据周期逐渐降低学习率
- 在特定周期使用较大的衰减来降低学习率
接下来,让我们看看如何在Keras中逐一使用这些学习率调度。
Python 深度学习需要帮助吗?
参加我的免费为期两周的电子邮件课程,发现 MLP、CNN 和 LSTM(附代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
基于时间的学习率调度
Keras内置了基于时间的学习率调度。
SGD类中的随机梯度下降优化算法实现有一个名为decay的参数。该参数在基于时间的学习率衰减调度方程中按如下方式使用:
|
1 |
学习率 = 学习率 * 1/(1 + decay * epoch) |
当decay参数为零(默认值)时,它不会影响学习率。
|
1 2 |
学习率 = 0.1 * 1/(1 + 0.0 * 1) 学习率 = 0.1 |
当指定decay参数时,它会按照给定的固定量降低前一个周期的学习率。
例如,如果您使用初始学习率0.1和衰减0.001,前五个周期的学习率将如下调整:
|
1 2 3 4 5 6 |
周期 学习率 1 0.1 2 0.0999000999 3 0.0997006985 4 0.09940249103 5 0.09900646517 |
将此扩展到100个周期将产生以下学习率(y轴)与周期(x轴)的图:
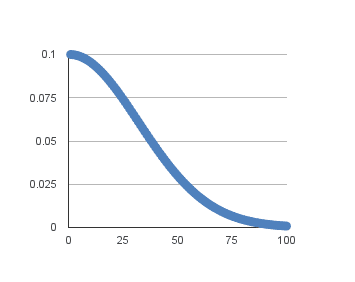
基于时间的学习率调度
您可以通过设置以下方式创建良好的默认调度:
|
1 2 3 |
衰减 = 学习率 / 周期数 衰减 = 0.1 / 100 衰减 = 0.001 |
以下示例演示了如何在Keras中使用基于时间的学习率自适应调度。
该示例在Ionosphere二元分类问题中进行了演示。这是一个小型数据集,您可以从UCI机器学习存储库下载。将数据文件放在工作目录中,文件名为ionosphere.csv。
离子层数据集非常适合练习神经网络,因为所有输入值都是同等尺度的小数值。
构建了一个小型神经网络模型,其中包含一个具有34个神经元、使用ReLU激活函数的隐藏层。输出层有一个神经元,使用Sigmoid激活函数,以便输出概率类的值。
随机梯度下降的学习率已设置为较高的值0.1。模型训练50个周期,decay参数设置为0.002,计算方式为0.1/50。此外,在使用自适应学习率时,使用动量可能是一个好主意。在本例中,我们使用动量值0.8。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 基于时间的学习率衰减 from pandas import read_csv from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.optimizers import SGD 从 sklearn.preprocessing 导入 LabelEncoder # 加载数据集 dataframe = read_csv("ionosphere.csv", header=None) dataset = dataframe.values # 分割为输入 (X) 和输出 (Y) 变量 X = dataset[:,0:34].astype(float) Y = dataset[:,34] # 将类别值编码为整数 编码器 = LabelEncoder() encoder.fit(Y) Y = encoder.transform(Y) # 创建模型 model = Sequential() model.add(Dense(34, input_shape=(34,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # 编译模型 epochs = 50 learning_rate = 0.1 decay_rate = learning_rate / epochs momentum = 0.8 sgd = SGD(learning_rate=learning_rate, momentum=momentum, decay=decay_rate, nesterov=False) model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy']) # 拟合模型 model.fit(X, Y, validation_split=0.33, epochs=epochs, batch_size=28, verbose=2) |
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑运行示例几次并比较平均结果。
该模型在67%的数据集上进行训练,并使用33%的验证数据集进行评估。
运行示例显示分类准确率为99.14%。这高于基线(不带学习率衰减或动量时为95.69%)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
... 周期 45/50 0秒 - loss: 0.0622 - acc: 0.9830 - val_loss: 0.0929 - val_acc: 0.9914 第 46/50 轮 0秒 - loss: 0.0695 - acc: 0.9830 - val_loss: 0.0693 - val_acc: 0.9828 第 47/50 轮 0秒 - loss: 0.0669 - acc: 0.9872 - val_loss: 0.0616 - val_acc: 0.9828 第 48/50 轮 0秒 - loss: 0.0632 - acc: 0.9830 - val_loss: 0.0824 - val_acc: 0.9914 第 49/50 轮 0秒 - loss: 0.0590 - acc: 0.9830 - val_loss: 0.0772 - val_acc: 0.9828 第 50/50 轮 0秒 - loss: 0.0592 - acc: 0.9872 - val_loss: 0.0639 - val_acc: 0.9828 |
基于衰减的学习率调度
另一种常用的深度学习模型学习率调度是在训练过程中定期衰减学习率。
通常,此方法是通过每固定数量的周期将学习率减半来实现的。例如,我们可能有一个初始学习率为0.1,每十个周期衰减0.5。前十个周期的训练将使用0.1的值,接下来的十个周期将使用0.05的学习率,依此类推。
如果将此示例的学习率绘制到100个周期,则会得到下图,显示学习率(y轴)与周期(x轴)的关系。
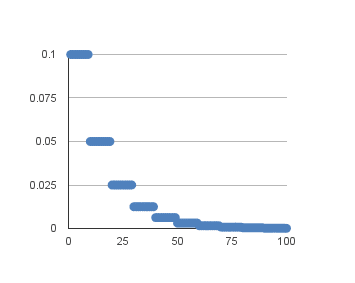
基于衰减的学习率调度
您可以使用LearningRateScheduler回调函数在Keras中实现这一点。
LearningRateScheduler回调允许您定义一个函数,该函数以周期号作为参数,并返回用于随机梯度下降的学习率。使用时,将忽略随机梯度下降中指定Thus learning rate。
在下面的代码中,我们使用与之前相同的示例,即在Ionosphere数据集上使用单隐藏层网络。定义了一个新的step_decay()函数,实现了以下方程:
|
1 |
学习率 = 初始学习率 * 衰减率 ^ floor(周期 / 周期衰减) |
在这里,InitialLearningRate是初始学习率(例如0.1),DropRate是每次更改学习率时修改学习率的量(例如0.5),Epoch是当前周期号,EpochDrop是更改学习率的频率(例如10)。
请注意,SGD类中的学习率设置为0,以清楚地表明它未使用。尽管如此,如果您想在此学习率调度中使用动量,则可以在SGD中设置动量项。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# 基于衰减的学习率衰减 from pandas import read_csv import math from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.optimizers import SGD from sklearn.preprocessing import LabelEncoder from tensorflow.keras.callbacks import LearningRateScheduler # 学习率调度 def step_decay(epoch): initial_lrate = 0.1 drop = 0.5 epochs_drop = 10.0 lrate = initial_lrate * math.pow(drop, math.floor((1+epoch)/epochs_drop)) return lrate # 加载数据集 dataframe = read_csv("ionosphere.csv", header=None) dataset = dataframe.values # 分割为输入 (X) 和输出 (Y) 变量 X = dataset[:,0:34].astype(float) Y = dataset[:,34] # 将类别值编码为整数 编码器 = LabelEncoder() encoder.fit(Y) Y = encoder.transform(Y) # 创建模型 model = Sequential() model.add(Dense(34, input_shape=(34,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # 编译模型 sgd = SGD(learning_rate=0.0, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy']) # 学习率调度回调 lrate = LearningRateScheduler(step_decay) callbacks_list = [lrate] # 拟合模型 model.fit(X, Y, validation_split=0.33, epochs=50, batch_size=28, callbacks=callbacks_list, verbose=2) |
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑运行示例几次并比较平均结果。
运行示例后,在验证数据集上的分类准确率为99.14%,这同样是相对于该问题的模型基线而言的改进。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
... 周期 45/50 0秒 - loss: 0.0546 - acc: 0.9830 - val_loss: 0.0634 - val_acc: 0.9914 第 46/50 轮 0秒 - loss: 0.0544 - acc: 0.9872 - val_loss: 0.0638 - val_acc: 0.9914 第 47/50 轮 0秒 - loss: 0.0553 - acc: 0.9872 - val_loss: 0.0696 - val_acc: 0.9914 第 48/50 轮 0秒 - loss: 0.0537 - acc: 0.9872 - val_loss: 0.0675 - val_acc: 0.9914 第 49/50 轮 0秒 - loss: 0.0537 - acc: 0.9872 - val_loss: 0.0636 - val_acc: 0.9914 第 50/50 轮 0秒 - loss: 0.0534 - acc: 0.9872 - val_loss: 0.0679 - val_acc: 0.9914 |
使用学习率调度程序的技巧
本节列出了一些在使用神经网络学习率调度时需要考虑的技巧。
- 增加初始学习率。由于学习率很可能降低,因此从一个较大的值开始衰减。较大的学习率将导致权重发生更大的变化,尤其是在开始时,从而使您在后期受益于微调。
- 使用较大的动量。使用较大的动量值将有助于优化算法在学习率缩小到较小值时继续朝着正确的方向进行更新。
- 尝试不同的调度。目前尚不清楚应使用哪种学习率调度,因此请尝试几种具有不同配置选项的方法,看看哪种最适合您的问题。另外,尝试指数衰减的调度,甚至响应模型在训练集或测试集上准确性的调度。
总结
在本文中,您了解了训练神经网络模型的学习率调度。
阅读本文后,您将了解:
- 如何在Keras中配置和使用基于时间的学习率调度
- 如何在Keras中开发自己的基于衰减的学习率调度
您对神经网络学习率调度或本文有任何疑问吗?请在评论中提问,我将尽力回答。





")
太棒了
谢谢,Hunaina。
不错的帖子
你好 Jason,
有趣的帖子。我们不能将这种学习率和动量用于SGD以外的优化器吗?由于“Adam”在大多数数据集上表现良好,我想尝试为“Adam”优化器调整学习率和动量。此外,我对此进行了快速研究,发现“Adam”已经具有衰减的学习率。这是真的吗?其他优化器呢?
我想实现一个与成本函数呈指数衰减的学习率?例如,学习率更新如下:
eta = eta0*exp(CostFunction)
这样,当成本高时使用较大的学习率,反之亦然。
您知道如何在Keras中实现这一点吗?谢谢!
嗨,Yuzhen,
我建议您在Excel或其他工具中开发您的衰减函数,以便进行测试和绘图。使用上面线性衰减函数的输入/输出来作为起点。
然后,您可以将您的函数插入到上面的示例之一中。
告诉我进展如何。
嗨,Jason!
感谢您的精彩帖子!非常有帮助!
还有个问题:我使用了“基于衰减的学习率调度”,如何在终端打印出当前的学习率?
祝好,
搞定了!只需打印出
好问题,你也许可以从自定义函数中调用print()。如果可以的话,请告诉我。
权重衰减是每个小批量更新还是每个周期更新?根据https://groups.google.com/forum/#!topic/keras-users/7KM2AvCurW0,它是每个小批量更新。在我的问题中,一个周期包含800个小批量。
如果您自己实现衰减,您可以控制调度,就像上面的教程一样(例如,它是周期的函数而不是小批量的函数)。
与SGD相比,将这些权重衰减技术用于Adam或RMSprop等自适应优化器是否有意义?还是会多此一举?
我想是的,但要在您的具体问题上进行测试以确定。数据说了算。
非常感谢这个指南!是否有一种方法可以看到更新之前的代码?我有一个限制,目前需要使用Keras 1.2,在应用SGD时,我遇到了
File “/usr/lib64/python2.7/site-packages/keras/models.py”, line 924, in fit_generator
pickle_safe=pickle_safe)
File “/usr/lib64/python2.7/site-packages/keras/engine/training.py”, line 1401, in fit_generator
self._make_train_function()
File “/usr/lib64/python2.7/site-packages/keras/engine/training.py”, line 713, in _make_train_function
self.total_loss)
TypeError: unbound method get_updates() must be called with SGD instance as first argument (got list instance instead)
我猜这是由于一些API更改,但我没发现。
抱歉,我不再拥有旧代码。
Jason,在Keras中使用Adam优化器时,是否有选项可以指定动量?我只在SGD中看到动量选项。
据我所知,没有。请仔细检查API以确保。
你好,我有一个问题
我想在训练期间打印学习率信息,但使用下面的代码不起作用
def step_decay(epoch)
initial_lrate = 0.001
drop = 0.5
epochs_drop = 100.0
lrate = initial_lrate * math.pow(drop, math.floor((1+epoch)/epochs_drop))
print (‘epoch: ‘ + str(epoch) + ‘, learning rate: ‘ + str(lrate)) # added
return lrate
NUM_EPOCHS = 700
BATCH_SIZE = 128
for each_epoch in range(0, NUM_EPOCHS)
lrate = callbacks.LearningRateScheduler(step_decay)
callbacks_list = [lrate]
history = model.fit(x_train, y_train, batch_size=BATCH_SIZE, epochs=1, callbacks=callbacks_list, verbose=2, validation_data=[x_test, y_test])
prediction_test = model.predict(x_test).flatten()
我是否必须将“epochs”设置为NUM_EPOCHS并删除for循环才能显示lrate?
帖子中的示例对您有用吗?
也许从一个能工作的示例开始,然后一次修改一个部分以达到您期望的结果?
示例可以工作,但我希望在训练期间显示学习率。
我期望回调函数中的print能够起作用。
请确保您是从命令行运行,而不是在笔记本或IDE中运行。
哦,不用了,它在没有for循环的情况下显示了每个周期的更改lrate。
训练期间显示了很多信息(verbose=1),我错过了lrate的报告。
谢谢,
很高兴听到这个消息。
嗨,Jason,
我知道Keras可以调整学习率,但所有选项似乎只包含一些衰减或降低学习率的功能。我想知道是否可以创建一个自定义调度,其功能类似于ReduceLROnPlateau,它会检查损失是否在连续几个周期内停止下降,如果是,则降低LR。但是,在几次“衰减”之后,下一次损失停滞时会增加学习率,然后之后再次继续衰减。
我的想法是,你可能会陷入一个局部最小值,除非你增加学习率,否则你就无法逃脱,然后继续下降到全局最小值。
创建学习率的函数是否合理?Keras会接受吗?
谁能给我一个关于如何编写这个函数的思路?
谢谢!
当然,我认为这不会有问题。您可能需要一个对象而不是一个函数来存储状态。我没有这样做过,所以可能需要一些实验。
嗨,Jason,
这篇帖子对我帮助很大。我该如何调整每个周期的学习率值?
您可以直接将此实现为自己的方法,遵循上面的教程。
我想知道如何使用 Keras 为每个层更改学习率?
好问题,我暂时不确定。也许可以在 Keras 用户组询问。
https://machinelearning.org.cn/get-help-with-keras/
嗨,我想绘制 adam 优化器的学习率曲线,我是否应该在 fit 函数中编写 callbacks=[lr]?
每个模型参数(权重)都有一个学习率,绘制每个参数将非常具有挑战性。
我使用了此链接中的教程:https://enlight.nyc/neural-network/ 并将其应用于 6 输入数据集。我的值总是收敛到约 0、0.5 或 1,具体取决于隐藏层的数量。每次调用 train 后都会发生这种情况。我怀疑这是因为它不包含学习率或偏差。在哪里可以将学习率应用到这个代码中?
如果您对别人的教程有疑问,也许直接问他们?
Jason博士您好,
感谢您关于 Keras 的信息丰富的帖子。
我按照您的教程使用 Drop 学习率调度,效果很好,并且可以在 step_decay() 函数中打印每个 epoch 的变化学习率。
由于内存不足,我保存了这个模型并在另一个脚本中重新加载它。
模型会重新加载并仅从前一个 epoch 开始优化。但我看不到回调的学习率。也许学习率调度回调状态未保存。您知道如何也将之前的回调状态用于重新加载的模型吗?
您可能需要手动重新播种它。
我们应该如何在 keras 中记录训练期间的学习率?
tensorboard 可以在每个 epoch 绘制学习率。
抱歉,我没有用于 tensorboard 监控学习率的示例。
如果我们想知道每个 epoch 训练期间的学习率,我们可以使用 keras 做什么?
非常感谢这篇非常有用的教程。
有没有一种方法可以在准确率下降时自动降低学习率?
是的,您可以配置一个学习率调度来实现此目的。
您是指“LearningRateScheduler”吗?
如果是,据我所知关于“LearningRateScheduler”,
我可以为一系列 epoch 手动设置学习率。
例如
def lr_schedule(epoch)
lrate = 0.0007
if epoch > 10
lrate = 0.0001
return lrate
lr_scheduler=LearningRateScheduler(lr_schedule)
callbacks_list = [lr_scheduler]
history=model.fit(X, Y, epochs=50, batch_size=80,
callbacks = callbacks_list)
但是,“LearningRateScheduler”是如何自动设置学习率的?
当使用 SGD 时,它会定位模型使用的 SGD 实例并设置 lr 参数。
您能举个例子吗,拜托?
抱歉,我没有能力准备示例。
那么,在 step_decay 函数中,epoch 参数的值是什么时候设置的?它是否意味着总 epochs?
它是当前 epoch 号。
也许我不明白这个问题?
以下是我用于调度器的代码,我希望当 epoch 处于 50% 时将学习率除以初始速率的 10,当 epoch 处于 75% 时除以 100。
def lr_schedule(epochs,lr)
initial_lr = 0.1
if epochs == epochs*0.5
lr = np.float32(initial_lr/10.0)
return lr
if epochs == epochs*0.75
lr = np.float32(initial_lr/100.0)
return lr
learning_scheduler=tf.keras.callbacks.LearningRateScheduler(lr_schedule)
from keras.callbacks import ModelCheckpoint
# 检查点
filepath=”weights-improvement-reg-{epoch:02d}-{val_acc:.2f}.hdf5″
checkpoint = ModelCheckpoint(filepath, monitor=’val_acc’, verbose=1, save_best_only=True, mode=’max’)
callbacks_list = [checkpoint,learning_scheduler]
# 创建数据生成器
datagen = ImageDataGenerator(rotation_range=15,width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True)
# 拟合模型
steps = int(X_train.shape[0] / batch_size)
history = model.fit_generator(datagen.flow(X_train, y_train, batch_size=batch_size), steps_per_epoch=steps, epochs=epochs, validation_data=(X_test, y_test), callbacks=callbacks_list, verbose=1)
错误
1352 lr = self.schedule(epoch)
1353 if not isinstance(lr, (float, np.float32, np.float64))
-> 1354 raise ValueError(‘The output of the “schedule” function ‘
1355 ‘should be float.’)
1356 K.set_value(self.model.optimizer.lr, lr)
ValueError: The output of the “schedule” function should be a float.
我遇到了上述错误。请帮助。
提前感谢!
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
抱歉,我看到有人发布了一个小的代码片段,所以我才这样做。谢谢!
不客气。
抱歉,我忘了在我的评论中添加。
sgd = tf.keras.optimizers.SGD(lr=0.1,momentum=0.9, decay=1e-4,nesterov=True)
model.compile(loss=’categorical_crossentropy’,optimizer=sgd,metrics=[‘accuracy’])
嗨,杰森,
当我对另一个数据集执行上述代码时,每个 epoch 的损失和准确率都没有变化……您能给我一些建议吗?
我不知道为什么会这样。也许可以尝试更多的损失值?
你好,Jason。
我想根据 val_accuracy 更改学习率。如何实现?
您可以配置回调来监控 val_accuracy。
你好,非常实用的帖子!
虽然我有点困惑于第一个图,“基于时间的学习率调度”。
我以为 Keras 在衰减率时所做的是
lr(n) = lr(0) / (1+k*n)
但这似乎是你计算时得到的图
lr(n) = lr(n-1) / (1+k*n)。
如何在 Keras 中获得这种类型的衰减?
你好 Matteo……以下资源应该能增加清晰度。
https://machinelearning.org.cn/understand-the-dynamics-of-learning-rate-on-deep-learning-neural-networks/