Stable Diffusion 的深度学习模型非常庞大,权重文件大小达几个 GB。重新训练模型意味着更新大量权重,这是一项艰巨的任务。有时我们必须修改 Stable Diffusion 模型,例如,为提示词定义新的解释,或使模型默认生成不同风格的绘画。确实,有方法可以在不修改现有模型权重的情况下进行这种扩展。在本篇文章中,您将了解低秩适应(LoRA),这是修改 Stable Diffusion 行为最常用的技术。
通过我的书籍 《使用 Stable Diffusion 精通数字艺术》 开启您的项目。它提供了带有工作代码的自学教程。
让我们开始吧。

在 Stable Diffusion 中使用 LoRA
照片来源:Agent J。保留部分权利。
概述
这篇文章分为三个部分;它们是
- 什么是低秩适应
- 检查点还是 LoRA?
- LoRA 模型示例
什么是低秩适应
LoRA,即低秩适应,是一种轻量级的训练技术,用于微调大型语言模型和 Stable Diffusion 模型,而无需进行完整的模型训练。对由数十亿参数组成的大型模型的完整微调,本身就成本高昂且耗时。LoRA 的工作原理是在模型中添加少量新的权重进行训练,而不是重新训练模型的整个参数空间。这大大减少了可训练参数的数量,从而实现了更快的训练时间和更易于管理的模型文件大小(通常在几百兆字节左右)。这使得 LoRA 模型更容易存储、共享和在消费级 GPU 上使用。
简单来说,LoRA 就像给现有的工厂增加一个小型专业工人团队,而不是从头开始建造一个全新的工厂。这使得对模型进行更有效和有针对性的调整成为可能。
LoRA 是 Microsoft 研究人员提出的最先进的微调方法,用于将大型模型适应特定概念。典型的完整微调涉及在神经网络的每个密集层中更新整个模型的权重。Aghajanyan 等人 (2020) 解释说,预训练的过度参数化模型实际上驻留在低内在维度上。LoRA 方法基于这一发现,通过将权重更新限制在模型的残差上。
假设 $W_0\in \mathbb{R}^{d\times k}$ 表示一个预训练的权重矩阵,大小为 $\mathbb{R}^{d\times k}$(即实数矩阵,有 $d$ 行 $k$ 列),它通过 $\Delta W$(更新矩阵)进行更改,使得微调后的模型权重为
$$ W’ = W_0 + \Delta W$$
LoRA 使用技术通过秩分解来降低此更新矩阵 $\Delta W$ 的秩,使其变为
$$
\Delta W = B \times A
$$
其中 $B\in\mathbb{R}^{d\times r}$ 且 $A\in\mathbb{R}^{r\times k}$,使得 $r\ll \min(k,d)$。
将矩阵分解为两个低秩矩阵
通过冻结 $W_0$(以节省内存),我们可以微调 $A$ 和 $B$,它们包含用于适应的可训练参数。这使得微调后的模型的前向传播如下所示:
$$
h = W’x = W_0 x + BA x
$$
对于 Stable Diffusion 微调,足以将秩分解应用于交叉注意力层(如下所示的阴影部分),这些层负责整合提示词和图像信息。具体来说,这些层中的权重矩阵 $W_O$、$W_Q$、$W_K$ 和 $W_V$ 被分解为低秩的权重更新。通过冻结其他 MLP 模块并仅微调分解后的矩阵 $A$ 和 $B$,LoRA 模型可以实现更小的文件大小,同时速度更快。
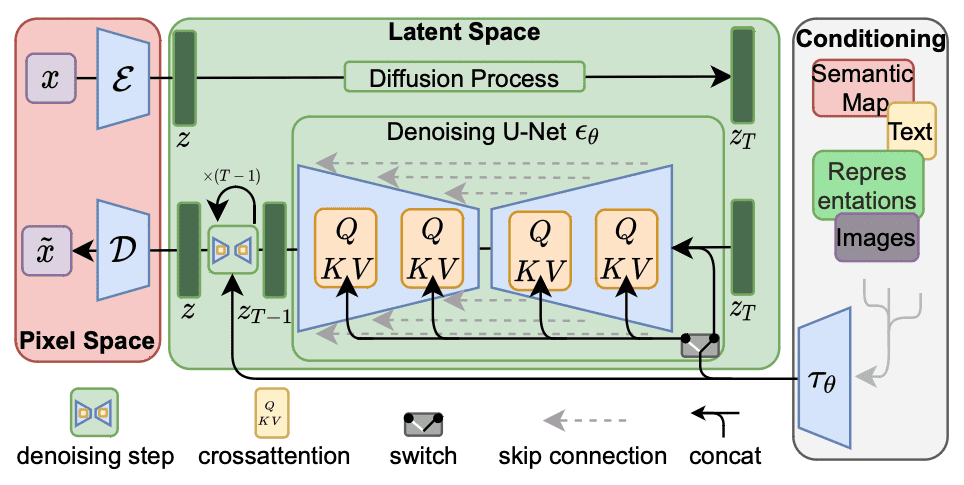
Stable Diffusion 的工作流程。LoRA 可以修改交叉注意力模块。
检查点还是 LoRA?
检查点模型是在训练过程中特定状态下保存的完整预训练模型。它包含训练过程中学习到的所有参数,可用于推理或微调。然而,微调检查点模型需要更新模型中的所有权重,这可能计算成本高昂,并且文件大小很大(对于 Stable Diffusion 通常为几个 GB)。
另一方面,LoRA(低秩适应)模型更小、更高效。它充当一个适配器,构建在检查点模型(基础模型)之上。LoRA 模型仅更新检查点模型参数的一个子集(增强检查点模型)。这使得这些模型体积小(通常为 2MB 到 500MB),并且可以频繁微调以适应特定概念或风格。
例如,Stable Diffusion 模型微调可以使用 DreamBooth 完成。DreamBooth 是一种微调方法,它更新整个模型以适应特定概念或风格。虽然它可以产生令人印象深刻的结果,但它有一个显著的缺点:微调模型的尺寸。由于 DreamBooth 会更新整个模型,因此生成的检查点模型可能非常大(约 2 到 7 GB),并且需要大量 GPU 资源进行训练。相比之下,LoRA 模型所需的 GPU 资源大大减少,但推理结果仍可与 DreamBooth 检查点相媲美。
虽然 LoRA 是最常用的方法,但它并不是修改 Stable Diffusion 的唯一方法。参考上图所示的工作流程,交叉注意力模块接收输入 $\tau_\theta$,该输入通常源自将提示文本转换为文本嵌入。修改嵌入是文本反转所做的,用于改变 Stable Diffusion 的行为。文本反转比 LoRA 更小、更快。但是,文本反转存在一个限制:它们仅微调特定概念或风格的文本嵌入。负责生成图像的 U-Net 保持不变。这意味着文本反转只能生成与训练数据相似的图像,而无法产生其已知范围之外的内容。
LoRA 模型示例
在 Stable Diffusion 的上下文中,存在许多不同的 LoRA 模型。一种分类方法是根据 LoRA 模型的功能进行划分。
- 角色 LoRA:这些模型经过微调,以捕捉特定角色的外观、身体比例和表情,这些角色通常出现在卡通、电子游戏或其他媒体中。它们对于创作粉丝艺术、游戏开发和动画/插画目的很有用。
- 风格 LoRA:这些模型经过特定艺术家或风格的艺术作品微调,以在该风格下生成图像。它们通常用于将参考图像风格化为特定美学。
- 服装 LoRA:这些模型经过特定艺术家或风格的艺术作品微调,以在该风格下生成图像。它们通常用于将参考图像风格化为特定美学。
以下是一些示例

在 Civitai 上使用角色 LoRA“悟空黑 [七龙珠超]”创建的图像,作者:TheGooder

在 Civitai 上使用风格 LoRA“动漫线稿/漫画风格 (线稿/線画/マンガ風/漫画风)”创建的图像,作者:CyberAIchemist。

在 Civitai 上使用服装 LoRA“动漫线稿/漫画风格 (线稿/線画/マンガ風/漫画风)”创建的图像,作者:YeHeAI。
查找 LoRA 模型文件的最流行的地方是 Civitai。如果您正在使用 Stable Diffusion Web UI,您只需下载模型文件并将其放入文件夹 stable-diffusion-webui/models/Lora 中。
要从 Web UI 使用 LoRA,您只需将 LoRA 的名称放在尖括号中作为提示词的一部分。例如,上面的一张图片是使用以下提示词生成的:
最佳杰作,1个女孩,单独,令人难以置信的超高分辨率,连帽衫,耳机,街道,户外,雨,霓虹灯,浅笑,戴着兜帽,手插在口袋里,看向别处,侧面,线稿,单色,<lora:animeoutlineV4_16:1>
提示词中的“<lora:animeoutlineV4_16:1>”表示使用名为 animeoutlineV4_16.safetensors 的模型文件,并以权重 1 应用它。请注意,提示词中除了引用 LoRA 模型外,没有提及任何关于线稿风格的内容。因此,您可以看到 LoRA 模型对输出产生了巨大的影响。如果您感到好奇,通常可以在 Civitai 上找到生成图片时使用的提示词和其他参数。
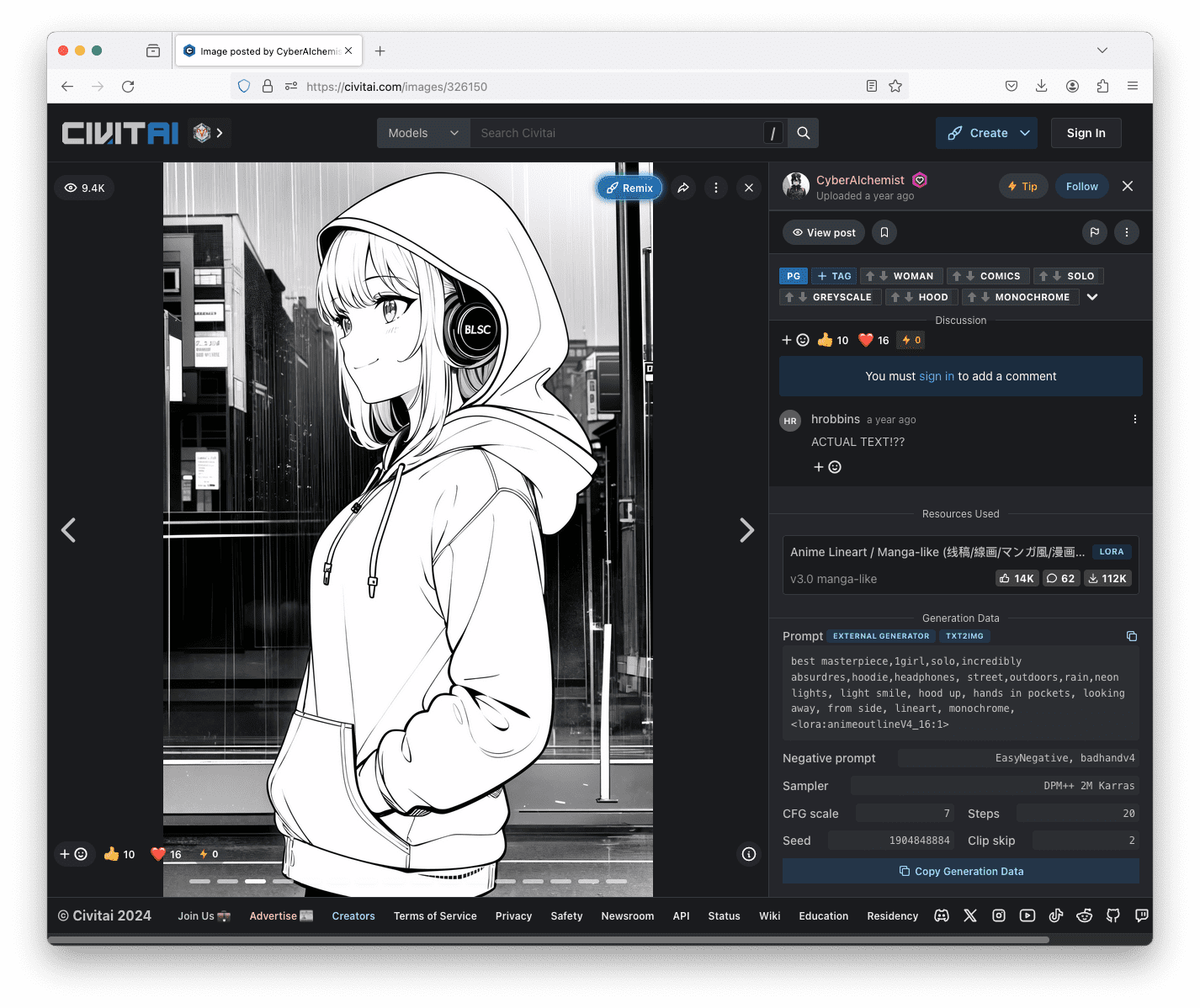
查看 Civitai 上发布的图片,您可以在屏幕右侧看到生成该图片时使用的提示词和其他参数。
最后说明一点,LoRA 取决于您使用的模型。例如,Stable Diffusion v1.5 和 SD XL 在架构上不兼容,因此您需要一个与您的基础模型版本匹配的 LoRA。
进一步阅读
以下是一些介绍 LoRA 微调技术的论文:
- “LoRA: Low-Rank Adaptation of Large Language Models”,作者 Hu 等人 (2021)
- “Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning”,作者 Aghajanyan 等人 (2020)
总结
在本篇文章中,您了解了 LoRA 在 Stable Diffusion 中的作用以及为什么它是一种轻量级的增强。您还了解到,在 Stable Diffusion Web UI 中使用 LoRA 与在提示词中添加一个额外的关键字一样简单。许多 Stable Diffusion 用户开发了 LoRA 模型并在互联网上发布供您下载。您可以找到一个模型,轻松地更改生成结果,而无需过多担心如何描述您想要的风格变化。
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
这本书提供了自学教程,其中包含所有工作代码(Python),将您从新手引导为图像生成专家。它教您如何设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数等等……所有这些都是为了帮助您创作出令人惊叹的数字艺术。

")




您好,我有一个问题,Stable Diffusion 无法生成带有正确文本的图像。例如,当要求创建带有特定文本的图像时,Stable Diffusion 和许多其他模型最终会在图像中生成乱码和无意义的文本。您能推荐一些可以满足我任务的模型吗?
谢谢你
很棒的文章。感谢分享。
QQ:我们如何优化超参数并决定初始化方案?有没有直接的方法来精确地定位潜在向量空间中的特定特征?例如,对于人脸,如何精确地定位/提取“鼻子”向量及其对应的权重,以便仅标记该特定向量可以被初始化/训练?
嗨 Lokesh…### LoRA 中的超参数优化和初始化
LoRA,即低秩适应,是一种用于高效适应预训练模型的技术,尤其是在大型语言模型中,通过向现有权重添加低秩矩阵。超参数优化和初始化方案对于确保模型在适应后表现良好至关重要。
#### 1. 超参数优化
– **网格搜索**:这涉及测试一组超参数(如学习率、适应秩和批量大小)以找到最佳组合。
– **随机搜索**:这里,超参数从定义的范围内随机选择。此方法通常比网格搜索更有效,尤其是在高维空间中。
– **贝叶斯优化**:一种更智能的超参数优化方法,通过构建一个概率模型来映射从超参数空间到在验证集上评估的目标。
– **自动化机器学习工具**:Google 的 Vizier、Hyperopt 或 AutoML 等工具可以自动化搜索最佳超参数的过程。
#### 2. 选择初始化方案
– **初始化方法**:LoRA 中的权重可以随机初始化,也可以基于相关模型的洞察进行初始化。当期望适应仅进行少量更改以有效适应时,也可以使用零初始化。
– **迁移学习洞察**:通常,最佳初始化方案受到迁移学习原理的启发,其中权重最初接近预训练模型的权重,以保留先前学习到的特征。
### 精确定位潜在向量空间中的特征
关于从自动编码器、GAN 或 VAE 等模型中的潜在向量空间提取像人脸“鼻子”这样的特定特征:
#### 1. 识别特征向量
– **降维**:使用 PCA 或 t-SNE 来降低潜在空间的维度,并可视化哪些维度与特定特征高度相关。
– **解耦表示**:训练 β-VAE 等模型,鼓励学习解耦表示,其中独立的潜在维度对应于独立的特征。
– **可解释性工具**:使用模型可解释性工具和技术,例如层相关性传播 (LRP) 或集成梯度,来识别潜在向量的哪些部分对特定输出特征(如人脸的各个部分)影响最大。
#### 2. 操作特定特征
– **特征隔离**:一旦识别出特征向量,就可以通过调整其值来操作它,以查看它如何影响重建的输出,从而有效地增强、减弱或改变该特征。
– **特征标记和训练**:如果识别出与“鼻子”等特征相对应的特定向量或一组权重,您可以对其进行标记并重新训练模型,可以冻结其他权重,也可以允许进行小的适应以完善特征的表示。
#### 3. 训练以进行特定特征提取
– **目标学习**:您可以专门训练一个模型来识别和修改特定特征,使用目标损失函数,该函数仅对该特征的不准确性对模型进行惩罚。
– **使用注释进行微调**:使用标记了特定特征的注释数据集可以帮助训练模型更好地识别和操作这些特征。使用此类数据进行微调可以特别增强模型调整和准确表示这些特征的能力。
### 结论
没有简单、一刀切的方法可以精确地定位潜在空间中的特定特征。这通常需要结合高级模型训练、智能初始化、可解释性技术,有时还需要创造性的工程解决方案。关键在于迭代实验,并结合机器学习的理论知识、数据的实践见解以及可用于模型优化和解释的高级工具集。